Python爬虫——HTML中Xpath定位
Xpath是一种路径查询语言。利用一个路径表达式从html文档中找到我们需要的数据位置,进而将其写入到本地或者数据库中。
学习Xpath爬虫,我们首先学习一下python中lxml库
关于库
lxml
终端下载Xpath需要用到的模块
pip install lxml
关于HTML
超文本标记语言,是用来描述网页的一种语言。主要用于控制数据的显示和外观。HTML文档一定意义上可以被称为网页。但反过来说网页不仅仅是HTML,网页本质有三部分构成:负责内容结构的HTML,负责表现的CSS,以及负责行为的javascript。本文主要分享的是最核心的内容结构部分。
html结构
完整的HTML文件至少包括标签、标签、
例如,我们打开 汽车之家 首页,摁下键盘上的F12键,打开浏览器自带“开发者工具”,可以看到一个完整的html文档结构,如下图

打开 中图网 首页,摁下键盘上的F12键,打开浏览器自带“开发者工具”,可以看到一个完整的html文档结构,如下图

从上图可以看出,一个完整的html文档主要包含三部分:DTD文档头,head头部信息和body正文信息。其中DTD文档头用来告诉浏览器执行标准是什么(比如html4或是html5),head头部信息用来说明浏览器的编码方式和文档头名称,body顾名思义就是浏览器的正文部分。
html标签
作为开始和结束的标记,由尖括号包围的关键词,比如 ,标签对中的第一个标签是开始标签,第二个标签是结束标签。html中常见标签如下:

其中, “< ul >< li >”是一种嵌套顺序,无序列表,成对出现;
li的父元素必须是ul或者ol,不同之处在于ol是一种有序列列表,而ul是无序列表;
html属性
属性是用来修饰标签的,放在开始标签里里面,html中常见四大属性:
| 属性 | 说明 |
|---|---|
| class | 规定元素的类名,大多数时候用于指定样式表中的类 |
| id | 唯一标识一个元素的属性,在html里面必须是唯一的 |
| href | 指定超链接目标的url |
| src | 指定图像的url |
Xpath
xpath常见使用方法
| 符号 | 功能 |
|---|---|
| // | 表示在整个文本中查找,是一种相对路径 |
| / | 表示则表示从根节点开始查找,是一种绝对路径 |
| text() | 找出文本值 |
| @ | 找出标签对应的属性值,比如@href就是找出对应的href链接 |
| . | 表示当前节点 |
| … | 表示当前节点的父节点 |
举个例子,定位中图网中图书畅销榜TOP1000书本的位置。
2024年畅销图书排行榜_图书销量排行榜_中图网
定位TOP1图书

在开发者工具这一侧按住ctrl+F,在浮出的搜索栏里依次输入我们找到top1图书的位置

/html/body/div[@class=‘content’]/div/div[@class=‘container’]/div/div[@class=‘listLeft’]/div[@class=‘bookList’]/ul/li
这是绝对路径,也就是完整路径。
我们也可以通过相对路径//定位到第一本书
//div[@class=‘listMainclearfix’]/div[2]/div[2]/ul/li
特别注意:通过相对路径找到的路径,用//开始 ,且//后面的标签是唯一的。可以在ctrl+F浮出的搜索栏里查询该标识符是否出现且唯一

这样我们就在HTML里顺利的找到TOP1的位置啦!
当然 Xpath除了上述常见用法外,还存在两种比较特殊的用法:
- 以相同的字符开头
用法1:以相同的字符开头:starts-with(@属性部分,属性字符相同部分
#例子1:
from lxml import etree
html1 = """
<!DOCTYPE html>
<html><head lang='en'><meta charest='utf-8'><title></title></head><body><div id="aaa">哇哈哈</div><div id="bbb">爽歪歪</div><div id="ccc">营养快线</div></body>
</html>
"""# 将符合html格式的字符串转成可以编写xpath语法的格式
info1 = etree.HTML(html1)res1 = info1.xpath('//div[1]/text()')
print(res1, type(res1))
print('------------------')
res2 = info1.xpath('//div[2]/text()')
print(res2, type(res2))
print('------------------')
res3 = info1.xpath('//div[3]/text()')
print(res3, type(res3))

- 标签套标签
用法2:标签套标签:string(.)
#例子2:
from lxml import etree
html2 = """
<!DOCTYPE html>
<html><head lang='en'><meta charest='utf-8'><title></title></head><body><div id="test3">我左青龙,<span id='tiger'>右白虎<ul>上朱雀,<li>下玄武,</li></ul></span>龙头在胸口</div></body>
</html>
"""
info2 = etree.HTML(html2)
res1 = str(info2.xpath('string(.)'))
res1 = res1.replace("\n","").replace(" ","").replace("\t","")
print(res1)

xpath的谓语结构
所谓"谓语条件",就是对路径表达式的附加条件。所有的条件,都写在方括号"[]"中,表示对节点进行进一步的筛选。例如:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore><book><title lang="eng">Harry Potter</title><price>29.99</price></book><book><title lang="eng">Learning XML</title><price>39.95</price></book><book><title lang="eng">Harry Potter</title><price>29.99</price></book><book><title lang="eng">Learning XML</title><price>39.95</price></book><book><title lang="eng">Harry Potter</title><price>29.99</price></book><book><title lang="eng">Learning XML</title><price>39.95</price></book>
</bookstore>
下面从几个简单的例子让大家体会一下
- /bookstore/book[1] :表示选择bookstore的第一个book子元素。
- /bookstore/book[last()] :表示选择bookstore的最后一个book子元素。
- /bookstore/book[last()-1] :表示选择bookstore的倒数第二个book子元素。
- /bookstore/book[position()< 3] :表示选择bookstore的前两个book子元素。
- //title[@lang] :表示选择所有具有lang属性的title节点。
- //title[@lang=‘eng’] :表示选择所有lang属性的值等于"eng"的title节点。
| 函数 | 说明 | 举例 |
|---|---|---|
| contains | 选取属性或者文本包含某些字符 | //div[contains(@id, ‘data’)] 选取 id 属性包含 data 的 div 元素 //div[contains(string(), ‘支付宝’)] 选取内部文本包含“支付宝”的 div 元素 |
| starts-with | 选取属性或者文本以某些字符开头 | //div[starts-with(@id, ‘data’)] 选取 id 属性以 data 开头的 div 元素 //div[starts-with(string(), ‘银联’)] 选取内部文本以“银联”开头的 div 元素 |
| ends-with | 选取属性或者文本以某些字符开头 | //div[ends-with(@id, ‘require’)] 选取 id 属性以 require 结尾的 div 元素 //div[ends-with(string(), ‘支付’)] 选取内部文本以“支付”结尾的 div 元素 |
学习了Xpath定位后,我们下一篇将用Xpath方法爬取中图网TOP1000的图书信息啦!
相关文章:
Python爬虫——HTML中Xpath定位
Xpath是一种路径查询语言。利用一个路径表达式从html文档中找到我们需要的数据位置,进而将其写入到本地或者数据库中。 学习Xpath爬虫,我们首先学习一下python中lxml库 关于库 lxml 终端下载Xpath需要用到的模块 pip install lxml 关于HTML 超文本标…...

电脑无法识别usb设备怎么办?电脑无法识别usb解决方法
usb设备是我们常解除的外部操作以及存储设备,它可以方便用户数据传输以及操作输入。但在使用过程中,大家基本都碰到过电脑无法识别usb设备这种情况。这种情况下,我们应该怎么办呢?下面将为你介绍几种可能的原因和解决方法…...

思特奇政·企数智化产品服务平台正式发布,助力运营商政企数智能力跃迁
数字浪潮下,产业数字化进程加速发展,信息服务迎来更广阔的天地,同时也为运营商政企支撑系统提出了更高要求。12月4日,2024数字科技生态大会期间,思特奇正式发布政企数智化产品服务平台,融合应用大数据、AI等新质生产要素,构建集平台服务、精准营销、全周期运营支撑、智慧大脑于…...
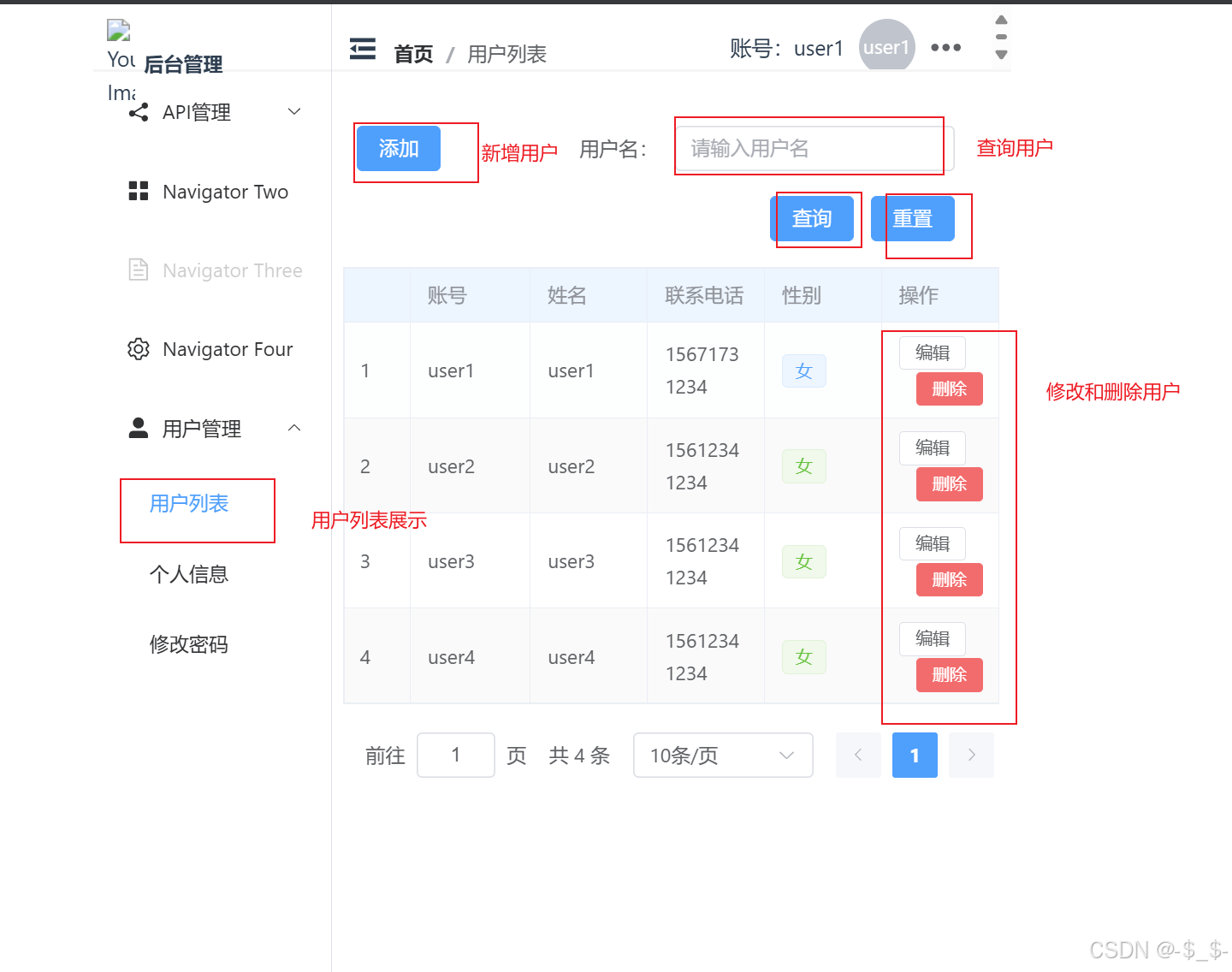
【Springboot3+vue3】从零到一搭建Springboot3+vue3前后端分离项目之前端环境搭建
【Springboot3vue3】从零到一搭建Springboot3vue3前后端分离项目之前端环境搭建 2 前端环境搭建2.1 环境准备2.2 创建Vue3项目2.3 项目搭建准备2.4 安装Element Plus2.5 安装axios2.5.1 配置(创建实例,配置请求,响应拦截器)2.5.2 …...
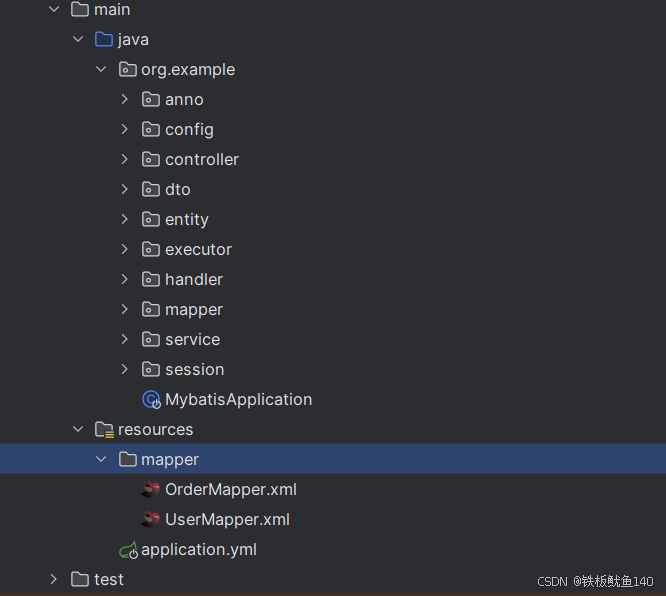
手写Mybatis框架源码(简写)
pom文件: springboot版本:2.6.5 jdk:8 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance&q…...

Flask返回中文Unicode编码(乱码)解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

最大值和最小值的差
最大值和最小值的差 C语言代码C 语言代码Java语言代码Python语言代码 💐The Begin💐点点关注,收藏不迷路💐 输出一个整数序列中最大的数和最小的数的差。 输入 第一行为M,表示整数个数,整数个数不会大于1…...
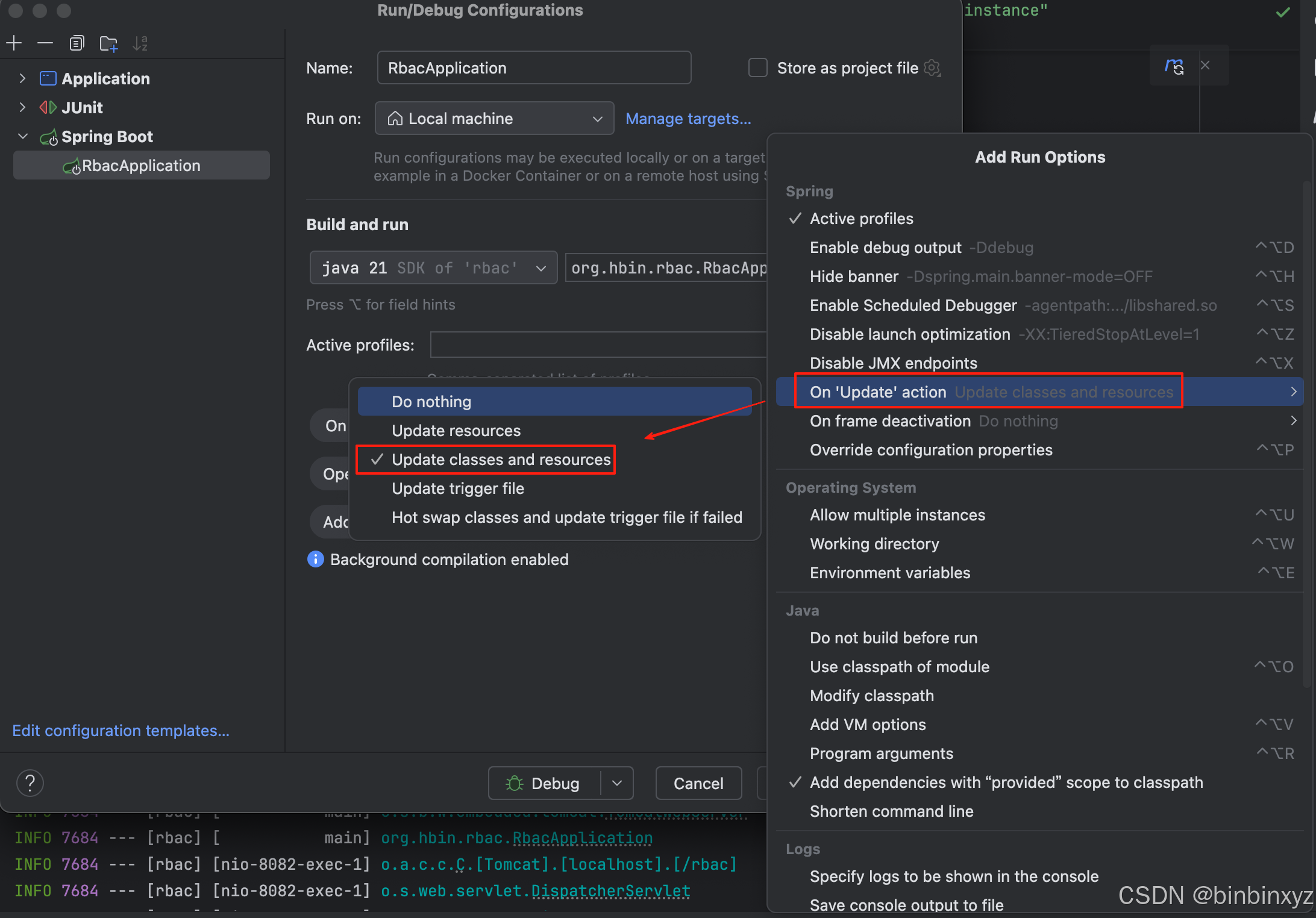
如何在 IntelliJ IDEA 中为 Spring Boot 应用实现热部署
文章目录 1. 引言2. 准备工作3. 添加必要的依赖4. 配置 IntelliJ IDEA4.1 启用自动编译4.2 开启热部署策略 5. 测试热部署6. 高级技巧7. 注意事项8. 总结 随着现代开发工具的进步,开发者们越来越重视提高生产力的特性。对于 Java 开发者来说,能够在不重启…...

探索 Java 中的 Bug 世界
在 Java 编程的旅程中,我们不可避免地会遇到各种 Bug。这些 Bug 可能会导致程序出现意外的行为、崩溃或者性能问题。了解 Java Bug 的类型、产生原因以及解决方法,对于提高我们的编程技能和开发出稳定可靠的应用程序至关重要。 一、Java Bug 的定义与分类…...

SQL面试题——百度SQL面试题 连续签到领金币
百度SQL面试题 连续签到领金币 今天的这个题目来自百度,而且这个题目很常见,是一个大家日常经常遇到的一个场景,几乎无处不在,就是签到送积分,只不过这里是签到领金币 有用户签到记录表,sign,记录用户当天是否完成签到,请计算出每个用户的每个月获得的金币数量; 签到…...
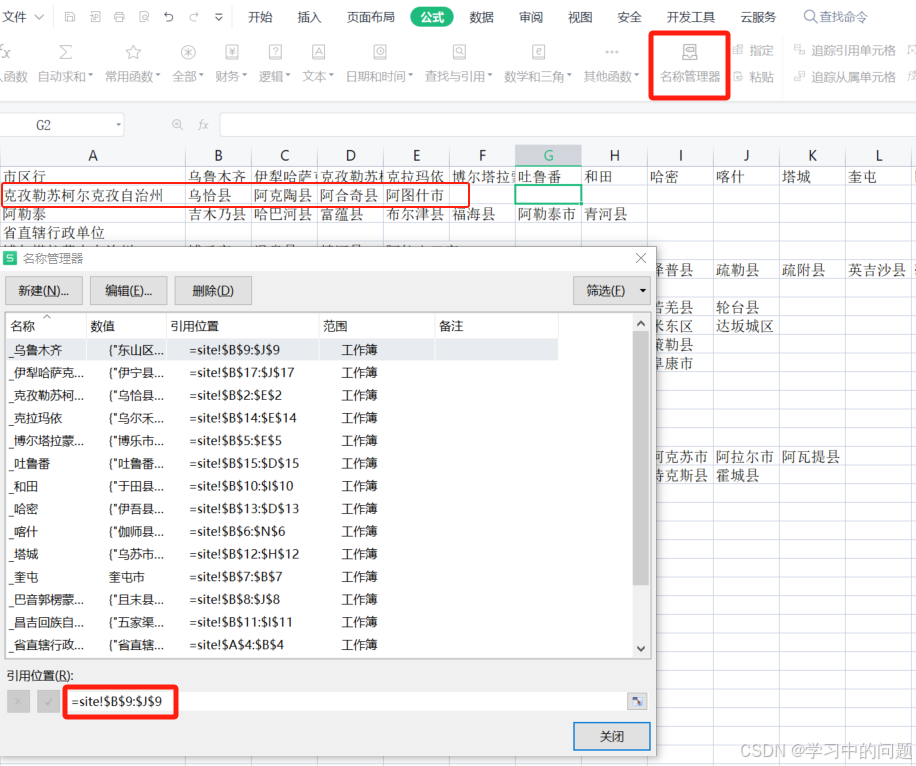
easyExcel单一下拉框和级联下拉框
文章目录: 单一下拉框级联下拉框 具体实现: 单一下拉框 public class BoolWriteHandler implements SheetWriteHandler {private List<String> dropDown;private List<Integer> indexList;public BoolWriteHandler(List<Integer> i…...
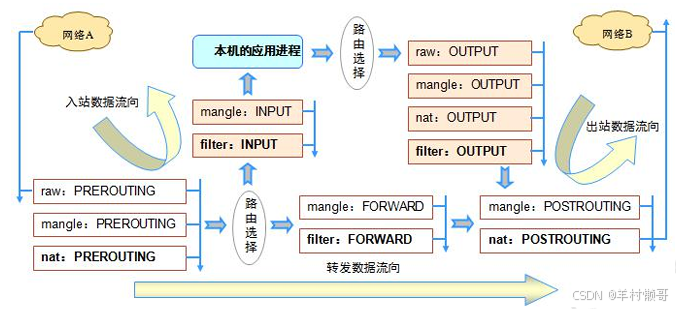
linux-安全-iptables防火墙基础笔记
目录 一、 iptables链结构 五链 二、 iptables表结构 四表 三、 匹配流程 四、 语法 五、 匹配 1. 通用匹配 2. 隐含匹配 3. 显示匹配 六、 SNAT 七、 DNAT 八、 规则备份及还原 1. 备份 2. 还原 这篇将讲解iptables防火墙的基础知识 一、 iptables链结构 规则…...
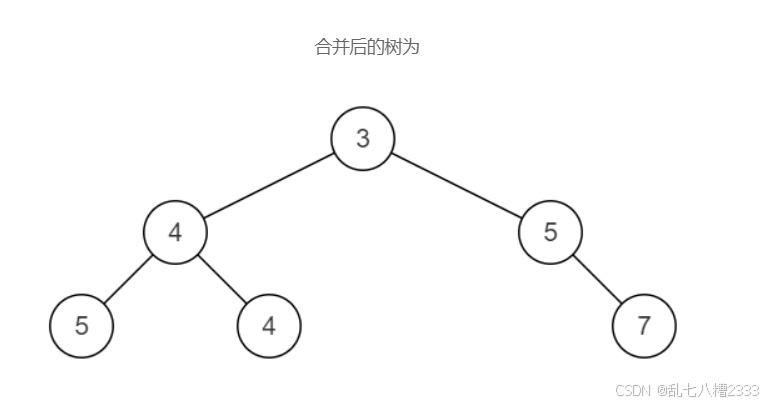
力扣刷题TOP101: 25.BM32合并二叉树
目录: 目的 思路 复杂度 记忆秘诀 python代码 目的: 已知两颗二叉树,将它们合并成一颗二叉树。合并规则是:都存在的结点,就将结点值加起来,否则空的位置就由另一个树的结点来代替。 思路 我们有两棵二…...

R的中文文本处理包--tmcn
文章目录 介绍tmcn 和 jieba 的关系函数:catUTF8toUTF8实例 介绍 tmcn 包是 R 语言中的一个用于处理和分析中文文本的包,特别适用于中文文本的分词、词频统计和文本挖掘等任务。以下是 tmcn 包的基本用法,包括安装、常用函数和示例。 一个用…...
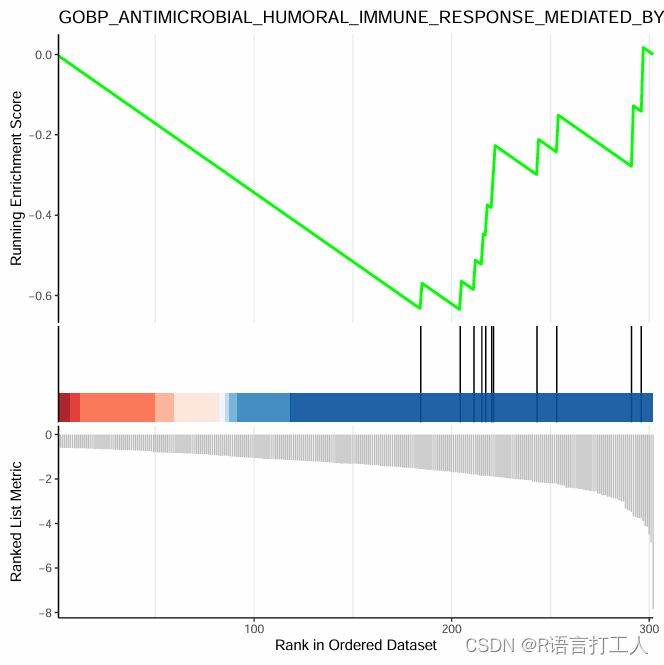
差异基因富集分析(R语言——GOKEGGGSEA)
接着上次的内容,上篇内容给大家分享了基因表达量怎么做分组差异分析,从而获得差异基因集,想了解的可以去看一下,这篇主要给大家分享一下得到显著差异基因集后怎么做一下通路富集。 1.准备差异基因集 我就直接把上次分享的拿到这…...

scrapy对接rabbitmq的时候使用post请求
之前做分布式爬虫的时候,都是从push url来拿到爬虫消费的链接,这里提出一个问题,假如这个请求是post请求的呢,我观察了scrapy-redis的源码,其中spider.py的代码是这样写的 1.scrapy-redis源码分析 def make_request_from_data(self, data):"""Returns a Reques…...
vue+elementUI+transition实现鼠标滑过div展开内容,鼠标划出收起内容,加防抖功能
文章目录 一、场景二、实现代码1.子组件代码结构2.父组件 一、场景 这两天做项目,此产品提出需求 要求详情页的顶部区域要在鼠标划入后展开里面的内容,鼠标划出要收起部分内容,详情底部的内容高度要自适应,我这里运用了鼠标事件t…...

大模型语料库的构建过程 包括知识图谱构建 垂直知识图谱构建 输入到sql构建 输入到cypher构建 通过智能体管理数据生产组件
以下是大模型语料库的构建过程: 一、文档切分语料库构建 数据来源确定: 首先,需要确定语料库的数据来源。这些来源可以是多种多样的,包括但不限于: 网络资源:利用网络爬虫技术从各种网站(如新闻…...

阿里云ECS服务器域名解析
阿里云ECS服务器域名解析,以前添加两条A记录类型,主机记录分别为www和,这2条记录都解析到服务器IP地址。 1.进入阿里云域名控制台,找到域名 ->“解析设置”->“添加记录” 2.添加一条记录类型为A,主机记录为www,…...

牛客周赛71:A:JAVA
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 题目描述 \hspace{15pt}对于给定的两个正整数 nnn 和 kkk ,是否能构造出 kkk 对不同的正整数 (x,y)(x,y)(x,y) ,使得 xynxynxyn 。 \hspace{15pt}我们认为两对正整数 (…...

企业内网虚拟机如何通过Taotoken安全接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内网虚拟机如何通过Taotoken安全接入多模型API 在许多企业的技术架构中,开发与测试环境常部署于内网虚拟机中。这些…...

Docker 的了解和使用
1. 虚拟化全虚拟化:虚拟机的操作系统可以和宿主机的操作系统完全不同。os层虚拟化:操作内核相同,软件虚拟化。2. docker安装 Docker容器本质上是Linux容器,它需要Linux内核环境才能运行。在Windows上直接运行Docker,需…...

MAX31856在工业温控项目中的实战应用:从选型、电路设计到故障诊断避坑指南
MAX31856工业温控系统设计全流程:从芯片选型到抗干扰实战 工业温度监测系统的可靠性直接关系到生产安全与产品质量。在钢铁冶炼、化工反应等场景中,一个温度传感器的失效可能导致数百万损失。MAX31856作为工业级热电偶数字转换器,其45V过压保…...

taotoken模型广场功能体验与主流模型选型建议
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken模型广场功能体验与主流模型选型建议 1. 平台入口与模型广场概览 登录Taotoken控制台后,最直观的功能入口之一…...

告别电网波动干扰:手把手教你用双同步坐标系锁相环搞定不平衡电压
告别电网波动干扰:手把手教你用双同步坐标系锁相环搞定不平衡电压 当光伏逆变器在阴天突然遭遇电网电压跌落,或是风电变流器面对负载突变导致的相位抖动时,工程师的控制台前总会亮起刺眼的警报灯。这种三相电压不平衡的工况,就像在…...

全网没人敢说,关于中小企业AI营销一体机到底是卖硬件还是卖落地闭环的屎盆子,我先扣为敬。
[实话] 干这行十年,我拍着桌子定过一条死规矩。三个不做:不做只卖盒子不管结果的,不做签完合同就消失的,不做让你自己研究三个月才能用的。[实话] 现在的“AI营销一体机”,90%都是在收智商税。我见过太多老板ÿ…...

打破高频、高速四种材料混压
打破高频、高速四种材料混压,铸就PCB行业硬核实力。在航空航天领域,每一次技术的突破都意味着对材料与工艺的极致追求。今天,我们要聊的这款产品,堪称多材料混压天花板,——16层、四种材料混压、三次压合、板厚5.0mm、…...
完全解析:从原理到代码,深入浅出)
DDR3内存训练(Training)完全解析:从原理到代码,深入浅出
DDR3内存训练(Training)完全解析:从原理到代码,深入浅出 目录 一、为什么需要内存训练? 二、DDR3训练的核心原理 三、训练流程详解:一场精密的三步仪式 四、代码实战:从初始化到训练完成...

C#元组类型简介
元组是 C# 7.0 引入的轻量级数据结构,用于临时组合多个值,无需定义专门的类或结构。 元组是有序的数据结构,成员按声明/创建时的顺序排列。(这里的元组只指值元组)元组类型在C#7.0前是有一个专门的内置类型,…...

基于物理信息神经网络与降阶模型的文物数字孪生保护框架
1. 项目概述:当文化遗产保护遇上科学计算与人工智能最近几年,我一直在关注一个交叉领域:如何用前沿的计算科学和人工智能技术,去解决那些看似传统、实则充满挑战的文物保护难题。这次分享的“基于SciML与数字孪生的文化遗产保护框…...