记录学习《手动学习深度学习》这本书的笔记(五)
这一章是循环神经网络,太难了太难了,有很多卡壳的地方理解了好久,比如隐藏层和隐状态的区别、代码的含义(为此专门另写了一篇【笔记】记录对自主实现一个神经网络的步骤的理解)、梯度计算相关(【笔记】记录对python中.grad()的一些理解)。
第八章:循环神经网络
8.1 序列模型
之前介绍了卷积神经网络,了解了怎么将空间结构融入模型,这一章的循环神经网络就是介绍如何将时间序列结构融入模型当中。
通常,在一个有序列结构的模型预测中,对于下一个时间步我们是按:来预测的。
但是这样的话,随着预测步数的推进,复杂度会上升得非常快,所以我们需要想出一些解决方法。
我们想出的方法(自回归模型)有两种:
- 一种叫自回归模型,是规定取预测步数之前的
个步数对当前预测步数进行预测,也就是说不需要从 t 步取回第 1 步了,只需要从t步取到第 t-
。
- 一种叫隐变量自回归模型,是我们后面会一直介绍的方法,将第 t 步之前步数的数据用一个隐状态
表示然后预测下一步 t+1 时只要将
进行线性变化组合得到
再用
这一章初步实现了一个简单的自回归模型,利用sin函数加一些随机误差生成数据,再利用自回归模型进行训练预测。
内插法是根据现有数据预测单个步的数据,预测数据来自现有数据。
外推法是根据现有数据不断推出后面的数据,每步根据前几步预测出来的数据对未来进行预测。
实验结果表明内推法难度更小,准确率也更高。而外推法得到的结果非常容易偏离正确值,因为预测的错误容易“累计”,不断预测非常容易偏离实际结果。
实验使用k步预测,由k步之前的数据预测第k步的数据,跨度为k,实验结果表明随着k的增加,错误会积累得越多,预测质量急剧下降。
8.2 文本预处理
我们选取《时光机器》中的文本数据。
提取文本步骤包括:
- 将文本作为字符串加载到内存中。
- 将字符串拆分为词元
- 建立词表将词元映射为数字索引
- 将文本转换为数字索引
第1步:
#@save
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt','090b5e7e70c295757f55df93cb0a180b9691891a')def read_time_machine(): #@save"""将时间机器数据集加载到文本行的列表中"""with open(d2l.download('time_machine'), 'r') as f:lines = f.readlines()return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]lines = read_time_machine()读取数据,将除了字母以外的字符转为空格(re.sub()正则匹配),去除首位空格(.strip()),将大写转为小写(.lower())
第2步:
将文本行继续拆分为单个词元。
def tokenize(lines, token='word'): #@save"""将文本行拆分为单词或字符词元"""if token == 'word':return [line.split() for line in lines]elif token == 'char':return [list(line) for line in lines]else:print('错误:未知词元类型:' + token)tokens = tokenize(lines)
for i in range(11):print(tokens[i])这个函数实现了拆分单词和拆分字母两种方式,默认拆分单词。
返回一些列表,每个列表代表一行,每一行有若干个单词(或字母)。
第3步:
这一步要将词元构成字典的形式,建立一个class类,需要实现将输入的词元匹配上一个对应的数字索引。
class Vocab: #@save"""文本词表"""def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):if tokens is None:tokens = []if reserved_tokens is None:reserved_tokens = []# 按出现频率排序counter = count_corpus(tokens)self._token_freqs = sorted(counter.items(), key=lambda x: x[1],reverse=True)# 未知词元的索引为0self.idx_to_token = ['<unk>'] + reserved_tokensself.token_to_idx = {token: idxfor idx, token in enumerate(self.idx_to_token)}for token, freq in self._token_freqs:if freq < min_freq:breakif token not in self.token_to_idx:self.idx_to_token.append(token)self.token_to_idx[token] = len(self.idx_to_token) - 1def __len__(self):return len(self.idx_to_token)def __getitem__(self, tokens):if not isinstance(tokens, (list, tuple)):return self.token_to_idx.get(tokens, self.unk)return [self.__getitem__(token) for token in tokens]def to_tokens(self, indices):if not isinstance(indices, (list, tuple)):return self.idx_to_token[indices]return [self.idx_to_token[index] for index in indices]@propertydef unk(self): # 未知词元的索引为0return 0@propertydef token_freqs(self):return self._token_freqsdef count_corpus(tokens): #@save"""统计词元的频率"""# 这里的tokens是1D列表或2D列表if len(tokens) == 0 or isinstance(tokens[0], list):# 将词元列表展平成一个列表tokens = [token for line in tokens for token in line]return collections.Counter(tokens)这个类大概是根据词元出现的频率排序,得出索引。
第4步:
执行:
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[:10])就可以得到:
[('<unk>', 0), ('the', 1), ('i', 2), ('and', 3), ('of', 4), ('a', 5), ('to', 6), ('was', 7), ('in', 8), ('that', 9)]
执行:
for i in [0, 10]:print('文本:', tokens[i])print('索引:', vocab[tokens[i]])就可以得到:
文本: ['the', 'time', 'machine', 'by', 'h', 'g', 'wells'] 索引: [1, 19, 50, 40, 2183, 2184, 400] 文本: ['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the'] 索引: [2186, 3, 25, 1044, 362, 113, 7, 1421, 3, 1045, 1]
整合以上功能:
def load_corpus_time_machine(max_tokens=-1): #@save"""返回时光机器数据集的词元索引列表和词表"""lines = read_time_machine()tokens = tokenize(lines, 'char')vocab = Vocab(tokens)# 因为时光机器数据集中的每个文本行不一定是一个句子或一个段落,# 所以将所有文本行展平到一个列表中corpus = [vocab[token] for line in tokens for token in line]if max_tokens > 0:corpus = corpus[:max_tokens]return corpus, vocabcorpus, vocab = load_corpus_time_machine()
len(corpus), len(vocab)加载数据,切分为字母,构造词典,整合成一个大列表,可选择是否取前max_tokens个字母。
8.3 语言模型和数据集
在构建模型之前,我们要了解一些关于自然语言处理的相关知识。
基本概率规则:比如 P(我想你) = P(你|我,想)P(想|我)P(我) ,为了得出一个句子的概率,我们需要知道单词出现的概率,以及单词在前几个单词出现的情况下出现的概率。
假设我们有一个非常大的语料库,对于上面式子的条件概率,我们可以通过 P(想|我) = P(我想) / P(我) 得到。
但是对于一些不常见的组合,语料库中出现的概率可能是零,于是就要利用拉普拉斯平滑,使所有语料库中没有出现过的组合概率不为零。
进行自然语言统计时,我们将之前的数据中频率最高的词汇打印出来,发现很多都是the、of、and之类的停用词,并且前几个出现的概率比后面的概率要高很多。

打印出图像可以看出词频从某个临界点开始就下降得特别快。
这意味着单词频率符合齐鲁夫定律。
如果采用之前的平滑方法,尾部数量就会大增。
我们再统计两个词汇组成的词组出现的频率、三个词汇组成的词组出现的频率:

可以看出都是这种情况。
说明拉普拉斯平滑并不适合语言建模,很多n元组很少出现,所以我们使用深度学习模型。
我们读取长序列数据,生成小批量数据作为特征,然后移动生成它的标签。
1.随机抽样:
def seq_data_iter_random(corpus, batch_size, num_steps): #@save"""使用随机抽样生成一个小批量子序列"""# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1corpus = corpus[random.randint(0, num_steps - 1):]# 减去1,是因为我们需要考虑标签num_subseqs = (len(corpus) - 1) // num_steps# 长度为num_steps的子序列的起始索引initial_indices = list(range(0, num_subseqs * num_steps, num_steps))# 在随机抽样的迭代过程中,# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻random.shuffle(initial_indices)def data(pos):# 返回从pos位置开始的长度为num_steps的序列return corpus[pos: pos + num_steps]num_batches = num_subseqs // batch_sizefor i in range(0, batch_size * num_batches, batch_size):# 在这里,initial_indices包含子序列的随机起始索引initial_indices_per_batch = initial_indices[i: i + batch_size]X = [data(j) for j in initial_indices_per_batch]Y = [data(j + 1) for j in initial_indices_per_batch]yield np.array(X), np.array(Y)my_seq = list(range(35))
for X, Y in seq_data_iter_random(my_seq, batch_size=2, num_steps=5):print('X: ', X, '\nY:', Y)生成特征和标签:
X: [[22. 23. 24. 25. 26.][27. 28. 29. 30. 31.]] Y: [[23. 24. 25. 26. 27.][28. 29. 30. 31. 32.]] X: [[ 7. 8. 9. 10. 11.][12. 13. 14. 15. 16.]] Y: [[ 8. 9. 10. 11. 12.][13. 14. 15. 16. 17.]] X: [[17. 18. 19. 20. 21.][ 2. 3. 4. 5. 6.]] Y: [[18. 19. 20. 21. 22.][ 3. 4. 5. 6. 7.]]
2.顺序分区:
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save"""使用顺序分区生成一个小批量子序列"""# 从随机偏移量开始划分序列offset = random.randint(0, num_steps)num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_sizeXs = np.array(corpus[offset: offset + num_tokens])Ys = np.array(corpus[offset + 1: offset + 1 + num_tokens])Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)num_batches = Xs.shape[1] // num_stepsfor i in range(0, num_steps * num_batches, num_steps):X = Xs[:, i: i + num_steps]Y = Ys[:, i: i + num_steps]yield X, Yfor X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):print('X: ', X, '\nY:', Y)生成特征和标签:
X: [[ 0. 1. 2. 3. 4.][17. 18. 19. 20. 21.]] Y: [[ 1. 2. 3. 4. 5.][18. 19. 20. 21. 22.]] X: [[ 5. 6. 7. 8. 9.][22. 23. 24. 25. 26.]] Y: [[ 6. 7. 8. 9. 10.][23. 24. 25. 26. 27.]] X: [[10. 11. 12. 13. 14.][27. 28. 29. 30. 31.]] Y: [[11. 12. 13. 14. 15.][28. 29. 30. 31. 32.]]
将两种方法打包:
class SeqDataLoader: #@save"""加载序列数据的迭代器"""def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):if use_random_iter:self.data_iter_fn = d2l.seq_data_iter_randomelse:self.data_iter_fn = d2l.seq_data_iter_sequentialself.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)self.batch_size, self.num_steps = batch_size, num_stepsdef __iter__(self):return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)def load_data_time_machine(batch_size, num_steps, #@saveuse_random_iter=False, max_tokens=10000):"""返回时光机器数据集的迭代器和词表"""data_iter = SeqDataLoader(batch_size, num_steps, use_random_iter, max_tokens)return data_iter, data_iter.vocab8.4 循环神经网络
循环神经网络将按照之前说的隐状态自回归模型,每一步根据上一步的状态h和当前读取数据进行预测。

隐状态H的作用是保留前面步的历史信息,相当于记忆一样。
这里书中提示了隐状态和隐藏层是不同的,想了老半天为什么,直到看到老师的ppt才懂:

其实两者指的是差不多的东西,只不过隐藏层是指那个层(箭头),而隐状态是指那个层输出的状态(h)。
没有隐状态就是普通神经网络,输入x输出y,中间的隐藏层不和前面的输入有关。
有隐状态就是隐藏层结合了前一个h,输出的是隐状态h,记录的前面的历史数据。
然后值得一提的是所有时间步是共享参数的,也就是的计算和
是类似的这使得循环神经网络的开销不会随着预测步数的增大而增大。
预测值y的计算如下:
隐状态h的计算如下:
循环神经网络对于每个批量(比如you ar)和它的标签(ou are),对每个小批量(一个或多个字母)执行上述计算操作,这样就可以推出下一个字母,如此反复。
由上述隐状态的公式可以看出,我们可以将上一个隐状态和这一个输入横向合并(物理),将权重W纵向合并(物理),两者相乘加b得到的也是同样结果。
最后来看评判模型好坏的困惑度,就是判断这个字母在这个位置出现的合理性(概率),可以用如下方法计算:
累乘会导致数字过大或者过小,于是将其取对数:
这就是困惑度。最好情况为1,最坏情况为正无穷大。
8.5 循环神经网络的从零开始实现
这一节单独放在【笔记】记录对自主实现一个神经网络的步骤的理解里了,只需再介绍一个独热编码的实现:
F.one_hot(torch.tensor([0, 2]), len(vocab))对0,1两个数字独热编码,长度为字母表长度。
运行结果是:
tensor([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0],[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0]])
如果传入的是数组,也可以给出对应独热编码,结果上升一个维度。
8.6 循环神经网络的简洁实现
这一章我们构建一个隐藏单元为256的单隐藏层循环神经网络。
像之前那样读取数据:
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)定义模型:
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)要注意的是,nn.RNN不是整个循环神经网络,而是只是隐藏层这部分,输出的是隐藏层的预测数据,我们还需要实现从隐状态到最后输出层的代码。
初始化隐状态:
state = torch.zeros((1, batch_size, num_hiddens))
state.shape由于nn.RNN只包含隐藏层,我们还需要建输出层,并将两个层合并成一个完整的循环神经网络:
#@save
class RNNModel(nn.Module):"""循环神经网络模型"""def __init__(self, rnn_layer, vocab_size, **kwargs):super(RNNModel, self).__init__(**kwargs)self.rnn = rnn_layerself.vocab_size = vocab_sizeself.num_hiddens = self.rnn.hidden_size# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1if not self.rnn.bidirectional:self.num_directions = 1self.linear = nn.Linear(self.num_hiddens, self.vocab_size)else:self.num_directions = 2self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)def forward(self, inputs, state):X = F.one_hot(inputs.T.long(), self.vocab_size)X = X.to(torch.float32)Y, state = self.rnn(X, state)# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)# 它的输出形状是(时间步数*批量大小,词表大小)。output = self.linear(Y.reshape((-1, Y.shape[-1])))return output, statedef begin_state(self, device, batch_size=1):if not isinstance(self.rnn, nn.LSTM):# nn.GRU以张量作为隐状态return torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens),device=device)else:# nn.LSTM以元组作为隐状态return (torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device),torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device))类接收一个隐藏层,词汇表大小作为参数,初始化传入参数,并且设置线性层作为由隐状态到输出的函数。
前向传播连接两个函数,先对输入进行独热编码,然后依次放入隐藏层和线性层中计算输出,输出为当前状态和当前输出。
begin_state函数初始化状态,每次新一轮预测就调用这个函数。
实现完整个模型,然后就可以将模型代入之前实现的预测和训练函数。
预测:
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
d2l.predict_ch8('time traveller', 10, net, vocab, device)训练:
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)8.7 通过时间反向传播
这一节分析了循环神经网络的梯度传播。

画出流程图可以看出,越后面的步需要回溯越多,这也是循环神经网络容易梯度爆炸和梯度消失的原因。
这一节主要是在用链式计算第t步的梯度公式。
相关文章:
记录学习《手动学习深度学习》这本书的笔记(五)
这一章是循环神经网络,太难了太难了,有很多卡壳的地方理解了好久,比如隐藏层和隐状态的区别、代码的含义(为此专门另写了一篇【笔记】记录对自主实现一个神经网络的步骤的理解)、梯度计算相关(【笔记】记录…...

【Qt】Qt+Visual Studio 2022环境开发
在使用Qt Creator的过程中,项目一大就会卡,所以我一般都是用VS开发Cmake开发, 在上一篇文章中,我已经安装了CMake,如果你没有安装就自己按一下。 记得配置Qt环境变量,不然CMake无法生成VS项目:…...

云计算HCIP-OpenStack04
书接上回: 云计算HCIP-OpenStack03-CSDN博客 12.Nova计算管理 Nova作为OpenStack的核心服务,最重要的功能就是提供对于计算资源的管理。 计算资源的管理就包含了已封装的资源和未封装的资源。已封装的资源就包含了虚拟机、容器。未封装的资源就是物理机提…...
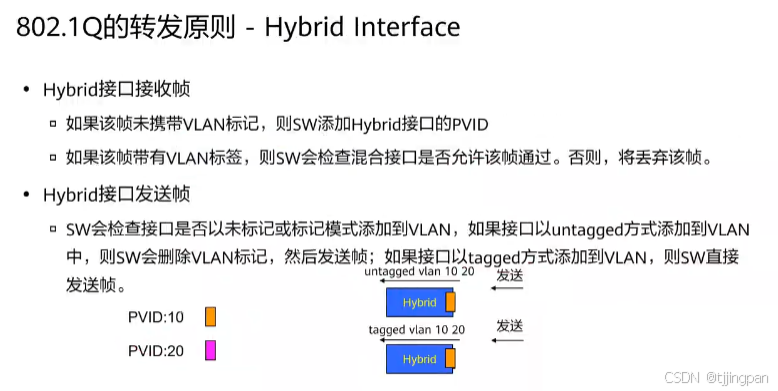
HCIA-Access V2.5_3_2_VLAN数据转发
802.1Q的转发原则--Access-Link 首先看一下Access,对于Access端口来说, 它只属于一个VLAN,它的VLANID等于PVID。 首先看一下接收方向,前面说过交换机内部一定要带标签转发,所以当交换机接收到一个不带tag的数据帧时,会给它打上端…...
transformer学习笔记-导航
本系列专栏,主要是对transformer的基本原理做简要笔记,目前也是主要针对个人比较感兴趣的部分,包括:神经网络基本原理、词嵌入embedding、自注意力机制、多头注意力、位置编码、RoPE旋转位置编码等部分。transformer涉及的知识体系…...

功能篇:JAVA后端实现跨域配置
在Java后端实现跨域配置(CORS,Cross-Origin Resource Sharing)有多种方法,具体取决于你使用的框架。如果你使用的是Spring Boot或Spring MVC,可以通过以下几种方式来配置CORS。 ### 方法一:全局配置 对于所…...

防火墙内局域网特殊的Nginx基于stream模块进行四层协议转发模块的监听443 端口并将所有接收转发到目标服务器
在一些特殊场合下, 公司内部网络防火墙限制, 不能做端口映射, 此时可以使用nginx的做从四层协议转发, 只走tcp/ip协议, 而不走http方式, 可以做waf设置, 就可以做443, 或其它端口, 从而达到被直接转发到远程服务器效果 机房只映射了一个IP:22280, 而需求是这个SDK只能通过…...
)
【Hive】-- hive 3.1.3 伪分布式部署(单节点)
1、环境准备 1.1、版本选择 apache hive 3.1.3 apache hadoop 3.1.0 oracle jdk 1.8 mysql 8.0.15 操作系统:Mac os 10.151.2、软件下载 https://archive.apache.org/dist/hive/ https://archive.apache.org/dist/hadoop/ 1.3、解压 tar -zxvf apache-hive-4.0.0-bin.tar…...

C++ STL 队列queue详细使用教程
序言 我们平常写广搜什么,上来就是一句 queue<XXX> qu; 说明队列时很重要的。 STL库中的queue把队列的各种操作封装成一个类,非常方便,信奥中使用它也是很有优势的。 目录 一、队列的定义 二、创建队列对象 三、队列的初始化 四、常…...

【前端】JavaScript 中的 filter() 方法的理论与实践深度解析
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: 前端 文章目录 💯前言💯filter() 方法的概念与原理1. 什么是 filter()?2. 基本工作原理3. 方法特点4. 用法格式参数解析 💯代码案例详解示例:筛选有效数字并…...

【机器学习算法】——决策树之集成学习:Bagging、Adaboost、Xgboost、RandomForest、XGBoost
集成学习 **集成学习(Ensemble learning)**是机器学习中近年来的一大热门领域。其中的集成方法是用多种学习方法的组合来获取比原方法更优的结果。 使用于组合的算法是弱学习算法,即分类正确率仅比随机猜测略高的学习算法,但是组合之后的效果仍可能高于…...

JVM运行时数据区内部结构
VM内部结构 对于jvm来说他的内部结构主要分成三个部分,分别是类加载阶段,运行时数据区,以及垃圾回收区域,类加载我们放到之后来总结,今天先复习一下类运行区域 首先这个区域主要是分成如下几个部分 下面举个例子来解释…...

Navicat for MySQL 查主键、表字段类型、索引
针对Navicat 版本11 ,不同版本查询方式可能不同 1、主键查询 (重点找DDL!!!) 方法(1) :右键 - 对象信息 - 选择要查的表 - DDL - PRIMARY KEY 方法(2&…...
如何在谷歌浏览器中实现自定义主题
在数字化时代,个性化设置已成为提升用户体验的重要一环。对于广泛使用的谷歌浏览器而言,改变默认的浏览器主题不仅能够美化界面,还能在一定程度上提升使用效率和愉悦感。本文将详细介绍如何在谷歌浏览器中实现自定义主题,包括从官…...

visual studio 2022 c++使用教程
介绍 c开发windows一般都是visual studio,linux一般是vscode,但vscode调试c不方便,所以很多情况都是2套代码,在windows上用vs开发方便,在转到linux。 安装 1、官网下载vs2022企业版–选择桌面开发–安装位置–安装–…...

曝光三要素
一光圈 光圈越大,数值越小,画面越亮,背景越模糊 光圈越小,数值越大,画面越暗,背景越清晰 二 快门 快门最主要的作用是控制曝光时间的长短 快门速度的单位是秒,一般用 1秒,1/8秒&am…...

01-2 :PyCharm安装配置教程(图文结合-超详细)
一、PyCharm安装 PyCharm集成开发工具(IDE),是当下全球Python开发者,使用最频繁的工具软件。 绝大多数的Python程序,都是在PyCharm工具内完成的开发。 本篇文章基于PyCharm软件工具进行描述,教你如何安装…...

类OCSP靶场-Kioptrix系列-Kioptrix Level 1
一、前情提要 二、实战打靶 1. 信息收集 1.1. 主机发现 1.2. 端口扫描 1.3 目录爆破 1.4. 敏感信息 2.根据服务搜索漏洞 2.1. 搜索exp 2.2. 编译exp 2.3. 查看exp使用方法,并利用 3. 提权 二、第二种方法 一、前情提要 Kioptrix Level是免费靶场&#x…...

Maven插件打包发布远程Docker镜像
dockerfile-maven-plugin插件的介绍 dockerfile-maven-plugin目前这款插件非常成熟,它集成了Maven和Docker,该插件的官方文档地址如下: 地址:https://github.com/spotify/dockerfile-maven 其他说明: dockerfile是用…...

VisualStudio vsix插件自动加载
本文介绍如何在Visual Studio扩展中实现PackageRegistration,包括设置UseManagedResourcesOnly为true,允许背景加载,并针对C#、VB、F#项目提供自动装载,附官方文档链接。增加以下特性即可…… [PackageRegistration(UseManagedRe…...

当A*算法遇上真实山地DEM:一份给无人机/机器人路径规划者的Python避坑指南
当A*算法遇上真实山地DEM:无人机路径规划的Python实战与优化 山地路径规划的独特挑战 在无人机和机器人导航领域,山地地形带来了传统路径规划算法难以应对的复杂性。与平坦城市环境不同,山地DEM(数字高程模型)数据包含…...

从‘盲猜’到‘先知’:深度解读神经RRT*如何让采样规划拥有‘大局观’
神经RRT*:当路径规划算法学会"思考"的范式革命 在自动驾驶汽车寻找最短路径、无人机规划避障航线的场景中,传统RRT算法就像一位盲人摸象的探险者——它通过随机撒点的方式探索环境,虽然最终能找到出路,却需要耗费大量时…...
4种颠覆性组合:重构Pixelle-Video的模块化潜能
4种颠覆性组合:重构Pixelle-Video的模块化潜能 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 想象一下:输入&qu…...

别再死记命令了!用ENSP模拟企业网,手把手教你配置VRRP+MSTP实现网关和链路双备份
企业网络高可用实战:用ENSP构建VRRPMSTP双冗余架构 刚接触企业网络设计的工程师常陷入一个误区:把网络设备配置等同于命令记忆。我曾见过一位学员能完整背诵VRRP的配置指令,却在真实网络故障时手足无措——因为他从未理解这些命令背后的网络逻…...

用Python实战脑电分析:手把手教你计算PLV、MVL、MI跨频耦合指标
Python脑电分析实战:PLV、MVL、MI跨频耦合指标全流程解析 神经振荡的跨频耦合(Cross-Frequency Coupling, CFC)分析正在成为探索大脑信息处理机制的重要工具。想象一下,当你面对一组EEG数据时,如何从复杂的波形中提取出…...

Taotoken 助力企业构建内部 AI 助手统一管理平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 助力企业构建内部 AI 助手统一管理平台 当企业内部开始涌现多个 AI 应用时,例如为研发团队配备的代码助手和为…...

如何编制ERP系统的物料编码?一文读懂底层逻辑
在数字化管理时代,企业上ERP系统已成为标配。但很多人会遇到一个共同的难题:物料编码到底该怎么编?编不好,ERP系统就成了“数据垃圾场”;编得好,则能让库存周转率提升30%以上。今天,我们就来深度…...

独立开发者如何借助 Taotoken 以更低成本试验不同大模型效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助 Taotoken 以更低成本试验不同大模型效果 对于独立开发者或小微创业团队而言,在产品原型或功能验证…...

别再死记硬背了!用Python写个语法分析器,帮你彻底搞懂英语非谓语动词
用Python构建英语非谓语动词分析器:从语法规则到代码逻辑 引言:当编程遇上英语语法 英语学习中最令人头疼的部分莫过于非谓语动词——那些不做谓语的动词形式,包括不定式、分词和动名词。传统学习方法要求死记硬背各种规则和例外,…...

LeetCode 前K个高频元素题解
LeetCode 前K个高频元素题解 题目描述 给定一个数组,找到前 k 个高频元素。 示例: 输入:nums [1,1,1,2,2,3], k 2输出:[1,2] 解题思路 方法:堆 思路: 使用哈希表统计每个元素出现的次数。使用最小堆维护前…...