爬虫基础学习
- 爬虫概念与工作原理
爬虫是什么:爬虫(Web Scraping)是自动化地访问网站并提取数据的技术。它模拟用户浏览器的行为,通过HTTP请求访问网页,解析HTML文档并提取有用信息。
爬虫的基本工作流程:
发送HTTP请求
获取响应数据(HTML、JSON等)
解析网页内容
提取和存储数据
处理反爬虫机制(如验证码、IP封锁等)
- Python爬虫基础
requests库:requests是一个Python库,用于发送HTTP请求并获取响应数据。
解析HTML内容:
学习如何使用BeautifulSoup库来解析HTML网页。
提取网页中的特定元素(如标题、链接、图片等)。
-
HTML、CSS、JS和DOM基础
HTML:了解HTML的基本结构,标签(如、 、)和属性(如href、src)。
CSS:了解如何使用CSS选择器定位页面元素。
JS和DOM:理解动态网页的加载方式及其与爬虫的关系。有些网页内容是由JavaScript动态渲染的,爬虫需要处理这些动态内容。 -
正则表达式:
学习如何使用正则表达式(re模块)来提取网页中的特定数据,例如价格、日期等。 -
爬虫调试与反爬虫技术
调试工具:学会使用浏览器的开发者工具(F12)来检查网页的网络请求、HTML结构、加载过程等。
User-Agent:模拟浏览器的User-Agent,避免被网站识别为爬虫。
IP封锁与代理:如果你遇到IP封禁问题,可以学习如何使用代理IP来绕过限制
import requests
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager#from webdriver_manager.chrome import ChromeDriverManager# # 设置请求头,模拟浏览器访问,避免被反爬虫机制拦截
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
# }# # 发送GET请求获取页面
# url = 'https://www.amazon.com/gp/new-releases/?ref_=nav_cs_newreleases'
# response = requests.get(url, headers=headers)# # 检查响应状态码
# if response.status_code == 200:
# # 不直接打印全部响应内容,而是打印前100个字符
# # print("响应内容预览:", response.text[:100])
# # print("页面加载成功!")
# # print(f"状态码:{response.status_code}")# with open('response.txt', 'w', encoding='utf-8') as f:
# f.write(response.text)
# print("页面加载成功!")
# print(f"状态码:{response.status_code}")
# print("响应内容已保存到 response.txt 文件中")
# else:
# print(f"请求失败,状态码:{response.status_code}")# # 获取网页内容
# soup = BeautifulSoup(response.text, 'html.parser')# # 解析页面中的新发布产品,假设产品名称和价格在特定的HTML元素中
# # 这里只是一个简单的示例,实际可能需要根据页面的结构调整选择器# 使用Selenium打开网页
# service = Service(executable_path='E:\\adfg\\chromedriver.exe')
# driver = webdriver.Chrome(service=service)# 使用 webdriver_manager 自动安装匹配的 ChromeDriver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)# driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# 获取页面源码
driver.get('https://www.amazon.com/gp/new-releases/?ref_=nav_cs_newreleases')
time.sleep(10)
page_source = driver.page_sourcesoup = BeautifulSoup(page_source, 'html.parser')# #纯文本
# soup_text = soup.get_text()
# print(soup_text)# 获取HTML原始文本
soup_text = str(soup)
#print(soup_text)with open('soup.txt', 'w', encoding='utf-8') as a:a.write(soup_text)# 关闭浏览器
driver.quit()# 提取产品名称作为示例
product_titles = soup.find_all('div', class_="p13n-sc-truncate-desktop-type2 p13n-sc-truncated")# 遍历所有找到的元素
# print(product_titles)
# for product_title in product_titles:
# product_title = product_title.get_text(strip=True) # 获取文本并去除空白 get_text获取的标题有可能被截断
# print(product_title)for product_title in product_titles:# 尝试获取完整的title属性full_title = product_title.get('title') or product_title.get_text(strip=True)print(full_title)# 获取产品价格
product_prices = soup.find_all('span', class_='_cDEzb_p13n-sc-price_3mJ9Z') # 根据网页结构查找价格
#print("\n产品价格:")
for idx, price in enumerate(product_prices[:10]): # 获取前10个价格print(f"{idx + 1}. Price: {price.get_text()}")- 请求失败或获取不到数据
问题:尝试获取网页内容时,获取到的页面内容为空或页面结构未更新。
解决方案:
确认请求状态码(如 200)以确保请求成功。
使用开发者工具(F12)检查请求和响应,确保正确获取目标数据。
如果是动态页面,使用 Selenium 或 Playwright 等工具模拟浏览器行为来获取渲染后的内容。 - 动态加载的内容
问题:页面内容由 JavaScript 渲染,requests 和 BeautifulSoup 无法正确获取到这些内容。
解决方案:
使用 Selenium 等浏览器自动化工具,等待 JavaScript 执行完成,获取渲染后的完整 HTML。
通过查看开发者工具中的 Network 选项卡,找到 AJAX 请求的 API 接口,直接请求返回的 JSON 数据。 - 反爬虫机制
问题:网站通过检测 User-Agent、限制请求频率、验证码等方式阻止爬虫抓取。
解决方案:
User-Agent 伪装:通过设置不同的 User-Agent 来模拟浏览器行为,避免被识别为爬虫。
IP 代理池:使用代理池轮换 IP,避免因频繁请求同一 IP 被封禁。
验证码处理:利用 OCR 技术(如 Tesseract)或第三方验证码识别服务(如 2Captcha)来绕过验证码。
相关文章:

爬虫基础学习
爬虫概念与工作原理 爬虫是什么:爬虫(Web Scraping)是自动化地访问网站并提取数据的技术。它模拟用户浏览器的行为,通过HTTP请求访问网页,解析HTML文档并提取有用信息。 爬虫的基本工作流程: 发送HTTP请求…...

C++对象数组对象指针对象指针数组
一、对象数组 对象数组中的每一个元素都是同类的对象; 例1 对象数组成员的初始化 #include<iostream> using namespace std;class Student { public:Student( ){ };Student(int n,string nam,char s):num(n),name(nam),sex(s){};void display(){cout<&l…...

D96【python 接口自动化学习】- pytest进阶之fixture用法
day96 pytest的fixture详解(三) 学习日期:20241211 学习目标:pytest基础用法 -- pytest的fixture详解(三) 学习笔记: fixture(scop"class") (scop"class") 每一个类调…...

【算法】动态规划中01背包问题解析
📢博客主页:https://blog.csdn.net/2301_779549673 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! 📢本文由 JohnKi 原创,首发于 CSDN🙉 📢未来很长&#…...

选择WordPress和Shopify:搭建对谷歌SEO友好的网站
在建设网站时,不仅要考虑它的美观和功能性,还要关注它是否对谷歌SEO友好。如果你希望网站能够获得更好的搜索排名,WordPress和Shopify是两个值得推荐的建站平台。 WordPress作为最流行的内容管理系统,其强大的灵活性和丰富的插件…...

代理IP与生成式AI:携手共创未来
目录 代理IP:网络世界的“隐形斗篷” 1. 隐藏真实IP,保护隐私 2. 突破网络限制,访问更多资源 生成式AI:创意与效率的“超级大脑” 1. 提高创作效率 2. 个性化定制 代理IP与生成式AI的协同作用 1. 网络安全 2. 内容创作与…...

iOS 应用的生命周期
Managing your app’s life cycle | Apple Developer Documentation Performance and metrics | Apple Developer Documentation iOS 应用的生命周期状态是理解应用如何在不同状态下运行和管理资源的基础。在 iOS 开发中,应用生命周期管理的是应用从启动到终止的整…...

Elasticsearch 集群快照的定期备份设置指南
Elasticsearch 集群快照的定期备份设置指南 概述 快照: 在给定时刻对整个集群或者单个索引进行备份,以便在之后出现故障时可以基于之前备份的快照进行快速恢复。 前提条件: 准备一个备份存储盘,本指南采用的是AWS EFS文件系统做…...

Docker--Docker Image(镜像)
什么是Docker Image? Docker镜像(Docker Image)是Docker容器技术的核心组件之一,它包含了运行应用程序所需的所有依赖、库、代码、运行时环境以及配置文件等。 简单来说,Docker镜像是一个轻量级、可执行的软件包&…...

C++ 中的序列化和反序列化
一、C 中的序列化和反序列化 (一)基本概念 在 C 中,序列化是将对象转换为字节流的过程,反序列化则是从字节流重新构建对象的过程。这对于存储对象状态到文件、网络传输等场景非常有用。 (二)简单的序列化…...

我的Github学生认证申请过程
先说结论:很简单。 学生认证链接:GitHub Education GitHub 1. 首先你得绑定edu邮箱。这个应该没什么问题,Github也会提示。 2. 我是在学校里面、使用流量而非WiFi申请的,听说地理位置很重要,该给的权限(…...

信奥题解:勾股数计算中的浮点数精度问题
来源:GESP C++ 二级模拟题 本文给出官方参考答案的详细解析,包括每一部分的功能和关键点,以及与浮点数精度相关的问题的分析。 题目描述 勾股数是很有趣的数学概念。如果三个正整数a 、b 、c ,满足 a 2 + b 2 = c 2 a^2 + b^2 = c^2 a2+b2=c2 ,而且1 ≤ a ≤ b ≤ c ,…...

重生之我在学Vue--第2天 Vue 3 Composition API 与响应式系统
重生之我在学Vue–第2天 Vue 3 Composition API 与响应式系统 文章目录 重生之我在学Vue--第2天 Vue 3 Composition API 与响应式系统前言一、Composition API 核心概念1.1 什么是 Composition API?1.2 Composition API 的核心工具1.3 基础用法示例 二、响应式系统2…...

【AI知识】逻辑回归介绍+ 做二分类任务的实例(代码可视化)
1. 分类的基本概念 在机器学习的有监督学习中,分类一种常见任务,它的目标是将输入数据分类到预定的类别中。具体来说: 分类任务的常见应用: 垃圾邮件分类:判断一封电子邮件是否是垃圾邮件 。 医学诊断:…...

Mysql 笔记2 emp dept HRs
-- 注意事项 -- 1.给数据库和表起名字时尽量选择全小写 -- 2.作为筛选条件的字符串是否区分大小写看设置的校对规则utf8_bin 区分 drop database if exists hrs; create database hrs default charset utf8 collate utf8_general_ci;use hrs; drop table if exists tb_emp; dro…...

MySQL和Oracle的区别
MySQL和Oracle的区别 MySQL是轻量型数据库,并且免费,没有服务恢复数据。 Oracle是重量型数据库,收费,Oracle公司对Oracle数据库有任何服务。 1.对事务的提交 MySQL默认是自动提交,而Oracle默认不自动提交࿰…...

实验12 C语言连接和操作MySQL数据库
一、安装MySQL 1、使用包管理器安装MySQL sudo apt update sudo apt install mysql-server2、启动MySQL服务: sudo systemctl start mysql3、检查MySQL服务状态: sudo systemctl status mysql二、安装MySQL开发库 sudo apt-get install libmysqlcli…...

09篇--图片的水印添加(掩膜的运用)
如何添加水印? 添加水印其实可以理解为将一张图片中的某个物体或者图案提取出来,然后叠加到另一张图片上。具体的操作思想是通过将原始图片转换成灰度图,并进行二值化处理,去除背景部分,得到一个类似掩膜的图像。然后…...

sql-labs(21-25)
第21关 第一步 可以发现cookie是经过64位加密的 我们试试在这里注入 选择给他编码 发现可以成功注入 爆出表名 爆出字段 爆出数据 第22关 跟二十一关一模一样 闭合换成" 第 23 关 第二十三关重新回到get请求,会发现输入单引号报错,但是注释符…...
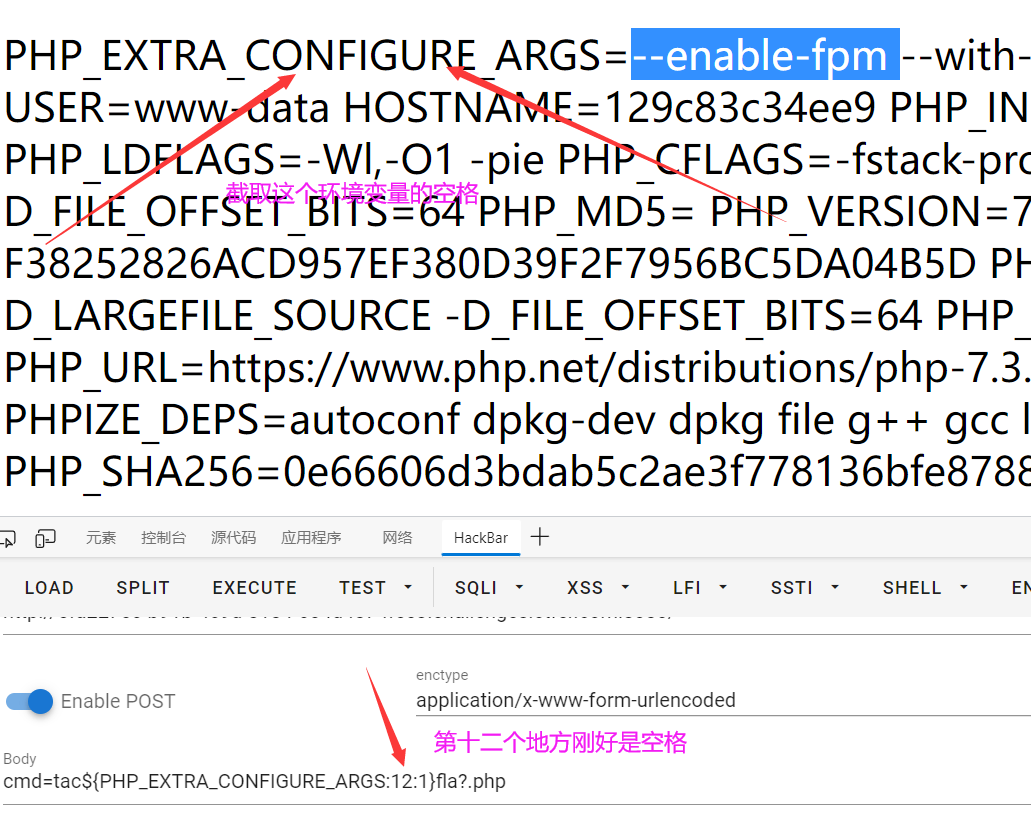
CTF知识集-命令执行
CTF知识集-命令执行 写在开头可能会用到的提醒 ;可以用%0a来替换 是shell_exec的缩写 ls | tee 1 把ls的输出内容存入1这个文件 shell查看文件的几种方式,tac | more | less | tail | sort | tac | cat | head | od | expand 针对flag 可以用grep { flag.php来…...

教育资源解析工具:打通国家中小学智慧教育平台电子课本获取通道
教育资源解析工具:打通国家中小学智慧教育平台电子课本获取通道 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容。 …...

语言的边界,与软件的命运
. GIF文件结构 相比于 WAV 文件的简单粗暴,GIF 的结构要精密得多,因为它天生是为了网络传输而设计的(包含了压缩机制)。 当我们用二进制视角观察 GIF 时,它是由一个个 数据块(Block) 组成的&…...
)
GRACE/GRACE-FO数据下载全攻略:从零开始搞定三大机构数据源(含最新FTP地址)
GRACE/GRACE-FO数据获取与处理全流程指南:2024年三大机构最新数据源解析 对于刚接触地球物理学和气候研究领域的研究人员来说,获取和处理GRACE/GRACE-FO卫星数据往往面临诸多挑战。本文将系统介绍2024年三大主流数据机构(JPL、GFZ、CSR&…...
)
FRP内网穿透实战:5分钟搞定Linux服务器+Docker部署(含HTTPS配置)
FRP内网穿透实战:Linux服务器与Docker部署全指南 引言 在当今分布式开发和远程办公的浪潮中,内网穿透技术已成为开发者工具箱中不可或缺的一部分。想象一下这样的场景:你正在本地开发一个Web应用,需要让远方的同事实时预览效果&am…...

Beyond Compare 5 本地密钥生成实用方案:告别试用限制的完整指南
Beyond Compare 5 本地密钥生成实用方案:告别试用限制的完整指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen Beyond Compare 5 作为一款专业的文件对比工具,在试用期…...

华为OD生存指南:转正挑战、身份认知与职业适配
1. 华为OD转正挑战的真相 刚入职华为OD时,很多人都会被HR描述的转正路径所吸引。四步转正流程听起来清晰明了:有HC、拿绩效A、通过可信认证、工作满一年。但真正进入这个体系后,你会发现每个环节都暗藏玄机。 关于HC(Head Count…...

智能排障:快马ai助手实时解答openclaw安装难题,告别卡壳
最近在折腾OpenClaw这个工具时,发现它的安装过程真是让人头大——各种依赖报错、环境冲突、权限问题接踵而至。好在发现了InsCode(快马)平台的AI辅助功能,简直像给安装过程装上了智能导航。下面分享我的实战经验,如何用AI快速攻克OpenClaw安装…...

3步解锁跨设备游戏自由:Sunshine串流技术重构娱乐体验
3步解锁跨设备游戏自由:Sunshine串流技术重构娱乐体验 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 在这个设备爆炸的时代,我们却被硬件束缚得越来越紧。…...

Qwen3-0.6B-FP8详细步骤:WebUI中max_new_tokens参数设置避坑指南
Qwen3-0.6B-FP8详细步骤:WebUI中max_new_tokens参数设置避坑指南 1. 引言:一个参数引发的“血案” 最近在折腾Qwen3-0.6B-FP8这个轻量级模型时,我遇到了一个挺有意思的问题。当时我正在测试它的“思考模式”——就是那个能展示模型内部推理…...

解锁Unity游戏定制潜能:MelonLoader全方位应用指南
解锁Unity游戏定制潜能:MelonLoader全方位应用指南 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader 副标题ÿ…...