yolov11剪枝
思路:yolov11中的C3k2与yolov8的c2f的不同,所以与之前yolov8剪枝有稍许不同;
后续:会将剪枝流程写全,以及增加蒸馏、注意力、改loss;
注意:
1.在代码105行修改pruning.get_threshold(yolo.model, 0.65),可以获得不同的剪枝率;
2.改代码放在训练代码同一页面下即可;
3.在最后修改文件夹地址来获得剪枝后的模型;
from ultralytics import YOLO
import torch
from ultralytics.nn.modules import Bottleneck, Conv, C2f, SPPF, Detect, C3k2
from torch.nn.modules.container import Sequential
import os# os.environ["CUDA_VISIBLE_DEVICES"] = "2"class PRUNE():def __init__(self) -> None:self.threshold = Nonedef get_threshold(self, model, factor=0.8):ws = []bs = []for name, m in model.named_modules():if isinstance(m, torch.nn.BatchNorm2d):w = m.weight.abs().detach()b = m.bias.abs().detach()ws.append(w)bs.append(b)print(name, w.max().item(), w.min().item(), b.max().item(), b.min().item())print()# keepws = torch.cat(ws)self.threshold = torch.sort(ws, descending=True)[0][int(len(ws) * factor)]def prune_conv(self, conv1: Conv, conv2: Conv):## Normal Pruninggamma = conv1.bn.weight.data.detach()beta = conv1.bn.bias.data.detach()keep_idxs = []local_threshold = self.thresholdwhile len(keep_idxs) < 8: ## 若剩余卷积核<8, 则降低阈值重新筛选keep_idxs = torch.where(gamma.abs() >= local_threshold)[0]local_threshold = local_threshold * 0.5n = len(keep_idxs)# n = max(int(len(idxs) * 0.8), p)print(n / len(gamma) * 100)conv1.bn.weight.data = gamma[keep_idxs]conv1.bn.bias.data = beta[keep_idxs]conv1.bn.running_var.data = conv1.bn.running_var.data[keep_idxs]conv1.bn.running_mean.data = conv1.bn.running_mean.data[keep_idxs]conv1.bn.num_features = nconv1.conv.weight.data = conv1.conv.weight.data[keep_idxs]conv1.conv.out_channels = nif isinstance(conv2, list) and len(conv2) > 3 and conv2[-1]._get_name() == "Proto":proto = conv2.pop()proto.cv1.conv.in_channels = nproto.cv1.conv.weight.data = proto.cv1.conv.weight.data[:, keep_idxs]if conv1.conv.bias is not None:conv1.conv.bias.data = conv1.conv.bias.data[keep_idxs]## Regular Pruningif not isinstance(conv2, list):conv2 = [conv2]for item in conv2:if item is None: continueif isinstance(item, Conv):conv = item.convelse:conv = itemif isinstance(item, Sequential):conv1 = item[0]conv = item[1].convconv1.conv.in_channels = nconv1.conv.out_channels = nconv1.conv.groups = nconv1.conv.weight.data = conv1.conv.weight.data[keep_idxs, :]conv1.bn.bias.data = conv1.bn.bias.data[keep_idxs]conv1.bn.weight.data = conv1.bn.weight.data[keep_idxs]conv1.bn.running_var.data = conv1.bn.running_var.data[keep_idxs]conv1.bn.running_mean.data = conv1.bn.running_mean.data[keep_idxs]conv1.bn.num_features = nconv.in_channels = nconv.weight.data = conv.weight.data[:, keep_idxs]def prune(self, m1, m2):if isinstance(m1, C3k2): # C3k2 as a top convm1 = m1.cv2if isinstance(m1, Sequential):m1 = m1[1]if not isinstance(m2, list): # m2 is just one modulem2 = [m2]for i, item in enumerate(m2):if isinstance(item, C3k2) or isinstance(item, SPPF):m2[i] = item.cv1self.prune_conv(m1, m2)def do_pruning(modelpath, savepath):pruning = PRUNE()### 0. 加载模型yolo = YOLO(modelpath) # build a new model from scratchpruning.get_threshold(yolo.model, 0.65) # 这里的0.8为剪枝率。### 1. 剪枝C3k2 中的Bottleneckfor name, m in yolo.model.named_modules():if isinstance(m, Bottleneck):pruning.prune_conv(m.cv1, m.cv2)### 2. 指定剪枝不同模块之间的卷积核seq = yolo.model.modelfor i in [3, 5, 7, 8]:pruning.prune(seq[i], seq[i + 1])### 3. 对检测头进行剪枝# 在P3层: seq[15]之后的网络节点与其相连的有 seq[16]、detect.cv2[0] (box分支)、detect.cv3[0] (class分支)# 在P4层: seq[18]之后的网络节点与其相连的有 seq[19]、detect.cv2[1] 、detect.cv3[1]# 在P5层: seq[21]之后的网络节点与其相连的有 detect.cv2[2] 、detect.cv3[2]detect: Detect = seq[-1]proto = detect.protolast_inputs = [seq[16], seq[19], seq[22]]colasts = [seq[17], seq[20], None]for idx, (last_input, colast, cv2, cv3, cv4) in enumerate(zip(last_inputs, colasts, detect.cv2, detect.cv3, detect.cv4)):if idx == 0:pruning.prune(last_input, [colast, cv2[0], cv3[0], cv4[0], proto])else:pruning.prune(last_input, [colast, cv2[0], cv3[0], cv4[0]])pruning.prune(cv2[0], cv2[1])pruning.prune(cv2[1], cv2[2])pruning.prune(cv3[0], cv3[1])pruning.prune(cv3[1], cv3[2])pruning.prune(cv4[0], cv4[1])pruning.prune(cv4[1], cv4[2])### 4. 模型梯度设置与保存for name, p in yolo.model.named_parameters():p.requires_grad = Trueyolo.val(data='data.yaml', batch=2, device=0, workers=0)torch.save(yolo.ckpt, savepath)if __name__ == "__main__":modelpath = "runs/segment/Constraint/weights/best.pt"savepath = "runs/segment/Constraint/weights/last_prune.pt"do_pruning(modelpath, savepath)
相关文章:

yolov11剪枝
思路:yolov11中的C3k2与yolov8的c2f的不同,所以与之前yolov8剪枝有稍许不同; 后续:会将剪枝流程写全,以及增加蒸馏、注意力、改loss; 注意: 1.在代码105行修改pruning.get_threshold(yolo.mo…...

智慧地图聚合(LockMap)标注系统开发说明文档
智慧地图聚合(LockMap)标注系统开发说明文档 1. 系统概述 智慧地图聚合(LockMap)标注系统是一个专为处理大规模地理信息数据而设计的综合解决方案。通过后端高效的数据管理和前端直观的地图展示,该系统能够实现对海量地理位置点的有效可视化。本项目旨在提供一个用…...

「Mac畅玩鸿蒙与硬件36」UI互动应用篇13 - 数字滚动抽奖器
本篇将带你实现一个简单的数字滚动抽奖器。用户点击按钮后,屏幕上的数字会以滚动动画的形式随机变动,最终显示一个抽奖数字。这个项目展示了如何结合定时器、状态管理和动画实现一个有趣的互动应用。 关键词 UI互动应用数字滚动动画效果状态管理用户交…...

cuda12.1版本的pytorch环境安装记录,并添加到jupyter和pycharm中
文章目录 前置准备使用anaconda prompt创建虚拟环境创建虚拟环境激活pytorch虚拟环境把pytorch下载到本地使用pip把安装包安装到pytorch环境中进入python环境检验是否安装成功将环境添加到jupyter在pycharm中使用该环境: 前置准备 安装anaconda,我的版本…...

Linux: network: nic: mellanox MRU初现
文章目录 在PPP协议了有提到过总结-吐槽MRU初现兼容问题详细的MRU的计算幸运下面这个commit缩小了幸运机会So在PPP协议了有提到过 MRU在RFC4638里有提到。但是在Linux内核里是的Ethernet是没有相关的概念。 总结-吐槽 说Mellanox的网卡驱动在2018年做了一个对进入packet的大…...

深入理解红黑树的底层逻辑
一、红黑树的定义 红黑树是一种自平衡的二叉查找树,每个节点都带有额外的颜色信息,可以是红色或黑色。红黑树的目的是通过引入颜色信息来确保树的平衡,从而提高查找、插入和删除等操作的效率。 二、红黑树的性质 每个节点都有颜色…...

【数据结构】手搓链表
一、定义 typedef struct node_s {int _data;struct node_s *_next; } node_t;typedef struct list_s {node_t *_head;node_t *_tail; } list_t;节点结构体(node_s): int _data;存储节点中的数据struct node_s *_next;:指向 node…...

ThinkPHP场景动态验证
一、缘由 今天在用thinkphp8写东西的时候发现,写验证器规则和场景优点费时间,就算用tinkphp的命令行生成也是生成一个空壳。内容还是要自己填写感觉麻烦。 就突发奇想能不能自动生成验证器,也不能是说自动生成验证器,生成验证其的…...

在M3上面搭建一套lnmp环境
下载docker-desktop 官网下载docker-desktop 切换镜像源 {"builder": {"gc": {"defaultKeepStorage": "20GB","enabled": true}},"experimental": false,"registry-mirrors": ["https://docke…...

【C++笔记】二叉搜索树
前言 各位读者朋友们大家好!上期我们讲完了面向对象编程三大属性之一的多态,这一期我们再次开始数据结构二叉搜索树的讲解。 目录 前言一. 二叉搜索树的概念二. 二叉搜索树的性能分析三. 二叉搜索树的插入四. 二叉搜索树的查找五. 二叉搜索树的删除六.…...

Fork/Join框架简介
一、Fork/Join框架简介 Fork/Join框架是Java 7引入的一个用于并行执行任务的框架,它可以将一个大任务分割成若干个小任务,并行执行这些小任务,然后将每个小任务的结果合并起来,得到大任务的结果。这种框架特别适合于能够被递归分…...

Java项目实战II基于微信小程序的电子竞技信息交流平台的设计与实现(开发文档+数据库+源码)
目录 一、前言 二、技术介绍 三、系统实现 四、核心代码 五、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。获取源码联系方式请查看文末 一、前言 随着互联网技术的飞速发展…...

Mysql读写分离分库分表
读写分离 什么是读写分离 读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上。 这样的话,就能够小幅提升写性能,大幅提升读性能。一般情况下,我们都会选择一主多从,也就是一台主数据库负责写,其他的从…...
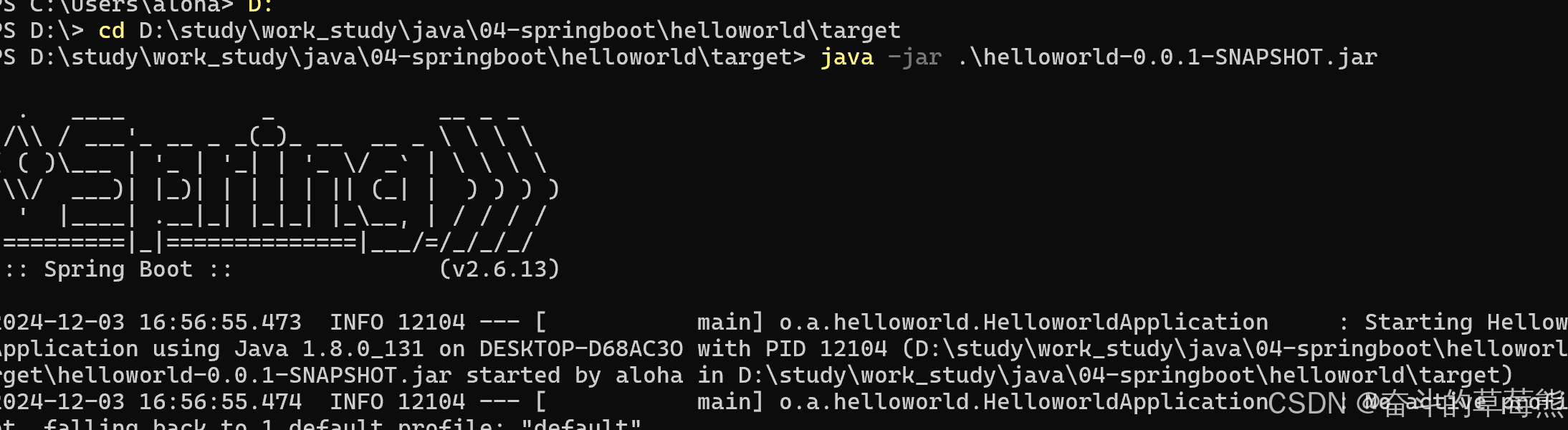
B站狂神说--springboot项目学习(新建一个springboot项目)
文章目录 1.新建项目java8项目1.解决自带的idea2024无法使用java8的问题 2.新建接口3.项目打包为jar包4.使用jar包 1.新建项目java8项目 1.解决自带的idea2024无法使用java8的问题 将server.url修改为阿里云的地址:https://start.aliyun.com/ 选择Spring Web 创建…...

eltable el-table 横向 滚动条常显
又遇到了难受的问题,el-table嵌入在一个div里面,结果因为内容太多,横向、纵向我都得滚动查看! 结果发现横向滚动时只能让它纵向触底后才能进行横向操作,这就很变态,明显不符合用户操作习惯。如下图: 要先纵…...

centos8 mysql 主从复制
原理 一、一主一从 准备工作 1.主库配置 1、修改配置文件 /etc/my.cnf #mysql 服务ID,保证整个集群环境中唯一,取值范围:1-232-1,默认为 server-id1 #是否只读,1 代表只读,0代表读写 read-only0 #忽略的数据,指不需要同步的数据库 #binlog…...

【C++】入门【五】
本节目标 一、C/C内存分布 二、C语言中动态内存管理方式 三、C中动态内存管理 四、operator new与operator delete函数 五、new和delete的实现原理 六、定位new表达式(placement-new) 七、常见面试题 一、C/C内存分布 一个程序占用的内存主要有以下几部分栈区(stac…...

【React】二、状态变量useState
文章目录 1、React中的事件绑定1.1 基础事件绑定1.2 使用事件对象参数1.3 传递自定义参数1.4 同时传递事件对象和自定义参数 2、React中的组件3、useState 1、React中的事件绑定 1.1 基础事件绑定 语法:on 事件名称 { 事件处理程序 },整体上遵循驼峰…...

SQL Server中的数据处理函数:提升SQL查询能力
文章目录 前言1. 数据类型转换函数CAST()CONVERT()TRY_CAST() 和 TRY_CONVERT() 2. 数学函数ABS()CEILING()FLOOR()ROUND()POWER()SQRT() 3. 日期和时间函数GETDATE()SYSDATETIME()DATEADD()DATEDIFF()YEAR()、MONTH() 和 DAY()FORMAT() 4. 条件处理函数CASEIIF() 总结 前言 在…...

TypeScript 语言学习入门级教程五
在前面的教程中,我们已经逐步深入地学习了 TypeScript 的诸多特性,包括基础语法、类型系统、面向对象编程、装饰器以及一些高级类型等。在本教程中,我们将聚焦于 TypeScript 的模块系统、命名空间与模块的关系、声明文件以及如何在实际项目中…...
](https://towardsdatascience.com/the-ultimate-guide-to-finding-outliers-in-yo)
[寻找时间序列数据中异常值终极指南(第三部分)](https://towardsdatascience.com/the-ultimate-guide-to-finding-outliers-in-yo
原文:towardsdatascience.com/the-ultimate-guide-to-finding-outliers-in-your-time-series-data-part-3-0ff73ce28ca3...

Themes 与 Styles
Themes 与 Styles 主题目录:Source/Themes项目说明H.Theme主题核心。H.Themes.Colors.Accent强调色。H.Themes.Colors.Blue蓝色。H.Themes.Colors.Copper铜色/复古。H.Themes.Colors.Gray灰色。H.Themes.Colors.Industrial工业风。H.Themes.Colors.Mineral矿物色。H…...

文档下载神器kill-doc:如何一键拯救被平台困住的30+文档资源
文档下载神器kill-doc:如何一键拯救被平台困住的30文档资源 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是…...

免费解密网易云音乐NCM格式:ncmdumpGUI完整使用指南
免费解密网易云音乐NCM格式:ncmdumpGUI完整使用指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲ÿ…...

告别环境报错:用Docker 10分钟在本地/服务器部署YOLOv8完整开发环境
告别环境报错:用Docker 10分钟在本地/服务器部署YOLOv8完整开发环境 在计算机视觉领域,YOLOv8作为当前最先进的目标检测模型之一,其强大的性能和易用性吸引了大量开发者和研究者。然而,传统的手动搭建开发环境过程往往令人望而生畏…...

抖音直播弹幕实时采集:基于Golang的高性能解决方案
抖音直播弹幕实时采集:基于Golang的高性能解决方案 【免费下载链接】douyin-live-go 抖音(web) 弹幕爬虫 golang 实现 项目地址: https://gitcode.com/gh_mirrors/do/douyin-live-go 在直播电商和内容创作蓬勃发展的今天,实时获取抖音直播间的弹幕…...

告别传统测深方式,超声波测深仪优势大盘点
在水文勘测、河道治理、库区运维、水域环境监测工作中,水深测量是最基础也最关键的作业环节。以往很多工作人员依赖测深杆、测深锤等传统工具测深,不仅操作繁琐、作业效率低,人工读数还容易产生误差,遇到流动水域、深水区域更是作…...
)
为什么 HDFS 文件一旦写入就不能修改,只能追加或删除(HDFS 设计哲学:一次写入,多次读取)
HDFS采用"一次写入,多次读取"的设计哲学,不支持文件内容修改。这种设计通过简化数据一致性机制、提高吞吐量和优化批处理场景性能,实现了高效的大数据处理。虽然不能直接修改文件,但支持追加、删除和覆盖操作。Hive等工…...

2026年最新解答:天学网的英语听力对孩子真的有用吗?
作为在英语听力教研领域深耕5年的从业者,今年Q1刚做完一轮主流AI英语听力工具的横评,刚好结合实测数据和一线教学反馈来客观回答这个问题,没有广告,全是干货。先聊聊当前英语听力训练的共性痛点我们团队最近1年调研了30多所公立校…...

Excel怎么转PDF?2026年实用转换方法大盘点与官方转换指南
Excel 转 PDF 是日常办公中的常见需求。无论是要将数据表格转换为便于分享和打印的格式,还是需要生成最终报告,选择合适的转换方法能帮你节省时间。本文将为你盘点 Excel 转 PDF 的多种方法,从官方内置功能到在线工具再到专业转换小程序&…...