linux 获取公网流量 tcpdump + python + C++
前言
需求为,统计linux上得上下行公网流量,常规得命令如iftop 、sar、ifstat、nload等只能获取流量得大小,不能区分公私网,所以需要通过抓取网络包并排除私网段才能拿到公网流量。下面提供了一些有效得解决思路,提供了部分得代码片段,但不提供整个代码内容。
方案
方案一:在Linux服务器上安装服务,抓取到数据包后发送到中央计算服务器
优点:①由于计算是在中央,并不会占用linux业务服务器得资源性能
缺点:①通过scp或其他传输手段,会占用一定得网络资源,特别当数据量大时
②中央计算服务器得资源易达到瓶颈,需要开多个计算节点
方案二:在Linux服务器上安装服务,抓取到数据包后本地处理,直接将结果发至中央
优点:①中央节点压力减小,数据实时性提升
缺点:①每个linux服务器都需要抓包并且处理,需要占用一定的计算资源,且单位包越大消耗越高
方案三:在同层交换机上放置旁路监控服务器,抓取广播域内所有包,逐个分析每个linux服务器上的流量情况
优点:
①独立部署,不会占用linux服务器资源
②维护相对容易,linux业务服务器与监控节点解耦,只需要维护监控节点而不需要维护linux服务器
缺点:
①需要跟linux服务器处在一个广播域,并且要求性能足够,当linux业务服务器数据过多时,易有瓶颈
②可能存在漏抓包的情况
③需要监听所有得vlan,并分别部署监控节点
方案四:加入流控设备,旁路到核心网关
优点:
①无需自研,有成熟的抓取功能,且有更多丰富的功能
缺点:
①成本较高
②缺乏控制能力,比如流量限速,阻断等
下面主要介绍第一和第二种方法得实现
方案一技术实现
先来看技术拓扑图,流程为:
- linux服务器开启tcpdump抓包
- linux服务器将pcap包发送到流量分析服务器
- 流量服务器进行公私网流量拆分,公网白名单过滤
- 获取步骤三得结果并传输到中央

下面讲解每一步得实现细节
1.linux服务器开启tcpdump抓包
核心命令为"tcpdump", "-i", interface , f"host {target_ip}", '-s 96',"-w", output_file ,'-p'
-i 接网卡名,host接希望抓取得ip(可不填),-s 96 表示只抓取包头部(可能有得包头超过这个长度,但96依然是个比较适中得值,-w 保存为pcap包,-p 关闭混杂模式(避免监听到广播得其他包使流量过多)
#执行tcpdump抓包
def run_tcpdump(target_ip):INTERVAL = 60interface = getInterface() #获取网卡名timestamp = datetime.now().strftime("%Y-%m-%dT%H:%M:%S") now = datetime.now().strftime("%Y-%m-%d %H:%M:%S") #获取开始时间output_file = f"{SAVEPATH}/xxx_{timestamp}.pcap"tcpdump_command = ["tcpdump", "-i", interface , f"host {target_ip}", '-s 96',"-w", output_file ,'-p']try:process = subprocess.Popen(tcpdump_command) #使用subprocess执行shell命令time.sleep(INTERVAL) #定义休眠时间process.terminate() #结束shell命令process.wait() #等待子进程退出,确保子进程清理完成except Exception as e:logger.error(f"xxx")2.linux服务器将pcap包发送到流量分析服务器
这一个步骤没有太多可讲得,使用socket 或requests 或 subprocess(scp)都可以,目的就是将抓取到得包发送到流量分析服务器。
3.流量服务器进行公私网流量拆分,公网白名单过滤
这一步是关键步骤,公私网流量,公网白名单过滤拆分需要一定得计算性能,所以核心代码推荐用C++语言编写,博主测试过同代码情况下,python C++ java得表现能力,C++(或C)性能要远超其他语言,如同体积包,假设占用30%得单核心性能,C++可以做到1%以内。
代码要实现两点:
1.公私网彻底拆分
2.过滤公网白名单内的(不希望统计得)数据
公私网流量拆分参考以下代码片段,首先剔除三类子网地址(0xFF000000 是掩码(255.0.0.0 的二进制形式),只保留 IP 地址的最高 8 位。0x0A000000 是 10.0.0.0 的二进制形式。)
注意:现在得大型网络多采用overlay得方式,有些ip虽然在私网段,但由于走了vxlan隧道占用了公网带宽,其实也是数据公网得。后续得处理需读者自行处理。
bool is_private_ip(const std::string &ip) {struct in_addr addr;inet_pton(AF_INET, ip.c_str(), &addr);uint32_t ip_addr = ntohl(addr.s_addr);// 10.0.0.0/8if ((ip_addr & 0xFF000000) == 0x0A000000) return true;// 172.16.0.0/12if ((ip_addr & 0xFFF00000) == 0xAC100000) return true;// 192.168.0.0/16if ((ip_addr & 0xFFFF0000) == 0xC0A80000) return true;return false;
}定义4个变量分别存公网下行,公网上行,私网下行,私网上行
uint64_t public_in= 0;uint64_t public_out = 0;uint64_t private_in = 0;uint64_t private_out = 0; pcap_t *handle = pcap_open_offline(pcap_file.c_str(), errbuf); #获取pcap包pcap_next_ex(handle, &header, &data) #调用libpcap 捕获库 const struct ip *ip_header = (struct ip *)(data + sizeof(struct ether_header)); #获取包得headstd::string src_ip = inet_ntoa(ip_header->ip_src); #获取src ipstd::string dst_ip = inet_ntoa(ip_header->ip_dst); #获取dst ip#判断是私网还是公网if (dst_ip == target_ip) {if (is_private_ip(src_ip)) {private_in += pkt_len;} else {public_in += pkt_len;}} else if (src_ip == target_ip) {if (is_private_ip(dst_ip)) {private_out += pkt_len;} else {public_out += pkt_len;}}接下来是过滤不希望统计的ip名单,在上面代码的基础上再做一层判断即可,
#判断是私网还是公网if (dst_ip == target_ip) {if (is_private_ip(src_ip)) {private_in += pkt_len;} else {if (filter_write(src_ip)){ #return true则公网ip不在白名单内,需要加和public_in += pkt_len;}}} else if (src_ip == target_ip) {if (is_private_ip(dst_ip)) {private_out += pkt_len;} else {if (filter_write(src_ip)){public_out += pkt_len;}}}4.获取步骤三得结果上报并持久化
拿到公网流量后,传输给用于持久化的程序进行入库操作(对于此类数据,建议用clickhouse进行建库,对体量小的用mysql也可以接受).关于传输方式,可以选择使用生产消费者方式,使用消息中间件缓冲数据(如Kafka)。数据量小通过http/https协议传输后插入也可以。
kafka模板
def push_kafka(data, retries=5, backoff_factor=1):logger.info(f"上传 {data}")# 配置 Kafka 生产者kafka_config = {'bootstrap.servers': KAFKA_URL, # 替换为你的 Kafka 地址'client.id': 'my-producer',}producer = Producer(kafka_config)topic = KAFKA_TOPIC # 替换为你的 Kafka 主题名# 重试逻辑for attempt in range(retries):try:# 将数据转换为 JSON 格式并发送到 Kafkaproducer.produce(topic=topic, value=json.dumps(data), callback=delivery_report)producer.flush() # 强制刷新缓冲区logger.info("数据上传成功")return # 成功后返回except KafkaException as e:logger.error(f"Kafka error occurred: {e}")except Exception as e:logger.error(f"Unexpected error: {e}")# 等待后重试wait_time = backoff_factor * (2 ** attempt)logger.info(f"等待 {wait_time} 秒后重试...")time.sleep(wait_time)logger.error("所有重试均失败")http/https直传
def post_with_retries_center(data, retries=5, backoff_factor=1):URL_CENTER = "192.168.10.10" #填自己的地址logger.info(f"上传{data}")session = requests.Session()headers = {'Content-Type': 'application/json',}# 定义重试策略retry_strategy = Retry(total=retries,status_forcelist=[404, 500, 502, 503, 504],allowed_methods=["POST"],backoff_factor=backoff_factor)# 创建适配器并将其安装到会话对象中adapter = HTTPAdapter(max_retries=retry_strategy)session.mount("http://", adapter)session.mount("https://", adapter)try:response = requests.post(URL_CENTER, json=data, headers=headers)response.raise_for_status() # 如果响应状态码不是200,则抛出异常except requests.exceptions.ConnectionError as conn_err:logger.error(f"Connection error occurred: {conn_err}")except requests.exceptions.Timeout as timeout_err:logger.error(f"Timeout error occurred: {timeout_err}")except requests.exceptions.RequestException as req_err:logger.error(f"An error occurred: {req_err}")except Exception as e:logger.error(f"Unexpected error: {e}")return None方案二技术实现
在Linux服务器上安装服务,抓取到数据包后本地处理,直接将结果发至中央
流程为
- linux服务器开启tcpdump抓包
- linux服务器分析包,获取私网、公网流量结果
- linux服务器推送消息中间件
- 中央消费者对消息消费并入库
方案二与方案一代码几乎相同,只是职权不同,原linux不需要处理包,现在需要处理,所以处理程序应该在linux服务器上,处理后推送到消息中间件,由中央消费者进行消费即可。代码片段这里就不贴了

结尾
本文章内容适用于基于linux系统的流量包分析,方案本身是完整闭环的。其中对包的处理快慢以及对公、私网的ip段判断、消息推送的方式这些是可以持续优化的点。由于方案本身具备一定商用价值,故没有贴上源码,若读者需要可联系博主提供。
相关文章:
linux 获取公网流量 tcpdump + python + C++
前言 需求为,统计linux上得上下行公网流量,常规得命令如iftop 、sar、ifstat、nload等只能获取流量得大小,不能区分公私网,所以需要通过抓取网络包并排除私网段才能拿到公网流量。下面提供了一些有效得解决思路,提供了…...

C++知识整理day3类与对象(下)——赋值运算符重载、取地址重载、列表初始化、友元、匿名对象、static
文章目录 1.赋值运算符重载1.1 运算符重载1.2 赋值运算符重载 2.取地址重载2.1 const成员函数2.2 取地址运算符重载 3.类与对象的补充3.1 再探构造函数---初始化列表3.2 类型转换3.3 static成员3.4 友元3.5 内部类3.6 匿名对象3.7 对象拷贝时的编译器优化 1.赋值运算符重载 赋…...

pytest(二)excel数据驱动
一、excel数据驱动 excel文件内容 excel数据驱动使用方法 import openpyxl import pytestdef get_excel():excel_obj openpyxl.load_workbook("../pytest结合数据驱动-excel/data.xlsx")sheet_obj excel_obj["Sheet1"]values sheet_obj.valuescase_li…...

python蓝桥杯刷题3
1.解方程组解 题解:首先让a,b,c进行遍历,然后计算得到1000时输出结果,其次考虑1000开根号是多大,计算得到32的倍数是1024,所有选择(1,32)进行遍历,…...

基于PySpark 使用线性回归、随机森林以及模型融合实现天气预测
基于PySpark 实现天气预测与模型集成 在大数据分析与机器学习领域,Spark 提供了强大的计算能力和灵活的扩展性。本文将介绍如何利用 PySpark 完成以下任务: 1、数据预处理:清洗和编码天气数据。 2、特征工程:合并数值和分类特征…...

Day 30 贪心算法 part04
今天的三道题目,都算是 重叠区间 问题,大家可以好好感受一下。 都属于那种看起来好复杂,但一看贪心解法,惊呼:这么巧妙! 这种题还是属于那种,做过了也就会了,没做过就很难想出来。 不过大家把如下三题做了之后, 重叠区间 基本上差不多了 452. 用最少数量的箭引爆气球…...

dns实验3:主从同步-完全区域传输
服务器192.168.234.111(主服务器),打开配置文件: 打开配置文件: 关闭防火墙,改宽松模式: 重启服务: 服务器192.168.234.112(从服务器),打开配置文…...

数据结构 (20)二叉树的遍历与线索化
一、二叉树的遍历 遍历是对树的一种最基本的运算,所谓遍历二叉树,就是按一定的规则和顺序走遍二叉树的所有节点,使每一个节点都被访问一次,而且只被访问一次。二叉树的遍历方式主要有四种:前序遍历、中序遍历、后序遍历…...

【docker】Overlay网络
什么是 Overlay 网络? Overlay 网络是一种 Docker 网络驱动,允许容器在不同主机间通信。 它依赖分布式存储(如 Swarm、Etcd 或 Consul)来管理网络配置和路由。 Overlay 网络的核心特点 跨主机通信:容器可以跨物理主…...

基于智能语音交互的智能呼叫中心工作机制
在智能化和信息化不断进步的现代,智能呼叫中心为客户提供高质量、高效率的服务体验,提升众多品牌用户的满意度和忠诚度。作为实现智能呼叫中心的关键技术之一的智能语音交互技术,它通过集成自然语言处理(NLP)、语音识别…...

Linux条件变量线程池详解
一、条件变量 【互斥量】解决了线程间同步的问题,避免了多线程对同一块临界资源访问产生的冲突,但同一时刻对临界资源的访问,不论是生产者还是消费者,都需要竞争互斥锁,由此也带来了竞争的问题。即生产者和消费者、消费…...

有趣的Docker
👉【腾讯云】云服务器、云数据库、COS、CDN、短信等云产品特惠热卖中 1. Docker 上的“全世界”命令行 你可以在 Docker 容器中运行一个模拟的 “世界地图”,并通过命令行与它互动。这是一个非常有趣的项目,结合了命令行和图形界面的交互。…...

深入探讨锁升级问题
1. 引言 本文深入探讨锁升级问题。 2. 锁升级问题概述 2.1 锁升级的概念 2.1.1 定义 锁升级是指数据库管理系统将较低粒度的锁(如行级锁)转换为较高粒度的锁(如表级锁)的过程。这种情况通常发生在事务对同一对象的多个较低粒…...

MySQL篇—通过官网下载linux系统下多种安装方式的MySQL社区版软件
💫《博主介绍》:✨又是一天没白过,我是奈斯,DBA一名✨ 💫《擅长领域》:✌️擅长Oracle、MySQL、SQLserver、阿里云AnalyticDB for MySQL(分布式数据仓库)、Linux,也在扩展大数据方向的知识面✌️…...

6.824/6.5840(2024)环境配置wsl2+vscode
本文是经过笔者实践得出的最速の环境配置 首先,安装wsl2和vscode 具体步骤参见Mit6.s081环境配置踩坑之旅WSL2VScode_mit6s081-CSDN博客 接下来开始为Ubuntu(笔者使用的版本依然是20.04)配置go的相关环境 1、更新Ubuntu的软件包 sudo apt-get install build-es…...
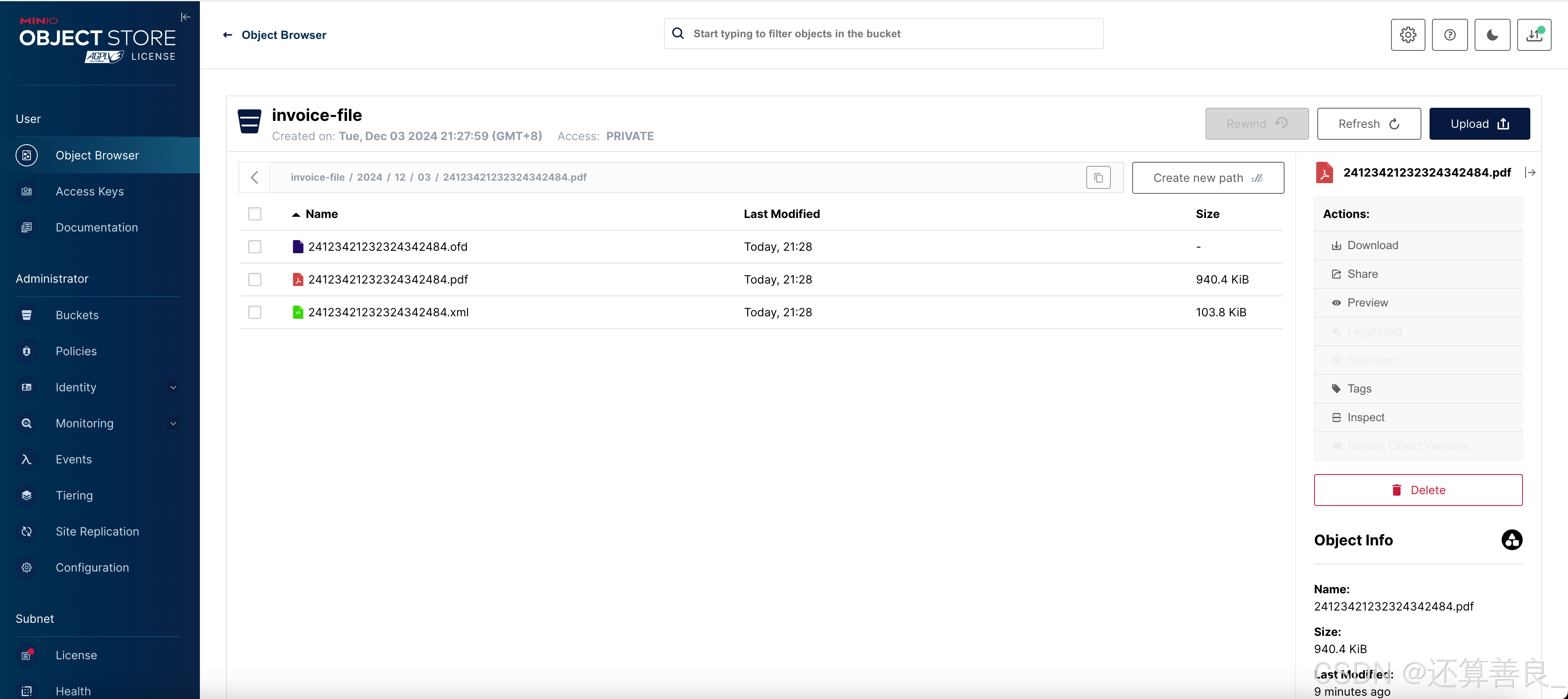
【乐企文件生成工程】搭建docker环境,使用docker部署工程
1、自行下载docker 2、自行下载docker-compose 3、编写Dockerfile文件 # 使用官方的 OpenJDK 8 镜像 FROM openjdk:8-jdk-alpine# 设置工作目录 WORKDIR ./app# 复制 JAR 文件到容器 COPY ../lq-invoice/target/lq-invoice.jar app.jar # 暴露应用程序监听的端口 EXPOSE 1001…...

常见的数据结构---队列、树与堆的深入剖析
目录 一、队列 二、树 三、堆 在现代计算机科学与工程领域,队列、树和堆是三种极其重要的基础数据结构,它们各自具有独特的特点和应用。在日常开发中,合理选择和使用这些数据结构可以显著提高程序的效率和可维护性。它们不仅奠定了算法设计…...

leetcode--螺旋矩阵
LCR 146.螺旋遍历二维数组 给定一个二维数组 array,请返回「螺旋遍历」该数组的结果。 螺旋遍历:从左上角开始,按照 向右、向下、向左、向上 的顺序 依次 提取元素,然后再进入内部一层重复相同的步骤,直到提取完所有元…...

JavaScript(JS)的对象
目录 1.array 数组对象 2.String 字符串对象 3.JSON 对象(数据载体,进行数据传输) 4.BOM 浏览器对象 5.DOM 文档对象(了解) 1.array 数组对象 定义方式1:var 变量名 new Array(元素列表); 定义方式…...

基于BM1684的AI边缘服务器-模型转换,大模型一体机
介绍 我们属于SoC模式,即我们在x86主机上基于tpu-nntc和libsophon完成模型的编译量化与程序的交叉编译,部署时将编译好的程序拷贝至SoC平台(1684开发板/SE微服务器/SM模组)中执行。 注:以下都是在Ubuntu20.04系统上操…...

Realsense D435i相机标定避坑指南:从棋盘格准备到OpenCV立体校正全流程
Realsense D435i相机标定实战:从硬件配置到立体校正的完整避坑手册 在三维视觉和机器人领域,相机标定是构建精准感知系统的基石。Intel Realsense D435i作为一款广泛使用的深度相机,其标定质量直接影响着SLAM、三维重建等应用的精度。本文将分…...

Go HTTP Router 深度解析:从原理到实战
Go HTTP Router 深度解析:从原理到实战 引言 在Go语言的Web开发中,Router是核心组件之一。高效的路由系统能够显著提升Web应用的性能和可维护性。本文将深入探讨Go语言HTTP Router的实现原理,并通过实战案例展示如何构建高性能的路由系统。 一…...

别再怕时序违例了!聊聊数字IC设计里那个‘偷时间’的Timing Borrow技巧
数字IC设计中的时序魔术:Timing Borrow实战解析 时钟信号如同城市交通的指挥灯,而数据信号则是川流不息的车辆。当某个路口(关键路径)出现拥堵时,传统做法是拓宽道路(优化逻辑)或降低车速&#…...

UniApp视频模块深度配置:云打包与Android离线打包的差异详解与选型建议
UniApp视频模块深度配置:云打包与Android离线打包的差异详解与选型建议 在移动应用开发领域,视频功能已成为提升用户体验的关键要素。UniApp作为跨平台开发框架,其VideoPlayer模块的集成方式直接影响着开发效率和最终产品质量。面对云打包与离…...

Balena Etcher:3步搞定镜像烧录,告别传统工具烦恼
Balena Etcher:3步搞定镜像烧录,告别传统工具烦恼 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 你是否曾为制作启动盘而烦恼࿱…...

Gemini3.1Pro和GPT5.5写代码到底谁更强五类任务实测数据说
做多模型编码能力横向对比测试时用了AI模型聚合平台,一站接入两个模型方便跑同一套编码任务。Gemini 3.1 Pro在SWE-Bench Verified拿到80.6%。GPT-5.5在Terminal-Bench拿到82.7%。分数接近但写代码的实际体验和分数不是一回事。这次用五类真实开发任务做了一轮系统对…...

GPT-4稀疏激活真相:2%参数如何实现高效推理
1. 项目概述:参数规模与稀疏激活的真相拆解 “GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区反复刷屏,常被当作“大模型已突破算力瓶颈”的标志性论断。但作为从2017年就开始部署LSTM语音识别系统、…...

gd32f303烧录提示Flash Timeout. Reset the Target and try it again.;
出现这个原因,是因为我在代码中使用了: ob_security_protection_config(FMC_USPC); // 开启保护 保护装置,导致烧录的时候出现 Flash Timeout. Reset the Target and try it again.; Error: Flash Download failed - "Cort…...

C#从零开始学习笔记---第九天
又是新的一天,欢迎大家继续查看我的学习笔记,这两天确实状态一般,今天内容我们也不记录太多,主要分为两大块,第一块是对之前提到过的数组进行一个复习,第二块就是在记录一下集合和哈希表的一些内容。话不多…...

B/S架构模式在校园管理系统中的应用研究
随着校园信息化建设的不断普及,各类校园管理系统层出不穷,系统架构模式直接决定系统的使用便捷性、运维难度与适配场景。传统C/S架构即客户端/服务器架构,需要用户下载安装专属客户端,存在部署繁琐、升级困难、跨终端适配差、运维…...