es 3期 第15节-词项查询与跨度查询实战运用
#### 1.Elasticsearch是数据库,不是普通的Java应用程序,传统数据库需要的硬件资源同样需要,提升性能最有效的就是升级硬件。
#### 2.Elasticsearch是文档型数据库,不是关系型数据库,不具备严格的ACID事务特性,任何企图直接替代严格事务性场景的应用项目都会失败!!!
##### 索引字段与属性都属于静态设置,若后期变更历史数据需要重建索引才可生效
##### 对历史数据无效!!!!
##### 一定要重建索引!!!!
#### 全文文本概念
### 概念介绍
## 1.文章语句分词
## 2.分词之后,支持基于分词检索
## 3.分词算法很多,分词领域很深入
## 4.基于倒排索引算法-Inverted-Index
## 5.分词检索的打分算法TF/IDF=>BM25
## 6.字段类型仅限于text类型
### Term 精确词项概念
# Term词项概念整个语句文字分为一个词
# 1.主要是keyword类型,其余非text字段部分可用2.数据内容有长度限制(2的16次方字节)
## 词项精确查询介绍
# l.Term
# 2.Terms
# 3.Terms Lookup
# 4.Terms set
## 是否需要分值计算
# query:分值计算
# filter:无需分值计算
# 准备数据DELETE kibana_sample_data_flights_term
POST _reindex
{"source": {"index": "kibana_sample_data_flights"},"dest": {"index": "kibana_sample_data_flights_term"}
}# 查不出来,因为Dest是text类型
GET kibana_sample_data_flights_term/_search
# 查不出来,因为Dest是text类型
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query":{"bool": {"must": [{"term": {"Dest": {"value": "Venice Marco Polo Airport"}}}]}}
}# 使用Dest.keyword查出来,既然是精确查询也可以不必用must,使用filter
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query":{"bool": {"filter": [{"term": {"Dest.keyword": {"value": "Venice Marco Polo Airport"}}}]}}
}# 去掉一个Airport就查询不出来,注意区分一整个词和分词的区别
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query":{"bool": {"filter": [{"term": {"Dest.keyword": {"value": "Venice Marco Polo"}}}]}}
}# Airport 改为小写的 airport 查询不出来,使用keywod时候es不会做任何处理
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query":{"bool": {"filter": [{"term": {"Dest.keyword": {"value": "Venice Marco Polo airport"}}}]}}
}# 使用term检索数值类型,原则上非text类型都能用term检索
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query":{"bool": {"filter": [{"term": {"FlightDelayMin": {"value": 30}}}]}}
}# 使用range效率没有term高,es对数值类型有两套存储检索方式
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query":{"bool": {"filter": [{"range": {"FlightDelayMin": {"gte": 20,"lte": 36}}}]}}
}# case_insensitive, ASCII 是否区分大小写,取值范围true/false,默认false,7.10.0版本之后增加
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query":{"bool": {"filter": [{"term": {"OriginCityName.keyword": {"value": "warsaw","case_insensitive": true}}}]}}
}### terms查询
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query": {"bool": {"filter": [{"terms": {"OriginCityName.keyword": ["Zurich","Warsaw"]}}]}}
} ## terms lookup查询
# 基于指定某条数据的词项作为输入值,生成词项查询条件
# 等同于应用中反向查询某个索引数据,作为输入源
# 非常适用于比较同类型数据,避免应用中二次查询
## 查询参数
# terms,查询关键字入口,查询表达式入口
# index,指定输入源索引
# id,指定输入源 数据 id
# path,指定输入源字段路径,特别要注意对象类型数据,以及层次
# routing,可指定输入源数据的路由标签
GET kibana_sample_data_ecommerce/_search
GET kibana_sample_data_ecommerce/_search
{"track_total_hits": true,"query": {"terms": {"sku": {"index": "kibana_sample_data_ecommerce","id": "9oTR0Y8BbWz2Sn6Eg4wZ","path": "sku","routing":"9oTR0Y8BbWz2Sn6Eg4wZ"}}}
} ## terms_set
# terms_set 也是多个输入值查询,类似与 terms查询,在属性条件上有更多的选择。
# 期望查询的字段的词数量与内容完全符合,而不是只命中其中一个,提供了一种字段数据与字段数据长度自主比较的能力。
## 查询参数
# terms_set,关键字,查询表达式
# terms,关键字,输入查询内容的词数组
# minimum should match field,关键字,指定一个数值类字段,要求输入的搜索内容必须与此值相等
# minimum should match script,关键字,通过脚本计算获取一个字段的长度数值
# boost,关键字,分值加权
GET kibana_sample_data_ecommerce/_search
# 重新准备新数据,使用脚本增加一个manufacturer_count字段,数据来源是manufacturer的长度
POST _reindex
{"source": {"index": "kibana_sample_data_ecommerce"},"dest": {"index": "kibana_sample_data_ecommerce_term"},"script": {"source": """ctx._source.manufacturer_count = ctx._source.manufacturer.length;"""}
}# terms 查询匹配数量与manufacturer_count一致的数据
GET kibana_sample_data_ecommerce_term/_mappings
GET kibana_sample_data_ecommerce_term/_search
# terms 查询匹配数量与manufacturer_count一致的数据
GET kibana_sample_data_ecommerce_term/_search
{"track_total_hits": true,"query": {"terms_set": {"manufacturer.keyword": {"terms": ["Elitelligence","Oceanavigations","Champion Arts","Pyramidustries"],"minimum_should_match_field": "manufacturer_count"}}}
}# terms 查询匹配数量与脚本返回一致的数据
GET kibana_sample_data_ecommerce_term/_search
{"track_total_hits": true,"query": {"terms_set": {"manufacturer.keyword": {"terms": ["Elitelligence","Oceanavigations","Champion Arts","Pyramidustries"],"minimum_should_match_script": {"source":"""doc['manufacturer.keyword'].length;"""}}}}
} ## Fuzzy 容错查询,非高效率查询
# 有很多应用场景,我们对于输入的内容并无严格的校验,导致入库的内容有错别字,此时需要一定的纠错查询,ES 针对此需求,设计了糊纠错查询。
# fuzzy 查询是一种非常消耗 CPU 资源的查询方式,主要要海量的计算,应该尽量避免或者缩短差值
## 查询参数
# fuzzy,关键字,查询表达式
# value,关键字,查询输入的内容单词,本质应该输入一个错误的词项
# fuzziness,关键字,容错的字符数量,建议设置为严格的数字,取值范围数字或者“AUTO”
# max_expansions,关键字,计算的容错词项数量,默认50,尽量控制这个数量!! 组,建议设置更低,性能影响巨大
# prefix_length,关键字,控制容错词的起始位置,从左开始,设置的值应该小于 value 的字符长度,建议设置的更加精确,性能更好
# transpositions,关键字,控制字符前后位置对调来纠错查询,取值范围 true/false,默认 true
# boost,关键字,分值加权
# rewrite,重写查询表达式,此值目前不过渡深入,属于资深人员学习掌握
GET kibana_sample_data_flights_term/_search
# 查询 Washington, 故意把最后一个字母写错Washingtom,可以查出来
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query": {"bool": {"must": [{"fuzzy": {"DestCityName.keyword": {"value": "Washingtom"}}}]}}
}# 查询 错误的 Washington, Washingtomm 并设置fuzziness数量为1查不出来,改为2就可以查出来了
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query": {"bool": {"must": [{"fuzzy": {"DestCityName.keyword": {"value": "Washingtomm","fuzziness":1}}}]}}
}## prefix 前缀查询,类说mysql 的like语句
# 基于词项的前缀内容自动匹配后面的内容,只要符合就全部查询出来
## 查询参数
# prefix,关键字,查询表达式
# value,关键字,输入的前缀字符内容
# rewrite,重写参数
# case_insensitive,大小写敏感
# 查询Washington的前缀
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query": {"bool": {"must": [{"prefix": {"DestCityName.keyword": {"value": "Washing"}}}]}}
}## wildcard,通配符查询,基于通配符"*"模糊查询
# ES7.9版本推出了 wildcard 字段类型,基于 ngram 算法,检索效率相比"*"的查询要高
## 查询参数
# wildcard,关键字,查询表达式
# value,关键字,查询输入内容,内容可以采用通配符方式
# boosts,关键字,分值加权
# rewrite,重写表达式
# case_insensitive,大小写敏感
# 在这个索引中DestCityName是text类型,使用通配时要定义成wildcard类型最好
GET kibana_sample_data_flights_term/_mappings
# 通配查询Washington
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query": {"wildcard": {"DestCityName.keyword": {"value": "*ashington"}}}
} ## exist 逻辑查询
# ES 字段是可以动态扩展的,常规下无任何限制,导致在数据查询时,会造成部分数据字段缺失,从而查询错误,此判断可以有效过滤筛选此类数据
GET kibana_sample_data_ecommerce,kibana_sample_data_ecommerce_term/_search
{"track_total_hits":true,"query":{"exists": {"field": "manufacturer_count"}}
}## ids查询,本质上等同于MGET
GET kibana_sample_data_ecommerce_term/_doc/9oTR0Y8BbWz2Sn6Eg4wZ
GET kibana_sample_data_ecommerce_term/_search
{"query":{"ids": {"values": ["9oTR0Y8BbWz2Sn6Eg4wZ","94TR0Y8BbWz2Sn6Eg4wZ"]}}
}
// 有限制字符串长度,默认512字节
GET kibana_sample_data_ecommerce_term/_search
{"query":{"terms": {"_id": ["9oTR0Y8BbWz2Sn6Eg4wZ","94TR0Y8BbWz2Sn6Eg4wZ"]}}
}## range 数值范围查询
# 查询参数
# range,关键字,查询表达式
# gte,关键字,范围值
# # # gt,关键字,范围值
# # lte,关键字,范围值
# lt,关键字,范围值
# boost,关键字,分值加权
# relation,关键字,范围查询关系,针对xxx_range 范围字段才有效
# 数值范围查询
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query":{"range": {"FlightDelayMin":{"gte": 10,"lte": 20,"boost": 1}}}
}## 时间范围查询
# date,时间是一种特殊的数值类型,还必须考虑到时区,所以建议任何时候都必须使用UTC格式,否则容易出现问题
# range,关键字,查询表达式
# time zone,关键字,时区表达式,增加时区或者减少时区
# 查询某个时间范围类的航班信息,时间范围支持固定时间,也支持动态计算类型
# 查询固定时间
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query":{"range": {"timestamp":{"time_zone": "+00:00", "gte":"2024-03-20T12:09:35","lte": "2024-07-20T12:09:35","boost": 2}}}
}
# 查询动态时间
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query":{"range": {"timestamp":{"time_zone": "+00:00", "gte":"now-200d/d","lte": "now","boost": 2}}}
}## ragexp 正则表达式查询,慎用或者禁用,容易出现性能问题!!!有通配符的已经足够了
# 查询参数
# regexp,关键字,查询表达式
# values,关键字,输入内容包括查询表达式
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query":{"regexp": {"DestCityName.keyword":{"value": "Man.*"}}}
}## 词项限制
# terms查询字段数量限制,超过查询会报错,一般也不会超过
# 此设置属于动态设置,可临时修改
# 字段数量限制,默认 65535index.max terms count:65536
### span 跨度查询,全文本查询使用,高级查询,非必须掌握
# span,跨度查询,基于分词词项的精确位置,控制问隔,设定相似度来执行,相比match 匹配类查询,提供了更加底层灵活的查询机制,同时也是非常复杂。
# span,也提供了多种跨度查询方式
# 默认分词会转成小写
POST _analyze
{"text":["Hello David so Cool"]
}## span_term
# span term 等同与 term 查询,区别在于前者是应用在 text类型中,后者是在 keyword 类型
# span term 单独查询仅仅是为了展示,目的是为了后续的关系查询准备
# 查询参数
# span term,关键字,查询表达式
# value,关键字,输入值,注意,默认standard分词下,此处采用统一会转化成小写
# boost,关键字,分值加权
# 大写开头查不出来,注意大小写
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query": {"span_term": {"Origin": {"value": "edmonton"}}}
}## span_first
# span_first,跨度第一个词搜索,词项位置属于靠前,从左往右
# 查询参数
# span_first,关键字,查询表达式
# span_term,关键字,指定其中跨度搜索的字段
# end,关键字,控制搜索词项内容的距离,最大位置
# 搜索目的地机场,名字中包含“international”,且从第1个位置不超过2个词;修改查询条件,对比前后查询的结果与数据量。
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query": {"span_first": {"match": {"span_term": {"Dest": "international"}},"end": 2}}
}## span near
# span_near,跨度相近位置查询
# 查询参数
# span_near,关键字,查询表达式
# clauses,关键字,组合多个跨度查询
# slop,多个跨度条件直接的间隔
# in_order,多个跨度查询是否按照顺序进行,取值范围true/false
# 搜索目的机场包含“charlotte”与“international“,且中间间隔不超过1个词项,必须按照顺序
GET kibana_sample_data_flights_term/_search
{"query": {"span_near": {"clauses": [{"span_term": {"Dest": {"value": "vienna"}}},{"span_term": {"Dest": {"value": "international"}}}],"slop": 1,"in_order": true}}
}## span_or
# span_or,多个跨度词项组合,关系是 or,只要其中任意的满足查询即可
# 查询参数
# span_or,关键字
# clauses,关键字,查询表达式,组成多个跨度查询
# span_term,关键字,跨度查询,必须所有的跨度查询,字段指向一致
GET kibana_sample_data_flights_term/_search
{"query": {"span_or": {"clauses": [{"span_term": {"Dest": {"value": "airport"}}},{"span_term": {"Dest": {"value": "international"}}},{"span_term": {"Dest": {"value": "pisa"}}}]}}
}## span not
# span_not,组合多个跨度查询,包含其中跨度,不包含其中部分跨度
# 查询参数
# span_not,关键字
# include,关键字,包含
# exclude,关键字,不包含
# 查询目的地机场,词项包含“internationa!”,不包含“Spokane”的航班信息
GET kibana_sample_data_flights_term/_search
{"query": {"span_not": {"include": {"span_term": {"Dest": {"value": "international"}}},"exclude": {"span_term": {"Dest": {"value": "spokane"}}}}}
}## span_multi
# span_multi,组合多种查询方式,
# 查询参数
# span_multi,关键字,查询表达式
# match,关键字,查询表达式,prefix、term、range、wildcard,fuzzy,参考 term 领域的查询方式
# 搜索目的地机场,词项前缀包括”edmonton“的航班信息
GET kibana_sample_data_flights_term/_search
{"query": {"span_multi": {"match": {"prefix": {"Dest": {"value": "edmonton"}}}}}
}## span_containing
# span containing,组合多种跨度查询;little 优先,big次之
# 组合多个条件检索,仅仅返回 little 部分数据
## span_within
# span within,组合多种跨度查询;big优先,little次之
# 组合多个条件检索,仅仅返回 big 部分数据
## field_masking_span
# field_maskingspan,组合多种跨度查询,带有一点伪装的特性。
# 跨越多个字段组合查询
## Specialized 特殊查询
# script
# script,脚本是一种非常灵活的查询方式,同时背后也是有性能代价的若脚本查询的字段需要更多的操作计算,建议可以采用runtime字段方式
# 查询参数
# script,脚本查询表达式入口
# source,脚本内容,必须符合 bool类型;脚本采用painless
# params,输入值参数
# 查询电商信息数据,依据星期数,过滤返回结果
GET kibana_sample_data_ecommerce/_search
{"track_total_hits": true,"query": {"bool": {"filter": [{"script": {"script": {"source": """doc['day_of_week_i'].value==1;""","params": {"day_of_week_i":1}}}}]}}
}## script score
# 文本字符查询,ES 默认采用 BM25 计算分值排序,若要需要基于自定义字段分值,可采用script_score
# 同比类同 function_score 一样
# 也支持很多高级函数
# 查询参数
# script score,脚本分值查询关键字,查询表达式入口
# query,查询表达式
# script,脚本计算,自定义分值计算
# boost,加权值
# min_score,最低分值限制
# 基于航班数据,搜索目的包含“warsaw”,排序基于2个时间相加
GET kibana_sample_data_flights_term/_search
{"track_total_hits": true,"query": {"script_score": {"query": {"match": {"Dest": "warsaw"}},"script": {"source": """doc['FlightDelayMin'].value+doc['FlightTimeMin'].value;"""}}}
}## pinned 文档“固定”到搜索结果的顶部
# 对于实现个性化推荐、广告展示或确保某些重要文档始终出现在搜索结果的前面非常有用
# ids:这是一个数组,包含你希望固定的文档的 _id 或其他唯一标识符。这些文档将被固定到搜索结果的顶部。
# field:指定用于匹配文档的字段,默认是 _id。如果你使用的是自定义的唯一标识符字段,可以在这里指定。
# exclude:布尔值,表示是否从最终的搜索结果中排除固定的文档。默认值为 false,即固定的文档仍然会出现在搜索结果中。如果设置为 true,则固定的文档不会出现在最终结果中,但它们的排名信息仍然会被保留。
# inner_hits:可选参数,用于配置返回的固定文档的详细信息。你可以使用 inner_hits 来控制返回的固定文档的数量、排序方式、高亮显示等。
# rest:这是用于查询其他非固定文档的查询条件。你可以在这里使用任何标准的 Elasticsearch 查询 DSL,例如 match、term、bool 等。
GET kibana_sample_data_ecommerce/_search
{"query": {"pinned": {"ids": ["VITR0Y8BbWz2Sn6Eg40a", "U4TR0Y8BbWz2Sn6Eg40a"], "organic": { "match": {"products.product_name": "top"}}}}
}### 查询建议
# Term查询应该大规模使用,属于精确查询
# span慎重应用,了解底层机制优先
# 词项查询
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/term-level-queries.html
# 跨度查询
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/span-queries.html
# 特殊查询
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/specialized-queries.html
# script-score 脚本分值
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/query-dsl-script-score-guery.htm
# index-max-terms-count
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/index-modules.html#index-max-terms-count
# fuzziness 取值范围
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/common-options.html#fuzziness
# fuzzy 计算算法
# https://en.wikipedia.org/wiki/Levenshtein_distance
# rewrite 重写参数
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/query-dsl-multi-term-rewrite.html
# date-math 时间计算
# https:/www.elastic.co/guide/en/elasticsearch/reference/8.6/common-options.html#date-math
# “固定”到搜索结果的顶部
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/query-dsl-pinned-query.html
相关文章:

es 3期 第15节-词项查询与跨度查询实战运用
#### 1.Elasticsearch是数据库,不是普通的Java应用程序,传统数据库需要的硬件资源同样需要,提升性能最有效的就是升级硬件。 #### 2.Elasticsearch是文档型数据库,不是关系型数据库,不具备严格的ACID事务特性ÿ…...

iOS Delegate模式
文章目录 一、 Delegate 模式的概念二、Delegate 的实现步骤步骤 1: 定义一个协议(Protocol)步骤 2: 在主类中添加一个 delegate 属性步骤 3: 实现协议的类遵守协议并实现方法步骤 4: 设置 delegate 三、Delegate 模式的特点四、Delegate 模式的常见场景…...

java-使用druid sqlparser将SQL DDL脚本转化为自定义的java对象
java-使用druid sqlparser将SQL DDL脚本转化为自定义的java对象 一、引言二、环境三、待解析的DDL四、解析后的对象结构五、完整的UT类六、控制台输出总结 一、引言 在日常开发中,有些需要对SQL进行解析的场景,比如读取表结构信息,生成文档、…...
)
React状态管理常见面试题目(一)
1. Redux 如何实现多个组件之间的通信?多个组件使用相同状态时如何进行管理? Redux 实现组件通信 Redux 是一个集中式的状态管理工具,通过共享一个全局 store 来实现多个组件之间的通信。 通信机制: 所有状态保存在 Redux 的全局 store 中。使用 ma…...
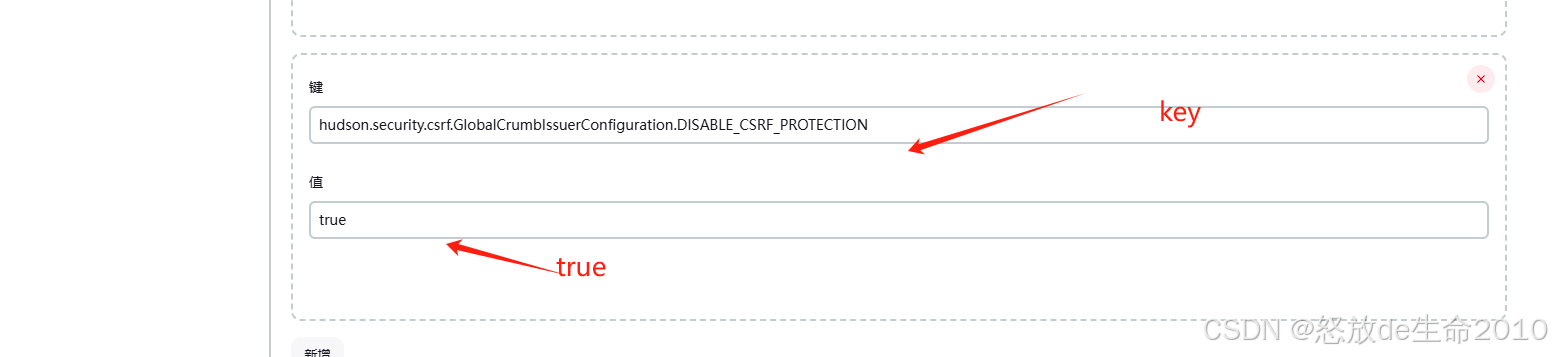
jenkins 出现 Jenkins: 403 No valid crumb was included in the request
文章目录 前言解决方式:1.跨站请求为找保护勾选"代理兼容"2.全局变量或者节点上添加环境变量3.(可选)下载插件 the strict Crumb Issuer plugin4.重启 前言 jenkins运行时间长了,经常出现点了好几次才能构建,然后报了Je…...

【前端面试】list转树、拍平, 指标,
这个题目涉及的是将一组具有父子关系的扁平数据转换为树形结构,通常称为“树形结构的构建”问题。类似的题目包括: 1. 组织架构转换 给定一个公司的员工列表,每个员工有 id 和 managerId,其中 managerId 表示该员工的上级。任务…...

游戏引擎学习第43天
仓库 https://gitee.com/mrxiao_com/2d_game 介绍运动方程 今天我们将更进一步,探索运动方程,了解真实世界中的物理,并调整它们,以创建一种让玩家感觉愉悦的控制体验。这并不是在做一个完美的物理模拟,而是找到最有趣…...

NVM:安装配置使用(详细教程)
文章目录 一、简介二、安装 nvm三、配置 nvm 镜像四、配置环境变量五、使用教程5.1 常用命令5.2 具体案例 六、结语 一、简介 在实际的开发和学习中可能会遇到不同项目的 node 版本不同,而出现的兼容性问题。 而 nvm 就可以很好的解决这个问题,它可以在…...
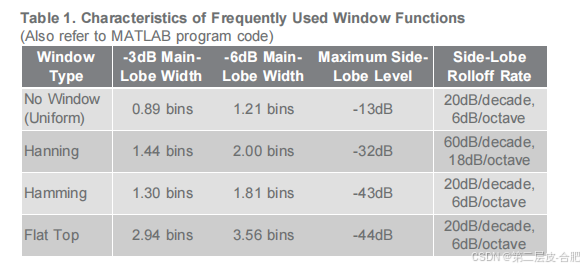
matlab测试ADC动态性能的原理
目录 摘要: 简介: 动态规范和定义 动态规格: 双面到单边的功率谱转换 摘要: 模数转换器(adc)代表了接收器、测试设备和其他电子设备中的模拟世界和数字世界之间的联系。正如本文系列的第1部分中所概述…...

PostgreSQL JSON/JSONB 查询与操作指南
PostgreSQL 提供了强大的 JSON 和 JSONB 数据类型及相关操作,适用于存储和查询半结构化数据。本文将详细介绍其常用操作。 1. 基础操作 1.1 JSON 属性访问 ->: 返回 JSON 对象中的值,结果为 JSON 格式。 SELECT {"a": {"b": 1…...
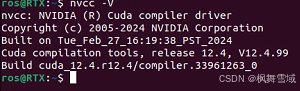
【Isaac Lab】Ubuntu22.04安装英伟达驱动
目录 1.1 禁用nouveau驱动 1.2 安装必要的依赖项 1.3 下载安装 1.4 查看是否安装成功 1.5 安装CUDA 1.5.1 下载 1.5.2 按照提示进行下载安装 1.5.3 添加环境变量 1.5.4 测试CUDA是否安装成功 1.1 禁用nouveau驱动 输入以下命令打开blacklist.conf文件 sudo vim /etc…...
JS,递归,处理树形数据组件,模糊查询树形结构数据字段
JS递归如何模糊查询树形结构数据,根据数据中的某一个字段值,模糊匹配 直接拿去使用就行 function filterTreeLabel(arr, label) {let result []arr.forEach((item) > {// if (String(item.POBJECT_NAME).toLowerCase().indexOf(label)!-1) {if (String(item.P…...

神州数码DCME-320 online_list.php 任意文件读取漏洞复现
0x01 产品描述: 神州数码DCME-320是一款高性能多业务路由器,专为多用户、多流量和多业务种类需求设计。它采用了...

nginx的内置变量以及nginx的代理
nginx的内置变量 客户端 命令含义$uri可以获取客户端请求的地址,包含主机和查询的参数$request_uri:获取客户端的请求地址,包含主机和查询参数。$host:请求的主机名,客户端—发送请求的url地址$http_user_agent获取客户端请求的浏览器和操作…...
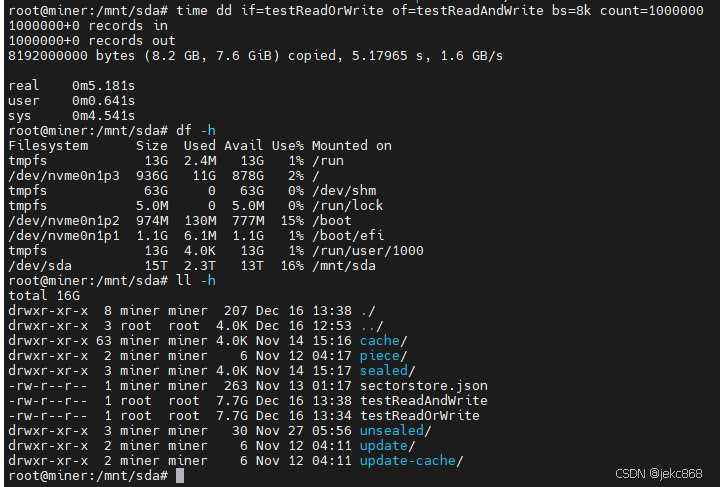
ubuntu监测硬盘状态
安装smartmontools smartctl -l error /dev/sdk smartctl -i /dev/sda lshw -class disk smartctl -H /dev/sd 结果1: 结果2:PASSED,这表示硬盘健康状态良好 smartctl -a /dev/sdb sdk lsblk blkid 测试写入速度 time dd if/dev/zero of…...

3.2.1.2 汇编版 原子操作 CAS
基本原理说明 在 x86 和 ARM 架构上,原子操作通常利用硬件提供的原子指令来实现,比如 LOCK 前缀(x86)或 LDREX/STREX(ARM)。以下是一些关键的原子操作(例如原子递增和比较交换)的汇…...

InnoDB事务系统(二):事务的实现
事务隔离性由锁来实现。原子性、一致性、持久性通过数据库的 redo log 和 undo log 来完成。 redo log 称为重做日志,用来保证事务的原子性和持久性。undo log 用来保证事务的一致性。 有的 DBA 或许会认为 undo 是 redo 的逆过程,其实不然。redo 和 u…...

xdoj :模式匹配
模式匹配 题目描述: 接收信号中包含特定的信号模式,对接收信号进行检测,以统计特定模式出现的次数。 例如接收信号为 9 3 5 7 5 8 6 3 5 7 1 9 3 5 7,如果特定信号为 3 5 7,则接收信号中包含了 3 个特定模式。通过键…...

Redis的基本使用命令(GET,SET,KEYS,EXISTS,DEL,EXPIRE,TTL,TYPE)
目录 SET GET KEYS EXISTS DEL EXPIRE TTL redis中的过期策略是怎么实现的(面试) 上文介绍reids的安装以及基本概念,本章节主要介绍 Redis的基本使用命令的使用 Redis 是一个基于键值对(KEY - VALUE)存储的…...
生产环境中遇到的问题及改进)
LruCache(本地cache)生产环境中遇到的问题及改进
问题:单机qps增加时请求摘要后端,耗时也会增加,因为超过了后端处理能力(最大qps,存在任务堆积)。 版本一 引入LruCache。为了避免数据失效,cache数据的时效性要小于摘要后端物料的更新时间&…...

终极Windows防休眠指南:使用Move Mouse保持电脑持续活跃
终极Windows防休眠指南:使用Move Mouse保持电脑持续活跃 【免费下载链接】movemouse Move Mouse is a simple piece of software that is designed to simulate user activity. 项目地址: https://gitcode.com/gh_mirrors/mo/movemouse 你是否经常遇到电脑自…...

《生产级性能监控实战:基于 Spring AOP + 消息提醒的智能告警系统设计与实现》
一、引言1.1 痛点场景在生产环境中,性能问题往往比业务缺陷更难以察觉,也更具破坏力。你是否也遇到过以下困境:生产环境性能问题难以发现?接口响应从 200ms 逐渐恶化到 5 秒,用户感知强烈,监控系统却毫无告…...

7个核心价值点:Python学习路径与实战案例深度解析
7个核心价值点:Python学习路径与实战案例深度解析 【免费下载链接】Python-100-Days Python - 100天从新手到大师 项目地址: https://gitcode.com/GitHub_Trending/py/Python-100-Days Python作为一门多用途编程语言,在数据分析、Web开发、人工智…...

从手术室到移动端:iMedSTAM交互式视频分割模型实战,5分钟搭建你的低延迟医学分析原型
从手术室到移动端:iMedSTAM交互式视频分割模型实战,5分钟搭建你的低延迟医学分析原型 在腹腔镜手术中,外科医生常常需要在实时视频流中快速定位关键解剖结构。传统AI模型往往需要完整视频输入和离线处理,而iMedSTAM的"随时预…...

Llama-3.2V-11B-cot惊艳效果:将儿童涂鸦转化为含因果逻辑的故事描述
Llama-3.2V-11B-cot惊艳效果:将儿童涂鸦转化为含因果逻辑的故事描述 1. 模型能力概览 Llama-3.2V-11B-cot 是一个突破性的视觉语言模型,它能将简单的儿童涂鸦转化为包含完整因果逻辑的故事描述。这个基于LLaVA-CoT论文实现的模型,展现了令人…...

终极指南:如何用BetterGI智能辅助工具彻底解放你的原神游戏体验
终极指南:如何用BetterGI智能辅助工具彻底解放你的原神游戏体验 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条龙 | 全连…...

OpenClaw安全防护指南:Qwen3-32B私有化部署下的权限管控策略
OpenClaw安全防护指南:Qwen3-32B私有化部署下的权限管控策略 1. 为什么需要关注OpenClaw的安全防护? 当我第一次把OpenClaw部署在自己的开发机上时,那种兴奋感至今记忆犹新——一个能帮我自动处理文件、整理资料、甚至写代码的AI助手&#…...

OpenClaw配置备份:千问3.5-35B-A3B-FP8环境快速迁移方案
OpenClaw配置备份:千问3.5-35B-A3B-FP8环境快速迁移方案 1. 为什么需要配置备份? 上周我的主力开发机突然硬盘故障,导致OpenClaw与千问3.5-35B-A3B-FP8的对接配置全部丢失。重新配置花了整整两天时间——从模型地址验证、飞书通道重建到技能…...

Qwen2.5-VL-7B-Instruct环境部署:torch29环境兼容性验证与降级策略
Qwen2.5-VL-7B-Instruct环境部署:torch29环境兼容性验证与降级策略 1. 项目概述与准备工作 Qwen2.5-VL-7B-Instruct是一款强大的多模态视觉-语言模型,能够同时处理图像和文本输入,生成高质量的响应。在部署过程中,我们发现torch…...

关于visio导出png jpg等格式图片边缘出现黄线的暂时解决方案
起因是更新windows后,visio导出图片边缘将会出现黄线,对于强迫症患者来说实在难以忍受。首先23H2是没有这个问题的,好像25H2才有的。随着我一直更新系统好像目前的黄线没有以前那么多了,但仍然有。删除更新感觉并不是一个很好的办…...