12.6深度学习_模型优化和迁移_整体流程梳理
七、整体流程梳理
1. 引入使用的包
用到什么包,临时引入就可以,不用太担心。
import time
import osimport numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10from torchvision.models import resnet18, ResNet18_Weights
import wandb
from torch.utils.tensorboard import SummaryWriter
from sklearn.metrics import *
import matplotlib.pyplot as plt
2. 数据
# 下面和以前就一样了
train_dataset = CIFAR10(root=datapath,train=True,download=True,transform=transform,
)
# 构建训练数据集
train_loader = DataLoader(#dataset=train_dataset,batch_size=batzh_size,shuffle=True,num_workers=2,
)
3. 模型
# 再次获取resnet18原始神经网络并对齐fc层进行调整
model = resnet18(weights=None)in_features = model.fc.in_features
# 重写FC:我们这里做的是10分类
model.fc = nn.Linear(in_features=in_features, out_features=10)# 需要对权重信息进行处理:要加载我们训练之后最新的权重文件
weights_default = torch.load(weightpath)
weights_default.pop("fc.weight")
weights_default.pop("fc.bias")# 把权重参数进行同步
new_state_dict = model.state_dict()
weights_default_process = {k: v for k, v in weights_default.items() if k in new_state_dict
}
new_state_dict.update(weights_default_process)
model.load_state_dict(new_state_dict)
model.to(device)4. 训练
4.1 数据增强
为了防止过拟合,增加模型的泛化能力,我们会数据增强
transform = transforms.Compose([transforms.RandomRotation(45), # 随机旋转,-45到45度之间随机选transforms.RandomCrop(32, padding=4), # 随机裁剪transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转 选择一个概率概率transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2471, 0.2435, 0.2616)),]
)transformtest = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2471, 0.2435, 0.2616)),]
)4.2 开始训练
# 损失函数和优化器loss_fn = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=lr)for epoch in range(epochs):# 开始时间start = time.time()# 总的损失值total_loss = 0.0# 样本数量:最后一次样本数量不是128samp_num = 0# 总的预测正确的分类correct = 0model.train()for i, (x, y) in enumerate(train_loader):x, y = x.to(device), y.to(device)# 累加样本数量samp_num += len(y)out = model(x)# 预测正确的样本数量correct += out.argmax(dim=1).eq(y).sum().item()loss = loss_fn(out, y)# 损失率累加total_loss += loss.item() * len(y)optimizer.zero_grad()loss.backward()optimizer.step()if i % 100 == 0:img_grid = torchvision.utils.make_grid(x)write1.add_image(f"r_m_{epoch}_{i}", img_grid, epoch * len(train_loader) + i)print("批次:%d 损失率:%.4f 准确率:%.4f 耗时:%.4f"% (epoch, total_loss / samp_num, correct / samp_num, time.time() - start))# log metrics to wandbwandb.log({"acc": correct / samp_num, "loss": total_loss / samp_num})4.3 保存模型
torch.save(model.state_dict(), weightpath)
4.4 训练过程可视化
wandb
# 训练过程可视化wandb.init(project="my-qianyi-project",config={"learning_rate": lr,"architecture": "CNN","dataset": "CIFAR-100","batch_size": batzh_size,"epochs": epochs,},)
tensorboard
write1 = SummaryWriter(log_dir=log_dir)
# 保存模型结构到tensorboard
write1.add_graph(model, input_to_model=torch.randn(1, 3, 32, 32).to(device=device))
5. 验证阶段
5.1 数据验证
weights_default = torch.load(weightpath)# 再次获取resnet18原始神经网络并对齐fc层进行调整model = resnet18(pretrained=False)in_features = model.fc.in_features# 重写FC:我们这里做的是10分类model.fc = nn.Linear(in_features=in_features, out_features=10)model.load_state_dict(weights_default)model.to(device)model.eval()samp_num = 0correct = 0data2csv = np.empty(shape=(0, 13))for x, y in vaild_loader:x = x.to(device)y = y.to(device)# 累加样本数量samp_num += len(y)# 模型运算out = model(x)# 数组的合并data2csv = np.concatenate((data2csv, outdata_softmax), axis=0)# 预测正确的样本数量correct += out.argmax(dim=1).eq(y).sum().item()print("准确率:%.4f" % (correct / samp_num))
5.2 验证结果可视化
验证数据保存到Excel
data2csv = np.empty(shape=(0, 13))#数据整理
out = model(x)
outdata = out.cpu().detach()
outdata_softmax = torch.softmax(outdata, dim=1)
# 合并目标值到样本 [5, 7,9,0,1,,1,2,3,4,3,4]
outdata_softmax = np.concatenate((# 本身预测的值outdata_softmax.numpy(),# 真正的目标值y.cpu().numpy().reshape(-1, 1),# 预测值outdata_softmax.argmax(dim=1).reshape(-1, 1),# 分类名称np.array([vaild_dataset.classes[i] for i in y.cpu().numpy()]).reshape(-1, 1),),axis=1,
)
# 数组的合并
data2csv = np.concatenate((data2csv, outdata_softmax), axis=0)#写入CSV
columns = np.concatenate((vaild_dataset.classes, ["target", "prep", "分类"]))
pddata = pd.DataFrame(data2csv, columns=columns)
pddata.to_csv(csvpath, encoding="GB2312")
指标分析:可视化
def analy():# 读取csv数据data1 = pd.read_csv(csvpath, encoding="GB2312")print(type(data1))# 整体数据分析报告report = classification_report(y_true=data1["target"].values,y_pred=data1["prep"].values,)print(report)# 准确度 Accprint("准确度Acc:",accuracy_score(y_true=data1["target"].values,y_pred=data1["prep"].values,),)# 精确度print("精确度Precision:",precision_score(y_true=data1["target"].values, y_pred=data1["prep"].values, average="macro"),)# 召回率print("召回率Recall:",recall_score(# 100y_true=data1["target"].values,y_pred=data1["prep"].values,average="macro",),)# F1 Scoreprint("F1 Score:",f1_score(y_true=data1["target"].values,y_pred=data1["prep"].values,average="macro",),)passdef matrix():# 读取csv数据data1 = pd.read_csv(csvpath, encoding="GB2312", index_col=0)confusion = confusion_matrix(# 0y_true=data1["target"].values,y_pred=data1["prep"].values,# labels=data1.columns[0:10].values,)print(confusion)# 绘制混淆矩阵plt.rcParams["font.sans-serif"] = ["SimHei"]plt.rcParams["axes.unicode_minus"] = Falseplt.matshow(confusion, cmap=plt.cm.Greens)plt.colorbar()for i in range(confusion.shape[0]):for j in range(confusion.shape[1]):plt.text(j, i, confusion[i, j], ha="center", va="center", color="b")plt.title("验证数据混淆矩阵")plt.xlabel("Predicted label")plt.xticks(range(10), data1.columns[0:10].values, rotation=45)plt.ylabel("True label")plt.yticks(range(10), data1.columns[0:10].values)plt.show()6. 使用
def app():dir = os.path.dirname(__file__)imgpath = os.path.join("./write", "6.png")# 读取图像文件 '8.png'img = cv2.imread(imgpath)# 将图像转换为灰度图img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 对灰度图进行二值化处理,采用OTSU自适应阈值方法,并反转颜色ret, img = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)plt.imshow(img)plt.show()# img = cv2.resize(img, (32, 32))img = torch.Tensor(img).unsqueeze(0)transform = transforms.Compose([transforms.Resize((32, 32)), # 调整输入图像大小为32x32transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,)),])img = transform(img).unsqueeze(0)# 加载我们的模型net = LeNet5()net.load_state_dict(torch.load(modelpath))# 预测outputs = net(img)print(outputs)print(outputs.argmax(axis=1))相关文章:

12.6深度学习_模型优化和迁移_整体流程梳理
七、整体流程梳理 1. 引入使用的包 用到什么包,临时引入就可以,不用太担心。 import time import osimport numpy as np import pandas as pd import torch import torch.nn as nn import torch.optim as optim import torchvision import torchvisio…...

TCP 和 UDP 可以使用同一个端口吗
TCP 和 UDP 可以使用同一个端口吗 简单来说 可以使用同一个端口,关键在于它们属于不同的传输层协议,在内核中是两个完全独立的软件模块,各自维护独立的端口空间,虽然端口号相同,但通过协议类型可以确定是哪种协议。 …...

信而泰网络测试仪校准解决方案
一、影响仪表精度的因素 网络测试仪是用于对数据网络及其相关设备性能参数进行测试的仪表,可以模拟网络终端产生流量,进行网络性能测试,对网络状态进行实时监测,分析和统计。数字计量对于精准数据的网络测试仪来说是一剂强心针&a…...
Java 实现给pdf文件指定位置盖章功能
Java 实现给pdf文件指定位置盖章功能 开发中遇到一个需求, 需要给用户上传的的pdf文件, 指定位置上盖公章的功能, 经过调研和对比, 最终确定实现思路. 这里是使用pdf文件中的关键字进行章子的定位, 之所以这样考虑是因为如果直接写死坐标的话, 可能会出现因pdf大小, 缩放, 盖章…...
算法)
机器学习支持向量机(SVM)算法
一、引言 在当今数据驱动的时代,机器学习算法在各个领域发挥着至关重要的作用。支持向量机(Support Vector Machine,SVM)作为一种强大的监督学习算法,以其在分类和回归任务中的卓越性能而备受瞩目。SVM 具有良好的泛化…...

解决 MySQL 启动失败与大小写问题,重置数据库
技术文档:解决 MySQL 启动失败与大小写问题,重置数据库 1. 问题背景 在使用 MySQL 时,可能遇到以下问题: MySQL 启动失败,日志显示 “permission denied” 或 “Can’t create directory” 错误。MySQL 在修改配置文…...

计算生成报价单小程序系统开发方案
计算生成报价单小程序报价系统,是根据商品品牌、类型、型号、规格、芯数、特性、颜色、分类进行选择不同的参数进行生成报价单,要求报价单支持生成图片、pdf、excel表格。 计算生成报价单小程序系统的主要功能模块有: 1、在线生成报价单&…...

若依集成Uflo2工作流引擎
文章目录 1. 创建子模块并添加依赖1.1 新建子模块 ruoyi-uflo1.2 引入 Uflo2 相关依赖 2. 配置相关 config2.1 配置 ServletConfig2.2 配置 UfloConfig2.3 配置 TestEnvironmentProvider 3. 引入Uflo配置文件4. 启动并访问 Uflo2 是由 BSTEK 自主研发的一款基于 Java 的轻量级工…...

STM32模拟I2C通讯的驱动程序
目录 STM32模拟I2C通讯的驱动程序 开发环境 引脚连接 驱动程序 STM32模拟I2C通讯的驱动程序 开发环境 立创天空星开发板、主控芯片为STM32F407VxT6 引脚连接 使用stm32的PB9引脚模拟I2C时钟线SCL、PB8引脚模拟I2C数据线SDA 驱动程序 i2c.h文件如下:#ifndef…...

Unity简单操作及使用教程
Unity 是一款强大的跨平台游戏引擎,它不仅支持 2D 和 3D 游戏的开发,还可以用于虚拟现实 (VR)、增强现实 (AR)、动画、建筑可视化等多个领域。Unity 提供了完整的开发环境,具有丰富的功能、工具和资源,可以帮助开发者快速实现创意…...

网络安全法-监测预警与应急处置
第五章 监测预警与应急处置 第五十一条 国家建立网络安全监测预警和信息通报制度。国家网信部门应当统筹协调有关部门加强网络安全信息收集、分析和通报工作,按照规定统一发布网络安全监测预警信息。 第五十二条 负责关键信息基础设施安全保护工作的部门…...

qt 设置系统缩放为150%,导致的文字和界面的问题
1 当我们设置好布局后,在100%的设置里面都是正常的,但是当我们修改缩放为150%后,字体图标,界面大小就出现问题了,这就需要我们设置一些参数。 QCoreApplication::setAttribute(Qt::AA_EnableHighDpiScaling);QCoreAppl…...

Scala的正则表达式二
验证用户名是否合法 规则 1.长度在6-12之间 2.不能数字开头 3.只能包含数字,大小写字母,下划线def main(args: Array[String]): Unit {val name1 "1admin"//不合法,是数字开头val name2 "admin123"//合法val name3 &quo…...

软考系分:今日成绩已出
前言 今年报考了11月份的软考高级:系统分析师。 考试时间:11月9日。 总体感觉偏简单,但是知识点记得不牢,估计机会不大。 今日 12.11 ,成绩已出,每科总分 75分,全部45分以上为通过。 成绩总…...
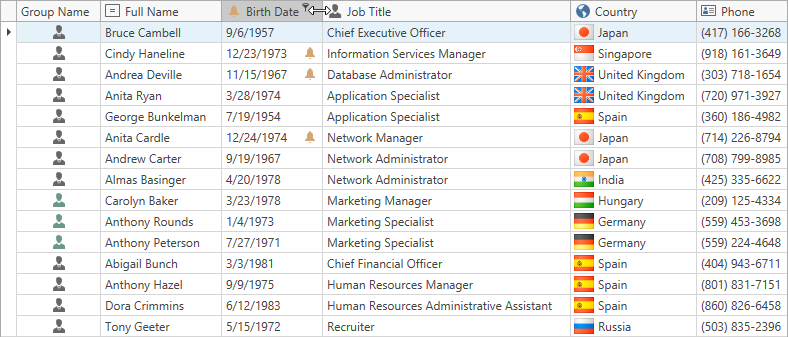
DevExpress WPF中文教程:Grid - 如何移动和调整列大小?(一)
DevExpress WPF拥有120个控件和库,将帮助您交付满足甚至超出企业需求的高性能业务应用程序。通过DevExpress WPF能创建有着强大互动功能的XAML基础应用程序,这些应用程序专注于当代客户的需求和构建未来新一代支持触摸的解决方案。 无论是Office办公软件…...

Docker 安装 sentinel
Docker 安装系列 1、拉取 [rootTseng ~]# docker pull bladex/sentinel-dashboard Using default tag: latest latest: Pulling from bladex/sentinel-dashboard 4abcf2066143: Pull complete 1ec1e81da383: Pull complete 56bccb36a894: Pull complete 7cc80011dc6f: Pull…...

PyCharm 2024.1 解锁版 (Python集成开发IDE)详细安装步骤
分享文件:PyCharm 2024.1 解锁版 (Python集成开发IDE) 链接:https://pan.xunlei.com/s/VOAa_CiVVvZnyQgLfpmCIOABA1 提取码:cx4h 安装步骤 1、下载解压后点击如下进行安装 2、选择安装路径 3、默认勾选将PyCharm创建桌面快捷方式 4、默认…...

SQL中的函数介绍
大多数SQL实现支持以下类型 文本函数:用于处理文本字符串(如删除或填充值,转换值为大写或小写)。数值函数:用于在数值数据上进行算术操作(如返回绝对值,进行代数运算)。日期和时间函…...

【工业机器视觉】基于深度学习的水表盘读数识别(2-数据采集与增强)
【工业机器视觉】基于深度学习的仪表盘识读(1)-CSDN博客 数据采集与增强 为了训练出适应多种表型和环境条件的模型,确保数据集的质量与多样性对于模型的成功至关重要。高质量的数据不仅需要准确无误、具有代表性,还需要涵盖尽可能…...

爬虫基础知识点
最近看了看爬虫相关知识点,做了记录,具体代码放到了仓库,本文仅学习使用,如有违规请联系博主删除。 这个流程图是我使用在线AI工具infography生成的,这个网站可以根据url或者文本等数据自动生成流程图,挺…...

告别窄带!用ADS仿真带你搞懂Doherty放大器带宽瓶颈与三种宽带方案
突破Doherty放大器带宽限制:ADS仿真实战与三大宽带方案解析 在射频功率放大器设计中,Doherty结构因其高效率特性成为5G基站和现代通信系统的核心组件。然而传统设计面临严峻的带宽挑战——当信号频率偏离中心频点时,效率可能骤降30%以上。本文…...
)
Spring Boot项目里application.properties突然不提示了?别慌,试试这3个排查步骤(附Idea 2023.3+版本截图)
Spring Boot项目里application.properties突然不提示了?别慌,试试这3个排查步骤 作为一名长期使用IntelliJ IDEA进行Spring Boot开发的程序员,配置文件提示功能突然消失的情况确实令人头疼。想象一下,当你正在快速编写配置时&…...

5分钟解决Mac NTFS读写难题:免费开源工具完全指南
5分钟解决Mac NTFS读写难题:免费开源工具完全指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management for NT…...

ARM Cortex-M位带操作:从原理到实战,实现GPIO原子级高效控制
1. 项目概述:从“点灯”到“位带”,一次底层效率的跃迁如果你是从51单片机或者Arduino这类平台转战到ARM Cortex-M系列微控制器(比如STM32)的开发者,在点亮第一个LED时,可能会感到一丝“别扭”。在51单片机…...

从原理图到GDS:半定制数字反相器版图实战全流程解析
1. 半定制数字反相器版图设计入门 刚接触IC设计的朋友们,看到"从原理图到GDS"这个流程可能会觉得头大。别担心,咱们今天就用最接地气的方式,手把手带你完成一个数字反相器的版图设计。这个看似简单的反相器,其实包含了M…...

别再照搬教科书了!聊聊西门子温度模块里那个‘奇怪’的热电偶采样电路
西门子温度模块热电偶采样电路的设计玄机:为何打破教科书常规? 第一次拆解西门子S7-1200系列温度模块时,我的目光被热电偶输入电路牢牢钉住了——这个电路竟然没有按照教科书上的经典差分放大结构来设计!更令人困惑的是࿰…...

Laravel-Admin单元测试终极指南:10个技巧确保后台代码质量 [特殊字符]
Laravel-Admin单元测试终极指南:10个技巧确保后台代码质量 🚀 【免费下载链接】laravel-admin Build a full-featured administrative interface in ten minutes 项目地址: https://gitcode.com/gh_mirrors/la/laravel-admin Laravel-Admin是一个…...

终极SolidityPy课程完整指南:从零构建区块链游戏与智能合约的完整教程 [特殊字符]
终极SolidityPy课程完整指南:从零构建区块链游戏与智能合约的完整教程 🚀 【免费下载链接】full-blockchain-solidity-course-py Ultimate Solidity, Blockchain, and Smart Contract - Beginner to Expert Full Course | Python Edition 项目地址: ht…...

终极视频下载解决方案:VideoDownloadHelper Chrome扩展完整指南
终极视频下载解决方案:VideoDownloadHelper Chrome扩展完整指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 在数字内容爆炸的…...

Cursor智能体工具包:从代码助手到自主编程代理的进化
1. 项目概述:从“智能代码补全”到“自主编程代理”的进化如果你和我一样,在过去一两年里深度使用过Cursor,那么你对它的第一印象大概率是“一个集成了AI的现代化代码编辑器”。它确实把智能代码补全、聊天式编程和代码理解做到了一个新高度&…...