MongoDB集群的介绍与搭建
MongoDB集群的介绍与搭建
一.MongoDB集群的介绍
注意:Mongodb是一个比较流行的NoSQL数据库,它的存储方式是文档式存储,并不是Key-Value形式;
1.1集群的优势和特性
MongoDB集群的优势主要体现在以下几个方面:
(1)高可用性
MongoDB集群支持主从复制和故障转移机制,这确保了数据的高可用性和冗余性。当主节点出现故障时,集群可以自动切换到从节点,保证系统的持续运行。这种故障转移能力对于维护系统的稳定性和可靠性至关重要。
(2)扩展性
MongoDB集群具有出色的扩展性,可以通过水平扩展来增加系统的处理能力和存储容量。随着数据量的增加和访问压力的增大,只需简单地添加新的节点,即可轻松应对。这种扩展性使得MongoDB集群能够适用于各种规模的数据存储和处理需求。
(3)数据分片
MongoDB集群支持数据分片功能,可以将数据划分为多个分片,并部署在不同的节点上。这种数据分片机制不仅提高了系统的读写性能,还提供了更大的存储容量。MongoDB能够根据数据的分布情况,自动将查询请求分发到相应的分片上进行处理,从而进一步优化了系统的性能。
(4)弹性伸缩
MongoDB集群具有弹性伸缩的能力,可以根据系统的负载情况进行自动调整。当负载过高时,可以添加更多的节点来分担压力;当负载较低时,可以减少节点数量以节省资源。这种弹性伸缩机制使得MongoDB集群能够灵活地应对各种负载变化,保持系统的稳定性和性能。
(5)灵活性
MongoDB集群提供了灵活的数据模型和查询语言,可以存储和处理各种类型的数据。它支持文档型、关系型和图形型数据,并提供了强大的查询和聚合功能,方便用户对数据进行分析和处理。这种灵活性使得MongoDB集群能够适用于各种复杂的数据存储和处理场景。
(6)数据安全与容灾
MongoDB集群通过数据冗余和备份机制,提供了数据的安全性和容灾功能。即使某个节点出现故障,其他节点仍然可以正常运行,并保证数据的一致性和完整性。此外,MongoDB还支持跨地域的数据复制和容灾部署,进一步提高了数据的安全性和可靠性。
然而,也需要注意到MongoDB集群的一些潜在挑战,如配置复杂性、成本较高以及数据一致性等问题。在实际应用中,需要根据具体的需求和资源情况来选择合适的集群类型和配置方案,并进行合理的优化和维护以确保系统的性能和稳定性。
综上所述,MongoDB集群具有高可用性、扩展性、数据分片、弹性伸缩、灵活性和数据安全与容灾等优势,适用于各种大规模数据存储和处理的场景。
二.MongoDB集群的搭建
主要介绍三种集群方式的搭建过程:
2.1Replica Set(副本集)方式
主节点-备节点-仲裁节点
是集群当中包含了多份数据,保证主节点挂掉了,备节点能继续提供数据服务,提供的前提就是数据需要和主节点一致。

其中,Mongodb(M)表示主节点,Mongodb(S)表示备节点,Mongodb(A)表示仲裁节点。主备节点存储数据,仲裁节点不存储数据。客户端同时连接主节点与备节点,不连接仲裁节点。
默认设置下,主节点提供所有增删查改服务,备节点不提供任何服务。但是可以通过设置使备节点提供查询服务,这样就可以减少主节点的压力,当客户端进行数据查询时,请求自动转到备节点上。这个设置叫做Read Preference Modes,同时Java客户端提供了简单的配置方式,可以不必直接对数据库进行操作。
仲裁节点是一种特殊的节点,它本身并不存储数据,主要的作用是决定哪一个备节点在主节点挂掉之后提升为主节点,所以客户端不需要连接此节点。这里虽然只有一个备节点,但是仍然需要一个仲裁节点来提升备节点级别。我开始也不相信必须要有仲裁节点,但是自己也试过没仲裁节点的话,主节点挂了备节点还是备节点,所以咱们还是需要它的。
(1)建立数据文件夹
一般情况下不会把数据目录建立在mongodb的解压目录下,不过这里方便起见,就建在mongodb解压目录下吧。
mkdir -p /mongodb/data/master
mkdir -p /mongodb/data/slaver
mkdir -p /mongodb/data/arbiter
#三个目录分别对应主,备,仲裁节点(2)建立配置文件
由于配置比较多,所以我们将配置写到文件里。
#master.conf
dbpath=/mongodb/data/master
logpath=/mongodb/log/master.log
pidfilepath=/mongodb/master.pid
directoryperdb=true
logappend=true
replSet=testrs
bind_ip=10.10.148.130
port=27017
oplogSize=10000
fork=true
noprealloc=true
#slaver.conf
dbpath=/mongodb/data/slaver
logpath=/mongodb/log/slaver.log
pidfilepath=/mongodb/slaver.pid
directoryperdb=true
logappend=true
replSet=testrs
bind_ip=10.10.148.131
port=27017
oplogSize=10000
fork=true
noprealloc=true
#arbiter.conf
dbpath=/mongodb/data/arbiter
logpath=/mongodb/log/arbiter.log
pidfilepath=/mongodb/arbiter.pid
directoryperdb=true
logappend=true
replSet=testrs
bind_ip=10.10.148.132
port=27017
oplogSize=10000
fork=true
noprealloc=true
| 参数解读: |
| dbpath:数据存放目录 |
| port:mongodb进程所使用的端口号,默认为27017 |
| logpath:日志存放路径、bind_ip:mongodb所绑定的ip地址 |
| oplogSize:mongodb操作日志文件的最大大小。单位为Mb,默认为硬盘剩余空间的5% |
| pidfilepath:进程文件,方便停止mongodb |
| fork:以后台方式运行进程 |
| directoryperdb:为每一个数据库按照数据库名建立文件夹存放 |
| noprealloc:不预先分配存储、replSet:replica set的名字 |
| logappend:以追加的方式记录日志 |
(3)启动mongodb
进入每个mongodb节点的bin目录下
./monood -f master.conf
./mongod -f slaver.conf
./mongod -f arbiter.conf(4)配置主,备,仲裁节点
可以通过客户端连接mongodb,也可以直接在三个节点中选择一个连接mongodb。
./mongo 10.10.148.130:27017 #ip和port是某个节点的地址
>use admin
>cfg={ _id:"testrs", members:[ {_id:0,host:'10.10.148.130:27017',priority:2}, {_id:1,host:'10.10.148.131:27017',priority:1},
{_id:2,host:'10.10.148.132:27017',arbiterOnly:true}] };
>rs.initiate(cfg) #使配置生效
cfg是可以任意的名字,当然最好不要是mongodb的关键字,conf,config都可以。最外层的_id表示replica set的名字,members里包含的是所有节点的地址以及优先级。优先级最高的即成为主节点,即这里的10.10.148.130:27017。特别注意的是,对于仲裁节点,需要有个特别的配置——arbiterOnly:true。这个千万不能少了,不然主备模式就不能生效。
配置的生效时间根据不同的机器配置会有长有短,配置不错的话基本上十几秒内就能生效,有的配置需要一两分钟。如果生效了,执行rs.status()命令会看到如下信息:
{"set" : "testrs","date" : ISODate("2013-01-05T02:44:43Z"),"myState" : 1,"members" : [{"_id" : 0,"name" : "10.10.148.130:27017","health" : 1,"state" : 1,"stateStr" : "PRIMARY","uptime" : 200,"optime" : Timestamp(1357285565000, 1),"optimeDate" : ISODate("2013-01-04T07:46:05Z"),"self" : true},{"_id" : 1,"name" : "10.10.148.131:27017","health" : 1,"state" : 2,"stateStr" : "SECONDARY","uptime" : 200,"optime" : Timestamp(1357285565000, 1),"optimeDate" : ISODate("2013-01-04T07:46:05Z"),"lastHeartbeat" : ISODate("2013-01-05T02:44:42Z"),"pingMs" : 0},{"_id" : 2,"name" : "10.10.148.132:27017","health" : 1,"state" : 7,"stateStr" : "ARBITER","uptime" : 200,"lastHeartbeat" : ISODate("2013-01-05T02:44:42Z"),"pingMs" : 0}],"ok" : 1
}
如果配置正在生效,其中会包含如下信息:
"stateStr" : "RECOVERING"同时可以查看对应节点的日志,发现正在等待别的节点生效或者正在分配数据文件。
现在基本上已经完成了集群的所有搭建工作。至于测试工作,可以留给大家自己试试。一个是往主节点插入数据,能从备节点查到之前插入的数据(查询备节点可能会遇到某个问题,可以自己去网上查查看)。二是停掉主节点,备节点能变成主节点提供服务。三是恢复主节点,备节点也能恢复其备的角色,而不是继续充当主的角色。二和三都可以通过rs.status()命令实时查看集群的变化。
2.2Sharding方式
主节点-备节点-仲裁节点-路由节点
和Replica Set类似,都需要一个仲裁节点,但是Sharding还需要配置节点和路由节点。就三种集群搭建方式来说,这种是最复杂的。

(1)启动数据节点
./mongod --fork --dbpath ../data/set1/ --logpath ../log/set1.log --replSet test #192.168.4.43
./mongod --fork --dbpath ../data/set2/ --logpath ../log/set2.log --replSet test #192.168.4.44
./mongod --fork --dbpath ../data/set3/ --logpath ../log/set3.log --replSet test #192.168.4.45 决策 不存储数据
(2)启动配置节点
./mongod --configsvr --dbpath ../config/set1/ --port 20001 --fork --logpath ../log/conf1.log #192.168.4.30
./mongod --configsvr --dbpath ../config/set2/ --port 20002 --fork --logpath ../log/conf2.log #192.168.4.31
(3)启动路由节点
./mongos --configdb 192.168.4.30:20001,192.168.4.31:20002 --port 27017 --fork --logpath ../log/root.log #192.168.4.29这里我们没有用配置文件的方式启动,其中的参数意义大家应该都明白。一般来说一个数据节点对应一个配置节点,仲裁节点则不需要对应的配置节点。注意在启动路由节点时,要将配置节点地址写入到启动命令里。
(4)配置Replica Set
这里可能会有点奇怪为什么Sharding会需要配置Replica Set。其实想想也能明白,多个节点的数据肯定是相关联的,如果不配一个Replica Set,怎么标识是同一个集群的呢。这也是人家mongodb的规定,咱们还是遵守吧。配置方式和之前所说的一样,定一个cfg,然后初始化配置。
./mongo 192.168.4.43:27017 #ip和port是某个节点的地址
>use admin
>cfg={ _id:"testrs", members:[ {_id:0,host:'192.168.4.43:27017',priority:2}, {_id:1,host:'192.168.4.44:27017',priority:1},
{_id:2,host:'192.168.4.45:27017',arbiterOnly:true}] };
>rs.initiate(cfg) #使配置生效
(5) 配置Sharding
./mongo 192.168.4.29:27017 #这里必须连接路由节点
>sh.addShard("test/192.168.4.43:27017") #test表示replica set的名字 当把主节点添加到shard以后,会自动找到set里的主,备,决策节点
>db.runCommand({enableSharding:"diameter_test"}) #diameter_test is database name
>db.runCommand( { shardCollection: "diameter_test.dcca_dccr_test",key:{"__avpSessionId":1}})
第一个命令很容易理解,第二个命令是对需要进行Sharding的数据库进行配置,第三个命令是对需要进行Sharding的Collection进行配置,这里的dcca_dccr_test即为Collection的名字。另外还有个key,这个是比较关键的东西,对于查询效率会有很大的影响,具体可以查看 Shard Key Overview
到这里Sharding也已经搭建完成了,以上只是最简单的搭建方式,其中某些配置仍然使用的是默认配置。如果设置不当,会导致效率异常低下,所以建议大家多看看官方文档再进行默认配置的修改。
2.3Master-Slave方式
主节点-备节点
这个是最简答的集群搭建,不过准确说也不能算是集群,只能说是主备。并且官方已经不推荐这种方式,所以在这里只是简单的介绍下吧,搭建方式也相对简单。
./mongod --master --dbpath /data/masterdb/ #主节点./mongod --slave --source <masterip:masterport> --dbpath /data/slavedb/ 备节点基本上只要在主节点和备节点上分别执行这两条命令,Master-Slaver就算搭建完成了。我没有试过主节点挂掉后备节点是否能变成主节点,不过既然已经不推荐了,大家就没必要去使用了。
三.自己亲测过程
3.1.准备工作
因为我这里的数据量不大,所以一般使用带仲裁节点的集群即可,没必要使用带有路由节点的;
(1)环境准备(三台Centos7的虚拟机):192.168.32.215 / 192.168.32.216 / 192.168.32.217
(2)机器分配:215为master节点 , 217为slave节点 , 216为仲裁节点
(3)安装包下载:使用wget来下载,版本为4.4.5,想要其他的版本自己可以更换:
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.4.5.tgz将安装包用scp命令传输到另外两台上;
3.2.进行配置
(1)目录准备
三台机器的目录尽量一致,我这里都存放解压后的目录为/opt/hadoop
创建目录:
215机器:
#在opt下创建hadoop
mkdir /opt/hadoop
#将安装包解压到hadoop下
tar -zxvf mongodb-linux-x86_64-rhel70-4.4.5.tgz -C /opt/hadoop/
#解压的目录形式为:/opt/hadoop/mongo4.4
#我这里修改为了:/opt/hadoop/mongodb4.4为了方便,然后就在mongodb4.4里面执行下面的操作#数据存文的目录
mkdir -p data/master
#日志目录
mkdir logs
#配置目录
mkdir conf
cd logs
#日志文件
touch master.log
cd conf
#配置文件
touch mongodb.conf 如同下面得图中表现:

217机器:
同上述节点:
mkdir -p data/slave
mkdir logs
mkdir conf
cd logs
touch slave.log
cd conf
touch mongodb.conf216机器:
同上述节点:
mkdir -p data/arbite
mkdir logs
mkdir conf
cd logs
touch arbite.log
cd conf
touch mongodb.conf(2)编辑配置文件
215节点(Master):
编辑mongodb.conf

#master配置
#数据存放路径
dbpath=/opt/hadoop/mongodb4.4/data/master
#日志路径
logpath=/opt/hadoop/mongodb4.4/logs/master.log
#以追加的方式记录日志
logappend=true
#mongoDB进程所绑定的ip地址
bind_ip=192.168.32.215
#端口号,默认端口号为27017
port=27017
#以后台方式运行进程
fork=true
#4.33版本后已经取消
#noprealloc=true
#集群名称
replSet=test 217节点(Slave):
编辑mongodb.conf
#slave配置
dbpath=/opt/hadoop/mongodb4.4/data/slave
logpath=/opt/hadoop/mongodb4.4/logs/slave.log
logappend=true
bind_ip=192.168.32.217
port=27017
fork=true
#noprealloc=true
replSet=test216节点(arbite仲裁节点):
编辑mongodb.conf
#仲裁节点配置
dbpath=/opt/hadoop/mongodb4.4/data/arbite
logpath=/opt/hadoop/mongodb4.4/logs/arbite.log
logappend=true
bind_ip=192.168.32.216
#注意仲裁节点我给的端口号是27018
port=27018
fork=true
#noprealloc=true
replSet=test3.3启用
分别启动mongodb
直接输入如下命令即可,要保证路径正确即可:
/opt/hadoop/mongodb4.4/bin/mongod -f /opt/hadoop/mongodb4.4/conf/mongodb.conf启动成功,如下

(4)再进一步简单的配置
a.在任意一个节点上,连接到主节点
这里ip换成你们配置中的主节点即可

b.输入如下命令(里面ip换成你们自己的即可):
cfg={_id:"test", members: [ {_id:0,host:'192.168.32.215:27017',priority:2} ,{_id:1,host:'192.168.32.217:27017',priority:1} ,{_id:2,host:'192.168.32.216:27018',arbiterOnly:true}]};
c.初始化集群-让配置生效
rs.initiate(cfg) 当你能看到代表成功ok:1
注意:如下是返回的初始化不成功的信息,需要关闭你们的机器防火墙即可;

关闭防火墙的命令:
systemctl status firewalld
systemctl stop firewalld
systemctl disable firewalld再次执行,发现返回状态成功。

d.查看集群状态



OK,测试完毕。
四.总结
以上三种集群搭建方式首选Replica Set,只有真的是大数据,Sharding才能显现威力,毕竟备节点同步数据是需要时间的。Sharding可以将多片数据集中到路由节点上进行一些对比,然后将数据返回给客户端,但是效率还是比较低的说。大家在应用的时候还是多多做下性能测试,毕竟不像Redis有benchmark。
Mongodb现在用的还是比较多的,但是个人觉得配置太多了,我看官网都看了好多天,才把集群搭建的配置和注意要点弄明白。而且用过的人应该知道mongodb吃内存的问题,解决办法只能通过ulimit来控制内存使用量,但是如果控制不好的话,mongodb会挂掉。
相关文章:
MongoDB集群的介绍与搭建
MongoDB集群的介绍与搭建 一.MongoDB集群的介绍 注意:Mongodb是一个比较流行的NoSQL数据库,它的存储方式是文档式存储,并不是Key-Value形式; 1.1集群的优势和特性 MongoDB集群的优势主要体现在以下几个方面: (1)高…...

PhpStorm配置Laravel
本文是2024最新的通过phpstorm创建laravel项目 1.下载phpstorm 2.检查本电脑的环境phpcomposer 显示图标就是安装成功了,不会安装的百度自行安装 3.安装完后,自行创建一个空目录不要有中文,然后运行cmd 输入以下命令,即可创建…...

Solving the Makefile Missing Separator Stop Error in VSCode
1. 打开 Makefile 并转换缩进 步骤 1: 在 VSCode 中打开 Makefile 打开 VSCode。使用文件浏览器或 Ctrl O(在 Mac 上是 Cmd O)打开你的 Makefile。 步骤 2: 打开命令面板 按 Ctrl Shift P(在 Mac 上是 Cmd Shift P)&…...

MySQL大小写敏感、MySQL设置字段大小写敏感
文章目录 一、MySQL大小写敏感规则二、设置数据库及表名大小写敏感 2.1、查询库名及表名是否大小写敏感2.2、修改库名及表名大小写敏感 三、MySQL列名大小写不敏感四、lower_case_table_name与校对规则 4.1、验证校对规则影响大小写敏感4.1、验证校对规则影响排序 五、设置字段…...

项目搭建:guice,jdbc,maven
当然,以下是一个使用Guice、JDBC和Maven实现接口项目的具体例子。这个项目将展示如何创建一个简单的用户管理应用,包括用户信息的增删改查(CRUD)操作。 ### 1. Maven pom.xml 文件 首先确保你的pom.xml文件包含必要的依赖&#…...
)
第四届新生程序设计竞赛正式赛(C语言)
A: HNUCM的学习达人 SQ同学是HNUCM的学习达人,据说他每七天就能够看完一本书,每天看七分之一本书,而且他喜欢看完一本书之后再看另外一本。 现在请你编写一个程序,统计在指定天数中,SQ同学看完了多少本完整的书&#x…...

【分布式知识】Redis6.x新特性了解
文章目录 Redis6.x新特性1. 多线程I/O处理2. 改进的过期算法3. SSL/TLS支持4. ACL(访问控制列表)5. RESP3协议6. 客户端缓存7. 副本的无盘复制8. 其他改进 Redis配置详解1. 基础配置2. 安全配置3. 持久化配置4. 客户端与连接5. 性能与资源限制6. 其他配置…...

程序员需要具备哪些知识?
程序员需要掌握的知识广泛而深厚,这主要取决于具体从事的领域和技术方向。不过,有些核心知识是共通的,就像建房子的地基一样,下面来讲讲这些关键领域: 1. 编程语言: 无论你是搞前端、后端、移动开发还是嵌…...

实验四:MyBatis 的关联映射
目录: 一 、实验目的: 熟练掌握实体之间的各种映射关系。 二 、预习要求: 预习数据库原理中所讲过的一对一、一对多和多对多关系 三、实验内容: 1. 查询所有订单信息,关联查询下单用户信息(注意:因为一…...

【Leetcode】189.轮转数组
题目链接: 189.轮转数组 题目描述: 解题思路: 要想实现数组元素向右轮转k个位置,可是将数组三次反转来实现 以 nums [1,2,3,4,5,6,7], k 3 为例,最终要得到[5,6,7,1,2,3,4]: 第一次反转:将整个数组反转…...

【JavaSE】常见面试问题
1. 什么是 Java 中的多态? 多态是 Java 中面向对象的核心特性之一,指的是同一操作作用于不同类型的对象时表现出不同的行为。通过方法重载和方法重写实现。方法重载是同一方法名,根据参数不同做不同处理,属于编译时多态ÿ…...
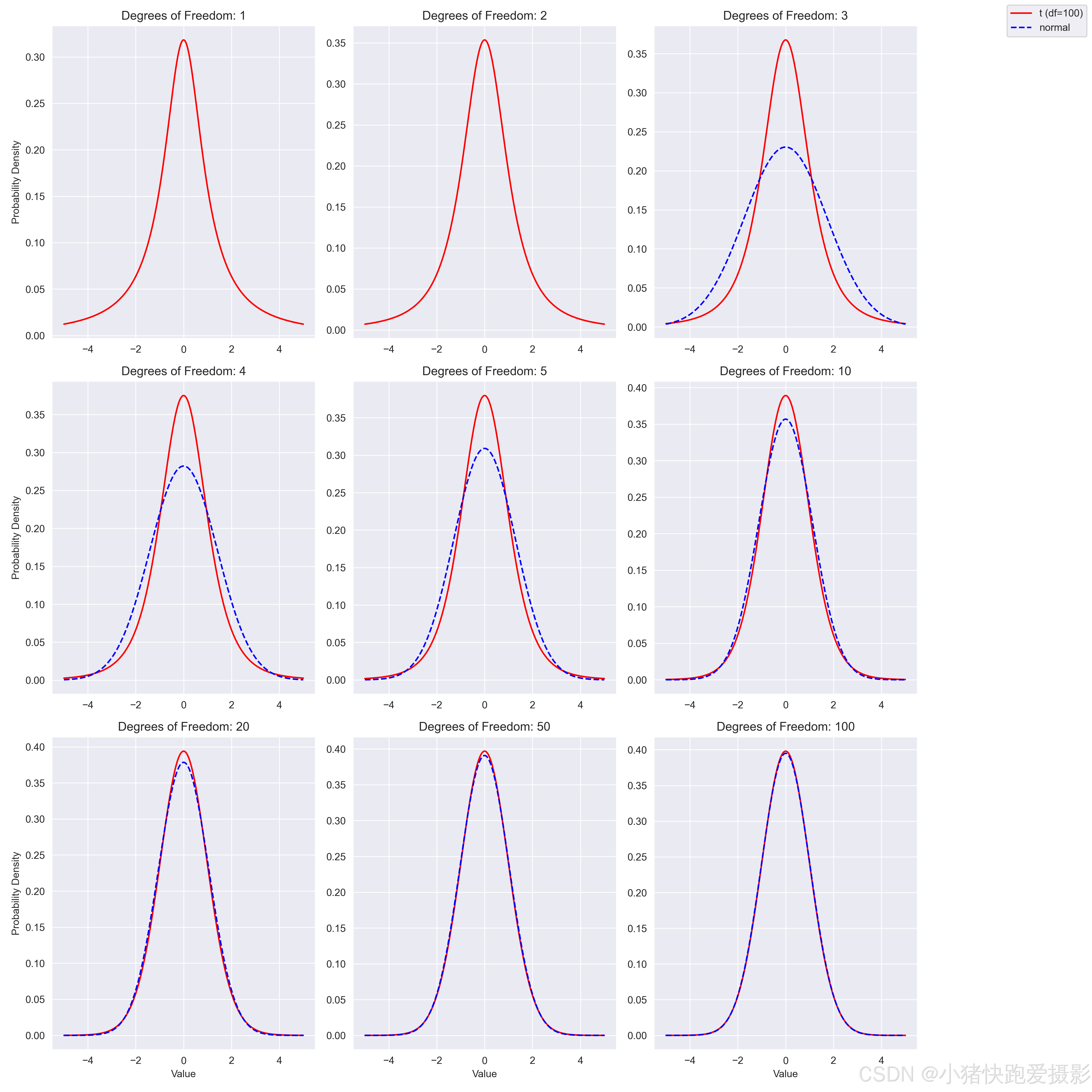
【超详图文】多少样本量用 t分布 OR 正态分布
文章目录 相关教程相关文献预备知识Lindeberg-Lvy中心极限定理 t分布的来历实验不同分布不同抽样次数的总体分布不同自由度相同参数的t分布&正态分布 作者:小猪快跑 基础数学&计算数学,从事优化领域7年,主要研究方向:MIP求…...

leetcode hot100【Leetcode 416.分割等和子集】java实现
Leetcode 416.分割等和子集 题目描述 给定一个非负整数的数组 nums ,你需要将该数组分割成两个子集,使得两个子集的元素和相等。如果可以分割,返回 true ,否则返回 false。 示例 1: 输入:nums [1,5,11,…...

《算法导论》英文版前言To the teacher第4段研习录:有答案不让用
【英文版】 Departing from our practice in previous editions of this book, we have made publicly available solutions to some, but by no means all, of the problems and exercises. Our Web site, http://mitpress.mit.edu/algorithms/, links to these solutions. Y…...

Laravel关联模型查询
一,多表关联 文章表articles 和user_id,category_id关联 //with()方法是渴求式加载,缓解了1N的查询问题,仅需11次查询就能解决问题,可以提升查询速度。with部分没有就以null输出,所以可以理解为 多表 left join 查…...

Clickhouse 数据类型
文章目录 字符串类型数值类型日期时间类型枚举类型数组类型元组类型映射类型其它类型 字符串类型 数据类型描述备注String可变长度字符串无长度限制,适用于存储任意字符FixedString固定长度字符串定长字符串,长度在创建时指定,如 FixedStrin…...

物联网智能项目如何实现设备高效互联与数据处理?
一、硬件(Hardware) 设备互联的基础,涵盖传感器、执行器、网关和边缘计算设备。 传感器与执行器 功能: 采集环境数据(如温度、湿度、运动等)并执行控制命令。优化方向: 低功耗、高精度传感器以…...

【云服务器】搭建博客服务
未完待续 一、云服务器二、1panel安装及其容器三、Halo博客 一、云服务器 选择了狗云服务器:狗云-高性价比的服务器 安装系统:Ubuntu22.04 前期配置: 修改ssh端口: 二、1panel安装及其容器 三、Halo博客 主题:butt…...

如何抽象策略模式
策略模式是什么 策略设计模式(Strategy Pattern)是一种面向对象设计模式,它定义了一系列算法,并将每个算法封装起来,使它们可以相互替换。这种模式使得算法可以独立于使用它们的客户端而变化。 策略设计模式包含三个主…...

BERT模型的输出格式探究以及提取出BERT 模型的CLS表示,last_hidden_state[:, 0, :]用于提取每个句子的CLS向量表示
说在前面 最近使用自己的数据集对bert-base-uncased进行了二次预训练,只使用了MLM任务,发现在加载训练好的模型进行输出CLS表示用于下游任务时,同一个句子的输出CLS表示都不一样,并且控制台输出以下警告信息。说是没有这些权重。…...

甲骨文免费服务器到手后,用Xshell连接不上?这份SSH密钥配置避坑指南请收好
甲骨文云SSH连接全攻略:从密钥解析到Xshell实战配置 密钥管理的核心逻辑与常见误区 初次接触甲骨文云免费实例的用户,90%的SSH连接问题都源于密钥处理不当。与常规密码登录不同,甲骨文云强制采用密钥对认证机制,这种设计虽然提升了…...

SAM优化原理与PyTorch实战:从尖锐度抑制到泛化能力提升
1. 项目概述:当“找最低点”升级为“找最稳的洼地”你有没有试过调参调到凌晨三点,模型在训练集上准确率飙到99.8%,一跑验证集直接掉到72%?那种看着loss曲线一路俯冲、心里却越来越慌的感觉,我太熟了——就像精心搭好一…...

告别手动敲变量!用Python脚本批量处理施耐德Control Expert变量表
用Python脚本解放双手:高效处理施耐德Control Expert变量表全攻略 在工业自动化领域,施耐德的Control Expert(原Unity Pro)是处理中高端PLC编程的主流软件。对于经常需要管理成百上千个变量的工程师来说,手动操作不仅耗…...

书匠策AI:你的论文过不了关?http://www.shujiangce.com这套组合拳直接救场!
开篇一句话:2025年写论文,拼的不是文笔,是"过关能力"。 查重40%以上被打回,AIGC检测疑似度超标被标记——这两座大山压在每个毕业生头上。你是不是也经历过这种绝望:明明每个字都是自己敲的,系统…...

5分钟掌握WeKWS:打造智能设备的语音唤醒终极指南
5分钟掌握WeKWS:打造智能设备的语音唤醒终极指南 【免费下载链接】wekws Production First and Production Ready End-to-End Keyword Spotting Toolkit 项目地址: https://gitcode.com/gh_mirrors/we/wekws 在人工智能时代,智能设备如何快速响应…...

Awesome Made by Brazilians 路线图深度分析:巴西开发者开源项目的未来发展趋势预测
Awesome Made by Brazilians 路线图深度分析:巴西开发者开源项目的未来发展趋势预测 【免费下载链接】awesome-made-by-brazilians 🇧🇷 A collection of amazing open source projects built by brazilian developers 项目地址: https://g…...

科研绘图革命:3步让Matplotlib图表达到期刊发表标准
科研绘图革命:3步让Matplotlib图表达到期刊发表标准 【免费下载链接】SciencePlots Matplotlib styles for scientific plotting 项目地址: https://gitcode.com/gh_mirrors/sc/SciencePlots 想象一下这样的场景:你花了数周时间收集数据、编写分析…...

DownGit:3分钟掌握GitHub文件下载的终极指南,无需克隆整个仓库!
DownGit:3分钟掌握GitHub文件下载的终极指南,无需克隆整个仓库! 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 你是否曾经为了下载GitHub上的一个配置文件,却被…...

ncmdump终极指南:3步快速解密网易云音乐NCM格式,重获音乐掌控权
ncmdump终极指南:3步快速解密网易云音乐NCM格式,重获音乐掌控权 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾为网易云音乐的NCM加密格式而烦恼?精心收藏的音乐只能在特定平台播放&…...

虚幻5细节面板消失的真相与四步唤醒方案
1. 这不是Bug,是虚幻5蓝图编辑器的“细节面板隐身术”在作祟2025年用虚幻引擎5做项目,突然发现蓝图编辑器右侧的细节面板(Details Panel)怎么点都不出来——节点选中了没反应,右键菜单里找不到“显示细节”,…...