Flink四大基石之CheckPoint(检查点) 的使用详解
目录
一、Checkpoint 剖析
State 与 Checkpoint 概念区分
设置 Checkpoint 实战
执行代码所需的服务与遇到的问题
二、重启策略解读
重启策略意义
代码示例与效果展示
三、SavePoint
与 Checkpoint 异同
操作步骤详解
四、总结
在大数据流式处理领域,Apache Flink 凭借其卓越的性能和强大的功能占据重要地位。而理解 Flink 中的 Checkpoint(检查点)、重启策略以及 SavePoint(保存点)这些关键概念,对于保障流处理任务的稳定性、容错性以及可维护性至关重要。本文将深入剖析它们的原理、用法,并结合实际代码示例展示其效果,希望能帮助大家更好地掌握 Flink 相关知识。

一、Checkpoint 剖析
State 与 Checkpoint 概念区分
State(状态)
在 Flink 中,State 代表某一个 Operator(算子)在某一时刻的状态,像常见的聚合算子 maxBy、sum 等操作过程中就会维护状态信息。比如在对数据流按某个字段做 sum 聚合时,它需要记住历史数据以便持续累加计算,并且这些状态数据默认存于内存之中,为算子的持续、准确运行提供依据。
Checkpoint(检查点 / 快照点)
它是 Flink 中所有有状态的 Operator 在某一个特定时刻的 State 快照信息汇总,也就是 State 的存档记录。可以简单理解为对整个作业运行时状态拍了一张 “照片”,定格所有相关算子彼时的状态,方便后续在故障恢复等场景使用。
设置 Checkpoint 实战
以下是一段设置 Checkpoint 的 Flink Java 代码示例:
package com.bigdata.day06;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class _01CheckPointDemo {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 在windows运行,将数据提交hdfs,会出现权限问题,使用这个语句解决。System.setProperty("HADOOP_USER_NAME", "root");// 在这个基础之上,添加快照// 第一句:开启快照,每隔1s保存一次快照env.enableCheckpointing(1000);// 第二句:设置快照保存的位置env.setStateBackend(new FsStateBackend("hdfs://bigdata01:9820/flink/checkpoint"));// 第三句: 通过webui的cancel按钮,取消flink的job时,不删除HDFS的checkpoint目录env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);//2. source-加载数据DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 9999);SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = dataStreamSource.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String s) throws Exception {String[] arr = s.split(",");return Tuple2.of(arr[0], Integer.valueOf(arr[1]));}});//3. transformation-数据处理转换SingleOutputStreamOperator<Tuple2<String, Integer>> result = mapStream.keyBy(0).sum(1);result.print();//4. sink-数据输出//5. execute-执行env.execute();}
}执行代码所需的服务与遇到的问题
启动本地的nc, 启动hdfs服务。
启动代码,发现有权限问题:
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=admin, access=WRITE, inode="/flink":root:supergroup:drwxr-xr-x解决方案:
System.setProperty("HADOOP_USER_NAME", "root");
在设置检查点之前,设置一句这样带权限的语句,如果是集群运行中,不存在该问题。可以不设置!!!

查看快照情况:
运行,刷新查看checkpoint保存的数据,它会先生成一个新的文件夹,然后再删除老的文件夹,在某一时刻,会出现两个文件夹同时存在的情况。


启动HDFS、Flink
start-dfs.sh
start-cluster.sh数据是保存了,但是并没有起作用,想起作用需要在集群上运行,以下演示集群上的效果:
第一次运行的时候
在本地先clean, 再package ,再Wagon一下:

flink run -c 全类名 /opt/app/flink-test-1.0-SNAPSHOT.jarflink run -c com.bigdata.day06._01CheckPointDemo /opt/app/FlinkDemo-1.0-SNAPSHOT.jar记得,先启动nc ,再启动任务,否则报错!通过nc -lk 9999 输入以下内容:


想查看运行结果,可以通过使用的slot数量判断一下:


取消flink job的运行

查看一下这次的单词统计到哪个数字了:

第二次运行的时候
flink run -c 全类名 -s hdfs://hadoop10:8020/flink-checkpoint/293395ef7e496bda2eddd153a18d5212/chk-34 /opt/app/flink-test-1.0-SNAPSHOT.jar启动:
flink run -c com.bigdata.day06._01CheckPointDemo -s hdfs://bigdata01:9820/flink/checkpoint/bf416df7225b264fc34f8ff7e3746efe/chk-603 /opt/app/FlinkDemo-1.0-SNAPSHOT.jar-s 指定从checkpoint目录恢复状态数据 ,注意每个人都不一样
从上一次离开时,截止的checkpoint目录


观察数据:输入一个hello,1 得到新的结果hello,8

二、重启策略解读
重启策略意义
流式数据如同永不干涸的河流持续流淌,一旦因某条错误数据致使程序异常退出,后续海量数据丢失风险极高,对企业而言,这意味着数据资产受损、业务分析结果偏差等严重后果,重启策略应运而生。它作为独立策略,与 Checkpoint 虽无必然绑定关系(即便没配置 Checkpoint 也能单独配置重启策略),却在保障程序持续运行层面协同发挥关键作用。
一个流在运行过程中,假如出现了程序异常问题,可以进行重启,比如,在代码中人为添加一些异常:

进行wordcount时,输入了一个bug,1 人为触发异常。

注意:此时如果有checkpoint ,是不会出现异常的,需要将checkpoint的代码关闭,再重启程序。会发现打印了异常,那为什么checkpoint的时候不打印,因为并没有log4j的配置文件,需要搞一个这样的配置文件才行。
程序中添加log4j.properties的代码:
# Global logging configuration
# Debug info warn error
log4j.rootLogger=debug, stdout
# MyBatis logging configuration...
log4j.logger.org.mybatis.example.BlogMapper=TRACE
# Console output...
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
开启检查点之后,报错了程序还在运行是因为开启检查点之后,程序会进行自动重启(无限重启【程序错了才重启】)。
//开启checkpoint,默认是无限重启,可以设置为不重启
//env.setRestartStrategy(RestartStrategies.noRestart());//重启3次,重启时间间隔是10s
//env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(10, TimeUnit.SECONDS)));//2分钟内重启3次,重启时间间隔是5s
env.setRestartStrategy(RestartStrategies.failureRateRestart(3,Time.of(2,TimeUnit.MINUTES),Time.of(5,TimeUnit.SECONDS))
);env.execute("checkpoint自动重启"); //最后一句execute可以设置jobName,显示在8081界面程序如果上传至服务器端运行,可以看到重启状态

代码示例与效果展示
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.concurrent.TimeUnit;public class Demo02 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 代码中不能有checkpoint,不是说checkpoint不好,而是太好了,它已经自带重试机制了。而且是无限重启的// 通过如下方式可将重试机制关掉// env.setRestartStrategy(RestartStrategies.noRestart());//// 两种办法// 第一种办法:重试3次,每一次间隔10S//env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(10, TimeUnit.SECONDS)));// 第二种写法:在2分钟内,重启3次,每次间隔10senv.setRestartStrategy(RestartStrategies.failureRateRestart(3,Time.of(2,TimeUnit.MINUTES),Time.of(5,TimeUnit.SECONDS)));//2. source-加载数据DataStreamSource<String> streamSource = env.socketTextStream("bigdata01", 8899);streamSource.map(new MapFunction<String, Tuple2<String,Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {String[] arr = value.split(",");String word = arr[0];if(word.equals("bug")){throw new Exception("有异常,服务会挂掉.....");}// 将一个字符串变为int类型int num = Integer.valueOf(arr[1]);// 第二种将字符串变为数字的方法System.out.println(Integer.parseInt(arr[1]));Tuple2<String, Integer> tuple2 = new Tuple2<>(word,num);// 还有什么方法? 第二种创建tuple的方法Tuple2<String, Integer> tuple2_2 = Tuple2.of(word,num);return tuple2;}}).keyBy(tuple->tuple.f0).sum(1).print();//3. transformation-数据处理转换//4. sink-数据输出//5. execute-执行env.execute();}
} 在此代码中人为在 map 函数里设置异常触发点(输入包含 “bug” 的数据时抛出异常)。若开启 Checkpoint,因它自带重试机制(默认无限重启),异常可能被掩盖,需关闭 Checkpoint 相关代码才能看到异常打印情况。同时,要完整看到重启策略效果(如按设定的次数、间隔重启),需打包代码上传至集群运行,本地测试难以呈现完整现象,且提交时务必确认使用的类名准确无误。
三、SavePoint
与 Checkpoint 异同
相同点
本质都是对 Flink 作业状态的一种保存方式,以便后续恢复作业时复用状态,保障数据处理连贯性。
不同点
Checkpoint 是 Flink 自动按设定规则周期性完成 State 快照保存,旨在应对故障自动恢复场景;而 SavePoint 是手动触发的快照操作,提供更灵活的作业状态管理时机,比如在版本升级、业务规则调整需暂停并后续重启作业场景发挥优势。
操作步骤详解
提交作业并输入数据
提交含重启策略代码打包成的 jar 包运行作业(类似 flink run -c 全类名 /opt/app/flink-test-1.0-SNAPSHOT.jar),输入数据观察单词对应数字变化。

执行 SavePoint 操作
以下是 --> 停止flink job,并且触发savepoint操作
flink stop --savepointPath hdfs://bigdata01:9820/flink-savepoint 152e493da9cdeb327f6cbbad5a7f8e41后面的序号为Job 的ID以下是 --> 不会停止flink的job,只是完成savepoint操作
flink savepoint 79f53c5c0bb3563b6b6ed3011176c411 hdfs://bigdata01:9820/flink-savepoint备注:如何正确停止一个 flink 的任务
flink stop 6a27b580aa5c6b57766ae6241d9270ce(任务编号)
查看与重启作业

查看最近完成作业对应的 SavePoint,之后依据之前保存路径重启作业(flink run -c 全类名 -s hdfs://hadoop10:8020/flink-savepoint/savepoint-79f53c-64b5d94771eb /opt/app/flink-test-1.0-SNAPSHOT.jar),再次输入数据可看到基于之前状态的累加效果。

此外,在集群运行 Flink 程序时,默认并行度常为 1,它不会按照机器的CPU核数,而是按照配置文件中的一个默认值运行的。比如:flink-conf.yaml

web-ui 界面提交作业:

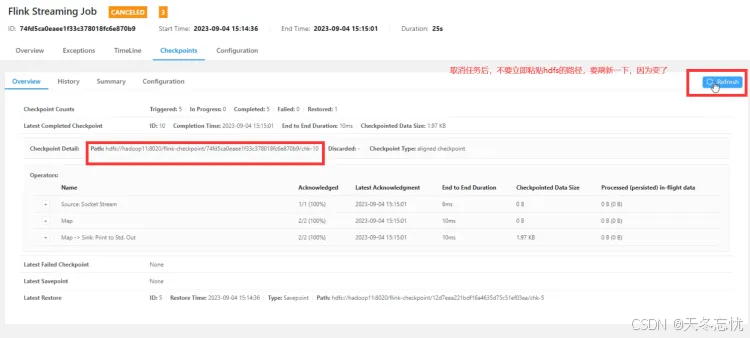
这个图形化界面,跟我们使用如下命令是一个效果:
flink run -c com.bigdata.day06._01CheckPointDemo -s hdfs://bigdata01:9820/flink/checkpoint/bf416df7225b264fc34f8ff7e3746efe/chk-603 /opt/app/FlinkDemo-1.0-SNAPSHOT.jar四、总结
通过对 Flink 中 Checkpoint、重启策略和 SavePoint 的详细解读与代码实践展示,我们明晰它们各自在保障流处理任务稳定、容错与灵活运维层面的独特价值。合理运用这些机制,能助我们打造更健壮、高效的 Flink 大数据处理应用,从容应对复杂多变的业务需求与运行环境挑战,后续大家可在实际项目中深入实践优化,挖掘其更大潜力。
相关文章:
Flink四大基石之CheckPoint(检查点) 的使用详解
目录 一、Checkpoint 剖析 State 与 Checkpoint 概念区分 设置 Checkpoint 实战 执行代码所需的服务与遇到的问题 二、重启策略解读 重启策略意义 代码示例与效果展示 三、SavePoint 与 Checkpoint 异同 操作步骤详解 四、总结 在大数据流式处理领域,Ap…...
)
JVM 常见面试题及解析(2024)
目录 一、JVM 基础概念 二、JVM 内存结构 三、类加载机制 四、垃圾回收机制 五、性能调优 六、实战问题 七、JVM 与其他技术结合 八、JVM 内部机制深化 九、JVM 相关概念拓展 十、故障排查与异常处理 一、JVM 基础概念 1、什么是 JVM?它的主要作用是…...

Python 调用 Umi-OCR API 批量识别图片/PDF文档数据
目录 一、需求分析 二、方案设计(概要/详细) 三、技术选型 四、OCR 测试 Demo 五、批量文件识别完整代码实现 六、总结 一、需求分析 市场部同事进行采购或给客户报价时,往往基于过往采购合同数据,给出现在采购或报价的金额…...

K8S资源之secret资源
secret资源介绍 secret用于敏感数据存储,底层基于base64编码,数据存储在etcd数据库中 应用场景举例: 数据库的用户名,密码,tls的证书ssh等服务的相关证书 secret的基础管理 1 在命令行响应式创建 1.响应式创建 …...

QT:信号和槽01
QT中什么是信号和槽 概念解释 在 Qt 中,信号(Signals)和槽(Slots)是一种用于对象间通信的机制。信号是对象发出的事件通知,而槽是接收并处理这些通知的函数。 例如,当用户点击一个按钮时&#…...

针对Qwen-Agent框架的Function Call及ReAct的源码阅读与解析:Agent基类篇
文章目录 Agent继承链Agent类总体架构初始化方法`__init__` 方法:`_init_tool` 方法:对话生成方法`_call_llm` 方法:工具调用方法`_call_tool` 方法:`_detect_tool` 方法:整体执行方法`run` 方法:`_run` 方法:`run_nonstream` 方法总结回顾本文在 基于Qwen-Agent框架的Functio…...

XML 查看器:深入理解与高效使用
XML 查看器:深入理解与高效使用 XML(可扩展标记语言)是一种用于存储和传输数据的标记语言。它通过使用标签来定义数据结构,使得数据既易于人类阅读,也易于机器解析。在本文中,我们将探讨 XML 查看器的功能、重要性以及如何高效使用它们。 什么是 XML 查看器? XML 查看…...

《Vue零基础入门教程》第十五课:样式绑定
往期内容 《Vue零基础入门教程》第六课:基本选项 《Vue零基础入门教程》第八课:模板语法 《Vue零基础入门教程》第九课:插值语法细节 《Vue零基础入门教程》第十课:属性绑定指令 《Vue零基础入门教程》第十一课:事…...

以AI算力助推转型升级,暴雨亮相CCF中国存储大会
2024年11月29日-12月1日,CCF中国存储大会(CCF ChinaStorage 2024)在广州市长隆国际会展中心召开。本次会议以“存力、算力、智力”为主题,由中国计算机学会(CCF)主办,中山大学计算机学院、CCF信…...

【VMware】Ubuntu 虚拟机硬盘扩容教程(Ubuntu 22.04)
引言 想装个 Anaconda,发现 Ubuntu 硬盘空间不足。 步骤 虚拟机关机 编辑虚拟机设置 扩展硬盘容量 虚拟机开机 安装 gparted sudo apt install gparted启动 gparted sudo gparted右键sda3,调整分区大小 新大小拉满 应用全部操作 调整完成...

3D Bounce Ball Game 有什么技巧吗?
关于3D Bounce Ball Game(3D弹球游戏)的开发,以下是一些具体的技巧和实践建议: 1. 物理引擎的使用: 在Unity中,使用Rigidbody组件来为游戏对象添加物理属性,这样可以让物体受到重力影响并发…...

【SQL】实战--组合两个表
题目描述 表: Person ---------------------- | 列名 | 类型 | ---------------------- | PersonId | int | | FirstName | varchar | | LastName | varchar | ---------------------- personId 是该表的主键(具有唯一值的列)…...

Spring基于注解实现 AOP 切面功能
前言 在Spring AOP(Aspect-Oriented Programming)中,动态代理是常用的技术之一,用于在运行时动态地为目标对象生成代理对象, 并拦截其方法调用。Spring AOP 默认使用两种类型的动态代理机制:JDK 动态代理和…...

设计模式 更新ing
设计模式 1、六大原则1.1 单一设计原则 SRP1.2 开闭原则1.3 里氏替换原则1.4 迪米特法则1.5 接口隔离原则1.6 依赖倒置原则 2、工厂模式 1、六大原则 1.1 单一设计原则 SRP 一个类应该只有一个变化的原因 比如一个视频软件,区分不同的用户级别 包括访客࿰…...

Elasticsearch 进阶
核心概念 索引(Index) 一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索…...

【AI】Sklearn
长期更新,建议关注、收藏、点赞。 友情链接: AI中的数学_线代微积分概率论最优化 Python numpy_pandas_matplotlib_spicy 建议路线:机器学习->深度学习->强化学习 目录 预处理模型选择分类实例: 二分类比赛 网格搜索实例&…...

通过 JNI 实现 Java 与 Rust 的 Channel 消息传递
做纯粹的自己。“你要搞清楚自己人生的剧本——不是父母的续集,不是子女的前传,更不是朋友的外篇。对待生命你不妨再大胆一点,因为你好歹要失去它。如果这世上真有奇迹,那只是努力的另一个名字”。 一、crossbeam_channel 参考 crossbeam_channel - Rust crossbeam_channel…...

【老白学 Java】对象的起源 Object
对象的起源 Object 文章来源:《Head First Java》修炼感悟。 上一篇文章中,老白学习了抽象类和抽象方法,不禁感慨,原来 Java 还可以这样玩。 同时又有了新的疑问,这些父类从何而来的? 本篇文章老白来聊一聊…...

Ubuntu Linux操作系统
一、 安装和搭建 Thank you for downloading Ubuntu Desktop | Ubuntu (这里我们只提供一个下载地址,详细的下载安装可以参考其他博客) 二、ubuntu的用户使用 2.1 常规用户登陆方式 在系统root用户是无法直接登录的,因为root用户的权限过…...

SpringBoot 打造的新冠密接者跟踪系统:企业复工复产防疫保障利器
摘 要 信息数据从传统到当代,是一直在变革当中,突如其来的互联网让传统的信息管理看到了革命性的曙光,因为传统信息管理从时效性,还是安全性,还是可操作性等各个方面来讲,遇到了互联网时代才发现能补上自古…...

在OpenClaw中配置Taotoken实现多模型Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw中配置Taotoken实现多模型Agent工作流 OpenClaw是一个流行的开源Agent框架,它允许开发者构建和编排基于大语…...

如何在Hermes Agent中自定义配置Taotoken提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何在Hermes Agent中自定义配置Taotoken提供商 基础教程类,为使用Hermes Agent的开发者提供配置指南,详细…...

Wand-Enhancer终极教程:三步解锁WeMod Pro高级功能完整指南
Wand-Enhancer终极教程:三步解锁WeMod Pro高级功能完整指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod Pro订阅费烦恼吗&am…...

初次使用Taotoken,从注册到成功发起第一次API调用的全过程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken,从注册到成功发起第一次API调用的全过程 对于初次接触大模型API的开发者而言,从注册平台…...

观察Taotoken在多模型间自动路由与容灾切换的实际响应情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型间自动路由与容灾切换的实际响应情况 在构建依赖大模型服务的应用时,服务的连续性与稳定性是开发…...

长期使用Taotoken Token Plan套餐对项目预算管理的帮助
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐对项目预算管理的帮助 对于需要持续调用大模型API的项目而言,成本的可预测性与可控性…...

如何免费将PPTX转为HTML?纯JavaScript终极解决方案完整指南
如何免费将PPTX转为HTML?纯JavaScript终极解决方案完整指南 【免费下载链接】PPTX2HTML Convert pptx file to HTML by using pure javascript 项目地址: https://gitcode.com/gh_mirrors/pp/PPTX2HTML 在数字化办公和在线教育的时代,你是否经常需…...
)
嵌入式开发 10 大经典硬件 BUG + 定位解决(15 年工程师踩坑实录)
一、引言 嵌入式系统是 "硬件 软件" 的紧密结合体,据统计,嵌入式开发中约 30% 的问题最终根源是硬件设计或焊接缺陷。与软件 BUG 不同,硬件 BUG 具有以下特点: 隐蔽性强:很多问题只在特定温度、电压或电磁…...

生成式AI驱动业务流程自动化:从流程挖掘到智能重构
1. 从流程执行到流程创造:生成式AI如何重塑BPM在业务流程管理(BPM)领域摸爬滚打了十几年,我亲眼见证了它从一套僵化的流程图和审批流,演变为一个动态的、数据驱动的智能决策中枢。传统的BPM核心在于“建模-执行-监控-优…...

记忆学习导向的高速运动感知图像的去模糊及目标识别【附数据】
✨ 长期致力于深度卷积网络、长短期记忆网络、相机高速运动感知、运动去模糊、运动目标识别研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)融合DCNN与…...