75_pandas.DataFrame 中查看和复制
75_pandas.DataFrame 中查看和复制
与pandas的DataFrame与NumPy数组ndarray类似,也有视图(view)和拷贝(copy)。
当使用loc[]或iloc[]等选择DataFrame的一部分以生成新的DataFrame时,与原对象共享内存的对象称为视图,与原对象分开重新分配内存的对象称为拷贝。
由于视图引用的是共同的内存,因此当一个对象的元素值被修改时,另一个对象的值也会被修改。
目录
- pandas.DataFrame的视图和拷贝的注意事项
- 通过loc, iloc进行部分选择
- 所有列数据类型dtype相同时
- 存在不同数据类型dtype的列时
- numpy.ndarray与pandas.DataFrame之间的内存共享
- 从numpy.ndarray生成pandas.DataFrame
- 从pandas.DataFrame生成numpy.ndarray
本文的示例代码中使用的pandas和NumPy版本如下。注意,由于版本不同,可能会有不同的规格。
import pandas as pd
import numpy as npprint(pd.__version__)
# 2.1.4print(np.__version__)
# 1.26.2
pandas.DataFrame的视图和拷贝的注意事项
关于DataFrame中的视图和拷贝,首先需要了解的是,至少在版本2.1.4的情况下,没有办法可以确定一个DataFrame是另一个DataFrame的视图还是拷贝。
如下面的例子所示,np.shares_memory()和DataFrame的_is_view属性也不能保证返回确定的结果。
通过调用DataFrame的copy()方法可以确保生成一个拷贝,但没有方法可以确保生成一个视图。在可能处理各种数据的代码中以视图为前提是危险的。
接下来会展示几个例子,但本文想要传达的不是“在这种情况下会返回视图(或拷贝)”,而是“无法确定会返回视图还是拷贝,所以要注意”。
通过loc, iloc进行部分选择
loc[]可以通过行名和列名选择DataFrame的范围,iloc[]可以通过行号和列号选择。不仅可以指定标量值,还可以使用切片或列表等指定多行多列。
- 04_Pandas获取和修改任意位置的值(at,iat,loc,iloc)
显示所有列数据类型dtype相同和存在不同数据类型dtype的列时的结果。
在几种模式下选择范围以生成新的DataFrame,显示np.shares_memory()和_is_view属性的结果,最后修改原DataFrame的元素值,以确认生成的DataFrame的值是否也被修改(是否共享内存)。
再重复一下,下面的示例代码和结果仅仅是一个例子,不能保证在所有条件下都生成视图或拷贝。
所有列数据类型dtype相同时
所有列数据类型dtype相同的情况。
df_homo = pd.DataFrame({'A': [0, 1, 2], 'B': [3, 4, 5]})
print(df_homo)
# A B
# 0 0 3
# 1 1 4
# 2 2 5print(df_homo.dtypes)
# A int64
# B int64
# dtype: object
通过切片选择。
df_homo_slice = df_homo.iloc[:2]
print(df_homo_slice)
# A B
# 0 0 3
# 1 1 4print(np.shares_memory(df_homo, df_homo_slice))
# Trueprint(df_homo_slice._is_view)
# True
通过列表选择。同样可以使用元组、ndarray、Series等指定。
df_homo_list = df_homo.iloc[[0, 1]]
print(df_homo_list)
# A B
# 0 0 3
# 1 1 4print(np.shares_memory(df_homo, df_homo_list))
# Falseprint(df_homo_list._is_view)
# False
布尔索引。同样可以使用元组、ndarray、Series等指定。
df_homo_bool = df_homo.loc[[True, False, True]]
print(df_homo_bool)
# A B
# 0 0 3
# 2 2 5print(np.shares_memory(df_homo, df_homo_bool))
# Falseprint(df_homo_bool._is_view)
# False
通过标量值选择。这种情况下是Series而非DataFrame。
s_homo_scalar = df_homo.iloc[0]
print(s_homo_scalar)
# A 0
# B 3
# Name: 0, dtype: int64print(np.shares_memory(df_homo, s_homo_scalar))
# Trueprint(s_homo_scalar._is_view)
# True
不使用loc[]或iloc[],而是用[列名]指定。
s_homo_col = df_homo['A']
print(s_homo_col)
# 0 0
# 1 1
# 2 2
# Name: A, dtype: int64print(np.shares_memory(df_homo, s_homo_col))
# Trueprint(s_homo_col._is_view)
# True
通过列表指定多个列名。
df_homo_col_list = df_homo[['A', 'B']]
print(df_homo_col_list)
# A B
# 0 0 3
# 1 1 4
# 2 2 5print(np.shares_memory(df_homo, df_homo_col_list))
# Falseprint(df_homo_col_list._is_view)
# False
修改原DataFrame的元素值,确认生成的DataFrame的值是否发生变化。
df_homo.iat[0, 0] = 100
print(df_homo)
# A B
# 0 100 3
# 1 1 4
# 2 2 5print(df_homo_slice)
# A B
# 0 100 3
# 1 1 4print(df_homo_list)
# A B
# 0 0 3
# 1 1 4print(df_homo_bool)
# A B
# 0 0 3
# 2 2 5print(s_homo_scalar)
# A 100
# B 3
# Name: 0, dtype: int64print(s_homo_col)
# 0 100
# 1 1
# 2 2
# Name: A, dtype: int64print(df_homo_col_list)
# A B
# 0 0 3
# 1 1 4
# 2 2 5
在这个简单的例子中,结果与np.shares_memory()和_is_view属性一致。
在列表和布尔索引中指定时,会生成拷贝,其他情况下则为视图。
需要注意的是,上述例子中仅指定了行[:2],但如果同时指定行和列(如[:2, [0, 1]]),只要行或列中包含列表,就会生成拷贝。另外,[0]是视图,而[[0]](包含一个元素的列表)是拷贝。
存在不同数据类型dtype的列时
存在不同数据类型dtype的列时比较复杂。以下Stack Overflow的回答中指出总是返回拷贝,但似乎也有例外。
以下是一个DataFrame的例子。
df_hetero = pd.DataFrame({'A': [0, 1, 2], 'B': ['x', 'y', 'z']})
print(df_hetero)
# A B
# 0 0 x
# 1 1 y
# 2 2 zprint(df_hetero.dtypes)
# A int64
# B object
# dtype: object
通过切片选择。仅行和行列都选择两种情况。
df_hetero_slice_row = df_hetero.iloc[:2]print(df_hetero_slice_row)
# A B# 0 0 x# 1 1 yprint(np.shares_memory(df_hetero, df_hetero_slice_row))# Falseprint(df_hetero_slice_row._is_view)# Falsedf_hetero_slice_row_col = df_hetero.iloc[:2, 0:]print(df_hetero_slice_row_col)# A B# 0 0 x# 1 1 yprint(np.shares_memory(df_hetero, df_hetero_slice_row_col))# Falseprint(df_hetero_slice_row_col._is_view)# False
通过列表选择。
df_hetero_list = df_hetero.iloc[[0, 1]]print(df_hetero_list)# A B# 0 0 x# 1 1 yprint(np.shares_memory(df_hetero, df_hetero_list))# Falseprint(df_hetero_list._is_view)# False
布尔索引。
df_hetero_bool = df_hetero.loc[[True, False, True]]print(df_hetero_bool)# A B# 0 0 x# 2 2 zprint(df_hetero_bool._is_view)# Falseprint(df_hetero_bool._is_view)# False
通过标量值选择。
s_hetero_scalar = df_hetero.iloc[0]print(s_hetero_scalar)# A 0# B x# Name: 0, dtype: objectprint(np.shares_memory(df_hetero, s_hetero_scalar))# Falseprint(s_hetero_scalar._is_view)# False
不使用loc[]或iloc[],而是用[列名]指定。
s_hetero_col = df_hetero['A']print(s_hetero_col)# 0 0# 1 1# 2 2# Name: A, dtype: int64print(np.shares_memory(df_hetero, s_hetero_col))# Falseprint(s_hetero_col._is_view)# True通过列表指定多个列名。
df_hetero_col_list = df_hetero[['A', 'B']]print(df_hetero_col_list)# A B# 0 0 x# 1 1 y# 2 2 zprint(np.shares_memory(df_hetero, df_hetero_col_list))# Falseprint(df_hetero_col_list._is_view)# False
更改原DataFrame的元素值,确认生成的DataFrame的值是否改变。
df_hetero.iat[0, 0] = 100print(df_hetero)# A B# 0 100 x# 1 1 y# 2 2 zprint(df_hetero_slice_row)# A B# 0 100 x# 1 1 yprint(df_hetero_slice_row_col)# A B# 0 0 x# 1 1 yprint(df_hetero_list)# A B# 0 0 x# 1 1 yprint(df_hetero_bool)# A B# 0 0 x# 2 2 zprint(s_hetero_scalar)# A 0# B x# Name: 0, dtype: objectprint(s_hetero_col)# 0 100# 1 1# 2 2# Name: A, dtype: int64print(df_hetero_col_list)# A B# 0 0 x# 1 1 y# 2 2 z
仅按行切片选择时,np.shares_memory()和_is_view属性为False,但内存共享(原DataFrame的更改会反映)。
此外,用[列名]指定时,np.shares_memory()为False且_is_view属性为True,但实际上原DataFrame的更改会反映,_is_view属性是正确的。
记住所有情况下是视图还是副本在现实中不太可能,所以最终可能会逐一确认,但记住切片选择中是否省略可能会导致视图或副本的变化可能会有所帮助。
numpy.ndarray和pandas.DataFrame之间的内存共享
DataFrame和ndarray可以互相转换。DataFrame和ndarray之间也可能共享内存。
相关文章:pandas.DataFrame, Series与NumPy数组ndarray的相互转换
在这种情况下,可能可以相信np.shares_memory()的结果。
无论是DataFrame还是ndarray,都可以通过copy()方法生成副本。
从numpy.ndarray生成pandas.DataFrame
从ndarray生成DataFrame的情况。
a = np.array([[0, 1, 2], [3, 4, 5]])print(a)# [[0 1 2]# [3 4 5]]df = pd.DataFrame(a)print(df)# 0 1 2# 0 0 1 2# 1 3 4 5np.shares_memory()和DataFrame的_is_view属性返回True。print(np.shares_memory(a, df))# Trueprint(df._is_view)# True修改ndarray的值时会反映到DataFrame,实际证实是视图。
a[0, 0] = 100print(a)# [[100 1 2]# [ 3 4 5]]print(df)# 0 1 2# 0 100 1 2# 1 3 4 5
并不总是视图,对于字符串情况是副本。
a_str = np.array([['a', 'b', 'c'], ['x', 'y', 'z']])
print(a_str)
# [['a' 'b' 'c']
# ['x' 'y' 'z']]df_str = pd.DataFrame(a_str)print(df_str)# 0 1 2# 0 a b c# 1 x y zprint(np.shares_memory(a_str, df_str))# Falseprint(df_str._is_view)# Falsea_str[0, 0] = 'A'
print(a_str)
# [['A' 'b' 'c']
# ['x' 'y' 'z']]print(df_str)# 0 1 2# 0 a b c# 1 x y z
从pandas.DataFrame生成numpy.ndarray
从DataFrame生成ndarray的情况。
DataFrame的各列数据类型dtype相同种类时是视图。
df_homo = pd.DataFrame([[0, 1, 2], [3, 4, 5]])print(df_homo)# 0 1 2# 0 0 1 2# 1 3 4 5print(df_homo.dtypes)# 0 int64# 1 int64# 2 int64# dtype: objecta_homo = df_homo.valuesprint(a_homo)# [[0 1 2]# [3 4 5]]print(np.shares_memory(a_homo, df_homo))# Truedf_homo.iat[0, 0] = 100print(df_homo)# 0 1 2# 0 100 1 2# 1 3 4 5print(a_homo)# [[100 1 2]# [ 3 4 5]]
异种情况是副本。
df_hetero = pd.DataFrame([[0, 'x'], [1, 'y']])
print(df_hetero)
# 0 1
# 0 0 x
# 1 1 yprint(df_hetero.dtypes)
# 0 int64
# 1 object
# dtype: objecta_hetero = df_hetero.values
print(a_hetero)
# [[0 'x']
# [1 'y']]print(np.shares_memory(a_hetero, df_hetero))
# Falsedf_hetero.iat[0, 0] = 100print(df_hetero)
# 0 1
# 0 100 x
# 1 1 yprint(a_hetero)
# [[0 'x']
# [1 'y']]
相关文章:

75_pandas.DataFrame 中查看和复制
75_pandas.DataFrame 中查看和复制 与pandas的DataFrame与NumPy数组ndarray类似,也有视图(view)和拷贝(copy)。 当使用loc[]或iloc[]等选择DataFrame的一部分以生成新的DataFrame时,与原对象共享内存的对…...

打电话玩手机识别-支持YOLO,COCO,VOC格式的标记,超高识别率可检测到手持打电话, 非接触式打电话,玩手机自拍等
打电话玩手机识别-支持YOLO,COCO,VOC格式的标记,超高识别率可检测到手持打电话, 非接触式打电话,玩手机自拍等1275个图片。 手持打电话: 非接触打电话 玩手机 数据集下载 yolov11:https://download.csdn…...

生产慎用之调试日志对空间矢量数据批量插入的性能影响-以MybatisPlus为例
目录 前言 一、一些缘由 1、性能分析 二、插入方式调整 1、批量插入的实现 2、MP的批量插入实现 3、日志的配置 三、默认处理方式 1、基础程序代码 2、执行情况 四、提升调试日志等级 1、在logback中进行设置 2、提升后的效果 五、总结 前言 在现代软件开发中,性能优…...
)
单片机:实现倒计时(附带源码)
使用单片机实现倒计时功能是一个常见的嵌入式应用,它能帮助你更好地理解如何进行时间控制和如何通过定时器实现精确的倒计时。通过该项目,你将学习如何使用单片机的定时器来进行时间计算,并通过LED或LCD显示倒计时的结果。 1. 项目概述 倒计…...

什么是多线程中的上下文切换
什么是多线程中的上下文切换 回答 上下文切换是指CPU从一个线程转到另一个线程时,需要保存当前线程的上下文状态,恢复另一个线程的上下文状态,以便于下一次恢复执行该线程时能够正确地运行。 在多线程编程中,上下文切换是一种常…...

如何在windwos批量拉取go mod
golang go-zero微服务开发,分的rpc项目太多了,变更了公共包,需要手动去拉取,直接一键拉取就好了,创建一个windwos脚本文件 文件名 tidy_all_go_mod.ps1 代码 # 辅助工具拉取go mod tidy # 根目录v99main执行 ./tidy_all_go_mod.ps1 # 定义项目的根目录 $RootDir Get-Locat…...

【Three.js基础学习】29.Hologram Shader
前言 three.js 通过着色器如何实现全息影像,以及一些动态的效果。 一些难点的思维,代码目录 下面图是摄像机视角观看影响上的时候,如何实现光影的渐变,透视以及叠加等。 一、代码 1.index.html <!DOCTYPE html> <html …...

文件包含进阶玩法以及绕过姿态
前言 欢迎来到我的博客 个人主页:北岭敲键盘的荒漠猫-CSDN博客 本文整理文件包含漏洞的进阶玩法与绕过姿态 不涉及基础原理了 特殊玩法汇总 本地包含 文件包含上传文件 原理: php的文件包含有着把其他文件类型当做php代码执行的功效,文件上传一般会限制后缀&am…...

Markdown编辑器工具--Typora
下载链接...

PyTorch 的 torch.unbind 函数详解与进阶应用:中英双语
中文版 PyTorch 的 torch.unbind 函数详解与进阶应用 在深度学习中,张量的维度操作是基础又重要的内容。PyTorch 提供了许多方便的工具来完成这些操作,其中之一便是 torch.unbind。与常见的堆叠函数(如 torch.stack)相辅相成&am…...

四十六:如何使用Wireshark解密TLS/SSL报文?
TLS/SSL是保护网络通信的重要协议,其加密机制可以有效地防止敏感信息被窃取。然而,在调试网络应用或分析安全问题时,解密TLS/SSL流量是不可避免的需求。本文将介绍如何使用Wireshark解密TLS/SSL报文。 前提条件 在解密TLS/SSL报文之前&…...
【人工智能】OpenAI O1模型:超越GPT-4的长上下文RAG性能详解与优化指南
在人工智能(AI)领域,长上下文生成与检索(RAG) 已成为提升自然语言处理(NLP)模型性能的关键技术之一。随着数据规模与应用场景的不断扩展,如何高效地处理海量上下文信息,成…...
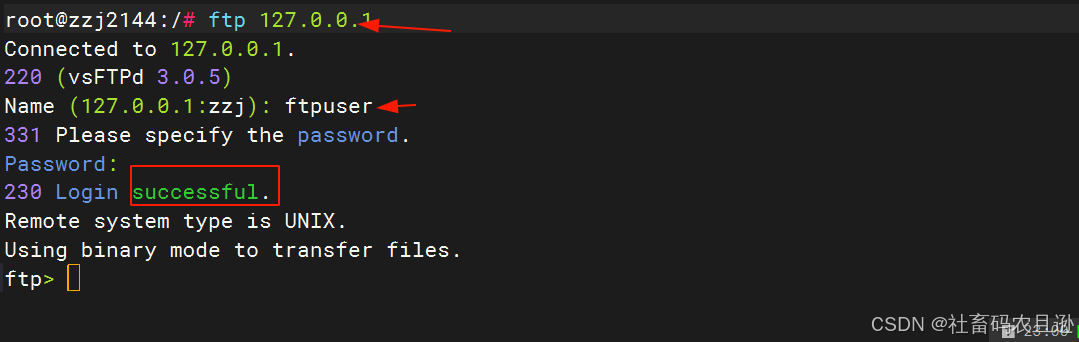
Ubuntu22.04搭建FTP服务器保姆级教程
在网络环境中,文件传输是一项至关重要的任务。FTP(文件传输协议)是一种基于客户端/服务器模式的协议,广泛用于在互联网上传输文件。Ubuntu作为一款流行的Linux发行版,因其稳定性和易用性而广受开发者和系统管理员的喜爱…...

操作系统(4)操作系统的结构
一、无序结构(整体结构或模块组合结构) 1.特点: 以大型表格和队列为中心,操作系统的各部分程序围绕着这些表格进行。操作系统由许多标准的、可兼容的基本单位(称为模块)构成,模块之间通过规定的…...
)
Python数据分析(OpenCV视频处理)
处理视频我们引入的还是numpy 和 OpenCV 的包 引入方式如下: import numpy as np import cv2 我们使用OpenCV来加载本地视频,参数就是你视频的路径就可以 #加载视频 cap cv2.VideoCapture(./1.mp4) 下面我们进行读取视频 #读取视频 flag,frame cap.re…...

跨域 Cookie 共享
跨域请求经常遇到需要携带 cookie 的场景,为了确保跨域请求能够携带用户的认证信息或其他状态,浏览器提供了 withCredentials 这个属性。 如何在 Axios 中使用 withCredentials 为了在跨域请求中携带 cookie,需要在 Axios 配置中设置 withCr…...
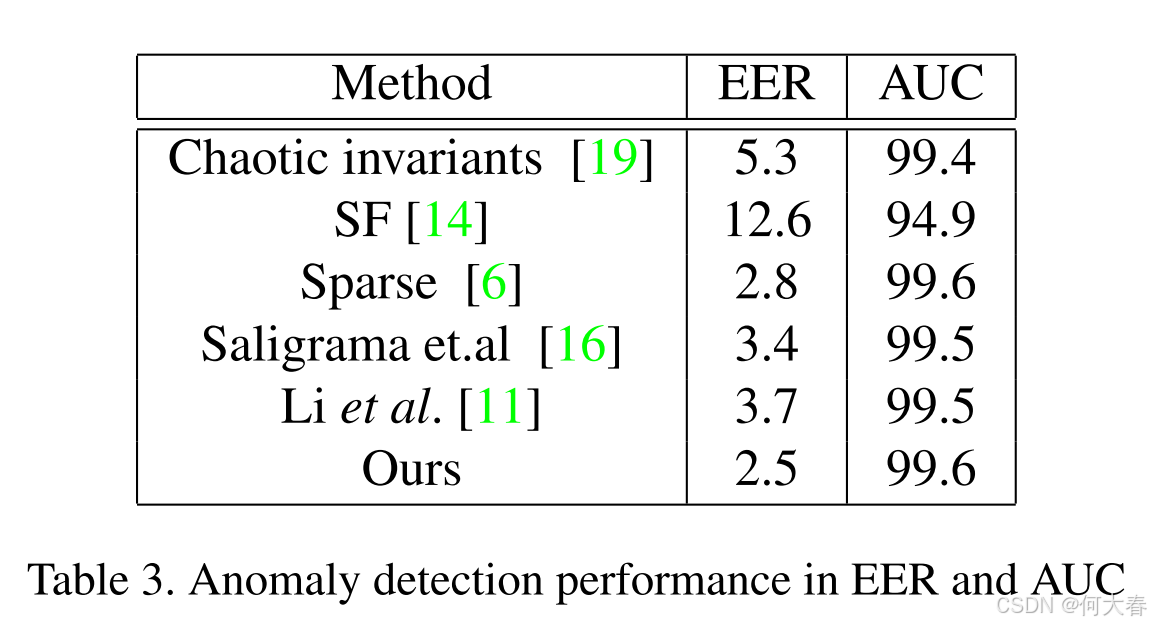
【视频异常检测】Real-Time Anomaly Detection and Localization in Crowded Scenes 论文阅读
文章信息: 发表于:CVPR2015(workshop) 原文链接:https://www.cv-foundation.org/openaccess/content_cvpr_workshops_2015/W04/papers/Sabokrou_Real-Time_Anomaly_Detection_2015_CVPR_paper.pdf Real-Time Anomaly D…...

设计模式12:抽象工厂模式
系列总链接:《大话设计模式》学习记录_net 大话设计-CSDN博客 参考: C设计模式:抽象工厂模式(风格切换案例)_c 抽象工厂-CSDN博客 1.概念 抽象工厂模式(Abstract Factory Pattern)是软件设计…...
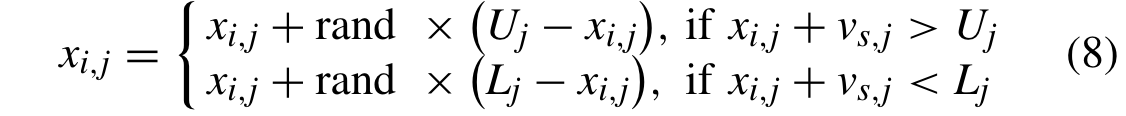
论文学习——多种变化环境下基于多种群进化的动态约束多目标优化
论文题目:Multipopulation Evolution-Based Dynamic Constrained Multiobjective Optimization Under Diverse Changing Environments 多种变化环境下基于多种群进化的动态约束多目标优化(Qingda Chen , Member, IEEE, Jinliang Ding , Senior Member, …...
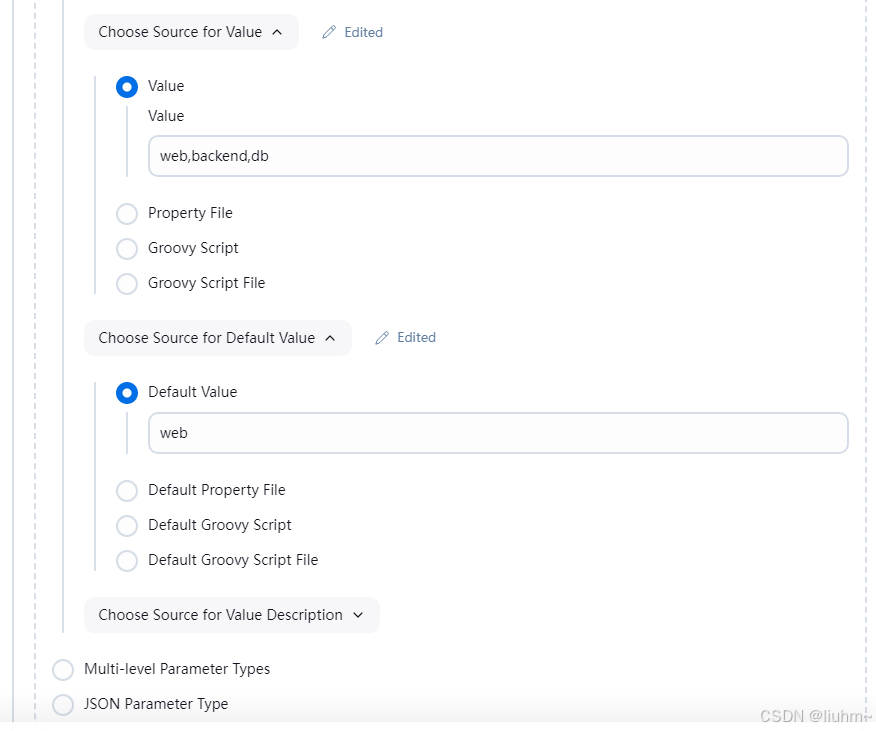
Jenkins参数化构建详解(This project is parameterized)
本文详细介绍了Jenkins中不同类型的参数化构建方法,包括字符串、选项、多行文本、布尔值和git分支参数的配置,以及如何使用ActiveChoiceParameter实现动态获取参数选项。通过示例展示了传统方法和声明式pipeline的语法 文章目录 1. Jenkins的参数化构建1…...

大厂疯抢!AI Agent开发岗要求速览+进阶学习路线图,速收藏!
文章分析了大厂AI Agent开发岗位的核心要求,包括扎实的后端开发基础、AI知识储备、主流框架掌握等。文章强调AI应用开发与后端开发并非对立,而是相辅相成,并提供了详细的学习路线图,涵盖基础阶段、AI知识入门、实践项目、深化与拓…...

VMware 虚拟机 Kali Linux 光标消失?五步实操攻略轻松找回
在 VMware Workstation Pro 中运行 Kali Linux 时,不少用户会遇到 “光标隐形” 的棘手问题 —— 系统可正常操作,但光标一进入虚拟机窗口就消失。这一现象多由硬件兼容性、驱动配置或增强工具缺失导致,并非硬件故障。本文整合社区实测有效方…...

开发提效新组合:用Cursor编写核心逻辑,快马平台一键生成完整企业级项目
今天想和大家分享一个提升开发效率的实用组合:用Cursor编写核心业务逻辑,再通过InsCode(快马)平台一键生成完整项目。最近在开发一个企业内部工时管理系统时,这套组合拳帮我节省了大量重复劳动时间。 1. 为什么选择这个技术组合 开发企业级…...
中摘要准确率与人工对比达92%)
intv_ai_mk11效果实测:在中文长文本理解任务(>3000字技术文档)中摘要准确率与人工对比达92%
intv_ai_mk11效果实测:在中文长文本理解任务(>3000字技术文档)中摘要准确率与人工对比达92% 1. 引言:AI长文本理解的新突破 当我们面对动辄数千字的技术文档时,如何快速抓住核心内容一直是个难题。传统方法要么依…...

OpenCore Legacy Patcher完整指南:四步让老旧Mac免费升级最新macOS
OpenCore Legacy Patcher完整指南:四步让老旧Mac免费升级最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为苹果官方停止支持的老旧…...

手把手调试:从V8引擎的ArrayBuffer到WebAssembly,一步步拆解Chrome CVE-2020-6507漏洞利用链
深入解析Chrome V8引擎漏洞利用:从ArrayBuffer到WebAssembly的内存操控实战 浏览器安全研究领域近年来持续升温,其中V8引擎作为Chrome和Node.js的核心组件,其安全性直接影响着数十亿用户。本文将带您深入探索一个典型V8漏洞(CVE-2…...
)
别再硬编码了!用注解+工厂模式,5分钟为你的Java应用扩展一个新PLC协议(ModbusTCP/S7为例)
工业物联网中Java协议扩展的优雅实践:注解驱动与工厂模式深度整合 工业物联网(IIoT)平台的开发者们经常面临一个棘手问题:如何在不重构核心代码的情况下,快速接入各种PLC设备协议?想象一下这样的场景:你的系统已经稳定…...

Claude Code 命令和用法
斜杠命令(会话内输入 / 触发)会话与导航命令说明/clear清除对话历史,释放上下文。别名:/reset、/new/compact [指令]压缩对话,可附加聚焦指令/resume [会话]恢复历史会话。别名:/continue/rename [名称]重命…...

无需配置环境!MinerU镜像一键部署,即刻体验智能文档解析
无需配置环境!MinerU镜像一键部署,即刻体验智能文档解析 1. 为什么选择智能文档解析? 在日常办公和学习中,我们经常需要处理各种文档资料:PDF报告、扫描合同、学术论文、财务报表等。传统方式要么需要手动输入&#…...

【Visual Leak Detector】跨平台 QT 项目集成 VLD 的便携式部署方案
1. Visual Leak Detector 与 QT 开发的那些事儿 做 C 开发的朋友应该都遇到过内存泄漏这个头疼的问题。特别是用 QT 开发跨平台应用时,随着项目规模扩大,内存管理就变得格外棘手。Visual Leak Detector(简称 VLD)这个轻量级工具简…...