cnocr配置及训练测试
cnocr配置及训练测试
- 1,相关链接
- 2,已有模型调用测试
- (1)下载相关模型
- (2)Cnstd文本检测模型
- (3)模型调用解析脚本
- 3,自定义数据集训练测试
- (1)标签转换
- (1-1)标签转换脚本labelme2cnocr.py
- (1-2)转换为cnocr数据集
- (2)训练
- (2-1)训练命令
- (2-2)训练结果
- (2-3)训练日志可视化(可略过)
- (3)测试
- (3-1)测试脚本
- (3-2)测试结果
1,相关链接
https://gitee.com/cyahua/cnocr/
cyahua / cnocr
https://github.com/breezedeus/CnOCR#%E5%8F%AF%E4%BD%BF%E7%94%A8%E7%9A%84%E8%AF%86%E5%88%AB%E6%A8%A1%E5%9E%8B
使用英文和数字的模型
https://zhuanlan.zhihu.com/p/660022852
CnOCR 纯数字识别新模型(里面包含博主自定义训练的硬币数据集)
纯英文模型检测精度更高,适用于检测字符相关
2,已有模型调用测试
(1)下载相关模型
https://zhuanlan.zhihu.com/p/660022852

https://pan.baidu.com/s/1wvIjbjw95akE-h_o1HQd9w?pwd=nocr&at=1703123910772#list/path=%2F

(2)Cnstd文本检测模型
https://github.com/breezedeus/cnstd
由此可知cnocr其内部文本检测使用的就是cnstd工具包,而进行cnocr训练的只有识别模型



(3)模型调用解析脚本
手写解析功能用于测试
from cnocr import CnOcr
import cv2#https://gitee.com/cyahua/cnocr?_from=gitee_search
#专用英文的模型#img_fp = './docs/examples/huochepiao.jpeg'
img_fp = 'E:/tupian/ocr2/O16.bmp'ocr = CnOcr(det_model_name='en_PP-OCRv3_det', rec_model_name='en_PP-OCRv3') # 所
out = ocr.ocr(img_fp)print(out)# 结果处理
#绘制矩形框到图像
# img2 = img_fp.copy()
img_fp2 = cv2.imread(img_fp)
results = ''
for output in out:result_text = output['text']result_position = output['position']# #数组转换成列表list_position = result_position.tolist()print(list_position)print(type(list_position))p0 = (int(list_position[0][0]),int(list_position[0][1]))p1 = (int(list_position[1][0]),int(list_position[1][1]))p2 = (int(list_position[2][0]),int(list_position[2][1]))p3 = (int(list_position[3][0]),int(list_position[3][1]))print(p0)print(p1)print(p2)print(p3)color_l = (0, 200, 0)thickness_l = 2cv2.line(img_fp2, p0, p1, color_l, thickness_l)cv2.line(img_fp2, p1, p2, color_l, thickness_l)cv2.line(img_fp2, p2, p3, color_l, thickness_l)cv2.line(img_fp2, p3, p0, color_l, thickness_l)font = cv2.FONT_HERSHEY_SIMPLEXfontScale = 1color = (255, 0, 0)thickness = 2cv2.putText(img_fp2, result_text, p0, font, fontScale, color, thickness, cv2.LINE_AA)cv2.imshow('demo',img_fp2)
cv2.waitKey(0)
相关测试结果

3,自定义数据集训练测试
(1)标签转换
(1-1)标签转换脚本labelme2cnocr.py
import cv2
import os
import csvinput_path = "E:/tupian/ocr2/ocr_data"
output_path = "./data"
ratio = 0.1#拆分列表
def split_list(lst, ratios, num_splits):"""将列表按照指定比例和数量拆分成子列表:param lst: 待拆分列表:param ratios: 每个子列表的元素占比,由小数表示的列表:param num_splits: 子列表的数量:return: 拆分后的子列表组成的列表"""if len(ratios) != num_splits:raise ValueError("The length of ratios must equal to num_splits.")total_ratio = sum(ratios)if total_ratio != 1:raise ValueError("The sum of ratios must be equal to 1.")n = len(lst)result = []start = 0for i in range(num_splits):end = start + int(n * ratios[i])result.append(lst[start:end])start = endreturn resultdef read_path(input_path,output_path,ratio):#遍历该目录下的所有图片文件train_list = []for filename in os.listdir(input_path):if '.jpg' in filename:img_filename = filenameimg_path = input_path +'/' + filenametxt_path = input_path +'/' + filename.replace('.jpg','.txt')img_output_path = output_path + "/images/" + img_filenameif not os.path.exists(output_path + "/images"):os.makedirs(output_path + "/images")print(img_path)print(txt_path)#读取保存图像img = cv2.imread(img_path)cv2.imwrite(img_output_path, img)#读取txt文件并保存到tsv#中间用tab隔开(字符空格隔开,使用space表示空格)label = ''with open(txt_path, "r", encoding='utf-8') as f:# read():读取文件全部内容,以字符串形式返回结果data = f.read()for char in data:if char == ' ':char = '<space>'label = label + char + ' 'label = label.replace(' \n ','')print(label)name_label_list =[]name_label_list.append(img_filename)name_label_list.append(label)print(name_label_list)train_list.append(name_label_list)#按照比例分割开ratios = [1-ratio, ratio]num_splits = 2result = split_list(train_list, ratios, num_splits)#其中,train.tsv是待创建的文件名或项目文件夹中已有的文件名,‘w’代表写入,指定newline=’‘是为了避免每写出一行数据就会有一个空行,delimiter代表分隔符,tsv的分隔符为’\t’,csv的分隔符为’,’。with open(output_path + '/train.tsv', 'w', newline='') as tsvfile:writer = csv.writer(tsvfile, delimiter='\t')writer.writerows(result[0])with open(output_path + '/dev.tsv', 'w', newline='') as tsvfile:writer = csv.writer(tsvfile, delimiter='\t')writer.writerows(result[1])#注意*处如果包含家目录(home)不能写成~符号代替
#必须要写成"/home"的格式,否则会报错说找不到对应的目录
#读取的目录
read_path(input_path, output_path, ratio)
#print(os.getcwd())
(1-2)转换为cnocr数据集

会生成三个文件,images是图像,dev.tsv是测试集,train.tsv是训练集


(2)训练
(2-1)训练命令

使用cpu进行的训练
(venv) PS G:\pyproject\CnOCR-master> cnocr train -m densenet_lite_136-fc -p data/densenet_lite_136-fc/cnocr-v2.2-densenet_lite_136-fc-epoch=039-complete_match_epoch=0.8597-model.ckpt --index-dir data --train-config-fp data/train_con
fig.json

(2-2)训练结果


(2-3)训练日志可视化(可略过)
https://blog.csdn.net/qq_44864833/article/details/131295460
wandb快速上手、使用心得(超好用的Tensorboard高替品)

离线训练完成后,可以通过wandb sync将相关日志文件上传,然后在线查看



https://wandb.ai/authorize
登录上方创建账号和key


(3)测试
(3-1)测试脚本
from cnocr import CnOcr
import cv2
import os#https://gitee.com/cyahua/cnocr?_from=gitee_search
#专用英文的模型def detect_imgs(input_path,output_path):for filename in os.listdir(input_path):if ('.jpg' in filename) or ('.png' in filename) or ('.bmp' in filename):img_filename = filenameimg_fp = input_path + '/' + filenametxt_path = input_path + '/' + filename.replace('.jpg', '.txt')img_output_path = output_path + "/outimgs/" + img_filenameif not os.path.exists(output_path + "/outimgs"):os.makedirs(output_path + "/outimgs")#img_fp = './docs/examples/huochepiao.jpeg'# img_fp = 'E:/tupian/ocr2/O7.bmp'# #使用已有的模型# ocr = CnOcr(det_model_name='en_PP-OCRv3_det', rec_model_name='en_PP-OCRv3') # 所en_PP-OCRv3 , en_number_mobile_v2.0, number-densenet_lite_136-fc# out = ocr.ocr(img_fp)# print(out)training_model_fp = "G:/pyproject/CnOCR-master/runs/CnOCR-Rec/5b5uka01/checkpoints/last.ckpt"# #调用自训练的识别模型,对原数据集进行验证(验证使用单行不要使用检测模型)ocr = CnOcr(rec_model_fp=training_model_fp, rec_model_backend='pytorch') # 调用训练好的识别模型(使用单行的进行)#ocr = CnOcr(rec_model_name='en_PP-OCRv3')out = ocr.ocr_for_single_line(img_fp)# print(out)# results = '--' + out['text']# img_fp2 = cv2.imread(img_fp)# cv2.imwrite(img_output_path, img_fp2)#调用配置好的模型(使用已有的检测模型en_PP-OCRv3_det,效果并不是很好,在原数据集上)#####################################################################ocr = CnOcr(det_model_name = 'en_PP-OCRv3_det', rec_model_name = 'densenet_lite_136-fc', rec_model_fp = training_model_fp, rec_model_backend = 'pytorch') # 所en_PP-OCRv3 , en_number_mobile_v2.0ocr = CnOcr(det_model_name='en_PP-OCRv3_det', rec_model_fp=training_model_fp, rec_model_backend = 'pytorch') #调用训练好的模型out = ocr.ocr(img_fp)#结果处理#绘制矩形框到图像img_fp2 = cv2.imread(img_fp)results = ''for output in out:result_text = output['text']result_position = output['position']# #数组转换成列表list_position = result_position.tolist()print(list_position)print(type(list_position))p0 = (int(list_position[0][0]),int(list_position[0][1]))p1 = (int(list_position[1][0]),int(list_position[1][1]))p2 = (int(list_position[2][0]),int(list_position[2][1]))p3 = (int(list_position[3][0]),int(list_position[3][1]))print(p0)print(p1)print(p2)print(p3)color_l = (0, 200, 0)thickness_l = 2cv2.line(img_fp2, p0, p1, color_l, thickness_l)cv2.line(img_fp2, p1, p2, color_l, thickness_l)cv2.line(img_fp2, p2, p3, color_l, thickness_l)cv2.line(img_fp2, p3, p0, color_l, thickness_l)font = cv2.FONT_HERSHEY_SIMPLEXfontScale = 1color = (255, 0, 0)thickness = 2cv2.putText(img_fp2, result_text, p0, font, fontScale, color, thickness, cv2.LINE_AA)results = results + '--' + result_text#cv2.imshow('demo',img_fp2)cv2.imwrite(img_output_path,img_fp2)#cv2.waitKey(0)############################################################################################################string_txt = img_output_path.replace('.jpg','') + '_'+ results + '.txt'print(string_txt)with open(string_txt, 'w') as tsvfile:tsvfile.write(results)#input_path = 'G:/pyproject/CnOCR-master/data/images'
input_path = 'E:/tupian/ocr2'
output_path = 'G:/pyproject/CnOCR-master/data'detect_imgs(input_path,output_path)
(3-2)测试结果
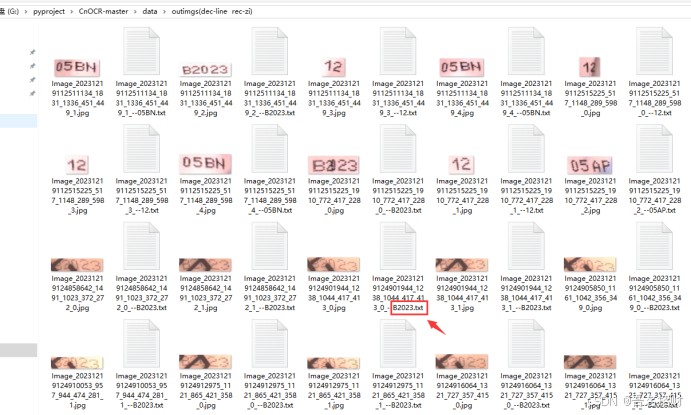
使用预训练模型训练300轮次左右得到的测试效果如下,被遮挡的文字识别也是比较准确的。
相关文章:
cnocr配置及训练测试
cnocr配置及训练测试 1,相关链接2,已有模型调用测试(1)下载相关模型(2)Cnstd文本检测模型(3)模型调用解析脚本 3,自定义数据集训练测试(1)标签转换…...

解决 Flutter 在 Mac 上的编译错误
解决 Flutter 在 Mac 上的编译错误 在使用 Flutter 进行项目开发并尝试在 Mac 设备上进行编译时,遇到了一系列的错误信息,这些错误信息给项目的构建与部署带来了阻碍。 一、错误详情 在编译过程中,Xcode 输出了大量的信息,其中…...
MR30分布式IO在新能源领域加氢站的应用
导读 氢能被誉为21世纪最具发展潜力的清洁能源,氢能科技创新和产业发展持续得到各国青睐。氢能低碳环保,燃烧的产物只有水,是用能终端实现绿色低碳转型的重要载体。氢能产业链分别为上游制氢、中游储运以及下游用氢。上游制氢工艺目前大部分…...
wxPython中wx.ListCtrl用法(二)
wx.ListCtrl是一个列表组件,可以以列表视图(list view)、报表视图(report view)、图标视图(icon view)和小图标视图(small icon view)等多种模式显示列表。 一、方法 __…...

kubernetes 资源汇总
kubernetes 资源汇总 官网 英文文档 官方英文文档 中文文档 官方中文文档 github github源码地址 培训认证 也就是linux基金会的认证,上面也提供培训课程 下载资源 官网下载资源,国内的话k8s镜像下载不了,要去镜像站 在线练习 killer…...
)
每日一题(对标gesp三级答案将在第二天公布)
编程题 题目描述: 小杨为数字4,5,6和7设计了一款表示形式,每个数字占用了66的网格。数字4,5,6和7的表示形式如下(此处自行设计复杂一些的表示形式示例): 数字4: …. …. …. …. *… 数字5: …...

让 Win10 上网本 Debug 模式 QUDPSocket 信号槽 收发不丢包的方法总结
在前两篇文章里,我们探讨了不少UDP丢包的解决方案。经过几年的摸索测试,其实方法非常简单, 无需修改代码。 1. Windows 下设置UDP缓存 这个方法可以一劳永逸解决UDP的收发丢包问题,只要添加注册表项目并重启即可。即使用Qt的信号与槽&#…...

Python爬虫之使用BeautifulSoup进行HTML Document文档的解析
BeautifulSoup 是一个用于解析 HTML 和 XML 文档的 Python 库,它为开发者提供了一种简单的方式来查找、遍历和修改文档树。BeautifulSoup 特别擅长处理不规则或格式不佳的标记语言,可以自动更正无效的 HTML,因此在网页抓取(Web Sc…...

vue.config.js配置参数说明新手教程
这篇文章主要是对vue.config.js配置文件的主要参数进行一下说明,方便使用时的查询, 下面进行介绍 1、vue.config.js vue.config.js 是一个可选的配置文件,如果项目的 (和 package.json 同级的) 根目录中存在这个文件,那么它会被…...
)
C# 关于加密技术以及应用(二)
AES(Advanced Encryption Standard)和 RSA(Rivest-Shamir-Adleman)是两种不同的加密算法,它们各自有特定的使用场景和优势。下面是它们的主要区别和适用场景: AES(高级加密标准) 特…...

视频中的某些片段如何制作GIF表情包?
动态表情包(GIF)已经成为我们日常沟通中不可或缺的一部分。GIF(Graphics Interchange Format),即图形交换格式,是一种支持多帧图像和透明度的位图文件格式。它最初由 CompuServe 公司在 1987 年推出&#x…...

图像识别 | Matlab基于卷积神经网络(CNN)的宝可梦识别源程序,GUI界面。附详细的运行说明。
图像识别 | Matlab基于卷积神经网络(CNN)的宝可梦识别源程序,GUI界面。附详细的运行说明。 目录 图像识别 | Matlab基于卷积神经网络(CNN)的宝可梦识别源程序,GUI界面。附详细的运行说明。预测效果基本介绍程序设计参考资料 预测效果 基本介绍 Matlab基…...

String【Redis对象篇】
🏆 作者简介:席万里 ⚡ 个人网站:https://dahua.bloggo.chat/ ✍️ 一名后端开发小趴菜,同时略懂Vue与React前端技术,也了解一点微信小程序开发。 🍻 对计算机充满兴趣,愿意并且希望学习更多的技…...

top命令和系统负载
1 top中的字段说明 top是一个实时系统监视工具,可以动态展现出 CPU 使用率、内存使用情况、进程状态等信息,注意这些显示的文本不能直接使用 > 追加到文件中。 [rootvv~]# top -bn 1 | head top - 20:08:28 up 138 days, 10:29, 4 users, load av…...

ES6 混合 ES5学习记录
基础 数组 let arr [数据1,数据2,...数组n] 使用数组 数组名[索引] 数组长度 arr.length 操作数组 arr.push() 尾部添加一个,返回新长度 arr.unshift() 头部添加一个,返回新长度 arr.pop() 删除最后一个,并返回该元素的值 shift 删除第一个单元…...

HTTP 状态码大全
常见状态码 200 OK # 客户端请求成功 400 Bad Request # 客户端请求有语法错误 不能被服务器所理解 401 Unauthorized # 请求未经授权 这个状态代码必须和WWW- Authenticate 报头域一起使用 403 Forbidden # 服务器收到请求但是拒绝提供服务 404 Not Found # 请求资源不存…...
| Redisson 看门狗机制深度解析)
Redis学习(13)| Redisson 看门狗机制深度解析
文章目录 摘要1. 引言2. 看门狗的工作原理2.1 自动续期2.2 防止意外释放2.3 合理配置 3. 应用场景4. 最佳实践4.1 设置合理的lockWatchdogTimeout4.2 避免死锁4.3 监控和日志 5. 实现方式6. 使用示例7. 结论 摘要 Redisson 是一个用于 Redis 的 Java 客户端,它提供…...

【开源大屏】玩转开源积木BI,从0到1设计一个大屏
积木 BI 重磅推出免费大屏设计器!功能超强大,操作超流畅,体验超酷炫。快来体验一下吧。 让我们一起来看一下如何从0到1设计一个大屏。 一、积木BI大屏介绍 积木BI可视化数据大屏 是一站式数据可视化展示平台,旨在帮助用户快速通…...

基于PCRLB的CMIMO雷达资源调度方法(MATLAB实现)
集中式多输入多输出CMIMO雷达作为一种新体制雷达,能够实现对多个目标的同时多波束探测,在多目标跟踪领域得到了广泛运用。自从2006年学者Haykin提出认知雷达理论,雷达资源分配问题就成为一个有实际应用价值的热点研究内容。本文基于目标跟踪的…...

PAT--1035 插入与归并
题目描述 根据维基百科的定义: 插入排序是迭代算法,逐一获得输入数据,逐步产生有序的输出序列。每步迭代中,算法从输入序列中取出一元素,将之插入有序序列中正确的位置。如此迭代直到全部元素有序。 归并排序进行如…...

OLAP引擎全景图鉴:从架构原理到场景适配,深度解析Impala/Druid/Presto/Kylin/ClickHouse的选型之道
1. OLAP技术全景解析:从基础概念到架构分类 当你打开手机查看每日步数统计,或是浏览电商平台的年度消费报告时,背后支撑这些数据分析的正是OLAP技术。OLAP(在线分析处理)就像一位不知疲倦的数据分析师,能够…...

完整指南:如何用3D打印技术构建高精度六轴机械臂Faze4
完整指南:如何用3D打印技术构建高精度六轴机械臂Faze4 【免费下载链接】Faze4-Robotic-arm All files for 6 axis robot arm with cycloidal gearboxes . 项目地址: https://gitcode.com/gh_mirrors/fa/Faze4-Robotic-arm Faze4是一个完全开源的6轴工业级机械…...

RT-Thread中断管理实战:从Cortex-M硬件机制到线程通信
1. 项目概述:从内核到中断,RT-Thread的实战拼图搞嵌入式开发,尤其是用RTOS,中断处理是绕不开的一道坎。之前我们聊RT-Thread的线程、IPC、内存管理,都是在“太平盛世”下进行的,线程们按部就班地运行、等待…...

AI应用网关ai-proxy:统一管理多模型API调用,实现路由、缓存与限流
1. 项目概述:一个为AI应用量身打造的智能代理网关如果你正在开发或部署基于大语言模型(LLM)的应用,比如一个聊天机器人、一个代码助手,或者一个内容生成工具,那么你大概率会遇到一个头疼的问题:…...

stm32开发者如何快速接入大模型api实现智能对话功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 STM32开发者如何快速接入大模型API实现智能对话功能 为嵌入式设备增加自然语言交互能力,是许多STM32开发者希望实现的功…...

如何用memtest_vulkan快速检测GPU显存稳定性:终极免费测试指南
如何用memtest_vulkan快速检测GPU显存稳定性:终极免费测试指南 【免费下载链接】memtest_vulkan Vulkan compute tool for testing video memory stability 项目地址: https://gitcode.com/gh_mirrors/me/memtest_vulkan 当你的游戏突然崩溃、AI训练意外中断…...

从零到一:在VSCode中高效搭建PyQt5开发环境
1. 为什么选择VSCodePyQt5组合? 作为一个常年混迹Python GUI开发的老手,我尝试过各种开发环境组合,最终发现VSCodePyQt5这对搭档特别适合新手入门。PyQt5作为Qt框架的Python绑定,能让你用简单的代码创建专业级桌面应用,…...

LZ4压缩算法演进:从r131到v1.9.5的终极速度革命 [特殊字符]
LZ4压缩算法演进:从r131到v1.9.5的终极速度革命 🚀 【免费下载链接】lz4 Extremely Fast Compression algorithm 项目地址: https://gitcode.com/GitHub_Trending/lz/lz4 LZ4作为当今最快的无损压缩算法之一,自诞生以来经历了令人瞩目…...

WechatSogou微信公众号爬虫实战指南:高效获取公众号数据的Python解决方案
WechatSogou微信公众号爬虫实战指南:高效获取公众号数据的Python解决方案 【免费下载链接】WechatSogou 基于搜狗微信搜索的微信公众号爬虫接口 项目地址: https://gitcode.com/gh_mirrors/we/WechatSogou 在信息爆炸的时代,微信公众号已成为内容…...

掌握Flash逆向工程:JPEXS免费反编译工具完全指南
掌握Flash逆向工程:JPEXS免费反编译工具完全指南 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler 在Flash技术逐渐淡出历史舞台的今天,无数经典的Flash动画、游戏…...