Sharding-jdbc基本使用步骤以及执行原理剖析
一、基本使用步骤
1、需求说明
使用sharding-jdbc完成对订单表的水平分表,通过快速入门的开发,了解sharding-jdbc使用方法
人工创建两张表,t_order_1和t_order_2,这两张表是订单表拆分后的表,通过sharding-jdbc向订单表插入数据,按照一定的分片规则,主键为偶数的进入t_order_1,另一部分数据进入t_order_2,通过sharding-jdbc查询数据,根据SQL语句的内容从t_order_1或t_order_2查询数据。
2、环境搭建
创建订单数据库order_db
CREATE DATABASE order_db CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'; 1在order_db中创建t_order_1、t_order_2表
DROP TABLE IF EXISTS t_order_1;CREATE TABLE t_order_1 (`order_id` BIGINT ( 20 ) NOT NULL COMMENT '订单id',`price` DECIMAL ( 10, 2 ) NOT NULL COMMENT '订单价格',`user_id` BIGINT ( 20 ) NOT NULL COMMENT '下单用户id',`status` VARCHAR ( 50 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',PRIMARY KEY ( `order_id` ) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;DROP TABLE IF EXISTS t_order_2;
CREATE TABLE t_order_2 (`order_id` BIGINT ( 20 ) NOT NULL COMMENT '订单id',`price` DECIMAL ( 10, 2 ) NOT NULL COMMENT '订单价格',`user_id` BIGINT ( 20 ) NOT NULL COMMENT '下单用户id',`status` VARCHAR ( 50 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',PRIMARY KEY ( `order_id` ) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;创建工程,引入坐标
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.0.RELEASE</version><relativePath/><!-- lookup parent from repository --></parent><dependencies><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.0</version><scope>provided</scope></dependency><!-- MySQL Connector/J for database connectivity --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.1.0</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.16</version></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><version>2.1.0.RELEASE</version><scope>test</scope></dependency></dependencies>3、配置文件
在application.properties中进行如下配置:(尤其关注sharding-jdbc的配置,我已经将每条配置都解释的很详细了)
# 端口号
server.port=56000
# 应用名称
spring.application.name=sharding_quick
# 表示spring中发现的bean会覆盖之前相同名称的bean
spring.main.allow-bean-definition-overriding=true
# 该配置项,将数据库中带有下划线的字段名称映射成驼峰命名
mybatis.configuration.map-underscore-to-camel-case=true# 以下配置为sharding-jdbc分片规则配置# 1.定义数据源
#定义数据源名称
spring.shardingsphere.datasource.names=m1
#数据源连接数据库
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/order_db?useUnicode=true
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456# 2.指定订单表的数据分布情况,配置数据节点 下面的't_order'是逻辑表,这个名字可以自己起一个 m1.t_order_$->{1..2}表示利用行表达式来实现动态表
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=m1.t_order_$->{1..2}# 3.指定t_order表中的主键生成策略#表示告诉sharding-jdbc数据库表中的那一个字段进行主键生成
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
#指定具体的主键生成策略 -> 雪花算法
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE# 4.指定t_order表的分片策略(分片策略=分片键+分片算法):主键为偶数路由到t_order_1中,否则插入到t_order_2中#告诉分片键是哪一个字段
spring.shardingsphere.sharding.tables.t_order.tableStrategy.inline.shardingColumn=order_id
#确定采取什么样的分片算法
spring.shardingsphere.sharding.tables.t_order.tableStrategy.inline.algorithmExpression=t_order_$->{order_id % 2 + 1}# 5.指定,打开sharding-jdbc提供的sql输出日志配置
spring.shardingsphere.props.sql.show=true# 日志配置
logging.level.root=info
logging.level.org.springframework=info
logging.level.com.lcc=debug
logging.level.druid.sql=debug
4、完成新增订单功能
创建订单实体
import lombok.Data;import java.math.BigDecimal;@Data
public class Order {private Long orderId;private BigDecimal price;private Long userId;private String status;}创建mapper接口
import com.lcc.domain.Order;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;import java.util.List;
import java.util.Map;@Mapper
public interface OrderMapper {/*** 这里t_order就是sharding-jdbc中的逻辑表*/@Insert("insert into t_order(price,user_id,status) values(#{price},#{userId},#{status})")public int insertOrder(Order order);
}在测试类中进行测试
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingQuickApplicationTests {@Autowiredprivate OrderMapper orderMapper;@Testpublic void insertTest(){for (int i = 0; i < 10; i++) {Order order = new Order();order.setStatus("success_"+i);order.setUserId(1L);order.setPrice(new BigDecimal((i+1)*5));int result = orderMapper.insertOrder(order);System.out.println(result);}}
}我们查看数据库发现,已经根据我们的分片策略进行不同orderId的落盘
5、完成查询订单功能
在mapper中新增selectListByOrderIds方法
@Mapper
public interface OrderMapper {/*** 这里t_order就是sharding-jdbc中的逻辑表*/@Insert("insert into t_order(price,user_id,status) values(#{price},#{userId},#{status})")public int insertOrder(Order order);@Select("<script>" +"select " +"* " +"from t_order t " +"where t.order_id in " +"<foreach collection='orderIds' item='id' open='(' separator=',' close=')'>" +"#{id}" +"</foreach>" +"</script>")public List<Map> selectListByOrderIds(@Param("orderIds") List<Long> orderIds);
}在测试类中新增selectTest方法
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingQuickApplicationTests {@Autowiredprivate OrderMapper orderMapper;@Testpublic void insertTest(){for (int i = 0; i < 10; i++) {Order order = new Order();order.setStatus("success_"+i);order.setUserId(1L);order.setPrice(new BigDecimal((i+1)*5));int result = orderMapper.insertOrder(order);System.out.println(result);}}@Testpublic void selectTest(){List<Long> orderIds = new ArrayList<>();orderIds.add(1074443883426873344L);orderIds.add(1074443883489787905L);List<Map> maps = orderMapper.selectListByOrderIds(orderIds);for (Map map : maps) {System.out.println(map);}}
}二、sharding-jdbc执行原理剖析
我们先来看一张官网上给出的大致执行流程图

我们再调整一下,SQL路由应该在SQL改写的前面,如下图

1、SQL解析
首先,使用内置的 SQL 解析器对原始 SQL 进行解析,识别出查询中的表名、条件、分组、排序等信息。这一步骤确保了后续操作能够正确地针对分片后的数据库和表进行。
2、SQL路由
根据分片策略和解析后的 SQL 信息,确定需要访问的具体分片。对于涉及多表关联查询的情况,还会检查是否为绑定表(Binding Table),以优化查询路径。
3、SQL改写
基于路由结果,对原始 SQL 进行必要的改写,例如替换表名为实际的分片表名,调整 LIMIT 子句等,以适应分片后的环境。
4、SQL执行
在完成 SQL 改写后,Sharding-JDBC 会为每个目标分片生成独立的执行计划。这意味着每个分片上的查询都会被视为单独的 SQL 操作,并行执行。
5、结果归并
由于同一个查询可能涉及到多个分片的数据,因此 Sharding-JDBC 需要负责将从各个分片获取的结果集合并成最终的结果返回给应用程序。这个过程包括:
-
数据去重:对于某些聚合查询或 DISTINCT 关键字的使用,需要去除重复记录。
-
排序和分页:如果原始查询包含 ORDER BY 或 LIMIT 等子句,则需要对合并后的结果重新排序或截取指定数量的记录。
相关文章:
Sharding-jdbc基本使用步骤以及执行原理剖析
一、基本使用步骤 1、需求说明 使用sharding-jdbc完成对订单表的水平分表,通过快速入门的开发,了解sharding-jdbc使用方法 人工创建两张表,t_order_1和t_order_2,这两张表是订单表拆分后的表,通过sharding-jdbc向订…...

mysql重置root密码(适用于5.7和8.0)
今天出一期重置mysql root密码的教程,适用于5.7和8.0,在网上搜索了很多的教程发现都没有效果,浪费了很多时间,尝试了多次之后发现这种方式是最稳妥的,那么废话不多说,往下看: 目录 第一步&…...

Linux下SVN客户端保存账号密码
参考文章:解决:Linux上SVN 1.12版本以上无法直接存储明文密码_linux svn 保存密码-CSDN博客新版本svn使用gpg-agent存储密码-CSDN博客svn之无法让 SVN 存储密码,即使配置设置为允许_编程设计_ITGUEST 方法一:明文方式保存密码 首…...

centos7.9 gcc升级到11.2.1
一、信息查看 # cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core) # gcc --version gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44) Copyright © 2015 Free Software Foundation, Inc. 本程序是自由软件;请参看源代码的版权声明。本软件没有任…...

HQChart使用教程30-K线图如何对接第3方数据42-DRAWTEXTREL,DRAWTEXTABS数据结构
HQChart使用教程30-K线图如何对接第3方数据42-DRAWTEXTREL,DRAWTEXTABS数据结构 效果图DRAWTEXTREL示例数据结构说明nametypecolorDrawVAlignDrawAlignDrawDrawTypeDrawDataFont DRAWTEXTABS示例数据结构说明nametypecolorDrawVAlignDrawAlignDrawDrawTypeDrawDataFont 效果图 …...

数仓高频面试 | 数仓为什么要分层
大家好,我是大D呀。 关于数仓分层,在面试过程中几乎是必问的。不过,面试官一般也不会直接考你数仓为什么要分层,而是在你介绍项目时,可能会换一种形式来穿插着问,比如数据链路为什么要这样设计,…...
网络安全—部署CA证书服务器
网络拓扑 两台服务器在同一网段即可,即能够互相ping通。 安装步骤 安装证书系统 首先我们对计算机名进行确认,安装了证书系统后我们是不能随意更改计算机名字的,因为以后颁发的证书都是和计算机也就是这一台的服务器名字有关。 修改完成后开…...

MATLAB中circshift函数的原理分析——psf2otf函数的核心
之所以讲到MATLAB中circshift函数,也是源于Rafael Gonzalez的这个图,作为前几篇答廖老师问的blog的基础。 Rafael Gonzalez的这个图无论从哪幅图到哪幅图都不是直接的傅里叶变换或傅里叶逆变换,需要循环移位,即circshift函数。 这…...

js 惰性函数
惰性函数 是一种优化技术,主要用于避免重复判断和计算。它在第一次调用时确定最终的执行逻辑,并将其替换为适当的函数实现,从而在后续调用中跳过不必要的判断或初始化。 惰性函数的核心思想 第一次调用时执行初始化逻辑,并根据环…...

智能技术引领未来:自动图像标注的创新应用与发展
🍑个人主页:Jupiter. 🚀 所属专栏:传知代码 欢迎大家点赞收藏评论😊 目录 概述算法原理核心逻辑效果演示使用方式参考文献 参考文献:需要本文的详细复现过程的项目源码、数据和预训练好的模型可从该地址处获…...

深入探索数据库世界:SQLite、Redis、MySQL 与数据库设计范式
数据库 深入探索数据库世界:SQLite、Redis、MySQL 与数据库设计范式一、SQLite 数据库全方位解析(一)创建与基本操作(二)数据存储与表结构设计(三)数据操作:增删改查(四)与 C 语言联合使用(五)防止 SQL 注入二、Redis 数据库深度剖析(一)数据存储类型与独特结构(…...

内网是如何访问到互联网的(华为源NAT)
私网地址如何能够访问到公网的? 在上一篇中,我们用任意一个内网的终端都能访问到百度的服务器,但是这是我们在互联网设备上面做了回程路由才实现的,在实际中,之前也说过运营商是不会写任何路由过来的,那对于…...

华为无线AC、AP模式与上线解析(Huawei Wireless AC, AP Mode and Online Analysis)
华为无线AC、AP模式与上线解析 为了实现fit 瘦AP的集中式管理,我们需要统一把局域网内的所有AP上线到AC,由AC做集中式管理部署。这里我们需要理解CAPWAP协议,该协议分为两种报文:1、管理报文 2、数据报文。管理报文实际在抓包过程…...

奖励模池化
奖励模池化 奖励模型概述 奖励模型(Reward Model)在机器学习,特别是强化学习领域中被广泛使用。它的主要作用是**对智能体(Agent)的行为进行评估并给予奖励。**例如,在训练一个机器人执行任务时,当机器人的动作符合预期目标(如成功抓取物品、按照正确路线行走等),奖励…...

基于django协同过滤的音乐推荐系统的设计与实现
一、摘要 随着现代音乐的快速发展,协同过滤的音乐推荐系统已成为人们业余生活的需求。该平台采用Python技术和django搭建系统框架,后台使用MySQL数据库进行信息管理;通过用户管理、音乐分类管理、音乐信息管理、歌曲数据管理、系统管理、我的…...

Tiptap,: 富文本编辑器入门与案例分析
Tiptap 是一个现代的富文本编辑器,基于 ProseMirror 打造,旨在提供一个灵活且功能强大的文本编辑解决方案。它具有开箱即用的能力,同时也允许开发者根据业务需求进行高度定制化扩展。与传统的富文本编辑器相比,Tiptap 提供了更精细…...
)
使用Linux的logrotate工具切割日志:Tomcat、NGINX(journal文件清理)
文章目录 引言I Tomcat日志切割配置轮转参数验证码II NGINX访问文件的配置和切割access.log 访问日志的配置使用Linux的logrotate工具切割日志验证文件切割III /run/log/journaljournalctl文件清理引言 journal文件清理: 只保留过去两天,清理之前的文件 journalctl --vacuu…...
-- 滤镜与混合模式详解)
CSS系列(11)-- 滤镜与混合模式详解
前端技术探索系列:CSS 滤镜与混合模式详解 🎨 致读者:探索视觉效果的艺术 👋 前端开发者们, 今天我们将深入探讨 CSS 滤镜与混合模式,学习如何创建独特的视觉效果。 滤镜效果详解 🚀 基础滤…...

linux - 存储管理
1.了解硬件 -- 磁盘 硬盘有机械硬盘(HDD)和固态硬盘(SDD) 接下来,主要以机械磁盘为例(更具代表性,在linux系统层面,无论是机械磁盘还是固态硬盘,文件的读取和写入都iNode(索引节点)管理文件的元数据和实际数据块) 1.盘片&#x…...
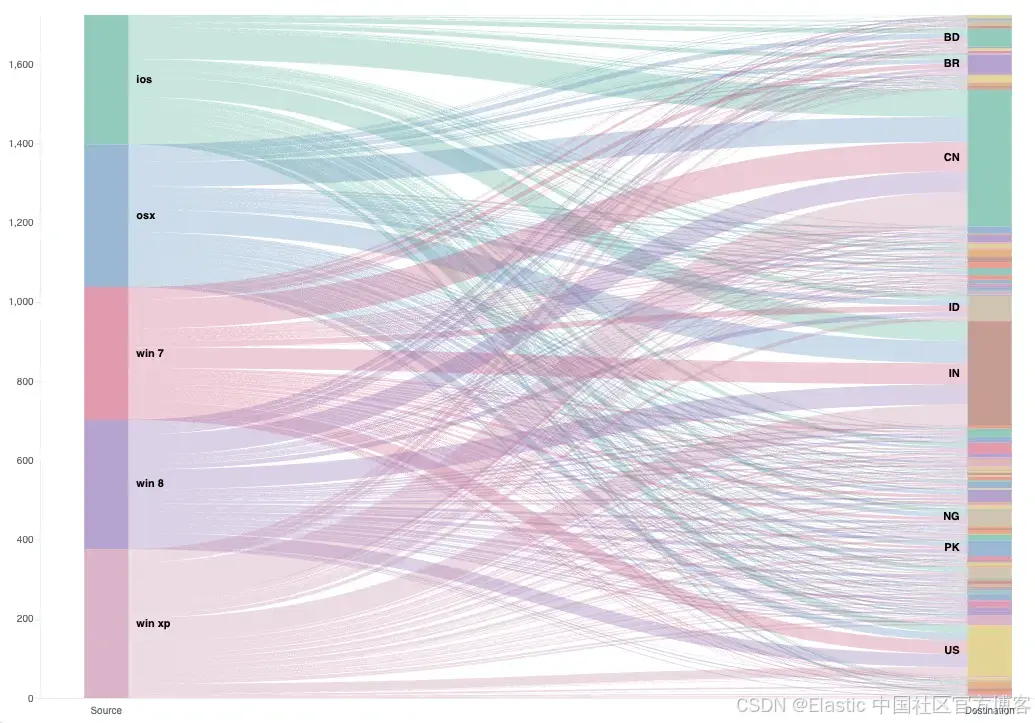
在 Kibana 中为 Vega Sankey 可视化添加过滤功能
作者:来自 Elastic Tim Bosman 及 Miloš Mandić 有兴趣在 Kibana 中为 Vega 可视化添加交互式过滤器吗?了解如何利用 “kibanaAddFilter” 函数轻松创建动态且响应迅速的 Sankey 可视化。 在这篇博客中,我们将了解如何启用 Vega Sankey 可视…...

3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南
3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否厌倦了每次运行AutoHotkey脚本都需要安…...

美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训
https://www.mckinsey.com/mgi/our-research/At-250-sustaining-Americas-competitive-edge 美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训 这一切始于一场惊天动地的反抗行动。 1776年7月,来自13…...

OpenSpire:开源贡献者协作平台的设计理念与实战指南
1. 项目概述:一个面向开源贡献者的协作平台最近在和一些刚接触开源的朋友交流时,发现一个挺普遍的现象:很多人对参与开源项目充满热情,但第一步“如何找到合适的项目并上手”就卡住了。GitHub上项目浩如烟海,一个新手面…...

openpilot自动驾驶系统深度解析:架构剖析与实战指南
openpilot自动驾驶系统深度解析:架构剖析与实战指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trending/…...

如何快速掌握阴阳师自动化脚本:OAS解放双手的完整教程
如何快速掌握阴阳师自动化脚本:OAS解放双手的完整教程 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化脚本(Onmyoji Auto Script,…...

如何3步获取百度网盘真实下载地址实现满速下载
如何3步获取百度网盘真实下载地址实现满速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾被百度网盘的非会员下载速度困扰?当下载重要的工作文件、学…...

【2026最新】鸿蒙NEXT ArkUI实战:培训班管理系统UI界面开发全攻略
鸿蒙UI开发总是踩坑?ArkUI组件用法记不住?本文用15分钟带你彻底搞懂ArkUI核心组件、布局系统、自定义组件和交互动画,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App界面从此丝滑流畅!一、培训班管理界面设计1…...

LLVM开发实战指南:从入门到精通编译器与程序分析
1. 项目概述:为什么你需要一份LLVM指南?如果你是一名C开发者,或者对编译器、程序分析、代码优化这些底层技术感兴趣,那么“LLVM”这个名字对你来说一定不陌生。它早已不是象牙塔里的学术玩具,而是驱动着从iOS、macOS到…...

EL线创客工作坊:从零到一的电致发光项目实践指南
1. 项目概述:为什么EL线工作坊是创客入门的绝佳选择如果你正在寻找一个能让新手快速上手、成品炫酷、且能完美融合电子与手工的创客项目,EL线工作坊几乎是一个无可挑剔的答案。EL,即电致发光,它不像LED那样依赖一个个分立的光点&a…...

Godot引擎实验项目解析:从角色控制到着色器优化的实战指南
1. 项目概述与核心价值如果你是一名游戏开发者,尤其是对独立游戏开发充满热情,那么“Godot”这个名字对你来说一定不陌生。它是一个功能强大、开源免费的游戏引擎,以其轻量、高效和友好的编辑器而闻名。然而,引擎本身只是一个工具…...