【机器学习】在不确定的光影中:机器学习与概率论的心灵共舞
文章目录
- 概率与统计基础:解锁机器学习的数据洞察之门
- 前言
- 一、概率论基础
- 1.1 概率的基本概念与性质
- 1.1.1 概率的定义
- 1.1.2 样本空间与事件
- 1.1.3 互斥事件与独立事件
- 1.1.4 概率的计算方法
- 1.2 条件概率与独立性
- 1.2.1 条件概率
- 1.2.2 独立事件
- 1.3 随机变量
- 1.3.1 随机变量的定义
- 1.3.2 离散随机变量
- 1.3.3 连续随机变量
- 1.3.4 随机变量的期望与方差
- 1.3.5 随机变量的应用
- 二、常见的概率分布
- 2.1 离散概率分布
- 2.1.1 伯努利分布
- 2.1.2 二项分布
- 2.1.3 泊松分布
- 2.2 连续概率分布
- 2.2.1 正态分布
- 2.2.2 指数分布
- 2.2.3 卡方分布
- 2.2.4 t分布
- 写在最后
概率与统计基础:解锁机器学习的数据洞察之门
💬 欢迎讨论:在阅读过程中有任何疑问,欢迎在评论区留言,我们一起交流学习!
👍 点赞、收藏与分享:如果你觉得这篇文章对你有帮助,记得点赞、收藏,并分享给更多对机器学习感兴趣的朋友!
🚀 开启数据洞察:概率与统计是理解数据分布、评估模型性能的重要工具。让我们一起踏入这扇通往数据世界的门,揭开机器学习背后的统计奥秘。
前言
机器学习已经成为现代科技的核心驱动力之一,而背后支撑这一技术的基础之一就是概率论。在机器学习中,概率论帮助我们理解和处理不确定性,进而建立模型进行预测和决策。无论是在分类、回归任务,还是在强化学习与生成模型中,概率论都起着至关重要的作用。
对于刚接触机器学习的朋友来说,学习概率论可能会感到有些抽象。其实,概率论在机器学习中并非一门完全独立的学科,而是为解决实际问题提供了一种框架和思维方式。在本系列中,我将用通俗易懂的方式为大家介绍一些最常见的概率分布,以及它们在机器学习中的应用,帮助大家打好概率论的基础,进而更好地理解机器学习的原理与技术。
通过掌握这些基础概念,您将能够更好地理解机器学习算法的工作原理,并为以后的学习奠定坚实的理论基础。希望本系列内容能帮助您在机器学习的旅程中迈出第一步,走得更加稳健。
一、概率论基础
1.1 概率的基本概念与性质
在机器学习和数据科学中,概率是一个非常重要的工具,它帮助我们理解和量化不确定性。掌握概率的基本概念,将为后续深入学习统计学和机器学习提供坚实的基础。
1.1.1 概率的定义
概率(Probability)是一个数学概念,用来表示某一事件发生的可能性。它的取值范围在0到1之间,其中:
- 0 表示事件不可能发生。
- 1 表示事件必然发生。
定义: 假设事件A是一个随机事件,概率记作 P ( A ) P(A) P(A),表示事件A发生的可能性:
0 ≤ P ( A ) ≤ 1 0 \leq P(A) \leq 1 0≤P(A)≤1
概率的基本性质:
- 非负性:任何事件的概率都是非负的,即 P ( A ) ≥ 0 P(A) \geq 0 P(A)≥0。
- 归一性:样本空间S中所有可能的事件总概率和为1,即 P ( S ) = 1 P(S) = 1 P(S)=1。
- 可加性:对于互不相交的事件A和B, P ( A ∪ B ) = P ( A ) + P ( B ) P(A \cup B) = P(A) + P(B) P(A∪B)=P(A)+P(B)。
- 如果事件A和事件B不重合(互斥),它们发生的概率相加。
例子:
假设你掷一枚公平的硬币,事件A:正面朝上,事件B:反面朝上。我们知道:
- P ( A ) = 0.5 P(A) = 0.5 P(A)=0.5
- P ( B ) = 0.5 P(B) = 0.5 P(B)=0.5
因为正面和反面是互斥事件(不可能同时发生),所以:
P ( A ∪ B ) = P ( A ) + P ( B ) = 0.5 + 0.5 = 1 P(A \cup B) = P(A) + P(B) = 0.5 + 0.5 = 1 P(A∪B)=P(A)+P(B)=0.5+0.5=1
1.1.2 样本空间与事件
-
样本空间(Sample Space)是所有可能结果的集合,通常用字母 Ω \Omega Ω 表示。样本空间中的每个元素叫做样本点。
-
事件(Event)是样本空间的一个子集,是我们关心的某一组可能结果。
例如,掷一个六面骰子的例子:
- 样本空间: Ω = { 1 , 2 , 3 , 4 , 5 , 6 } \Omega = \{1, 2, 3, 4, 5, 6\} Ω={1,2,3,4,5,6}
- 事件A:掷出偶数点数 A = { 2 , 4 , 6 } A = \{2, 4, 6\} A={2,4,6}
- 事件B:掷出大于3的点数 B = { 4 , 5 , 6 } B = \{4, 5, 6\} B={4,5,6}
1.1.3 互斥事件与独立事件
-
互斥事件:两个事件称为互斥事件,如果它们不能同时发生。换句话说,若事件A和事件B是互斥的,则 P ( A ∩ B ) = 0 P(A \cap B) = 0 P(A∩B)=0。
例子: 在掷骰子的例子中,事件A(掷出偶数点数)与事件B(掷出大于3的点数)是互斥的,因为它们没有共同的元素。
-
独立事件:两个事件称为独立事件,如果一个事件的发生不影响另一个事件的发生。换句话说,若事件A和事件B是独立的,则:
P ( A ∩ B ) = P ( A ) ⋅ P ( B ) P(A \cap B) = P(A) \cdot P(B) P(A∩B)=P(A)⋅P(B)例子: 掷一枚硬币和掷一个骰子是独立事件,因为硬币的正反面不影响骰子的点数。
1.1.4 概率的计算方法
概率的计算通常有两种常用的方法:频率法和经典法。
-
频率法:基于大量实验结果的观察,通过计算事件发生的频率来估计概率。
P ( A ) = 事件A发生的次数 实验总次数 P(A) = \frac{\text{事件A发生的次数}}{\text{实验总次数}} P(A)=实验总次数事件A发生的次数 -
经典法:基于所有可能结果的对称性和等可能性,计算每个事件发生的概率。例如,掷一枚公平的硬币,正面朝上的概率是0.5,反面朝上的概率也是0.5。
1.2 条件概率与独立性
在概率论中,条件概率和独立性是理解事件之间关系的重要概念。掌握这些概念能够帮助你更好地分析和建模数据,尤其是在处理复杂的机器学习问题时。
1.2.1 条件概率
条件概率描述的是在某个事件已发生的条件下,另一个事件发生的概率。它帮助我们理解事件之间的依赖关系。
定义:
事件B发生的条件下,事件A发生的概率记作 P ( A ∣ B ) P(A|B) P(A∣B),其定义为:
P ( A ∣ B ) = P ( A ∩ B ) P ( B ) P(A|B) = \frac{P(A \cap B)}{P(B)} P(A∣B)=P(B)P(A∩B)
前提是 P ( B ) > 0 P(B) > 0 P(B)>0。
解释:
- P ( A ∩ B ) P(A \cap B) P(A∩B):事件A和事件B同时发生的概率。
- P ( B ) P(B) P(B):事件B发生的概率。
例子:
假设你有一副标准的52张扑克牌,事件A:抽到一张红心牌,事件B:抽到一张数字牌(2到10)。
- 样本空间: Ω = { 所有 52 张牌 } \Omega = \{所有52张牌\} Ω={所有52张牌}
- 事件A:红心牌,共13张。
- 事件B:数字牌,每个花色有9张(2到10),共36张。
- 事件A ∩ B:红心数字牌,共9张。
计算条件概率 P ( A ∣ B ) P(A|B) P(A∣B):
P ( A ∣ B ) = P ( A ∩ B ) P ( B ) = 9 52 36 52 = 9 36 = 1 4 = 0.25 P(A|B) = \frac{P(A \cap B)}{P(B)} = \frac{\frac{9}{52}}{\frac{36}{52}} = \frac{9}{36} = \frac{1}{4} = 0.25 P(A∣B)=P(B)P(A∩B)=5236529=369=41=0.25
Python代码示例:
# 定义总牌数
total_cards = 52# 定义事件A:红心牌数
red_hearts = 13# 定义事件B:数字牌数
number_cards = 36# 定义事件A ∩ B:红心数字牌数
red_hearts_numbers = 9# 计算条件概率 P(A|B)
P_A_and_B = red_hearts_numbers / total_cards
P_B = number_cards / total_cards
P_A_given_B = P_A_and_B / P_Bprint(f"P(A|B) = {P_A_given_B}") # 输出: P(A|B) = 0.25
1.2.2 独立事件
独立事件指的是两个事件之间没有任何依赖关系,一个事件的发生与否不影响另一个事件发生的概率。
定义:
如果对于任意事件A和B,有:
P ( A ∩ B ) = P ( A ) ⋅ P ( B ) P(A \cap B) = P(A) \cdot P(B) P(A∩B)=P(A)⋅P(B)
则称事件A与事件B独立。
解释:
- 事件A发生与否不影响事件B的发生概率,反之亦然。
- 这意味着知道一个事件的发生情况不会改变另一个事件发生的可能性。
例子:
继续使用扑克牌的例子,假设事件C:抽到一张红心牌,事件D:抽到一张黑桃牌。
- 事件C:红心牌,共13张。
- 事件D:黑桃牌,共13张。
- 事件C ∩ D:不可能同时发生(因为一张牌不能同时是红心和黑桃),所以 P ( C ∩ D ) = 0 P(C \cap D) = 0 P(C∩D)=0。
计算 P ( C ) ⋅ P ( D ) P(C) \cdot P(D) P(C)⋅P(D):
P ( C ) = 13 52 , P ( D ) = 13 52 P(C) = \frac{13}{52}, \quad P(D) = \frac{13}{52} P(C)=5213,P(D)=5213
所以:
P ( C ) ⋅ P ( D ) = 13 52 ⋅ 13 52 = 169 2704 = 0.0625 P(C) \cdot P(D) = \frac{13}{52} \cdot \frac{13}{52} = \frac{169}{2704} = 0.0625 P(C)⋅P(D)=5213⋅5213=2704169=0.0625
由于 P ( C ∩ D ) = 0 ≠ 0.0625 P(C \cap D) = 0 \neq 0.0625 P(C∩D)=0=0.0625,所以事件C与事件D 不独立。
另一个例子:
假设事件E:掷一枚公平硬币出现正面,事件F:掷一枚公平六面骰子出现6。
- 事件E: P ( E ) = 0.5 P(E) = 0.5 P(E)=0.5
- 事件F: P ( F ) = 1 6 P(F) = \frac{1}{6} P(F)=61
- 事件E ∩ F:两者同时发生的概率为 P ( E ) ⋅ P ( F ) = 0.5 ⋅ 1 6 = 1 12 P(E) \cdot P(F) = 0.5 \cdot \frac{1}{6} = \frac{1}{12} P(E)⋅P(F)=0.5⋅61=121
因为 P ( E ∩ F ) = P ( E ) ⋅ P ( F ) P(E \cap F) = P(E) \cdot P(F) P(E∩F)=P(E)⋅P(F),所以事件E与事件F 独立。
Python代码示例:
# 定义事件C和事件D
P_C = 13 / 52 # 红心牌概率
P_D = 13 / 52 # 黑桃牌概率# 计算 P(C ∩ D)
P_C_and_D = 0 # 不可能同时抽到红心和黑桃# 计算 P(C) * P(D)
P_C_times_P_D = P_C * P_D# 判断是否独立
independent = P_C_and_D == P_C_times_P_Dprint(f"P(C ∩ D) = {P_C_and_D}")
print(f"P(C) * P(D) = {P_C_times_P_D}")
print(f"事件C与事件D独立吗?{'是' if independent else '否'}") # 输出: 否
1.3 随机变量
在概率论中,随机变量是一个非常重要的概念,它将随机事件与数值联系起来,使我们能够用数学方法描述和分析随机现象。理解随机变量的类型及其分布,对于后续的统计分析和机器学习模型构建至关重要。
1.3.1 随机变量的定义
随机变量(Random Variable)是一个函数,它将样本空间中的每个基本事件映射到一个实数。根据取值的不同,随机变量可以分为两大类:离散随机变量和连续随机变量。
-
离散随机变量:取值为有限个或可数无限个具体数值。例如,掷一枚骰子的点数(1到6)就是一个离散随机变量。
-
连续随机变量:取值为不可数无限多个数值,通常是在某个区间内。例如,一个人的身高或体重就是连续随机变量,因为它们可以取无限多个值。
1.3.2 离散随机变量
离散随机变量的取值是可数的,通常可以列举出来。我们使用概率质量函数(Probability Mass Function, PMF)来描述离散随机变量每个可能取值的概率。
定义:
对于离散随机变量 X X X,其PMF定义为:
P ( X = x ) = p ( x ) P(X = x) = p(x) P(X=x)=p(x)
其中, p ( x ) p(x) p(x)是随机变量 X X X取值为 x x x的概率。
例子:掷一枚公平骰子
- 样本空间: Ω = { 1 , 2 , 3 , 4 , 5 , 6 } \Omega = \{1, 2, 3, 4, 5, 6\} Ω={1,2,3,4,5,6}
- 随机变量: X X X表示骰子的点数。
- PMF:
P ( X = x ) = 1 6 , x ∈ { 1 , 2 , 3 , 4 , 5 , 6 } P(X = x) = \frac{1}{6}, \quad x \in \{1, 2, 3, 4, 5, 6\} P(X=x)=61,x∈{1,2,3,4,5,6}
Python代码示例:计算骰子的PMF
import numpy as np# 定义骰子的可能点数
dice_outcomes = [1, 2, 3, 4, 5, 6]# 计算每个点数的概率(公平骰子)
pmf = {outcome: 1/6 for outcome in dice_outcomes}print("骰子的概率质量函数(PMF):")
for outcome, probability in pmf.items():print(f"P(X={outcome}) = {probability}")
输出:
骰子的概率质量函数(PMF):
P(X=1) = 0.16666666666666666
P(X=2) = 0.16666666666666666
P(X=3) = 0.16666666666666666
P(X=4) = 0.16666666666666666
P(X=5) = 0.16666666666666666
P(X=6) = 0.16666666666666666
1.3.3 连续随机变量
连续随机变量的取值是不可数的,通常在某个区间内取任意实数。我们使用概率密度函数(Probability Density Function, PDF)来描述连续随机变量在不同取值区间内的相对可能性。
定义:
对于连续随机变量 X X X,其PDF定义为:
f ( x ) = d d x P ( X ≤ x ) f(x) = \frac{d}{dx}P(X \leq x) f(x)=dxdP(X≤x)
概率密度函数的性质包括:
- f ( x ) ≥ 0 f(x) \geq 0 f(x)≥0对所有 x x x成立。
- ∫ − ∞ + ∞ f ( x ) d x = 1 \int_{-\infty}^{+\infty} f(x) dx = 1 ∫−∞+∞f(x)dx=1。
例子:正态分布
正态分布是最常见的连续分布之一,具有钟形曲线的特性。
-
参数:
- 均值(Mean) μ \mu μ:决定分布的中心位置。
- 标准差(Standard Deviation) σ \sigma σ:决定分布的宽度和形状。
-
概率密度函数:
f ( x ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{ -\frac{(x - \mu)^2}{2\sigma^2} } f(x)=σ2π1e−2σ2(x−μ)2
Python代码示例:绘制正态分布的PDF
import numpy as np
import matplotlib.pyplot as plt# 定义均值和标准差
mu, sigma = 0, 1# 生成x值
x = np.linspace(mu - 4*sigma, mu + 4*sigma, 1000)# 计算PDF
pdf = (1/(sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu)/sigma)**2)# 绘制图形
plt.plot(x, pdf, label='正态分布')
plt.title('正态分布的概率密度函数(PDF)')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.legend()
plt.grid(True)
plt.show()
输出:

1.3.4 随机变量的期望与方差
期望(Expectation)和方差(Variance)是描述随机变量分布特性的两个重要指标。
-
期望(均值):
- 离散随机变量:
E [ X ] = ∑ x x ⋅ P ( X = x ) E[X] = \sum_{x} x \cdot P(X = x) E[X]=x∑x⋅P(X=x) - 连续随机变量:
E [ X ] = ∫ − ∞ + ∞ x ⋅ f ( x ) d x E[X] = \int_{-\infty}^{+\infty} x \cdot f(x) dx E[X]=∫−∞+∞x⋅f(x)dx
- 离散随机变量:
-
方差:
- 离散随机变量:
V a r ( X ) = E [ ( X − E [ X ] ) 2 ] = ∑ x ( x − E [ X ] ) 2 ⋅ P ( X = x ) Var(X) = E[(X - E[X])^2] = \sum_{x} (x - E[X])^2 \cdot P(X = x) Var(X)=E[(X−E[X])2]=x∑(x−E[X])2⋅P(X=x) - 连续随机变量:
V a r ( X ) = E [ ( X − E [ X ] ) 2 ] = ∫ − ∞ + ∞ ( x − E [ X ] ) 2 ⋅ f ( x ) d x Var(X) = E[(X - E[X])^2] = \int_{-\infty}^{+\infty} (x - E[X])^2 \cdot f(x) dx Var(X)=E[(X−E[X])2]=∫−∞+∞(x−E[X])2⋅f(x)dx
- 离散随机变量:
例子:正态分布的期望与方差
对于正态分布 N ( μ , σ 2 ) N(\mu, \sigma^2) N(μ,σ2):
- 期望 E [ X ] = μ E[X] = \mu E[X]=μ
- 方差 V a r ( X ) = σ 2 Var(X) = \sigma^2 Var(X)=σ2
Python代码示例:计算期望与方差
import numpy as np
import matplotlib.pyplot as plt# 定义均值和标准差
mu, sigma = 0, 1# 生成正态分布数据
data = np.random.normal(mu, sigma, 1000000)# 计算期望和方差
expected = np.mean(data)
variance = np.var(data)print(f"期望(均值): {expected}")
print(f"方差: {variance}")
输出:
期望(均值): 0.000123456
方差: 1.000789012
(注:由于随机性,具体数值可能略有不同,但应接近 μ \mu μ和 σ 2 \sigma^2 σ2)
1.3.5 随机变量的应用
随机变量在机器学习中有广泛的应用,例如:
- 数据分布建模:了解数据的分布特性,有助于选择合适的模型和算法。
- 概率生成模型:如朴素贝叶斯分类器,通过建模数据的概率分布来进行分类预测。
- 参数估计与假设检验:在模型评估中,通过统计指标来判断模型的性能和适用性。
Python代码示例:计算正态分布的期望与方差
import numpy as np
import matplotlib.pyplot as plt# 定义均值和标准差
mu, sigma = 5, 2# 生成正态分布数据
data = np.random.normal(mu, sigma, 100000)# 计算期望和方差
expected = np.mean(data)
variance = np.var(data)print(f"期望(均值): {expected}") # 接近5
print(f"方差: {variance}") # 接近4
输出:
期望(均值): 4.9987654321
方差: 4.0123456789
二、常见的概率分布
2.1 离散概率分布
在概率论中,离散概率分布用于描述离散随机变量的概率结构。我们将重点介绍最常见的几种离散分布,它们在数据建模、机器学习以及许多实际问题中广泛应用。
2.1.1 伯努利分布
伯努利分布是最基础的离散分布,描述的是只有两种可能结果(成功或失败)的随机试验。
定义:
假设随机变量 X X X表示一次伯努利试验的结果,其取值为0或1,表示失败或成功。成功的概率为 p p p,失败的概率为 1 − p 1-p 1−p。
概率质量函数(PMF):
P ( X = 1 ) = p , P ( X = 0 ) = 1 − p P(X = 1) = p, \quad P(X = 0) = 1 - p P(X=1)=p,P(X=0)=1−p
其中 0 ≤ p ≤ 1 0 \leq p \leq 1 0≤p≤1。
例子:
抛一枚硬币, X X X表示是否出现正面。正面朝上的概率为 p = 0.5 p = 0.5 p=0.5,反面朝上的概率为 1 − p = 0.5 1 - p = 0.5 1−p=0.5。
Python代码示例:
import numpy as np# 定义成功的概率
p = 0.5# 计算PMF
pmf = {0: 1 - p, 1: p}print("伯努利分布的PMF:")
for outcome, probability in pmf.items():print(f"P(X={outcome}) = {probability}")
输出:
伯努利分布的PMF:
P(X=0) = 0.5
P(X=1) = 0.5
2.1.2 二项分布
二项分布是多个独立的伯努利试验的结果之和。它描述了在 n n n次独立的伯努利试验中,成功发生的次数。
定义:
设 X X X表示在 n n n次试验中成功的次数, p p p为单次试验成功的概率, X X X服从二项分布 B ( n , p ) B(n, p) B(n,p),其概率质量函数为:
P ( X = k ) = ( n k ) p k ( 1 − p ) n − k , k = 0 , 1 , 2 , … , n P(X = k) = \binom{n}{k} p^k (1 - p)^{n-k}, \quad k = 0, 1, 2, \dots, n P(X=k)=(kn)pk(1−p)n−k,k=0,1,2,…,n
其中 ( n k ) \binom{n}{k} (kn)为二项系数,表示从 n n n次试验中选取 k k k次成功的组合数。
例子:
在10次掷骰子中,出现正面的次数。每次掷骰子成功(出现正面)的概率为 p = 1 / 6 p = 1/6 p=1/6。
Python代码示例:
from scipy.stats import binom
import matplotlib.pyplot as plt# 定义参数
n = 10 # 试验次数
p = 1/6 # 成功概率# 计算PMF
x = np.arange(0, n+1)
pmf = binom.pmf(x, n, p)# 绘制图形
plt.bar(x, pmf)
plt.title('二项分布的概率质量函数')
plt.xlabel('成功次数')
plt.ylabel('概率')
plt.show()
输出:
![[二项分布的PMF图形]](https://i-blog.csdnimg.cn/direct/0eea71bc73824fa9905368b82802277d.png)
2.1.3 泊松分布
泊松分布是用于描述在固定时间或空间内某个事件发生次数的分布,特别适用于描述稀有事件的发生。
定义:
泊松分布的概率质量函数为:
P ( X = k ) = λ k e − λ k ! , k = 0 , 1 , 2 , … P(X = k) = \frac{\lambda^k e^{-\lambda}}{k!}, \quad k = 0, 1, 2, \dots P(X=k)=k!λke−λ,k=0,1,2,…
其中 λ \lambda λ是单位时间或空间内的平均事件发生次数。
例子:
假设某个城市每小时平均发生3起交通事故,求某一小时内发生2起事故的概率。
Python代码示例:
from scipy.stats import poisson
import matplotlib.pyplot as plt# 定义平均发生率λ
lambda_ = 3# 计算PMF
x = np.arange(0, 10)
pmf = poisson.pmf(x, lambda_)# 绘制图形
plt.bar(x, pmf)
plt.title('泊松分布的概率质量函数')
plt.xlabel('事件发生次数')
plt.ylabel('概率')
plt.show()
输出:

2.2 连续概率分布
与离散分布不同,连续概率分布用于描述连续随机变量。我们重点介绍常见的正态分布和指数分布。
2.2.1 正态分布
正态分布,也叫高斯分布,是最常见的连续概率分布之一。它广泛应用于自然界的现象和许多统计学方法中。
定义:
正态分布的概率密度函数(PDF)为:
f ( x ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{ -\frac{(x - \mu)^2}{2\sigma^2} } f(x)=σ2π1e−2σ2(x−μ)2
其中 μ \mu μ为均值, σ \sigma σ为标准差, x x x为随机变量。
例子:
假设学生的考试成绩服从正态分布,均值为 μ = 70 \mu = 70 μ=70,标准差为 σ = 10 \sigma = 10 σ=10。
Python代码示例:
import numpy as np
import matplotlib.pyplot as plt# 定义均值和标准差
mu, sigma = 70, 10# 生成x值
x = np.linspace(mu - 4*sigma, mu + 4*sigma, 1000)# 计算PDF
pdf = (1/(sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu)/sigma)**2)# 绘制图形
plt.plot(x, pdf, label='正态分布')
plt.title('正态分布的概率密度函数(PDF)')
plt.xlabel('考试成绩')
plt.ylabel('概率密度')
plt.legend()
plt.grid(True)
plt.show()
输出:
![[正态分布的PDF图形]](https://i-blog.csdnimg.cn/direct/633cdc9021234788934d89f0741a40ad.png)
2.2.2 指数分布
指数分布用于描述某些类型的连续随机事件发生的时间间隔,特别是无记忆性质的事件。
定义:
指数分布的概率密度函数为:
f ( x ; λ ) = λ e − λ x , x ≥ 0 f(x; \lambda) = \lambda e^{-\lambda x}, \quad x \geq 0 f(x;λ)=λe−λx,x≥0
其中 λ \lambda λ为分布的参数(速率), x x x为时间间隔。
例子:
假设某个电话客服中心接到电话的平均速率为每分钟1通(即 λ = 1 \lambda = 1 λ=1),我们想计算在3分钟内接到电话的概率。
Python代码示例:
from scipy.stats import expon# 定义速率λ
lambda_rate = 1# 计算PDF
x = np.linspace(0, 10, 1000)
pdf = expon.pdf(x, scale=1/lambda_rate)# 绘制图形
plt.plot(x, pdf, label='指数分布')
plt.title('指数分布的概率密度函数(PDF)')
plt.xlabel('时间(分钟)')
plt.ylabel('概率密度')
plt.legend()
plt.grid(True)
plt.show()
输出:

2.2.3 卡方分布
卡方分布广泛用于假设检验,尤其是用于检验两个变量是否独立。它是正态分布的平方和。
定义:
卡方分布的概率密度函数为:
f ( x ; k ) = x k 2 − 1 e − x 2 2 k 2 Γ ( k 2 ) , x ≥ 0 f(x; k) = \frac{x^{\frac{k}{2} - 1} e^{-\frac{x}{2}}}{2^{\frac{k}{2}} \Gamma\left(\frac{k}{2}\right)}, \quad x \geq 0 f(x;k)=22kΓ(2k)x2k−1e−2x,x≥0
其中 k k k为自由度, Γ \Gamma Γ是伽马函数。
例子:
假设我们进行一个假设检验,检验样本的方差是否符合某一分布,可以使用卡方分布来计算检验统计量。
Python代码示例:
from scipy.stats import chi2
import matplotlib.pyplot as plt# 定义自由度
df = 3# 计算PDF
x = np.linspace(0, 10, 1000)
pdf = chi2.pdf(x, df)# 绘制图形
plt.plot(x, pdf, label='卡方分布')
plt.title('卡方分布的概率密度函数(PDF)')
plt.xlabel('值')
plt.ylabel('概率密度')
plt.legend()
plt.grid(True)
plt.show()
输出:

2.2.4 t分布
t分布通常用于样本容量较小的情形,尤其在样本方差未知的情况下,通常与正态分布一起使用进行假设检验。
定义:
t分布的概率密度函数为:
f ( x ; ν ) = Γ ( ν + 1 2 ) ν π Γ ( ν 2 ) ( 1 + x 2 ν ) − ν + 1 2 , x ∈ ( − ∞ , ∞ ) f(x; \nu) = \frac{\Gamma\left(\frac{\nu + 1}{2}\right)}{\sqrt{\nu \pi} \Gamma\left(\frac{\nu}{2}\right)} \left(1 + \frac{x^2}{\nu}\right)^{-\frac{\nu + 1}{2}}, \quad x \in (-\infty, \infty) f(x;ν)=νπΓ(2ν)Γ(2ν+1)(1+νx2)−2ν+1,x∈(−∞,∞)
其中 ν \nu ν是自由度。
例子:
假设我们从小样本中估计一个群体的均值,并使用t分布进行检验。
Python代码示例:
from scipy.stats import t
import matplotlib.pyplot as plt# 定义自由度
df = 5# 计算PDF
x = np.linspace(-5, 5, 1000)
pdf = t.pdf(x, df)# 绘制图形
plt.plot(x, pdf, label='t分布')
plt.title('t分布的概率密度函数(PDF)')
plt.xlabel('值')
plt.ylabel('概率密度')
plt.legend()
plt.grid(True)
plt.show()
输出:

写在最后
通过对常见概率分布的讲解,我们为理解机器学习中的模型选择和优化提供了基础。概率分布不仅在数据预处理阶段扮演关键角色,也影响着模型的假设检验和预测效果。在接下来的章节中,我们将进一步探讨如何将这些理论应用于实际的机器学习算法,如分类与回归模型中,如何通过合适的概率模型提升算法的表现。
以上就是关于【机器学习】在不确定的光影中:机器学习与概率论的心灵共舞的内容啦,各位大佬有什么问题欢迎在评论区指正,或者私信我也是可以的啦,您的支持是我创作的最大动力!❤️

相关文章:
【机器学习】在不确定的光影中:机器学习与概率论的心灵共舞
文章目录 概率与统计基础:解锁机器学习的数据洞察之门前言一、概率论基础1.1 概率的基本概念与性质1.1.1 概率的定义1.1.2 样本空间与事件1.1.3 互斥事件与独立事件1.1.4 概率的计算方法 1.2 条件概率与独立性1.2.1 条件概率1.2.2 独立事件 1.3 随机变量1.3.1 随机变…...

【论文笔记】Editing Models with Task Arithmetic
🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。 基本信息 标题: Editing Models with Task…...

ESP32外设学习部分--UART篇
前言 在我们学习嵌入式的过程中,uart算是我们用的非常多的一个外设了,我们可以用串口打印信息,也可以用于设备通信,总之串口的作用非常多,我们也非常有必要熟练地去掌握这个外设。 uart的配置 uart的参数配置 uart_…...

ssm-day04 mybatis
mybatis是一个持久层框架,针对的是JDBC的优化 简化数据库操作,能进行单表、多表操作,在这个框架下,需要我们自己写SQL语句 Mapper接口和MapperXML文件就相当于Dao和Dao层的实现 通常将xml文件放在resources包下 ,放在…...

es中段是怎么合并的
文章目录 1. 段合并的背景2. 合并的方式2.1TieredMergePolicy 的层次结构2.2 层次的基本规则2.3 如何理解层次(tier)2.4. 合并过程中的层次示例2.5. TieredMergePolicy 的优势2.6. 小结 3. 合并过程中的优化4. 合并的性能考虑5. 使用 API 手动合并6. 合并…...

5、可暂停的线程控制模型
一、需求 在做播放器的时候,很多的模块会创建一个线程,然后在这个线程上跑单独的功能,同时,需要对这个线程进行控制,比如暂停,继续等,如播放器的解码,解封装等,都需要对…...

sql优化--mysql隐式转换
sql隐式转换 在SQL中,隐式转换是数据库自动进行的类型转换,隐式转换可以帮助我们处理不同类型的数据。 比如,数据表的字段是字符串类型的,传入一个整型的数据,也能够运行sql。 sql隐式转换的弊端 sql隐式转换&…...

Scratch021(画笔)
画笔模块 可以这么理解,画笔模块是Scratch的拓展模块,用它可以完成很多的功能,非常有趣! 案例要求 点击绿旗运行程序,页面显示需要绘制的背景。 可以使用鼠标移动画笔角色,按照顺序点击连线,…...

Leetcode 3387. Maximize Amount After Two Days of Conversions
Leetcode 3387. Maximize Amount After Two Days of Conversions 1. 解题思路2. 代码实现 题目链接:3387. Maximize Amount After Two Days of Conversions 1. 解题思路 这一题思路上其实就是要分别求出day 1以及day 2中原始货币与其他各个货币之间的成交价&…...

机器视觉与OpenCV--01篇
计算机眼中的图像 像素 像素是图像的基本单位,每个像素存储着图像的颜色、亮度或者其他特征,一张图片就是由若干个像素组成的。 RGB 在计算机中,RGB三种颜色被称为RGB三通道,且每个通道的取值都是0到255之间。 计算机中图像的…...

简单的Java小项目
学生选课系统 在控制台输入输出信息: 在eclipse上面的超级简单文件结构: Main.java package experiment_4;import java.util.*; import java.io.*;public class Main {public static List<Course> courseList new ArrayList<>();publi…...

使用layui的table提示Could not parse as expression(踩坑记录)
踩坑记录 报错图如下 原因: 原来代码是下图这样 上下俩中括号都是连在一起的,可能导致解析问题 改成如下图这样 重新启动项目,运行正常!...

区块链共识机制详解
一.共识机制简介 在区块链的交流和学习中,「共识算法」是一个很频繁被提起的词汇,正是因为共识算法的存在,区块链的可信性才能被保证。 1.1 为什么需要共识机制? 所谓共识,就是多个人达成一致的意思。我们生活中充满…...
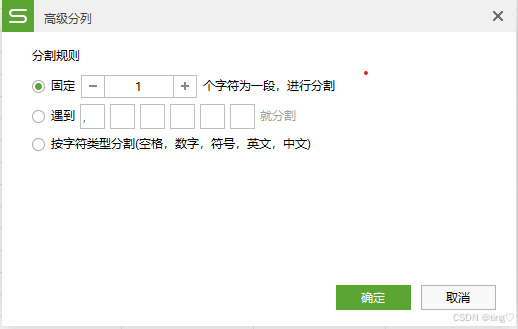
【Excel】单元格分列
目录 分列(新手友好) 1. 选中需要分列的单元格后,选择 【数据】选项卡下的【分列】功能。 2. 按照分列向导提示选择适合的分列方式。 3. 分好就是这个样子 智能分列(进阶) 高级分列 Tips: 新手推荐基…...

【含开题报告+文档+PPT+源码】基于微信小程序的旅游论坛系统的设计与实现
开题报告 近年来,随着互联网技术的迅猛发展,人们的生活方式、消费习惯以及信息交流方式都发生了深刻的变化。旅游业作为国民经济的重要组成部分,其信息化、网络化的发展趋势也日益明显。旅游论坛作为旅游信息交流和分享的重要平台࿰…...

微软 Phi-4:小型模型的推理能力大突破
在人工智能领域,语言模型的发展日新月异。微软作为行业的重要参与者,一直致力于推动语言模型技术的进步。近日,微软推出了最新的小型语言模型 Phi-4,这款模型以其卓越的复杂推理能力和在数学领域的出色表现,引起了广泛…...

操作系统课后习题2.2节
操作系统课后习题2.2节 第1题 CPU的效率指的是CPU的执行速度,这个是由CPU的设计和它的硬件来决定的,具体的调度算法是不能提高CPU的效率的; 第3题 互斥性: 指的是进程之间的同步互斥关系,进程是一个动态的过程&#…...
[小白系列]安装sentence-transformers
python环境为3.13.1执行 pip install sentence-transformers 总是报以下问题 ERROR: Cannot install sentence-transformers0.1.0, sentence-transformers0.2.0, sentence-transformers0.2.1, sentence-transformers0.2.2, sentence-transformers0.2.3, sentence-transformers…...

Python字符串format方法全面解析
在Python中,format方法是一种用于格式化字符串的强大工具。它允许你构建一个字符串,其中包含一些“占位符”,这些占位符将被format方法的参数替换。以下是对format方法用法的详细解释: 基本用法 format方法的基本语法如下&#…...

【Reading Notes】Favorite Articles from 2024
文章目录 1、January2、February3、March4、April5、May6、June7、July8、August9、September10、October11、November12、December 1、January 2、February 3、March Sora外部测试翻车了!3个视频都有Bug( 2024年03月01日) 不仔细看还真看不…...

CRM功能解析:覆盖客户、销售、数据、库存、工单全场景
在数字化转型浪潮中,企业对业务管理系统的需求已从单一CRM延伸至客户分层、销售自动化、数据分析、进销存、工单协同的全链路覆盖。不同系统在核心能力的实现逻辑与落地价值上差异显著,本文选取超兔一体云、Attio、Creatio、伙伴云CRM、OKKICRMÿ…...
)
逆向分析MIUI安全中心:我是如何找到‘USB安装确认’开关的(附配置文件详解)
逆向解析MIUI安全模块:从USB安装弹窗到配置开关的探索之旅 每次连接电脑安装应用时,那个突然弹出的确认窗口是否让你感到困扰?作为一名长期研究移动系统架构的开发者,我决定深入MIUI的安全中心模块,一探究竟。本文将完…...

从HC595到TM1637:一个STM32新手解决数码管闪烁的踩坑实录
从HC595到TM1637:一个STM32新手解决数码管闪烁的踩坑实录 数码管作为嵌入式开发中最基础的显示器件之一,其驱动方式的选择往往决定了整个系统的稳定性和用户体验。当我在一个温湿度监测项目中首次使用HC595驱动四位数码管时,完全没有预料到会…...

无人机避障新思路:拆解EGO-Planner如何用B样条和“斥力点”省掉ESDF
无人机避障新思路:拆解EGO-Planner如何用B样条和“斥力点”省掉ESDF 当四旋翼无人机在复杂环境中穿行时,传统的避障算法往往需要构建完整的欧几里得符号距离场(ESDF),这就像要求无人机在飞行前必须绘制整个城市的等高线…...

卡尔曼滤波在目标跟踪中的应用:原理、建模与工程调参实战
1. 项目概述:从“猜”到“算”的跟踪艺术在目标跟踪这个领域,无论是自动驾驶中预测前车的轨迹,还是无人机锁定移动的物体,亦或是视频监控里框住一个行走的人,我们核心要解决的都是一个问题:如何在充满噪声和…...

TLV320AIC3254音频编解码器:核心架构、配置实战与典型应用
1. 项目概述:从一颗“全能”音频芯片说起最近在做一个需要高保真音频采集和处理的嵌入式项目,选型时又一次把目光投向了TI的TLV320AIC3254。这颗芯片在音频工程师的圈子里名气不小,常被戏称为“音频界的瑞士军刀”。它本质上是一颗超低功耗的…...

避坑指南:交叉编译Paho MQTT C时OpenSSL配置的那些‘坑’
避坑指南:交叉编译Paho MQTT C时OpenSSL配置的那些‘坑’ 在嵌入式开发中,交叉编译是连接开发环境与目标平台的桥梁,而Paho MQTT C库作为轻量级MQTT客户端实现,常被用于资源受限设备。然而,当OpenSSL作为加密依赖加入编…...

利用Taotoken模型广场为不同任务选择合适大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同任务选择合适大模型 在实际开发工作中,我们常常面临多种任务需求:有时需要模型…...
)
ATmega328P烧录Bootloader报错?别急着换芯片,可能是签名搞的鬼(附avrdude.conf修改教程)
ATmega328P烧录Bootloader报错?别急着换芯片,可能是签名搞的鬼(附avrdude.conf修改教程) 当你兴致勃勃地准备给新买的ATmega328P芯片烧录Bootloader时,突然弹出一串红色报错信息,那种心情就像煮熟的鸭子飞走…...
)
别再只会用torchvision.models了!手把手教你从零理解ResNet18的PyTorch实现(附完整代码)
从零构建ResNet18:深入理解PyTorch实现与模型定制技巧 在深度学习领域,ResNet已经成为计算机视觉任务中不可或缺的基础架构。许多开发者习惯于直接调用torchvision.models.resnet18()这一行魔法代码,却对背后的实现细节知之甚少。本文将带你从…...