第十五章 Linux Shell 编程
15.1 Shell 变量
-
了解:Shell的功能
-
了解:Shell的种类
-
了解:Shell的调用
-
了解:Shell变量的概念
-
了解:Shell变量的定义
-
了解:Shell数组变量
-
了解:Shell内置变量
-
了解:双引号 和 单引号
-
了解:Shell变量作用域
15.1.1 shell的概念
Shell 的英文含义是<外壳>
Shell 是<命令解释器程序>的统称,专门用于对<用户命令>进行解释,从而让内核可以理解并执行,因此 Shell就是<用户>与<内核>交互的<桥梁>
Shell 功能如下:
● 接收 用户命令
● 调用 相应的应用程序
● 解释并交给 内核去处理
● 返还 内核处理结果
人机交互程序,命令解释器,翻译官,让内核理解我们输入的命令

15.1.2 shell 的种类
Shell 的种类有多种:
MS-DOS(本身就是一个Shell)
Windows的Shell:Windows Explorer(图形化)、cmd(命令行)
UNIX的Shell:sh、bash、csh、ksh等等(平时我们所说的Shell,多指UNIX的Shell)
sh程序:
<sh程序>是shell的一种,它遵循<Unix POSIX 标准>,从而具备<UNIX可移植性>。
<sh程序>是<其他 UNIX Shell>的基础,各类<UNIX系统>均可很好的支持。大部分shell都是有sh 改进而来,最强的是/bin/bash也是默认的
bash程序:
<bash程序>是<sh程序>的增强版,也是<大多数Linux系统>的<默认Shell>。
15.1.3 shell 的调用
chsh -l ## 查看:系统可用的 Shell
echo $SHELL ## 查看默认的shell 也是放内嵌命令的地方 一般是 /bin/bash永久更改:用户的登录Shell
useradd user01
chsh -s /bin/sh user01 ## 永久更改user01用户的登录 Shell
cat /etc/passwd ## 查看更改结果 显示调用shell
bash -c date ## 显式调用bash,来执行date命令
sh -c date ## 显式调用sh,来执行date命令隐式调用shell 用的最多
date ## 隐式调用<用户默认的Shell>,来执行date命令
vi test.sh
#!/bin/bash ## 在Shell脚本中,申明本脚本所调用的Shell
date
15.1.4 Shell 变量赋值与引用
变量:就是一个<进程>中用于<存储数据>的<内存实体>,它对应着一个<内存存储空间>。
<变量名>只能包括:<字母>、<数字>和<_下划线>,并且,<变量名>不能以<数字>开头。
定义Shell变量
var01="123" ## 直接赋值
var02="${var01}456" ## 引用<其他变量值>来赋值
var03="`date` ## 引用<命令屏显输出>来赋值
echo "$var01" ## 显示<变量值> 123
echo "$var02" ## 显示<变量值> 123456
echo "$var03" ## 显示<变量值> 显示时间,注意显示的是定义变量的时间,而不是echo 这里的时间
15.1.5 Shell 数组变量
Shell 数组变量:就是一组同姓不同名的<变量集合>,彼此用<索引下标>加以区分。
Shell 数组变量:分为两类
第一类:普通数组,即:数字下标,有序数组 (最常用)
第二类:关联数组,即:命名下标,无序数组 (不常用)
定义:Shell数组变量(普通数组)
a=() ## 只定义不赋值
a=("a" "b" "c") ## 赋值需要空格隔开,下标从0开始
a=(
a
b
c
) ## 同上
a[0]="a"
a[1]="b"
a[5]="c" ## 赋值单个数组
引用:Shell数组变量(普通数组),里面的都是数组而不是单个变量
echo $a ## 读取第一个数组元素值,即下标0
echo ${a[n]} ## 读取下标n的数组元素值,n是数字
echo ${a[*]} ## 读取全部数组元素值
echo ${a[@]} ## 读取全部数组元素值 常用于循环脚本echo ${a[*]:n} ## 从下标n开始,读取后面全部数组元素值
echo ${a[*]:n:m} ## 从下标n开始,读取m个数组元素值
例如:
echo ${a[*]:0:3} ## 显示下标 0 1 2 的值
echo ${a[*]:1:3} ## 显示下标 1 2 3 的值
echo ${a[*]:2:4} ## 从下标2开始,读取4个数据的值,2 3 4 5 echo ${!a[*]} ## 列出所有元素的下标(因为定义数组时候可不一定按下标顺序来定义)
echo ${#a[*]} ## 显示数组有多少元素数量,相当于有多少下标 有10个元素则 输出10
echo ${#a[1]} ## 显示a[1]里面的值有多少位数,比如a[1]=100,则输出 3
echo ${#a[*]} ## 在判断某不确定命令有多少数组时,去抓取做循环很好
${a[@]} 使用例子,数组一个个打印出来
#!/bin/bash
Service="1,2,3,4,5"
# 使用逗号分割字符串为数组 赋值给service
IFS=',' read -r -a service <<< "$Service"# 将数组每个值赋值给 test
for test in "${service[@]}"; doecho "$test"
done
15.1.6 删除 shell 变量
语法:unset 变量名
比如 :unset a 删除a 或者 删除a数组
15.1.7 执行shell 脚本
共享<父进程>执行法:source test.sh 或者 . test.sh (可使用 export 刷新环境变量)
独立<子进程>执行法:bash test.sh 或者 sh test.sh
./test.sh(需要x权限) 或者 /root/test.sh(需要x权限)
置换<父进程>执行法:exec ./test.sh(需要x权限)或者 exec /root/test.sh(需要x权限)
15.1.8 shell 内置变量
(命令行参数)
Shell 内置变量:就是<Shell命令解释器程序>固有的<变量>,无需定义便可以直接引用。(系统自带变量)
常用的Shell内置变量:
$0 ## Shell脚本自身的<文件名>和<调用路径>
$1 -- $n ## Shell脚本的<命令行参数>,$1是第1参数、$2是第2参数,以此类推## 从${10}开始参数需要强制使用花括号{}括起来
$* $@ ## Shell脚本的<所有命令行参数>的<列表>## 如Shell脚本接收了$1 $2两个参数,则 $* 等于$1 $2
$# ## Shell脚本的<命令行参数>的<总个数>
$? ## 保存上一个命令的return状态返回值 0表示成功运行,1表示有问题
$! ## 保存的是最近一个后台进程的 PID (可存储pid遍历判断) <<命令 & pid=$!>>
$$ ## Shell脚本自身的<PID进程号>
例子:
vim test.sh
#!/bin/bash
echo "$* ## 表示这个程序的所有参数 "
echo "$# ## 表示这个程序的参数个数"
echo "$$ ## 表示程序的进程 ID "
echo "执行命令 ls & pid=\$!"
ls & pid=$! ## pid=$!这里 pid 是一个变量
echo "${pid} ## 这里的\${pid}则是\$!"
echo "$! ## 执行上一个后台指令的 PID"
echo "$? ## 表示上一个程序执行返回结果 "
echo -e "## 显示<本Shell脚本>=$0"
echo -e "## 格式输出:指定的<命令行参数>=$1\t$2\t$3"## \t 是正则表达式,表示水平制表符bash test.sh aa bb cc dd ee ## 执行脚本且写5个参数 终端如下显示
[root@dj tmp]# bash test.sh aa bb cc dd ee
aa bb cc dd ee ## 表示这个程序的所有参数
5 ## 表示这个程序的参数个数
1143 ## 表示程序的进程 ID
执行命令 ls & pid=$!
1144 ## 这里的${pid}则是$!
1144 ## 执行上一个后台指令的 PID
0 ## 表示上一个程序执行返回结果
## 显示<本Shell脚本>=test.sh
## 格式输出:指定的<命令行参数>=aa bb cc## 注意 aa bb cc dd ee 是新写的五个变量,可以用五个下标表示
$! 使用例子
检查k8s部署状态
export service=$(echo $service | base64 -d)
export Test_Version=$(echo $Test_Version | base64 -d)# 执行 kubectl rollout status 命令并等待100秒
kubectl rollout status deployment/${service}-rpc${Test_Version} -n go & pid=$!# 等待命令执行完毕或超时(100秒)
sleep 100# 检查命令执行状态
if kill -0 $pid > /dev/null 2>&1; thenecho "-------------部署未完成,超时打印日志-------------"# 获取部署的所有 Pod 名称pod_names=$(kubectl get pods -l app=${service}-rpc${Test_Version} -n go -o=jsonpath='{.items[*].metadata.name}')# 打印每个 Pod 的日志for pod in ${pod_names}; doecho "Logs for pod ${pod}:"kubectl logs ${pod} -n godoneexit 1
elseecho "部署成功"
fi
15.1.9 双引号 和 单引号
<""双引号> 是:<部分引用>,可以识别<特殊符号>
<''单引号> 是:<完全引用>,不能识别<特殊符号>
举例:
终端显示如下
[root@dj tmp]# a=abc
[root@dj tmp]# echo "${a}"
abc
[root@dj tmp]# echo '${a}' ## 单引号 不能识别特殊符号 比如 $ 符
${a}
[root@dj tmp]# echo ${a}
abc
15.1.10 `` 或 $() 命令替换
$() 或 `` 命令替换:将<字符串>中的<命令>,置换为<命令>的<屏显输出>
`` 命令替换 :是sh的语法,兼容性最高
$()命令置换 :是bash语法,sh不支持 所以一般使用 反引号 ``
a="ls -l"
echo $a 会输出 ls -la=`ls -l` 或者 a=$(ls -l)
echo $a 会输出 ls -l命令列出的内容
15.1.11 shell 变量作用域 export
Shell 变量作用域:指的是一个<Shell变量>的<有效范围>。
按<Shell 变量作用域>分类:
Shell 本地变量:仅在<本进程>中生效的<Shell变量>。
Shell 环境变量:仅在<本进程>中生效,又可被<子进程>继承并生效的<Shell变量>。
也就是说如果开两个远程连接,在第一个远程连接定义本地变量,另外一个远程连接用不了该本地变量,但是如果是环境变量,可以通过继承去使用该环境变量。
注意:<Shell 数组变量>不可定义为<Shell 环境变量>。
本地变量定义方法:
a=“123”
环境变量定义方法:
export a="123" ## 定义变量a为Shell 环境变量 一般使用这个declare -x b="456" ## 定义变量b为Shell 环境变量
例子证明
a=123 ## 定义本地变量
vim test.sh ## 写一个脚本证明## 脚本相当于一个子进程,因为脚本也可以使用另外一个远程连接来写#!/bin/bash
echo $a 在脚本里面运行bash test.sh
## 发现并无 123 输出
## 说明本地变量不能给子进程使用,只能给创建a的进程使用
export b=123 ## 定义环境变量
vim test.sh ## 写一个脚本证明## 脚本相当于一个子进程,因为脚本也可以使用另外一个远程连接来写#!/bin/bash
echo $b 在脚本里面运行bash test.sh 发现有123显示在终端上,说明环境变量可在脚本里面也可运行## 注意:因为前面用 a 设置本地变量,所以设置环境变量不能使用 a ,否则会出错,因为环境变量虽然会覆盖本地变量的a,但是其实在配置文件里面还会存在本地变量a为123
## 这时就会出现 在脚本里面运行的时候,会运行本地变量的 a 而不是环境变量的 a 从而导致一样没有123显示,这样就无法判断
Linux 系统中设置环境变量例子 .env文件
export LOCAL_DEBUG=0
export NACOS_HOST=120.79.2.53
export NACOS_PASSWD=nacos
export NACOS_USERNAME=nacos
export NACOS_NAMESPACEID=datahub
export NACOS_DATAID=BehaviorDataReceiver
export NACOS_LOGLEVEL=debug
export NACOS_GROUP=DEFAULT_GROUP
export NACOS_LOGDIR=nacos_log
export NACOS_CACHEDIR=nacos_cache
执行 source .env 加载该配置文件
注意:这是一个包含环境变量的配置文件,不是脚本
一般环境变量可以在运行应用程序时被读取,以便配置应用程序的行为或连接数据库、服务等
.env 也可以加载 也可以写在 k8s yaml 的env 里面,一般使用该配置文件用于快速测试能否连接
15.2 echo 标准错误输出 重定向符 管道符
15.2.1 echo 命令
功能:将<参数>写到<标准输出>。
语法:echo [-neE] [参数 …]
选项参数:
-n ## 不追加换行符 ☚ 默认情况下,两条命令结合起来会追加换行符
-e ## 启用:反斜杠转义
echo 支持的常用<反斜杠字符>如下:
\n ## 换行
\t ## 横向制表符
\r ## 用于表示回车符 一般用于循环覆盖前面的内容比如 echo -e "\r" 表示输出一个回车符
回车符会将光标移动到当前行的开头位置,使得后续输出会覆盖当前行的内容。这在一些需要实现文本动态更新或进度条效果的场景中特别有用。
比如 倒数计时
[root@server ~]# a=`df -h`
[root@server ~]# echo $a
文件系统 容量 已用 可用 已用% 挂载点 devtmpfs 475M 0 475M 0% /dev tmpfs 487M 0 487M 0% /dev/shm tmpfs 487M 7.7M 479M 2% /run tmpfs 487M 0 487M 0% /sys/fs/cgroup /dev/mapper/centos-root 18G 1.5G 17G 9% / /dev/sda2 1014M 138M 877M 14% /boot tmpfs 98M 0 98M 0% /run/user/0[root@server ~]# echo "$a" ## 加上双引号
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 475M 0 475M 0% /dev
tmpfs 487M 0 487M 0% /dev/shm
tmpfs 487M 7.7M 479M 2% /run
tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root 18G 1.5G 17G 9% /
/dev/sda2 1014M 138M 877M 14% /boot
tmpfs 98M 0 98M 0% /run/user/0## 侧面说明了在赋予变量的时候,还是按照命令的格式,而不是变成空格一行输出,变成一行是echo的原因
-n选项:
[root@dj ~]# echo "1"; echo "2"; echo "3" ## 会换行
1
2
3
[root@dj ~]# echo -n "1"; echo -n "2"; echo "3"
123与之相似还有 命令|tr -d 还有 命令| sed ':y;N;s/\n//g;b y'
比如 echo `ifconfig`
-e 和 \t 选项
[root@dj tmp]# echo "123\t456\n789"
123\t456\n789
[root@dj tmp]# echo -e "123\t456\n789"
123 456
789[root@dj ~]# echo -e "1\t2\t3"
1 2 3
[root@dj ~]# echo -e 1\t2\t3
1t2t3 ## 注意:不加双引号不行,-e 不起作用
echo 1.txt | rm -rf ## 这样不行,因为echo只是输出给 rm 接收,它不一定会接收## 不行就添加 xargs
倒计时覆盖
#!/bin/bash
for i in {5..1}
do echo -n "还有$i秒,幸运儿究竟是谁" ## 不换行输出echo -ne "\r\r" ## 覆盖输出 不加的话会显示全部 一个\r就可以sleep 1 ## 不加的话运行会显示[root@dj tmp]# 究竟是谁,(还有$i秒) 被覆盖了
done
15.2.2 标准输入 标准输出 标准错误输出
标准输入:就是通过<I/O字符终端设备,如:键盘)输入的<信息>。(输入是没错的) (0 表示)
标准输出:命令执行成功之后,在屏幕上输出的<命令结果显示信息>。(1 表示)
标准错误输出:命令执行失败之后,在屏幕上输出的<命令错误提示信息>。(2 表示)
(& 表示全部,无论正确还是错误信息)
ls 1>> 1.txt ## 把ls 展现的正确输出结果 追加到 1.txt
sksoefsl 2>> 1.txt ## 把展示出来的错误信息 追加到 1.txt
ls &>> 1.txt ## 无论是正确还是错误的,该命令的输出全部追加到 1.txt
对于不需要的信息,我们可以写入 黑洞 ,不占内存,黑洞路径是 /dev/null ,比如
yum -y install tree &> /dev/null
echo $? ## 查看上条命令成功与否,0为成功,1为失败
省略不写相当于是标准输出1
常用于丢弃输出,然后自定义显示
命令 > /dev/null 2>&1
ls -waadaw > /dev/null 2>&1 ## 标准输出1重定向到/dev/null## 标准错误输出2重定向到标准输出1
或
ls -waadaw &> /dev/null ## 将标准输出和标准错误都重定向到/dev/null
15.2.3 >、>> 标准错误输出重定向
重定向:改变<命令>的<标准输出/标准错误输出>的<输出方向>,不输出到<屏幕>,而是输出到<文件>。
★ > 重定向符:覆盖式重定向
★ >> 重定向符:追加式重定向
<标准输出>重定向,主要用于保存<命令执行成功的结果信息>,便于后期引用。
echo "123" > 1.txt ## 覆盖式重定向
echo "456" >> 1.txt ## 追加式重定向
<标准错误输出>重定向,主要用于保存<命令执行失败的错误信息>,便于查阅分析
yum instll wget -y 2> 1.txt ## 覆盖式重定向
yum updata -y 2>> 1.txt ## 追加式重定向
<标准输出/标准错误输出>重定向,静默执行命令 不输出内容
yum update -y &> /dev/null ## 方法1:&代表<标准输出/标准错误输出>
yum update -y 1> /dev/null 2>&1 ## 方法2:2代表标准错误输出;1代表标准输出## 2给1,1给/dev/null,这个世界就安静了
15.2.4 <、<< 标准重定向输出
★ < 输入重定向:从<指定文件>中,读取数据,输入到<指定文件>中
★ << 输入重定向:从<标准输入>中,读取数据,输入到<指定文件>或<指定命令>中
< 输入重定向例子:
覆盖式输入
echo "aaa" > 1.txt
cat > 3.txt < 1.txt ## 将1.txt里面的内容写进3.txt并覆盖
追加式输入
cat >> 3.txt < 1.txt
<< 输入重定向例子
cat <<
EOF
This is a test.
Hello, world!
EOF## 会直接在终端输出
This is a test.
Hello, world!
将111222追加到 3.txt
cat << EOF >> 3.txt
111222
EOF
15.2.5 | 管道符
管道符:像流水线一样,将一个<命令>的<标准输出>,作为另一个<命令>的<标准输入>。
echo "1.txt" | touch - ## 创建 1.txt文件 不一定成功
echo "1.txt" | xargs touch ## 创建 1.txt
15.2.6 生成随机数 $RANDOM
使用 R A N D O M 变量: RANDOM变量: RANDOM变量:RANDOM 是一个环境变量,它可以在每次被调用时生成一个 0 到 32767(2^15-1)之间的随机整数。可以通过以下脚本来生成一个随机数:
最简单命令:echo $RANDOM
原理:
#!/bin/bash
random_number=$RANDOM
echo "随机数:$random_number"
##随机数 生成 0 到 32767 的某一个数
例子1:随机生成 0 到 2的随机数
#!/bin/bash
echo $[RANDOM%3]
相当于对 3 取余,只有 0 1 2 产生
##运行脚本 生成 0 1 2 三个随机数,可拿来做数组下标,做一个随机生成名字喊人回答问题的代码
随机字符 /dev/urandom 生成随机字符
[root@dj tmp]# cat /dev/urandom |tr -dc [:alnum:] |head -c 8nRSCSps2
[root@dj tmp]# cat /dev/urandom |tr -dc [:alnum:] |head -c 8
yCGqVAzq[root@dj tmp]#
例子2 随机生成石头剪刀布,赢了退出,输了继续比
思想:做一个死循环,如果满足条件就 break 退出该循环,while true 也可以
[root@dj tmp]# cat 2.sh
#!/bin/bash
echo "我们一起来玩石头剪刀布吧"
xt=1
while (($xt<3))
doxt=$[RANDOM%3]read -e -p "请输入您的选择(0:石头 1:剪刀 2:布):" aif [[ $a == 0 ]]thenecho "您出的是石头"if (($xt==1))thenecho "我出的是剪刀,恭喜宁赢了,欢迎下次再来pk"breakelif (($xt==0))thenecho "不好意思我出的也是石头,平局喔,请继续"elseecho "不好意思我出的是布,您输了,请继续"fielif [[ $a == 1 ]]thenecho "您出的是剪刀"if (($xt==2))thenecho "我出的是布,恭喜宁赢了,欢迎下次再来pk"breakelif (($xt==1))thenecho "不好意思我出的也是剪刀,平局喔,请继续"elseecho "不好意思我出的是石头,您输了,请继续"fielif [[ $a == 2 ]]thenecho "您出的是布"if (($xt==0))thenecho "我出的是石头,恭喜宁赢了,欢迎下次再来pk"breakelif (($xt==2))thenecho "不好意思我出的也是布,平局喔,请继续"elseecho "不好意思我出的是石头,您输了,请继续"fielseecho "输入错误,请重新输入"fi
done
##注意:输入那里的 if 判断必须使用 [[ ]] ,如果是 (( )),如果输入大于3的数字会正常,但是输入字母会默认成石头
例子3 随机点名
#!/bin/bash
for i in {2..1}
doecho -n 还有$i秒,幸运儿究竟是谁 !!echo -ne "\r\r" sleep 1
doneecho " "clearname=(`cat /root/name.txt`)name_list=${#name[*]} ## 数组有多少元素赋值给它,假如有5个元素则为5name_index=$[RANDOM%$name_list]echo -n "${name[$name_index]}" ## 根据下标找人echo ""## 注意:name.txt 里面放的是名单 一行一个名字,还有 name_list 是里面存放是数字,而不是名字
## xt=$[RANDOM%3]可以换成 ((xt=RANDOM%3)) 或者 let "xt=RANDOM%3"
例子4 猜1到1000的随机数
#!/bin/bash
target=$[$RANDOM%1000+1]while true
doread -p "请输入一个数字(1到1000): " n# 检查输入是否为整数if ! [[ $n =~ ^[0-9]+$ ]]; thenecho "请输入有效的数字!"continuefi# 判断猜测结果if [ $guess -eq $n ]; thenecho "恭喜你,猜对了!"breakelif [ $guess -lt $n ]; thenecho "猜的数字太小了,请继续猜!"elseecho "猜的数字太大了,请继续猜!"fidone
15.3 通配符、正则、grep
15.3.1 通配符
通配符:是Shell自身的一种特殊语句,实现<路径名展开 pathname expansion>展开功能。
用于:模糊搜索<文件>。
* ## 表示0或多个的<任意字符> (相当于正则里面 .*)
? ## 表示单个<任意字符> (相当于正则 .)
[ ] ## 表示匹配<字符列表或范围>中的<单个字符>(和正则里面一样)
[xyz] ## 设置可选的<字符列表>
[x-y] ## 设置可选的<字符范围>
[^xyz] ## 表示不选择x、y、z;
^ ## 表示不匹配,^ 必须是第一个字符
举例:
cd /tmp; rm -rf *; mkdir dir1 dir2 dir3; touch file1 file2 file3
## 通过<路径名展开 pathname expansion>的<通配符>来列出<目录或文件>ls -l -d dir[1-3]
ls -l file[1-3]rm -rf ??? ## 删除当前目录下所有的任意3个字符命名的文件
15.3.2 正则表达式
1 正则表达式(Regular Expression)的概念
正则表达式:描述了<目标字符串>的<匹配模式(pattern)>。
注意:<正则表达式>和<Shell 通配符>不是一回事!
生活比喻:
我们要在一群人中找一个人,但是我只知道他是湖北武汉人,姓催,因此我们只能这样说:“那个"姓催的武汉人”,请出来,我们有事找你"。在这段话中,"姓催的武汉人"就是一个生活中的<正则表达式>。
2 正则表达式的种类
基本正则:是<标准的元字符集>,是其他<正则>的<子集>。
扩展正则:是<扩展的元字符集>,包含着<标准元字符+扩展元字符>。 -E
Perl正则 -P
3 认识:正则元字符
| 元字符 | 基本 | 扩展 | 功能说明 |
|---|---|---|---|
| ^ | ✔ | ✔ | 匹配:行首 ^s 以s开头 |
| $ | ✔ | ✔ | 匹配:行尾 s$ 以s结尾 |
| . | ✔ | ✔ | 匹配:任意单个字符 |
| ? | ✘ | ✔ | 匹配:<前一项>出现<0次或1次> |
| + | ✘ | ✔ | 匹配:<前一项>出现<1次或多次> |
| * | ✔ | ✔ | 匹配:<前一项>出现<0次或多次> .* 代表0个或多个任意单个字符 |
| [ ] | ✔ | ✔ | 匹配:<字符列表>中的<任意一个字符> 注意:在 [ ] 中,字符中间的 - 有着<特殊含义> [-] 匹配:<字符范围>中的<任意一个字符> [-] 匹配:依照<字典顺序>到达<指定字符>截止的<所有字符> [^] 匹配:<字符集合>外的<任意一个字符> 在 [ ] 中,开头第一个 ^ 有着<特殊含义> 在 [ ] 中,<其余字符>均为<原义字符> |
| ( ) | ✘ | ✔ | 定义:<正则分组> |
| | | ✘ | ✔ | 设置:逻辑或 |
| { } | ✘ | ✔ | {n} 匹配:<前一项>出现<n次>,n可以设为0 {n,} 匹配:<前一项>最少出现<n次>,n可以设为0 {,m} 匹配:<前一项>最多出现<m次> {n,m} 匹配:<前一项>最少出现<n次>,最多出现<m次> |
| < | ✔ | ✔ | 匹配:<单词>的<左边界字符> |
| > | ✔ | ✔ | 匹配:<单词>的<右边界字符> |
| \b | ✔ | ✔ | 匹配:<单词>的<左边界字符>或<右边界字符> |
| \B | ✔ | ✔ | 匹配:<单词>的<非左边界字符>或<非右边界字符> |
| \d | ✘ | ✘ | 匹配:单个<数字字符> ☚ 仅属于:<perl 正则元字符集> |
| \D | ✘ | ✘ | 匹配:单个<非数字字符> ☚ 仅属于:<perl 正则元字符集> |
| \w | ✔ | ✔ | 匹配:单个<单词的字符>,如:字母、数字、_下划线 |
| \W | ✔ | ✔ | 匹配:单个<非单词的字符> |
| \s | ✔ | ✔ | 匹配:单个<空白字符>,包含:水平/垂直制表符 |
| \S | ✔ | ✔ | 匹配:单个<非空白字符> |
| \t | ✘ | ✘ | 匹配:水平制表符 ☚ 仅属于:<perl 正则元字符集> |
| \v | ✘ | ✘ | 匹配:垂直制表符 ☚ 仅属于:<perl 正则元字符集> |
| \f | ✘ | ✘ | 匹配:换页符 ☚ 仅属于:<perl 正则元字符集> |
4 认识:转义符 \
转义符:恢复<元字符>的<原义>,还原为<本义字符>。
举例说明:
^ ## 匹配行首,比如 s^ 是匹配 s
\^ ## 表示这是一个 ^本义字符,它不再是 ^元字符,而是^本身意思$ ## 匹配行尾,比如 s 是匹配 s
\$ ## 表示:这是一个 $本义字符,它不再是 $元字符。
15.3.3 grep命令
grep命令的功能: 三剑客 (grep sed awk ,其中 tr 称为 小sed,cut称为小awk)
注意:grep只能列出文件想要看的精准内容,不能用grep修改
逐行扫描<文本文件>或者<标准输出/标准错误输出>的<每一行>。
通过<关键字>和<正则表达式>,来筛选出<匹配的行>,然后标准输出<匹配的整行>。
注意:通过匹配行内的某些特征去匹配那一行,使用 -o 则只输出匹配的字符
语法:grep [选项] <关键字 和 正则表达式> [文件名 | -]
文件名 指定需要读取的<文件名>
表示准备接收<标准输入> 具备这功能的命令,可以接收 | 管道符
选项:建议无脑开启扩展正则
-E ## 采用:扩展正则 egrep 相当于 grep -E
-P ## 采用:Perl正则
-i ## 忽略:大小写
-o ## 仅输出:匹配的<字符串> 不写都是输出满足匹配的行
-c ## 统计:匹配的行数 ☚ 注意:不是输出的行数 有多少行输出多少几 可拿来统计个数
-v ## 输出:不匹配的<行>
-l ## 列出:包含<匹配字符串>的<文件名>
-L ## 列出:不包含<匹配字符串>的<文件名>
-r ## 执行:目录递归操作 ☚ 仅与 -l 或 -L 配合使用
-w ## 选项表示只匹配整个单词,而不是部分匹配
--exclude=FILE_PATTERN ## 排除:指定的文件名,仅可使用<通配符>
--exclude-dir=PATTERN ## 排除:指定的目录名,仅可使用<通配符>
-c 例子 更多使用 wc -l
[root@dj exports.d]# grep -c '' /tmp/passwd 有49行
49
例子:查看文件,去除注释和空行 扩展正则
egrep -v "^\s*(#|$)" /etc/passwd ## 以 0个或多个 空格 开头,然后接 # 号 或者 直接结尾
-w 例子
netstat -tunlp | grep -w "22"## 会匹配 22 的内容,但是 222,223 122 这种不会被匹配
-o 例子 过滤数字和字母
egrep -o '[0-9]+'
egrep -o '[a-zA-Z]+'
15.4 各种常用辅助命令
15.4.1 sort、uniq、wc 命令
sort 命令:排序
☛ 命令选项说明
-g ## 按<一般数值>排序
-n ## 按<字符串数值>排序
-r ## 逆序排序(默认升序) -gr 就是按数字降序排序 重要
-f ## 忽略<字母大小写>
-b ## 忽略<前导的空白区域>
-k ## 按照指定字段进行排序 sort -k 2 file.txt 按第二字段进行排序
-o ## 将<排序结果>回写入<原文件>,例如:cat 1.txt
★ uniq 命令:分组汇总
有相同的行就去重。
-c ## 去重的同时统计出现多少次
uniq -c ## 常用于查找ip访问最多
★ wc 命令:统计
☛ 命令选项说明
不加选项,分别表示行数、单词数量和字节数 比如 wc /etc/passwd
-l ## 统计:行数
-W ## 统计:单词数
-c ## 统计:字节数
-m ## 统计:字符数
-L ## 显示:最长行的长度
一般组合使用是 找相同 排序 去重 在排序
统计并显示次数出现前十的ip access_log 是文件名
[root@dj ~]# cat access_log | awk '{print $1}'| sort -r | uniq -c | sort -gr | head -101055 192.168.1.25509 192.168.1.14360 192.168.1.37303 192.168.1.12262 192.168.1.41254 192.168.1.21242 192.168.1.8234 192.168.1.5203 192.168.1.31195 192.168.1.30netstat -anlp|grep 80|grep tcp|awk ‘{print $5}’|awk -F: ‘{print $1}’|sort|uniq -c|sort -nr|head -n20
三个一起使用能发挥重大作用,一个排序 一个去重 一个分组
例子:
lastb | sort -k 3 -k 1 | uniq -c | sort -k 1 ## 统计显示:<lastb命令>查看到的登录失败信息ss -tan |sort | uniq -c ## 统计显示网络连接信息
cat /etc/passwd | wc -l ## 统计显示/etc/passwd 文件的行数
cat /etc/passwd | wc -m ## 统计显示/etc/passwd 文件的字符数
统计显示:网络连接信息:没排序和 排序和排序去重的区别对比
[root@dj ~]# ss -tan
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 5 192.168.122.1:53 *:*
LISTEN 0 128 *:22 *:*
LISTEN 0 128 127.0.0.1:631 *:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 128 *:111 *:*
ESTAB 0 0 192.168.58.150:22 192.168.58.1:50395
ESTAB 0 0 192.168.58.150:22 192.168.58.1:50298
ESTAB 0 0 192.168.58.150:22 192.168.58.1:50288
ESTAB 0 0 192.168.58.100:22 192.168.58.1:51760
ESTAB 0 0 192.168.58.150:22 192.168.58.1:50394
ESTAB 0 0 192.168.58.100:22 192.168.58.1:51684
ESTAB 0 0 192.168.58.100:22 192.168.58.1:51761
LISTEN 0 128 [::]:22 [::]:*
LISTEN 0 128 [::1]:631 [::]:*
LISTEN 0 100 [::1]:25 [::]:*
LISTEN 0 128 [::]:111 [::]:* [root@dj ~]# ss -tan |sort (排序后)
ESTAB 0 0 192.168.58.100:22 192.168.58.1:51684
ESTAB 0 0 192.168.58.100:22 192.168.58.1:51760
ESTAB 0 0 192.168.58.100:22 192.168.58.1:51761
ESTAB 0 0 192.168.58.150:22 192.168.58.1:50288
ESTAB 0 0 192.168.58.150:22 192.168.58.1:50298
ESTAB 0 0 192.168.58.150:22 192.168.58.1:50395
ESTAB 0 36 192.168.58.150:22 192.168.58.1:50394
LISTEN 0 100 [::1]:25 [::]:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 128 *:111 *:*
LISTEN 0 128 [::]:111 [::]:*
LISTEN 0 128 127.0.0.1:631 *:*
LISTEN 0 128 [::1]:631 [::]:*
LISTEN 0 128 *:22 *:*
LISTEN 0 128 [::]:22 [::]:*
LISTEN 0 5 192.168.122.1:53 *:*
State Recv-Q Send-Q Local Address:Port Peer Address:Port [root@dj ~]# ss -tan |sort | uniq -c (去重后)1 ESTAB 0 0 192.168.58.100:22 192.168.58.1:51684 1 ESTAB 0 0 192.168.58.100:22 192.168.58.1:51760 1 ESTAB 0 0 192.168.58.100:22 192.168.58.1:51761 1 ESTAB 0 0 192.168.58.150:22 192.168.58.1:50288 1 ESTAB 0 0 192.168.58.150:22 192.168.58.1:50298 1 ESTAB 0 0 192.168.58.150:22 192.168.58.1:50395 1 ESTAB 0 36 192.168.58.150:22 192.168.58.1:50394 1 LISTEN 0 100 [::1]:25 [::]:* 1 LISTEN 0 100 127.0.0.1:25 *:* 1 LISTEN 0 128 *:111 *:* 1 LISTEN 0 128 [::]:111 [::]:* 1 LISTEN 0 128 127.0.0.1:631 *:* 1 LISTEN 0 128 [::1]:631 [::]:* 1 LISTEN 0 128 *:22 *:* 1 LISTEN 0 128 [::]:22 [::]:* 1 LISTEN 0 5 192.168.122.1:53 *:* 1 State Recv-Q Send-Q Local Address:Port Peer Address:Port
15.4.2 cut、tr 命令
cut 命令 小awk
功能:将<每个文件>中<每一行>的<匹配部分>打印到<标准输出>。
语法:cut OPTION… [FILE]…
注意:字符是一个整体,一个字符可能占一个字节,也可能占几个字节。a是字符也是字节
汉字是字符,但一个汉字不止占一个字节
编码utf -8 的情况下,一个汉字占3个字节
常用选项:
-b, --bytes=LIST ## 按<字节>进行选择,不承认<分隔符>
-n ## 和 -b选项 一起使用:不分割<多字节字符>,如:汉字
-c, --characters=LIST ## 按<字符>进行选择,不承认<分隔符>
-f, --fields=LIST ## 按<字段>进行选择,承认<分隔符>,以<分隔符>区分<字段>## 除非指定了-s选项,否则,还会打印任何不包含<分隔符>的<行>
-s, --only-delimited ## 不打印没有包含<分界符>的<行>
-d, --delimiter=DELIM ## 设置单个<自定义分隔符>,需使用<单引号 或 双引号>## 默认为Tab制表符## 连续多个<分隔符>,只有第1个有效,剩余的视为<普通字符>## 只能和 -f选项 一起使用--complement ## 补全选中的<字节、字符、字段>
--output-delimiter=TRING ## 使用指定的字符串作为输出分界符,默认采用输入的分界符## 针对 -b,-c,-f 这三个选项,只能使用其中的一个
## <输入顺序>将作为<读取顺序>,<每行字符串>仅能输入一次
## 每一个<LIST列表>,都是一个<范围值>,可以使用<,逗号>来分隔<多个范围值>
## <范围值>的格式如下:N ## 仅仅<第N个>的<字节、字符、域>
N- ## 从<第N个>到<行尾>之间(包括<第N个>)的所有<字节、字符、字段>
N-M ## 从<第N个>到<第M个>之间(包括<第M个>)的所有<字节、字符、字段>
-M ## 从<第1个>开始到<第M个>之间(包括<第M个>)的所有<字节、字符、字段>
N1,N2,N3,N-,N-M,-M ... ## 可以使用<,逗号>来分隔<多个范围值>
如果没有<文件参数>,或者<文件>不存在时,则从<标准输入>读取
这说明:cut 命令 可以接收 | 管道符
测试:按<字节>进行选择,不承认<分隔符>
echo -e "123456789\nabcdefghi\nABCDEFGHI" > /tmp/1.txt
cut -b 5 /tmp/1.txt ## 只输出每一行的<第5个字节>
cut -b 2-5 /tmp/1.txt ## 输出从<第2个字节>到<第5个字节>之间的内容
cut -b 5- /tmp/1.txt ## 输出从<第5个字节>到<行尾>之间的内容
cut -b -5 /tmp/1.txt ## 输出从<第1个字节>到<第5个字节>之间的内容
cut -f 1 -d ":" passwd ## 输出每行的第一个字段
2 tr 命令 小sed
功能:从<标准输入>中替换、缩减、删除<字符>,并将<结果>写到<标准输出>。
特点:是针对<单个字符>在<SET1字符集>中进行<匹配操作>,然后通过<SET2字符集>进行<位置映射>的<替换操作>,
而不是针对<整个字符串>进行<相关操作>。
语法:tr [选项]… SET1 [SET2]
常用选项:
-c, -C, --complement ## 取代所有不属于<SET1字符集>的字符
-d, --delete ## 删除所有属于<SET1字符集>的字符 tr -d 任何内容转为一行输出
-s, --squeeze-repeats ## 去重把<连续重复的字符>以<单独一个字符>表示
-t, --truncate-set1 ## 参照<SET2字符集>的个数,先截短<SET1字符集>,然后执行<替换操作>
--help ## 显示此帮助信息并退出
--version ## 显示版本信息并退出
<SET1字符集>:指定要替换或删除的<原字符集>,一旦匹配了<原字符集>,则对<该字符>予以<相关处理>,否则,
就予以保留。
当执行替换操作时,必须使用参数<SET2字符集>指定替换的<目标字符集>。
但执行删除操作时,不需要参数<SET2字符集>。
<SET2字符集>:指定要替换成的<目标字符集>
<SET1字符集>和<SET2字符集>都是一组<字符串>,一般都可按照字面含义理解。
基本原理图:
echo "0123456789" | tr "9876543210" "12345" ## 输出结果:5555554321

如果第二行没有第一行的内容,直接不变写入,
如果第二行存在第一行的内容,相当于把第二行的内容替换成第三行的
如果有第二行但是第三行没有替换对应的,则替换成第三行最后一个字符
语法练习
echo -e "112233445566778899\nabcdefghiABC\nABCDEFGHIabc" > /tmp/1.txt
cat /tmp/1.txt | tr "a-c" "A-C" ## 针对每一行,将<a,b,c>替换为<A,B,C>,然后执行<标准输出>
cat /tmp/1.txt | tr "0-9" "1" ## 针对每一行,将<所有数字>替换为<1>,然后执行<标准输出>
cat /tmp/1.txt | tr "a-zA-Z" "9" ## 针对每一行,将<所有字母>替换为<9>,然后执行<标准输出>
cat /tmp/1.txt | tr -d "a-zA-Z" ## 针对每一行,将<所有字母>删除,然后执行<标准输出>
cat /tmp/1.txt | tr -s "0-9" ## 针对每一行,去除所有重复的<数字>,然后执行<标准输出>
cat /tmp/1.txt | tr -t "abc" "12" ## 针对每一行,参照<SET2字符集>的个数,先截短<SET1字符集>,然后执行<替换操作>## 即:SET1=abc,SET=12(长度为2个字符),因此,只将<a,b>替换<1,2>
cat /tmp/1.txt | tr -c -d 1-4,'\n',a-b ## 针对<每一行>,删除不是<1,2,3,4,a,b,\n换行符>的<其他字符># 大小写转换
echo "ABCDEFGHIJKLMNOPQRSTUVWXYZ" | tr "A-Z" "a-z"
# 加密解密
echo "123456" | tr "0123456789" "987654321" ## 加密,加密输出结果为:876543
echo "876543" | tr "987654321" "0123456789" ## 解密,解密输出结果为:123456
15.4.3 read 命令脚本常用
功能:接收<键盘输入>,并保存到<指定的变量>中,即作用于输入变量定义,类似于c语言的scan,c ++ 的cin
注意:read命令不能在<while read 循环语句>中使用
选项:
-i "string" ## 缓冲区文字,用于设置<默认输入值>
-e ## 交互式输入,允许<backspace键>回退
-p "string" ## 设置<提示输入的说明文字> 必有 ep 一般一起使用
-s ## 不显示<输入内容,包括:换行符>(常用于输入密码) 可以设置密码
-a array_name ## 将<word单词>赋值给<array_name数组变量>,<数组下标>从 0 开始 一般和 for循环使用,和-ep 混用要注意
-r ## 不允许<反斜杠>转义<任何字符>
例子
-i
read -i "/usr/local/nginx" -ep "请您输入 nginx 的安装目录(例如 /usr/local/nginx):" a
## 会显示 请您输入 nginx 的安装目录(例如 /usr/local/nginx):/usr/local/nginx
vim 1.sh
#!/bin/bash
read -p "请输入您要创建的文件名:" g
touch $g#!/bin/bash
read -e "txt" -p "请输入您要创建的文件名:" g ## 输错时候,允许回退 -e
touch $g#!/bin/bash
read -e -i "txt" -p "请输入您要创建的文件名:" g ## 必须输入有txt的才可以 -i
touch $g## 将输入的<参会的人员名单列表>依次保存在<dj 数组变量>中
read -e -a dj -p "请输入<参会的人员名单列表>:"
echo ${dj[*]}
read -a例子
vim 1.sh
#!/bin/bash# 提示用户输入一行以空格分隔的字符串
echo "请输入一行以空格分隔的字符串:"
read -a array# 打印数组的每个元素
echo "数组的元素如下:"
for element in "${array[*]}"
doecho "$element"
donebash 1.sh aa bb cc 会打印 aa bb cc 一行打印一个
#!/bin/bash
echo "您可以一次创建一个或多个目录,用空格隔开"
read -ep "创建的共享目录名是(如test1):" -a gx
for i in ${gx[*]}
domkdir -p /$i
done随便输入创建 1个 或 多个目录
以 , 分隔例子
#!/bin/bashdir_paths="/,/go-data,/alidata,/k8s-alidata" # 字符串IFS=',' read -r -a dir_array <<< "$dir_paths"# 遍历每个目录for dir_path in "${dir_array[@]}"; doecho $dir_path# 使用 df 命令获取磁盘使用率,并提取使用率百分比# df_used=$(df -h "$dir_path" | awk 'NR==2 {print $5}' | sed 's/%//')# echo "$dir_path: $df_used%"done
15.4.4 sleep wait 命令
1 sleep 命令 & 把要运行的内容脚本等等 甩后台运行
功能:暂停一段时间,时间单位可以是 s m h d,默认是 s(秒)
举例:
sleep 10s ## 暂停 10 秒,直接作用不了
sleep 10s & ## 在后台暂停 10 秒
2 wait 命令
功能:
wait命令 是用来阻塞<当前进程>的执行,直至<当前进程的指定子进程>或者<当前进程的所有子进程>返回状态为0,执行结束之后,方才继续执行。
使用 wait命令 可以在<bash脚本>的<多进程>执行模式下,起到一些<特殊控制>的作用。
注意:wait命令 仅仅针对<当前父进程>的<子进程>方可生效!
语法:wait [进程号 或 作业号],例如:wait 或 wait 23 或 wait %1
备注:
wait 不带<任何的进程号或作业号> ,则会阻塞<当前进程>,直至<当前进程的所有子进程>全部执行结束
wait 23 阻塞<当前进程>,直至<指定的PID子进程>执行结束
wait %1 阻塞<当前进程>,直至<指定JOB作业任务>执行结束
#!/bin/bash
echo "当前父进程PID号 = $$"
echo "当前开始时间是:$(date)"
sleep 60 &
echo "该 sleep 60 子进程PID号 = $!"
sleep 120 &
echo "该 sleep 120 子进程PID号 = $!"
wait
echo "当前结束时间是:$(date)"
15.5.5 dirname、basename
dirname 功能:输出文件路径的根路径到父路径
basename 功能:输出文件路径的文件名
dirname 1/2/3/4/5 ## 输出1/2/3/4
basename 1/2/3/4/5 ## 输出5 无论有没有该文件路径都会这样输出
15.5.6 xargs 命令
功能:xargs命令 可以通过<| 管道符>接受<字符串>,并将<接收到的字符串>依据<默认空格>分割成<许多参数>,然后,将<这些参数>作为<命令行参数>传递给<后面的命令>,<后面命令>则可以使用这些<命令行参数>来执行。
作用:管道符 | 对于不支持标准输入的命令(比如 rm ),无法传输文件,使用该命令即可 例如:
echo “1.txt” | rm -rf ## 操作失败,因为 rm 无法感知 1.txt 是文件名还是字符串
echo "1.txt" |xargs rm ## 成功删除当前目录下的1.txt文件
选项:
-d ## 指定分隔符,不写的情况下默认是以 空格(包括制表符等等)为分隔符
echo '11@22@33' | xargs -d '@' echo ## 指定 @ 为分隔符 输出 11 22 33
-p ## 输出<即将要执行的完整命令>,询问<是否执行> 可拿来查看将要输出什么但是不输出
-n ## 设置<每次传递>的<命令行参数>的<个数>,可以<分批传输,分批执行>
echo '11@22@33@44@55' | xargs -n 2 -d '@' echo ## 11 22 33 44 55 将分成<两次>传送,分成<三次>执行-E ## 仅仅传递<指定命令行参数>之前的<命令行参数>
echo '11 22 33 44' | xargs -E '33' echo ## 输出 11 22 如果加 -p 就会询问## 注意:【-E选项】不能和【-d选项】一起使用,如果一起使用,则【-E选项】无效。即便【-d选项】指定的是<空格>也是如此。
15.5 shell 算数计算
15.5.1 计算简单格式
1 整数计算 ((…)) 和 let " " $[ ]必须使用该格式才可以进行计算和相关操作
使用 + - * / % < > 需要使用该格式 ,专门使用拿来定义表达式
n=1;((n=n+1));echo $n ## 输出2
n=1;let n-n+1;echo $n ## 输出2 let是内嵌命令let "x=10, y=5, z=x+y"
echo $z ## 输出 15((x=100/10)) let "x=100/10" x=$[100/10] ## 将100/10赋值给x
例子:
[root@dj tmp]# ((x=100/10))
[root@dj tmp]# echo $x
10
[root@dj tmp]# ((x=100/5))
[root@dj tmp]# echo $x
20[root@dj tmp]# let "x=100/10"
[root@dj tmp]# echo $x
10
[root@dj tmp]# let "x=100/5"
[root@dj tmp]# echo $x
20[root@dj tmp]# x=$[100/10]
[root@dj tmp]# echo $x
10
[root@dj tmp]# x=$[100/5]
[root@dj tmp]# echo $x
20
2 浮点数计算 bc 外部命令
yum -y install bc ## 外部命令要安装
echo "10/3" ## 输出 10/3
echo "10/3" | bc ## 输出 3 默认是整数
echo "scale=2;10/3" | bc ## 输出 3.33 scale 是指定 输出小数后多少位,默认是0,即输出整数
echo "scale=3;10/3" | bc ## 输出 3.333
运算速率: [let命令] 等价于 ((…)) ;大于 [bc命令]
15.5.2 算数计算表达式:操作符(重要)
有 a++ a-- ++a --a + - * / % **(幂)
! 逻辑取反
let "x=1, y=2, z=(x<y)" ## 判断语句
echo $z ## 输出 1 ,布尔类型中 1 代表正确let "x=1, y=2, z=!(x<y)" ## 判断语句
echo $z ## 输出 0 ,布尔类型中 0 代表错误
~ 按位取反
let "x=2, y=~x" ## y=~x 就是:按位取反
echo "y=$y" ## 计算结果:y=-3
<< 和 >> 对应的二机制数移位
let "x=1, y=x<<1" ## x<<1 就是:按位左移1位 二进制 01 左移变成 10 ,变回十进制就是 2
echo "y=$y" ## 计算结果: y=2 输出 y=2而不是输出2[root@dj tmp]# let "x=6, y=x>>1" ## 右移动 二进制 110 右移变成 11 即 3
[root@dj tmp]# echo $y
3
& 逻辑与 | 逻辑或 ^ 逻辑异或 都是二进制的对比
& ## 双 1 为 1 ,否则为 0
| ## 有 1 为 1 ,全 0 为 0
^ ## 相同为 0 ,不同 为 1
let "x=(10^12)" ## 二进制分别是 1010 1100 得到 0110 即 6
echo $x ## 输出 6
<赋值>操作符 : =, *=, /=, %=, +=, -=, <<=, >>=, &=, ^=, |=
= ## 例句:let "x=1+2"
*= ## 例句:let "x*=2" 等价于 let "x=x*2"
/= ## 例句:let "x/=2" 等价于 let "x=x/2"
%= ## 例句:let "x%=2" 等价于 let "x=x%2"
+= ## 例句:let "x+=2" 等价于 let "x=x+2"
-= ## 例句:let "x-=2" 等价于 let "x=x-2"
<<= ## 例句:let "x<<=2" 等价于 let "x=x<<2"
>>= ## 例句:let "x>>=2" 等价于 let "x=x>>2"
&= ## 例句:let "x&=2" 等价于 let "x=x&2"
^= ## 例句:let "x^=2" 等价于 let "x=x^2"
|= ## 例句:let "x|=2" 等价于 let "x=x|2"
15.6 shell 条件判断
1 算数条件判断表达式
<, <=, >, >= ## 小于,小于等于,大于,大于等于
==, != ## 等于,不等于expr1?expr2:expr3 ## 根据<条件判断>结果,来予以<赋值>if expr1; then expr2 ; else expr3 ; fi
expr1 && expr2 || expr3
意思是:如果怎么样,那么就怎么样,否则就这样
((x=($a<$b)?$a*10:$b*100)) ## 如果 $a小于$b,则 x=$a*10,否则 x=$b*100 ## 三目运算符
a=1
b=2
echo $x ## 测试发现 输出 10
2 字符条件判断表达式
<整数>判断(正负整数)
-eq ## 等于 ,如:arg1 -eq arg2
-ne ## 不等于 ,如:arg1 -ne arg2
-gt ## 大于 ,如:arg1 -gt arg2
-ge ## 大于等于,如:arg1 -ge arg2
-lt ## 小于 ,如:arg1 -lt arg2
-le ## 小于等于,如:arg1 -le arg2
<字符串>判断
-z string ## 判断<字符串>长度是否为<0字节>?(长度为<0字节>,则为true真)
str=""; if [[ -z $str ]]; then echo "true"; else echo "false"; fi
## 显示结果:ture
str="123"; if [[ -z $str ]]; then echo "cxk"; else echo "ikun"; fi
## 显示结果:ikun注意:中括号之间一定要加空格string ## 判断:<字符串>长度是否为<非0字节>?(长度为<非0字节>,则为true真)
-n string ## 判断:<字符串>长度是否为<非0字节>?(长度为<非0字节>,则为true真)## 备注:-n 可以省略
str=""; if [[ -n $str ]]; then echo "true"; else echo "false"; fi
## 显示结果:false
str="123"; if [[ $str ]]; then echo "true"; else echo "false"; fi
## 显示结果:truestring1 = string2 ## 判断:是否相同?(如:str01□=□str02,str01□==□str02)## =等于符号 是为了确保与【POSIX系统】的兼容一致性(在test命令中应该用 =)
string1 == string2 ## 判断:是否相同?(如:str01□=□str02,str01□==□str02)
string1 != string2 ## 判断:是否不相同?(如:str01□!=□str02)
string1 < string2 ## 判断:是否在string2之前?(注意:按字典排序)(如:str01□<□str02)
string1 > string2 ## 判断:是否在string2之后?(注意:按字典排序)(如:str01□>□str02)
3 正则条件判断表达式
<正则条件表达式>:<操作符>
=~ 扩展正则表达式 ## 判断:是否匹配<扩展正则表达式>
注意:
在 =~ 扩展正则表达式 中,=~ 左右两边各有一个<空格>
在 =~ 扩展正则表达式 中,<扩展正则表达式>不要使用<""双引号>和<''单引号>
在 =~ 扩展正则表达式 中,如果需要匹配<空格>,则需要使用<\转义符>
以下是扩展正则表达式
n="1.1.1.1"; [[ $n =~ ^([0-9]{1,3}(\.|$)){4} ]] && echo "符合" || echo "不符合"
n="1.1.1.1"; if [[ $n =~ ^([0-9]{1,3}(\.|$)){4} ]];then echo "符合"; else echo "不符合"; fi
## 显示结果:符合n="1..1.1"; [[ $n =~ ^([0-9]{1,3}(\.|$)){4} ]] && echo "符合" || echo "不符合"
n="1..1.1"; if [[ $n =~ ^([0-9]{1,3}(\.|$)){4} ]];then echo "符合"; else echo "不符合"; fi
## 显示结果:不符合 ..不符合要求n="1.1.1.1111"; [[ $n =~ ^([0-9]{1,3}(\.|$)){4} ]] && echo "符合" || echo "不符合"
n="1.1.1.1111"; if [[ $n =~ ^([0-9]{1,3}(\.|$)){4} ]];then echo "符合"; else echo "不符合"; fi
## 显示结果:不符合 1111不符合要求,范围是 0 到 999n="1.1 1.1.1"; [[ $n =~ ^([0-9]{1,3}(\.|$)){4} ]] && echo "符合" || echo "不符合"
n="1.1 1.1.1"; if [[ $n =~ ^([0-9]{1,3}(\.|$)){4} ]];then echo "符合"; else echo "不符合"; fi
## 显示结果:不符合 5个数不符合要求,最多四个str="/testdir/subdir"; if [[ $str =~ ^~?/ ]]; then echo "true"; else echo "false"; fi
## 显示结果:true ##这里的~表示家目录,0或1个以 ~ 开头,然后是 / ,满足条件
str="testdir/subdir"; if [[ $str =~ ^~?/ ]]; then echo "true"; else echo "false"; fi
## 显示结果:false
注意:
grep 命令 既支持<扩展正则表达式>,又支持<Perl正则表达式>!
if 命令 =~ 仅支持<扩展正则表达式>,不支持<Perl正则表达式>!
使用grep来检验:<文件路径或目录路径>的<规范性>
要求1 可以且只能:以【/斜杠】开头或结尾,所有【/斜杠】不能重复,设计<Perl正则表达式>为:^/?
要求2 两个【/斜杠】之间,不能存在:【/斜杠】、【空格】、【Tab符】、【'或"单双引号】,设计<Perl正则表达式>为:
^(/?[^/\s\"\']+)+/?$ ## 第二个 ^ 是取反的不匹配 \" 表示 "
要求3 如果路径中需要包含<空格>,则必须:在<整个路径的最外层>添加【""双引号】,设计<Perl正则表达式>为:
^[\"]{1}(/?[^\"\']+)+/?[\"]{1}$
注意:下面的写法实际上输出不是以 ” ” 开头和结尾,所以不要被后面的匹配 ‘’ ‘’ 给骗了
str="/testdir/subdir"
echo $str | grep -oP "(^(/?[^/\s\"\']+)+/?$|^[\"]{1}(/?[^\"\']+)+/?[\"]{1}$)" && echo "匹配" || echo "不匹配"
## 显示结果:匹配str=" /testdir/subdir" ## <赋值语句>会自动去掉<字符串>前后的<空格>
echo $str | grep -oP "(^(/?[^/\s\"\']+)+/?$|^[\"]{1}(/?[^\"\']+)+/?[\"]{1}$)" && echo "匹配" || echo "不匹配"
## 显示结果:匹配 是匹配前面的 而不是匹配后面的str="/test dir/subdir"
echo $str | grep -oP "(^(/?[^/\s\"\']+)+/?$|^[\"]{1}(/?[^\"\']+)+/?[\"]{1}$)" && echo "匹配" || echo "不匹配"
## 显示结果:不匹配str="/testdir//subdir"
echo $str | grep -oP "(^(/?[^/\s\"\']+)+/?$|^[\"]{1}(/?[^\"\']+)+/?[\"]{1}$)" && echo "匹配" || echo "不匹配"
## 显示结果:不匹配str="\"/test dir/sub dir\""
echo $str | grep -oP "(^(/?[^/\s\"\']+)+/?$|^[\"]{1}(/?[^\"\']+)+/?[\"]{1}$)" && echo "匹配" || echo "不匹配"
## 显示结果:匹配str="\"/test dir/sub dir/\""
echo $str | grep -oP "(^(/?[^/\s\"\']+)+/?$|^[\"]{1}(/?[^\"\']+)+/?[\"]{1}$)" && echo "匹配" || echo "不匹配"
## 显示结果:匹配 这才是 匹配后面的 以双引号开头,双引号结尾
4 多个条件判断表达式
组合符
&& 逻辑与
|| 逻辑或
示例1:组合使用多个<算数条件表达式>
(((1<2)&&(2<3))) 或者 [[ ( 1 < 2 ) && ( 2 < 3 ) ]]
echo $? ## 结果显示:<算数条件表达式>的<状态返回值>为<0> 判断上条命令运行结果,正确返回 0,错误返回1 和布尔类型相反
(((2<1)||(2<3)))
echo $? ## 结果显示:<算数条件表达式>的<状态返回值>为<0>
示例2:组合使用多个<字符条件表达式>
[[ "a" == "a" ]] && [[ "b" == "b" ]]
echo $? ## 结果显示:<字符条件表达式>的<状态返回值>为<0>
[[ "a" == "a" ]] || [[ "a" == "b" ]]
echo $? ## 结果显示:<字符条件表达式>的<状态返回值>为<0>
5 test 条件判断命令(判断文件)
这里可以拿来判断文件是否存在,是什么类型的文件,是否为空文件等等
test 和 [[ ]] 用法一样
1 判断:任意类型的文件(Linux一切皆文件)
-a filename ## 如果filename存在,不管文件是什么类型,则为true真
-e filename ## 如果filename存在,不管文件是什么类型,则为true真
-s filename ## 如果filename存在,并且是<非空文件(长度 > 0字节)>,不管文件是什么类型,则为true真
[[ -a /etc/passwd ]] 或者 test -a /etc/passwd
比如:
if test -e filename; thenecho "文件存在"
fi# 或者使用 [[ ]]
if [[ -e filename ]]; thenecho "文件存在"
fi
2 判断:特定类型的文件(Linux一切皆文件)
-f filename ## 如果filename存在,且为<常规文件>,则为true真
-d filename ## 如果filename存在,且为<目录>,则为true真
-b filename ## 如果filename存在,且为<块文件>,则为true真
-c filename ## 如果filename存在,且为<字符设备文件>,则为true真
-S filename ## 如果filename存在,且为<socket套接字文件>,则为true真
-p filename ## 如果filename存在,且为<命名管道文件>,则为true真
-h filename ## 如果filename存在,且为<符号链接文件>,则为true真
-L filename ## 如果filename存在,且为<符号链接文件>,则为true真## 注意:<符号链接文件>不是<硬链接文件>
3 判断:文件的属性(Linux一切皆文件)
-r filename ## 如果针对filename,<当前用户>拥有<r读权限>,则为true真
-w filename ## 如果针对filename,<当前用户>拥有<w写权限>,则为true真
-x filename ## 如果针对filename,<当前用户>拥有<x可执行权限>,则为true真
-u filename ## 如果filename设置了<SUID权限位>,则为true真
-g filename ## 如果filename设置了<SGID权限位>,则为true真
-k filename ## 如果filename设置了<SBIT权限位>,则为true真
-O filename ## 如果filename的<所有者>是<当前用户>,则为true真
-G filename ## 如果filename的<所有者>是<当前用户>的<主要组>,则为true真
-N filename ## 如果filename在<最后一次读取>之后被修改,则为True真
-t fd ## 如果<fd文件描述符>关联着一个<终端>,则为True真例如:test -t 0 ## 文件描述符0:是关联着<终端>的<标准输入>
例如:test -t 1 ## 文件描述符1:是关联着<终端>的<标准输出>
例如:test -t 2 ## 文件描述符2:是关联着<终端>的<标准错误输出>
4 判断:文件的对比(Linux一切皆文件)
file01 -nt file02 ## 如果file01比 file02新,则为true真
file01 -ot file02 ## 如果file01比 file02旧,则为true真
file01 -ef file02 ## 如果file01和file02是同一个文件,则为true真## 主要是依据file01和file02各自的inode编号,来判断是否为<硬链接文件/软连接文件>?
5 判断:字符串 STRING 代表字符串,不是特指
-z STRING ## 判断:<字符串>是否为<空>?
-n STRING ## 判断:<字符串>是否为<非空>?
STRING1 = STRING2 ## 判断:<字符串>是否为<相等>?
STRING1 != STRING2 ## 判断:<字符串>是否为<不相等>?
STRING1 < STRING2 ## 基于<字典>来判断:<字符串1>是否小于<字符串2>?
STRING1 > STRING2 ## 基于<字典>来判断:<字符串1>是否大于<字符串2>?
6 判断:数值
arg1 OP arg2 ## 比较:arg1和arg2这两个<算数值>## OP是<操作符>,取值范围是:-eq等于、-ne不等于、-lt小于、-le小于等于、-gt大于、-ge大于等于。
7 判断:其他
-o OPTION ## 如果指定的<set内建的Shell选项>已经<启用>,则为true真
例如:
[ -o history ] && echo $? ## 判断是否启用了<set内建的Shell选项:history功能>?
-v VAR ## 如果一个<VAR变量>已被<定义并赋值>,则为true真
8 逻辑操作
! EXPR ## 执行:逻辑取反
EXPR1 -a EXPR2 ## 执行:逻辑与
EXPR1 -o EXPR2 ## 执行:逻辑或
举例:
[ -d /tmp -a -d /etc ] && echo $?
[ -d /tmp -o -d /dir01 ] && echo $?
6 [ ] 和 [[ ]] 的区别
建议用 [[ ]]
[ ] :它是一个<命令>,是<test 内嵌命令>的<简写形式>。
[[ ]] :它不是一个<命令>,只是一个中的<关键字>,[[ ]] 结构 比 [ ] 结构 更加通用。
[[ ]] 用法:里面每一个参数都要隔开,严格按照格式,不能紧贴着,包括不能贴着两边
双中括号[[]]是bash shell中的关键词,相对于[]有以下特点和优势:
[[ ]] 结构比[ ]结构更加通用。在[[和]]之间所有的字符都不会发生文件名扩展或者单词分割,但是会发生参数扩展和命令替换。支持字符串的模式匹配,使用=~操作符时甚至支持shell的正则表达式。字符串比较时可以把右边的作为一个模式,而不仅仅是一个字符串,比如[[ hello == hell? ]],结果为真。[[ ]] 中匹配字符串或通配符,不需要引号。使用[[ ... ]]条件判断结构,而不是[... ],能够防止脚本中的许多逻辑错误。比如,&&、||、<和> 操作符能够正常存在于[[ ]]条件判断结构中,但是如果出现在[ ]结构中的话,会报错。bash把双中括号中的表达式看作一个单独的元素,并返回一个退出状态码。实际上,原理就是,在双中括号中,可以使用=~进行shell的正则匹配,找出右边的字符串是否在左边的字符串中。但是需要注意的是,双中括号在bash中可以使用,在sh中会报找不到的错,这是一个大坑。
7 if 条件判断语句
注意:if 之后判断一次,不能直接用来做循环,循环得用 for 和 while
1 语法
语法1:
if 条件; then 操作; [elif 条件; then 操作;] ... [else 操作;] fi
注意: elif 和 else 如果不需要可以不写,看条件选一个完成,完不成都选择
语法2 :
if 条件; then操作
[elif 另外满足的条件; then操作]
... ...
[else操作]
fi
语法3 : 常用
if 条件
then操作
elif 条件
then操作
... ...
else操作
fi
注意: if 和 elif 都需要加 then ,else 不需要加 then ,开头 if 结尾 fi
2 工作原理
按序依次检查:<if COMMANDS;语句块>和<elif COMMANDS;语句块>的<状态返回值>
如果 <状态返回值> = 0 ,则执行:<then COMMANDS;语句块>
如果 <状态返回值> = 非0,则执行:<else COMMANDS;语句块>
3 例子
以下例子全用脚本来写
输入1就1,输入2就2 输入别的就空格
#!/bin/bash
read -e -p "请输入一个数字:" a
if (( $a==1 ))
thenecho "你输入的是1"
elif (( $a==2 ))
thenecho "你输入的是2"
elseecho " "
fi
注意:这里条件判断使用 [[ ]] 也可以
字符条件判断
a="ABC"
b="CBA"
if [[ $a < $b ]]
thenecho "<a变量值>的<字符串编码数>小于<b变量值>"
elif [[ $a == $b ]]
thenecho "<a变量值>的<字符串编码数>等于<b变量值>"
elseecho "<a变量值>的<字符串编码数>大于<b变量值>"
fi
字符条件判断,,输入 no 输出yes,输入yes输出no
#!/bin/bash
read -e -p "请输入: " a
if [[ $a == "yes" ]]
thenecho "no"
elif [[ $a == "no" ]]
thenecho "yes"
elseecho "你是人才吗"
fi
定义 holiday_name 字符串变量记录节日名称 (字符串判断)
如果是 情人节 应该 买玫瑰/看电影
如果是 平安夜 应该 买苹果/吃大餐
如果是 生日 应该 买蛋糕
其他的日子每天都是节日啊……
#!/bin/bash
read -e -p "请输入节日名称:" holiday_name
if [[ $holiday_name == "情人节" ]]
thenecho "如果是$holiday_name应该买玫瑰"
elif [[ $holiday_name == "平安夜" ]]
thenecho "如果是$holiday_name应该买苹果"
elif [[ $holiday_name == "生日" ]]
thenecho "如果是$holiday_name应该买蛋糕"
elseecho "其他的日子每天都是节日啊……"
fi
判断是否有 /etc/passwd 文件存在 (test判断)
#!/bin/bash
if [[ -a /etc/passwd ]]
thenecho "存在"
elseecho "不存在"
fi
判断数组是否含有某变量在其中 (正则表达判断)
#!/bin/bash
a="abc"
char_list=("bcd" "abc" "xyz")
if [[ ${char_list[*]} =~ $a ]] ## =~ 匹配正则
then echo "$a包含在字符串序列中"
elseecho "$a不包含在字符串序列中"
fi
8 case 条件判断命令
1 功能
根据匹配的<PATTERN模式>,有选择的执行<COMMANDS命令>
case 与 if 的不同在于:case只做一次<条件判断>,if可做多次<条件判断>
2 语法
case $a in case $a in
判断条件1 ) 判断条件1 )操作 操作
;; ;&
判断条件2 ) 判断条件2 )操作 操作
;; ;&
…… ……
;; ;&
* ) * )操作 操作
;; ;&
esac esac#注意:case里面不需要 then ;; ## 表示一旦匹配,则不继续往下执行<其他PATTERN模式>的<指令>;& ## 表示即便匹配,也会继续往下执行<其他PATTERN模式>的<指令>(无论是否匹配)
3 例子
使用脚本来写,和 if 用法差不多
#!/bin/bash
read -e -p "请输入你的年龄 = " age
case $age in[0-9])echo "你是儿童";;1[0-9])echo "你是青少年";;2[0-9])echo "你正值壮年";;[3-5][0-9])echo "你步入中年了";;[6-8][0-9])echo "你是个老人了";;9[0-9]|1[0-9][0-9])echo "你是个神仙了";;*)echo "你是人还是鬼?";;
esac
输入1就1,输入2就2 输入别的显示 您真是一个大聪明
#!/bin/bash
read -e -p "请输入一个数字 " a
case $a in
1 )
echo "您输入的是1"
;;
2 )
echo "您输入的是2"
;;
* )
echo "您真是一个大聪明"
;;
esac
输入 yes 就输出no
#!/bin/bash
read -e -p "请输入: " a
case $a in
"yes")echo "no"
;;
"no")echo "yes"
;;
*)echo "你是人才吗"
;;
esac
9 ; && ||
| 符号 | 功能 | 例句 |
|---|---|---|
| ; 分号 | 在一行中,依次执行多个命令, 不管<左边命令>是否执行成功,都将执行<右边命令> | echo “ x " ; e c h o " x"; echo " x";echo"PATH” |
| && | 条件判断:<&&左边命令>的<状态返回值>为 0(满足),方可执行<&&右边的命令> | echo “KaTeX parse error: Expected 'EOF', got '&' at position 4: x" &̲& echo "PATH” |
| || | 条件判断:<||左边命令>的<状态返回值>为 非0(不满足),方可执行<||右边的命令> | echo “ x " ∣ ∣ e c h o " x" || echo " x"∣∣echo"PATH” |
例子
[ -d /tmp ] && rm -rf /tmp/* || echo "没有这个目录"
[ -d /tmp ] || echo "没有这个目录" && rm -rf /tmp/*## 两个意思一样:有没有/tmp 目录,有的话删除 /tmp/目录下所有文件,没有的话就输出 没有这个目录 (第一个好理解)
组合条件判断
[ -d /tmp -a -d /etc ] && echo "两个目录均存在" || echo "至少其中一个目录不存在"
[ -d /tmp -o -d /dir01 ] && echo "其中一个目录一定存在" || echo "两个目录均不存在"
15.7 shell 循环控制
15.7.1 for 循环
for 里面判断条件是 一些 数学算数判断循环,如果是字符这方面,要到 if 里面去判断
注意: for 循环 里面可以嵌套 if 和 for 循环
类似于
for …… 类似于 if [[ ]]
do then …… ……
done fi
语法 1 : for ((EXPR1; EXPR2; EXPR3)) ; do COMMANDS ; done
#!/bin/bash
for ((n=1;n<3;n++))
dotouch $n.txt
done
创建 1.txt 2.txt
语法 2:for 变量 [in 单词序列] ; do COMMANDS; done i为变量 for i in ……
#!/bin/bash
for a in 1 2 3 4 55 或者 for a in {1..10}
doecho "$a"
done
死循环
for ((;;)); doecho "这是一个死循环,按Ctrl + c结束"
done ## 初始值,条件,增量都不写或者for ((i=1;;i++)); doecho "这是一个死循环,按 Ctrl + c 终止"
done ## 不写循环条件或者for ((i=1;i<=10;)); doecho "这是一个死循环,按 Ctrl + c 终止"
done ## 不写增量
强制 y
#!/bin/bash
for ((;;))
doif [[ $Y != "y" ]]thenread -e -p "请输入(y/n):" Yelseexitfi
done
强制玩原神
#!/bin/bash
for ((;;))
doif [[ $Y != "玩" ]]thenread -e -p "你玩原神吗? (玩/不玩)" Yelseexitfi
done## 注意:因为要使该循环无限运行,使用要使 for 运行死循环,在使用if判断退出循环
使用ping命令去测试整个 192.168.1.0 网段,将能ping通的机器ip写到/tmp/ok.txt .将不能ping通的ip写到/tmp/no.txt (本公司网段)
将 ping 成功或者错误的信息丢进黑洞 ,每一个 ping 跑3遍即可 , 不然太慢了
#!/bin/bash
for ((a=1;a<256;a++))
doif ping 192.168.1.$a -c 3 &>> /dev/nullthenecho 192.168.1.$a >> ok.txtelseecho 192.168.1.$a >> no.txtfi
done
## -c 3 表示显示3次即可,不然ping 会一直显示在屏幕上,没学进程只能开新窗口解决
## 注意:& 要紧贴 重定向符号,表示全部信息,无论正确错误的信息都丢尽黑洞 /dev/null
## ping的过程很久,因为有 255 个ip ,可以开两个新窗口 tail -f /tmp/ok.txt 和 tail -f /tmp/no.txt 实时查看
15.7.2 while 循环
满足条件就继续循环,不满足就中止循环
for能做的while也可以,for不能的while也可以
语法:
初始值定义
while 条件
do……
done ## 最好有初始值定义,不然无法进入该循环
强制 y
#!/bin/bash
Y="n"
while [[ $Y != "y" ]]
doread -e -p "请输入(y/n):" Y
done如果用 for 循环来做,如下,需要先让for进入死循环
#!/bin/bash
for ((;;))
doif [[ $Y != "y" ]]thenread -e -p "请输入(y/n):" Yelseexitfi
done
强制玩原神
#!/bin/bash
a="随便写"
while [[ $a != "玩" ]]; doread -e -p "你玩原神吗[玩/不玩]: " a
done[root@dj tmp]# bash 3.sh
你玩原神吗[玩/不玩]: 玩
[root@dj tmp]# bash 3.sh
你玩原神吗[玩/不玩]: 不玩
你玩原神吗[玩/不玩]: 不玩
死循环
while true; doecho "OK"
done
手动创建用户,并核对二次密码
y="no"
while [[ $y == "no" ]]; doread -e -p "请输入用户名=" usernameread -e -s -p "请输入密码(不少于8个字符)=" aechoread -e -s -p "请再次输入密码(不少于8个字符)=" bechoif [[ $a == $b ]]; thenecho "OK,你本次密码设置有效"echo "$username:$a" | chpasswdy="yes"elseclearecho "NO,你的两次密码不一致,请重新输入!"y="no"fi
done
创建十个用户,分别叫user1-user5,批量设置密码,pass1-pass5
如果用户已存在则输出用户已存在,如果用户不存在则创建用户设置密码
#!/bin/bash
zh=1
while (($zh <= 10))
doif id user$zh &> /dev/null then echo "用户user${zh}已经存在" elseuseradd user$zhmm=$zhecho "user$zh:pass$mm" | chpasswdecho "用户user${zh}创建成功"echo "用户密码设置成功"fi((zh++))
done
## 如果用户存在,那么 if 会执行成功,把id user$zh 命令成功的信息写进黑洞,然后运行第一个
## 如果用户不存在,那么 if 会执行失败,把报错信息写进黑洞,然后运行第二个
计算 1+2+3+……+100 = 5050
#!/bin/bash
num=0
n=1
while ((n<=100))
do((num=num+n))((n++))
doneecho $num或者#!/bin/bash
num=0
for ((n=1;n<=100;n++))
do((num=num+n))
doneecho $num
15.7.3 while read 循环语句
语法1:遍历<标准输入>的<行>循环
COMMANDS | while read VAR; do COMMANDS; done
了解即可...
语法2:遍历<文件>的<行>循环
while read VAR; do COMMANDS; done < FILE
15.7.4 until 循环语句
直到<条件满足>,就终止循环
不满足条件就一直循环,满足就中止 和 while 相反
所以当 until 和 while 条件范围相反 ,完成的内容其实是一样的
强制 y
Y="n"
until [[ $Y == "y" ]]
doread -e -p "请输入(y/n):" Y
done
15.7.5 continue 命令
功能:中止本次循环,但是不会中止本轮全部循环,会直接跳转到下一次循环 跳过的意思
语法: continue [N] 终止<本轮循环>
● 仅在<N层嵌套循环体>语句结构中,发挥作用,可以终止<当前循环体>的<第N层上级循环体>
● <第1层>就是<循环体自身>,即:continue 1 等同于 continue
要知道 continue和break还有exit的区别
# 打印 1 到 10 之间的奇数
#!/bin/bash
for ((i=1; i<=10; i++))
doif ((i % 2 == 0))thencontinuefiecho $i
done
##如果是偶数就不满足条件,直接中断本次循环到下一次循环判定
15.7.6 break 命令
功能:中止本轮全部循环,直接退出循环 停止的意思
语法: break [N] 终止<整个循环>
● 仅在<N层嵌套循环体>语句结构中,发挥作用,可以终止<当前循环体>的<第N层上级循环体>
● <第1层>就是<循环体自身>,即:break 1 等同于 break
和exit 区别:break之后退出该循环,但是会执行循环外面的内容
exit 直接跳出脚本,当前面使用了exit ,后面的内容直接不生效
如果循环外部后面没有内容,那exit 和 break 都可以使用
# 示例:找到第一个大于 5 的数字
#!/bin/bash
numbers=(1 2 3 4 5 6 7 8 9 10)for num in ${numbers[*]}
do# 如果数字大于 5,则打印并终止循环if [[ $num > 5 ]]thenecho "找到第一个大于 5 的数字:$num"break #exit # 如果把break 替换为 exit ,那循环外面的内容则无用,即后面那句话不会显示fi
done
echo "break就显示,exit不显示"[root@dj ~]# bash 5.sh
找到第一个大于 5 的数字:6
break就显示,exit不显示[root@dj ~]# vim 5.sh 改成exit保存后
[root@dj ~]# bash 5.sh
找到第一个大于 5 的数字:6本来要循环10次,找到大于5的直接中止循环
15.8 sed 三剑客之一
15.8.1 命令简介
重要:可修改匹配的行或者匹配的内容返回文件,玩出花来的正则表达式
sed 是一个用于 过滤并转换 文本行 的 流编辑器
sed 和 vi 的区别:
vi 是<交互式>的<文本编辑器>
sed 是<非交互式>的<文本流编辑器>,接受<input输入字符流>,然后过滤并转换,最后输出<output输出字符流> 适合脚本和dockerfile
注意:sed 和 vi 有一些命令是通用的,比如替换 s///
sed 是一个基于<行>字符流,执行<整行处理>的<文本处理工具>
awk 是一个基于<行>字符流,精细到<列处理>的<文本处理工具>
15.8.2 工作原理
重点理解:
-
逐行输入、逐行处理、逐行输出。(从左到右,从上到下,一般原文件不会改变)
-
在<模式空间>:暂存数据、处理数据、输出数据、清空数据

15.8.3 sed 的运用
注意:sed 里面 替换那里不能使用 \s 做制表符,可以使用 \t ,因为 s有替换的意思 \s 会转义成s 和 s一样
功能:匹配某一行,也可以进行操作修改,或者对行内的某一些内容修改
语法:
sed [options] script filename
sed [options] -f script filename
sed 选项 ’ 地址范围和子命令(正则) ’ 文件名
注意:要修改文件的话 必须 在后面接文件名, 如果是前面用| ,那么不能修改,因为只是对前面匹配到的字符串进行操作而不是原文件
选项
-r ## 使用扩展正则
-e ## 可以同时对文件执行多个 子命令 ## 如-e 'script01' -e 'script02' -e 'script03'
-n ## 抑制 sed命令 的标准输出,因为不使用该命令对文件操作会输出文件原内容和操作的内容
-i ## 回写 标准输出到源文件,是覆盖式回写 (修改原文件)
-i.bak ## 修改原文件之前进行备份
-f ## 后接sed脚本,指定执行的sed脚本
\< \> ## 单词边界 ,比如 \<root\> 仅匹配root## rootab wadroot 这种不匹配,重要
-e 作用
打印pass文件的第1行和第3行
sed '1p;3p' /tmp/pass 或 sed -e '1p' -e '3p' /tmp/pass 删除第一行和最后一行
sed '1d;$d' pass打印最后一行,原理:删除第一到倒数第二行即可 sed '$!d' pass
sed '!$d' pass 和 sed '1,($-1)d' pass 都不行,必须如上所示
-n 的作用
[root@dj ~]# sed '' /tmp/passwd
[root@dj ~]# sed -n '' /tmp/passwdsed -n '$p' /tmp/passwd ## 输出最后一行打印出来
sed -ni '1,5p' passwd ## 把文件内容改成原文件内容前五行
sed -r 's/^([a-zA-Z0-9]+)([^a-zA-Z0-9])([a-zA-Z0-9]+)/\3\2\1/' ## 交换第一个和第三个单词
常用的sed 子命令
i\ ## 不写\也行 在指定行新建上一行写入内容
c\ ## 在指定行替换写入内容,常用,用这个进行匹配并替换整行内容
a\ ## 在指定行新建下一行写入内容 追加
r\ ## 在指定行新建下一行写入指定文件的内容 插入
比如
sed '1a 1.txt' passwd ## 会在passwd文件第一行下面写入 "1.txt"
sed '1r 1.txt' passwd ## 会在passwd文件第一行下面写入文件1.txt里面的内容! ## 放在命令面前取反
d ## 删除,写在要删除的内容的后面
p ## 打印,写在要打印的内容的后面
q ## q 匹配到 第5行就退出地址范围:
1 ## 就是处理第1行
$ ## 处理最后一行
1,5 ## 处理1到5行 sed '1,5p' 1.txt
2~2 ## 从第2行开始,每隔1行 注意:2~1 相当于 2,$ ,第二行到最后一行
2~5 ## 从第二行开始,每隔4行
3,+5 ## 处理3-8行或者以正则表达式匹配的作为地址范围(精确处理)
1)、/正则表达式/ 一般出现 / / 不是正则表达式 就是 替换
如:/^root/
2)、/正则表达式1/,/正则表达式2/ 表示从第一次匹配到正则表达式1开始到第一次匹配到正则表达式2之间的所有行
如:/^r/,/^s/ 或者 '/^root/,/^b.*n$/p'匹配那一行改为禁用模式
sed -r -i '/^[ \t]*SELINUX=/c\SELINUX=disabled' /etc/selinux/config
注意:如果匹配到范围开头,但是范围结尾匹配不到,那会匹配开头那行到最后一行如果匹配到范围结尾,没有匹配到开头,那就匹配不到s/被替换/替换/ s||| s### s@@@ 替换
g ## 全局替换 一行的全局 vi需要在前面加 % ,这个不用,因为默认是替换所有行的第一个关键字(g写在后面)
i ## 查找时忽略大小写
n ## 第n个被匹配到的 n表示数字
& ## 表示将要被替换关键字
sed -r 's/l..e/&r/' 1.txt ## &代表前面的 l..e .代表任意单个字符
\1 \2 ## 如果被替换的内容使用了(),即正则分组进行分成几组## 那么 \1 \2 分别表示第一组和第二组
注意:g 写在后面,& 和 \1 这些写在 替换 那里,()和别的正则 或者 地址范围写在 被替换 那里y/// ## 也是替换,但是如果找不到被替换的,会把被替换的分开出来找
s/abc/ABC/ ## 把abc替换成 ABC ,前提要有 abc 整体
y/abc/ABC/ ## 把a替换成A ,b替换成B,c替换成C仅将 root替换ROOT,但是rootab不会匹配到替换成 ROOTab
sed 's/\<root\>/ROOT/g' pass
注意:使用 s###的时候,如果匹配内容有 / ,那么不需要使用转义字符进行转义
分别指定第一行 写入123456 查看 i c a 的区别
[root@dj ~]# sed '' /tmp/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin ## 原内容,后面还有很多行省略...[root@dj ~]# sed '1i\123456' /tmp/passwd
123456
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin[root@dj ~]# sed '1c\123456' /tmp/passwd
123456
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin[root@dj ~]# sed '1a\123456' /tmp/passwd
root:x:0:0:root:/root:/bin/bash
123456
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin难点:
[root@dj tmp]# sed '/^root/a\hello\nworld' /tmp/passwd ## \n 是换行符
root:x:0:0:root:/root:/bin/bash
hello
world
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin意思:匹配以 root开头 a\ (格式,下一行新建行写入)
查看 d p 的作用,删除第1到2行 ,从第一行开始,每隔一行进行打印 里面包括简单的地址范围
[root@dj ~]# sed '1,2d' /tmp/passwd
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin[root@dj ~]# sed '1~2p' /tmp/passwd
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
地址范围难点 正则表达式
匹配以root开头的所有行并打印
[root@dj tmp]# sed -r '/^root/p' /tmp/passwd
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin匹配以root开头那一行开始 以^b为开头那一行为结尾,打印
[root@dj tmp]# sed -r '/^root/,/^b/p' /tmp/passwd
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin匹配从r开头那一行开始,到b开头 n结尾那一行结束并打印
[root@dj tmp]# sed -r '/^root/,/^b.*n$/p' /tmp/passwd
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
替换内容 难点 s/// ,如果替换内容有 / ,可以改成 s###测试
cat 1.txt ## 查看原文件内容
hello like
my love [root@dj tmp]# sed -r 's/l..e/&r/' 1.txt ## &代表前面的 l..e 即like和love
hello liker
my lover[root@dj tmp]# sed -r 's/l(.)(.)e/\2\1s/' 1.txt
hello kis ## 难点:ik 和 ov满足匹配,并被分为两组
my vos ## 将匹配的内容,替换成 正则的 第二组 + 第一组 加 r## i 是第一组 k是第2组 ,第二行的o是第一组,v是第二组删除每一行倒数第二个字符
[root@dj tmp]# sed -r 's#(.)(.)$#\2#' /tmp/passwd
root:x:0:0:root:/root:/bin/bah
bin:x:1:1:bin:/bin:/sbin/nologn
daemon:x:2:2:daemon:/sbin:/sbin/nologn## 匹配倒数最后两个字符分两组,然后替换成第2组,第1组(倒数第二个字符)就没了将passwd文件的每一行 第二个字符和倒数第二个字符替换
sed -r -e 's/^(.)(.)(.*)(.)(.)$/\1\4\3\2\5/' passwd ## 无-e也行,只有一个子命令注意:在这里如果要\1\2之间有空格,可使用空格键和 \t,\s不行,会和s一样在 \1 \2 之间输出s,因为s有替换的功能,\s相当于转义成s
15.9 awk 命令
15.9.1 awk 命令简介
1、awk的特点和作用
格式化文本,对文本进行比较复杂的格式处理(此格式化是变成有格式,而不是删除内容的格式化)
2、awk的程序结构(也就是语法结构)
语法:awk 选项 ‘BEGIN{命令} pattern{命令}END{命令}’ 文件名
AWK 是一种解释执行的编程语言,它非常的强大,被设计用来专门处理文本数据。
AWK 的名称是由它们设计者的名字缩写而来 —— Afred Aho, Peter Weinberger 与 Brian Kernighan。
GNU/Linux 发布的 AWK 版本通常被称之为 GNU AWK,由自由软件基金( Free Software Foundation, FSF)负责开发维护的
目前总共有如下几种不同的 AWK 版本。
AWK 这个版本是 AWK 最原初的版本,它由 AT&T 实验室开发。
NAWK NAWK(New AWK)是 AWK 的改进增强版本。
GAWK GAWK 即 GNU AWK,所有的 GNU/Linux 发行版都包括 GAWK,且 GAWK 完全兼容 AWK 与 NAWK。
CentOS 7 中,<awk命令>就是<gawk命令>的<符号链接文件>
★ AWK 可以做非常多的工作,下面只是其中的一小部分:
文本处理
生成格式化的文本报告
进行算术运算
字符串操作
以及其它更多
15.9.2 awk 工作原理
★ AWK 执行的流程非常简单:读(Read)、执行(Execute)与重复(Repeat)
★ AWK 分为三个功能代码块:
(1) BEGIN {…;…;…}开始块 ☚ 可选
(2) pattern {…;…;…}主体块 ☚ 必选 重要
(3) END {…;…;…} 结束块 ☚ 可选
15.9.3 awk 基本运用
1 原理
1. 了解:BEGIN {…;…;…} 开始块
注意:<BEGIN开始块>是可选的,你的程序可以没有<BEGIN开始块>。
开始块的语法: BEGIN {awk-commands}
同一行多个<awk子命令>用<;分号>隔开
功能:顾名思义,<开始块>就是在<程序启动>时的<执行代码>,并且它在<整个过程>中只<执行一次>。
一般情况下,我们在<开始块>中<初始化>一些<变量>,BEGIN 是 AWK 的关键字,因此它必须是大写的。
2 了解 pattern {…;…;…} 主体块 (重要)
主体块是必有的
主体部分的语法: pattern {awk-commands}
同一行多个<awk子命令>用<;分号>隔开
在<主体块>没有<关键字>的存在,pattern 表示<模> ,但是pattern不是关键字。(使用awk不用写,默认’ ’ 里面就是主体块)
功能:对于<每一个输入的行>都会执行一次<主体部分的命令>,但是,我们可以将其限定在指定的<pattern模>中。
<pattern模>可以是:
/正则表达式/ awk '/pattern/ {print $0}' file ## 打印 主体块的全部内容
关系表达式 awk 'END{print $0}' file ## 打印最后一行
多个 pattern模 的运用:
pattern1&&pattern2 ## 表示逻辑与(AND),既要匹配pattern1,也要匹配pattern2
pattern1||pattern2 ## 表示逻辑或(OR),或者匹配pattern1,或者匹配pattern2
pattern1?pattern2:pattern3 ## 表示如果pattern1匹配为ture,则执行 pattern2匹配,否则,则执行 pattern3匹配
(pattern) ## 表示限定pattern的范围
!pattern ## 表示不匹配pattern
pattern1,pattern2 ## 表示从匹配pattern1的行开始,到匹配pattern2的行结束## 通过<正则表达式>来表示<一个字段的结尾>,可以使用<$符号>,因为awk将<每一个字段>当做<一个个的小行>。
例子
cat >1.txt <<EOF
tcp 1.2.3.4
tcp6 1.2.3.4
EOF匹配第一个字段以tcp字符串结尾的行
[root@dj tmp]# cat 1.txt | awk '$1~/tcp$/{print}'
tcp 1.2.3.4## ~/tcp$/ 表示正则匹配以 tcp 结尾的字符串匹配第一字段(列)以6结尾的行
[root@dj tmp]# cat 1.txt | awk '$1~/6$/{print}'
tcp6 1.2.3.4## ~ 表示后面正则匹配的对象是匹配前面的内容,而不是全文匹配,这里是对第一字段进行匹配
3. 了解:END {…;…;…} 结束块
注意:<END结束块>是可选的,你的程序可以没有<END结束块>。
结束块的语法: END {awk-commands} ☚ 同一行多个<awk子命令>用<;分号>隔开
顾名思义,<结束块>是在程序结束时执行的代码,并且它在整个过程中只执行一次。
END 也是 AWK 的关键字,它也必须大写。
2 awk 简单语法和例子
用法选项介绍
可以精准定义 某一行某一列的某一内容。
语法 awk ’ {print } ’ 1.txt
注意: { } 外面左边匹配行,NR匹配行号 或者 ~匹配正则,定义行 。{ }里面匹配列(字段)
语法:
awk 选项 ‘’ 文件名 注意:’ '里面写操作命令或者内置变量,比如 ‘NR==1 {print $1}’
命令 | awk 选项 ‘’
命令 | xargs awk 选项 ‘’
选项:
-F ## 指定分割符,不写默认以空白为分隔符 常用
例如
-F ":" ,以:为分隔符
-F ":|/" ,以:或者 / 作为分隔符-v ## 自定义变量
内置变量:
NR ## 指定行 默认全部行 ## 如 NR==2 文件第二行, NR > 2 第三行到结尾 {print NR}输出行号
\t ## 是TAB键
\n ## 是换行符
$1 ## 是内置变量,$0表示一整行,$1表示每行的第1列,$2表示每行的第2列
$0这个变量包含执行过程中当前行的文本内容NF 表示每一行的字段数,默认分隔符是空白 {print NF} 打印每行的字段数
$NF 当前行最后一个字段的值 {print $NF} 打印每一行最后一个字段
$(NF-1) 当前行倒数第二个字段的值FIELDWIDTHS ## 定义每个数据字段宽度
FS ## 输入列字段分隔符(默认是空格)
RS ## 输入行分隔符(默认是换行符\n)
OFS ## 输出列字段分隔符(默认值是空格),可替换分隔符输出,不能修改源文件
ORS ## 输出行分隔符(默认值是换行符\n)
例子: 不常用
OFS: 也是修改分隔符,不过在BEGIN 里面使用 例如 把 :作为分隔符,并改成 @ 显示出来
[root@dj tmp]# awk -F ":" 'BEGIN{OFS="@"} {print $1,$2,$4}' passwd
root@x@0
bin@x@1
daemon@x@2if (条件表达式){动作}else if(条件表达式){动作}else{动作}
awk -F ":" '{if($3==0){print $0" 这是root用户"}else if(($3>0)&&($3<1000)){print $0" 这是系统用户"}else{print $0" 这是普通用户"}}' /etc/passwd案例:
awk '{max=$1;for(i=2;i<=4;i++){if($i>max){max=$i}}print max}' /tmp/number
awk -F : 'NR==1{for(i=1;i<=NF;i++){print $i}}' /etc/passwd
1 主体用法案例
下面语法都是只使用了 主体 而没有使用 BEGIN 和 END
例子 自定义变量
用户自定义变量
定义变量和引用变量,均不需要加$符号(推荐使用小写)
例子:
[root@exercise1 opt]# awk 'BEGIN{var="1"}{print var}' a2.txt
1
1
使用选项定义变量
[root@exercise1 opt]# awk -v var=1 '{print var}' a2.txt
1
1
## 有多少行就输出多少个1,在主体里面有多少行 就打印多少次打印passwd行数
awk '{n++;}END{print n}' /etc/passwd
或者
awk -v n=0 '{n++}END{print n}' passwd
例子 NR
打印passwd文件的奇数行和偶数行 还有行号显示
awk 'NR%2==0{print NR,$0}' /tmp/passwd ## 偶数行 括号里面的 NR 表示打印行号
awk 'NR%2!=0{print NR,$0}' /tmp/passwd ## 注意:$0 是打印全部内容把第一行的字段换行显示出来
awk -F : 'NR==1{for(i=1;i<=NF;i++){print $i}}' /etc/passwd
例子 -F 和 print 还有 printf
df -h | awk '{print $5}' ## 输出每一行的第五字段的内容
awk -F ":" '{print "随便输出"}' passwd ## 输出每一行,写着 随便输出 ,有多少行就输出多少个 随便输出
awk -F ":/" '{print $1}' passwd ## 输出以 :/ 作为分隔符的第一个字段
awk -F ":|/" '{print $1}' passw ## 输出以 : 或者 / 为分隔符 的第一字段## 注意:如果两个分隔符连在一起,那么会假设两分隔符之间的内容是空白,会输出空白行指定 df -h 的第6行 第5字段(列),默认是空格为分隔符
[root@dj tmp]# df -h | awk 'NR==6{print "你的根分区用了"$5}'
你的根分区用了0% 大于第2行的每一行的第5字段打印出来
df -h | awk 'NR>2{print "你的根分区用了"$5}' 自定义第1字段占15字符左对齐,第7字段左对齐
awk -F ":" '{printf "%15-s %-s\n",$1,$5}' passwd ## 类似于c语言输出, %s 表示 十进制整数 %-s 表示左对齐 %8-s 表示左对齐,且占8个字符位置
查工资
[root@dj tmp]# cat 1.txt
工资条
姓名 工号 银行卡号 基本工资 绩效 五险一金
小明 121 45678789 3500 5000 -1000
小小明 123 45678987 2500 3000 -800
[root@dj tmp]# awk 'NR>2{print $1"的工资是"$4+$5+$6}' 1.txt
小明的工资是7500
小小明的工资是4700
2 BEGIN+主体+END 结合使用案例
## 创建一个名为 test.txt 的文件(其中包括序列号、学生名字、课程名称与所得分数)。
cat > /tmp/test.txt <<EOF
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
EOF[root@dj ~]# awk '($4>=80)&&($4<86){print}' /tmp/test.txt
1) Amit Physics 80
4) Kedar English 85## 输出<文件中的内容>,同时输出<表头信息>即输出 序号 姓名 课程 分数
[root@dj ~]# awk 'BEGIN {printf "序号\t姓名\t课程\t分数\n"} {print $1"\t"$2"\t"$3"\t"$4} END {print "###打印结束###"}' /tmp/test.txt
序号 姓名 课程 分数
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
###打印结束###示例6:##pattern1?pattern2:pattern3(条件表达式)
条件?满足就做这个:不满足就做这个
## 显示Amit同学成绩大于等于80成绩单,同时,也显示成绩大于等于90的其他同学的成绩单
awk '/Amit/?($4>=80):($4>=90){print}' /tmp/test.txt示例7:!pattern(逻辑非)
## 显示非English课程的成绩单
awk '!/English/{print}' ~/test.txt示例8:pattern1,pattern2(地址对)
## 显示成绩单中从Amit同学到Shyam同学的行
awk '/Amit/,/Shyam/{print}' /tmp/test.txt## 创建一个名为 students.txt 的文件(其中包括学生名字、性别、籍贯、年龄)。
cat >/tmp/students.txt <<EOF
张三 男 湖北 12岁
李丽 女 湖北 12岁
李丽 女 山西 12岁
李丽 女 北京 12岁
王五 男 湖北 12岁
EOF
[root@dj ~]# awk 'BEGIN{print "姓名\t性别\t地址\t年龄"} {print $1"\t"$2"\t"$3"\t"$4} END{print "##原神玩家列表##"}' /tmp/students.txt
姓名 性别 地址 年龄
张三 男 湖北 12岁
李丽 女 湖北 12岁
李丽 女 山西 12岁
李丽 女 北京 12岁
王五 男 湖北 12岁
##原神玩家列表##
判断问题
判断uid小于等于10 输出 aaa 大于10 输出 bbb (多个方法)
awk -F: '{$3<10?USER="aaa":USER="bbb";print $1,USER}' /etc/passwd判断uid小于等于10 输出 user 大于10 输出 pass
awk -F: '{if($3<10){print "user=>"$1}else{print "pass=>"$1}}' /etc/passwd判断 普通用户系统用户root用户
awk -F ":" '{if($3==0){print $0" 这是root用户"}else if(($3>0)&&($3<1000)){print $0" 这是系统用户"}else{print $0" 这是普通用户"}}' /etc/passwd
3 awk 的变量使用
[root@server144 ~]# echo $name ## 这里的 $ 是通配符
root
[root@server144 ~]# cat /etc/passwd|awk -F ':' '/^$name/{print $1}'
## 开了正则 $ 是正则
[root@server144 ~]# cat /etc/passwd|awk -F ':' '/^\$name/{print $1}'
## 转义了 是$ ,无任何意义
[root@server144 ~]# cat /etc/passwd|awk -F ':' '/^"$name"/{print $1}'
## 无法输出 和 第一条一样
[root@server144 ~]# cat /etc/passwd|awk -F ':' '/^'$name'/{print $1}'
## 成功
root
15.10 函数的使用
函数的声明
语法1:
function 变量名 {
命令
}
语法2:
变量名(){
命令
}
#!/bin/bash
sbsb(){echo "eb"}echo "6666666"
sbsb
声明函数 sbsb 并使用
函数的传参
例子
#!/bin/bash
a(){
echo "$1 $2 $3 "
}
a 123 $2 789
[root@dj tmp]# bash 7.sh abc 456 awfa
123 456 789
对于脚本来说 $1 是固定123 $3 是固定 789 ,而$2 没有规定,在运行脚本后面的 $2的位置 是456
相关文章:
第十五章 Linux Shell 编程
15.1 Shell 变量 了解:Shell的功能 了解:Shell的种类 了解:Shell的调用 了解:Shell变量的概念 了解:Shell变量的定义 了解:Shell数组变量 了解:Shell内置变量 了解:双引号 和…...
)
【c++笔试强训】(第三十八篇)
目录 不相邻取数(动态规划-线性dp) 题目解析 讲解算法原理 编写代码 空调遥控(⼆分/滑动窗⼝) 题目解析 讲解算法原理 编写代码 不相邻取数(动态规划-线性dp) 题目解析 1.题目链接:不相…...

go 自己写序列化函数不转义
以map[int32]string转化为[]byte为例 背景:算法传给我一个map[int32]string类型的值(map的值本身是json转化成的string),我需要把这个值生成一个文件上传到OSS,但是发现通过url下载下来的文件里面有转义字符。 原因&a…...

一般行业安全管理人员考试题库分享
1.在高速运转的机械飞轮外部安装防护罩,属于(B)安全技术措施。 A.限制能量 B.隔离 C.故障设计 D.设置薄弱环节 2.生产经营单位的(B)是本单位安全生产的第一责任人,对落实本单位安全生产主体责任全面负责,具体履行安全生产管理职责。 A.全员 B…...

Marketo REST API 批量修改邮件内容
以下是更加细化的 使用 Marketo REST API 批量修改邮件内容 的步骤,详细解释每个阶段的操作,包括 API 的请求、数据处理及潜在问题解决。 前期准备工作 确保 Marketo API 访问权限 你需要 Marketo REST API 用户 和 API Role,有权限访问邮件资…...

《云原生安全攻防》-- K8s安全框架:认证、鉴权与准入控制
从本节课程开始,我们将来介绍K8s安全框架,这是保障K8s集群安全比较关键的安全机制。接下来,让我们一起来探索K8s安全框架的运行机制。 在这个课程中,我们将学习以下内容: K8s安全框架:由认证、鉴权和准入控…...

淘宝获取sku详细信息 API
淘宝获取 SKU 详细信息的 API 主要是 taobao.item_sku 接口,以下是详细介绍: 公共参数 key:调用 key,是调用接口的身份验证信息,必须以 GET 方式拼接在 URL 中1.secret:调用密钥,与 key 配合使…...

基于Spring Boot的体育商品推荐系统
一、系统背景与目的 随着电子商务的快速发展和人们健康意识的提高,体育商品市场呈现出蓬勃发展的态势。然而,传统的体育商品销售方式存在商品种类繁多、用户选择困难、个性化需求无法满足等问题。为了解决这些问题,基于Spring Boot的体育商品…...

C++小细节笔记
1、C字符串转数字 – 数字转字符串 //string > int 使用 stoi stol//int > string 使用 to_string()2、C遍历 int evalRPN(vector<string>& tokens) {stack<int> intStack;for(string &str:tokens){}bool isValid(string s) {stack<char> …...
)
go语言并发读写数据队列,不停写的同时,一次最多读取指定量数据(逐行注释)
1、数据队列可以存储任意类型的一个数据(下程序是添加整数值)。 数据队列代码点这里查看《go语言结构体实现数据结构队列(先进先出)存储数据(逐行注释)》 2、读写操作并发进行(下程序向队列中…...
密码学——密码学概述、分类、加密技术(山东省大数据职称考试)
大数据分析应用-初级 第一部分 基础知识 一、大数据法律法规、政策文件、相关标准 二、计算机基础知识 三、信息化基础知识 四、密码学 五、大数据安全 六、数据库系统 七、数据仓库. 第二部分 专业知识 一、大数据技术与应用 二、大数据分析模型 三、数据科学 密码学 大数据…...
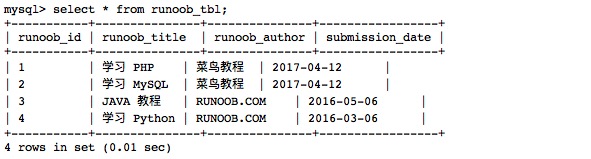
【数据库MySQL篇二】MySQL数据库入门基础教程:一网打尽数据库和表各种操作、命令和语法
一、MySQL创建数据库 使用Create命令创建数据库 我们可以在登陆 MySQL 服务后,使用 create 命令创建数据库,语法如下: CREATE DATABASE 数据库名; 以下命令简单的演示了创建数据库的过程,数据名为 RUNOOB: [roothost]# mysql -u root -p…...

Android 解决“Could not resolve all artifacts for configuration ‘:classpath‘方法
前些天发现了一个蛮有意思的人工智能学习网站,8个字形容一下"通俗易懂,风趣幽默",感觉非常有意思,忍不住分享一下给大家。 👉点击跳转到教程 报错背景,公司的项目,长时间没有打开,时隔半年再次打…...

青少年编程与数学 02-004 Go语言Web编程 08课题、使用Gin框架
青少年编程与数学 02-004 Go语言Web编程 08课题、使用Gin框架 一、Gin框架二、接收和处理请求三、应用示例 课题摘要:本文介绍了Gin框架的特点、如何接收和处理请求以及一个应用示例。Gin是一个高性能、轻量级的Go语言Web框架,以其快速、极简设计、强大的路由和中间…...

PostgreSQL: 事务年龄
排查 在 PostgreSQL 数据库中,事务年龄(也称为事务 ID 年龄)是一个重要的监控指标,因为 PostgreSQL 使用事务 ID(XID)来保持事务的隔离性。每个事务都会被分配一个唯一的事务 ID,这个 ID 随着每…...

C# 识别二维码
文章目录 一. 二维码识别技术概述二 维码识别的步骤图像预处理二维码的定位和检测二维码解码 三 常用的二维码识别库1. OpenCV2. ZXing.Net 一. 二维码识别技术概述 二维码是一种通过黑白矩阵排列来编码数据的图形符号,它的编码方式具有较强的容错性,可以…...

KeepAlive与RouterView缓存
参考 vue动态组件<Component>与<KeepAlive> KeepAlive官网介绍 缓存之keep-alive的理解和应用 Vue3Vite KeepAlive页面缓存问题 vue多级菜单(路由)导致缓存(keep-alive)失效 vue3 router-view keeperalive对于同一路径但路径…...

RK3588 , mpp硬编码rgb, 保存MP4视频文件.
RK3588 , mpp硬编码yuv, 保存MP4视频文件. ⚡️ 传送 ➡️ RK3588, FFmpeg 拉流 RTSP, mpp 硬解码转RGBRk3588 FFmpeg 拉流 RTSP, 硬解码转RGBUbuntu x64 架构, 交叉编译aarch64 FFmpeg mppCode Init MppMPP_RET init_mpp...

使用 Wireshark 和 Lua 脚本解析通讯报文
在复杂的网络环境中,Wireshark 凭借其强大的捕获和显示功能,成为协议分析不可或缺的工具。然而,面对众多未被内置支持的协议或需要扩展解析的场景,Lua 脚本的引入为Wireshark 提供了极大的灵活性和可扩展性。本文将详细介绍如何使…...

ElasticSearch08-分析器详解
零、文章目录 ElasticSearch08-分析器详解 1、分析器原理 Elasticsearch的分词器(Analyzer)是全文搜索的核心组件,它负责将文本转换为一系列单词(term/token)的过程,也叫分词。 (1ÿ…...

逆向工程实现原理深度解析:Hook技术高效突破百度网盘macOS版系统限制
逆向工程实现原理深度解析:Hook技术高效突破百度网盘macOS版系统限制 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS BaiduNetdiskPlugin-m…...

探索汽车LAR LQG半主动/主动悬架:基于Simulink的奇妙之旅
汽车lar lqg 半主动/主动悬架 simulink在汽车工程领域,悬架系统犹如车辆的“脚”,直接影响着行驶的平顺性和安全性。今天咱们就来唠唠汽车的LAR LQG半主动/主动悬架,顺便用Simulink来比划比划。 LAR LQG悬架原理简述 LAR(Linear …...

抖音视频批量下载终极指南:5分钟掌握高效下载技巧
抖音视频批量下载终极指南:5分钟掌握高效下载技巧 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

Step3-VL-10B效果展示:10B轻量级模型实现媲美大模型的视觉语言推理能力
Step3-VL-10B效果展示:10B轻量级模型实现媲美大模型的视觉语言推理能力 1. 引言:当“小个子”拥有了“大智慧” 想象一下,你面前有一张复杂的科学图表、一份手写的数学笔记,或者一个满是按钮的软件界面。你能看懂多少࿱…...


BilibiliDown:如何轻松搞定B站视频下载与批量管理的完整指南
BilibiliDown:如何轻松搞定B站视频下载与批量管理的完整指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mir…...

毫米波雷达开发者必看:双级联方案如何用DDMA波形实现300米精准测距?
毫米波雷达双级联方案实战:DDMA波形设计如何突破300米测距极限? 当特斯拉HW4.0的雷达模块在暴雨中依然稳定输出300米外的障碍物坐标时,背后的技术密码正是双级联架构与DDMA波形的完美融合。作为L3级自动驾驶系统的"全天候之眼"&am…...

MediaPipe模型离线部署与本地Demo实战指南
1. MediaPipe模型离线部署全攻略 遇到MediaPipe模型下载失败的问题,相信不少开发者都踩过这个坑。特别是在内网环境或者网络不稳定的情况下,官方自动下载功能经常无法正常工作。我去年在给某制造企业部署智能质检系统时就遇到过类似情况,他们…...

从ARXML文件反推软件架构:一个ComM模块的配置实例如何映射到你的C代码
从ARXML到C代码:ComM模块配置的逆向工程实战 当你第一次打开ComM_Cfg_SWCD.arxml文件时,那些层层嵌套的XML标签是否让你感到无从下手?作为AUTOSAR开发中最关键的配置文件之一,ARXML实际上是一张精确的"施工图纸"&#x…...

Joy-Con Toolkit开源工具:Switch手柄深度定制与性能优化方案
Joy-Con Toolkit开源工具:Switch手柄深度定制与性能优化方案 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit Joy-Con Toolkit是一款面向任天堂Switch玩家的开源手柄管理工具,提供专业级传…...