Hbase整合Mapreduce案例1 hdfs数据上传至hbase中——wordcount
目录
- 整合结构
- 准备
- java API 编写
- pom.xml
- Main.java
- Map.java
- Reduce
- 运行
整合结构
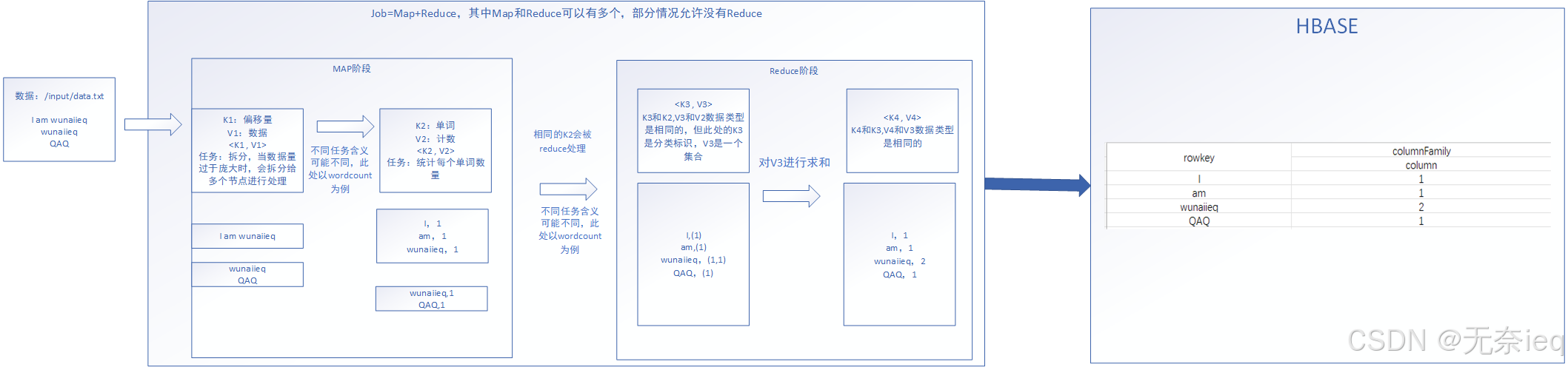
准备
- 上传hdfs data.txt数据
data.txt
I am wunaiieq
QAQ
123456
Who I am
In todays interconnected world the role of technology cannot be overstated It has revolutionized the way we live work and communicate From smartphones to social media platforms technology has made the world more accessible and connected Than ever before It has enabled us to stay informed and connected with people across the globe allowing for instant communication and collaboration The impact of technology on education healthcare and business has been profound It has transformed the way we learn access medical information and conduct business operations As we continue to advance technologically it is essential that we understand and adapt to these changes to fully harness their potential
hdfs
hdfs dfs -put data.txt /input
- 制作hbase表格
Hbase shell
create "wunaiieq:wordcount","colf"
java API 编写
pom.xml
包含hbase和hdfs的依赖文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.hbase</groupId><artifactId>hdfs2hbase</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><hadoop.version>3.1.3</hadoop.version><hbase.version>2.2.3</hbase.version></properties><dependencies><!-- Hadoop Dependencies --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-yarn-api</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-streaming</artifactId><version>${hadoop.version}</version></dependency><!-- HBase Dependencies --><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-common</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-mapreduce</artifactId><version>${hbase.version}</version></dependency><!-- Other Dependencies --><dependency><groupId>com.google.protobuf</groupId><artifactId>protobuf-java</artifactId><version>3.19.1</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version><scope>compile</scope></dependency></dependencies><build><plugins><plugin><!--声明--><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.3.0</version><!--具体配置--><configuration><archive><manifest><!--jar包的执行入口--><mainClass>org.wunaiieq.hdfs2hbase.Main</mainClass></manifest></archive><descriptorRefs><!--描述符,此处为预定义的,表示创建一个包含项目所有依赖的可执行 JAR 文件;允许自定义生成jar文件内容--><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><!--执行配置--><executions><execution><!--执行配置ID,可修改--><id>make-assembly</id><!--执行的生命周期--><phase>package</phase><goals><!--执行的目标,single表示创建一个分发包--><goal>single</goal></goals></execution></executions></plugin></plugins></build>
</project>
Main.java
程序主类,和原有的Mapreduce相比逻辑上没有多大的区别
不过原有的mr程序调用的reduce接口的实现类
现在调用的则是TableReducer接口的实现类
package org.wunaiieq.hdfs2hbase;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.streaming.io.InputWriter;
import org.apache.hadoop.hbase.mapreduce.*;public class Main {public static void main(String[] args) throws Exception {//配置文件,写在resources目录下Job job =Job.getInstance(new Configuration());//入口类job.setJarByClass(Main.class);//文件输入路径(命令行手动输入)FileInputFormat.setInputPaths(job,new Path(args[0]));//直接规定,不过我是打jar包,不推荐这么做//FileInputFormat.setInputPaths(job,new Path("/input/data.txt"));//Mapper类job.setMapperClass(Map.class);job.setMapOutputKeyClass(Text.class);//k2job.setMapOutputValueClass(IntWritable.class);//v2//Redecer类,由于写入Hbase,因此此处做出一些修改TableMapReduceUtil.initTableReducerJob("wunaiieq:wordcount",//输入表的名称Reduce.class,//Reducer类,需要实现TableReducer接口job,//job实例,当前的作业null,//输入格式类的类型null,//输入键的类类型null,//输入值的类类型null,//输出键的类类型false//是否将 HBase 和 Hadoop 的相关依赖 JAR 文件添加到作业的 classpath 中。);job.waitForCompletion(true);}
}
Map.java
没什么需要特别注明的,Map层并没有什么修改
package org.wunaiieq.hdfs2hbase;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;
public class Map extends Mapper<LongWritable, Text,Text, IntWritable> {private Text k2 =new Text();private IntWritable v2 =new IntWritable(1);@Overrideprotected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException {//将输入文本转成String类型的变量String data =v1.toString();//切分单词String words[]=data.split(" ");for(String word :words){//对k2v2进行赋值,k2应为单词,作为后续的rowkeyk2.set(word);//v2应为1,每次统计时算1个v2.set(1);context.write(k2,v2);//做法相同//context.write(new Text(word),new IntWritable(1));}}
}Reduce
和一般MR程序不同,此处实现TableReducer的接口
package org.wunaiieq.hdfs2hbase;import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
/*** 查看代码原文<br>* public abstract class TableReducer < k3, v3, k4> <br>* extends Reducer< k3, v3, k4, Mutation> <br>*这里的Mutation也就是v4,这个类则是输出到hbase中* **/
// K3 V3 K4
public class Reduce extends TableReducer<Text, IntWritable,Text> {@Overrideprotected void reduce(Text k3, Iterable<IntWritable> v3, Reducer<Text, IntWritable, Text, Mutation>.Context context) throws IOException, InterruptedException {int sum =0;for (IntWritable value :v3){sum+=value.get();}//创建Put对象,设置rowkey为k3(单词)Put put =new Put(Bytes.toBytes(k3.toString()));//指定列put.addColumn("colf".getBytes(),"count".getBytes(),Bytes.toBytes(sum));//输出k4,正常来讲,k4应该等于k3,但此处没有多大作用,因为是输出到hbase中,这一步仅是作为规范Text k4 =k3;context.write(k4,put);}
}运行
注意下哈,这里是hadoop jar
hadoop jar hdfs2hbase-1.0-SNAPSHOT-jar-with-dependencies.jar /input/data.txt
hadoop jar和java -jar的区别

相关文章:
Hbase整合Mapreduce案例1 hdfs数据上传至hbase中——wordcount
目录 整合结构准备java API 编写pom.xmlMain.javaMap.javaReduce 运行 整合结构 准备 上传hdfs data.txt数据 data.txt I am wunaiieq QAQ 123456 Who I am In todays interconnected world the role of technology cannot be overstated It has revolutionized the way we …...

PyQt 中的无限循环后台任务
在 PyQt 中实现一个后台无限循环任务,需要确保不会阻塞主线程,否则会导致 GUI 无响应。常用的方法是利用 线程(QThread) 或 任务(QRunnable 和 QThreadPool) 来运行后台任务。以下是一些实现方式和关键点&a…...

5G CPE核心器件-基带处理器(三)
5G CPE 核心器件 -5G基带芯片 基带芯片简介基带芯片组成与结构技术特点与发展趋势5G基带芯片是5G CPE中最核心的组件,负责接入5G网络,并进行上下行数据业务传输。移动通信从1G发展到5G,终端形态产生了极大的变化,在集成度、功耗、性能等方面都取得巨大的提升。 基带芯片简…...
)
鸿蒙next版开发:拍照实现方案(ArkTS)
文章目录 拍照功能开发步骤1. 导入相关接口2. 创建会话3. 配置会话4. 触发拍照5. 监听拍照输出流状态 结语 在HarmonyOS 5.0中,ArkTS提供了一套完整的API来管理相机功能,特别是拍照功能。本文将详细介绍如何在ArkTS中实现拍照功能,并提供代码…...

C++面试突破---C/C++基础
1.C特点 1. C在C语言基础上引入了面对对象的机制,同时也兼容C语言。 2. C有三大特性(1)封装。(2)继承。(3)多态; 3. C语言编写出的程序结构清晰、易于扩充,程序可读性好。…...

项目搭建+修改
一 : 在列表成功回调函数,追加数据中,添加修改的按钮 for (let x of res) {//追加数据$("#table").append(<tr><td><input type"checkbox" class"ck" value"\${x.uid}"></td><td>\${x.uid}</td>…...
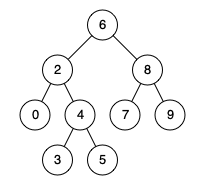
每日算法一练:剑指offer——树篇(4)
1.计算二叉树的深度 某公司架构以二叉树形式记录,请返回该公司的层级数。 示例 1: 输入:root [1, 2, 2, 3, null, null, 5, 4, null, null, 4] 输出: 4 解释: 上面示例中的二叉树的最大深度是 4,沿着路径 1 -> 2 -> 3 -&…...

Nginx静态资源配置
基本配置原则 明确资源目录:为不同类型的静态资源指定不同的路径,这样可以避免路径冲突,并且便于管理。正确设置文件权限:确保 Nginx 具有读取静态资源的权限。缓存优化:为静态资源设置缓存头(如 expires&…...

困扰解决:mfc140u.dll丢失的解决方法,多种有效解决方法全解析
当电脑提示“mfc140u.dll丢失”时,这可能会导致某些程序无法正常运行,给用户带来不便。不过,有多种方法可以尝试解决这个问题。这篇文章将以“mfc140u.dll丢失的解决方法”为主题,教大家有效解决mfc140u.dll丢失。 判断是否是“mf…...

D3.js 初探
文章目录 D3.js 简单介绍选择集与方法数据绑定方法选择集添加DOM元素以及删除元素理解update enter 以及 exit关于比例尺layout 布局force layout 坐标轴元素添加动态效果demo1: 绘制简单柱状图 #D3.js 初探 最近在做一个Data Visualization 的项目,由于对最终呈现的…...

linux常用指令 | 适合初学者
linux常用指令 1.ls: 列出当前,目录中的文件和子目录 ls 2.pwd: 显示当前工作目录的路径 pwd3.cd切换工作目录 cd /path/to/director4.mkdir:创建新目录 mkdir directory_name5.rmdir:删除空目录 rmdir directory_name6.rm: 删除文件或目录 rm file_name r…...

用 NotePad++ 运行 Java 程序
安装包 网盘链接 下载得到的安装包: 安装步骤 双击安装包开始安装. 安装完成: 配置编码 用 NotePad 写 Java 程序时, 需要设置编码. 在 设置, 首选项, 新建 中进行设置, 可以对每一个新建的文件起作用. 之前写的文件不起作用. 在文件名处右键, 可以快速打开 CMD 窗口, 且路…...

在 Linux 环境下搭建 OpenLab Web 网站并实现 HTTPS 和访问控制
实验要求 综合练习:请给openlab搭建web网站 网站需求: 1.基于域名[www.openlab.com](http://www.openlab.com)可以访问网站内容为 welcome to openlab!!! 2.给该公司创建三个子界面分别显示学生信息,教学资料和缴费网站,…...

微信小程序wx.showShareMenu配置全局分享功能
在app.js文件中配置如下即可: onLaunch() {//开启分享功能this.overShare()},/*** 开启朋友圈分享功能* 监听路由切换/自动执行*/overShare() {wx.onAppRoute((res) > {// console.log(route, res)let pages getCurrentPages()let view pages[pages.length - …...

机器学习面试八股总结
下面是本人在面试中整理的资料和文字,主要针对机器学习面试八股做浅显的总结,大部分来源于ChatGPT,中间有借鉴一些博主的优质文章,已经在各文中指出原文。有任何问题,欢迎随时不吝指正。 文章系列图像使用动漫 《星游…...

南京邮电大学《2024年812自动控制原理真题》 (完整版)
本文内容,全部选自自动化考研联盟的:《南京邮电大学812自控考研资料》的真题篇。后续会持续更新更多学校,更多年份的真题,记得关注哦~ 目录 2024年真题 Part1:2024年完整版真题 2024年真题...

大数据新视界 -- Hive 数据湖集成与数据治理(下)(26 / 30)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

Android EventBus最全面试题及参考答案
目录 什么是 EventBus? 请解释 EventBus 是什么,以及它的工作原理。 简述 EventBus 的工作原理。 EventBus 的主要组成部分有哪些? EventBus 是如何实现发布订阅模式的? EventBus 与观察者模式有什么区别? Even…...
)
C++ 游戏开发:开启游戏世界的编程之旅(1)
在游戏开发领域,C 一直占据着极为重要的地位。它以高效的性能、对底层硬件的良好控制能力以及丰富的库支持,成为众多大型游戏开发项目的首选编程语言。今天,就让我们一同开启 C 游戏开发的探索之旅。 一、C 游戏开发基础 (一&am…...

SpringBoot mq快速上手
1.依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId> </dependency> 2.示例代码 基础信息配置 package com.example.demo.config;import org.springframework.amqp.co…...

书匠策AI实测揭秘:毕业论文全流程竟然能这样“偷懒“?
各位同学,我是一个专门教别人写论文的博主。说实话,每次看到评论区有人问"论文到底怎么开头",我都想穿越屏幕去帮他敲键盘。 但今天不一样,我要给你们安利一个我自己偷偷用了好几次的工具——书匠策AI。注意࿰…...

百度文库纯净阅读助手:三分钟实现广告屏蔽与PDF导出
百度文库纯净阅读助手:三分钟实现广告屏蔽与PDF导出 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 您是否曾在百度文库上查阅资料时,被满屏的广告、VIP提示和干扰元素所困…...

RTB点击率预估中的长尾失衡与价值重标定
1. 项目概述:当广告竞价遇上“长尾陷阱”——为什么实时竞价系统里99%的流量不说话,却决定着100%的效果你有没有遇到过这样的情况:训练了一个看起来AUC高达0.92的点击率预估模型,上线后CTR却比老模型还低0.3个百分点?或…...

Nginx慢速HTTP攻击防护:超时配置与内核级加固实战
1. 这不是误报:当Nginx日志里反复出现“client timed out”时,你面对的已是真实攻击面“检测到目标主机可能存在缓慢的HTTP拒绝服务攻击”——这条告警在安全扫描报告里出现时,很多运维同学第一反应是:又一个误报。毕竟Nginx跑得稳…...

C#字节序反转:从原理到工业级实现
1. 字节序反转不是“字节倒序”,而是数据语义的精准翻转很多人第一次看到“字节序反转”这个词,下意识就去写Array.Reverse(bytes)——结果一测发现:整数读出来完全不对。我去年在做工业PLC通信协议解析时就栽过这个跟头:设备返回…...
作用与上市,全球首个犬用 JAK 抑制剂)
爱波克 Apoquel(奥拉替尼)作用与上市,全球首个犬用 JAK 抑制剂
奥拉替尼是全球首个获批用于兽医的 JAK 抑制剂,2013 年 5 月美国 FDA 获批,2023 年 6 月推出咀嚼片剂型,提升用药依从性Zoetis。其作用机制为选择性抑制 JAK1,阻断 IL-4、IL-13、IL-31 等关键致痒与促炎细胞因子信号,从…...

【ElevenLabs广西话语音落地实战】:20年语音AI专家亲授3步绕过方言合成陷阱,97.3%自然度实测达标
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs广西话语音落地实战总览 ElevenLabs 官方尚未提供原生广西话(粤语邕浔片/平话混合语境)语音模型,但通过其 API 的自定义语音微调(Fine-tuning&…...

3分钟解决iPhone网络共享驱动问题:Windows用户终极指南
3分钟解决iPhone网络共享驱动问题:Windows用户终极指南 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mi…...

从账单明细看Taotoken计费模式的透明与可追溯性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从账单明细看Taotoken计费模式的透明与可追溯性 对于将大模型API集成到产品中的团队而言,成本控制与核算是一个核心的工…...

技术人的时间管理:高效利用每一天
技术人的时间管理:高效利用每一天 引言 作为一名技术人,我们每天都面临着大量的工作任务和学习需求。如何在有限的时间内高效完成工作、持续学习提升,同时保持良好的生活质量,是每个技术人都需要面对的挑战。 在过去的几年里&…...