【机器学习】窥数据之序,悟算法之道:机器学习的初心与远方
文章目录
- 机器学习入门:从零开始学习基础与应用
- 前言
- 第一部分:什么是机器学习?
- 1.1 机器学习的定义
- 1.1.1 举个例子:垃圾邮件分类器
- 1.2 机器学习的核心思想
- 1.2.1 数据驱动的模式提取
- 1.2.2 为什么机器学习比传统方法更灵活?
- 1.3 机器学习的三大类型
- 1.3.1 监督学习
- 1.3.2 无监督学习
- 1.3.3 强化学习
- 1.4 为什么机器学习突然火了?
- 1.5 机器学习与传统方法的对比
- 1.6 常见误区
- 1.6.1 必须精通数学才能入门?
- 1.6.2 必须自己实现所有算法?
- 第二部分:机器学习能做什么?
- 2.1 机器学习的应用领域
- 2.1.1 搜索引擎优化
- 2.1.2 推荐系统
- 2.1.3 图像处理
- 2.2 推荐系统详解
- 2.2.1 推荐系统的两种方法
- 2.2.2 推荐系统的局限性
- 2.3 深入行业案例
- 2.3.1 医疗行业
- 2.3.2 金融行业
- 2.3.3 自动驾驶
- 2.4 游戏中的机器学习
- 2.4.1 游戏AI
- 2.4.2 游戏推荐系统
- 2.5 常见问题与未来展望
- 2.5.1 当前挑战
- 2.5.2 未来趋势
- 第三部分:学习机器学习需要什么基础?
- 3.1 数学基础
- 3.1.1 线性代数
- 3.1.2 概率与统计
- 3.1.3 微积分
- 3.2 编程基础
- 3.2.1 必备工具库
- 3.2.2 基础代码示例
- 3.3 学习路径推荐
- 3.3.1 阶段一:零基础入门
- 3.3.2 阶段二:初步实践
- 3.3.3 阶段三:进阶提升
- 3.4 常见学习误区
- 3.4.1 数学恐惧症
- 3.4.2 忽略实践
- 第四部分:机器学习的核心流程
- 4.1 数据收集
- 4.1.1 数据来源
- 4.1.2 数据采集的注意事项
- 4.2 数据预处理
- 4.2.1 缺失值处理
- 4.2.2 数据标准化和归一化
- 4.2.3 特征工程
- 4.3 模型选择
- 4.3.1 回归任务
- 4.3.2 分类任务
- 4.3.3 聚类任务
- 4.3.4 深度学习模型
- 4.4 模型训练
- 4.4.1 训练集与测试集划分
- 4.4.2 超参数调整
- 4.5 模型评估
- 4.5.1 常用评估指标
- 4.5.2 交叉验证
- 4.6 模型部署
- 4.6.1 部署方式
- 第五部分:写第一个机器学习程序
- 5.1 项目背景
- 5.2 项目步骤
- 5.2.1 数据加载与预处理
- 5.2.2 数据可视化
- 5.2.3 模型训练
- 5.2.4 模型预测
- 5.2.5 模型评估
- 5.3 完整代码
- 写在最后
机器学习入门:从零开始学习基础与应用
💬 欢迎讨论:如果在学习过程中有任何疑问,欢迎在评论区留言交流。
👍 点赞、收藏与分享:觉得这篇文章对你有帮助吗?记得点赞、收藏并分享给更多的朋友吧!你们的支持是我创作的动力!
🚀 分享给更多人:如果你身边有对机器学习感兴趣的小伙伴,欢迎分享这篇文章,一起学习进步!
前言
机器学习是一个热门又复杂的技术领域,但其实入门并没有你想象的那么难。如果你对机器学习完全陌生,不知道如何开始学习,这篇文章就是为你准备的。我们将从最基础的概念讲起,逐步带你了解机器学习的本质、应用、工作流程以及如何入门学习。
- 什么是机器学习? 它是人工智能的一部分,通过算法让计算机从数据中“学习”规律,而不是直接写死规则。
- 适合人群:零基础、没有编程经验、对数学知识较陌生的小白。
- 目标:建立机器学习的基础认知,帮助读者清晰规划学习路径。
第一部分:什么是机器学习?
1.1 机器学习的定义
机器学习(Machine Learning)是人工智能(AI)的一个分支,它通过算法让计算机从数据中学习规律,而不是明确地编程规则。
1.1.1 举个例子:垃圾邮件分类器
- 传统编程:我们需要为每种垃圾邮件的特征手动定义规则,比如含有“中奖”、“优惠”等关键词。
- 机器学习:给计算机提供带标签的数据集(垃圾/非垃圾),它会自动学习垃圾邮件的特征。
数据示例:
| 邮件内容 | 是否垃圾邮件 |
|---|---|
| 恭喜您中奖了!请点击领取 | 是 |
| 会议通知:今天下午2点召开 | 否 |
| 优惠大促销:仅限今日 | 是 |
1.2 机器学习的核心思想
1.2.1 数据驱动的模式提取
机器学习的核心是通过数据找到规律,而不是人工定义规则。
- 案例:房价预测
假设我们有以下数据:
| 面积 (平方米) | 房价 (万元) |
|---|---|
| 50 | 100 |
| 100 | 200 |
| 150 | 300 |
通过分析数据,机器学习模型发现房价与面积的关系:
房价 = 2 × 面积 \text{房价} = 2 \times \text{面积} 房价=2×面积
当输入一个120平方米的房子时,模型预测其房价为240万元。
1.2.2 为什么机器学习比传统方法更灵活?
- 传统编程的局限性:规则固定,难以覆盖所有情况。
- 机器学习的优势:
- 自动学习:模型可以从数据中自动提取规律。
- 持续优化:数据越多,模型效果越好。
1.3 机器学习的三大类型
1.3.1 监督学习
- 特点:需要标注数据(输入与输出明确对应)。
- 用途:
- 回归任务:预测连续值,如房价预测。
- 分类任务:预测类别,如垃圾邮件分类。
- 常见算法:线性回归、逻辑回归、决策树。
1.3.2 无监督学习
- 特点:数据没有标签,目标是发现数据结构或模式。
- 用途:
- 聚类任务:如用户分组。
- 降维任务:如简化数据以便于可视化。
- 常见算法:K均值聚类、主成分分析(PCA)。
1.3.3 强化学习
- 特点:通过“试错”和“奖励机制”学习最优决策。
- 用途:
- 游戏AI:如AlphaGo通过强化学习击败人类。
- 自动驾驶:通过模拟学习最优驾驶策略。
- 常见算法:深度强化学习、Q学习。
1.4 为什么机器学习突然火了?
-
数据爆炸
- 随着互联网和移动设备普及,全球数据量呈指数级增长,为机器学习提供了充足的训练数据。
- 案例:淘宝每天产生上亿条用户行为数据,支撑了精准推荐系统。
-
硬件性能提升
- GPU、TPU等高性能硬件的发展,大幅缩短了模型训练时间。
- 深度学习模型训练从几周缩短到几小时。
-
开源工具普及
- TensorFlow、PyTorch等工具降低了技术门槛,即使是零基础也能快速上手复杂算法。
-
商业需求驱动
- 各行各业都希望通过数据预测提升效率,如金融风控、医疗诊断。
1.5 机器学习与传统方法的对比
| 传统方法 | 机器学习 |
|---|---|
| 依赖手工规则编写 | 自动从数据中学习规律 |
| 固定规则,难以适应变化 | 灵活适应复杂、多变的数据 |
| 执行效率高,但扩展性差 | 模型可持续优化,扩展性强 |
1.6 常见误区
1.6.1 必须精通数学才能入门?
- 真相:入门阶段只需了解基础数学概念(如均值、方差、线性方程)。
- 建议:随着学习深入,逐步补充数学知识。
1.6.2 必须自己实现所有算法?
- 真相:Scikit-learn、TensorFlow等工具提供了大量现成的算法,初学者可以直接调用。
- 建议:在理解算法逻辑后,再尝试从零实现。
第二部分:机器学习能做什么?
2.1 机器学习的应用领域
机器学习正在改变我们的日常生活,以下是一些常见的应用领域:
2.1.1 搜索引擎优化
- 场景:Google、百度等搜索引擎利用机器学习分析用户的搜索意图,优化搜索结果。
- 技术细节:
- 自然语言处理 (NLP):理解搜索关键词的含义。
- 排序算法:基于点击率、跳出率优化结果顺序。
- 案例:用户搜索“周末去哪玩”,搜索引擎结合用户位置推荐本地热门景点。
2.1.2 推荐系统
推荐系统是机器学习应用中最成功的领域之一:
- 场景:电商、短视频平台利用用户行为数据提供个性化推荐。
- 技术细节:
- 协同过滤:基于相似用户的行为推荐内容。
- 基于内容的推荐:根据商品或内容的特征推荐相似的商品。
- 案例:用户在淘宝浏览一款手机,系统推荐耳机、手机壳等配件。
2.1.3 图像处理
- 场景:从人脸识别到自动驾驶,图像处理领域离不开机器学习。
- 技术细节:
- 卷积神经网络 (CNN):处理图像数据的核心算法。
- 数据增强:通过翻转、裁剪等方法扩充训练数据。
- 案例:支付宝刷脸支付通过分析用户面部特征完成身份验证。
2.2 推荐系统详解
2.2.1 推荐系统的两种方法
-
基于内容的推荐:
- 系统分析商品或内容的特征(如颜色、品牌、价格),推荐相似内容。
- 案例:喜欢红色连衣裙的用户可能被推荐其他品牌的红裙子。
- 实现代码:
from sklearn.metrics.pairwise import cosine_similarity # 假设我们有商品的特征向量 features = [[1, 0, 1], [0, 1, 1], [1, 1, 0]] similarity = cosine_similarity(features) print("相似度矩阵:", similarity)
-
协同过滤:
- 系统通过分析用户的行为模式,推荐其他用户喜欢的内容。
- 案例:买了手机的用户可能被推荐耳机和充电宝。
2.2.2 推荐系统的局限性
- 冷启动问题:当新用户或新内容缺乏数据时,系统无法推荐。
- 数据依赖性:推荐效果高度依赖于数据的质量和数量。
2.3 深入行业案例
2.3.1 医疗行业
机器学习在医疗领域的应用正在加速:
- 疾病预测:分析患者基因、体检数据,预测患病风险。
- 案例:谷歌研发的AI能比医生更早发现糖尿病性视网膜病变。
- 医学影像分析:通过深度学习算法自动分析CT、X光片,发现早期病变。
- 药物研发:机器学习加速药物筛选,减少研发时间和成本。
2.3.2 金融行业
金融行业高度依赖机器学习进行风险控制和业务优化:
- 信用评分:通过用户的历史数据分析其违约风险。
- 反欺诈系统:实时监控交易,识别异常行为并阻止诈骗。
- 案例:支付宝的风控系统能“秒级”拦截异常交易。
2.3.3 自动驾驶
自动驾驶是机器学习最前沿的应用:
- 技术基础:
- 卷积神经网络 (CNN):处理摄像头采集的图像。
- 强化学习:通过模拟驾驶环境优化行车策略。
- 案例:特斯拉的自动驾驶系统可以实现高速公路的自动变道和泊车。
2.4 游戏中的机器学习
2.4.1 游戏AI
- 场景:AlphaGo通过强化学习击败人类围棋冠军。
- 原理:
- 蒙特卡洛树搜索 (MCTS):探索可能的棋局。
- 深度神经网络 (DNN):评估棋局状态并选择最优策略。
- 案例:游戏《Dota2》的AI系统可以与职业选手对战。
2.4.2 游戏推荐系统
- 场景:Steam通过分析玩家行为,推荐感兴趣的游戏。
- 技术实现:
- 协同过滤:基于其他玩家的评分推荐新游戏。
- 基于内容的推荐:分析游戏特性(如类别、玩法)推荐类似游戏。
2.5 常见问题与未来展望
2.5.1 当前挑战
- 数据隐私问题:过度依赖用户数据可能导致隐私泄露。
- 算法偏见:模型可能因训练数据不平衡而表现出偏见。
2.5.2 未来趋势
- 跨领域融合:不同领域之间的数据和模型共享将带来更多创新。
- 实时学习能力:未来的模型将更快速地适应实时变化的数据环境。
第三部分:学习机器学习需要什么基础?
3.1 数学基础
学习机器学习需要一些数学知识的支撑,但无需一次性掌握所有高深内容。以下是核心数学领域及其作用。
3.1.1 线性代数
-
作用:矩阵和向量运算是机器学习模型的基础,常用于数据表示、特征变换和优化。
-
示例:
数据可以用矩阵表示:
X = [ 1 50 1 100 1 150 ] , y = [ 100 200 300 ] X = \begin{bmatrix} 1 & 50 \\ 1 & 100 \\ 1 & 150 \end{bmatrix}, \quad y = \begin{bmatrix} 100 \\ 200 \\ 300 \end{bmatrix} X= 11150100150 ,y= 100200300
其中 ( X ) 是特征矩阵,( y ) 是目标值。 -
推荐学习资源:
- 《线性代数及其应用》 by Gilbert Strang
- 3Blue1Brown 的线性代数可视化讲解
3.1.2 概率与统计
-
作用:概率分布、条件概率和统计推断在模型评估、特征提取和预测中扮演重要角色。
-
示例:
贝叶斯分类器根据以下公式计算垃圾邮件的概率:
P ( 垃圾 ∣ 关键词 ) = P ( 关键词 ∣ 垃圾 ) ⋅ P ( 垃圾 ) P ( 关键词 ) P(\text{垃圾}|\text{关键词}) = \frac{P(\text{关键词}|\text{垃圾}) \cdot P(\text{垃圾})}{P(\text{关键词})} P(垃圾∣关键词)=P(关键词)P(关键词∣垃圾)⋅P(垃圾) -
推荐学习资源:
- 《概率论与数理统计》 by Blitzstein
- Khan Academy 概率和统计课程
3.1.3 微积分
-
作用:微分用于梯度下降法优化模型,积分用于概率分布的计算。
-
示例:
梯度下降优化过程如下:
θ = θ − α ∂ J ( θ ) ∂ θ \theta = \theta - \alpha \frac{\partial J(\theta)}{\partial \theta} θ=θ−α∂θ∂J(θ)
其中:- θ \theta θ是参数向量;
- α \alpha α是学习率;
- J ( θ ) J(\theta) J(θ)是损失函数。
-
推荐学习资源:
- 《微积分入门》 by James Stewart
- Paul’s Online Math Notes
3.2 编程基础
机器学习开发离不开编程,其中 Python 是目前最流行的语言。它的简单易学和强大的库支持,使其成为入门的最佳选择。
3.2.1 必备工具库
- NumPy:用于数组操作和矩阵计算。
- Pandas:用于数据处理和清洗。
- Matplotlib:用于数据可视化。
- Scikit-learn:提供简单易用的机器学习算法接口。
3.2.2 基础代码示例
以下代码演示如何使用 NumPy 和 Pandas 进行数据处理:
import numpy as np
import pandas as pd# 创建特征矩阵和目标值
X = np.array([[50], [100], [150]])
y = np.array([100, 200, 300])# 创建数据框
data = pd.DataFrame({'面积': X.flatten(), '房价': y})
print(data)
输出:
面积 房价
0 50 100
1 100 200
2 150 300
3.3 学习路径推荐
3.3.1 阶段一:零基础入门
-
学习 Python 编程:
- 学习变量、数据结构、函数。
- 推荐教程:Python 编程:从入门到实践
-
了解基础数学:
- 学习线性代数的矩阵运算、概率论的基本公式。
3.3.2 阶段二:初步实践
- 使用 Scikit-learn 完成简单任务:
- 回归:预测房价。
- 分类:垃圾邮件分类。
- 学习数据预处理:
- 特征工程:数据编码、特征缩放。
- 缺失值处理:
df.fillna(df.mean(), inplace=True)
3.3.3 阶段三:进阶提升
- 深入学习核心算法:
- 线性回归、逻辑回归、决策树。
- 推荐资源:StatQuest 机器学习视频
- 探索深度学习:
- 学习 TensorFlow 或 PyTorch 的基础操作。
3.4 常见学习误区
3.4.1 数学恐惧症
- 误区:以为必须精通高等数学才能入门。
- 真相:仅需掌握基本概念,深入研究时再补充。
3.4.2 忽略实践
- 误区:只看理论,不写代码。
- 建议:从简单项目入手,通过实践加深理解。
第四部分:机器学习的核心流程
机器学习项目的开发一般分为几个主要步骤,每一步都需要结合具体场景和目标进行设计。以下将详细讲解从数据收集到模型部署的完整流程。
4.1 数据收集
数据是机器学习的基础。没有高质量的数据,模型就无法学习到有意义的规律。
4.1.1 数据来源
- 公开数据集:
- Kaggle: 提供大量领域多样的数据集。
- UCI Machine Learning Repository: 各种经典机器学习数据。
- 示例:Kaggle 数据集
- 自建数据集:
- 通过传感器收集(如温度、压力数据)。
- 通过爬虫技术从网络抓取。
4.1.2 数据采集的注意事项
- 确保数据的多样性和代表性。
- 遵守数据隐私法规,如 GDPR 和 CCPA。
4.2 数据预处理
数据质量直接影响模型的效果。在正式训练前,需要对原始数据进行清洗和预处理。
4.2.1 缺失值处理
- 方法一:填补缺失值:
df['column_name'].fillna(df['column_name'].mean(), inplace=True) # 用均值填补 - 方法二:删除缺失值:
df.dropna(inplace=True) # 删除含有缺失值的行
4.2.2 数据标准化和归一化
- 标准化:将特征值转换为标准正态分布(均值为0,标准差为1)。
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() df[['feature1', 'feature2']] = scaler.fit_transform(df[['feature1', 'feature2']]) - 归一化:将特征值缩放到 [0, 1] 范围。
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() df[['feature1', 'feature2']] = scaler.fit_transform(df[['feature1', 'feature2']])
4.2.3 特征工程
- 特征提取:从原始数据中提取有用信息。
- 特征选择:使用统计方法挑选对预测结果影响较大的特征。
- 示例:剔除相关性较低的特征。
4.3 模型选择
根据任务的类型选择合适的算法:
4.3.1 回归任务
- 场景:预测连续值(如房价)。
- 常用算法:线性回归、决策树回归、随机森林回归。
4.3.2 分类任务
- 场景:判断类别(如垃圾邮件分类)。
- 常用算法:逻辑回归、支持向量机(SVM)、随机森林。
4.3.3 聚类任务
- 场景:将数据分组(如客户分群)。
- 常用算法:K均值聚类、层次聚类。
4.3.4 深度学习模型
- 场景:适用于图像、语音、自然语言处理等复杂任务。
- 常用框架:TensorFlow、PyTorch。
4.4 模型训练
通过将数据输入模型进行学习,让模型找到输入和输出之间的关系。
4.4.1 训练集与测试集划分
- 通常将数据分为训练集、验证集和测试集(比例为6:2:2)。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
4.4.2 超参数调整
- 定义:模型训练前设定的参数,例如学习率、决策树深度。
- 方法:使用网格搜索或随机搜索优化超参数。
from sklearn.model_selection import GridSearchCV param_grid = {'max_depth': [3, 5, 10]} grid_search = GridSearchCV(estimator=model, param_grid=param_grid) grid_search.fit(X_train, y_train)
4.5 模型评估
4.5.1 常用评估指标
- 分类任务:
- 准确率:正确分类的样本比例。
- 混淆矩阵:区分不同类别的正确与错误预测。
from sklearn.metrics import confusion_matrix print(confusion_matrix(y_test, y_pred))
- 回归任务:
- 均方误差 (MSE):衡量预测值与真实值的偏差。
from sklearn.metrics import mean_squared_error mse = mean_squared_error(y_test, y_pred) print("MSE:", mse)
- 均方误差 (MSE):衡量预测值与真实值的偏差。
4.5.2 交叉验证
- 定义:将数据分成K份,每次用一份作为验证集,其余作为训练集。
- 优点:提高评估结果的可靠性。
from sklearn.model_selection import cross_val_score scores = cross_val_score(model, X, y, cv=5) print("Cross-validation scores:", scores)
4.6 模型部署
完成训练和评估后,将模型应用到实际环境中。
4.6.1 部署方式
-
API 部署:
- 使用 Flask/Django 等框架,将模型封装为 REST API。
- 示例代码:
from flask import Flask, request app = Flask(__name__)@app.route('/predict', methods=['POST']) def predict():data = request.get_json()prediction = model.predict([data['features']])return {'prediction': prediction.tolist()} app.run(port=5000)
-
嵌入式部署:
- 将模型集成到手机应用或嵌入式设备中。
第五部分:写第一个机器学习程序
本部分将通过一个完整的代码示例,带领您从头实现一个简单的房价预测模型。我们将使用 Python 和 Scikit-learn 完成数据处理、模型训练和预测。
5.1 项目背景
假设我们有一组房价数据,包含房屋的面积和对应的价格。目标是根据给定的面积,预测房子的价格。
数据示例:
| 面积 (平方米) | 房价 (万元) |
|---|---|
| 50 | 100 |
| 100 | 200 |
| 150 | 300 |
5.2 项目步骤
5.2.1 数据加载与预处理
我们将手动创建一个小型数据集,并进行必要的预处理操作。
import numpy as np
import pandas as pd# 创建数据
X = np.array([[50], [100], [150], [200]]) # 特征:房屋面积
y = np.array([100, 200, 300, 400]) # 目标值:房价# 转为 DataFrame 便于观察
data = pd.DataFrame({'面积': X.flatten(), '房价': y})
print(data)
输出:
面积 房价
0 50 100
1 100 200
2 150 300
3 200 400
5.2.2 数据可视化
在开始训练模型前,我们用可视化工具查看数据的分布。
import matplotlib.pyplot as plt# 数据可视化
plt.scatter(X, y, color='blue', label='实际数据')
plt.xlabel('面积 (平方米)')
plt.ylabel('房价 (万元)')
plt.title('房价与面积的关系')
plt.legend()
plt.show()
可视化效果:
一张散点图,展示房屋面积和价格的线性关系。
5.2.3 模型训练
我们将使用 Scikit-learn 提供的线性回归模型。
from sklearn.linear_model import LinearRegression# 创建并训练模型
model = LinearRegression()
model.fit(X, y)# 打印模型参数
print(f"模型的系数: {model.coef_[0]}") # 系数 (斜率)
print(f"模型的截距: {model.intercept_}") # 截距
输出示例:
模型的系数: 2.0
模型的截距: 0.0
解释:模型学到的公式为:
房价 = 2 × 面积 \text{房价} = 2 \times \text{面积} 房价=2×面积
5.2.4 模型预测
我们用训练好的模型对新数据进行预测。
# 预测新房价
new_area = np.array([[120]]) # 新房屋面积
predicted_price = model.predict(new_area)
print(f"预测房价: {predicted_price[0]:.2f} 万元")
输出:
预测房价: 240.00 万元
5.2.5 模型评估
用评估指标衡量模型的效果。
from sklearn.metrics import mean_squared_error, r2_score# 预测值
y_pred = model.predict(X)# 计算评估指标
mse = mean_squared_error(y, y_pred) # 均方误差
r2 = r2_score(y, y_pred) # R^2 分数
print(f"均方误差 (MSE): {mse:.2f}")
print(f"R^2 分数: {r2:.2f}")
输出示例:
均方误差 (MSE): 0.00
R^2 分数: 1.00
解释:
- 均方误差 (MSE) 越接近 0,模型的预测效果越好。
- R^2 分数 越接近 1,模型拟合效果越好。
5.3 完整代码
以下是完整的 Python 脚本,可以直接运行。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score# 数据准备
X = np.array([[50], [100], [150], [200]]) # 特征:面积
y = np.array([100, 200, 300, 400]) # 目标值:房价# 数据可视化
plt.scatter(X, y, color='blue', label='实际数据')
plt.xlabel('面积 (平方米)')
plt.ylabel('房价 (万元)')
plt.title('房价与面积的关系')
plt.legend()
plt.show()# 创建并训练模型
model = LinearRegression()
model.fit(X, y)# 模型参数
print(f"模型的系数: {model.coef_[0]}")
print(f"模型的截距: {model.intercept_}")# 预测新房价
new_area = np.array([[120]])
predicted_price = model.predict(new_area)
print(f"预测房价: {predicted_price[0]:.2f} 万元")# 模型评估
y_pred = model.predict(X)
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"均方误差 (MSE): {mse:.2f}")
print(f"R^2 分数: {r2:.2f}")
写在最后
本篇文章从零出发,循序渐进地带你领略了机器学习的核心概念、应用场景以及学习路径。从理解机器学习的定义到明确三大类型的核心思想,再到具体领域中的落地应用,我们一起完成了第一层认知的构建。此外,文章还通过房价预测项目的完整实现,帮助读者初步感受到机器学习的逻辑和力量。无论你是零基础小白,还是对机器学习充满好奇的初学者,都可以从中找到切入点。
机器学习是一场征程,而非目的地。希望这篇文章能为你的学习之旅点亮第一盏灯,让你在知识的海洋中步步为营,不断突破!
以上就是关于【机器学习】窥数据之序,悟算法之道:机器学习的初心与远方的内容啦,各位大佬有什么问题欢迎在评论区指正,或者私信我也是可以的啦,您的支持是我创作的最大动力!❤️

相关文章:
【机器学习】窥数据之序,悟算法之道:机器学习的初心与远方
文章目录 机器学习入门:从零开始学习基础与应用前言第一部分:什么是机器学习?1.1 机器学习的定义1.1.1 举个例子:垃圾邮件分类器 1.2 机器学习的核心思想1.2.1 数据驱动的模式提取1.2.2 为什么机器学习比传统方法更灵活࿱…...

OpenCL介绍
OpenCL(Open Computing Language)详解 OpenCL 是一个开源的框架,用于编写在异构平台(包括中央处理单元(CPU)、图形处理单元(GPU)、数字信号处理器(DSP)和其他…...

「Mac畅玩鸿蒙与硬件42」UI互动应用篇19 - 数字键盘应用
本篇将带你实现一个数字键盘应用,支持用户通过点击数字键输入数字并实时更新显示内容。我们将展示如何使用按钮组件和状态管理来实现一个简洁且实用的数字键盘。 关键词 UI互动应用数字键盘按钮组件状态管理用户交互 一、功能说明 数字键盘应用将实现以下功能&…...

【前端知识】npm命令行详细说明
npm命令行详细说明 概述一、定义与功能二、基本命令三、配置文件与注册表四、应用场景五、高级特性 环境设置1. 设置镜像源2. 配置全局依赖存储路径3. 配置缓存路径4. 查看所有配置5. 清除缓存6. 升级npm版本 npm组件打包1. 初始化项目2. 安装依赖3. 构建脚本4. 打包项目5. 发布…...

Python网络爬虫技术详解与实践案例
Python网络爬虫技术详解与实践案例 在大数据和人工智能盛行的今天,数据的获取与分析成为许多项目和业务的关键。网络爬虫作为一种自动化的数据采集工具,广泛应用于数据挖掘、市场分析、情报收集等领域。本文将详细介绍Python网络爬虫的基本概念、工作流程、进阶技巧,并附上…...

【遥感目标检测综述】【GRSS】遥感目标检测与深度学习的相遇:挑战与进展的元综述
Remote Sensing Object Detection Meets Deep Learning: A Meta-review of Challenges and Advances 遥感目标检测与深度学习的相遇:挑战与进展的元综述 论文链接 0.论文摘要和作者信息 摘要 遥感目标检测(RSOD)是遥感领域最基…...

【大数据技术基础】 课程 第3章 Hadoop的安装和使用 大数据基础编程、实验和案例教程(第2版)
第3章 Hadoop的安装和使用 3.1 Hadoop简介 Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中。H…...
【机器学习】机器学习的基本分类-监督学习-决策树-C4.5 算法
C4.5 是由 Ross Quinlan 提出的决策树算法,是对 ID3 算法的改进版本。它在 ID3 的基础上,解决了以下问题: 处理连续型数据:支持连续型特征,能够通过划分点将连续特征离散化。处理缺失值:能够在特征值缺失的…...

云计算vsphere 服务器上添加主机配置
这里是esxi 主机 先把主机打开 然后 先开启dns 再开启 vcenter 把每台设备桌面再vmware workstation 上显示 同上也是一样 ,因为在esxi 主机的界面可能有些东西不好操作 我们选择主机和集群 左边显示172.16.100.200...

Linux笔记---进程:进程替换
1. 进程替换的概念 进程替换是指在一个正在运行的进程中,用一个新的程序替换当前进程的代码和数据,使得进程开始执行新的程序,而不是原来的程序。 这种技术通常用于在不创建新进程的情况下,改变进程的行为。 我们之前谈到过for…...
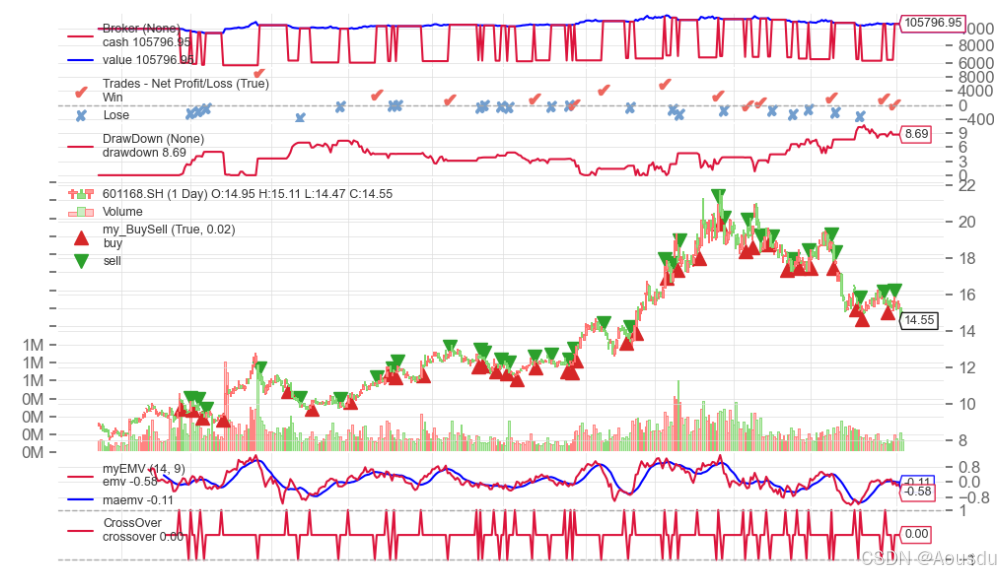
量化交易backtrader实践(五)_策略综合篇(1)_股票软件指标回测
在第三章6到9节,我们学习和实践了大部分股票软件指标,且这些指标是backtrader内置指标实践中没有讲到过的。然后,在进行策略综合之前,我们先热个身,把一些可能比较有参考意义的股票软件内置指标在backtrader里给实现了…...

4.STM32通信接口之SPI通信(含源码)---软件SPI与W25Q64存储模块通信实战《精讲》
经过研究SPI协议和W25Q64,逐步了解了SPI的通信过程,接下来,就要进行战场实战了!跟进Whappy步伐! 目标:主要实现基于软件的SPI的STM32对W25Q64存储写入和读取操作! 开胃介绍(代码基本…...

MINDAGENT:游戏交互中的新兴性设计
一、摘要 1.问题/研究背景 LLM具有在多智能体系统中执行复杂调度的能力,并可以协调这些代理以完成需要广泛合作的复杂任务。 但是,目前还没有一个标准的游戏场景和相关的测试指标来评估 LLM 在游戏中的表现以及与人类玩家的合作能力。 2.研究目标/动…...

【工具变量】上市公司企业所在地城市等级直辖市、副省级城市、省会城市 计划单列市(2005-2022年)
一、包含指标: 股票代码 股票代码 股票简称 年份 所属城市 直辖市:企业所在地是否属于直辖市。1是,0否。 副省级城市:企业所在地是否属于副省级城市。1是,0否。 省会城市&a…...

C# 动态类型 Dynamic
文章目录 前言1. 什么是 Dynamic?2. 声明 Dynamic 变量3. Dynamic 的运行时类型检查4. 动态类型与反射的对比5. 使用 Dynamic 进行动态方法调用6. Dynamic 与 原生类型的兼容性7. 动态与 LINQ 的结合8. 结合 DLR 特性9. 动态类型的性能考虑10. 何时使用 Dynamic&…...

Css动画:旋转相册动画效果实现
🌈个人主页:前端青山 🔥系列专栏:Css篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来Css篇专栏内容:Css动画:旋转相册动画效果实现 前言 随着Web技术的发展,网页不再局限于静态展示&#…...

Unity 基于Collider 组件在3D 物体表面放置3D 物体
实现 从鼠标点击的屏幕位置发送射线,以射线监测点击到的物体,根据点击物体的法线向量调整放置物体的位置及朝向。 Ray ray Camera.main.ScreenPointToRay(Input.mousePosition); if (Physics.Raycast(ray, out RaycastHit hit, 100)) {obj.transform.…...

Hbase整合Mapreduce案例1 hdfs数据上传至hbase中——wordcount
目录 整合结构准备java API 编写pom.xmlMain.javaMap.javaReduce 运行 整合结构 准备 上传hdfs data.txt数据 data.txt I am wunaiieq QAQ 123456 Who I am In todays interconnected world the role of technology cannot be overstated It has revolutionized the way we …...

PyQt 中的无限循环后台任务
在 PyQt 中实现一个后台无限循环任务,需要确保不会阻塞主线程,否则会导致 GUI 无响应。常用的方法是利用 线程(QThread) 或 任务(QRunnable 和 QThreadPool) 来运行后台任务。以下是一些实现方式和关键点&a…...

5G CPE核心器件-基带处理器(三)
5G CPE 核心器件 -5G基带芯片 基带芯片简介基带芯片组成与结构技术特点与发展趋势5G基带芯片是5G CPE中最核心的组件,负责接入5G网络,并进行上下行数据业务传输。移动通信从1G发展到5G,终端形态产生了极大的变化,在集成度、功耗、性能等方面都取得巨大的提升。 基带芯片简…...

2026 年好用的事业编面试软件盘点:AI 驱动的结构化备考解决方案
文章摘要 随着 2026 年全国事业单位招聘考试进入高峰期,越来越多的考生开始借助专业软件进行面试备考。本文从技术架构、功能完整性、用户体验和备考效果四个维度,对当前市场上主流的事业编面试软件进行全面测评。经过多轮实际测试和用户反馈分析&#…...

GD25Q64EWIGR、2.7-3.6V宽压供电的专业级串行闪存
内容介绍 今天我要向大家介绍的是 GigaDevice 的一款串行闪存——GD25Q64EWIGR。它能稳定提供 64M-bit(8MB)的海量存储,同时支持标准、双路和四路 SPI 高速读写,四路 I/O 数据传输速度最高可达 532Mbit/s。更难能可贵的是&…...
)
Gemini第三方嵌入组件合规黑洞(Cloudflare、Segment、Hotjar等11个SDK实测风险报告)
更多请点击: https://kaifayun.com 第一章:Gemini第三方嵌入组件合规黑洞全景概览 Gemini API 的第三方嵌入组件(如 、google/generative-ai 浏览器 SDK、社区封装的 React/Vue 组件)在快速落地的同时,正悄然形成一个…...

安徽话语音合成从0到商用,11步完成ElevenLabs API对接、情感注入与皖北/皖南口音校准
更多请点击: https://codechina.net 第一章:安徽话语音合成的地域语言学基础与商用价值 安徽话并非单一均质方言,而是涵盖江淮官话(如合肥话、扬州话)、中原官话(如阜阳话)、赣语(如…...

c# while循环 do while循环
while循环//while循环 //while(){}:当小括号条件成立 执行{}里面的东西,条件不成立的时候,循环就结束了while (true) //true 就是永远成立 一直执行{} {Console.WriteLine("死循环");break; //跳出死循环 只会执行一次 }while (tru…...

AI产品经理入门实战:如何理解知识图谱?
亲爱的小伙伴,如有帮助请订阅专栏!跟着老师每课一练,系统学习AI产品经理课程! 《AI产品经理入门实战》https://edu.csdn.net/course/detail/41126《Axure原型设计精品课》...

炉石传说佣兵战记自动化脚本:告别重复操作的全能指南
炉石传说佣兵战记自动化脚本:告别重复操作的全能指南 【免费下载链接】lushi_script This script is to save your time from Mercenaries mode of Hearthstone 项目地址: https://gitcode.com/gh_mirrors/lu/lushi_script 还在为《炉石传说》佣兵战记模式中…...

3分钟快速上手:R3nzSkin国服换肤神器完全指南
3分钟快速上手:R3nzSkin国服换肤神器完全指南 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 还在为英雄联盟国服皮肤价格昂贵而烦恼吗&…...

3分钟快速掌握Cursor试用重置工具:一键解除AI编程助手限制的完整指南
3分钟快速掌握Cursor试用重置工具:一键解除AI编程助手限制的完整指南 【免费下载链接】go-cursor-help 解决Cursor在免费订阅期间出现以下提示的问题: Your request has been blocked as our system has detected suspicious activity / Youve reached your trial r…...

监区越界预警技术革命:基于纯视觉无感全域风控体系,重构智慧监所时空管控范式
监区越界预警技术革命:基于纯视觉无感全域风控体系,重构智慧监所时空管控范式当前国内智慧监所越界预警领域,传统管控方案高度依赖UWB超宽带单点定位技术,整体技术架构以硬件堆叠为核心,依托标签穿戴、单点锚定、局部电…...