【模型压缩】原理及实例
在移动智能终端品类越发多样的时代,为了让模型可以顺利部署在算力和存储空间都受限的移动终端,对模型进行压缩尤为重要。模型压缩(model compression)可以降低神经网络参数量,减少延迟时间,从而实现提高神经网络推理速度、节省存储空间等目的。
一.量化
量化是指将模型权重参数用更少的比特数存储,以此来减少模型的存储空间和算力消耗。
1.基本原理
(1) 量化感知训练
Quantization-aware Training,QAT在训练过程中模拟量化过程,数据虽然表示为float32,但实际的值的间隔却会受到量化参数的设置。
QAT的具体流程如下:
1)初始化:设置权重和激活值范的范围和
的初始值;
2)构建模拟量化网络:在需要量化的权重和激活值后插入伪量化算子;
3)量化训练:重复执行以下步骤直至网络收敛(计算量化网络层的权重和激活值的范围和
,并根据该范围将量化损失带入到前向推理和后向参数更新的过程中);
4)导出量化网络:获取和
,并计算量化参数,将量化参数s和z代入到量化公式中,转换网络中的权重为量化整数值;删除伪量化算子,在量化网络层前后分别插入量化和反量化算子。
(2) 后训练动态量化
Post training dynamic quantization是在浮点模型训练收敛之后进行量化操作,weight被提前量化,activation在前向推理过程中被动态量化(即每次都要根据实际运算的浮点数据范围每一层计算1次scale和zero_point,然后进行量化)。
在量化激活值时会以校准数据集为输入,执行推理流程然后统计每层激活值的数据分布并得到相应的量化参数,具体操作流程如下:
1)使用直方图统计的方式得到原始float32数据的统计分布;
2)在给定的搜索空间中选取若干个和
分别对激活值进行量化,得到量化后的数据
;
3)使用直方图统计得到的统计分布;
4)计算每个与
的统计分布差异,并找到差异性最低的1个对应的
和
来计算相应的量化参数;常用的用于度量分布差异的指标包括KL散度、对称KL散度和JS散度。
(3) 后训练静态量化
activation会基于之前校准过程中记录下的固定的scale和zero_point进行量化,整个过程不存在量化参数(scale,zero_point)的再计算。
2.代码实例
(1) 加载数据
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
from torch.quantization import QuantStub, DeQuantStub
import torch.optim as optim
from torch.quantization import get_default_qconfig, prepare_qat, convert# 定义数据预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化
])# 加载训练集和测试集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)
testloader = DataLoader(testset, batch_size=64, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')(2) 构建量化网络
class QuantizedCNN(nn.Module):def __init__(self):super(QuantizedCNN, self).__init__()self.quant = QuantStub()self.conv1 = nn.Conv2d(3, 16, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(16, 32, 5)self.fc1 = nn.Linear(32 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)self.dequant = DeQuantStub()def forward(self, x):# x = self.quant(x)x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = torch.flatten(x, 1)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)x = self.dequant(x)return xdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = QuantizedCNN().to(device)
model.qconfig = get_default_qconfig('qnnpack')(3) 量化训练并保存模型
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):model.train()running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = data[0].to(device), data[1].to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()if i % 2000 == 1999:print(f'[{epoch + 1}, {i + 1}] loss: {running_loss / 2000:.3f}')running_loss = 0.0# 切换到评估模式进行测试model.eval()correct = 0total = 0with torch.no_grad():for data in testloader:images, labels = data[0].to(device), data[1].to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))# 在最后1个epoch后完成量化if epoch == num_epochs - 1:model_quantized = convert(model.eval(), inplace=True)print("Model quantization completed.")# 保存量化模型torch.save(model_quantized.state_dict(), 'quantized_model.pth')
(4) 模型测试
def test_quantized_model(model, dataloader, device='cpu'):model = convert(model.eval(), inplace=True)model.to(device) correct = 0total = 0with torch.no_grad(): for data, targets in dataloader:data, targets = data.to(device), targets.to(device) outputs = model(data) _, predicted = torch.max(outputs.data, 1) total += targets.size(0)correct += (predicted == targets).sum().item()accuracy = 100 * correct / totalprint(f'Accuracy of the quantized model on the test data: {accuracy:.2f}%')# 测试模型
quantized_model=QuantizedCNN()
quantized_model.load_state_dict(torch.load('quantized_model.pth'))
test_quantized_model(quantized_model, test_loader, device='cuda' if torch.cuda.is_available() else 'cpu'二.剪枝
剪枝是指去除模型参数中冗余或不重要的部分,可以高效地生成规模更小、内存利用率更高、能耗更低、推断速度更快的模型。

1.基本原理
根据剪枝流程的位置,可以将剪枝操作分为2种:训练时剪枝和后剪枝。
(1) 训练时剪枝
和训练时使用dropout操作较为类似,训练时剪枝会根据当前模型的结果,删除不重要的结构,固化模型再进行训练,以后续的训练来弥补部分结构剪枝带来的不利影响。
(2) 后剪枝
在模型训练完成后,根据模型权重参数和剪枝测试选取需要剪枝的部分。
2.代码实例
(1) 加载预训练模型
import torch
import torchvision.models as models# 加载预训练的ResNet18模型
model = models.resnet18(pretrained=True)
(2) 定义剪枝算法
from torch.nn.utils.prune import global_unstructured# 定义剪枝比例
pruning_rate = 0.5# 对全连接层进行剪枝
def prune_model(model, pruning_rate):for name, module in model.named_modules():if isinstance(module, torch.nn.Linear):global_unstructured(module, pruning_dim=0, amount=pruning_rate)
(3)执行剪枝操作
prune_model(model, pruning_rate)# 查看剪枝后的模型结构
print(model)
(4) 重新训练和微调
剪枝后的模型需要重新进行训练和微调,以保证模型的准确性和性能。
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)(5) 性能测试
三.蒸馏
蒸馏是指将知识从大模型(教师模型)向小模型(学生模型)传输的过程,可以用于模型压缩和训练加速。核心组件包括:知识(knowledge)、蒸馏算法(distillation algorithm)、教师学生架构(teacher-student architecture)。

1.基本原理
蒸馏的知识的形式可以是:激活、神经元、中间层特征、教师网络参数等。可将其归类为以下3种类型。

(1) Feature-Based Knowledge
基于特征的知识蒸馏引入中间层表征,教师网络的中间层作为学生网络对应层的提示(Hints层),从而提升学生网络模型的性能。核心是期望学生能够直接模仿教师网络的特征激活值。

(2) Relation-Based Knowledege
基于关系的知识蒸馏可以分为不同层之间的关系建模和不同样本之间的关系建模2种。
•不同层之间的关系建模
通常可以建模为:
![]()
其中,,
表示学生网络内成对的特征图,
,
是相似度函数,
代表教师网络与学生网络的关联函数。
•不同样本之间的关系建模

建模如下:
![]()
其中,,
分别是teacher和student模型的特征表示;
,
。
基于关系的知识蒸馏的具体算法如下表所示。

(3) Response-Based Knowleddge
基于响应的知识蒸馏里响应一般指的是神经元的响应,即教师模型的最后1层逻辑输出。核心想法是让学生模型模仿教师网络的输出。

响应知识的loss:

Hinton提出的KD是将teacher的logits层作为soft label:

T是用于控制soft target重要程度的超参数。
整体蒸馏loss可以写作:
![]()
2.代码实例
(1) 加载数据
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()# Normalize data
x_train = x_train.astype("float32") / 255.0
x_train = np.reshape(x_train, (-1, 28, 28, 1))x_test = x_test.astype("float32") / 255.0
x_test = np.reshape(x_test, (-1, 28, 28, 1))(2) 构建teacher 、student模型结构
# Create the teacher
teacher = keras.Sequential([keras.Input(shape=(28, 28, 1)),layers.Conv2D(256, (3, 3), strides=(2, 2), padding="same"),layers.LeakyReLU(alpha=0.2),layers.MaxPooling2D(pool_size=(2, 2), strides=(1, 1), padding="same"),layers.Conv2D(512, (3, 3), strides=(2, 2), padding="same"),layers.Flatten(),layers.Dense(10),],name="teacher",
)# Create the student
student = keras.Sequential([keras.Input(shape=(28, 28, 1)),layers.Conv2D(16, (3, 3), strides=(2, 2), padding="same"),layers.LeakyReLU(alpha=0.2),layers.MaxPooling2D(pool_size=(2, 2), strides=(1, 1), padding="same"),layers.Conv2D(32, (3, 3), strides=(2, 2), padding="same"),layers.Flatten(),layers.Dense(10),],name="student",
)# Clone student for later comparison
student_scratch = keras.models.clone_model(student)(3) 训练模型
# 1.Train teacher as usual
teacher.compile(optimizer=keras.optimizers.Adam(),loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Train and evaluate teacher on data.
teacher.fit(x_train, y_train, epochs=3)
teacher.evaluate(x_test, y_test)# 2.Train student as usual
student_scratch.compile(optimizer=keras.optimizers.Adam(),loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Train and evaluate student on data
student_scratch.fit(x_train, y_train, epochs=3)
student_scratch.evaluate(x_test, y_test)(4) 构建蒸馏模型
class Distiller(keras.Model):def __init__(self, student, teacher):super(Distiller, self).__init__()self.teacher = teacherself.student = studentdef compile(self,optimizer,metrics,student_loss_fn,distillation_loss_fn,alpha=0.1,temperature=3,):super(Distiller, self).compile(optimizer=optimizer, metrics=metrics)self.student_loss_fn = student_loss_fnself.distillation_loss_fn = distillation_loss_fnself.alpha = alphaself.temperature = temperaturedef train_step(self, data):# Unpack datax, y = data# Forward pass of teacherteacher_predictions = self.teacher(x, training=False)with tf.GradientTape() as tape:# Forward pass of studentstudent_predictions = self.student(x, training=True)# Compute lossesstudent_loss = self.student_loss_fn(y, student_predictions)# Compute scaled distillation lossdistillation_loss = (self.distillation_loss_fn(tf.nn.softmax(teacher_predictions / self.temperature, axis=1),tf.nn.softmax(student_predictions / self.temperature, axis=1),)* self.temperature**2)loss = self.alpha * student_loss + (1 - self.alpha) * distillation_loss# Compute gradientstrainable_vars = self.student.trainable_variablesgradients = tape.gradient(loss, trainable_vars)# Update weightsself.optimizer.apply_gradients(zip(gradients, trainable_vars))# Update the metrics configured in `compile()`.self.compiled_metrics.update_state(y, student_predictions)# Return a dict of performanceresults = {m.name: m.result() for m in self.metrics}results.update({"student_loss": student_loss, "distillation_loss": distillation_loss})return resultsdef test_step(self, data):# Unpack the datax, y = data# Compute predictionsy_prediction = self.student(x, training=False)# Calculate the lossstudent_loss = self.student_loss_fn(y, y_prediction)# Update the metrics.self.compiled_metrics.update_state(y, y_prediction)# Return a dict of performanceresults = {m.name: m.result() for m in self.metrics}results.update({"student_loss": student_loss})return results(5)蒸馏
# Train student as doen usually
student_scratch.compile(optimizer=keras.optimizers.Adam(),loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=[keras.metrics.SparseCategoricalAccuracy()],
)# Train and evaluate student trained from scratch.
student_scratch.fit(x_train, y_train, epochs=1)
student_scratch.evaluate(x_test, y_test)四.参考
(1) Knowledge Distillation: A Survey
相关文章:

【模型压缩】原理及实例
在移动智能终端品类越发多样的时代,为了让模型可以顺利部署在算力和存储空间都受限的移动终端,对模型进行压缩尤为重要。模型压缩(model compression)可以降低神经网络参数量,减少延迟时间,从而实现提高神经…...

常用的JVM启动参数有哪些?
大家好,我是锋哥。今天分享关于【常用的JVM启动参数有哪些?】面试题。希望对大家有帮助; 常用的JVM启动参数有哪些? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 JVM(Java Virtual Machine)启…...

Curvelet 变换与FDCT
Curvelet变换 Curvelet变换 是一种多尺度、多方向的信号分析工具,专门用于处理具有各向异性特征的信号,例如边缘和曲线。与传统的傅里叶变换和小波变换相比,Curvelet变换能够更精确地表示信号中的曲线特征,因此在图像处理、地震数据分析、医学成像等领域得到了广泛应用。 …...
Django Admin 管理工具
Django 提供了基于 web 的管理工具。 Django 自动管理工具是 django.contrib 的一部分。你可以在项目的 settings.py 中的 INSTALLED_APPS 看到它: /HelloWorld/HelloWorld/settings.py 文件代码: INSTALLED_APPS ( django.contrib.admin, django.co…...

Android笔记【19】
具体示例 run: val result someObject.run {// 这里可以使用 thisthis.someMethod() }let: val result someObject?.let {// 这里使用 itit.someMethod() }with: val result with(someObject) {// 这里使用 thissomeMethod() }apply: val obj SomeClass().apply {// 这里使…...
矩阵在资产收益(Asset Returns)中的应用:以资产回报矩阵为例(中英双语)
本文中的例子来源于: 这本书,网址为:https://web.stanford.edu/~boyd/vmls/ 矩阵在资产收益(Asset Returns)中的应用:以资产回报矩阵为例 在量化金融中,矩阵作为一种重要的数学工具,被广泛用于描述和分析…...

Docker 中如何限制CPU和内存的使用 ?
在容器化的动态世界中,Docker 已经成为构建、部署和管理容器化的关键工具应用。然而,Docker 的效率在很大程度上取决于资源管理得有多好。设置适当的内存和 CPU 限制对于优化 Docker 性能至关重要,确保每个容器在不使主机负担过重的情况下获得…...

【AIGC-ChatGPT进阶提示词-《动图生成》】怪物工厂:融合想象力与创造力的奇幻世界
引言 在这个科技飞速发展的时代,人工智能正在不断突破我们的想象。而在众多AI应用中,有一个独特的创意工具正在悄然兴起,它就是"怪物工厂"。这个神奇的工具能够将人类天马行空的想象力与AI的创造力完美结合,打造出一个个奇异、有趣、甚至有些恐怖的怪物形象。本…...

docker 使用 xz save 镜像
适用场景 如果docker save -o xxx > xxx 镜像体积过大,可以使用 xz 命令压缩。 命令 例如 save busybox:1.31.1 镜像,其中 -T 是使用多核心压缩,可以加快压缩。 docker save busybox:1.31.1 |xz -T 8 > /tmp/busybox:1.31.1安装 xz Ubuntu/Debian sudo apt upda…...

C#经典算法面试题
网络上收集的一些C#经典算法面试题,分享给大家 # 递归算法 ## C#递归算法计算阶乘的方法 > 一个正整数的阶乘(factorial)是所有小于及等于该数的正整数的积,并且0的阶乘为1。自然数n的阶乘写作n!。1808年,基斯顿…...

vulnhub靶场【DriftingBlues】之9 final
前言 靶机:DriftingBlues-6,IP地址192.168.1.66 攻击:kali,IP地址192.168.1.16 都采用虚拟机,网卡为桥接模式 主机发现 使用arp-scan -l或netdiscover -r 192.168.1.1/24 信息收集 使用nmap扫描端口 网站探测 访…...

有124个叶子节点的,完全二叉树最多有多少个节点
n=n0n1n2 其中n0为叶子节点, n2=n0-1 完全二叉树的定义和性质 最后化简,n=2*n0n1-1...

从RNN到Transformer:生成式AI自回归模型的全面剖析
个人主页:chian-ocean 文章专栏 生成式AI中的自回归模型详解 在生成式AI的飞速发展中,自回归模型作为核心技术之一,成为文本生成、语音合成、图像生成等领域的重要支柱。本文将全面探讨自回归模型的原理、架构、实际应用,并结合…...

Java爬虫大冒险:如何征服1688商品搜索之巅
在这个信息爆炸的时代,数据就是力量。对于电商平台而言,数据更是金矿。今天,我们要踏上一场Java爬虫的冒险之旅,目标是征服1688这个B2B电商巨头,获取按关键字搜索的商品信息。这不仅是技术的挑战,更是智慧的…...

基于Spring Boot的无可购物网站系统
一、系统背景与意义 随着互联网的快速发展,电子商务已经成为人们日常生活的重要组成部分。构建一个稳定、高效、可扩展的电商平台后端系统,对于满足用户需求、提升用户体验、推动业务发展具有重要意义。Spring Boot作为当前流行的Java开发框架ÿ…...

智能人家谱程序创意
实现一个家谱程序,并结合自传、视频、图片资料和智能对话系统,涉及到多个领域的技术:自然语言处理(NLP)、机器学习、计算机视觉、多媒体处理和数据存储。下面,我为你制定一个可执行的计划,详细阐…...

Redis 7.x哨兵模式如何实现?基于Spring Boot 3.x版
大家好,我是袁庭新。 在Redis主从复制模式中,因为系统不具备自动恢复的功能,所以当主服务器(master)宕机后,需要手动把一台从服务器(slave)切换为主服务器。在这个过程中࿰…...
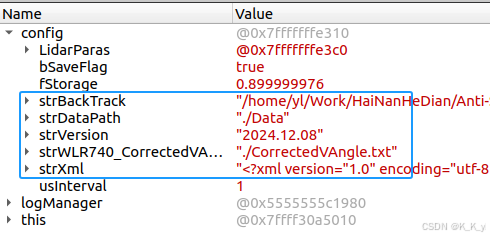
解决QTCreator在Debug时无法显示std::string类型的问题
环境: 操作系统:Ubuntu 20.04.6 LTS QT版本:Qt Creator 4.11.0 问题: Debug时,无法显示std::string类型的值,如下图: 解决方法: 修改/usr/share/qtcreator/debugger/stdtypes.py…...

leetcode 面试经典 150 题:无重复字符的最长子串
链接无重复字符的最长子串题序号3类型字符串解题方法滑动窗口难度中等 题目 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s “abcabcbb” 输出: 3 解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。 …...

0101多级nginx代理websocket配置-nginx-web服务器
1. 前言 项目一些信息需要通过站内信主动推动给用户,使用websocket。web服务器选用nginx,但是域名是以前通过阿里云申请的,解析ip也是阿里云的服务器,甲方不希望更换域名。新的系统需要部署在内网服务器,简单拓扑图如…...

ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch + CUDA环境配置与避坑
ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch CUDA环境配置与避坑 在深度学习模型部署领域,BFloat16数据类型正逐渐成为提升推理性能的新宠。这种16位浮点格式保留了与32位浮点相同的指数位,在保持数值范围的同时减少了内存占…...

保姆级教程:用CH34xSerCfg修改USB转串口芯片的VID/PID,解决驱动冲突和串口号固定问题
嵌入式开发实战:用CH34xSerCfg定制USB转串口设备标识与驱动管理 当你的工作台上同时连接着五个相同型号的USB转TTL模块,Windows设备管理器里COM端口像走马灯一样随机变换编号时;当团队协作开发中,每个成员需要固定识别自己的调试设…...

终极免费方案:3步轻松解锁QQ音乐加密文件,让音乐随处可听
终极免费方案:3步轻松解锁QQ音乐加密文件,让音乐随处可听 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾遇到过这样的情况&a…...
深入Transformer内部:LoRA到底改动了哪部分权重才让模型“学会”新任务?
深入Transformer内部:LoRA如何通过低秩更新重塑大模型能力 在自然语言处理领域,大型预训练模型的微调一直是个计算密集型任务。传统全参数微调需要更新数十亿甚至数千亿参数,这对大多数研究者和企业来说都是难以承受的负担。低秩适应(LoRA)技…...

百度网盘直链解析工具:突破下载限速的Python解决方案
百度网盘直链解析工具:突破下载限速的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾经为百度网盘的下载速度而烦恼?作为国内最…...

Steam Achievement Manager完整指南:快速解决游戏成就难题的终极工具
Steam Achievement Manager完整指南:快速解决游戏成就难题的终极工具 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 核心关键词:S…...

基于LLM的游戏AI智能体:从感知到决策的框架构建与实践
1. 项目概述:一个能“玩”游戏的AI智能体最近在GitHub上看到一个挺有意思的项目,叫ChattyPlay-Agent。光看名字,你可能会觉得这又是一个基于大语言模型的聊天机器人。但点进去仔细研究后,我发现它的定位非常独特:这是一…...

开源PCB自动布线神器FreeRouting:5分钟上手,效率提升300%
开源PCB自动布线神器FreeRouting:5分钟上手,效率提升300% 【免费下载链接】freerouting Advanced PCB auto-router 项目地址: https://gitcode.com/gh_mirrors/fr/freerouting FreeRouting是一款功能强大的开源PCB自动布线工具,它能帮…...

5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南
5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南 【免费下载链接】SerialAssistant A serial port assistant that can be used directly in the browser. 项目地址: https://gitcode.com/gh_mirrors/se/SerialAssistant 你是否还在为串口调试工具…...

从零构建Next.js全栈应用:实战解析服务端渲染与API路由
1. 项目概述与核心价值最近在社区里看到不少朋友在讨论一个叫“panaverse/learn-nextjs”的项目,作为一个在Web开发领域摸爬滚打了十多年的老码农,我立刻来了兴趣。这个项目名直译过来就是“Panaverse的Next.js学习项目”,听起来像是一个学习…...