【JavaWeb后端学习笔记】MySQL的数据查询语言(Data Query Language,DQL)
MySQL DQL
- 1、DQL语法与数据准备
- 1.1 DQL语法
- 1.2 数据准备
- 2、基础查询
- 2.1 查询指定字段
- 2.2 查询返回所有字段
- 2.3 给查询结果起别名
- 2.4 去除重复记录
- 3、条件查询
- 3.1 条件查询语法
- 3.2 条件查询案例分析
- 4、分组查询
- 4.1 分组查询语法
- 4.2 分组查询案例分析
- 5、排序查询
- 5.1 排序查询语法
- 5.2 排序查询案例分析
- 6、分页查询
- 6.1 分页查询语法
- 6.2 分页查询案例分析
1、DQL语法与数据准备
1.1 DQL语法
MySQL的数据查询语言(Data Query Language,DQL)用于查询数据库中表的记录,是MySQL中最常用的部分。
DQL语法的总体结构如下:
select字段列表
from表名列表
where条件列表
group by分组字段列表
having分组后条件列表
order by排序字段列表
limit分页参数
与DDL、DML相比,DQL最为复杂。为满足不同的查询条件和查询数据的需求,DQL可分为:
- 基本查询
- 条件查询(where)
- 分组查询(group by)
- 排序查询(order by)
- 分页查询(limit)
1.2 数据准备
本文案例所需资料获取链接(来自黑马程序员):百度网盘链接:fttx
下载百度网盘中提供的SQL脚本,将DQL-数据准备.sql中的代码复制粘贴到IDEA中运行,得到数据库表以及表中的内容。后续基于这些数据进行实例分析。

2、基础查询
2.1 查询指定字段
查询指定字段 name,entrydate 并返回。
-- 1. 查询指定字段 name,entrydate 并返回
select name, entrydate from tb_emp;
查询结果:

2.2 查询返回所有字段
查询返回所有字段,可以列出所有的字段,也可以使用通配符。
-- 2. 查询返回所有字段
-- 列出所有字段(推荐)
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp;-- 使用通配符(不推荐,不直观,性能低)
select * from tb_emp;
查询结果:

2.3 给查询结果起别名
使用 as 关键字给查询结果取别名。
查询所有员工的 name,entrydate, 并起别名(姓名、入职日期)
-- 3. 查询所有员工的 name,entrydate, 并起别名(姓名、入职日期)
select name as "姓名", entrydate as "入职日期" from tb_emp;
查询结果:

2.4 去除重复记录
查询已有的员工关联了哪几种职位(不要重复)。
使用distinct可以去除重复记录,还有一种方式是使用group by。
// distinct去除重复记录
select distinct job from tb_emp;
// group by分组去除重复记录
select job from tb_emp group by job;
查询结果:

3、条件查询
3.1 条件查询语法
条件查询语法
select 字段列表 from 表名 where 条件列表;
条件列表中包含多种运算:
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <>或!= | 不等于 |
| between…and… | 在某个范围之内(含最小、最大值) |
| in(…) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(_匹配单个字符,%匹配任意个字符) |
| is null | 是null |
| 逻辑运算符 | 功能 |
| and 或 && | 并且(多个条件同时成立) |
| or 或 || | 或者(多个条件任意一个成立) |
| not 或 ! | 非,不是 |
3.2 条件查询案例分析
-- 1. 查询 姓名 为 杨逍 的员工
-- 通过 "=" 指定姓名为 "杨逍" 的员工
select * from tb_emp where name = '杨逍';-- 2. 查询 id小于等于5 的员工信息
-- 设置查询条件 id <= 5
select * from tb_emp where id <= 5;-- 3. 查询 没有分配职位 的员工信息
-- 没有分配职位的员工 job 字段为 null
select * from tb_emp where job is null;-- 4. 查询 有职位 的员工信息
-- 有职位的员工 job 字段非空
select * from tb_emp where job is not null;-- 5. 查询 密码不等于 '123456' 的员工信息
-- 不等于运算符为 "!=" 或者 "<>"
select * from tb_emp where password != '123456';
select * from tb_emp where password <> '123456';-- 6. 查询 入职日期 在 '2000-01-01' (包含) 到 '2010-01-01'(包含) 之间的员工信息
-- 查询一个范围内的条件可以使用 between...and... 或者 >= <= 配合使用
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01';
select * from tb_emp where entrydate >= '2000-01-01' and entrydate <= '2010-01-01';-- 7. 查询 入职时间 在 '2000-01-01' (包含) 到 '2010-01-01'(包含) 之间 且 性别为女 的员工信息
-- 条件列表中有多个条件,使用 "and" 或者 "or" 或者 "&&" 或者 "||" 连接
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' and gender = 2;
select * from tb_emp where entrydate >= '2000-01-01' and entrydate <= '2010-01-01' and gender = 2;-- 8. 查询 职位是 2 (讲师), 3 (学工主管), 4 (教研主管) 的员工信息
-- 查询条件是一个列表,可以使用 in(...)
select * from tb_emp where job in (2,3,4);-- 9. 查询 姓名 为两个字的员工信息
-- 指定一个字段的长度,可以使用占位符 "_",如果长度未知,可以使用"%"匹配任意长度
select * from tb_emp where name like '__'; -- _ 表示一个字符的占位符-- 10. 查询 姓 '张' 的员工信息
-- 占位符 "%" 匹配任意长度
select * from tb_emp where name like '张%';
4、分组查询
4.1 分组查询语法
分组查询语法:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];
where和having的区别:
- 执行机制不同:where是分组之前进行过滤,不满足where条件,不参与分组;having是分组后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以用聚合函数。
注意事项:
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
- 执行顺序:where > 聚合函数 > having。
- null值不参与任何聚合函数计算。
常用的聚合函数:
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值(求指定字段的最大值) |
| min | 最小值(求指定字段的最小值) |
| avg | 平均值(求指定字段的平均值) |
| sum | 求和(求指定字段的和) |
4.2 分组查询案例分析
-- 聚合函数
-- 1. 统计该企业员工数量
-- 使用count聚合函数统计数量,有三种使用方式
select count(*) as 员工数量 from tb_emp; -- count(*) (推荐)
select count(name) as 员工数量 from tb_emp; -- count(字段)
select count(5) as 员工数量 from tb_emp; -- count(常量)-- 2. 统计该企业员工 ID 的平均值
-- 统计字段平均值使用avg函数
select avg(id) from tb_emp;-- 3. 统计该企业最早入职的员工
-- 统计字段最小值使用min函数,这里where条件中返回了一个子表
select * from tb_emp where entrydate = (select min(entrydate) from tb_emp);-- 4. 统计该企业最迟入职的员工
-- 统计字段最大值使用max函数
select * from tb_emp where entrydate = (select max(entrydate) from tb_emp);-- 5. 统计该企业员工的 ID 之和
-- -- 统计字段和使用sum函数
select sum(id) from tb_emp;-- 分组
-- 1. 根据性别分组 , 统计男性和女性员工的数量
-- 使用 group by 对性别分组,再返回性别以及对应的数量
select gender as 性别, count(*) 数量 from tb_emp group by gender;-- 3. 先查询入职时间在 '2015-01-01' (包含) 以前的员工 , 并对结果根据职位分组 , 获取员工数量大于等于2的职位
-- 使用 group by 对职位分组,通过 having 过滤掉 人数少于 2 的职位,最后返回职位已经剩余人数
select job as 职位, count(*) as 数量 from tb_emp where entrydate <= '2015-01-01' group by job having count(job) >= 2;
5、排序查询
5.1 排序查询语法
排序查询语法:
select 字段列表 from 表名 [where 条件列表] [group by 分组字段] order by 字段1 排序方式1,字段2 排序方式2,...;
排序方式有两种:
· ASC:升序(默认值)
· DESC:降序
注意:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
5.2 排序查询案例分析
-- 1. 根据入职时间, 对员工进行升序排序
select * from tb_emp order by entrydate asc ;
select * from tb_emp order by entrydate ; -- 默认排序方式为升序,asc可省-- 2. 根据入职时间, 对员工进行降序排序
select * from tb_emp order by entrydate desc ;-- 3. 根据 入职时间 对公司的员工进行 升序排序,入职时间相同,再按照 更新时间 进行降序排序
select * from tb_emp order by entrydate asc , update_time desc ;
6、分页查询
6.1 分页查询语法
select 字段列表 from 表名 limit 起始索引,查询记录数;
MySQL的索引是从 0 开始。
假设要查第 n 页,每页展示 m 条数据,通过公式可计算:
起始索引 = ( n - 1 ) * m;
查询记录数 = m;
6.2 分页查询案例分析
分页查询较为简单。
-- 1. 从起始索引0开始查询员工数据, 每页展示5条记录
select * from tb_emp limit 0, 5;-- 2. 查询 第1页 员工数据, 每页展示5条记录
select * from tb_emp limit 0, 5;-- 3. 查询 第2页 员工数据, 每页展示5条记录
select * from tb_emp limit 5, 5;-- 4. 查询 第3页 员工数据, 每页展示5条记录
select * from tb_emp limit 10, 5;
相关文章:
【JavaWeb后端学习笔记】MySQL的数据查询语言(Data Query Language,DQL)
MySQL DQL 1、DQL语法与数据准备1.1 DQL语法1.2 数据准备 2、基础查询2.1 查询指定字段2.2 查询返回所有字段2.3 给查询结果起别名2.4 去除重复记录 3、条件查询3.1 条件查询语法3.2 条件查询案例分析 4、分组查询4.1 分组查询语法4.2 分组查询案例分析 5、排序查询5.1 排序查询…...

360 最新Android面试题及参考答案
一个 activity 只能有一个进程么【对进程的理解】 在 Android 中,一个 Activity 并不只能有一个进程。进程是操作系统进行资源分配和调度的一个独立单位。 从原理上来说,Android 系统允许开发者通过在 AndroidManifest.xml 文件中的<activity>标签设置 android:process…...

《操作系统 - 清华大学》6 -3:局部页面置换算法:最近最久未使用算法 (LRU, Least Recently Used)
文章目录 1. 最近最久未使用算法的工作原理2. 最近最久未使用算法示例3.LRU算法实现3.1 LRU的页面链表实现3.2 LRU的活动页面栈实现3.3 链表实现 VS 堆栈实现 1. 最近最久未使用算法的工作原理 最近最久未使用页面置换算法,简称 LRU, 算法思路ÿ…...
)
ES6新增了哪些特性(待更新)
1.let,const 1.1.var,let,const的区别 1.1.1 var存在变量提升,let和const不存在。 1.1.2 let和const只能在块作用域里访问。 1.1.3 同一作用域下let和const不能声明同名变量,而var可以。 1.1.4 const定义常量&am…...

剖析一下自己的简历第二条
剖析一下自己的简历第二条 背景前置说明可能会被问到的问题 背景 剖析一下自己简历, 增加对一些专业知识的掌握. 我的简历第二条是这样写的: “2. 熟悉JVM、JMM,包括内存模型,垃圾回收机制,了解其基本调优技巧并具备线上调优经验。”. 前置…...

威联通-001 手机相册备份
文章目录 前言1.Qfile Pro2.Qsync Pro总结 前言 威联通有两种数据备份手段:1.Qfile Pro和2.Qsync Pro,实践使用中存在一些区别,针对不同备份环境选择是不同。 1.Qfile Pro 用来备份制定目录内容的。 2.Qsync Pro 主要用来查看和操作文…...

性能测试基础知识jmeter使用
博客主页:花果山~程序猿-CSDN博客 文章分栏:测试_花果山~程序猿的博客-CSDN博客 关注我一起学习,一起进步,一起探索编程的无限可能吧!让我们一起努力,一起成长! 目录 性能指标 1. 并发数 (Con…...

Ceph文件存储
Ceph文件存储1.概念:数据以文件的形式存储在存储介质上,每个文件都有一个唯一的文件名并存储在一个目录结构中。提供方便的文件访问接口,支持多种文件操作,如创建、删除、读取、写入、复制等。用于存储和管理个人文件,如文档、图片…...

Hive分区表新增字段并指定位置
Hive分区表新增字段并指定位置 1、Hive分区表新增字段2、CASCADE关键字3、历史分区新增列为NULL问题 1、Hive分区表新增字段 Hive分区表新增字段并指定位置主要分为两步:新增字段和移动字段 1)新增字段 ALTER TABLE table_name ADD COLUMNS (col_name …...
与非关系型数据库(NoSQL)应用场景)
关系型数据库(RDBMS)与非关系型数据库(NoSQL)应用场景
关系型数据库适用于事务性、强一致性和结构化数据场景;非关系型数据库则在高并发、大数据、非结构化数据场景中表现更优;数据量和并发量增加时,应通过分库分表、缓存、集群扩展等手段进行优化。 1. 在什么样的业务场景下,你会优先…...

浅谈CI持续集成
1.什么是持续集成 持续集成(Continuous Integration)(CI)是一种软件开发实践,团队成员频繁地将他们的工作成果集成到一起(通常每人每天至少提交一次,这样每天就会有多次集成),并且在每次提交后…...

华为新手机和支付宝碰一下 带来更便捷支付体验
支付正在变的更简单。 11月26日,华为新品发布会引起众多关注。发布会上,华为常务董事余承东专门提到,华为Mate 70和Mate X6折叠屏手机的“独门支付秘技”——“碰一下”,并且表示经过华为和支付宝的共同优化,使用“碰…...

shell编程基础笔记
目录 echo改字体颜色和字体背景颜色 bash基本功能: 运行方式:推荐使用第二种方法 变量类型 字符串处理: 条件判断:(使用echo $?来判断条件结果,0为true,1为false) 条件语句&a…...

VS Code配置Lua调试环境
我这里选用Emmylua进行Lua代码调试,调试环境配置如下: 一、安装Emmylua 在VS Code扩展里搜索emmylua,然后进行安装, 如下 二、配置launch.json 在Run and Debug里生成launch.json文件 点击以上菜单后,生成launch.json文件如下: 三、配置.e…...

FPGA(一)Quartus II 13.1及modelsim与modelsim-altera安装教程及可能遇到的相关问题
零.前言 在学习FPGA课程时,感觉学校机房电脑用起来不是很方便,想着在自己电脑上下载一个Quartus II 来进行 基于 vhdl 语言的FPGA开发。原以为是一件很简单的事情,没想到搜了全网文章发现几乎没有一个完整且详细的流程教学安装(也…...

【单片机】ESP32-S3+多TMC2209控制步进电机系列1 UART通信及无传感回零 硬件部分
目录 1. 硬件选型1.1 esp32硬件型号1.2 TMC2209 硬件型号 2 原理接线图2.1 esp32接线2.2 TMC2209接线2.2.1 单向通讯 不配置地址2.2.2 单向通讯 配置地址2.2.3 双向通讯 单UART 【本文采用】2.2.4 双向通讯 多UART 3. 成品效果 1. 硬件选型 1.1 esp32硬件型号 采用的是微雪ES…...

Django之ORM
1.ORM介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。 简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对…...

html css 图片背景透明
html css图标背景透明 css属性: background-color:transparent; mix-blend-mode: multiply; 完整HTML代码: <html><head><title>Test</title></head><body><div id"test" style"background-col…...
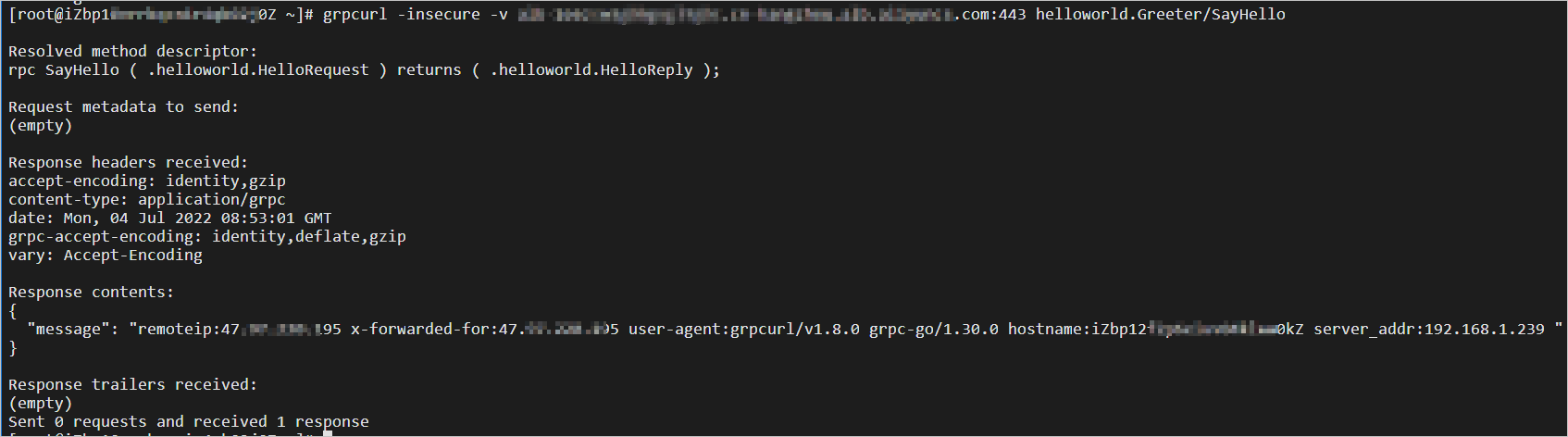
使用ALB实现gRPC协议的负载均衡
gRPC是一种高性能、开源的远程过程调用框架,当您使用gRPC进行后端服务通信时,您可使用应用型负载均衡ALB(Application Load Balancer)实现gRPC协议的负载均衡,统一流量入口。gRPC基于HTTP/2协议进行通信,目…...

解决IDEA的easycode插件生成的mapper.xml文件字段之间逗号丢失
问题 easycode插件生成的mapper.xml文件字段之间逗号丢失,如图 解决办法 将easycode(在settings里面的othersettings)设置里面的Template的mapper.xml.vm和Global Config的mybatisSupport.vm的所有$velocityHasNext换成$foreach.hasNext Template的mapper.xml.vm(…...

如何彻底解决《神界:原罪2》模组冲突问题:Divinity Mod Manager 专业指南
如何彻底解决《神界:原罪2》模组冲突问题:Divinity Mod Manager 专业指南 【免费下载链接】DivinityModManager A mod manager for Divinity: Original Sin - Definitive Edition. 项目地址: https://gitcode.com/gh_mirrors/di/DivinityModManager …...

抖音无水印视频下载技术深度解析:双架构设计与性能优化方案
抖音无水印视频下载技术深度解析:双架构设计与性能优化方案 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downloader 抖音无…...
)
别再只烧SD卡了!IMX6ULL的BOOT_CFG引脚配置详解(附正点原子核心板电路图)
IMX6ULL启动配置全解析:从BOOT_CFG引脚到多介质启动实战 当你在深夜调试IMX6ULL开发板时,是否遇到过这样的困境——明明按照教程操作,系统却始终无法从EMMC启动?问题的根源往往藏在那些容易被忽略的硬件细节中。今天,我…...

体验Taotoken多模型路由带来的高稳定性与低延迟响应
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken多模型路由带来的高稳定性与低延迟响应 在构建依赖大模型能力的应用时,开发者最关心的两个核心指标往往是…...

基于STM32MP25x构建工业级嵌入式Linux平台:Debian、XFCE、VNC与TSN集成实践
1. 项目概述:一个面向工业边缘的“全能”嵌入式Linux平台最近,我们团队基于STM32MP25x系列核心板,成功构建并发布了一套完整的Debian系统镜像。这个项目的目标非常明确:打造一个开箱即用、功能全面且高度适配工业边缘计算场景的嵌…...
)
用emWin定时器给你的STM32 GUI界面“注入灵魂”:实现动态数据刷新与简易动画(基于WM_TIMER消息)
用emWin定时器为STM32 GUI注入动态交互的灵魂 在嵌入式设备的人机交互设计中,静态界面往往给人呆板的印象。想象一下工业仪表盘上凝固的数字,或是医疗设备上永不变化的指示灯——这种缺乏生命力的呈现方式不仅降低用户体验,还可能掩盖关键数据…...

3分钟搞定B站缓存视频转换:m4s-converter无损合并完整指南
3分钟搞定B站缓存视频转换:m4s-converter无损合并完整指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经遇到过这样的情…...

3种高效方案解析:如何深度还原微信小程序源代码结构
3种高效方案解析:如何深度还原微信小程序源代码结构 【免费下载链接】wxappUnpacker forked from https://github.com/qwerty472123/wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 你是否曾面对一个加密的微信小程序包&…...

Android Studio中文界面完整汉化指南:三步打造母语开发环境
Android Studio中文界面完整汉化指南:三步打造母语开发环境 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为And…...

快速解密QQ音乐加密文件:qmc-decoder完整指南
快速解密QQ音乐加密文件:qmc-decoder完整指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 还在为QQ音乐下载的.qmc、.qmc3、.qmcflac格式文件无法在其他播放…...