Hive分区表新增字段并指定位置
Hive分区表新增字段并指定位置
- 1、Hive分区表新增字段
- 2、CASCADE关键字
- 3、历史分区新增列为NULL问题
1、Hive分区表新增字段
Hive分区表新增字段并指定位置主要分为两步:新增字段和移动字段
1)新增字段
ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...) [CASCADE|RESTRICT];
该命令允许用户将新列添加到现有列的末尾但在分区列之前
ADD COLUMNS命令只修改Hive的元数据,不修改实际数据。用户应该确保表/分区的实际数据布局符合元数据定义
2)更改(移动)字段
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
该命令允许用户更改列的名称、数据类型、注释或位置,或它们的任意组合
CHANGE COLUMN命令只修改Hive的元数据,不修改实际数据。用户应该确保表/分区的实际数据布局符合元数据定义
以下是一些示例:
CREATE TABLE test_change (a int, b int, c int);// 将列a的名称更改为a1
ALTER TABLE test_change CHANGE a a1 INT;// 将列a1的名称更改为a2,数据类型更改为string,并将其放在列b后
ALTER TABLE test_change CHANGE a1 a2 STRING AFTER b;
// 新表的结构:b int, a2 string, c int// 将列c的名称更改为c1,并放在第一列
ALTER TABLE test_change CHANGE c c1 INT FIRST;
// 新表的结构:c1 int, b int, a2 string// 给列a1添加注释
ALTER TABLE test_change CHANGE a1 a1 INT COMMENT 'a1 comment';
2、CASCADE关键字
CASCADE中文为"级联",顾名思义就是有联系的。Hive官网对CASCADE关键字的描述如下:
CASCADE/RESTRICT子句在Hive 1.1.0中可用。CHANGE COLUMN CASCADE命令修改表元数据的列,并将相同的更改级联到所有分区元数据。RESTRICT是默认值,它只限制对表元数据的列更改
CHANGE COLUMN CASCADE子句将覆盖表分区的列元数据,而不管表或分区的保护模式如何,请谨慎使用
详情参考官网:https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=27362034#LanguageManualDDL-AlterColumn
什么意思呢?下面以一个示例演示不加CASCADE与添加CASCADE的区别
1)数据准备
create table test_cascade (id bigint, name string) partitioned by (dt string);
insert into table test_cascade partition (dt='2024-11-01') values (1, 'a');
insert into table test_cascade partition (dt='2024-12-01') values (2, 'b');
select * from test_cascade;
'''
id name dt
1 a 2024-11-01
2 b 2024-12-01
'''
2)不加CASCADE
alter table test_cascade add columns (age int);
insert into table test_cascade partition (dt='2024-11-01') values (1,'a',19);
insert into table test_cascade partition (dt='2024-12-01') values (2,'b',18);
insert into table test_cascade partition (dt='2025-01-01') values (3,'c',20);
select * from test_cascade;
'''
id name age dt
1 a NULL 2024-11-01
1 a NULL 2024-11-01
2 b NULL 2024-12-01
2 b NULL 2024-12-01
3 c 20 2025-01-01
'''
3)添加CASCADE
alter table test_cascade add columns (age int) cascade;
insert into table test_cascade partition (dt='2024-11-01') values (1,'a',19);
insert into table test_cascade partition (dt='2024-12-01') values (2,'b',18);
insert into table test_cascade partition (dt='2025-01-01') values (3,'c',18);
select * from test_cascade;
'''
id name age dt
1 a NULL 2024-11-01
1 a 19 2024-11-01
2 b NULL 2024-12-01
2 b 18 2024-12-01
3 c 20 2025-01-01
'''
据此,可得如下结论:
- 不加CASCADE:插入数据时,已存在数据的分区新增字段值为NULL,无数据的分区新增字段值可以插入成功
- 添加CASCADE:插入数据时,已存在数据的分区和无数据的分区新增字段值都可以插入成功
即就是,默认RESTRICT只变更新分区的表结构(新分区元数据),而CASCADE不仅变更新分区的表结构(新分区元数据),同时也级联变更旧分区的表结构(旧分区元数据)
3、历史分区新增列为NULL问题
实际应用中,通常会存在修改表结构的需求,例如,增加一个字段
如果使用如下语句新增列:
ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment]);
则可以成功添加列col_name,但如果数据表table_name中已有旧的分区,则该旧分区中的col_name将为NULL且无法更新,即使使用INSERT OVERWRITE也无效
出现这个问题的原因就是没有使用CASCADE关键字导致的。CASCADE不仅可以变更新分区的表结构(元数据),同时也会级联变更旧分区的表结构(元数据)
解决方法也很简单,只需要在原语句后面添加CASCADE关键字即可:
ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment]) CASCADE;
针对分区表新增字段不加CASCADE关键字时对于历史分区新插入的数据,新增的列数据都会显示为NULL,其它已有列的数据则显示正常
值得注意的是,如果还需要更改新增列的位置,也需要使用CASCADE关键字:
ALTER TABLE table_name CHANGE [COLUMN] col_name col_name data_type [COMMENT col_comment] AFTER column_name CASCADE;
另外,如果存储格式为Parquet,那么该新增列的数据都将为NULL,如果为TextFile格式,则不会出现这种情况
参考文章:https://blog.csdn.net/sx157559322/article/details/131950817
相关文章:

Hive分区表新增字段并指定位置
Hive分区表新增字段并指定位置 1、Hive分区表新增字段2、CASCADE关键字3、历史分区新增列为NULL问题 1、Hive分区表新增字段 Hive分区表新增字段并指定位置主要分为两步:新增字段和移动字段 1)新增字段 ALTER TABLE table_name ADD COLUMNS (col_name …...
与非关系型数据库(NoSQL)应用场景)
关系型数据库(RDBMS)与非关系型数据库(NoSQL)应用场景
关系型数据库适用于事务性、强一致性和结构化数据场景;非关系型数据库则在高并发、大数据、非结构化数据场景中表现更优;数据量和并发量增加时,应通过分库分表、缓存、集群扩展等手段进行优化。 1. 在什么样的业务场景下,你会优先…...

浅谈CI持续集成
1.什么是持续集成 持续集成(Continuous Integration)(CI)是一种软件开发实践,团队成员频繁地将他们的工作成果集成到一起(通常每人每天至少提交一次,这样每天就会有多次集成),并且在每次提交后…...

华为新手机和支付宝碰一下 带来更便捷支付体验
支付正在变的更简单。 11月26日,华为新品发布会引起众多关注。发布会上,华为常务董事余承东专门提到,华为Mate 70和Mate X6折叠屏手机的“独门支付秘技”——“碰一下”,并且表示经过华为和支付宝的共同优化,使用“碰…...

shell编程基础笔记
目录 echo改字体颜色和字体背景颜色 bash基本功能: 运行方式:推荐使用第二种方法 变量类型 字符串处理: 条件判断:(使用echo $?来判断条件结果,0为true,1为false) 条件语句&a…...

VS Code配置Lua调试环境
我这里选用Emmylua进行Lua代码调试,调试环境配置如下: 一、安装Emmylua 在VS Code扩展里搜索emmylua,然后进行安装, 如下 二、配置launch.json 在Run and Debug里生成launch.json文件 点击以上菜单后,生成launch.json文件如下: 三、配置.e…...

FPGA(一)Quartus II 13.1及modelsim与modelsim-altera安装教程及可能遇到的相关问题
零.前言 在学习FPGA课程时,感觉学校机房电脑用起来不是很方便,想着在自己电脑上下载一个Quartus II 来进行 基于 vhdl 语言的FPGA开发。原以为是一件很简单的事情,没想到搜了全网文章发现几乎没有一个完整且详细的流程教学安装(也…...

【单片机】ESP32-S3+多TMC2209控制步进电机系列1 UART通信及无传感回零 硬件部分
目录 1. 硬件选型1.1 esp32硬件型号1.2 TMC2209 硬件型号 2 原理接线图2.1 esp32接线2.2 TMC2209接线2.2.1 单向通讯 不配置地址2.2.2 单向通讯 配置地址2.2.3 双向通讯 单UART 【本文采用】2.2.4 双向通讯 多UART 3. 成品效果 1. 硬件选型 1.1 esp32硬件型号 采用的是微雪ES…...

Django之ORM
1.ORM介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。 简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对…...

html css 图片背景透明
html css图标背景透明 css属性: background-color:transparent; mix-blend-mode: multiply; 完整HTML代码: <html><head><title>Test</title></head><body><div id"test" style"background-col…...
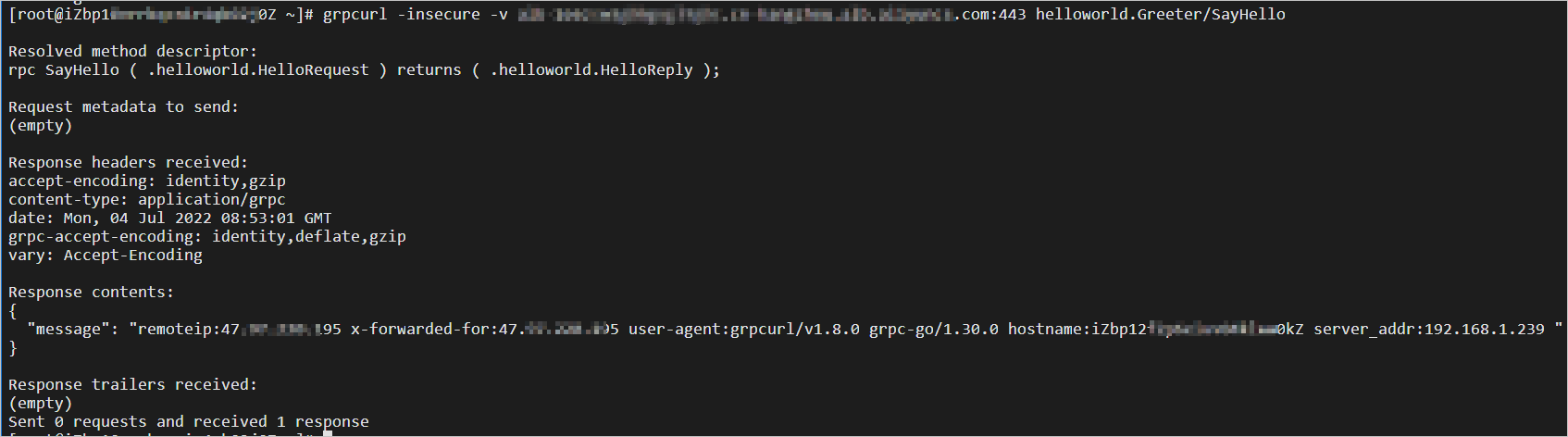
使用ALB实现gRPC协议的负载均衡
gRPC是一种高性能、开源的远程过程调用框架,当您使用gRPC进行后端服务通信时,您可使用应用型负载均衡ALB(Application Load Balancer)实现gRPC协议的负载均衡,统一流量入口。gRPC基于HTTP/2协议进行通信,目…...

解决IDEA的easycode插件生成的mapper.xml文件字段之间逗号丢失
问题 easycode插件生成的mapper.xml文件字段之间逗号丢失,如图 解决办法 将easycode(在settings里面的othersettings)设置里面的Template的mapper.xml.vm和Global Config的mybatisSupport.vm的所有$velocityHasNext换成$foreach.hasNext Template的mapper.xml.vm(…...

【Linux测试题】
1. 选择题 题目: 如果想将电脑中Windows C盘(hd1)安装在Linux文件系统的/winsys目录下,请问正确的命令是()。 选项: A. root104.123.123.123:~# mount dev/hd1 /winsys B. root104.123.123.12…...
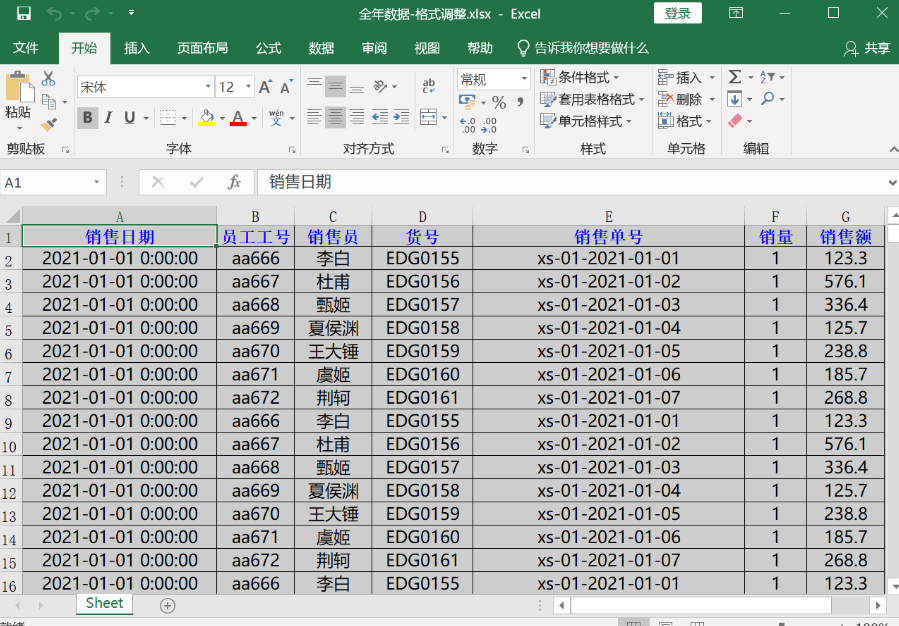
python使用openpyxl处理excel
文章目录 一、写在前面1、安装openpyxl2、认识excel窗口 二、基本使用1、打开excel2、获取sheet表格3、获取sheet表格 尺寸4、获取单元格数据5、获取区域单元格数据6、sheet.iter_rows()方法7、修改单元格的值8、向表格中插入行数据9、实战:合并多个excel 三、获取E…...

【JavaWeb后端学习笔记】Mybatis基础操作以及动态SQL(增、删、改、查)
Mybatis 0、环境准备0.1 准备数据库表emp;0.2 准备SpringBoot工程0.3 配置文件中引入数据库连接信息0.4 创建对应的实体类0.5 准备Mapper接口 1、MyBatis基础操作1.1 删除1.2 新增(主键返回)1.3 更新1.4 查询(解决字段名与类属性名…...
基于MATLAB野外观测站生态气象数据处理分析实践应用
1.本课程基于MATLAB语言 2.以实践案例为主,提供所有代码 3.原理与操作结合 4.布置作业,答疑与拓展 示意图: 以野外观测站高频时序生态气象数据为例,基于MATLAB开展上机操作: 1.不同生态气象要素文件的数据读写与批处理…...

IP 地理位置定位技术原理概述
本文深入探讨 IP 地理位置定位技术的原理。介绍了 IP 地址的基本概念及其在网络中的作用,随后阐述了基于数据库查询、基于网络拓扑分析以及基于机器学习算法的三种主要 IP 地理位置定位技术原理中的基于IP数据库查询。 IP 地址基础 IP 地址是互联网协议࿰…...
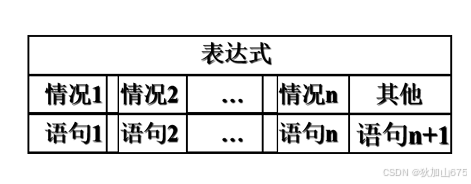
C语言(分支结构)
问题引出 我们在程序设计往往会遇到如下的问题,比如下的函数的计算。 也就是我们是必须要通过一个条件的结果来选择下一步的操作,算法上属于一个分支结构,C语言中实现分支结构主要使用if语句。 条件判断 根据某个条件成立与否,…...

批量将不同的工作簿合并到同一个Excel文件
批量将不同的工作簿合并到同一个Excel文件 下面是一个示例,展示如何批量将不同的工作簿合并到同一个Excel文件,并生成模拟数据。我们将使用 Python 的 pandas 库来完成这个任务。具体步骤如下: 步骤 1: 安装必要的库 首先确保你已安装 pan…...

详解AI网关助力配电房实现智能化管控应用
对于一些建设年份久远的老旧配电房,由于配套降温散热设施设备不完善、线路设备老化等因素,极易出现因环境过热而影响设备正常稳定运行,进而导致电气故障甚至火灾等事故产生。 基于AI网关的配电房智能监控及管理 针对配电房的实时安全监测及…...

从《魔兽世界》到你的项目:深入拆解Recast导航网格生成与优化的全流程
从《魔兽世界》到现代项目:Recast导航网格技术的深度实践指南 1. 导航网格技术的演进与核心价值 2004年《魔兽世界》的发布不仅是MMO游戏史上的里程碑,更悄然改变了游戏AI寻路技术的演进轨迹。当数百万玩家在艾泽拉斯大陆自由探索时,鲜少有人…...

G-Helper终极指南:3分钟告别Armoury Crate臃肿,释放华硕笔记本真正性能
G-Helper终极指南:3分钟告别Armoury Crate臃肿,释放华硕笔记本真正性能 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, Pr…...

5种文本切块策略大解析:从字符到语义,打造高效检索系统!
文本切块是构建向量索引前的重要环节,避免语义切断和检索效果冲淡。文章详细解析了五种常见切块策略:按字符长度切分、按Token长度切分、按句子语义切分、按段落结构切分(含默认语法和自定义语法)以及混合方式切分。每种策略都有其…...

用Rsoft DiffractionMOD给光伏减反膜‘算个命’:手把手教你仿真矩形光栅的反射谱
用Rsoft DiffractionMOD给光伏减反膜‘算个命’:手把手教你仿真矩形光栅的反射谱 在光伏组件研发中,减反射膜的性能直接影响着光电转换效率。传统试错法需要反复镀膜测试,成本高周期长。本文将演示如何通过Rsoft DiffractionMOD模块ÿ…...

告别时序警告!手把手教你为Vivado自定义分频器添加正确时钟约束
深度解析Vivado分频器时钟约束:从原理到实战的全链路指南 在FPGA开发中,时钟管理是确保设计稳定性的核心环节。当我们面对低频应用场景时,常常需要将高频系统时钟分频至工作频率,而Vivado工具链对这类自定义分频器的时序约束有着特…...

sleek开发者指南:基于Electron+React的现代桌面应用架构
sleek开发者指南:基于ElectronReact的现代桌面应用架构 【免费下载链接】sleek todo.txt manager for Linux, Windows and MacOS, free and open-source (FOSS) 项目地址: https://gitcode.com/gh_mirrors/sl/sleek sleek是一款跨平台的todo.txt管理器&#…...

C51结构体内存分配限制与解决方案
1. C51结构体成员的内存空间限制解析在8051单片机开发中,C51编译器对结构体成员的内存分配有着严格限制。这个问题困扰过不少从标准C转向嵌入式开发的工程师。让我用一个实际案例来解释这个技术细节:struct sensor_data {float data temperature; // 试…...

Jenkins 安装Publish over SSH插件远程发布执行shell脚本
1.在jenkins安装Publish over SSH插件,在Manage Jenkins–Plugins–Available plugins中搜索Publish over SSH,然后安装即可。2.安装成功以后,需要到系统设置DashBoard—Manage Jenkins—System中进行配置,如图 可以通过密码链接也…...

深入了解Linux命名空间的cgroups:打开容器技术的黑匣子
cgroups,全称为 Control Groups,是 Linux 内核提供的一种强大的资源管理机制。它的核心作用是将一组进程(tasks)组织成一个层级化的组,并为这些组分配、限制和监控资源的使用情况。 简单来说,cgroups 允许系…...

STM32F103C8T6 Bootloader分区与跳转详解:手把手配置64KB Flash的16+48分配方案
STM32F103C8T6 Bootloader分区与跳转实战:64KB Flash的1648分配方案深度解析 在嵌入式开发中,Bootloader的设计往往是项目成败的关键一环。对于资源受限的STM32F103C8T6这类仅有64KB Flash的MCU来说,如何在Bootloader和应用程序之间合理分配这…...