Redis篇-12--数据结构篇4--Hash内存模型(数组,链表,压缩列表zipList,哈希表,短结构)
Redis的Hash数据结构用于存储键值对(key-value形式)的集合(类似java中HashMap或对象)。为了在保证高效性能的同时节省内存,Redis对Hash的底层实现进行了多种优化。特别是通过使用压缩列表(ziplist)和哈希表(hashtable)两种不同的数据结构来适应不同场景下的需求。
下面,先来认为一下哈希表,之后在详细解释下Hash内存模型的特点吧。
一、哈希表
1、数组(Array)
数组是一种线性数据结构,它以连续的内存块来存储相同类型的元素。每个元素可以通过其索引(通常是基于0或1开始的整数)直接访问。数组的大小是在创建时确定的,并且通常不能轻易改变。
原理:
- 内存分配:当创建一个数组时,操作系统会分配一块连续的内存区域,这块区域的大小等于数组长度乘以每个元素所占的字节数。
- 随机访问:由于数组元素是连续存储的,因此可以通过起始地址加上偏移量(即索引乘以每个元素的大小)来快速计算任何元素的地址,从而实现O(1)时间复杂度的随机访问。
- 插入与删除:在数组中间插入或删除元素需要移动其他元素,以保持数组的连续性,这会导致O(n)的时间复杂度,其中n是数组的长度。
主要特点:
长度固定,内存空间连续,查询快,插入和删除相对比较慢。
2、链表(Linked List)
链表是由一系列节点组成的集合,每个节点包含数据部分和下一个节点的引用(指针)。链表不要求节点在内存中是连续存储的。
原理:
- 内存分配:链表中的节点可以在内存的任何位置分配,因为每个节点都有一个指针指向下一个节点。这意味着链表可以动态增长或收缩。
- 访问元素:链表不支持随机访问,要访问某个特定的元素,必须从头节点开始遍历链表,直到找到目标节点。因此,查找操作的时间复杂度为O(n)。
- 插入与删除:如果已经定位到了要插入或删除的位置,那么这些操作只需修改相邻节点的指针,时间复杂度为O(1)。但是,定位到该位置本身可能需要O(n)的时间。
特点:
长度不固定,内存不连续,节点包含数据和方向指针,查询比较慢,插入和删除比较快。
分类:
链表分为单向链表(每个节点只有一个指向下一个节点的指针)、双向链表(每个节点有两个指针,分别指向前后两个节点)和循环链表(最后一个节点指向第一个节点形成环形)。
3、哈希表(Hash Table)
(1)、概述
哈希表是计算机科学中一种非常重要的数据结构,它在解决大规模数据存储和查找问题上发挥着关键作用。
哈希表是一种用于存储键值对的数据结构,它使用哈希函数将key映射到表中的一个位置来快速访问到记录value。哈希表旨在提供平均情况下的常数时间复杂度O(1)的查找、插入和删除操作。
哈希表是通过数组+链表的方式实现的,主结构是数组,数组的每一个节点都是一张单独的链表。
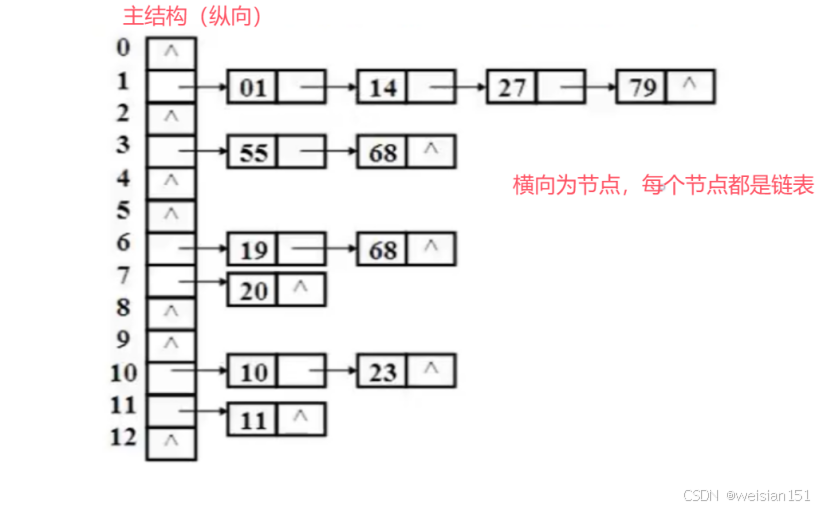
(2)、主要特点
(1)、数组+链表的结构,主结构是数组,数组的每一个节点都是一个链表。
(2)、操作key-value类型数据,key用于确认表的位置,value存储在这个位置中。
(3)、自动扩容,查询、插入和删除都比较快。
(3)、工作原理
(1)、插入元素原理
第一步:计算key的哈希码(调用hashCode()方法计算,返回int型,整数的哈希码是自身)。
第二步:根据哈希码算出该key在哈希表中的位置index
如:算法index=x%11 (假设当前数组长度是11,实际数组的长度会自动扩容的)
第三步:将数据value存入哈希表的index位置。
情况1:一次添加成功(该位置没有任何数据)
情况2:多次添加成功(出现了冲突,即数组中该位置已有元素,则调用equals()和对应链表的元素进行逐个比较,结果都是false,创建新节点,在该位置的链表末尾添加新元素)
情况3:不添加(出现了冲突,调用equals()和该位置的链表的元素逐个进行比较,结果是true,表明本次是重复插入,不添加元素)
结论:哈希表的数据是无序的,唯一的。最快插入数据需要三步。
说明下;哈希表刚创建时期,数组长度相对比较短。第二步hash算法需要把第一步的hashCode都映射到这些较短的位置上,所以就会有很多重复。实际上第一步计算hashCode出来的重复概率非常非常低的,经过第二步hash算法后,重复概率才变高的。

(2)、查询元素原理
基本和插入元素逻辑相同。
第一步:计算key的哈希码。
第二步:根据哈希码算出该key在哈希表中的位置index。
第三步:查询该位置index的元素。
情况1:直接查询失败(该位置没有任何数据)
情况2:多次查询失败(该位置链表存在1个或多个元素,逐个调用equals()方法比较,结果都是false,则说明不存在目标key存储)
情况3:查询成功(该位置链表存在1个或多个元素,逐个调用equals()方法比较,存在返回true,则说明存在目标key存储,返回该位置的value值)
删除元素逻辑和查询元素原理一致,则不在赘述了。
4、动态扩容
(1)、哈希表的核心原理:
-
哈希函数:使用哈希函数将每个键转换为一个整数索引(也称为哈希值)。这个哈希值决定了键在哈希表中的存储位置。哈希函数的设计目标是尽量减少冲突(即不同的键映射到同一个索引),以提高查找效率。
-
冲突解决:即使哈希函数设计得再好,也难免会出现多个键映射到同一个索引的情况,这被称为“哈希冲突”。为了处理冲突,哈希表采用链地址法(Separate Chaining),即每个哈希表的槽位(bucket)实际上是一个链表。当发生冲突时,新的键会被添加到链表的末尾。虽然链表查找的时间复杂度是 O(n),但在实际应用中,哈希冲突的概率非常低,因此平均查找时间仍然是 O(1)。
(2)、为什么要扩容?
假设哈希表需要存储100万个键,哈希表的大小为 16384(2^14)。每个键通过哈希函数计算出一个0到16383之间的索引位置,然后存储在对应的槽位中。由于哈希表的大小远小于键的数量,哈希冲突是不可避免的,且每个槽位的链表也会非常的长,进而导致查询性能会下降(前面我们介绍过,哈希函数找到槽位后,进一步在链表中找到key需要遍历链表元素进行equal比较,如果链表越长,比较次数就越多,自然查询也就越慢)。
为了避免这种情况,哈希表会随着负载因子(即键的数量与哈希表大小的比值)超过一定阈值时,触发 rehash 操作,即将哈希表的大小扩大,并重新分配所有键。
(3)、哈希表rehash机制
在大多数情况下,当哈希表的装载因子超过某个阈值时,哈希表会进行扩容,并将所有元素从旧的哈希表迁移到新的、更大的哈希表中。这个过程是一次性的,意味着它会在一个操作中完成所有的迁移工作。这种方法的优点是简单直接,但缺点是在迁移期间可能会显著影响性能,因为所有读写操作都需要等待迁移完成。
Redis为了减少rehash操作对性能的影响而采用的一种特定策略,即渐进式rehash(也称增量rehash)。
(4)、Redis渐进式rehash机制
渐进式rehash是Redis为了优化性能而设计的一种特殊策略,它有效地解决了大规模哈希表rehash时可能导致的性能问题。
1、渐进式rehash的工作原理
-
双哈希表:在 rehash 过程中,Redis同时维护两个哈希表:旧哈希表(ht[0])和新哈希表(ht[1])。所有新的键都会直接插入到新哈希表中,而旧哈希表中的键会逐步迁移到新哈希表。(key会直接插入新哈希表,且对旧哈希表的当前key槽数据迁移到新哈希表,保证新旧哈希表中只会有一个key存在)
-
逐步迁移:Redis不会在一次操作中将所有键从旧哈希表迁移到新哈希表,而是每次处理客户端请求时,迁移一部分键。具体来说,Redis会在每次执行命令时,从旧哈希表中随机选择一些槽位,并将这些槽位中的键迁移到新哈希表。这样可以确保 rehash操作不会影响 Redis的正常性能。
-
rehash完成:当所有键都迁移到新哈希表后,Redis会丢弃旧哈希表,只保留新哈希表。此时,rehash操作完成,哈希表的大小已经扩大,查找性能得到恢复。
2、渐进式rehash如何优化性能
-
避免一次性性能波动:如果一次性完成rehash操作,Redis 需要遍历所有键并重新计算哈希值,这会导致性能显著下降,尤其是在键数量非常多的情况下。渐进式 rehash将rehash操作分散到多个请求中,确保了在高并发场景下,Redis 的性能不会受到明显影响。
-
不影响正常操作:在rehash过程中,Redis仍然可以正常处理客户端请求。对于新插入的键,Redis会直接将其插入到新哈希表中;对于旧哈希表中的键,Redis会先在旧哈希表中查找,如果找不到,再在新哈希表中查找。这种机制确保了 rehash 不会影响正常的读写操作。
3、Redis哈希表的具体实现
- 字典(Dictionary):Redis的哈希表是通过字典(dict)来实现的。字典内部包含两个哈希表(ht[0] 和 ht[1]),用于支持渐进式rehash。
- 哈希函数:Redis使用MurmurHash2或者更现代的MurmurHash3作为默认的哈希函数,这些哈希函数具有良好的分布特性和较高的计算效率。
- 冲突解决:Redis 采用链地址法来处理冲突,即每个桶包含一个链表,链表中的每个节点存储一个键值对。
4、查找键的过程
当Redis进行rehash时,需要查找一个键时,它会按照以下步骤进行:
(1)、计算哈希值:首先,Redis会使用哈希函数计算目标键的哈希值,并确定该键应该存储在哪个槽位中。
(2)、检查新哈希表:如果当前正在进行rehash,Redis会先在新哈希表(ht[1])中查找该键。如果找到了,直接进行操作。
(3)、再检查旧哈希表:如果在新哈希表中没有找到该键,Redis会继续在旧哈希表(ht[0])中查找。如果找到了,返回结果;如果没有找到,则说明该键不存在。
(4)、处理冲突:如果在某个槽位中发生了哈希冲突,Redis会遍历该槽位对应的链表,逐个比较键的值,直到找到匹配的键或遍历完链表。
(5)、查找时间复杂度
-
理想情况下:在没有哈希冲突的情况下,查找时间复杂度为 O(1),因为 Redis 可以直接通过哈希值定位到键所在的槽位。
-
存在哈希冲突时:如果发生了哈希冲突,Redis 需要在链表中逐个比较键的值,查找时间复杂度为 O(n),其中 n 是该槽位中键的数量(即:链表的长度)。然而,在实际应用中,哈希冲突的概率非常低,因此平均查找时间仍然是 O(1)。
(6)、哈希表的扩展策略
Redis 的哈希表会根据键的数量自动调整大小,以确保负载因子保持在一个合理的范围内。具体的扩展策略如下:
-
触发条件:
- 当哈希表的负载因子(即键的数量与哈希表大小的比值)超过
max-load-factor(默认是 1.0)时,触发 rehash 操作。 - 当哈希表的负载因子低于
min-load-factor(默认是 0.1)时,触发收缩操作(即将哈希表缩小)。
- 当哈希表的负载因子(即键的数量与哈希表大小的比值)超过
-
扩展倍数:Redis 通常会将哈希表的大小扩展为原来的两倍(即 2^n 的形式),以确保哈希表的大小始终是2的幂次方。这样可以简化哈希函数的实现,并且有助于减少哈希冲突。
(7)、内存碎片整理
虽然Redis的哈希表扩展机制能够有效减少哈希冲突,但在长时间运行的情况下,内存碎片(由于扩容或收缩造成内存使用不充分,出现未使用且已开辟的小内存片段)可能会逐渐积累。为此,Redis使用了高效的内存分配器(如 jemalloc),并且提供了内存碎片整理机制。通过定期回收未使用的内存页,Redis可以确保在大规模数据集的情况下,内存使用率仍然保持高效。
(8)、动态扩容总结
Redis 能够在几百万个键的情况下快速找到目标键,主要得益于以下几点:
- 哈希表:Redis 使用哈希表作为其主要的数据结构,通过哈希函数将键映射到固定的数组位置,实现了O(1) 的平均查找时间。
- 渐进式rehash:当哈希表的负载因子过高时,Redis会触发rehash操作,但为了避免一次性rehash对性能的影响,Redis采用了渐进式rehash机制,将rehash操作分散到多个请求中逐步完成。
- 双哈希表机制:在 rehash 过程中,Redis 同时维护两个哈希表,确保在 rehash 期间仍然可以正常处理客户端请求。
- 哈希冲突处理:即使发生了哈希冲突,Redis 也通过链地址法有效地解决了冲突,确保了查找性能。
二、Redis的Hash结构
Redis的Hash数据结构用于存储键值对(key-value形式)的集合(类似java中HashMap)。通过使用压缩列表(ziplist)和哈希表(hashtable)两种不同的数据结构来适应不同场景下的需求。
1、压缩列表(ziplist)
当Hash中的元素数量较少且每个字段和值都较短时,Redis使用压缩列表(ziplist)来存储 Hash。压缩列表是一种紧凑的内存表示形式,能够将多个键值对打包到一个连续的内存块中,减少了指针开销和内存碎片。
(1)、压缩列表的特点
-
紧凑存储:压缩列表将多个键值对(即key和value)打包到一个连续的内存块中,避免了指针开销。每个键值对的存储空间根据其实际大小动态调整,支持变长编码。
-
有序性:压缩列表中的键值对是按插入顺序排列的,虽然Hash本身是无序的,但压缩列表的内部结构是有序的,这有助于提高查找效率。
-
内存高效:由于压缩列表是紧凑的数组结构,它减少了内存碎片,并且不需要额外的指针开销。这使得压缩列表在处理小规模数据时具有很高的内存利用率。
-
前缀压缩:对于相邻的字符串字段或值,压缩列表会使用前缀压缩技术来减少重复字符串的存储空间。如果两个相邻的字符串有相同的前缀,压缩列表只会存储一次前缀,并在后续的字符串中引用该前缀。
-
局部重排:当插入或删除键值对时,压缩列表会尽量保持数据的紧凑性,避免频繁的内存分配和释放。它通过局部重排(即将新键值对插入到合适的位置,并调整相邻键值对的存储位置)来减少内存碎片。
(2)、压缩列表的工作原理
-
变长编码:压缩列表使用变长编码来存储字段和值。例如,小整数可以使用较少的字节来表示,而大整数则使用更多的字节。这种变长编码方式减少了不必要的内存浪费。
-
前缀压缩:对于相邻的字符串字段或值,压缩列表会使用前缀压缩技术来减少重复字符串的存储空间。这在处理大量相似的字符串时特别有效,能够显著节省内存。
-
局部重排:当插入或删除键值对时,压缩列表会尽量保持数据的紧凑性,避免频繁的内存分配和释放。它通过局部重排(即将新键值对插入到合适的位置,并调整相邻键值对的存储位置)来减少内存碎片。
(3)、压缩列表的内存优化
-
减少内存碎片:压缩列表通过紧凑的数组结构减少了内存碎片,特别适合处理小规模数据。它避免了传统链表中常见的内存碎片问题,提高了内存利用率。
-
缓存友好:由于压缩列表中的键值对是连续存储的,访问这些键值对时可以充分利用 CPU 缓存,减少缓存未命中的次数。这有助于提升性能。
2、哈希表(hashtable)
当Hash中的元素数量较多,或者字段和值的长度较长时,Redis会切换使用哈希表(hashtable)来存储Hash。哈希表是一种基于哈希函数的数据结构,能够提供O(1)的平均查找、插入和删除操作。
(1)、哈希表的特点
-
快速查找:哈希表通过哈希函数将字段映射到固定的桶中,查找、插入和删除操作的平均时间复杂度为O(1)。这使得哈希表在处理大规模数据时具有很高的性能。
-
无重复字段:哈希表保证Hash中没有重复的字段,符合Hash的语义要求。
-
动态调整大小:当哈希表的装载因子(已用槽位数与总槽数的比例)过高时,哈希表会进行扩容,以减少冲突并保持性能。Redis使用渐进式rehash来分摊rehash的工作量,避免一次性迁移所有元素导致的性能下降。
-
冲突解决:哈希表使用链地址法(Separate Chaining)来处理冲突。每个桶包含一个链表,当多个字段被哈希到同一个桶时,它们会被添加到该链表中。虽然链地址法可能会导致链表过长,但Redis 通过渐进式rehash来减少冲突的发生。
(2)、哈希表的工作原理
-
哈希函数:哈希表使用哈希函数将字段映射到固定的桶中。Redis使用MurmurHash2或 MurmurHash3作为默认的哈希函数,这些哈希函数具有良好的分布特性和较高的计算效率。
-
渐进式rehash:当哈希表的装载因子过高时,Redis会创建一个新的、更大的哈希表,并将元素逐步迁移到新的表中。这个过程是逐渐进行的,每次执行命令时,Redis会迁移一部分元素,直到所有元素都迁移完毕。渐进式rehash确保了在高并发环境下,Hash的操作性能仍然保持稳定。
-
冲突处理:当多个字段被哈希到同一个桶时,哈希表使用链地址法来处理冲突。每个桶包含一个链表,链表中的每个节点存储一个字段值对。虽然链地址法可能会导致链表过长,但 Redis通过渐进式rehash来减少冲突的发生。
(3)、哈希表的内存优化
-
减少冲突:通过渐进式rehash,Redis能够动态调整哈希表的大小,减少冲突的发生,从而提高查找效率并节省内存。
-
内存高效:哈希表的每个节点只包含字段和值的指针,避免了额外的内存开销。相比于压缩列表,哈希表在处理大规模数据时更加高效,特别是在字段和值的长度较长时。
3、混合结构,自动转换
Redis的Hash实现了一个智能的混合结构,能够在压缩列表(ziplist)和哈希表(hashtable) 之间自动转换,以适应不同的应用场景。
(1)、自动切换原理
-
初始状态:当Hash中的元素数量较少且每个字段和值都较短时,Redis使用压缩列表(ziplist)来存储Hash。此时,Hash具有最高的内存利用率和操作效率。
-
自动升级:当Hash中的元素数量超过某个阈值,或者字段和值的长度超过一定限制时,Redis会立即将压缩列表转换为哈希表。这个转换过程是一次性的,不会影响后续的操作。
-
不会反向转换:Redis不会将哈希表转换回压缩列表,因为一旦Hash的规模较大,哈希表已经能够高效地处理这些元素。(转换过程是一次性的,也会造成性能的开销,如果在临界值的地方修改hash数据,就会造成数据结构频繁切换,进而导致性能消耗很大,所以也不会逆向切换了。)
(2)、自动转换的条件
-
元素数量:当Hash中的元素数量超过某个阈值时,Redis会自动将压缩列表转换为哈希表。这个阈值可以通过配置参数hash-max-ziplist-entries来调整,默认值为 512。
-
字段和值的长度:即使Hash中的元素数量较少,但如果某个字段或值的长度超过一定限制,Redis也会将压缩列表转换为哈希表。这个长度限制可以通过配置参数 hash-max-ziplist-value来调整,默认值为64字节。
4、内存优化的其他技术
除了压缩列表和哈希表的结合使用,Redis还采用了其他一些内存优化技术来进一步提升 Hash的性能和内存利用率:
-
渐进式rehash:当哈希表需要扩容时,Redis使用渐进式rehash来分摊rehash的工作量,避免一次性迁移所有元素导致的性能下降。这确保了在高并发环境下,Hash的操作性能仍然保持稳定。
-
惰性释放:当Hash中的键值对被删除时,Redis不会立即回收多余的内存,而是保留下来用于后续可能的增长。这减少了频繁的内存分配和释放操作,提升了性能。
-
前缀压缩:对于相邻的字符串字段或值,Redis使用前缀压缩技术来减少重复字符串的存储空间。这在处理大量相似的字符串时特别有效,能够显著节省内存。
-
变长编码:Redis使用变长编码来存储整数和浮点数,减少了不必要的内存浪费。例如,小整数可以使用较少的字节来表示,而大整数则使用更多的字节。
5、Redis的hash结构总结
Redis的Hash通过结合压缩列表(ziplist)和哈希表(hashtable)两种不同的数据结构,实现了高效的内存优化。当 Hash 中的元素数量较少且每个字段和值都较短时,Redis使用压缩列表来存储Hash。当 Hash中的元素数量较多,或者字段和值的长度较长时,Redis使用哈希表来存储Hash。
Redis会在压缩列表和哈希表之间自动转换,以适应不同的应用场景。当Hash中的元素数量超过某个阈值,或者字段和值的长度超过一定限制时,压缩列表会自动转换为哈希表。
当哈希表需要扩容时,Redis使用渐进式rehash来分摊rehash的工作量,避免一次性迁移所有元素导致的性能下降。
三、传统哈希表和redis哈希结构对比
(1)、概述
Redis 确实实现了哈希表的原理,但它对传统哈希表进行了扩展和优化,以适应其特定的需求和使用场景。因此,可以说 Redis 的哈希表是一种基于传统哈希表原理的增强型数据结构,但主要原理还是哈希表的概念。
(2)、对比分析
1、基本原理:
- 传统哈希表:使用哈希函数将键映射到一个固定的数组(桶)中,当发生冲突时,通常采用链地址法来处理。
- Redis哈希表:同样使用哈希函数将键映射到桶中,但引入了渐进式rehash、压缩列表等优化机制,以提高性能和内存利用率。
2、扩容机制:
- 传统哈希表:在扩容时,通常会一次性完成所有元素的重新哈希和迁移,这可能会导致短暂的性能下降。
- Redis哈希表:通过渐进式rehash,Redis将rehash过程分摊到多个命令执行的过程中,减少了对性能的影响,确保了高并发环境下的稳定性和响应速度。
3、内存优化:
- 传统哈希表:通常不会对小规模数据进行特殊优化,内存使用较为固定。
- Redis哈希表:对于小规模数据,Redis使用压缩列表(ziplist)或整数集合(intset)来存储数据,从而节省内存。这些特殊的数据结构在数据量较小时非常高效,但在数据量增大时会自动转换为标准的哈希表结构。
4、并发处理:
- 传统哈希表:在多线程环境中,通常需要加锁来保证线程安全,这可能会影响性能。
- Redis哈希表:Redis是单线程的,但在rehash期间,它允许同时访问两个哈希表(ht[0] 和 ht[1]),并通过逐步迁移的方式确保数据的一致性和高性能。
5、应用场景:
- 传统哈希表:适用于一般的键值对存储和查找场景,提供 O(1) 的平均时间复杂度。
- Redis哈希表:除了基本的键值对存储和查找功能外,还支持丰富的命令集,如批量操作、事务、持久化等,特别适合于缓存、会话管理、计数器等高性能应用场景。
(3)、总结
Redis 的哈希表并不是完全脱离了传统哈希表的概念,而是基于传统哈希表的原理进行了多项优化和改进。这些优化使得 Redis的哈希表在高并发、低延迟的应用场景中表现出色,同时保持了高效的内存利用率和良好的性能。可以说 Redis的哈希表是一种“增强型”的哈希表,它结合了传统哈希表的优点,并针对 Redis 的需求进行了专门的设计和优化。
附录:
Redis短结构
“短结构”(Small Encoding)是指Redis为某些数据类型提供的一种优化的内存的方式,旨在减少小数据的内存占用。Redis通过使用紧凑的数据结构来存储小规模数据,避免了不必要的指针开销和内存碎片,从而提高了内存利用率和性能。
*Redis的"短结构"主要应用于以下几种数据类型:
1、Hash
2、List
3、Set
4、Sorted Set
- Hash和List在元素数量较少且每个元素较短时使用压缩列表ziplist。
- Set在元素数量较少且所有元素都是整数时使用整数集合intset。
- Sorted Set在元素数量较少且每个元素的分数和成员较短时使用压缩列表ziplist。*
这些数据类型在元素数量较少且每个元素较小时,Redis会使用一种紧凑的编码方式(通常是压缩列表ziplist或整数集合intset)来存储数据,而不是立即使用更复杂的数据结构(如哈希表、双向链表等)。这种紧凑的编码方式被称为短结构(small encoding)。
本篇我们介绍了Hash的短结构模式(zipList),后面篇章会陆续介绍其他数据类型的短结构实现。
学海无涯苦作舟!!!
相关文章:
Redis篇-12--数据结构篇4--Hash内存模型(数组,链表,压缩列表zipList,哈希表,短结构)
Redis的Hash数据结构用于存储键值对(key-value形式)的集合(类似java中HashMap或对象)。为了在保证高效性能的同时节省内存,Redis对Hash的底层实现进行了多种优化。特别是通过使用压缩列表(ziplistÿ…...

二、windows环境下vscode使用wsl教程
本篇文件介绍了在windows系统使用vscode如何连接使用wsl,方便wsl在vscode进行开发。 1、插件安装 双击桌面vscode,按快捷键CtrlShiftX打开插件市场,搜索【WSL】点击安装即可。 2、开启WSL的linux子系统 点击左下方图标【Open a Remote Win…...

Qwen2-VL微调体验
1.配置环境 2.数据集准备 3.模型下载 4.注册SwanLab 5.微调 6.训练过程可视化 1.配置环境 本博客使用的是2B模型,所以仅用了单卡3090,若大一点的模型,自行根据实际情况准备显卡 安装Python>3.8 安装Qwen2-VL必要的库 pip install…...

论文的模拟环境和实验环境
模拟环境和实验环境 在撰写SCI计算机领域论文时,模拟环境和实验环境是两个重要的概念,它们之间存在显著的差异。 模拟环境主要是利用计算机、数学方法等手段对实际系统进行描述和分析的过程。在计算机科学中,模拟环境可以用于模拟各种算法、系统或网络的行为,以便在不需要…...

MySQL EXPLAIN 详解:一眼看懂查询计划
在日常的数据库开发中,我们经常需要分析 SQL 查询性能,而 EXPLAIN 是 MySQL 提供的利器,可以帮我们快速理解查询计划,优化慢查询。本文将详细解析 EXPLAIN 的输出字段及其含义,并结合实际案例分享优化思路。 一、什么是…...

自动呼入机器人如何与人工客服进行无缝切换?
自动呼入机器人如何与人工客服进行无缝切换? 原作者:开源呼叫中心FreeIPCC,其Github:https://github.com/lihaiya/freeipcc 自动呼入机器人与人工客服的无缝切换详解 自动呼入机器人与人工客服之间的无缝切换是确保客户体验连续…...
二分类模型的性能评价指标
1. 混淆矩阵 (Confusion Matrix) 预测正类预测负类实际正类 (P)True Positive (TP)False Negative (FN)实际负类 (N)False Positive (FP)True Negative (TN) True Positive (TP): 模型正确预测为正类的样本数。True Negative (TN): 模型正确预测为负类的样本数。False Positi…...

鸿蒙操作系统简介
华为鸿蒙系统(HUAWEI HarmonyOS),是华为公司于2019年8月9日在东莞举行的华为开发者大会(HDC.2019)上正式发布的面向全场景的分布式操作系统,可以创造一个超级虚拟终端互联的世界,将人、设备、场…...
)
单片机:实现蜂鸣器数码管的显示(附带源码)
单片机实现蜂鸣器数码管显示 蜂鸣器和数码管在嵌入式系统中广泛应用。蜂鸣器可以发出声音警告或提示,而数码管则用于显示数字或字母。在本项目中,我们将通过8051单片机实现一个控制蜂鸣器和数码管显示的系统,结合使用蜂鸣器和数码管…...

C语言期末复习笔记(上)
目录 一、为什么要学习C语言 1.C语言适合做什么 2.开发C程序的步骤 3.常用术语 二、C语言数据结构 1.常量与变量 (1)常量 编辑 (2)变量 2.数据类型 编辑 (1)数据类型的分类 (2&a…...

HarmonyOS 实时监听与获取 Wi-Fi 信息
文章目录 摘要项目功能概述代码模块详细说明创建 Wi-Fi 状态保存对象Wi-Fi 状态监听模块获取当前 Wi-Fi 信息整合主模块 运行效果展示性能分析总结 摘要 本文展示了如何使用 HarmonyOS 框架开发一个 Demo,用于监听手机的 Wi-Fi 状态变化并实时获取连接的 Wi-Fi 信息…...

Unity超优质动态天气插件(含一年四季各种天气变化,可用于单机局域网VR)
效果展示:https://www.bilibili.com/video/BV1CkkcYHENf/?spm_id_from333.1387.homepage.video_card.click 在你的项目中设置enviro真的很容易!导入包裹并按照以下步骤操作开始的步骤! 1. 拖拽“EnviroSky”预制件(“environme…...

1 JVM JDK JRE之间的区别以及使用字节码的好处
JDK jdk是编译java源文件成class文件的,我们使用javac命令把java源文件编译成class文件。 我们在java安装的目录下找到bin文件夹,如下图所示: 遵循着编译原理,把java源文件编译成JVM可识别的机器码。 其中还包括jar打包工具等。主要是针对…...

【网络安全】网站常见安全漏洞—服务端漏洞介绍
文章目录 网站常见安全漏洞—服务端漏洞介绍引言1. 第三方组件漏洞什么是第三方组件漏洞?如何防范? 2. SQL 注入什么是SQL注入?如何防范? 3. 命令执行漏洞什么是命令执行漏洞?如何防范? 4. 越权漏洞什么是越…...

MAPTR:在线矢量化高精地图构建的结构化建模与学习(2208)
MAPTR: STRUCTURED MODELING AND LEARNING FOR ONLINE VECTORIZED HD MAP CONSTRUCTION MAPTR:在线矢量化高精地图构建的结构化建模与学习 ABSTRACT High-definition (HD) map provides abundant and precise environmental information of the driving scene, se…...

基于容器的云原生,让业务更自由地翱翔云端
无论是要构建一个应用或开发一个更庞大的解决方案,在技术选型时,技术的开放性和可移植性已经成为很多企业优先考虑的问题之一。毕竟没人希望自己未来的发展方向和成长速度被自己若干年前选择使用的某项技术所限制或拖累。 那么当你的业务已经上云&#x…...

大屏开源项目go-view二次开发2----半环形控件(C#)
环境搭建参考: 大屏开源项目go-view二次开发1----环境搭建(C#)-CSDN博客 要做的半环形控件最终效果如下图: 步骤如下: 1 在go-view前端项目的\src\packages\components\Charts目录下新增Others目录,并在Others目录下新增PieExt…...

web:pc端企业微信登录-vue版
官方文档:developer.work.weixin.qq.com/document/pa… 不需要调用ww.register,直接调用ww.createWWLoginPanel即可创建企业微信登录面板 - 文档 - 企业微信开发者中心 (qq.com) 引入 //通过 npm 引入 npm install wecom/jssdk import * as ww from we…...

OpenGL ES 01 渲染一个四边形
项目架构 着色器封装 vertex #version 300 es // 接收顶点数据 layout (location 0) in vec3 aPos; // 位置变量的属性位置值为0 layout (location 1) in vec4 aColors; // 位置变量的属性位置值为1 out vec4 vertexColor; // 为片段着色器指定一个颜色输出void main() {gl…...

【ETCD】【源码阅读】深入解析 EtcdServer.applyEntries方法
applyEntries方法的主要作用是接收待应用的 Raft 日志条目,并按顺序将其应用到系统中;确保条目的索引连续,避免丢失或重复应用条目。 一、函数完整代码 func (s *EtcdServer) applyEntries(ep *etcdProgress, apply *apply) {if len(apply.…...

对比直接使用厂商 API 体验 Taotoken 在路由容灾上的价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在路由容灾上的价值 在开发依赖大模型能力的应用时,服务的连续性与稳定性是保障用…...

【低功耗蓝牙】④ 蓝牙MIDI协议:从ESP32 MicroPython代码到智能乐器DIY
1. 蓝牙MIDI协议入门:从音乐小白到智能乐器开发者 第一次听说蓝牙MIDI协议时,我正盯着桌上的ESP32开发板发呆。作为一个只会弹几个和弦的编程爱好者,完全没想到自己能用代码"演奏"音乐。蓝牙MIDI就像音乐世界的通用语言,…...

NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南
NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾为游戏卡顿而烦恼?是否觉得显卡性能总差那么一点&#x…...

ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案
ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的情况ÿ…...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞!
Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统…...

构建高可用AI模型代理服务:统一接口、智能路由与生产级部署
1. 项目概述:一个无处不在的AI助手接口最近在折腾AI应用开发的朋友,可能都遇到过这样一个痛点:想在自己的项目里快速接入一个靠谱的、能处理复杂对话的AI模型,但要么被OpenAI的API调用限制和网络问题搞得焦头烂额,要么…...

AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程
AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and addi…...

Oracle数据库触发器概述
Oracle数据库触发器概述触发器介绍数据库触发器是一个 已编译的存储程序单元 ,使用 PL/SQL 或 Java 编写。 触发器是模式对象,类似于子程序;但其调用方法不同。 子程序由用户、应用程序、或触发器显式运行。而触发器是在触发的事件发生时由 数…...

30亿条出行记录解密:如何用纽约出租车数据洞察城市脉搏 [特殊字符][特殊字符]
30亿条出行记录解密:如何用纽约出租车数据洞察城市脉搏 🚖📊 【免费下载链接】nyc-taxi-data Import public NYC taxi and for-hire vehicle (Uber, Lyft) trip data into a PostgreSQL or ClickHouse database 项目地址: https://gitcode.…...