【数据结构实战篇】用C语言实现你的私有队列
🏝️专栏:【数据结构实战篇】
🌅主页:f狐o狸x

在前面的文章中我们用C语言实现了栈的数据结构,本期内容我们将实现队列的数据结构
一、队列的概念
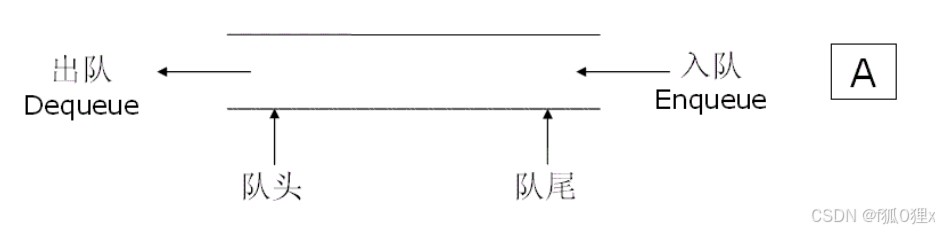
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out)
入队列:进行插入操作的一端称为队尾
出队列:进行删除操作的一端称为队头
二、队列的实现
2.1 队列的定义
动用你聪明的小脑袋想一想队列的结构是啥样的,是不是从队尾插入数据,再从队头输出数据,那是不是在队列的结构里面需要一个头结点,还需要一个尾节点,为了方便后面的操作,我们再加一个size变量来记录当前队列的大小
typedef int QDatatype;typedef struct QueueNode
{QDatatype Data;struct QueueNode* next;
}QueueNode;typedef struct Queue
{struct QueueNode* head;struct QueueNode* tail;int size;
}Queue;
2.2 队列的初始化
//初始化队列
void QueueInit(Queue* pq)
{pq->size = 0;pq->head = NULL;pq->tail = NULL;
}2.3 队列入、出
其实这里就是简单的尾插和头删
//队列增
void QueuePush(Queue* pq, QDatatype x)
{QueueNode* newnode = (QueueNode*)malloc(sizeof(QueueNode));if (newnode == NULL){perror("malloc fail");return;}newnode->Data = x;newnode->next = NULL;if (pq->head == NULL){assert(pq->tail == NULL);pq->head = pq->tail = newnode;}else{pq->tail->next = newnode;pq->tail = newnode;}pq->size++;
}
//队列删
void QueuePop(Queue* pq)
{assert(pq);assert(!QueueEmpty(pq));QueueNode* cur = pq->head;if (cur->next == NULL){free(cur);cur = NULL;}else{pq->head = pq->head->next;free(cur);cur = NULL;}pq->size--;
}
2.4 检查队列是否为空、队列大小
//队列大小
int QueueSize(Queue* pq)
{assert(pq);return pq->size;
}
//判断队列是否为空
bool QueueEmpty(Queue* pq)
{assert(pq);return pq->size == 0;
}2.5 返回队头、队尾
//返回队头
QDatatype QueueFront(Queue* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->head->Data;
}
//返回队尾
QDatatype QueueBack(Queue* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->tail->Data;
}2.6 测试队列
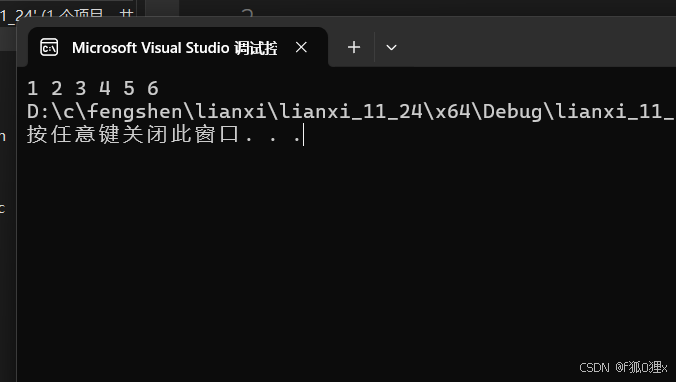
int main()
{Queue Q = { 0 };QueueInit(&Q);QueuePush(&Q, 1);QueuePush(&Q, 2);QueuePush(&Q, 3);QueuePush(&Q, 4);QueuePush(&Q, 5);QueuePush(&Q, 6);while (!QueueEmpty(&Q)){printf("%d ", QueueFront(&Q));QueuePop(&Q);}return 0;
}运行结果如下:
三、实战练习
学习了栈和队列的数据结构,我们现在就来练练手
3.1 有效的括号
力扣链接:有效的括号
给定一个只包括
'(',')','{','}','[',']'的字符串s,判断字符串是否有效
3.1.1题目分析
这个题可以用栈的结构来完成这个题,如果字符串中是左括号 ‘ ( ’ ‘ [ ’ ‘ { ’,则正常入栈,如果字符串为右括号‘ ) ’ ‘ ] ’ ‘ } ’,则将这个字符和栈顶元素对比,如果相等就进行下一次循环,如果没有匹配成功,则放回false,循环结束后,并且栈里没有元素了,就返回true,记得在每次返回的时候将空间释放了,不要有内存泄漏哈~
3.1.2 解题代码
对了,因为这里用的是c语言,因此我们需要自己手搓一个栈,不过问题不大啦
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>typedef int StackDataType;typedef struct stack
{int* StackData;int top;int capacity;
}ST;//初始化
void InitStack(ST* ps);
//销毁
void DestoryStack(ST* ps);
//增加
void STPush(ST* ps, StackDataType x);
//删除
void STPop(ST* ps);
//判断是否为空
bool STEmpty(ST* ps);
//栈顶位置
StackDataType STTop(ST* ps);//初始化
void InitStack(ST* ps)
{assert(ps);ps->StackData = (StackDataType*)malloc(sizeof(StackDataType)*4);if (ps->StackData == NULL){perror("InitStack::malloc");return;}ps->capacity = 4;ps->top = 0;
}//销毁
void DestoryStack(ST* ps)
{assert(ps);free(ps->StackData);ps->StackData = NULL;ps->capacity = 0;ps->top = 0;
}//增加
void STPush(ST* ps, StackDataType x)
{assert(ps);if (ps->top == ps->capacity){StackDataType* tmp = (StackDataType*)realloc(ps->StackData,sizeof(StackDataType) * ps->capacity * 2);if(tmp == NULL){perror("STPush::realloc");return;}ps->StackData = tmp;ps->capacity *= 2;}ps->StackData[ps->top] = x;ps->top += 1;}//删除
void STPop(ST* ps)
{assert(ps);assert(!STEmpty(ps));ps->top--;
}//判断是否为空
bool STEmpty(ST* ps)
{assert(ps);return ps->top == 0;
}//栈顶位置
StackDataType STTop(ST* ps)
{assert(ps);assert(!STEmpty(ps));return ps->StackData[ps->top - 1];
}bool isValid(char* s) {ST st = {0};InitStack(&st);char* ps = s;while(*s){if(*s == '(' || *s == '[' || *s == '{'){STPush(&st, *s);//左括号入栈}else{if(STEmpty(&st)){DestoryStack(&st);return false;}char top = STTop(&st);STPop(&st);if((*s == ')' && top != '(') ||(*s == ']' && top != '[') ||(*s == '}' && top != '{')){DestoryStack(&st);return false; }}s++;}bool ret = STEmpty(&st);DestoryStack(&st);return ret;
}3.2 用队列实现栈
力扣链接:用队列实现栈
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)
3.2.1 题目分析
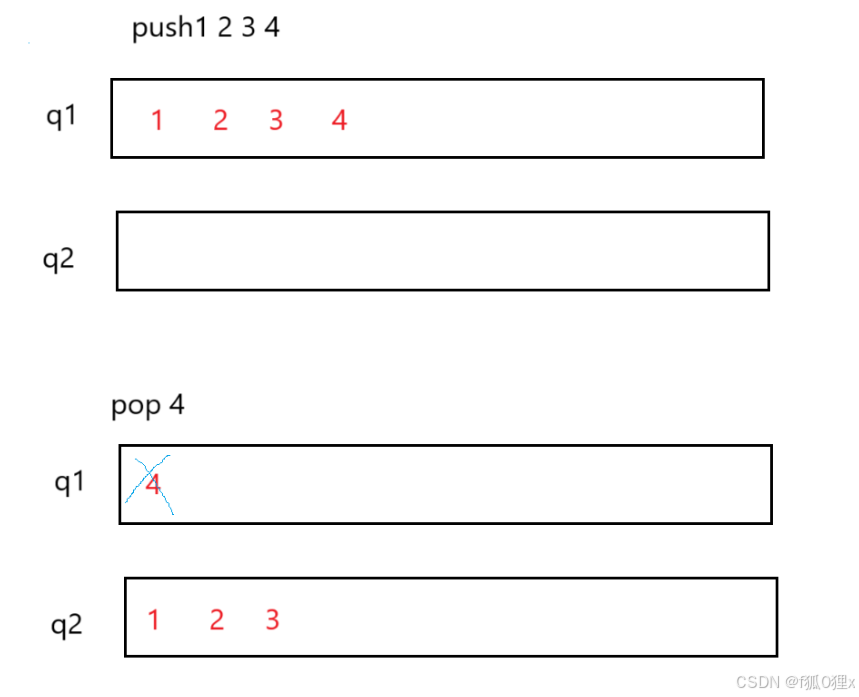
题目要求我们用两个队列来实现栈的结构,因此我们可以先随便将数据输入到一个队列中,再把队列一中的数据除了最后一个,全部转移到另外一个空的队列中,这样就可以实现栈的操作
3.2.2 解题代码
这里也是同样的需要我们手搓一个队列出来,不过上面已经实现过来,所以我们直接cv一下
typedef int QDatatype;typedef struct QueueNode
{QDatatype Data;struct QueueNode* next;
}QueueNode;typedef struct Queue
{struct QueueNode* head;struct QueueNode* tail;int size;
}Queue;//初始化队列
void QueueInit(Queue* pq);
//销毁队列
void QueueDestroy(Queue* pq);
//队列增
void QueuePush(Queue* pq, QDatatype x);
//队列删
void QueuePop(Queue* pq);
//队列大小
int QueueSize(Queue* pq);
//判断队列是否为空
bool QueueEmpty(Queue* pq);
//返回队头
QDatatype QueueFront(Queue* pq);
//返回队尾
QDatatype QueueBack(Queue* pq);//初始化队列
void QueueInit(Queue* pq)
{pq->size = 0;pq->head = NULL;pq->tail = NULL;
}//销毁队列
void QueueDestroy(Queue* pq)
{assert(pq);QueueNode* cur = pq->head;while (cur){QueueNode* del = cur;cur = cur->next;free(del);}pq->head = NULL;pq->tail = NULL;pq->size = 0;
}
//队列增
void QueuePush(Queue* pq, QDatatype x)
{QueueNode* newnode = (QueueNode*)malloc(sizeof(QueueNode));if (newnode == NULL){perror("malloc fail");return;}newnode->Data = x;newnode->next = NULL;if (pq->head == NULL){assert(pq->tail == NULL);pq->head = pq->tail = newnode;}else{pq->tail->next = newnode;pq->tail = newnode;}pq->size++;
}
//队列删
void QueuePop(Queue* pq)
{assert(pq);assert(!QueueEmpty(pq));if (pq->head->next == NULL){free(pq->head);pq->head = NULL;}else{QueueNode* next = pq->head->next;free(pq->head);pq->head = next;}pq->size--;
}
//队列大小
int QueueSize(Queue* pq)
{assert(pq);return pq->size;
}
//判断队列是否为空
bool QueueEmpty(Queue* pq)
{assert(pq);return pq->size == 0;
}
//返回队头
QDatatype QueueFront(Queue* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->head->Data;
}
//返回队尾
QDatatype QueueBack(Queue* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->tail->Data;
}typedef struct {Queue q1;Queue q2;
} MyStack;MyStack* myStackCreate() {MyStack* pst = (MyStack*)malloc(sizeof(MyStack));if(pst == NULL){perror("myStackCreate::malloc");}QueueInit(&pst->q1);QueueInit(&pst->q2);return pst;
}void myStackPush(MyStack* obj, int x) {if(!QueueEmpty(&obj->q1)){QueuePush(&obj->q1,x);}else{QueuePush(&obj->q2,x);}
}int myStackPop(MyStack* obj) {Queue* emptyQ = &obj->q1;Queue* nonemptyQ = &obj->q2;if(!QueueEmpty(&obj->q1)){emptyQ = &obj->q2;nonemptyQ = &obj->q1;}while(QueueSize(nonemptyQ)>1){QueuePush(emptyQ,QueueFront(nonemptyQ));QueuePop(nonemptyQ);}int top = QueueFront(nonemptyQ);QueuePop(nonemptyQ);return top;
}int myStackTop(MyStack* obj) {if(!QueueEmpty(&obj->q1)){return QueueBack(&obj->q1);}else{return QueueBack(&obj->q2);}}bool myStackEmpty(MyStack* obj) {return QueueEmpty(&obj->q1) && QueueEmpty(&obj->q2);
}void myStackFree(MyStack* obj) {QueueDestroy(&obj->q1);QueueDestroy(&obj->q2);free(obj);
}本期内容到这里就完啦,感谢大家观看~
对了对了,留下你的三连吧,求你啦~ QAQ

相关文章:
【数据结构实战篇】用C语言实现你的私有队列
🏝️专栏:【数据结构实战篇】 🌅主页:f狐o狸x 在前面的文章中我们用C语言实现了栈的数据结构,本期内容我们将实现队列的数据结构 一、队列的概念 队列:只允许在一端进行插入数据操作,在另一端…...

基于web的海贼王动漫介绍 html+css静态网页设计6页+设计文档
📂文章目录 一、📔网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站演示 五、⚙️网站代码 🧱HTML结构代码 💒CSS样式代码 六、🔧完整源码下载 七、📣更多 一、&#…...

2022 年 9 月青少年软编等考 C 语言三级真题解析
目录 T1. 课程冲突T2. 42 点思路分析T3. 最长下坡思路分析T4. 吃糖果思路分析T5. 放苹果思路分析T1. 课程冲突 此题为 2021 年 9 月三级第一题原题,见 2021 年 9 月青少年软编等考 C 语言三级真题解析中的 T1。 T2. 42 点 42 42 42 是: 组合数学上的第 5 5 5 个卡特兰数字…...

机器学习算法(六)---逻辑回归
常见的十大机器学习算法: 机器学习算法(一)—决策树 机器学习算法(二)—支持向量机SVM 机器学习算法(三)—K近邻 机器学习算法(四)—集成算法 机器学习算法(五…...

计算机科学中的主要协议
1、主要应用层协议: HTTP、FTP、SMTP、POP、IMAP、DNS、TELNET和SSH等 应用层协议的主要功能是支持网络应用,定义了不同应用程序之间的通信规则。它们负责将用户操作转换为网络可以理解的数据格式,并通过传输层进行传输。应用层协议直接与用…...

下载maven 3.6.3并校验文件做md5或SHA512校验
一、下载Apache Maven 3.6.3 Apache Maven 3.6.3 官方下载链接: 二进制压缩包(推荐): ZIP格式: https://archive.apache.org/dist/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.zipTAR.GZ格式: https://archive.apache.org/dist/…...

【Android】View工作原理
View 是Android在视觉上的呈现在界面上Android提供了一套GUI库,里面有很多控件,但是很多时候我们并不满足于系统提供的控件,因为这样就意味这应用界面的同类化比较严重。那么怎么才能做出与众不同的效果呢?答案是自定义View&#…...

TIE算法具体求解-为什么是泊松方程和傅里叶变换
二维泊松方程的通俗理解 二维泊松方程 是偏微分方程的一种形式,通常用于描述空间中某个标量场(如位相场、电势场)的分布规律。其一般形式为: ∇ 2 ϕ ( x , y ) f ( x , y ) \nabla^2 \phi(x, y) f(x, y) ∇2ϕ(x,y)f(x,y) 其…...
截取指定位数的字符等)
postman中获取随机数、唯一ID、时间日期(包括当前日期增减)截取指定位数的字符等
在Postman中,您可以使用内置的动态变量和编写脚本的方式来获取随机数、唯一ID、时间日期以及截取指定位数的字符。以下是具体的操作方法: 一、postman中获取随机数、唯一ID、时间日期(包括当前日期增减)截取指定位数的字符等 获取…...

【计算机网络】实验3:集线器和交换器的区别及交换器的自学习算法
实验 3:集线器和交换器的区别及交换器的自学习算法 一、 实验目的 加深对集线器和交换器的区别的理解。 了解交换器的自学习算法。 二、 实验环境 • Cisco Packet Tracer 模拟器 三、 实验内容 1、熟悉集线器和交换器的区别 (1) 第一步:构建网络…...

flink学习(14)—— 双流join
概述 Join:内连接 CoGroup:内连接,左连接,右连接 Interval Join:点对面 Join 1、Join 将有相同 Key 并且位于同一窗口中的两条流的元素进行关联。 2、Join 可以支持处理时间(processing time)和事件时…...

HTTP协议详解:从HTTP/1.0到HTTP/3的演变与优化
深入浅出:从头到尾全面解析HTTP协议 一、HTTP协议概述 1.1 HTTP协议简介 HTTP(HyperText Transfer Protocol,超文本传输协议)是互联网上应用最广泛的通信协议之一。它用于客户端与服务器之间的数据传输,尤其是在Web…...
张量并行和流水线并行在Transformer中的具体部位
目录 张量并行和流水线并行在Transformer中的具体部位 一、张量并行 二、流水线并行 张量并行和流水线并行在Transformer中的具体部位 张量并行和流水线并行是Transformer模型中用于提高训练效率的两种并行策略。它们分别作用于模型的不同部位,以下是对这两种并行的具体说…...

WEB开发: 丢掉包袱,拥抱ASP.NET CORE!
今天的 Web 开发可以说进入了一个全新的时代,前后端分离、云原生、微服务等等一系列现代技术架构应运而生。在这个背景下,作为开发者,你一定希望找到一个高效、灵活、易于扩展且具有良好性能的框架。那么,ASP.NET Core 显然是一个…...

【论文阅读】Federated learning backdoor attack detection with persistence diagram
目的:检测联邦学习环境下,上传上来的模型是不是恶意的。 1、将一个模型转换为|L|个PD,(其中|L|为层数) 如何将每一层转换成一个PD? 为了评估第𝑗层的激活值,我们需要𝑐个输入来获…...

Gooxi Eagle Stream 2U双路通用服务器:性能强劲 灵活扩展 稳定易用
人工智能的高速发展开启了飞轮效应,实施数字化变革成为了企业的一道“抢答题”和“必答题”,而数据已成为现代企业的命脉。以HPC和AI为代表的新业务就像节节攀高的树梢,象征着业务创新和企业成长。但在树梢之下,真正让企业保持成长…...

【计算机网络】实验2:总线型以太网的特性
实验 2:总线型以太网的特性 一、 实验目的 加深对MAC地址,IP地址,ARP协议的理解。 了解总线型以太网的特性(广播,竞争总线,冲突)。 二、 实验环境 • Cisco Packet Tracer 模拟器 三、 实…...

如何在Spark中使用gbdt模型分布式预测
这目录 1 训练gbdt模型2 第三方包python环境打包3 Spark中使用gbdt模型3.1 spark配置文件3.2 主函数main.py 4 spark任务提交 1 训练gbdt模型 我们可以基于lightgbm快速的训练一个gbdt模型,训练相对比较简单,只要把训练样本处理好,几行代码可…...

Qt-5.14.2 example
官方历程很丰富,modbus、串口、chart图表、3D、视频 共享方便使用 Building and Running an Example You can test that your Qt installation is successful by opening an existing example application project. To run an example application on an Android …...

virtualbox给Ubuntu22创建共享文件夹
1.在windows上的操作,创建共享文件夹Share 2.Ubuntu22上的操作,创建共享文件夹LinuxShare 3.在virtualbox虚拟机设置里,设置共享文件夹 共享文件夹路径:选择Windows系统中你需要共享的文件夹 共享文件夹名称:挂载至wi…...

ncmdumpGUI:三步解密网易云音乐NCM文件,实现音乐自由播放
ncmdumpGUI:三步解密网易云音乐NCM文件,实现音乐自由播放 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了心爱…...

2026中国AI应用全景图谱报告
这份《2026 中国 AI 应用全景图谱报告》由量子位智库发布,全景式呈现中国 AI 应用的生态格局、规模数据、发展趋势与标杆方案,揭示行业从工具化走向任务化、商业化与垂直深耕的关键跃迁。关注公众号:【互联互通社区】,回复【AI999…...

GIF动画处理工具Gifsicle:如何高效优化与管理动态图像资源
GIF动画处理工具Gifsicle:如何高效优化与管理动态图像资源 【免费下载链接】giflossy Merged into Gifsicle! 项目地址: https://gitcode.com/gh_mirrors/gi/giflossy Gifsicle是一个专为GIF动画处理而设计的命令行工具套件,它提供了完整的GIF文件…...

基于贝叶斯与ANOVA的模型逆向解释:从异常预测精准定位根因
1. 逆向解释:当模型预测“跑偏”时,我们如何找到“元凶”?在工业界摸爬滚打这些年,我处理过不少“事后诸葛亮”式的分析需求。比如,一条生产线的良率突然从99%掉到了95%,老板劈头盖脸就问:“哪个…...

跨平台资源下载终极指南:轻松获取视频号、抖音、直播流等全网资源
跨平台资源下载终极指南:轻松获取视频号、抖音、直播流等全网资源 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

终极免费方案:5分钟解锁Windows多用户远程桌面完整指南
终极免费方案:5分钟解锁Windows多用户远程桌面完整指南 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 还在为Windows家庭版限制远程桌面连接而烦恼吗?RDP Wrapper Library为您提供完美的解…...

聚合芘环石墨炔:机器学习模拟揭示新型二维碳负极材料的储锂潜力
1. 项目概述:从石墨烯到PolyPyGY,二维碳负极材料的进阶之路在锂离子电池这个已经相当成熟的领域里,负极材料的创新一直是推动能量密度和功率密度突破的关键。从早期的石墨,到后来的硅基材料,再到如今备受瞩目的二维材料…...

量子机器学习中的偏见:从编码到测量的系统性挑战与缓解策略
1. 量子机器学习中的偏见:一个被忽视的工程挑战量子机器学习(QML)正从理论实验室走向现实应用,从药物分子筛选到金融衍生品定价,其潜力令人兴奋。然而,作为一名长期关注量子算法落地的从业者,我…...

IGND算法:融合高斯牛顿法与增量学习的优化新范式
1. IGND算法:当高斯牛顿法遇见增量学习在机器学习的世界里,模型训练的本质就是一场持续的优化之旅。我们手握一个由参数构成的复杂函数,目标是在浩瀚的参数空间中,找到那个能让预测误差最小化的“甜蜜点”。多年来,随机…...

行列式点过程:从统计独立到负依赖的机器学习范式跃迁
1. 项目概述:从统计独立到负依赖的范式跃迁在机器学习和统计学的工具箱里,统计独立性长期以来扮演着基石的角色。从朴素贝叶斯分类器的特征条件独立假设,到蒙特卡洛方法中独立同分布的采样点,再到随机梯度下降中独立的小批量数据&…...