推荐学习笔记:矩阵补充和矩阵分解
参考:
召回
fun-rec/docs/ch02/ch2.1/ch2.1.1/mf.md at master · datawhalechina/fun-rec · GitHub

业务

隐语义模型与矩阵分解
协同过滤算法的特点:
- 协同过滤算法的特点就是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,是一个可解释性很强, 非常直观的模型。
- 但是也存在一些问题,处理稀疏矩阵的能力比较弱。
为了使得协同过滤更好处理稀疏矩阵问题, 增强泛化能力。从协同过滤中衍生出矩阵分解模型(Matrix Factorization, MF)或者叫隐语义模型:
- 在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品。
- 通过挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
近似最近邻查找
- 支持最近邻查找的系统
- 系统:Milvus、Faiss、HnswLib、等等
- 快速最近邻查找的算法已经被集成到这些系统中
- 衡量最近邻的标准:
- 欧式距离最小(L2 距离)
- 向量内积最大(内积相似度)
- 矩阵补充用的就是内积相似度
- 向量夹角余弦最大(cosine 相似度)
- 最常用
- 对于不支持的系统:把所有向量作归一化(让它们的二范数等于 1),此时内积就等于余弦相似度
音乐评分实例
假设每个用户都有自己的听歌偏好, 比如用户 A 喜欢带有小清新的, 吉他伴奏的, 王菲的歌曲,如果一首歌正好是王菲唱的, 并且是吉他伴奏的小清新, 那么就可以将这首歌推荐给这个用户。 也就是说是小清新, 吉他伴奏, 王菲这些元素连接起了用户和歌曲。
当然每个用户对不同的元素偏好不同, 每首歌包含的元素也不一样, 所以我们就希望找到下面的两个矩阵:
- 潜在因子—— 用户矩阵Q 这个矩阵表示不同用户对于不同元素的偏好程度, 1代表很喜欢, 0代表不喜欢, 比如下面这样:
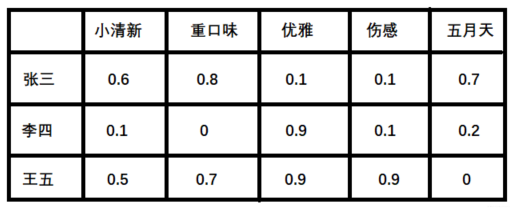
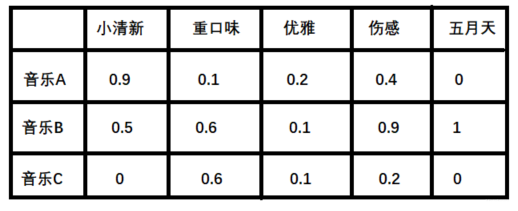
2. 潜在因子——音乐矩阵P 表示每种音乐含有各种元素的成分, 比如下表中, 音乐A是一个偏小清新的音乐, 含有小清新的Latent Factor的成分是0.9, 重口味的成分是0.1, 优雅成分0.2...
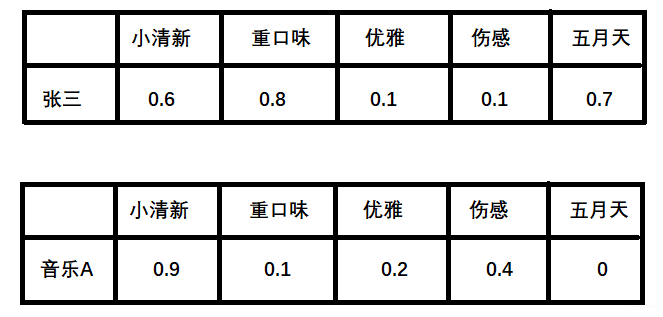
**计算张三对音乐A的喜爱程度**
利用上面的这两个矩阵,将对应向量进行内积计算,我们就能得出张三对音乐A的喜欢程度:
-
张三对小清新的偏好 * 音乐A含有小清新的成分 + 张三对重口味的偏好 * 音乐A含有重口味的成分 + 张三对优雅的偏好 * 音乐A含有优雅的成分...
-
根据隐向量其实就可以得到张三对音乐A的打分,使用内积相似度:
0.6∗0.9+0.8∗0.1+0.1∗0.2+0.1∗0.4+0.7∗0=0.680.6∗0.9+0.8∗0.1+0.1∗0.2+0.1∗0.4+0.7∗0=0.68
计算所有用户对不同音乐的喜爱程度
按照这个计算方式, 每个用户对每首歌其实都可以得到这样的分数, 最后就得到了我们的评分矩阵:
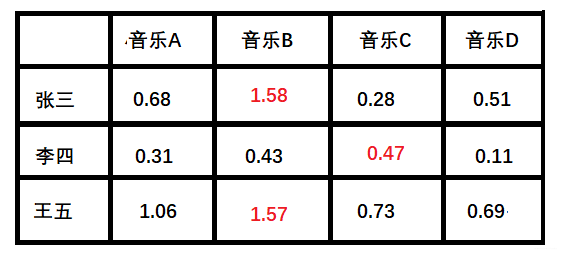
+ 红色部分表示用户没有打分,可以通过隐向量计算得到的。
小结
-
上面例子中的小清晰, 重口味, 优雅这些就可以看做是隐含特征, 而通过这个隐含特征就可以把用户的兴趣和音乐的进行一个分类, 其实就是找到了每个用户每个音乐的一个隐向量表达形式(与深度学习中的embedding等价)
-
这个隐向量就可以反映出用户的兴趣和物品的风格,并能将相似的物品推荐给相似的用户等。 有没有感觉到是把协同过滤算法进行了一种延伸, 把用户的相似性和物品的相似性通过了一个叫做隐向量的方式进行表达
-
现实中,类似于上述的矩阵 P,QP,Q 一般很难获得。有的只是用户的评分矩阵,如下:
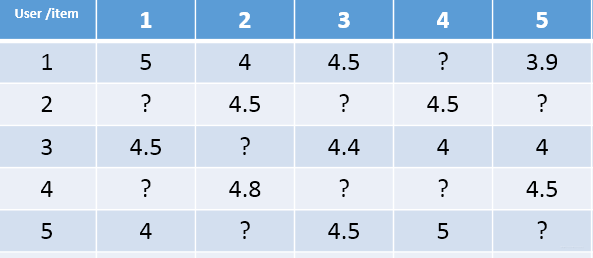
- 这种矩阵非常的稀疏,如果直接基于用户相似性或者物品相似性去填充这个矩阵是不太容易的。
- 并且很容易出现长尾问题, 而矩阵分解就可以比较容易的解决这个问题。
-
矩阵分解模型:
- 基于评分矩阵,将其分解成Q和P两个矩阵乘积的形式,获取用户兴趣和物品的隐向量表达。
- 然后,基于两个分解矩阵去预测某个用户对某个物品的评分了。
- 最后,基于预测评分去进行物品推荐。
编程实现

import random
import mathclass BiasSVD():def __init__(self, rating_data, F=5, alpha=0.1, lmbda=0.1, max_iter=100):self.F = F # 这个表示隐向量的维度self.P = dict() # 用户矩阵P 大小是[users_num, F]self.Q = dict() # 物品矩阵Q 大小是[item_nums, F]self.bu = dict() # 用户偏置系数self.bi = dict() # 物品偏置系数self.mu = 0 # 全局偏置系数self.alpha = alpha # 学习率self.lmbda = lmbda # 正则项系数self.max_iter = max_iter # 最大迭代次数self.rating_data = rating_data # 评分矩阵for user, items in self.rating_data.items():# 初始化矩阵P和Q, 随机数需要和1/sqrt(F)成正比self.P[user] = [random.random() / math.sqrt(self.F) for x in range(0, F)]self.bu[user] = 0for item, rating in items.items():if item not in self.Q:self.Q[item] = [random.random() / math.sqrt(self.F) for x in range(0, F)]self.bi[item] = 0# 采用随机梯度下降的方式训练模型参数def train(self):cnt, mu_sum = 0, 0for user, items in self.rating_data.items():for item, rui in items.items():mu_sum, cnt = mu_sum + rui, cnt + 1self.mu = mu_sum / cntfor step in range(self.max_iter):# 遍历所有的用户及历史交互物品for user, items in self.rating_data.items():# 遍历历史交互物品for item, rui in items.items():rhat_ui = self.predict(user, item) # 评分预测e_ui = rui - rhat_ui # 评分预测偏差# 参数更新self.bu[user] += self.alpha * (e_ui - self.lmbda * self.bu[user])self.bi[item] += self.alpha * (e_ui - self.lmbda * self.bi[item])for k in range(0, self.F):self.P[user][k] += self.alpha * (e_ui * self.Q[item][k] - self.lmbda * self.P[user][k])self.Q[item][k] += self.alpha * (e_ui * self.P[user][k] - self.lmbda * self.Q[item][k])# 逐步降低学习率self.alpha *= 0.1# 评分预测def predict(self, user, item):return sum(self.P[user][f] * self.Q[item][f] for f in range(0, self.F)) + self.bu[user] + self.bi[item] + self.mu# 通过字典初始化训练样本,分别表示不同用户(1-5)对不同物品(A-E)的真实评分
def loadData():rating_data={1: {'A': 5, 'B': 3, 'C': 4, 'D': 4},2: {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},3: {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},4: {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},5: {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}}return rating_data# 加载数据
rating_data = loadData()
# 建立模型
basicsvd = BiasSVD(rating_data, F=10)
# 参数训练
basicsvd.train()
# 预测用户1对物品E的评分
for item in ['E']:print(item, basicsvd.predict(1, item))# 预测结果:E 3.685084274454321梯度下降推导



相关文章:
推荐学习笔记:矩阵补充和矩阵分解
参考: 召回 fun-rec/docs/ch02/ch2.1/ch2.1.1/mf.md at master datawhalechina/fun-rec GitHub 业务 隐语义模型与矩阵分解 协同过滤算法的特点: 协同过滤算法的特点就是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与…...

etcd分布式存储系统快速入门指南
在分布式系统的复杂世界中,确保有效的数据管理至关重要。分布式可靠的键值存储在维护跨分布式环境的数据一致性和可伸缩性方面起着关键作用。 在这个全面的教程中,我们将深入研究etcd,这是一个开源的分布式键值存储。我们将探索其基本概念、特…...

解决VUE3 Vite打包后动态图片资源不显示问题
解决VUE3 Vite打包后动态图片资源不显示问题 <script setup> let url ref()const setimg (item)>{let src ../assets/image/${e}.pngurl.value src }</script><template><div v-for"item in 6"><h1 click"setimg(item)"…...

大数据新视界 -- 大数据大厂之 Hive 临时表与视图:灵活数据处理的技巧(上)(29 / 30)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

Android学习14--charger
1 概述 最近正好在做关机充电这个,就详细看看吧。还是本着保密的原则,项目里的代码也不能直接用,这里就用的Github的。https://github.com/aosp-mirror 具体位置是:https://github.com/aosp-mirror/platform_system_core/tree/mai…...

页面开发样式和布局入门:Vite + Vue 3 + Less
页面开发样式和布局入门:Vite Vue 3 Less 引言 在现代前端开发中,样式和布局是页面开发的核心部分。随着技术的不断发展,Vite、Vue 3和Less等工具和框架的出现,使得前端开发变得更加高效和灵活。然而,尽管这些工具…...

瑞芯微RK3566/RK3568开发板安卓11固件ROOT教程,Purple Pi OH演示
本文介绍RK3566/RK3568开发板Android11系统,编译ROOT权限固件的方法。触觉智能Purple Pi OH鸿蒙开发板演示,搭载了瑞芯微RK3566四核处理器,Laval鸿蒙社区推荐开发板,已适配全新OpenHarmony5.0 Release系统,SDK源码全开…...

Netty 入门应用:结合 Redis 实现服务器通信
在上篇博客中,我们了解了 Netty 的基本概念和架构。本篇文章将带你深入实践,构建一个简单的 Netty 服务端,并结合 Redis 实现一个数据存取的示例。在这个场景中,Redis 作为缓存存储,Netty 作为服务端处理客户端请求。通…...

试题转excel;pdf转excel;试卷转Excel,word试题转excel
一、问题描述 一名教师朋友,偶尔会需要整理一些高质量的题目到excel中 以往都是手动复制搬运,几百道题几乎需要一个下午的时间 关键这些事,枯燥无聊费眼睛,实在是看起来就很蠢的工作 就想着做一个工具,可以自动处理…...

查看网卡设备Bus号
在Linux系统中,通过ip命令能够看到网卡设备的名称,那么怎么看这个网卡设备对应的硬件设备以及Bus号? 例如在下面的虚拟机中能够看到有一个网口名为enp1s0 如何查看这个设备对应的Bus编号,可以在/sys中找到对应的设备 ll /sys/cl…...

鸿蒙Next星河版高级用例之网络请求和自适应布局以及响应式布局
目录: 1、发起网络请求的两种方式第一种使用httpRequest发送http的请求:1.1、在进行网络请求前,您需要在module.json5文件中申明网络访问权限1.2、GET 请求1.3、POST请求1.4、处理响应的结果第二种使用axios发送http的请求:1.1、在…...
...)
鸿蒙技术分享:敲鸿蒙木鱼,积____功德——鸿蒙元服务开发:从入门到放弃(3)...
本文是系列文章,其他文章见:敲鸿蒙木鱼,积____功德🐶🐶🐶——鸿蒙元服务开发:从入门到放弃(1)敲鸿蒙木鱼,积____功德🐶🐶🐶——鸿蒙元服务开发&am…...

Hadoop生态圈框架部署 伪集群版(六)- MySQL安装配置
文章目录 前言一、MySQL安装与配置1. 安装MySQL2. 安装MySQL服务器3. 启动MySQL服务并设置开机自启动4. 修改MySQL初始密码登录5. 设置允许MySQL远程登录6. 登录MySQL 卸载1. 停止MySQL服务2. 卸载MySQL软件包3. 删除MySQL配置文件及数据目录 前言 在本文中,我们将…...

【Docker】创建Docker并部署Web站点
要在服务器上创建Docker容器,并在其中部署站点,你可以按照以下步骤操作。我们将以Flask应用为例来说明如何完成这一过程。 1. 准备工作 确保你的服务器已经安装了Docker。如果没有,请根据官方文档安装: Docker 安装指南 2. 创…...

实验七 用 MATLAB 设计 FIR 数字滤波器
实验目的 加深对窗函数法设计 FIR 数字滤波器的基本原理的理解。 学习用 Matlab 语言的窗函数法编写设计 FIR 数字滤波器的程序。 了解 Matlab 语言有关窗函数法设计 FIR 数字滤波器的常用函数用法。 掌握 FIR 滤波器的快速卷积实现原理。 不同滤波器的设计方法具有不同的优…...

学习ESP32开发板安装鸿蒙操作系统(新板子esp32c3不支持)
鸿蒙LiteOS网址:LiteOS: Huawei LiteOS开源代码官方主仓库.LiteOS Studio 开发工具请访问https://gitee.com/LiteOS/LiteOS_Studio 失败的实践记录见:完全按照手册win10里装Ubuntu 虚拟机然后编译ESP32(主要是想针对ESP32C3和S3)…...

asp.net core过滤器应用
筛选器类型 授权筛选器 授权过滤器是过滤器管道的第一个被执行的过滤器,用于系统授权。一般不会编写自定义的授权过滤器,而是配置授权策略或编写自定义授权策略。简单举个例子。 using Microsoft.AspNetCore.Authorization; using Microsoft.AspNetCo…...

力扣面试题 31 - 特定深度节点链表 C语言解法
题目: 给定一棵二叉树,设计一个算法,创建含有某一深度上所有节点的链表(比如,若一棵树的深度为 D,则会创建出 D 个链表)。返回一个包含所有深度的链表的数组。 示例: 输入…...

WordPress阅读文章显示太慢的处理
有两种方式, 1. 完全静态化。 动态都变成html,不再查数据库就快了。 但尝试了几个插件,都未成功。算了后面再研究。 2. cache缓存 用了WP Super Cache测试了一下,打开过一次后,文章秒开,也算达到了要求…...

关于多个线程共享一个实例对象
在多线程环境中,多个线程可能同时调用同一个对象的实例方法,这时候需要考虑如何保证线程安全。理解不同场景下的线程安全性是至关重要的,特别是当方法涉及共享状态时。 1. 共享实例与方法执行 共享实例:多个线程共享同一个实例对…...

CW32L083定时器中断全解析:从基础定时到PWM捕获的实战指南
1. 项目概述与核心价值最近在做一个基于CW32L083的低功耗数据采集项目,其中有一个核心需求是每隔100毫秒精确采集一次传感器数据。为了实现这个看似简单的定时功能,我不得不把CW32的定时器子系统从头到尾捋了一遍。这不捋不知道,一捋才发现&a…...

通关NandGame组合电路后,我悟了:原来CPU设计的关键是“复用”与“延迟”
从NandGame看硬件设计的艺术:复用与延迟的哲学 在数字电路设计的浩瀚宇宙中,每一个逻辑门都如同星辰般微小却不可或缺。当我第一次接触NandGame时,本以为这不过是又一个教人拼凑逻辑门的普通教程,直到亲手搭建起第一个异或门&…...

基于MATLAB的GPS捕获、跟踪与PVT计算实现
一、系统架构设计 GPS信号处理流程分为信号捕获、信号跟踪、导航电文解调和PVT解算四个核心模块。以下为MATLAB实现框架: % 主程序流程 [acquired_data, doppler_shift, code_phase] acquisition(signal, PRN_list); [tracked_data, cn0_est] tracking(acquired_d…...

VMware 17 开机自启实战:从配置到故障排查的完整指南
1. VMware 17开机自启基础配置 很多运维工程师在生产环境中都会遇到这样的需求:让VMware虚拟机像系统服务一样随宿主机自动启动。这个功能对于无人值守的服务器、工控机等场景特别重要。下面我就以VMware Workstation 17为例,手把手教你配置全过程。 首…...

天龙八部单机版GM工具:5分钟快速上手指南与完整功能解析
天龙八部单机版GM工具:5分钟快速上手指南与完整功能解析 【免费下载链接】TlbbGmTool 某网络游戏的单机版本GM工具 项目地址: https://gitcode.com/gh_mirrors/tl/TlbbGmTool 还在为《天龙八部》单机版的数据管理而烦恼吗?TlbbGmTool是一款专为天…...

显卡选购指南:从显存、位宽到AI创作,2023年如何避开参数陷阱?
1. 显卡市场新动态:价格、定位与玩家选择的博弈最近显卡圈子里有点热闹,但这份热闹背后,更多是玩家们的困惑和观望。NVIDIA悄无声息地给RTX 4060 Ti加了个“大显存”的版本,价格直接上探到3899元,比8GB版贵出700块。这…...

HT4182:5V 输入 1.6A 同步升压双节锂电充电器,高集成全保护可 P2P 替代
在便携式音箱、POS 机、电子烟、对讲机等采用双节串联锂电池供电的设备中,5V USB 输入升压充电是最主流的方案,市场对充电效率、集成度和可靠性的要求越来越高。HT4182 作为一款专为 5V 输入优化的同步升压型双节锂电池充电器,凭借高转换效率…...

别再被假密码骗了!手把手教你用010 Editor识别并破解ZIP/RAR伪加密压缩包
010 Editor实战:揭秘ZIP/RAR伪加密压缩包的技术真相 当你从某个CTF比赛下载到一个加密压缩包,输入密码却提示错误时,是否想过这可能是个精心设计的陷阱?网络安全领域存在一种特殊的"伪加密"技术,它让压缩包看…...

CANN/asc-devkit SIMD矢量加法
Adds 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/…...

从提示词到成片:2026年AI视频工作流效率革命——Top 5工具的Prompt工程兼容度、重绘响应延迟与跨平台资产复用率实测
更多请点击: https://intelliparadigm.com 第一章:2026年AI视频生成工具全景图谱与评测方法论 截至2026年,AI视频生成已从实验性原型迈入工业化应用阶段,工具生态呈现“三极分化”格局:消费级轻量工具专注短视频创意提…...