【Spark】Spark的两种核心Shuffle工作原理详解
Spark 的shuffle机制
一、Spark ShuffleManager 发展历程
- Spark 1.1.0 之前
- 在 Spark 1.1.0 之前,Spark 使用 BlockStoreShuffleFetcher 来处理 Shuffle 操作。这个实现主要依赖于直接从 BlockManager 获取 Shuffle 数据,并通过网络进行交换。

- 在 Spark 1.1.0 之前,Spark 使用 BlockStoreShuffleFetcher 来处理 Shuffle 操作。这个实现主要依赖于直接从 BlockManager 获取 Shuffle 数据,并通过网络进行交换。
- Spark 1.1.x(默认使用 HashShuffleManager)
- HashShuffleManager 使用哈希算法将数据划分到不同的分区。在进行 Shuffle 操作时,Spark 会为每个键计算一个哈希值,然后根据该值将数据分配到相应的分区。

- HashShuffleManager 使用哈希算法将数据划分到不同的分区。在进行 Shuffle 操作时,Spark 会为每个键计算一个哈希值,然后根据该值将数据分配到相应的分区。
- Spark 1.2.x 及以后版本(默认使用 SortShuffleManager)
- Spark 2.0.x 及以后版本(不在使用HashShuffleManager,默认使用 SortShuffleManager)


二、HashShuffleManager 原理
假设:每个
Executor只有1个CPU core,也就是说,无论这个Executor上分配多少个task
线程,同一时间都只能执行一个task线程。
- 未经优化的HashShuffleManager工作原理

1.Shuffle Write 阶段
- 将每个task处理的数据按照key进行hash算法,从而将相同key都写入同一个磁盘文件,而每一个磁盘文件都只属于下游stage的一个task,在数据写入磁盘之前,会现将数据写入内存缓冲区中,当内存缓冲区填满以后,才会溢写到磁盘文件中去。
- 下一个stage的task有多少个,当前stage的每个task就要创建多少分磁盘文件,比如当前stage有20个task,总共有4个Executor,每个Executor执行5个task,下一个stage总共有40个task,那么每个Executor上就要创建200个磁盘文件,所有Executor会创建800个磁盘文件,由此可见,未经过优化的shuffle write操作所产生的磁盘文件数据是惊人的。
2. Shuffle Read 阶段
- 将上一个stage的计算结果中所有相同的key,从各个节点上通过网络都拉取到自己所在的节点上,然后按照key进行聚合或连接等操作。
- 由于shuffle write阶段,map task给下游stage的每个reduce task都创建了一个磁盘文件,因此shuffle read阶段,每个reduce task只要从上游stage的所有map task所在节点上拉取属于自己的那个磁盘文件即可。
- shuffle read的拉取过程是一边拉取一边聚合的,每个shuffle read task都有一个自己的buffer缓冲,每次只能拉取与buffer缓冲相同大小的数据,然后在内存中进行聚合等操作,聚合完一批数据,再拉取下一批,以此类推,直接所有数据拉取完,并得到最终结果。
- 优化后的HashShuffleManager工作原理

为了优化 HashShuffleManager,可以启用参数
spark.shuffle.consolidateFiles,该参数的默认值为false,启用后设置为true,可以启动优化机制。开启优化机制后的效果:
1.Shuffle Write 阶段
- 在 shuffle write 过程中,task就不是为下游stage的每个task创建一个磁盘文件了,此时会出现shuffleFileGroup的概念,每个shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。
- 一个Executor上有多少个 CPU core,就可以并行执行多少个task。而第一批并行执行的每个task都会创建一个 shuffleFileGroup,并将数据写入对应的磁盘文件内。
- 当执行下一批task时,下一批task就会复用之前已有的 shuffleFileGroup,包括其中的磁盘文件。
- consolidate 机制允许不同的task复用同一批磁盘文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升 shuffle write 的性能。
- 比如当前stage有20个task,总共有4个Executor,每个Executor执行5个task,下一个stage总共有40个task,那么每个Executor上就要创建40个磁盘文件,所有Executor会创建160个磁盘文件,由此可见,优化后shuffle write操作所产生的磁盘文件较优化前明显减少。
2. Shuffle Read 阶段
- 由于shuffle write阶段,每个Executor仅为下游每个reduce task创建一个磁盘文件,在shuffle read阶段,每个reduce task只要从上游stage的所有map task所在节点上拉取属于自己的那个磁盘文件即可。
三、SortShuffleManager 原理
SortShuffleManager 的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。 当 shuffle
read task 的数量小于等于 spark.shuffle.sort.bypassMergeThreshold参数(默认为
200)的值且不是聚合类的shuffle算子时,就会启用 bypass 机制。
- 普通运行机制的SortShuffleManager工作原理

- 在该模式下,数据会先写入一个内存数据结构中,此时根据不同的 shuffle 算子, 可能选用不同的数据结构。如果是 reduceByKey 这种聚合类的 shuffle 算子,那么会 选用 Map 数据结构,一边通过 Map 进行聚合,一边写入内存;如果是join 这种普通的 shuffle 算子,那么会选用 Array 数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。在溢写到磁盘文件之前,会先根据 key 对内存数据结构中已有的数据进行排序。 排序过后,会分批将数据写入磁盘文件。默认的 batch 数量是10000 条,也就是说,排序好的数据,会以每批 1 万条数据的形式分批写入磁盘文件。写入磁盘文件是通 过 Java 的BufferedOutputStream 实现的。BufferedOutputStream 是 Java的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲填满之后再一次写入磁盘文件中,这样可以减少磁盘 IO 次数,提升性能。
- 一个 task 将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作, 也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是 merge 过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最 终的磁盘文件之中。此外,由于一个 task就只对应一个磁盘文件,也就意味着该 task 为下游 stage 的 task 准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个 task 的数据在文件中的 start offset 与 end offset。
- SortShuffleManager 由于有一个磁盘文件 merge 的过程,因此大大减少了文件数量。比如第一个 stage 有 20 个 task,总共有 4 个 Executor,每个 Executor 执行 5 个 task,而第二个 stage 有 40 个 task。由于每个 task 最终只有一个磁盘文件,因此 此时每个 Executor 上只有 5 个磁盘文件,所有 Executor 只有
20 个磁盘文件。
- bypass运行机制的SortShuffleManager工作原理

- 每个 task 会为每个下游 task 都创建一个临时磁盘文件,并将数据按 key进行 hash 然后根据 key 的 hash 值,将 key 写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
- 该过程的磁盘写机制其实跟未经优化的 HashShuffleManager 是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此 少量的最终磁盘文件,也让该机制相对未经优化的 HashShuffleManager 来说,shuffle read 的性能会更好。
- 而该机制与普通 SortShuffleManager 运行机制的不同在于:第一,磁盘写机制 不同;第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write
过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
相关文章:
【Spark】Spark的两种核心Shuffle工作原理详解
Spark 的shuffle机制 一、Spark ShuffleManager 发展历程 Spark 1.1.0 之前 在 Spark 1.1.0 之前,Spark 使用 BlockStoreShuffleFetcher 来处理 Shuffle 操作。这个实现主要依赖于直接从 BlockManager 获取 Shuffle 数据,并通过网络进行交换。 Spark …...

TCP 的文化内涵
从历史和文化内涵的视角看 TCP 协议的优势和局限,这些都刻在基因里。节约和经济获得向下兼容,但这也意味着它没有浪费带宽的本意,任何相左的优化策略终将遇到无法解决的困难,大致就这样,这为设计新协议提了意见&#x…...

ASP.NET |日常开发中读写XML详解
ASP.NET |日常开发中读写XML详解 前言一、XML 概述1.1 定义和结构1.2 应用场景 二、读取 XML 文件2.1 使用XmlDocument类(DOM 方式)2.2 使用XmlReader类(流方式) 三、写入 XML 文件3.1 使用XmlDocument类3.2 使用XmlWr…...

Less和SCSS,哪个更好用?
前言 Less 和 SCSS 都是流行的 CSS 预处理器,它们的目的都是扩展 CSS 的功能,使样式表更具组织性、可维护性和可重用性。虽然它们有许多相似之处,但在语法、特性和工作方式上也存在一些差异。 Less Less 是一种动态样式表语言,…...

第一个C++程序--(蓝桥杯备考版)
第一个C程序 基础程序 #include <iostream>//头⽂件 using namespace std;//使⽤std的名字空间 int main()//main函数 {cout << "hello world!" << endl; //输出:在屏幕打印"hello world!" return 0;}main函数 main 函数是…...

NanoLog起步笔记-7-log解压过程初探
nonolog起步笔记-6-log解压过程初探 再看解压过程建立调试工程修改makefile添加新的launch项 注:重新学习nanolog的README.mdPost-Execution Log Decompressor 下面我们尝试了解,解压的过程,是如何得到文件头部的meta信息的。 再看解压过程 …...

【MySQL 进阶之路】基础语法及优化技巧
MySQL DML 基础语法及优化技巧 一、DML(数据操作语言)概述 DML 是数据库操作语言的子集,用于数据的增、删、改、查四个基本操作。MySQL 中的 DML 操作通常是指以下四种基本操作: INSERT:插入数据SELECT:…...

微信小程序做电子签名功能
文章目录 最近需求要做就记录一下。 人狠话不多,直接上功能: 直接搂代码吧,复制过去就可以用,有其他需求自己改吧改吧。 signature.wxml <!-- 电子签名页面 --> <custom-navbar title"电子签名"show-home"{{fals…...

PR的选择与移动
选择工具 可以选择序列上的剪辑,如果需要多选可以按住shift键选中多个剪辑 CtrlA:可以进行全选 编组 选中多个剪辑后“右键-编组“可以将所选的剪辑连接在一起。这时单击任意剪辑都可以选中全部 向前选择轨道工具与向后选择轨道工具 向前选择轨道工具…...

Linux系统 —— 进程系列 - 进程状态 :僵尸与孤儿
目录 1. 进程状态的概念 1.1 课本上的说法:名词提炼 1.2 运行,阻塞和挂起 1.2.1 什么叫做运行状态(running)? 1.2.2 什么叫做阻塞状态(sleeping)? 1.2.3 什么叫做挂起状态&…...

linux/centOS7用户和权限管理笔记
linux系列中可以: 配置多个用户配置多个用户组用户可以加入多个用户中 linux中关于权限的管理级别有2个级别,分别是: 针对用户的权限控制针对用户组的权限控制 一,root用户 root用户拥有最大的系统操作权限,而普通…...

使用C#基于ADO.NET编写MySQL的程序
MySQL 是一个领先的开源数据库管理系统。它是一个多用户、多线程的数据库管理系统。MySQL 在网络上特别流行。MySQL 数据库可在大多数重要的操作系统平台上使用。它可在 BSD Unix、Linux、Windows 或 Mac OS 上运行。MySQL 有两个版本:MySQL 服务器系统和 MySQL 嵌入…...

Scala函数的泛型
package hfd //泛型 //需求:你是一个程序员,老板让你写一个函数,用来获取列表中的中间元素 //List(1,2,3,4,5)>中间元素的下标长度/2 >3 //getMiddleEle object Test38_5 {def print1():Unit{println(1)}def print2(): Unit {println(…...

云轴科技ZStack亮相中国生成式AI大会上海站 展现AI Infra新势力
近日,以“智能跃进,创造无限”为主题的2024中国生成式AI大会在上海举办。本次大会由上海市人工智能行业协会指导,智东西、智猩猩共同发起,邀请了人工智能行业的顶尖嘉宾汇聚一堂,以前瞻性视角解构和把脉生成式AI的技术…...

态感知与势感知
“态感知”和“势感知”是两个人机交互中较为深奥的概念,它们虽然都与感知、认知相关,但侧重点不同。下面将从这两个概念的定义、区分以及应用领域进行解释: 1. 态感知 态感知通常指的是对事物当前状态、属性或者内在特征的感知。它强调的是在…...

汽车零部件设计之——发动机曲轴预应力模态分析仿真APP
汽车零部件是汽车工业的基石,是构成车辆的基础元素。一辆汽车通常由上万件零部件组成,包括发动机系统、传动系统、制动系统、电子控制系统等,它们共同确保了汽车的安全、可靠性及高效运行。在汽车产业快速发展的今天,汽车零部件需…...

谷歌浏览器的网页数据导出与导入方法
谷歌浏览器是全球最受欢迎的网络浏览器之一,它不仅提供了快速、安全的浏览体验,还拥有丰富的功能和扩展程序。本文将详细介绍如何在Chrome浏览器中导出和导入网页数据,同时涵盖一些相关的实用技巧,如调试JavaScript、自动填充表单…...
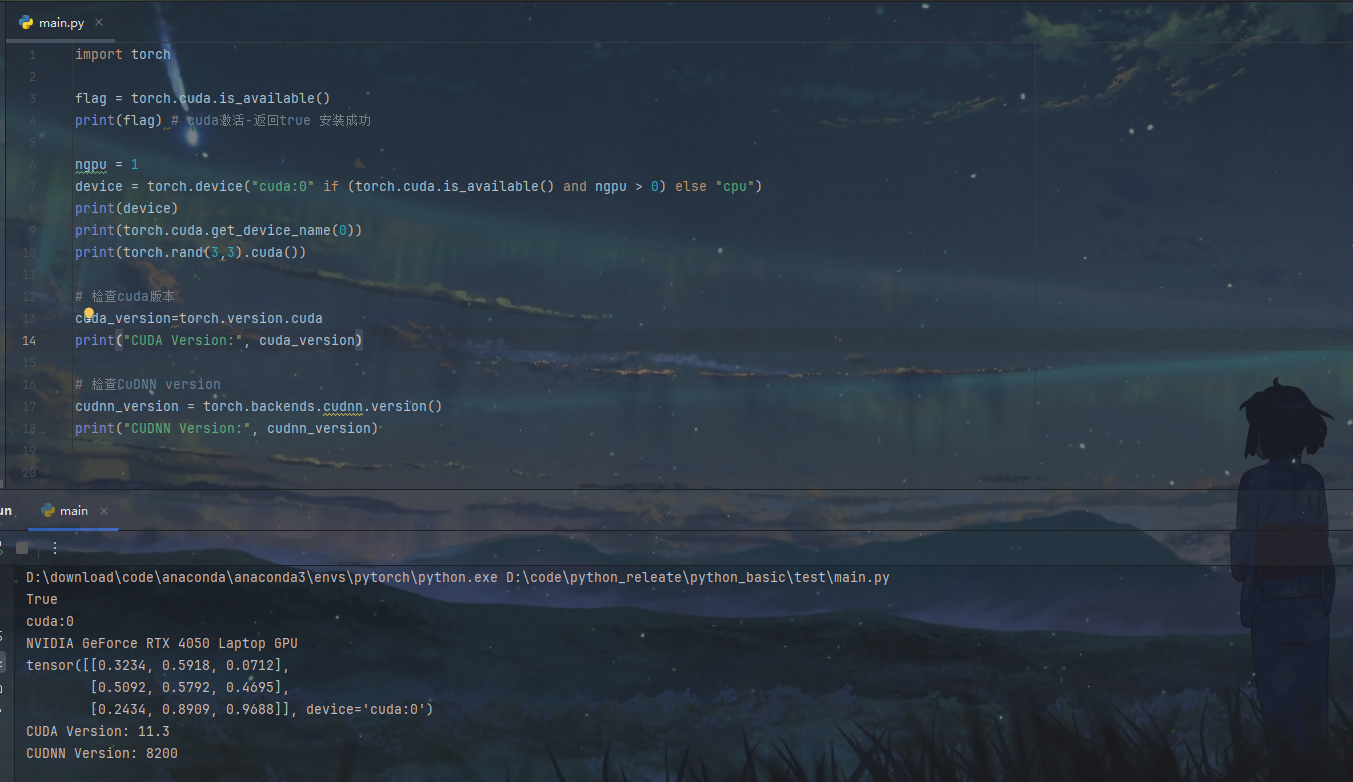
pytroch环境安装-pycharm
环境介绍 安装pycharm 官网下载即可,我这里已经安装,就不演示了 安装anaconda 【官网链接】点击下载 注意这一步选择just me 这一步全部勾上 打开 anaconda Prompt 输入conda create -n pytorch python3.8 命令解释:创建一个叫pytorch&…...

【大模型】PostgreSQL是向量数据库吗
PostgreSQL(通常简称为 Postgre)本身并不是一个专门的向量数据库,但它可以通过扩展或插件支持向量数据的存储、检索和处理,因此可以在某些场景下作为向量数据库使用。以下是关于 PostgreSQL 是否可以作为向量数据库的详细说明&…...
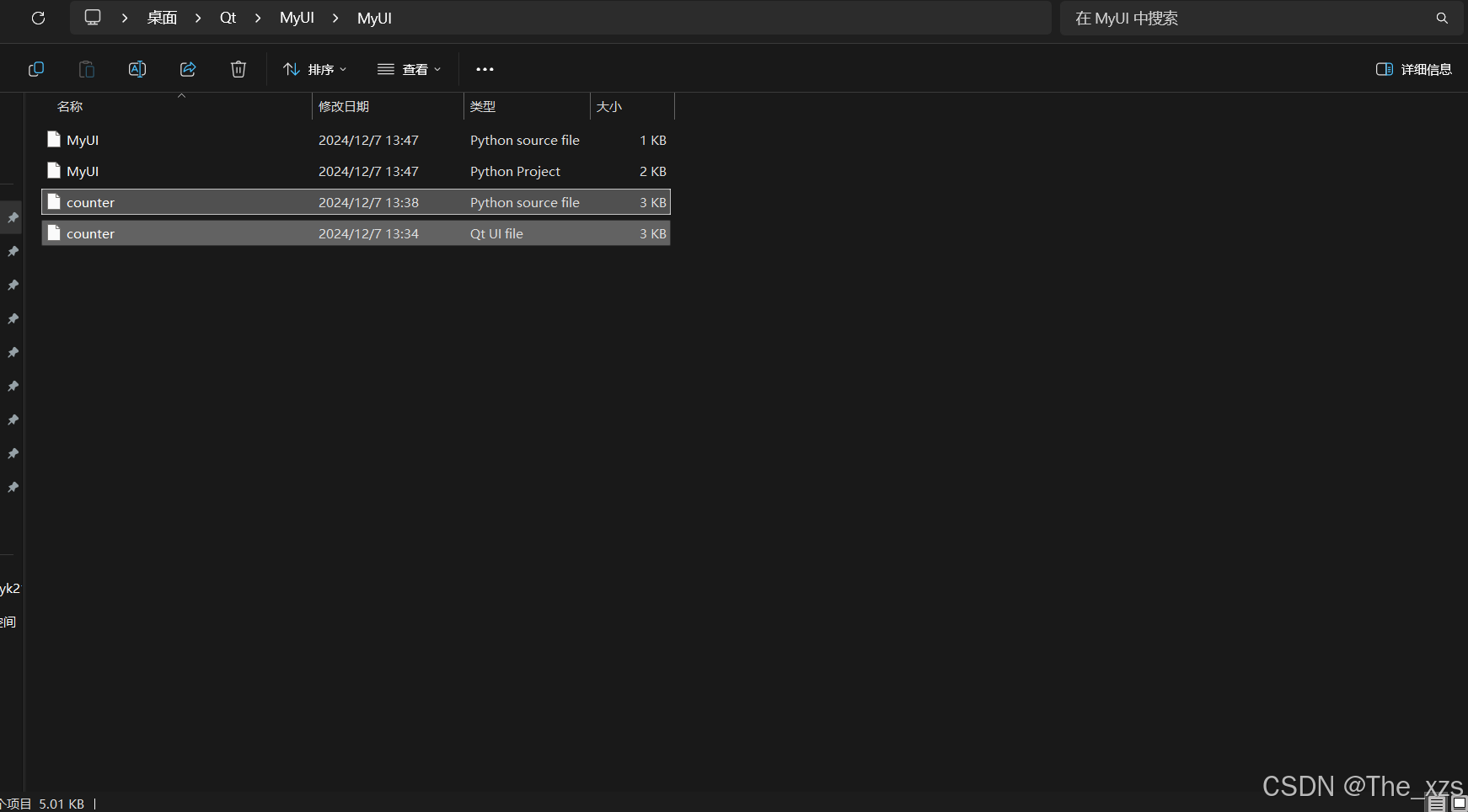
【PyQt5教程 一】Qt Designer 安装及其使用方法说明,附程序源码
目录 一、PyQt5介绍: (1)PyQt简介: (2)PyQt API: (3)支持的环境: (4)安装: (5)配置环境变量…...

本地部署YakGPT:打造私有化ChatGPT前端,实现语音交互与数据安全
1. 项目概述:为什么我们需要一个本地运行的ChatGPT UI? 如果你和我一样,已经深度依赖ChatGPT来处理日常工作,从代码调试到文案构思,那你肯定也经历过官方网页端那令人捉急的加载速度,或者在移动端上打字的…...

HolmesGPT 值不值得跟?把 AI SRE 的七强格局摊开看
CNCF Sandbox 在 2025-10 收了一个项目叫 HolmesGPT,定位是"开源 SRE Agent"。看着像下一个值得跟的风口——但同样进了 Sandbox 的 k8sgpt 已经 7,746 星,比它早一年;新来的 kagent 背靠 Solo.io,2,716 星只用了一年就…...

STM32时钟树配置避坑指南:从HSE到PLL,手把手教你调出72MHz系统时钟
STM32时钟树配置避坑指南:从HSE到PLL,手把手教你调出72MHz系统时钟 第一次接触STM32的时钟系统时,我盯着数据手册上那张复杂的时钟树图看了整整一个下午,脑子里全是问号。为什么需要这么多时钟源?PLL到底是怎么工作的&…...

NVIDIA Profile Inspector终极指南:解锁显卡隐藏性能的完整配置手册
NVIDIA Profile Inspector终极指南:解锁显卡隐藏性能的完整配置手册 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专为技术爱好者和进阶用户设计的开源显卡…...

dnGrep搜索结果分析与报告生成:如何导出和分享搜索数据
dnGrep搜索结果分析与报告生成:如何导出和分享搜索数据 【免费下载链接】dnGrep Graphical GREP tool for Windows 项目地址: https://gitcode.com/gh_mirrors/dn/dnGrep dnGrep是一款强大的Windows图形化GREP搜索工具,它不仅能够快速搜索文件内容…...
)
【奇点智能大会·治理白皮书首发】:基于27家头部AI企业的服务治理数据,验证出唯一有效的3维可观测性模型(QPS/Token耗时/上下文漂移)
更多请点击: https://intelliparadigm.com 第一章:大模型服务治理:奇点智能大会 在2024年奇点智能大会上,大模型服务治理成为核心议题。随着LLM推理服务规模化部署,如何统一调度、细粒度限流、多租户隔离与可观测性闭…...

Redis模糊查询实战:从keys到scan的演进与避坑指南
1. Redis模糊查询的生死抉择:keys命令的血泪教训 那天凌晨三点,我被急促的电话铃声惊醒。线上订单系统突然卡死,监控大屏一片飘红。登录服务器后用redis-cli --latency检测,发现Redis响应时间高达2000ms!紧急排查后发现…...

N_m3u8DL-RE终极实战指南:三步破解流媒体下载技术难题
N_m3u8DL-RE终极实战指南:三步破解流媒体下载技术难题 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

别再手动K帧了!Maya路径动画保姆级教程,5分钟让模型丝滑走位
Maya路径动画终极指南:告别手动K帧,实现模型智能运动 在三维动画制作中,让角色或物体沿着预设路径运动是一个常见需求。无论是制作蛇形移动的生物、赛车漂移轨迹,还是摄像机漫游动画,路径动画都能大幅提升工作效率。传…...

如何3步搞定QQ音乐、网易云音乐加密文件,让你的音乐真正属于你
如何3步搞定QQ音乐、网易云音乐加密文件,让你的音乐真正属于你 【免费下载链接】unlock-music-electron Unlock Music Project - Electron Edition 在Electron构建的桌面应用中解锁各种加密的音乐文件 项目地址: https://gitcode.com/gh_mirrors/un/unlock-music-…...