如何将你的 Ruby 应用程序从 OpenSearch 迁移到 Elasticsearch
作者:来自 Elastic Fernando Briano

将 Ruby 代码库从 OpenSearch 客户端迁移到 Elasticsearch 客户端的指南。
OpenSearch Ruby 客户端是从 7.x 版 Elasticsearch Ruby 客户端分叉而来的,因此代码库相对相似。这意味着当将 Ruby 代码库从 OpenSearch 迁移到 Elasticsearch 时,来自相应客户端库的代码看起来会非常熟悉。在这篇博文中,我将展示一个使用 OpenSearch 的示例 Ruby 应用程序以及将此代码迁移到 Elasticsearch 的步骤。
这两个客户端都是根据流行的 Apache 许可证 2.0 发布的,因此它们是开源和免费软件。Elasticsearch 的许可证最近进行了更新,Elasticsearch 和 Kibana 的核心自 8.16 版起根据 OSI 批准的开源许可证 AGPL 发布。
版本
迁移时需要考虑的一个问题是要使用哪个版本的 Elasticsearch。我们建议使用最新的稳定版本,在撰写本文时为 8.17.0。Elasticsearch Ruby 客户端次要版本遵循 Elasticsearch 次要版本。因此,对于 Elasticsearch 8.17.x,你可以使用 Ruby gem 的 8.17.x 版本。
OpenSearch 是从 Elasticsearch 7.10.2 分叉而来的。因此,API 可能已更改,并且可以使用不同的功能。但这超出了本文的范围,我只会在示例应用程序中研究最常见的操作。
对于 Ruby on Rails,你可以使用官方 Elasticsearch 客户端或 Rails 集成库。我们建议分别迁移到 Elasticsearch 和客户端的最新稳定版本。elasticsearch-rails gem 版本 8.0.0 支持 Rails 6.1、7.0 和 7.1 以及 Elasticsearch 8.x。
代码
对于此示例,我按照以下步骤从 tarball 安装 OpenSearch。下载并解压 tarball 后,我需要设置一个初始管理员密码,稍后我将使用该密码来实例化客户端。
我创建了一个包含 Gemfile 的目录,如下所示:
source 'https://rubygems.org'gem 'opensearch-ruby'运行 bundle install 后,我的项目就安装了 gem。这安装了 opensearch-ruby 版本 3.4.0,我运行的 OpenSearch 版本是 2.18.0。我在同一目录中的 example_code.rb 文件中编写了代码。此文件中的初始代码是 OpenSearch 客户端的实例化:
require 'opensearch'client = OpenSearch::Client.new(host: 'https://localhost:9200',user: 'admin',password: ENV['OPENSEARCH_INITIAL_ADMIN_PASSWORD'],transport_options: { ssl: { verify: false } }
)传输选项 ssl: { verify: false} 参数按照用户指南传递,以便于测试。在生产中,应根据 OpenSearch 的部署进行设置。
自 OpenSearch 2.12.0 版起,运行安装脚本时必须将 OPENSEARCH_INITIAL_ADMIN_PASSWORD 环境变量设置为强密码。按照从 tarball 安装 OpenSearch 的步骤,我在控制台中导出了该变量,现在它可用于我的 Ruby 脚本。
确保客户端连接到 OpenSearch 的简单 API 是使用 cluster.health API:
puts 'HEALTH:'
pp client.cluster.health确实有效:
$ be ruby example_code.rb
HEALTH:
{"cluster_name"=>"opensearch",
"status"=>"yellow","timed_out"=>false,"number_of_nodes"=>1,"number_of_data_nodes"=>1,我测试了 Elasticsearch Ruby 客户端文档中的一些常见示例,它们按预期工作:
index = 'books'
puts 'Creating index'
response = client.indices.create(index: index)
puts response
# Creating index
# {"acknowledged"=>true, "shards_acknowledged"=>true, "index"=>"books"}puts 'Indexing a document'
document = { title: 'The Time Machine', author: 'H. G. Wells', year: 1895 }
response = client.index(index: index, body: document, refresh: true)
puts response
# Indexing document
# {"_index"=>"books", "_id"=>"esalT5MB4vnuJz5TtqOc", "_version"=>1, "result"=>"created", "forced_refresh"=>true, "_shards"=>{"total"=>2, "successful"=>1, "failed"=>0}, "_seq_no"=>0, "_primary_term"=>1}id = response['_id']
puts 'Getting document'
response = client.get(index: index, id: id)
puts response
# Getting document
# {"_index"=>"books", "_id"=>"esalT5MB4vnuJz5TtqOc", "_version"=>1, "_seq_no"=>0, "_primary_term"=>1, "found"=>true, "_source"=>{"title"= >"The Time Machine", "author"=>"H. G. Wells", "year"=>1895}}puts "Does an index exist?"
puts client.indices.exists(index: 'imaginary_index')
# Does an index exist?
# falseputs 'Processing Bulk request'
body = [{ index: { _index: 'books', data: { name: 'Leviathan Wakes', author: 'James S.A. Corey', release_date: '2011-06-02', page_count: 561 } } },{ index: { _index: 'books', data: { name: 'Hyperion', author: 'Dan Simmons', release_date: '1989-05-26', page_count: 482 } } },{ index: { _index: 'books', data: { name: 'Dune', author: 'Frank Herbert', release_date: '1965-06-01', page_count: 604 } } },{ index: { _index: 'books', data: { name: 'Dune Messiah', author: 'Frank Herbert', release_date: '1969-10-15', page_count: 331 } } },{ index: { _index: 'books', data: { name: 'Children of Dune', author: 'Frank Herbert', release_date: '1976-04-21', page_count: 408 } } },{ index: { _index: 'books', data: { name: 'God Emperor of Dune', author: 'Frank Herbert', release_date: '1981-05-28', page_count: 454 } } },{ index: { _index: 'books', data: { name: 'Consider Phlebas', author: 'Iain M. Banks', release_date: '1987-04-23', page_count: 471 } } },{ index: { _index: 'books', data: { name: 'Pandora\'s Star', author: 'Peter F. Hamilton', release_date: '2004-03-02', page_count: 768 } } },{ index: { _index: 'books', data: { name: 'Revelation Space', author: 'Alastair Reynolds', release_date: '2000-03-15', page_count: 585 } } },{ index: { _index: 'books', data: { name: 'A Fire Upon the Deep', author: 'Vernor Vinge', release_date: '1992-06-01', page_count: 613 } } },{ index: { _index: 'books', data: { name: 'Ender\'s Game', author: 'Orson Scott Card', release_date: '1985-06-01', page_count: 324 } } },{ index: { _index: 'books', data: { name: '1984', author: 'George Orwell', release_date: '1985-06-01', page_count: 328 } } },{ index: { _index: 'books', data: { name: 'Fahrenheit 451', author: 'Ray Bradbury', release_date: '1953-10-15', page_count: 227 } } },{ index: { _index: 'books', data: { name: 'Brave New World', author: 'Aldous Huxley', release_date: '1932-06-01', page_count: 268 } } },{ index: { _index: 'books', data: { name: 'Foundation', author: 'Isaac Asimov', release_date: '1951-06-01', page_count: 224 } } },{ index: { _index: 'books', data: { name: 'The Giver', author: 'Lois Lowry', release_date: '1993-04-26', page_count: 208 } } },{ index: { _index: 'books', data: { name: 'Slaughterhouse-Five', author: 'Kurt Vonnegut', release_date: '1969-06-01', page_count: 275 } } },{ index: { _index: 'books', data: { name: 'The Hitchhiker\'s Guide to the Galaxy', author: 'Douglas Adams', release_date: '1979-10-12', page_count: 180 } } },{ index: { _index: 'books', data: { name: 'Snow Crash', author: 'Neal Stephenson', release_date: '1992-06-01', page_count: 470 } } },{ index: { _index: 'books', data: { name: 'Neuromancer', author: 'William Gibson', release_date: '1984-07-01', page_count: 271 } } },{ index: { _index: 'books', data: { name: 'The Handmaid\'s Tale', author: 'Margaret Atwood', release_date: '1985-06-01', page_count: 311 } } },{ index: { _index: 'books', data: { name: 'Starship Troopers', author: 'Robert A. Heinlein', release_date: '1959-12-01', page_count: 335 } } },{ index: { _index: 'books', data: { name: 'The Left Hand of Darkness', author: 'Ursula K. Le Guin', release_date: '1969-06-01', page_count: 304 } } },{ index: { _index: 'books', data: { name: 'The Moon is a Harsh Mistress', author: 'Robert A. Heinlein', release_date: '1966-04-01', page_count: 288 } } }
]
puts client.bulk(body: body, refresh: true)
# Processing Bulk request
# {"took"=>38, "errors"=>false, "items"=>[{"index"=>{"_index"=>"books", "_id"=>" ...query = { query: { multi_match: { query: 'dune', fields: ['name'] } } }
puts 'Search results'
response = client.search(index: index, body: query)
puts response
# Search results
# {"_index"=>"books", "_id"=>"oEawT5MBOXHuGXdEu5Wu", "_score"=>2.2886353, "_source"=>{"name"=>"Dune", "author"=>"Frank Herbert", "release_date"=>"1965-06-01", "page_count"=>604}}
# {"_index"=>"books", "_id"=>"oUawT5MBOXHuGXdEu5Wu", "_score"=>1.8893257, "_source"=>{"name"=>"Dune Messiah", "author"=>"Frank Herbert", "release_date"=>"1969-10-15", "page_count"=>331}}
# {"_index"=>"books", "_id"=>"okawT5MBOXHuGXdEu5Wu", "_score"=>1.6086557, "_source"=>{"name"=>"Children of Dune", "author"=>"Frank Herbert", "release_date"=>"1976-04-21", "page_count"=>408}}
# {"_index"=>"books", "_id"=>"o0awT5MBOXHuGXdEu5Wu", "_score"=>1.40059, "_source"=>{"name"=>"God Emperor of Dune", "author"=>"Frank Herbert", "release_date"=>"1981-05-28", "page_count"=>454}}puts 'Updating document'
document = { title: 'Walkaway', author: 'Cory Doctorow', release_date: '2017' }
response = client.index(index: index, body: document, refresh: true)
id = response['_id']
response = client.update(index: index, id: id, body: { doc: { release_date: '2017-04-26' } })
puts response
# Updating document
# {"_index"=>"books", "_id"=>"degnZJMBIGr4X0Yim55L", "_version"=>2, "result"=>"updated", "_shards"=>{"total"=>2, "successful"=>1, "failed"=>0}, "_seq_no"=>26, "_primary_term"=>1}puts 'Retrieveing multiple documents'
response = client.search(index: index, body: { query: { match_all: {} }, size: 3, stored_fields: '_id' })
ids = response['hits']['hits']
ids.map { |a| a.delete('_score') }
response = client.mget(body: { docs: [{ _index: index, _id: ids }] })
puts response
# Retrieveing multiple documents
# {"docs"=>[{"_index"=>"books", "_id"=>"qeg2ZJMBIGr4X0YiiqD2", "_version"=>1, "_seq_no"=>0, "_primary_term"=>1, "found"=>true, "_source"=>{"title"=>"The Time Machine", "author"=>"H. G. Wells", "year"=>1895}}, {"_index"=>"books", "_id"=>"q-g2ZJMBIGr4X0Yii6Ah", "_version"=>1, "_seq_no"=>1, "_primary_term"=>1, "found"=>true, "_source"=>{"name"=>"Leviathan Wakes", "author"=>"James S.A. Corey", "release_date"=>"2011-06-02", "page_count"=>561}}, {"_index"=>"books", "_id"=>"rOg2ZJMBIGr4X0Yii6Ah", "_version"=>1, "_seq_no"=>2, "_primary_term"=>1, "found"=>true, "_source"=>{"name"=>"Hyperion", "author"=>"Dan Simmons", "release_date"=>"1989-05-26", "page_count"=>482}}]}puts "Count #{client.count(index: index)['count']}"
puts 'Deleting by query'
response = client.delete_by_query(index: index, body: { query: { match: { author: 'Robert A. Heinlein' } } }, refresh: true)
puts response
puts "Count #{client.count(index: index)['count']}"
# Count 26
# Deleting by query
# {"took"=>16, "timed_out"=>false, "total"=>2, "deleted"=>2, "batches"=>1, "version_conflicts"=>0, "noops"=>0, "retries"=>{"bulk"=>0, "search"=>0}, "throttled_millis"=>0, "requests_per_second"=>-1.0, "throttled_until_millis"=>0, "failures"=>[]}
# Count 24puts 'Deleting document'
response = client.delete(index: index, id: id)
puts response
# Deleting document
# {"_index"=>"books", "_id"=>"nEawT5MBOXHuGXdEu5WA", "_version"=>2, "result"=>"deleted", "_shards"=>{"total"=>2, "successful"=>1, "failed"=>0}, "_seq_no"=>25, "_primary_term"=>1}puts 'Deleting index'
response = client.indices.delete(index: index)
puts response
# Deleting index
# {"acknowledged"=>true}迁移到 Elasticsearch
第一步是在 Gemfile 中添加 elasticsearch-ruby。运行 bundle install 后,将安装 Elasticsearch Ruby 客户端 gem。如果你想在完全迁移之前测试你的代码,你可以先将 opensearch-ruby gem 保留在那里。
下一个重要步骤是客户端实例化。这将取决于你如何运行 Elasticsearch。为了保持这些示例的类似方法,我按照下载 Elasticsearch 并在本地运行它中的步骤进行操作。
运行 bin/elasticsearch 时,Elasticsearch 将启动并自动配置安全功能。请确保复制 elastic 用户的密码(但你可以通过运行 bin/elasticsearch-reset-password -u elastic 来重置它)。如果你按照此示例操作,请确保在启动 Elasticsearch 之前停止 OpenSearch,因为它们在同一个端口上运行。
在 example_code.rb 的开头,我注释掉了 OpenSearch 客户端实例并添加了 Elasticsearch 客户端的实例:
# require 'opensearch'# client = OpenSearch::Client.new(
# host: 'https://localhost:9200',
# user: 'admin',
# password: ENV['OPENSEARCH_INITIAL_ADMIN_PASSWORD']
# transport_options: { ssl: { verify: false } }
# )require 'elasticsearch'client = Elasticsearch::Client.new(host: 'https://localhost:9200',user: ENV['ELASTICSEARCH_USER'],password: ENV['ELASTICSEARCH_PASSWORD'],transport_options: { ssl: { verify: false } }
)如你所见,此测试场景中的代码几乎相同。它会根据 Elasticsearch 的部署以及你决定如何连接和验证它而有所不同。这里与 OpenSearch 中的安全性相同,不验证 SSL 的选项仅用于测试目的,不应在生产中使用。
设置客户端后,我使用以下命令再次运行代码:bundle exec ruby example_code.rb。一切正常!
调试
根据你的应用程序使用的 API,如果 OpenSearch 的 API 不同,则在针对 Elasticsearch 运行代码时可能会收到错误。REST API 文档是有关如何使用 API 的详细信息的重要参考。请务必检查你正在使用的 Elasticsearch 版本的文档。你还可以参考 Elasticsearch::API 参考。
你可能遇到的一些 Elasticsearch 错误可能是:
- ArgumentError: Required argument '<ARGUMENT>' missing - 这是一个客户端错误,当请求缺少必需参数时会引发此错误。
- Elastic::Transport::Transport::Errors::BadRequest: [400] {"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"request [/example/_doc] contains unrecognized parameter: [test]"}]... 此错误来自 Elasticsearch,这意味着客户端代码正在使用 Elasticsearch 无法识别的参数。
Elasticsearch 客户端将通过服务器发送的详细错误消息引发 Elasticsearch 错误。因此,即使对于不支持的参数或端点,错误也应该会告知你有什么不同。
结论
正如我们通过此示例代码所演示的那样,从 Ruby 的角度来看,将 Ruby 应用程序从 OpenSearch 迁移到 Elasticsearch 并不太复杂。你需要了解搜索引擎之间的版本控制和任何潜在的不同 API。但对于最常见的操作,迁移客户端时的主要变化是在实例化中。它们在这方面都很相似,但主机和凭据的定义方式因 Stack 的部署方式而异。设置客户端并验证它是否连接到 Elasticsearch 后,你可以用 Elasticsearch 客户端无缝替换 OpenSearch 客户端。
想要获得 Elastic 认证?了解下一次 Elasticsearch 工程师培训何时开始!
Elasticsearch 包含新功能,可帮助你为你的用例构建最佳搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用,或立即在你的本地机器上试用 Elastic。
原文:https://www.elastic.co/search-labs/blog/ruby-opensearch-elasticsearch-migration
相关文章:
如何将你的 Ruby 应用程序从 OpenSearch 迁移到 Elasticsearch
作者:来自 Elastic Fernando Briano 将 Ruby 代码库从 OpenSearch 客户端迁移到 Elasticsearch 客户端的指南。 OpenSearch Ruby 客户端是从 7.x 版 Elasticsearch Ruby 客户端分叉而来的,因此代码库相对相似。这意味着当将 Ruby 代码库从 OpenSearch 迁…...

day1数据结构,关键字,内存空间存储与动态分区,释放
小练习 在堆区空间连续申请5个int类型大小空间,用来存放从终端输入的5个学生成绩,然后显示5个学生成绩,再将学生成绩升序排序,排序后,再次显示学生成绩。显示和排序分别用函数完成(两种排序方法࿰…...
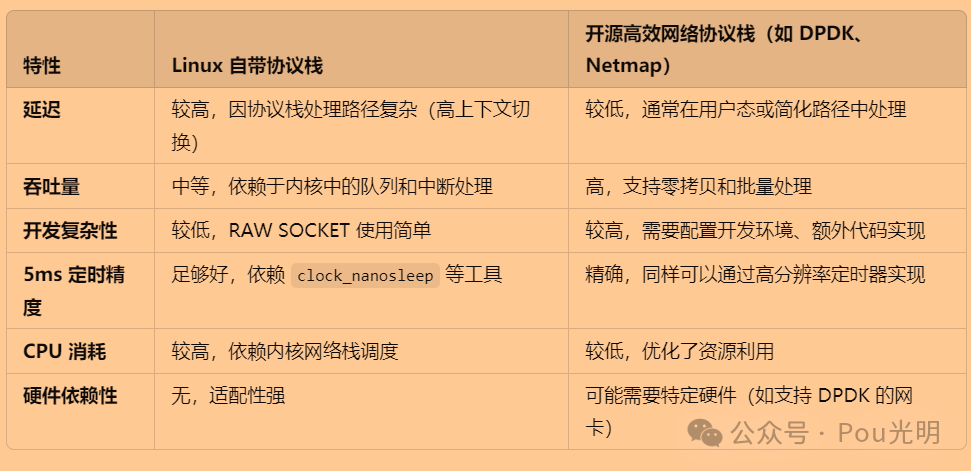
1_linux系统网络性能如何优化——几种开源网络协议栈比较
之前合集《计算机网络从入门到放弃》第一阶段算是已经完成了。都是理论,没有实操,让“程序猿”很难受,操作性不如 Modbus发送的报文何时等到应答和 tcp通信测试报告单1——connect和send。开始是想看linux内核网络协议栈的源码,然…...

【问题记录】07 MAC电脑,使用FileZilla(SFTP)连接堡垒机不成功
项目场景: 使用MAC电脑,以子账号(非root)的形式登录,连接堡垒机CLB(传统型负载均衡),使用FileZilla(SFTP)进行FTP文件传输。 问题描述: MAC电脑…...

前端报错npm ERR cb() never called问题
环境使用node版本v14.21.3,npm版本6.14.18 1.问题描述 1.1使用npm install后报错 npm ERR! cb() never called!npm ERR! This is an error with npm itself. Please report this error at: npm ERR! ? ? <https://npm.community>npm ERR! A complete log…...
康谋方案 | 多源相机数据采集与算法集成测试方案
目录 一、相机组成 二、多源相机采集与测试方案 三、应用案例分享 四、结语 在智能化技术快速发展当下,图像数据的采集与处理逐渐成为自动驾驶、工业等领域的一项关键技术。高质量的图像数据采集与算法集成测试都是确保系统性能和可靠性的关键。随着技术的不断进…...

Graspness 端到端抓取点估计 | 环境搭建 | 模型推理测试
在复杂场景中实现抓取检测,Graspness是一种端到端的方法; 输入点云数据,输出抓取角度、抓取深度、夹具宽度等信息。 开源地址:https://github.com/rhett-chen/graspness_implementation?tabreadme-ov-file 论文地址࿱…...
)
交换机是如何避免数据碰撞的(详细解释 + 示例)
交换机是如何避免数据碰撞的(详细解释 示例) 1. 独立冲突域 交换机的每个端口都形成一个独立的冲突域。这意味着通过交换机连接的每个设备都拥有自己的通信通道,互不干扰。 示例: 假设一个交换机有4个端口,分别连接…...

魅族手机刷官方系统
从魅族官网下载固件 https://flyme.cn/firmware.html 找到自己的型号,里面有历史版本、最新版,按照需求下载。 下载的是update.zip,改名就不能升级了 方法1 直接点击下载的update.zip包就可以升级。 方法2 将文件移动到文件管理的根目录&a…...

女人想要的,是那份懂她的情绪价值
女人想要的,是那份懂她的情绪价值 在情感的世界里,我们常常听到这样的声音:“我不需要你帮我解决问题,我只希望你能懂我。”这句话,简单却深刻,它揭示了女性在情感需求上的一个独特面向——她们渴望的&…...

[python SQLAlchemy数据库操作入门]-10.性能优化:提升 SQLAlchemy 在股票数据处理中的速度
哈喽,大家好,我是木头左! 当处理大量数据时,如股票数据,默认的ORM操作可能会显得效率低下。本文将探讨如何通过一些技巧和策略来优化SQLAlchemy ORM的性能,从而提升其在股票数据处理中的速度。 1. 选择合适的数据类型 在定义模型时,选择合适的数据类型对于性能至关重要…...

【网络取证篇】取证实战之PHP服务器镜像网站重构及绕密分析
【网络取证篇】取证实战之PHP服务器镜像网站重构及绕密分析 在裸聊敲诈、虚假理财诈骗案件类型中,犯罪分子为了能实现更低成本、更快部署应用的目的,其服务器架构多为常见的初始化网站架构,也称为站库同体服务器!也就是说网站应用…...

[python]使用 Pandas 处理 Excel 数据:分割与展开列操作
在数据处理的过程中,时常需要对 Excel 表格中的数据进行清洗与转换,下面介绍使用 Python 中的 Pandas 库对 Excel 文件中的数据进行操作,具体包括分割列、展开数据、清除空格以及格式转换等操作。 目标: 读取一个没有表头的 Exc…...

单片机的选择因素
在选择单片机型号时,需要根据具体的应用需求来选择合适的单片机。单片机(Microcontroller Unit, MCU)是一种将计算机的主要部分集成在一个芯片上的微型计算机,它通常包括处理器、存储器、输入/输出接口等。随着技术的发展…...

软件测试兼容性测试丨分布式测试与多设备管理
本文将从分布式测试的概念、重要性以及实施方法入手,紧接着探讨多设备管理的必要性和管理策略,最后分析其对软件测试行业的前景与影响。 分布式测试简介 什么是分布式测试? 分布式测试是指将测试任务分散到不同的计算机或者设备上进行&…...

Linux驱动开发(13):输入子系统–按键输入实验
计算机的输入设备繁多,有按键、鼠标、键盘、触摸屏、游戏手柄等等,Linux内核为了能够将所有的输入设备进行统一的管理, 设计了输入子系统。为上层应用提供了统一的抽象层,各个输入设备的驱动程序只需上报产生的输入事件即可。 下…...

微服务篇-微服务保护:使用 Sentinel 来实现请求限流、线程隔离、服务熔断和 Fallback 备用方案的使用
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 微服务保护 1.1 请求限流方案 1.2 线程隔离方案 1.3 服务熔断方案 2.0 Sentinel 2.1 Sentinel 安装 2.2 微服务整合 3.0 Sentinel-请求限流 4.0 Sentinel-线程隔离…...

vscode 排除文件夹搜索
排除的文件夹 node_modules/,dist/...

设计模式学习之——装饰者模式
装饰者模式(Decorator Pattern)是一种结构型设计模式,它允许你动态地向一个现有的对象添加新的行为,同时又不改变其结构。 一、定义与特点 定义:装饰者模式动态地将责任附加到对象上。若要扩展功能,装饰者…...

【Vulkan入门】10-CreatePipeline
目录 先叨叨Git信息关键代码TestPipeline::Initialize() 编译运行 先叨叨 到上篇为止已经创建了FrameBuffer和RenderPass。建立Pipeline的先决条件已经具备。本篇就来创建Pipeline。 Git信息 repository: https://gitee.com/J8_series/easy-car-uitag: 10-CreatePipelineurl…...

Unity 2D物理关节底层原理与实战避坑指南
1. 为什么2D物理关节不是“加个组件就完事”——从一个弹球卡墙的bug说起我第一次在Unity里拖进一个HingeJoint2D,想做个旋转门,结果运行时门直接飞出屏幕,撞上墙后像被磁铁吸住一样死死贴着不动。当时以为是刚体质量设错了,调了半…...

终极指南:3分钟学会用Awoo Installer免费安装Switch游戏
终极指南:3分钟学会用Awoo Installer免费安装Switch游戏 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游戏安装而烦恼吗…...

我用AI一周做了个口播视频平台,现在开源了
做独立开发这两年,我一直在想一个问题:一个人到底能做到什么程度? 上周我给出了自己的答案——我用 DeepSeek 定义需求 CodeBuddy 辅助编码,一个人从零搞了一个 AI 口播视频生成平台,取名智播坊。输入文案࿰…...

NoFences:免费开源的Windows桌面整理终极方案,告别杂乱桌面
NoFences:免费开源的Windows桌面整理终极方案,告别杂乱桌面 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为Windows桌面上杂乱无章的图标而烦恼…...

ConstraintLayout的‘隐藏技巧’:用百分比、比例和GoneMargin搞定复杂UI适配
ConstraintLayout高级适配技巧:百分比、比例与动态隐藏视图的完美解决方案 在Android开发中,ConstraintLayout已经成为构建复杂界面的首选布局方式。但许多开发者仅仅停留在基础使用层面,未能充分发挥其强大的适配能力。本文将深入探讨三个关…...

Steam创意工坊下载难题终结者:WorkshopDL让你的模组下载从未如此简单
Steam创意工坊下载难题终结者:WorkshopDL让你的模组下载从未如此简单 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为想玩Steam创意工坊的模组却没有Steam账号…...

如何用Seraphine智能游戏助手5分钟提升排位赛胜率:免费英雄联盟战绩查询工具完整指南
如何用Seraphine智能游戏助手5分钟提升排位赛胜率:免费英雄联盟战绩查询工具完整指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 还在为排位赛的BP阶段手忙脚乱吗?每次选英雄时都担…...

3步解锁你的专属B站:Bilibili-Evolved开源增强工具完全指南
3步解锁你的专属B站:Bilibili-Evolved开源增强工具完全指南 【免费下载链接】Bilibili-Evolved 强大的哔哩哔哩增强脚本 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Evolved 你是否曾对B站千篇一律的界面感到审美疲劳?是否被首页推荐…...

CANN/PyPTO精度调试指南
精度调试 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 简介 当PyPTO算子执行后无功能告警或报错,但输出数据不符合预期时&#x…...

3步解锁Beyond Compare 5专业版:Python密钥生成器终极指南
3步解锁Beyond Compare 5专业版:Python密钥生成器终极指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 还在为Beyond Compare 5的30天试用期而烦恼吗?想免费使用这款强…...