每日算法一练:剑指offer——树篇(4)
1.计算二叉树的深度
某公司架构以二叉树形式记录,请返回该公司的层级数。
示例 1:
输入:root = [1, 2, 2, 3, null, null, 5, 4, null, null, 4] 输出: 4 解释: 上面示例中的二叉树的最大深度是 4,沿着路径 1 -> 2 -> 3 -> 4 或 1 -> 2 -> 5 -> 4 到达叶节点的最长路径上有 4 个节点。
方法一:后序遍历(DFS)
算法解析
- 特点:后序遍历是深度优先搜索的一种实现方式,在递归中先计算子树的深度,再计算当前树的深度。
- 关键点:
- 每个节点的深度等于其左子树深度和右子树深度中的较大值 + 1。
- 利用递归实现。
步骤
- 终止条件:如果当前节点
root为空,则返回深度 0。 - 递归计算:
- 计算当前节点左子树的深度,
calculateDepth(root.left)。 - 计算当前节点右子树的深度,
calculateDepth(root.right)。
- 计算当前节点左子树的深度,
- 返回值:
- 返回当前节点深度,即
max(左子树深度, 右子树深度) + 1。
- 返回当前节点深度,即
Java代码
class Solution {public int calculateDepth(TreeNode root) {if (root == null) {return 0; // 如果节点为空,深度为0}// 递归计算左、右子树的深度,取较大值加1return Math.max(calculateDepth(root.left), calculateDepth(root.right)) + 1;}
}复杂度分析
- 时间复杂度:O(N),每个节点仅被访问一次。
- 空间复杂度:O(N),最差情况下(退化为链表),递归栈的深度为 N。
方法二:层序遍历(BFS)
算法解析
- 特点:层序遍历是广度优先搜索的一种实现方式,通过逐层遍历计算树的深度。
- 关键点:
- 每遍历一层时,计数器
res增加 1。 - 通过队列存储当前层的所有节点,依次将下一层节点加入队列。
- 每遍历一层时,计数器
步骤
- 初始化:
- 队列
queue存储根节点。 - 深度计数器
res初始化为 0。
- 队列
- 循环遍历:
- 每次遍历队列中的所有节点,将它们的子节点加入一个临时队列
tmp。 - 将临时队列赋值给
queue,表示更新为下一层节点。 - 深度计数器
res自增。
- 每次遍历队列中的所有节点,将它们的子节点加入一个临时队列
- 终止条件:当队列为空时,说明所有节点都已遍历完成,返回深度计数器。
Java代码
class Solution {public int calculateDepth(TreeNode root) {if (root == null) {return 0; // 如果节点为空,深度为0}// 递归计算左、右子树的深度,取较大值加1return Math.max(calculateDepth(root.left), calculateDepth(root.right)) + 1;}
}
复杂度分析
- 时间复杂度:O(N),每个节点仅被访问一次。
- 空间复杂度:O(N),最差情况下(完全平衡树),队列中最多同时存储 N/2 个节点。
两种方法对比
| 方法 | 适用场景 | 优缺点 |
|---|---|---|
| DFS | 递归计算,适合理解树的递归性质。 | 代码简洁,递归深度受栈空间限制,可能导致栈溢出。 |
| BFS | 遍历树的所有层,计算深度或查找某一层内容。 | 使用队列实现,较耗内存,但避免了递归深度的限制。 |
选择建议
- 如果树的节点较少,DFS 和 BFS 都适合。
- 如果树的节点较多且深度较大,建议使用 BFS,以避免递归导致的栈溢出问题。
2.判断是否为平衡二叉树
输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。
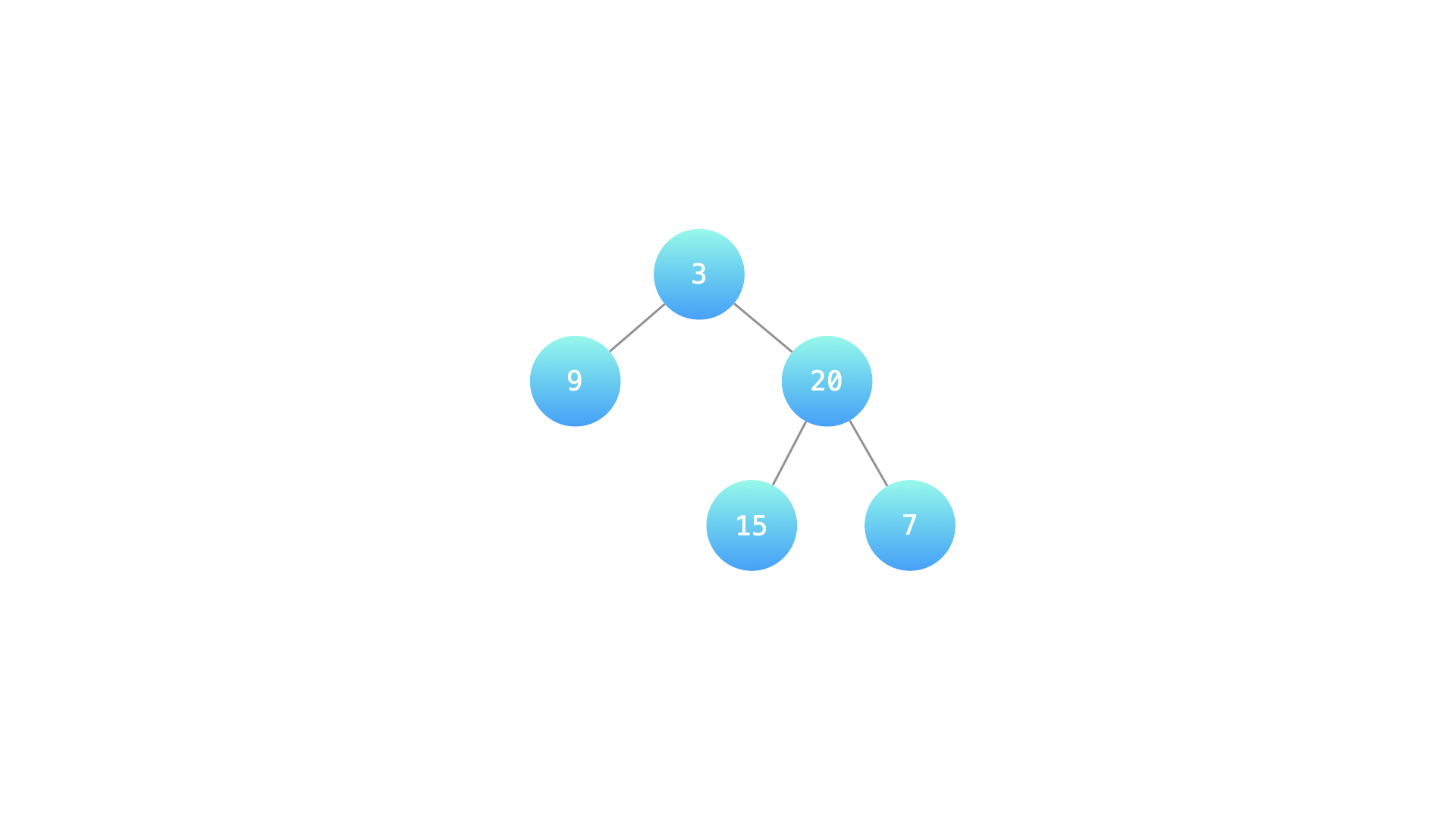
示例 1:
输入:root = [3,9,20,null,null,15,7] 输出:true 解释:如下图
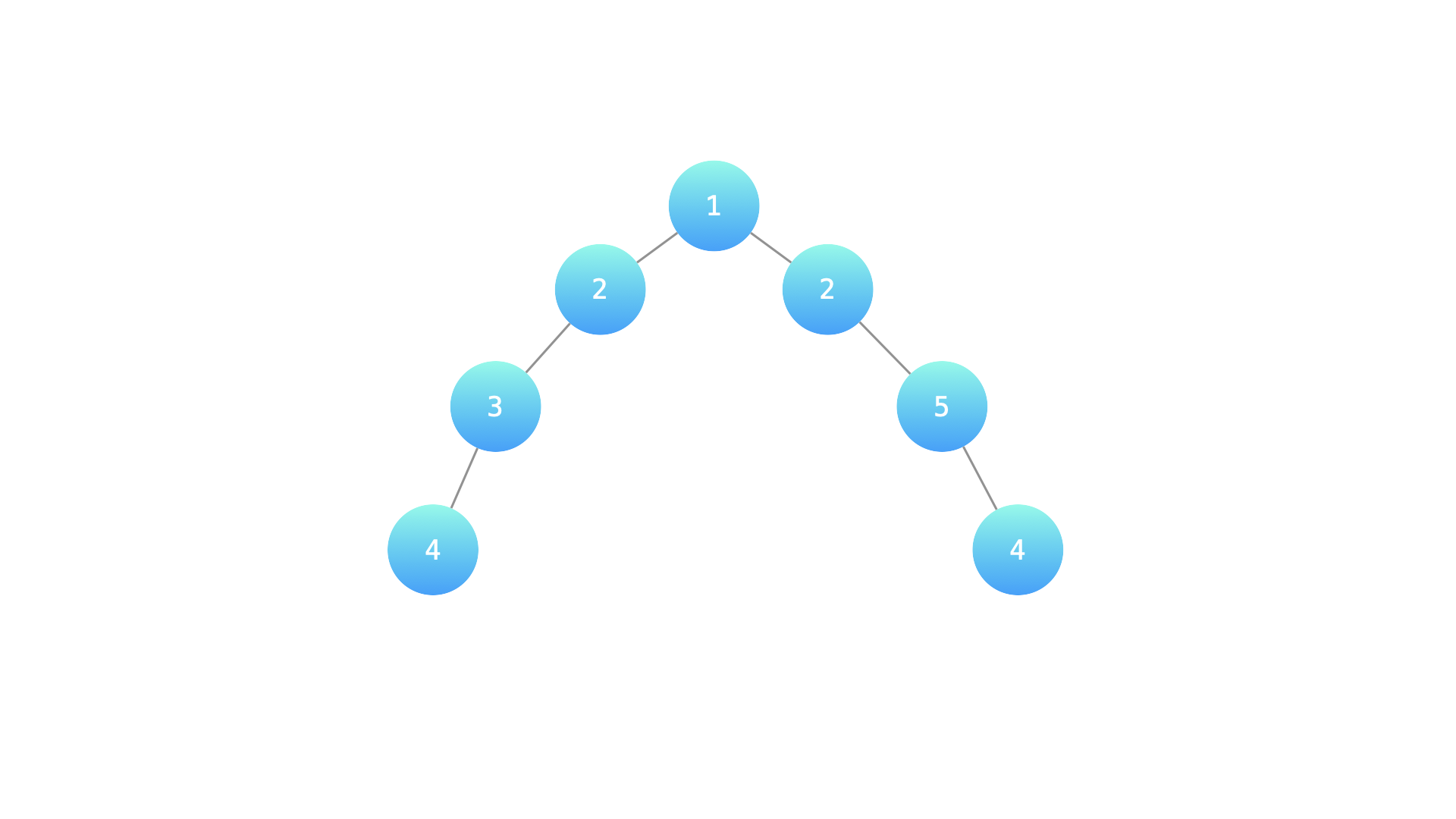
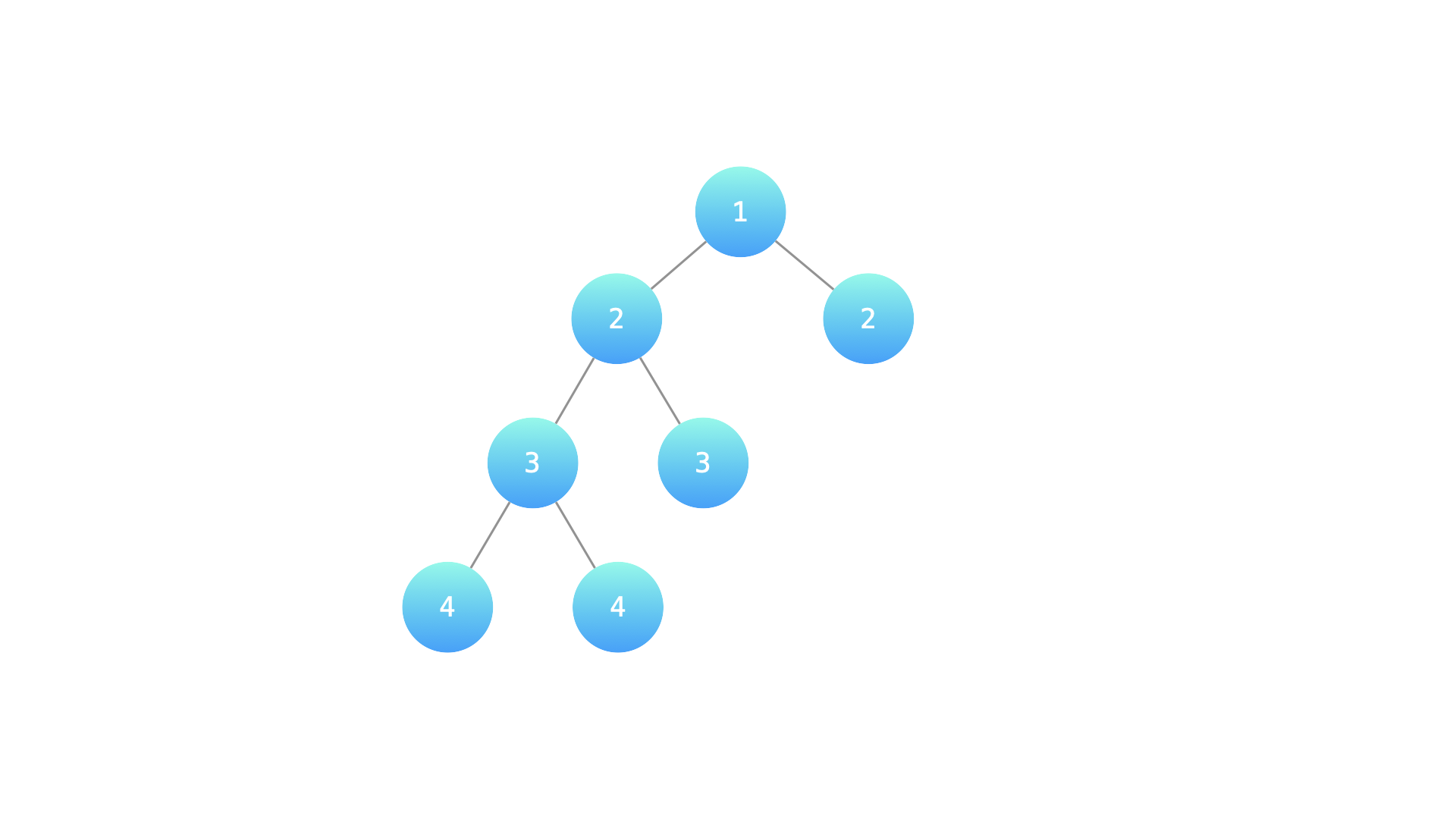
示例 2:
输入:root = [1,2,2,3,3,null,null,4,4] 输出:false 解释:如下图
提示:
0 <= 树的结点个数 <= 10000
解题思路解析
题目要求判断一棵二叉树是否是平衡二叉树,所谓平衡二叉树的定义是:任意节点的左右子树深度之差不超过1。
基于此,可以通过两种方式实现:
- 后序遍历 + 剪枝(从底至顶判断)
- 先序遍历 + 深度判断(从顶至底判断)
方法一:后序遍历 + 剪枝
核心思路
利用后序遍历的方式计算子树深度,同时在递归过程中判断当前子树是否平衡。如果发现某个子树不平衡,立即返回,减少无效计算。
算法步骤
- 定义一个递归函数
recur(root),用于返回当前节点的子树深度:- 如果当前节点为
null,返回深度为0; - 递归求左右子树的深度
left和right; - 如果左右子树已经被标记为不平衡(深度为
-1),则直接返回-1; - 如果左右子树深度差大于
1,也返回-1; - 否则,返回当前节点的深度,即
max(left, right) + 1。
- 如果当前节点为
- 在主函数
isBalanced(root)中调用recur(root),判断返回值是否为-1。如果是,则说明树不平衡,返回false;否则返回true。
代码实现(Java)
class Solution {public boolean isBalanced(TreeNode root) {return recur(root) != -1;}private int recur(TreeNode root) {if (root == null) return 0; // 叶子节点高度为 0int left = recur(root.left); // 左子树高度if (left == -1) return -1; // 左子树不平衡,直接剪枝int right = recur(root.right); // 右子树高度if (right == -1) return -1; // 右子树不平衡,直接剪枝return Math.abs(left - right) <= 1 ? Math.max(left, right) + 1 : -1; // 判断当前节点是否平衡}
}
复杂度分析
- 时间复杂度:
每个节点最多访问一次,因此时间复杂度为 O(N),其中 NNN 是节点总数。 - 空间复杂度:
系统递归栈的深度取决于树的高度,最坏情况下(树退化为链表)空间复杂度为 O(N)。
方法二:先序遍历 + 深度判断
核心思路
通过一个辅助函数 depth(root) 计算当前节点的深度,并在主函数中递归判断每个节点是否满足平衡条件。若任一节点不满足条件,则标记整棵树不平衡。
算法步骤
- 定义辅助函数
depth(root),用于计算树的深度:- 若节点为
null,返回深度0; - 否则递归计算左右子树深度,返回
max(left, right) + 1。
- 若节点为
- 主函数
isBalanced(root):- 若根节点为
null,直接返回true; - 通过
depth(root.left)和depth(root.right)计算左右子树深度,判断是否满足平衡条件:abs(left - right) <= 1; - 同时递归判断左右子树是否平衡。
- 若根节点为
- 只有当所有节点均满足条件时,返回
true。
代码实现(Java)
class Solution {public boolean isBalanced(TreeNode root) {if (root == null) return true; // 空树是平衡的return Math.abs(depth(root.left) - depth(root.right)) <= 1 // 当前节点平衡&& isBalanced(root.left) // 左子树平衡&& isBalanced(root.right); // 右子树平衡}private int depth(TreeNode root) {if (root == null) return 0; // 空节点深度为 0return Math.max(depth(root.left), depth(root.right)) + 1; // 递归计算深度}
}
复杂度分析
- 时间复杂度:
- 最坏情况(满二叉树):每个节点都需要调用
depth计算子树深度,每次计算需遍历整个子树,导致时间复杂度为 O(NlogN)。 - 最优情况(剪枝效果明显):当某子树不平衡时提前结束计算,降低时间复杂度。
- 最坏情况(满二叉树):每个节点都需要调用
- 空间复杂度:
同方法一,递归栈深度为树的高度,最坏情况下为 O(N)。
方法对比
| 方法 | 时间复杂度 | 空间复杂度 | 适用场景 |
|---|---|---|---|
| 后序遍历 + 剪枝 | O(N) | O(N) | 效率优先 |
| 先序遍历 + 判断 | O(NlogN) | O(N) | 思路简单易懂 |
3.二叉搜索树的最近公共祖先
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
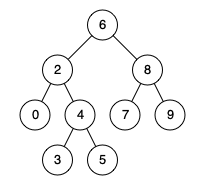
示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 输出: 6 解释: 节点 2 和节点 8 的最近公共祖先是 6。
示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4 输出: 2 解释: 节点2和节点4的最近公共祖先是2, 因为根据定义最近公共祖先节点可以为节点本身。
说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉搜索树中。
这是关于在 二叉搜索树(BST) 中寻找两个节点最近公共祖先(LCA)的经典题目。以下是思路的详细解析和实现过程:
核心概念:
-
祖先的定义:
如果节点p是节点root的左子树或右子树中的节点,或者p == root,则称root是p的祖先。 -
最近公共祖先的定义:
节点root是p和q的公共祖先,并且root是离p和q最近的那个祖先。根据这一定义,最近公共祖先可能有以下三种情况:p和q分别位于root的左右子树中。p == root且q在root的子树中。q == root且p在root的子树中。
二叉搜索树的性质:
- 对于任意节点
root:- 若
p.val和q.val都小于root.val,说明它们都在左子树。 - 若
p.val和q.val都大于root.val,说明它们都在右子树。 - 否则,
root就是最近公共祖先。
- 若
方法一:迭代
思路:
- 从根节点
root开始遍历。 - 根据
p和q的值相对于root.val的大小关系决定遍历方向:- 如果
p和q都在右子树中,进入右子树。 - 如果
p和q都在左子树中,进入左子树。 - 否则,当前节点就是最近公共祖先。
- 如果
- 返回找到的
root。
优化:
通过保证 p.val < q.val,可以减少判断条件。
代码(优化版):
class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {if (p.val > q.val) { // 确保 p.val < q.valTreeNode temp = p;p = q;q = temp;}while (root != null) {if (root.val < p.val) { // p, q 都在右子树root = root.right;} else if (root.val > q.val) { // p, q 都在左子树root = root.left;} else {break; // 找到最近公共祖先}}return root;}
}
方法二:递归
思路:
- 对于当前节点
root,判断p和q的值:- 如果
p和q都小于root,递归左子树。 - 如果
p和q都大于root,递归右子树。 - 否则,当前节点就是最近公共祖先。
- 如果
- 返回找到的
root。
代码:
class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {if (root.val < p.val && root.val < q.val) {return lowestCommonAncestor(root.right, p, q);}if (root.val > p.val && root.val > q.val) {return lowestCommonAncestor(root.left, p, q);}return root; // root 是最近公共祖先}
}
复杂度分析:
- 时间复杂度:
- 最好情况:树是平衡的,树高为 logN,每次递归或迭代排除一半子树,复杂度为 O(logN)。
- 最坏情况:树退化成链表,复杂度为 O(N)。
- 空间复杂度:
- 迭代:O(1),无需额外空间。
- 递归:最差情况下递归深度为 O(N)。
4.二叉树的最近公共祖先
解题思路
定义
- 祖先:若节点 ppp 在节点 rootrootroot 的子树中,或 p=rootp = rootp=root,则称 rootrootroot 是 ppp 的祖先。
- 最近公共祖先:设节点 rootrootroot 为节点 p,qp, qp,q 的某公共祖先,若其左子节点 root.leftroot.leftroot.left 和右子节点 root.rightroot.rightroot.right 都不是 p,qp, qp,q 的公共祖先,则称 rootrootroot 为“最近公共祖先”。
思路概述
我们通过递归遍历的方式来解决:
- 当递归到底部时返回
null。 - 如果当前节点是 ppp 或 qqq,直接返回当前节点。
- 对当前节点的左右子树分别递归,返回值记为 leftleftleft 和 rightrightright。
- 根据 leftleftleft 和 rightrightright 的情况判断当前节点是否是最近公共祖先。
具体判断
-
终止条件:
- 当前节点 rootrootroot 为
null,直接返回null。 - 当前节点等于 ppp 或 qqq,直接返回 rootrootroot。
- 当前节点 rootrootroot 为
-
递推逻辑:
- 对左子树递归调用,返回值为 leftleftleft。
- 对右子树递归调用,返回值为 rightrightright。
-
返回值分析:
- 情况 1:left=nullleft = nullleft=null 且 right=nullright = nullright=null,说明当前节点的左右子树都不包含 p,qp, qp,q,返回
null。 - 情况 2:left≠nullleft \neq nullleft=null 且 right≠nullright \neq nullright=null,说明 ppp 和 qqq 分别位于当前节点的左右子树,当前节点为最近公共祖先,返回 rootrootroot。
- 情况 3:left=nullleft = nullleft=null 且 right≠nullright \neq nullright=null,说明 p,qp, qp,q 均在右子树中,返回 rightrightright。
- 情况 4:left≠nullleft \neq nullleft=null 且 right=nullright = nullright=null,说明 p,qp, qp,q 均在左子树中,返回 leftleftleft。
- 情况 1:left=nullleft = nullleft=null 且 right=nullright = nullright=null,说明当前节点的左右子树都不包含 p,qp, qp,q,返回
代码实现
class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {// 终止条件if (root == null || root == p || root == q) return root;// 递归左右子树TreeNode left = lowestCommonAncestor(root.left, p, q);TreeNode right = lowestCommonAncestor(root.right, p, q);// 根据返回值判断if (left == null && right == null) return null; // 情况 1if (left != null && right != null) return root; // 情况 2return left != null ? left : right; // 情况 3 和 情况 4}
}
复杂度分析
- 时间复杂度:O(N)O(N)O(N)
- 每个节点最多被访问一次,因此时间复杂度为树中节点总数 NNN。
- 空间复杂度:O(N)O(N)O(N)
- 在最坏情况下,递归调用栈的深度等于树的高度,最差情况下(链状树)高度为 NNN。
示例分析
输入
二叉树:
3/ \5 1/ \ / \6 2 0 8/ \7 4
查找节点 5 和 1 的最近公共祖先。
输出
最近公共祖先是 3,因为 5 和 1 分别位于 3 的左右子树中。
递归过程:
- 从根节点 3 开始递归,左右子树分别找到 5 和 1。
- 5 和 1 分列于根节点 3 的异侧,返回 3 作为结果。
相关文章:
每日算法一练:剑指offer——树篇(4)
1.计算二叉树的深度 某公司架构以二叉树形式记录,请返回该公司的层级数。 示例 1: 输入:root [1, 2, 2, 3, null, null, 5, 4, null, null, 4] 输出: 4 解释: 上面示例中的二叉树的最大深度是 4,沿着路径 1 -> 2 -> 3 -&…...

Nginx静态资源配置
基本配置原则 明确资源目录:为不同类型的静态资源指定不同的路径,这样可以避免路径冲突,并且便于管理。正确设置文件权限:确保 Nginx 具有读取静态资源的权限。缓存优化:为静态资源设置缓存头(如 expires&…...

困扰解决:mfc140u.dll丢失的解决方法,多种有效解决方法全解析
当电脑提示“mfc140u.dll丢失”时,这可能会导致某些程序无法正常运行,给用户带来不便。不过,有多种方法可以尝试解决这个问题。这篇文章将以“mfc140u.dll丢失的解决方法”为主题,教大家有效解决mfc140u.dll丢失。 判断是否是“mf…...

D3.js 初探
文章目录 D3.js 简单介绍选择集与方法数据绑定方法选择集添加DOM元素以及删除元素理解update enter 以及 exit关于比例尺layout 布局force layout 坐标轴元素添加动态效果demo1: 绘制简单柱状图 #D3.js 初探 最近在做一个Data Visualization 的项目,由于对最终呈现的…...

linux常用指令 | 适合初学者
linux常用指令 1.ls: 列出当前,目录中的文件和子目录 ls 2.pwd: 显示当前工作目录的路径 pwd3.cd切换工作目录 cd /path/to/director4.mkdir:创建新目录 mkdir directory_name5.rmdir:删除空目录 rmdir directory_name6.rm: 删除文件或目录 rm file_name r…...

用 NotePad++ 运行 Java 程序
安装包 网盘链接 下载得到的安装包: 安装步骤 双击安装包开始安装. 安装完成: 配置编码 用 NotePad 写 Java 程序时, 需要设置编码. 在 设置, 首选项, 新建 中进行设置, 可以对每一个新建的文件起作用. 之前写的文件不起作用. 在文件名处右键, 可以快速打开 CMD 窗口, 且路…...

在 Linux 环境下搭建 OpenLab Web 网站并实现 HTTPS 和访问控制
实验要求 综合练习:请给openlab搭建web网站 网站需求: 1.基于域名[www.openlab.com](http://www.openlab.com)可以访问网站内容为 welcome to openlab!!! 2.给该公司创建三个子界面分别显示学生信息,教学资料和缴费网站,…...

微信小程序wx.showShareMenu配置全局分享功能
在app.js文件中配置如下即可: onLaunch() {//开启分享功能this.overShare()},/*** 开启朋友圈分享功能* 监听路由切换/自动执行*/overShare() {wx.onAppRoute((res) > {// console.log(route, res)let pages getCurrentPages()let view pages[pages.length - …...

机器学习面试八股总结
下面是本人在面试中整理的资料和文字,主要针对机器学习面试八股做浅显的总结,大部分来源于ChatGPT,中间有借鉴一些博主的优质文章,已经在各文中指出原文。有任何问题,欢迎随时不吝指正。 文章系列图像使用动漫 《星游…...

南京邮电大学《2024年812自动控制原理真题》 (完整版)
本文内容,全部选自自动化考研联盟的:《南京邮电大学812自控考研资料》的真题篇。后续会持续更新更多学校,更多年份的真题,记得关注哦~ 目录 2024年真题 Part1:2024年完整版真题 2024年真题...

大数据新视界 -- Hive 数据湖集成与数据治理(下)(26 / 30)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

Android EventBus最全面试题及参考答案
目录 什么是 EventBus? 请解释 EventBus 是什么,以及它的工作原理。 简述 EventBus 的工作原理。 EventBus 的主要组成部分有哪些? EventBus 是如何实现发布订阅模式的? EventBus 与观察者模式有什么区别? Even…...
)
C++ 游戏开发:开启游戏世界的编程之旅(1)
在游戏开发领域,C 一直占据着极为重要的地位。它以高效的性能、对底层硬件的良好控制能力以及丰富的库支持,成为众多大型游戏开发项目的首选编程语言。今天,就让我们一同开启 C 游戏开发的探索之旅。 一、C 游戏开发基础 (一&am…...

SpringBoot mq快速上手
1.依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId> </dependency> 2.示例代码 基础信息配置 package com.example.demo.config;import org.springframework.amqp.co…...

图像处理网络中的模型水印
论文信息:Jie Zhang、Han Fang、Weiming Zhang、Wenbo Zhou、Hao Cui、Hao Cui、Nenghai Yu:Model Watermarking for Image Processing Networks 本文首次提出了图像处理网络中深度水印问题,将知识产权问题引入图像处理模型 提出了第一个深…...

Halcon 瑕疵检测原理及应用
摘要: 本文详细阐述了 Halcon 在瑕疵检测领域的原理、相关技术以及广泛的应用场景。首先介绍了 Halcon 软件的基本概况及其在机器视觉领域的重要地位,接着深入剖析了瑕疵检测所涉及的图像采集、预处理、特征提取与分析以及分类与判定等核心原理ÿ…...

JAVA 架构师面试 100套含答案:JVM+spring+ 分布式 + 并发编程》...
今年的行情,让招聘面试变得雪上加霜。已经有不少大厂,如腾讯、字节跳动的招聘名额明显减少,面试门槛却一再拔高,如果不用心准备,很可能就被面试官怼得哑口无言,甚至失去了难得的机会。 现如今,…...

多模态学习详解
多模态学习详解 引言 多模态(Multimodal)学习是机器学习和人工智能领域的一个重要分支,它涉及从多个不同类型的输入数据中提取信息,并将这些信息融合以改善模型的性能。多模态学习能够处理的数据类型广泛,包括但不限…...
的显示)
C#应用开发:基于C# WPF界面实现本机网络通讯状态(下载速度)的显示
目录 概述 具体实现 第一步:获取网络接口信息 代码解释: 第二步:创建 WPF 界面 第三步:绑定数据 注意事项 概述 在 WPF 中实现一个界面来显示本机网络接口的状态,通常需要以下几个步骤: 获取网络接口…...

Octo—— 基于80万个机器人轨迹的预训练数据集用于训练通用机器人,可在零次拍摄中解决各种任务
概述 论文地址:https://arxiv.org/abs/2405.12213 在机器人学中,通常使用针对特定机器人或任务收集的数据集来学习策略。然而,这种方法需要为每项任务收集大量数据,由此产生的策略只能实现有限的泛化性能。利用其他机器人和任务的…...
)
Git从入门到工作流:GitLab私有仓库最佳实践(SSH免密、.DS_Store全局忽略)
本文将带你从零开始配置GitLab私有仓库,涵盖SSH密钥免密登录、本地仓库初始化与推送、以及macOS下.DS_Store文件的全局忽略与清理。每一步都有命令和解释,适合新手和想规范Git工作流的开发者。 一、注册GitLab账号并创建私有仓库 1. 注册账号 访问 Git…...

量子增强生成模型革新格点场理论计算
1. 量子增强生成模型在格点场理论中的突破性应用在计算物理领域,特别是高能物理研究中,格点场理论(Lattice Field Theory, LFT)一直是研究非微扰量子场论的重要工具。传统方法如马尔可夫链蒙特卡洛(MCMC)虽…...

Ollama REST API 深度解析:如何用 HTTP 接口调用模型
系列导读 你现在看到的是《Ollama 本地大模型管理实战:从部署到调优的完整指南》的第 4/10 篇,当前这篇会重点解决:让读者掌握通过 HTTP 接口编程调用 Ollama 模型的核心技能。 上一篇回顾:第 3 篇《模型加载与运行参数调优:从默认到高性能的实战配置》主要聚焦 教会读者…...

二供泵站PLC智慧升级物联网方案解析
某二供水务企业计划为各个老旧泵站进行改造升级,要求实现远程启停、自动控泵、高温预警、水质/视频/电气全量采集,泵站集中管理等功能,统一接入污水厂总平台,实现精细化管理与高效运维。对此,物通博联提供高效可靠的二…...

观察使用Taotoken后月度AI模型API账单的清晰度与成本分布
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用Taotoken后月度AI模型API账单的清晰度与成本分布 作为个人开发者或技术团队的负责人,在项目开发中引入多个大模…...

AI产品经理入门实战:如何理解知识图谱?
亲爱的小伙伴,如有帮助请订阅专栏!跟着老师每课一练,系统学习AI产品经理课程! 《AI产品经理入门实战》https://edu.csdn.net/course/detail/41126《Axure原型设计精品课》...

OpenClaw API限速机制解析与工程化应对方案
1. 这不是服务器崩了,是OpenClaw在“礼貌地拒客”你刚把OpenClaw集成进自己的数据采集流程,跑通第一个API调用,返回200,心里一热;第二轮批量请求发出去,不到三秒,控制台炸出一行红字:…...

深入解析Linux内核sk_buff内存布局与核心操作原理
1. 项目概述:从数据包到sk_buff的旅程在网络编程和内核开发领域,sk_buff(socket buffer)是一个绕不开的核心数据结构。它就像网络数据包在内核世界里的“标准集装箱”,负责承载从网卡接收到应用层发送的每一份数据。无…...

如何用BilibiliDown一键下载B站视频?3分钟掌握批量下载技巧
如何用BilibiliDown一键下载B站视频?3分钟掌握批量下载技巧 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirr…...

ExternalDNS自动化DNS管理实践:实现Kubernetes服务自动注册
ExternalDNS自动化DNS管理实践:实现Kubernetes服务自动注册 一、ExternalDNS概述 ExternalDNS是一个Kubernetes控制器,能够自动同步Kubernetes资源(如Service和Ingress)到外部DNS服务商。它消除了手动管理DNS记录的繁琐工作&…...