分库分表—4.数据迁移系统文档
大纲
1.数据库设计
2.枚举类
3.接⼝设计
4.定时任务设计
(1)定时核对校验数据的定时任务
(2)数据量统计定时任务
(3)增量数据落地定时任务
(4)失败重试定时任务
5.技术亮点
(1)滚动拉取方案
(2)巧妙的统计滚动进度方案
(3)防止增量同步数据丢失和高效写入方案
(4)数据扩容方案
6.全量同步和增量同步整体流程图
7.功能升级
(1)数据迁移系统数据源动态化配置
(2)迁移数据库操作对应的xml动态⽣成
(3)扩容迁移数据时的问题
1.数据库设计
(1)订单表——order_info
create table order_info (id bigint(32) auto_increment,order_no varchar(32) not null comment '订单号',order_amount decimal(8, 2) not null comment '订单⾦额',merchant_id bigint(32) not null comment '商户ID',user_id bigint(32) not null comment '⽤户ID',order_freight decimal(8, 2) default 0.00 not null comment '运费',order_status tinyint(3) default 0 not null comment '订单状态:10待付款,20待接单,30已接单,40配送中,50已完成,55部分退款,60全部退款,70取消订单',trans_time timestamp default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '交易时间',pay_status tinyint(3) default 2 not null comment '⽀付状态:1待⽀付、2⽀付成功、3⽀付失败',recharge_time timestamp default CURRENT_TIMESTAMP not null comment '⽀付完成时间',pay_amount decimal(8, 2) default 0.00 not null comment '实际⽀付⾦额',pay_discount_amount decimal(8, 2) default 0.00 not null comment '⽀付优惠⾦额',address_id bigint(32) not null comment '收货地址ID',delivery_type tinyint(3) default 2 not null comment '配送⽅式:1⾃提,2配送',delivery_status tinyint(3) default 0 null comment '配送状态:0 配送中,2已送达,3待收货,4已送达',delivery_expect_time timestamp null comment '配送预计送达时间',delivery_complete_time timestamp null comment '配送送达时间',delivery_amount decimal(8, 2) default 0.00 not null comment '配送运费',coupon_id bigint(32) null comment '优惠券id',cancel_time timestamp null comment '订单取消时间',confirm_time timestamp null comment '订单确认时间',remark varchar(512) null comment '订单备注留⾔',create_user bigint(32) null comment '创建⽤户',update_user bigint(32) null comment '更新⽤户',create_time timestamp default CURRENT_TIMESTAMP not null comment '创建时间',update_time timestamp null on update CURRENT_TIMESTAMP comment '更新时间',delete_flag tinyint default 0 not null comment '逻辑删除标记',primary key (id, order_no)
) comment '订单表';
create index inx_order_no on order_info (order_no);
create index inx_create_time on order_info (create_time, order_no);(2)订单详情表——order_info
-- auto-generated definition
create table order_item_detail (id bigint(32) auto_increment primary key,order_no varchar(32) not null comment '订单号',product_id bigint(32) not null comment '商品ID',category_id bigint(32) not null comment '商品分类ID',goods_num int(8) default 1 not null comment '商品购买数量',goods_price decimal(8, 2) default 0.00 not null comment '商品单价',goods_amount decimal(8, 2) default 0.00 not null comment '商品总价',product_name varchar(64) null comment '商品名',discount_amount decimal(8, 2) default 0.00 not null comment '商品优惠⾦额',discount_id bigint(32) null comment '参与活动ID',product_picture_url varchar(128) null comment '商品图⽚',create_user bigint(32) null comment '创建⽤户',update_user bigint(32) null comment '更新⽤户',create_time timestamp default CURRENT_TIMESTAMP not null comment '创建时间',update_time timestamp default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',delete_flag tinyint default 0 not null comment '逻辑删除标记'
) comment '订单明细表' charset = utf8;
create index inx_create_time on order_item_detail (create_time, order_no);
create index inx_item_order_no on order_item_detail (order_no);(3)binlog消息消费记录表——etl_binlog_consume_record
create table etl_binlog_consume_record (id bigint auto_increment comment '主键' primary key,queue_id int null comment '消息队列id(即:queueId)',offset bigint null comment '消息偏移量(唯⼀定位该消息在队列中的位置)',topic varchar(500) null comment '消息所属主题',broker_name varchar(255) null comment '消息所在broker名称',consume_status tinyint(1) null comment '消费状态:0未消费,1消费成功,2已提交',create_time datetime null comment '记录创建时间',update_time datetime null comment '记录更新时间',constraint queue_id unique (queue_id, offset)
) comment 'binlog消息消费记录表' charset = utf8mb4;(4)迁移明细表——etl_dirty_record
create table etl_dirty_record (id bigint auto_increment comment '主键' primary key,logic_model varchar(255) not null comment '逻辑模型名(逻辑表或模型名称)',ticket varchar(32) not null comment '迁移批次',cur_ticket_stage int(10) not null comment '当前所属批次阶段号',record_key varchar(60) not null comment '字段名',record_value varchar(128) null comment '字段值',status int(12) null comment '迁移状态',error_msg varchar(500) null comment '错误消息',retry_times int(12) null comment '已重试次数',last_retry_time datetime null comment '上次重试时间',is_deleted tinyint(1) default 0 null comment '0未被删除,1已删除',create_time datetime default CURRENT_TIMESTAMP not null comment '创建时间',update_time datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '修改时间',sync_size int default 0 null comment '每次同步数量'
) comment '迁移明细表' charset = utf8mb4;(5)迁移表——etl_progress
create table etl_progress (id bigint auto_increment comment '主键' primary key,logic_model varchar(255) null comment '逻辑模型名(逻辑表或模型名称)',ticket varchar(32) null comment '迁移批次',cur_ticket_stage int(10) null comment '当前所属批次阶段号',progress_type int(10) null comment '进度类型(0滚动查询数据,1核对查询数据)',status int(12) null comment '迁移状态:1同步中,2同步完成,3同步失败',retry_times int default 0 null comment '已同步次数',finish_record bigint default 0 null comment '已完成记录数',scroll_id varchar(100) default '0' null comment '记录上⼀次滚动最后记录字段值',scroll_time datetime null comment '开始滚动时间',scroll_end_time datetime null comment '滚动截⽌时间',is_deleted tinyint(1) default 0 null comment '0:未被删除,1:已删除',create_time datetime default CURRENT_TIMESTAMP not null comment '创建时间',update_time datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '修改时间'
) comment '迁移表' charset = utf8mb4;(6)迁移配置表——etl_progress_config
create table etl_progress_config (id bigint auto_increment comment '主键' primary key,logic_model varchar(255) null comment '逻辑模型名(逻辑表或模型名称)',record_key varchar(32) null comment '迁移批次模型字段名称',record_type int(10) null comment '迁移字段匹配类型(0唯⼀字段,1查询匹配字段)',is_deleted tinyint(1) default 0 null comment '0:未被删除,1:已删除',create_time datetime default CURRENT_TIMESTAMP not null comment '创建时间',update_time datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '修改时间'
) comment '迁移配置表' charset = utf8mb4;(7)需要迁移的表的数据量统计表——etl_statistical
create table etl_statistical (id bigint auto_increment comment '主键' primary key,logic_model varchar(255) null comment '逻辑模型名(逻辑表或模型名称)',statistical_count bigint null comment '统计数据量',statistical_time int(8) null comment '统计时间(按天为单位)',is_deleted tinyint(1) default 0 null comment '0:未被删除,1:已删除',create_time datetime default CURRENT_TIMESTAMP not null comment '创建时间',update_time datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '修改时间'
) comment '需要迁移的表的数据量统计表' charset = utf8mb4;
create index inx_logic_model on etl_statistical (logic_model);
create index inx_statistical_time on etl_statistical (statistical_time);2.枚举类
(1)增量数据同步的操作类型——BinlogType
public enum BinlogType {INSERT ("新增", "INSERT"),UPDATE ("修改", "UPDATE"),DELETE ("删除", "DELETE");
}(2)增量同步消费操作结果——ConsumerStatus
public enum ConsumerStatus {NOT_CONSUME ("未消费", 0),CONSUME_SUCCESS ("消费成功", 1),COMMITTED("已提交", 2);
}(3)DB数据库渠道——DBChannel
public enum DBChannel {//渠道⼀CHANNEL_1 ("历史数据库", "1"),//渠道⼆CHANNEL_2 ("新的数据库", "2");
}(4)操作结果枚举值——OperateResult
public enum OperateResult {FAILED ("失败", "1"),SUCCESS ("成功", "0");
}(5)操作类型——OperateType
public enum OperateType {ADD ("增量", 1),ALL ("全量", 2);
}(6)滚动类型——ProgressType
public enum ProgressType {RANGE_SCROLL("滚动查询数据", 0),CHECK_DATA ("核对查询数据", 1);
}3.接⼝设计
(1)访问迁移看板界⾯
http://localhost:8080/migrate/toIndex(2)查询同步进度接⼝
//取得迁移进度信息
//@param queryCondition 查询条件
@RequestMapping(value = "/getEtlProgresses", method = RequestMethod.POST)
public Map<String, Object> getEtlProgresses(@RequestBody EtlProgressReq queryCondition) {Map<String, Object> resultMap = new HashMap<>();resultMap.put("resultCode", OperateResult.SUCCESS.getValue());resultMap.put("resultMsg", OperateResult.SUCCESS.getName());EtlProgress etlProgress = new EtlProgress();BeanUtils.copyProperties(queryCondition, etlProgress);List<EtlProgress> resultList = migrateService.getEtlProgresses(etlProgress);resultMap.put("resultList", resultList);return resultMap;
}(3)发起全量同步接⼝
需要同步的表和时间段
//新增全量同步 将前端传过来的世界格式化
//@param rangeScroll 全量同步条件
//@return 保存结果
@RequestMapping(value = "/addScroll", method = RequestMethod.POST)
public Map<String, Object> addScroll(@RequestBody RangeScroll rangeScroll) {rangeScroll.setStartTime(DateUtils.getStartTimeOfDate(rangeScroll.getStartTime()));rangeScroll.setEndTime(DateUtils.getDayEndTime(rangeScroll.getEndTime()));Map<String, Object> resultMap = new HashMap<>();resultMap.put("resultCode", OperateResult.SUCCESS.getValue());resultMap.put("resultMsg", OperateResult.SUCCESS.getName());scrollProcessor.scroll(rangeScroll);return resultMap;
}4.定时任务设计
(1)定时核对校验数据的定时任务
代码入口:CheckDataTask
public void CheckData() {log.info("数据核对校验开始");if (lock.tryLock()) {try {CheckDataProcessor checkDataProcessor = CheckDataProcessor.getInstance();//查询已同步完成的批次,未核对的数据进⾏核对处理List<RangeScroll> rangeScrollList = checkDataProcessor.queryCheckDataList();for (RangeScroll rangeScroll:rangeScrollList) {// 已经在核对,本次跳过checkDataProcessor.checkData(rangeScroll);}} catch (Exception e) {log.error("数据核对过程中发⽣异常 {}", e.getMessage(), e);} finally {log.info("数据核对校验结束");lock.unlock();}}
}流程图:

核心代码如下:
//核验数据
//@param rangeScroll 要检查的数据抽取模型
public void checkData(RangeScroll rangeScroll) {EtlProgress etlProgress = addEtlProgress(rangeScroll);try {//1.先获取⽼库的⼀批数据List<Map<String, Object>> sourceList = querySourceList(rangeScroll);//2.再获取新库的⼀批数据List<Map<String, Object>> targetList = queryTargetList(sourceList, rangeScroll);//3.对数据进⾏核对校验Map<BinlogType, List<Map<String, Object>>> comparisonMap = comparison(sourceList,targetList,rangeScroll);//4.对数据进⾏归正处理updateComparisonData(comparisonMap,rangeScroll);//5.完成数据核对校验,更改状态updateEtlDirtyRecord(etlProgress, EtlProgressStatus.CHECK_SUCCESS.getValue(),rangeScroll, null);} catch (Exception e) {//数据核对过程失败,只记录数据核对错误信息 updateEtlDirtyRecord(etlProgress, EtlProgressStatus.SUCCESS.getValue(),rangeScroll, e.getMessage());log.error("数据核对过程中发⽣异常 {"+e.getMessage()+"}", etlProgress);}
}(2)数据量统计定时任务
代码入口:CountCacheTask
@Scheduled(cron = "0 0 0/1 * * ? *")
void countRefresh() {try {Constants.statisticalCountMap.clear();//获取所有配置的需要同步的表List<String> filedKeyList = MergeConfig.getFiledKey(STATISTICAL_KEY);for (String fileKey : filedKeyList) {log.info("开始同步:" + fileKey + "的表数据");EtlStatistical etlStatistical = new EtlStatistical();etlStatistical.setLogicModel(fileKey);EtlStatistical etlStatistical1 = migrateScrollMapper.getMaxDateEtlStatistical(etlStatistical);//验证单个表的数据明细是否已统计,如果未统计则默认从最⼩时间天数开始统计//否则只更新最近15天的数据(超过15天的数据变化概率很低,暂不考虑更新)if (ObjectUtils.isNotEmpty(etlStatistical1)) {//已统计的最⼤时间格式Integer statisticalTime = etlStatistical1.getStatisticalTime();Long distanceDays = DateUtils.getDistanceDays(String.valueOf(statisticalTime), DateUtils.format(new Date()) + "");Date minDate = null;if (distanceDays < 15) {//更新最近15天的该表统计数量minDate = DateUtils.addDays( -15);} else {minDate = DateUtils.parseStrToDate(String.valueOf(statisticalTime), DateUtils.DATE_FORMAT_YYYYMMDD);}saveStatistical(minDate, fileKey, false);} else {//先取最⼩的⽇期,然后以该⽇期,以天为单位开始统计Date minDate = getMinDate(fileKey);saveStatistical(minDate, fileKey, true);}}} catch (Exception e) {e.printStackTrace();}
}流程图:

(3)增量数据落地定时任务
代码入口:IncrementTask
void IncrementTask() {//获取阻塞队列的⽅法LocalQueue localQueue = LocalQueue.getInstance();//验证读队列的数据已被处理完毕if (!localQueue.getIsRead()) {log.info("增量数据执⾏写⼊");//执⾏数据写⼊localQueue.doCommit();}
}流程图:

(4)失败重试定时任务
代码入口:ScrollTask
public void Scroll() {List<EtlProgress> progressList = queryFailAndStopProgressList();for (EtlProgress progress:progressList) {if (progress.getRetryTimes() < 3) {RangeScroll rangeScroll = new RangeScroll();rangeScroll.setId(progress.getId());rangeScroll.setStartScrollId(progress.getScrollId());rangeScroll.setTableName(progress.getLogicModel());rangeScroll.setPageSize(progress.getFinishRecord());rangeScroll.setStartTime(progress.getScrollTime());rangeScroll.setEndTime(progress.getScrollEndTime());rangeScroll.setCurTicketStage(progress.getCurTicketStage());rangeScroll.setTicket(progress.getTicket());rangeScroll.setRetryFlag(true);scrollProcessor.scroll(rangeScroll);}}
}流程图:

5.技术亮点
(1)滚动拉取方案
全量同步时,是需要分批次查询数据的,这里的分批次拉取数据就是滚动拉取数据。

可以看到的具体流程是:
步骤一:每次进⾏全量同步时都会往迁移表中添加⼀条记录。
步骤二:然后每次最多查询500条数据作为⼀个批次,该批次会在迁移明细表中对应添加⼀条记录。
步骤三:其中会进行滚动查询。也就是会根据当前选择数据同步的时间范围内,到订单表中查询最⼩订单号,然后将这个最⼩的订单号会保存在⼀个RangeScroll的实体类中。当查询订单数据时,查询条件会⽐较简单,就是订单号⼤于最⼩的订单号。然后经过时间过滤以及过滤掉目标库已有的数据后,剩下的就是本次全量同步的⽬标数据了。当这些目标数据同步到目标库后,会更新迁移明细状态,以及将当前已查到的订单数据中的最⼤订单号重置到RangeScroll类中。这样在下⼀轮查询时,查询参数中的最⼩订单号会从RangeScroll类中获取,从而实现滚动查询。
举个例⼦:有四条订单数据,对应四个订单号:1001、1002、1003、1004。初始查询发现最⼩订单号为1001,此时会对1001减1=1000,保证订单号为1001这条数据能查到,也能同步过去(这个细节容易忽视)。然后假设每次只能查询2条数据,第⼀次查询,因为查询条件是⼤于最⼩订单号减1也就是1000,查询到了1001、1002这两个订单号的订单数据。处理完第⼀轮后,会把本次最⼤的订单号也就是1002,作为下⼀轮查询的最⼩订单号。下⼀轮查询情况,会查询订单号⼤于1002的订单数据,此时就会查询出1003、1004对应的订单数据,并且将1004作为下⼀轮的最⼩订单号查询。再下⼀轮查询时,条件就变为订单号⼤于1004,此时就查询不到数据了,数据迁移结束。本次全量同步经过两个批次查询,⼀共添加了⼀条迁移记录,还有两条迁移明细。最后迁移记录和迁移明细的状态,都会更新为同步成功状态。
步骤四:根据表名分组进行批量插⼊。当查询源数据库的数据并过滤掉⼀些数据后,并不是⼀条⼀条插⼊到目标库中的。⽽是会根据表名进⾏分组,然后批量插⼊目标库。相⽐于⼀条条数据插⼊,这样效率也会更⾼⼀点,这是需要做的⼀个优化点。
步骤五:更新迁移明细表记录和迁移记录为同步状态。循环滚动查询出来的每一批次数据处理完后,就更新迁移明细表中该批次的同步状态。当循环滚动从源数据库查不出数据后,就更新本次迁移记录为同步状态。
(2)巧妙的统计滚动进度方案
在进行数据迁移时,怎么能在不影响性能的情况下快速计算出现在迁移进度执行到多少呢?

从图中可以看到:会有⼀个定时任务,每隔⼀个⼩时就会统计⼀下不同时间段的数据量。⾸先会创建⼀张订单数据统计表,用于统计每天的数据量,⽅便后续计算迁移进度。定时任务会从订单数据统计表中,查询最新的⼀条记录,也就是最近⼀次统计的记录。
第⼀次统计时定时任务肯定是查不到的,所以这时定时任务会到订单表中查询订单的最小创建时间,并计算距今的天数。然后开始统计订单数量,统计⽅式是,对每天的订单数量⽣成⼀条订单数据统计记录。
⽐如,最早的⼀条订单创建时间为2020-01-01。下⼀步会计算这个时间,距离当前全量数据迁移任务执⾏时有⼏天,假设有1年。然后为这1年来的每⼀天创建每天订单数据统计记录,即每⼀条记录会统计每⼀天的订单量。比如查询2020-01-01 00:00:00~2020-01-01 23:59:59这⼀天时间范围内的订单数据量,然后创建⼀条数据迁移统计记录,以此类推。
当第⼆次执⾏这个定时任务时,就可以查到最新⽣成的⼀条订单数据统计记录了。此时会看下这条记录的时间,距离现在是否超过2天,防⽌跨天数据产⽣。
有了以上数据统计后,在迁移明细表中的每条记录中,同步完⼀批数据都会记录⽬前已迁移完多少数据。这样就可⽤已同步完毕的数据量,除以订单数据统计记录的订单总数据量,结果就是迁移进度。
(3)防止增量同步数据丢失和高效写入方案
在增量同步中,首先会通过Canal监听源数据库中的binlog⽇志,然后Canal再将监听到的binlog⽇志发送放到RocketMQ中,接着数据迁移系统会消费RocketMQ中的binlog消息,把增删改操作同步到目标数据库。
问题一:数据迁移系统消费MQ消息时,如何保证从MQ获取到的binlog消息不会丢失
如果源数据库增删改操作了,但由于消费异常导致binlog消息丢失了,那么目标数据库中就没有对应的增量数据操作,这样源数据库和目标数据库的数据就会不⼀致。为了避免消费异常导致binlog消息丢失,需要设置禁止自动提交消息。
消费MQ的binlog消息时,为了提升消费速度,可以采用多线程进行消费。比如每消费一条MQ消息,就向线程池提交一个任务,任务执行完才提交消息。当这些任务的执行速度慢于消费MQ消息的速度时,线程池的阻塞队列中就会积压一些任务。如果此时机器发布重启,那么就可能会导致线程池中阻塞队列里积压的任务丢失。但是由于禁止消息自动提交,所以这些丢失任务对应的MQ消息后续还可以重新被消费,然后再次被提交到线程池中进行处理。
为了方便对binlog消息进行管理和确保binlog消息不丢失且有记录可查,这里引⼊消息拉取落库和异步消息提交机制,由两个定时任务来完成。如下所示:

⾸先源数据库中会有⼀张消费记录表,定时任务1每次从MQ拉取并消费⼀条消息时,都会先在消费记录表中新增⼀条消费记录,每条消费记录的初始状态都为未消费。然后定时任务1再将获取到的binlog消息,在目标数据库中重做binlog⽇志。也就是将旧库中的增删改操作,在目标数据库中重做⼀遍。重做完成后,再来更新刚刚添加的消费记录的状态,将记录的状态从未消费更新为已消费状态。
此时需要注意:定时任务1消费MQ的binlog消息后,并不是自动向MQ提交消息,⽽是需要进行⼿动提交。否则如果消息都没有消费成功,就自动向MQ提交消息,则可能会出现消息丢失的情况。所以为了保证binlog消息不丢失,不会⾃动提交消息,⽽是将提交消息的任务交给定时任务2来处理。
定时任务2会专⻔从消费记录表中,查询已消费的那些记录,然后向MQ提交消息,这样下次就不会从MQ中消费到了。向MQ提交完消息后,同时会将消费记录表中的记录状态,从已消费更新为已提交。⾄此,⼀个消息的消费流程才算结束。
问题二:如何提高增量同步时的数据写入效率
为了提高数据写入目标数据库的效率,这里引入了数据合并、过滤、读写队列的机制,读写队列和数据合并流程图如下:

定时任务1添加完消费记录后,并不会⻢上把数据写入目标库,⽽是把binlog日志先放到⼀个写队列中,与写队列相对的还有⼀个读队列。读队列是专⻔用于提供给定时任务3进行处理消息写⼊操作的。
数据合并提升写入效率:如果源数据库中的数据在短时间内进⾏了多次操作,其实只需要保留最新的binlog⽇志即可。所以才使用了一个内存队列来存放binlog消息,而且会每隔15秒批量处理一次内存队列的所有binlog消息,以此减少同一条数据对应多条binlog的写入处理。
binlog日志的处理细节:从合并后的binlog⽇志中获取主键ID,根据主键ID到目标库中查询对应的数据。
如果目标库中能查到这条数据,那么需要和源数据库的binlog数据进⾏对⽐。只有当源数据库的更新时间⼤于目标库的更新时间,才允许更新数据到目标库中。如果当前的binlog⽇志的操作类型为删除操作,则可不⽤对⽐更新时间,直接在目标库中重做这条binlog⽇志,毕竟源数据库在删除⼀条数据时不会更新修改时间。
如果源数据库的⼀条binlog⽇志对应的数据在目标库中没有查到,那么继续判断。如果binlog⽇志是删除操作,那就没必要在目标库中重做这条⽇志了,直接过滤掉。目标库都没有数据了,就没必要执⾏删除操作。如果binlog⽇志的类型为修改操作,那也没必要执⾏修改操作。因为目标库没数据,直接update也不⾏,可以将binlog的操作类型修改为新增操作。毕竟在binlog⽇志中,包含了⼀条订单数据的所有字段的值,⾜以满⾜新增数据需要的所有字段。
经过以上的数据过滤操作,⼀⽅⾯避免源数据库中的旧数据覆盖了目标库的新数据,另⼀⽅⾯避免没必要执⾏的删除和更新操作也在目标库中继续执⾏。
代码入口如下:
@Component
public class CanalConsumeTask implements ApplicationRunner { //rocketmq的nameServer地址@Value("${rocketmq.name-server:127.0.0.1:9876}")private String nameServerUrl; @Autowiredprivate MigrateConfigService migrateConfigService;@Overridepublic void run(ApplicationArguments args) throws Exception {// 当前配置的全部迁移系统List<ScrollDomain> scrollDomainList = migrateConfigService.queryScrollDomainList();ExecutorService executors = Executors.newFixedThreadPool(scrollDomainList.size());for (ScrollDomain scrollDomain:scrollDomainList) {if (scrollDomain.getDataSourceType().equals(1)) {//执⾏拉取任务executors.execute(new CanalPullRunner(scrollDomain.getDomainTopic(), nameServerUrl));//执⾏提交任务executors.execute(new CanalPullCommitRunner(scrollDomain.getDomainTopic(), nameServerUrl));} } }
}(4)数据扩容方案
扩容的过程其实就是将一个8库8表的源数据库数据迁移到16库16表的目标库中,如下:

单库 -> 8库8表 和 8库8表->16库16表是⾮常相似的。因为它们都需要全量同步、增量同步、数据验证的功能,这些处理其实是⼀样的。可以直接使⽤单库 -> 8库8表的数据迁移系统的代码。
数据迁移系统的代码需要如下改动:
改动一:源数据库和目标库配置
读取源数据源(单库)和⽬标数据源(8库8表)的地⽅,就是读取单库的地⽅,修改为读取8库8表,⽽写⼊⽬标数据源由8库8表修改为16库16表。
改动二:修改Canal配置
因为单库 -> 8库8表增量同步时,Canal监听的是单库的binlog。扩容时,Canal需要监听8库的binlog。
6.全量同步和增量同步整体流程图

7.功能升级
现在数据迁移系统的迁移来源数据源和写入数据源都是配置在migrate.properties⽂件⾥的,这种写死数据源的⽅式不⽅便扩展和修改。假设在使⽤过程中需要对其他库和表进⾏数据迁移,则需要在代码⾥更改原数据源和写⼊数据源,并且重新部署新项⽬进⾏相关配置后,再来进⾏迁移操作,所以我们采⽤数据库配置的⽅式来进⾏。
(1)数据迁移系统数据源动态化配置
新建4张表存放动态化配置:
-- auto-generated definition
create table scroll_db_config (id bigint auto_increment comment '主键' primary key,domain_id bigint null comment '归属系统数据源配置ID',jdbc_url varchar(256) null comment '数据库连接串',jdbc_username varchar(64) null comment '⽤户名',jdbc_pasword varchar(256) null comment '密码',is_deleted tinyint(1) default 0 null comment '0:未被删除,1:已删除',create_time datetime default CURRENT_TIMESTAMP not null comment '创建时间',update_time datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '修改时间'
) comment '迁移数据源配置表' charset = utf8mb4; -- auto-generated definition
create table scroll_domain (id bigint auto_increment comment '主键' primary key,domain varchar(128) null comment '所属系统(会员、订单、交易)',domain_topic varchar(128) null comment '当数据源为来源的时候,配置对应的消息topic',data_source_type tinyint(1) null comment '数据源类型,1数据来源配置,2数据写⼊配置',sql_show tinyint(1) default 0 null comment '是否显示 shardingsphere sql执⾏⽇志,默认不打印(0不打印,1打印)',table_num int(8) null comment '每个逻辑库中表的数量',is_deleted tinyint(1) default 0 null comment '0:未被删除,1:已删除',create_time datetime default CURRENT_TIMESTAMP not null comment '创建时间',update_time datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '修改时间'
) comment '迁移业务配置表' charset = utf8mb4;-- auto-generated definition
create table scroll_shard_config (id bigint auto_increment comment '主键' primary key,domain_id bigint not null comment '数据业务系统源ID',logic_model varchar(128) not null comment '逻辑模型名(逻辑表或物理表名称)',db_sharding_columns varchar(256) not null comment '库分⽚列名称,多个列以逗号分隔',table_sharding_columns varchar(256) not null comment '表分⽚列名称,多个列以逗号分隔',db_sharding_algorithm varchar(256) not null comment '库分⽚策略类名',table_sharding_algorithm varchar(256) not null comment '表分⽚策略类名',is_deleted tinyint(1) default 0 null comment '0:未被删除,1:已删除',create_time datetime default CURRENT_TIMESTAMP not null comment '创建时间',update_time datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '修改时间'
) comment '数据源分⽚规则配置表' charset = utf8mb4;-- auto-generated definition
create table scroll_table_config (id bigint auto_increment comment '主键' primary key,domain varchar(128) null comment '业务系统',source_table_name varchar(128) null comment '源表名',target_table_name varchar(128) null comment '⽬标表名',create_time datetime default CURRENT_TIMESTAMP not null comment '创建时间',update_time datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '修改时间'
) comment '迁移表映射配置' charset = utf8mb4;流程图:

表配置简述:
一.⾸先配置scroll_domain(迁移业务配置表)表。这里会配置2条数据,⼀个是订单的来源数据库数据,⼀个是订单的⽬标库数据。其中源数据库需要配置domain_topic,也就是Canal读取数据库⽇志要发送的MQ的topic。
二.配置scroll_db_config(迁移数据源配置表)指定迁移数据源。
三.配置scroll_shard_config(数据源分⽚规则配置表)⽤来指定分库分表的规则。
四.配置scroll_table_config(迁移表映射配置),⽤来映射订单系统两个表需要迁移到分库分表⾥的哪个表⾥⾯去。
(2)迁移数据库操作对应的xml动态⽣成
关于动态SQL我们采⽤PreparedStatement⽅式拼接SQL,PreparedStatement的第⼀次执⾏消耗是很⾼的,它的性能体现在后⾯的重复执⾏(缓存的作⽤)。相关代码如下:
@Override
public String queryMinScrollId(RangeScroll rangeScroll) {//验证必填参数if (StrUtil.isNotBlank(rangeScroll.getTableName())) {SqlSession session = null;PreparedStatement pst = null;try {rangeScroll.setScrollName(MergeConfig.getSingleKey(rangeScroll.getTableName()));String sql = " select " + rangeScroll.getScrollName() + " from " + rangeScroll.getTableName() + " where create_time >= ?" + " order by create_time asc, " + rangeScroll.getScrollName() + " asc LIMIT 1";//获取指定的数据源session = scrollDataSourceConfig.getSqlSession(rangeScroll.getDomain(), 1);pst = session.getConnection().prepareStatement(sql);pst.setDate(1, new Date(rangeScroll.getStartTime().getTime()));ResultSet result = pst.executeQuery();while (result.next()) {return String.valueOf(Long.parseLong(result.getString(1)) - 1);}return null;} catch (Exception e) {log.error("queryInfoList⽅法执⾏出错", e);return "0";} finally {closeSqlSession(session,pst,rangeScroll.getDomain(), 1);}}return "0";
}//负责分⻚滚动数据
//@param rangeScroll 查询条件
@Override
@SuppressWarnings({"unchecked"})
public List<Map<String, Object>> queryInfoList(RangeScroll rangeScroll) {if (StrUtil.isNotBlank(rangeScroll.getTableName()) && StrUtil.isNotBlank(rangeScroll.getStartScrollId())) {SqlSession session = null;PreparedStatement pst = null;try {String sql = "select * from " + rangeScroll.getTableName() + " where " + rangeScroll.getScrollName() + " > ? " + " order by " + rangeScroll.getScrollName() + " asc LIMIT " + rangeScroll.getPageSize();//获取指定的数据连接session = scrollDataSourceConfig.getSqlSession(rangeScroll.getDomain(), 1);pst = session.getConnection().prepareStatement(sql);pst.setString(1,rangeScroll.getStartScrollId());ResultSet resultSet = pst.executeQuery();return converter(resultSet);} catch (Exception e) {log.error("queryInfoList⽅法执⾏出错", e);return new ArrayList<>();} finally {closeSqlSession(session,pst,rangeScroll.getDomain(), 1);}}return new ArrayList<>();
}这⾥需要注意批量插⼊数据时,需要对数据进⾏格式识别和处理。
//SQL预处理,需要什么加什么
//@param preparedStatement SQL预处理
//@param pos 定位
//@param value 值
public static void buildPerParedStatement(PreparedStatement preparedStatement, int pos, Object value) {try {if (value instanceof String) {preparedStatement.setString(pos, (String) value);} else if (value instanceof Long) {preparedStatement.setLong(pos, (Long) value);} else if (value instanceof Float) {preparedStatement.setFloat(pos, (Long) value);} else if (value instanceof Double) {preparedStatement.setDouble(pos, (Long) value);} else if (value instanceof Integer) {preparedStatement.setInt(pos, (Integer) value);} else if (value instanceof java.util.Date) {preparedStatement.setTimestamp(pos, new Timestamp(((Date) value).getTime()));} else if (value instanceof Boolean) {preparedStatement.setBoolean(pos, (Boolean) value);} else if (value instanceof BigDecimal) {preparedStatement.setBigDecimal(pos, (BigDecimal) value);}} catch (Exception e) {log.error("SQL预处理失败:{}", e);}
}(3)扩容迁移数据时的问题
当全局滚动和增量滚动进⾏数据过滤时:会根据滚动号order_no进⾏in查询,这时候会从分库⾥⾯进⾏批量查询。但如下的这个查询⽅法⽐较耗时,因为ShardingSphere在in查询操作时,会去8个库8张表⾥⾯去轮流查询,导致效率很低。虽然SQL的执⾏结果是正确的,但并未达到最优的查询效率。
//批量查询数据信息
//@param scroll 数据对象
//@param identifiers 唯⼀标识List
//@param dbChannel 指向具体的BD库
@Override
@SuppressWarnings({"unchecked"})
public List<Map<String, Object>> findByIdentifiers(RangeScroll scroll, List<String> identifiers,String dbChannel) {if (!Objects.isNull(scroll) && CollUtil.isNotEmpty(identifiers)) {SqlSession session = null;PreparedStatement pst = null;Integer dataSourceType = 2;try {if (DBChannel.CHANNEL_1.getValue().equals(dbChannel)) {dataSourceType = 1;}session = scrollDataSourceConfig.getSqlSession(scroll.getDomain(), dataSourceType);if (null != session) {StringBuffer sql = new StringBuffer();sql.append("select * from " + scroll.getTargetTableName() + " where " + scroll.getScrollName() + " in (");for (String id : identifiers) {sql.append("?,");}String sqlStr = sql.substring(0, sql.length() - 1) + ")";pst = session.getConnection().prepareStatement(sqlStr);for (int i=1; i<=identifiers.size(); i++) {pst.setString(i,identifiers.get(i-1));}ResultSet resultSet = pst.executeQuery();return converter(resultSet);}} catch (Exception e) {log.error("findByIdentifiers⽅法执⾏出错", e);return new ArrayList<>();} finally {closeSqlSession(session,pst,scroll.getDomain(), dataSourceType);}}return new ArrayList<>();
}相关文章:
分库分表—4.数据迁移系统文档
大纲 1.数据库设计 2.枚举类 3.接⼝设计 4.定时任务设计 (1)定时核对校验数据的定时任务 (2)数据量统计定时任务 (3)增量数据落地定时任务 (4)失败重试定时任务 5.技术亮点 (1)滚动拉取方案 (2)巧妙的统计滚动进度方案 (3)防止增量同步数据丢失和高效写入方案 (4)…...

HAMR技术进入云存储市场!
2024年12月3日,Seagate宣布其Mozaic 3系列HAMR(热辅助磁记录)硬盘获得了来自一家领先云服务提供商(可能AWS、Azure或Google Cloud其中之一)以及其他高容量硬盘客户的资格认证。 Seagate的Mozaic 3技术通过引入热辅助磁…...

Vulnhub---kioptirx5 超详细wp
个人博客 WuTongSec 欢迎大佬指点 打点 nmap 192.168.128.0/24 -sP 找ip nmap 192.168.128.137 --min-rate 10000 -p- 简单全端口扫描 nmap 192.168.128.137 -sC -sV -O -sT 详细 脚本 版本 系统 扫描 dirsearch -u http://192.168.128.137 目录扫描 PORT S…...

单片机状态机实现多个按键同时检测单击、多击、长按等操作
1.背景 在之前有个项目需要一个或多个按键检测:单击、双击、长按等操作 于是写了一份基于状态机的按键检测,分享一下思路 2.实现效果 单击翻转绿灯电平 双击翻转红灯电平 长按反转红绿灯电平 实现状态机检测按键单击,双击,长…...

oracle之用户的相关操作
(1)创建用户(sys用户下操作) 简单创建用户如下: CREATE USER username IDENTIFIED BY password; 如果需要自定义更多的信息,如用户使用的表空间等,可以使用如下: CREATE USER mall IDENTIFIED BY 12345…...

黑马redis
Redis的多IO线程只是用来处理网络请求的,对于读写操作命令Redis仍然使用单线程来处理 Redisson分布式锁实现15问 文章目录 主线程和IO线程是如何协作的Unix网络编程中的五种IO模型Linux世界一切皆文件生产上限制keys *、flushdb、flushall等危险命令keys * 遍历查询100W数据花…...

HCIA-Access V2.5_1_2 PON技术的特点、优势与典型应用
PON接入技术优势 它的接入方式有两种,点到点光接入和点到多点光接入。 点到点 PON口的资源被一个用户独占,该用户可以享受到更好的带宽体验,同时故障好排查,出现问题,重点检测这一条链路以及终端用户,同…...

css部分
前面我们学习了HTML,但是HTML仅仅只是做数据的显示,页面的样式比较简陋,用户体验度不高,所以需要通过CSS来完成对页面的修饰,CSS就是页面的装饰者,给页面化妆,让它更好看。 1 层叠样式表&#…...

【TCP 网络通信(发送端 + 接收端)实例 —— Python】
TCP 网络通信(发送端 接收端)实例 —— Python 1. 引言2. 创建 TCP 服务器(接收端)2.1 代码示例:TCP 服务器2.2 代码解释: 3. 创建 TCP 客户端(发送端)3.1 代码示例:TCP…...

LSTM+改进的itransformer时间序列预测模型代码
代码在最后 本次设计了一个LSTM基于差分多头注意力机制的改进的iTransformer时间序列预测模型结合了LSTM(长短期记忆网络)和改进版的iTransformer(差分多头注意力机制),具备以下优势: 时序特征建模能力&am…...

Apache-HertzBeat 开源监控默认口令登录
0x01 产品描述: HertzBeat(赫兹跳动) 是一个开源实时监控系统,无需Agent,性能集群,兼容Prometheus,自定义监控和状态页构建能力。HertzBeat 的强大自定义,多类型支持,高性能,易扩展,希望能帮助用户快速构建自有监控系统。0x02 漏洞描述: HertzBeat(赫兹跳动) 开源实时…...

Delete Number
翻译: 主要思路解释 整体思路概述: 本题的目标是给定整数(要删除的数字个数)和整数(以字符串形式表示的数字),通过合理删除个数字,使得最终得到的新数字最小。程序采用了一种贪心算…...

Linux常用快捷键
目录 编辑 剪切/复制/粘贴/删除等快捷键 终端及标签页快捷键 历史命令快捷键 移动光标快捷键 控制命令 剪切/复制/粘贴/删除等快捷键 快捷键 功能 ShiftCtrlC 复制 ShiftCtrlV 粘贴 CtrlInsert 复制命令行内容 ShiftInsert 粘贴命令行内容 Ctrlk 剪切&#…...

针对xpath局限的解决方案
上篇《网页数据提取利器 -- Xpath》我们对xpath的介绍中提到了xpath的几点局限性: 结构依赖性强性能动态网页支持不足 本篇是针对这些局限提出的解决方案和补充方法,以提升 XPath 的实用性和适应性。 1. 动态网页的处理 局限: XPath 无法…...

深入解析 HTML Input 元素:构建交互性表单的核心
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...
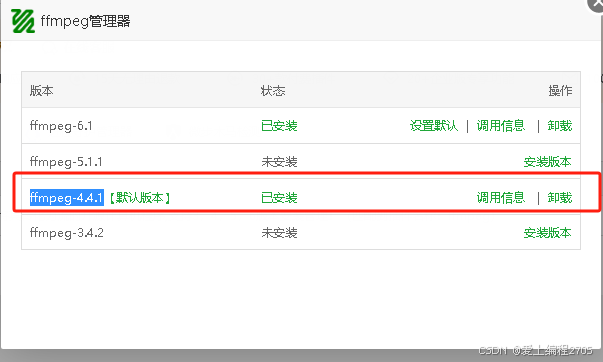
ffmpeg转码与加水印
文章目录 转码 与加水印引入jar包代码ffmpeg安装错误解决方法 转码 与加水印 引入jar包 <dependency><groupId>net.bramp.ffmpeg</groupId><artifactId>ffmpeg</artifactId><version>0.6.2</version></dependency>代码 impo…...

Leetcode 104. 二叉树的最大深度(Java-深度遍历)
题目描述: 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 示例: 输入:root [3,9,20,null,null,15,7] 输出:3示例 2: 输入:…...

阳明心学-传习录学习总结
资料 王阳明介绍:明代杰出的思想家、军事家、教育家;自刑部主事历任贵州龙场驿丞、庐陵知县、右佥都御史、南赣巡抚、两广总督等职,接连平定南赣、两广盗乱及宸濠之乱,因功获封“新建伯”,成为明代因军功封爵的三位文…...

macOS sequoia 15.1中应用程序“程序坞”没有权限打开
在macOS sequoia 15.1版本中新安装的应用程序在访达中打开报错显示应用程序“程序坞”没有权限打开“(null)”。 解决办法 在启动台中找到终端,点击打开,切换到应用目录下,输入 cd /Applications/ 找到需要打开的应用程序目录࿰…...

使用 MinIO 和 KKFileView 实现在线文件预览功能
在项目开发中,文件的在线预览是常见的需求,尤其是对 PDF、Word、Excel 等格式的文件进行无客户端依赖的直接查看。本文将介绍如何通过 MinIO 和 KKFileView 搭建在线文件预览服务,并通过 docker-compose 一键部署。 一、环境准备 1. Docker …...

轻量级工作流编排引擎:从脚本管理到自动化流程的实践指南
1. 项目概述:从单体脚本到流程编排的进化 如果你和我一样,在数据工程、自动化运维或者机器学习模型训练这些领域摸爬滚打过几年,大概率会遇到一个相似的困境:手头的任务脚本越来越多,它们之间有的有依赖关系࿰…...

从零构建个人知识库:Go+React全栈项目RocketNotes实战解析
1. 项目概述:从零到一构建个人知识管理工具最近在整理个人笔记和代码片段时,发现了一个挺有意思的开源项目fynnfluegge/rocketnotes。乍一看这个名字,可能会联想到火箭(Rocket)和笔记(Notes)的结…...

低温预警!固化慢、易开裂……密封胶冬季施工手册
低温预警!固化慢、易开裂……密封胶冬季施工手册 硅酮耐候密封胶主要作用是保障幕墙的气密性、水密性。其出现问题,可能会导致耐候密封失效,从而造成幕墙漏水漏气,影响幕墙的正常使用。耐候密封胶由于考虑到现场施工,几乎都是单组分硅酮密封胶产品。进入冬季,气候变化明…...

开源虚拟世界引擎Vircadia核心架构与部署实战指南
1. 项目概述:一个开源虚拟世界的核心引擎如果你对构建一个属于自己的、去中心化的虚拟世界感兴趣,那么你很可能已经听说过或者正在寻找一个合适的底层引擎。今天要聊的这个项目,就是这样一个领域的重量级选手:vircadia/vircadia-n…...

3步掌握yfinance:从金融数据获取到智能分析的完整指南
3步掌握yfinance:从金融数据获取到智能分析的完整指南 【免费下载链接】yfinance Download market data from Yahoo! Finances API 项目地址: https://gitcode.com/GitHub_Trending/yf/yfinance yfinance是一个强大的Python库,能够轻松从Yahoo! F…...

怎么判断一家工厂还在不在正常生产?6 类活跃度信号,从纸面到现场
跑工厂的销售员都遇到过这种事:手机里存着一份名单,导航开两小时,到门口才发现卷帘门焊死、车间长草、保安说"厂子去年就搬了"。 问题出在哪?大多数人判断"这家工厂在不在",靠的是工商登记——执照…...

Lingoose框架实战:构建智能客服工单处理AI工作流
1. 项目概述:从“Lingo”到“Goose”,一个AI应用编排框架的诞生如果你最近在折腾大语言模型应用,尤其是想把OpenAI、Anthropic这些API的能力整合到自己的业务流程里,那你大概率已经体会过那种“胶水代码”的烦恼了。今天要聊的这个…...

树莓派机械爪项目实战:从硬件连接到Python控制全解析
1. 项目概述:当树莓派遇上机械爪最近在折腾一个挺有意思的小项目,叫Demwunz/openclaw-pi-installation。光看这个名字,就能猜到个大概:这是一个为树莓派(Raspberry Pi)准备的机械爪(Claw&#x…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...

faah:轻量级自动化任务编排器,简化运维与数据处理工作流
1. 项目概述:一个被低估的自动化利器最近在整理自己的自动化工具链时,又翻出了kiron0/faah这个项目。说实话,第一次看到这个仓库名,我也有点懵——“faah”?这名字听起来不像是一个典型的工具。但点进去之后࿰…...