Kaggler日志--Day9
进度24/12/18
昨日复盘:
补充并解决Day7Kaggler日志–Day7统计的部分问题
今日进度:
继续完成Day8Kaggler日志–Day8统计问题的解答
明日规划:
今天报名了Regression with an Insurance Dataset算是新手村练习比赛,截止时间是25年1月1日,还有13天。
问题解决
整体流程
四个部分:
- EDA(探索性数据分析)
- 预处理(移除行、列,填补空缺值)
- 特征工程(新增特征,特征放缩变换)(类似更高级的预处理)
- 建模(模型选择,集成,训练与评估)
昨天的问题:
- EDA部分
- 对不同变量类型判别的举例说明:
- 分类可视化时:离散型数值类型、连续型数值类型、类别类型
- 填补空缺时:填补
NA的,填补众数的类别型,填补平均数的数值型,分组填补的。
- 对于不同类型变量使用的可视化图表的理解
- 连续分布:kde核密度估计画柱状图、箱线图
- 离散分布:柱状图
- 多变量分析可视化
- 两两相关性分析:相关性热力图–找多重共线性变量
- 单变量与目标值的相关性:相关性指标、散点图
- 箱线图与离群点、skewed:箱线图要素以及偏态的判断
- 对不同变量类型判别的举例说明:
待解决问题
- EDA部分
- 空缺值填补策略
- 特征工程
- CV验证的应用
- 集成模型
- 模型融合
空缺值填补
Pandas中使用NaN表示空缺值。
空缺值的产生可能是由于维护不当,或用户没有响应造成的。
缺失值类型:
- 完全随机缺失(MCAR):当数据缺失的概率在所有观测值中均匀分布时为这种缺失。该数据的缺失与数据集中任何其它观察到的或者未观察到的数据之间没有关系。这种缺失是纯随机的,没有任何可辨别的模式。
- 随机缺失(MAR):数据缺失取决于观测到的数据而不是缺失的数据本身。该缺失值可以通过已拥有的信息变量来解释。缺失值中存在某种模式。(eg.一份数据中,性别为空的记录中才可能缺少年龄项,年龄的缺失取决于性别,但缺少性别的记录中年龄的缺失仍是随机的)
- 非随机缺失(MNAR):数据的缺失与未观测数据本身有关,此类缺失有固定的模式,但是通过观测变量来解释。(在有关图书馆的调查中,逾期图书较多的人不太可能回应调查,因此逾期图书数量缺失,取决于逾期图书的数量)
了解缺失数据类型至关重要,因为它决定了处理缺失值的适当策略并确保统计分析的完整性
处理类型:
- 删除:丢弃太多数据会影响结论的可靠性
- 归纳法:
- 均值/中位数/众数插补:如果数据缺失不是随机分布的,可能会引入偏差。
- K近邻(KNN插补):根据可用特征找到最近的数据点(邻居),并使用它们的值来估计缺失值。当拥有大量数据且缺失分散时,KNN很有用
- 基于模型的插补:根据数据中的其它特征来预测缺失值,这可能是一种强大的技术,但是需要更多的专业知识,并且计算成本可能很高。
为什么要处理缺失值:
- 如果数据包含缺失值,许多机器学习算法都会失败
- 最终可能构建一个有偏见的模型,如果缺失值处理不当会导致不正确的结果
- 缺失数据可能导致系统缺乏精度
处理方法:
- 删除缺失值
- 填补缺失值
- 填补分类特征的缺失值
- 使用
Sci-kit学习库填补缺失值 - 使用缺失值作为特征
删除缺失值
一般来说不推荐,如果缺失值属于非随机确实类型(MNAR),则更不应删除。
如果为随机缺失或者完全随机缺失,则可以考虑删除,当然删除就可能丢失有用数据
删除也有两种方法:
- 整行删除
df.dropna(axis=0) - 整列删除``df.drop([‘col_name’], axis=1)
估算缺失值
- 用任意值替换
df["col_name"].fillna(0) - 用平均值(适用数值)/众数(适用类别)/中位数(适用出现异常的数值)替换
df["col_name"] = df["col_name"].fillna(df["col_name"].mean()) - 用前一个值向前填充(适用于时间序列数据)
Series.fillna(methods='ffill')。用下一个值是bfill - 插值:有多种不同的插值方法–多项式、线性、二次。默认是线性
Series.interpolate()
(插值是利用周围的数值来估计中间的空缺值,一般用在序列数据或图像数据上)
分类特征缺失值
- 估算最常见的值
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="most_frequent")
imputer.fit_transformer(X)
- 估算缺失值:
SimpleImputer(strategy="constant", fill_value="missing")
使用Sci-kit学习库填补缺失值
通过创建另一个模型来根据另一个变量预测一个变量的观测值,称为回归填补
- 单变量方法
imp = SimpleImputer(missing_values=np.nan, strategy='mean') - 多变量方法
- KNNImputer:找到已有观测值最相似的行,利用这些行估计缺失值
- IterativeImputer:构建从已有观测值计算缺失观测值的模型来估计缺失值
使用“缺失值”作为特征
某些情况下,可以保留缺失值的缺失情况作为特征。因为有时,缺失值缺失的原因与尝试预测的目标变量之间可能存在关系。
(eg. 假设正在预测疾病,由于没有贫困人口记录,年龄缺失很可能可是一个很好的指标,因为年龄缺失不是随机的,贫困人口很可能缺失年龄,并且贫困核疾病相关)
imputer = SimpleImputer(add_indicator=True)
imputer.fit_transform(X)
特征工程
特征工程是指从原始数据转化为特征向量的过程,特征工程是机器学习中最重要的起始步骤,会直接影响机器学习的效果,并通常需要大量的时间。典型的特征工程包括数据清理、特征提取、特征选择等过程。
数据清理
- 缩放特征值
- 处理极端离群值
- 分箱(离散化)
- 填补遗漏值
- 移除重复样本、不良标签、不良特征值等
- 平滑
- 正则化
降维
高维情形下经常会碰到样本系数、距离计算困难的问题,解决方法就是降维
- 主成分分析法(PCA)
- 核化线性降维(KPCA)
- 等…
特征选择
特征选择是一个从给定的特征集合种选择与当前学习任务相关的特征的过程。一些“冗余特征”需要剔除。
常见的特征选择方法有三类:
- 过滤式选择:先对数据集进行特征选择,再训练学习器,特征选择与后续机器学习无关。典型算法为Relief算法
- 方差选择法
- 相关系数法
- 卡方检验
- 互信息法
- 包裹是选择:选择直接把最终要使用的学习器的性能作为特征子集的评价标准。典型算法为LVM
- 递归特征消除法
- 嵌入式选择:将特征选择过程与学习器训练过程融为一体,两者再同一个优化过程中文昌,即再学习器训练过程中自动地进行了特征选择。典型算法为岭回归、LASSO回归等
- 基于惩罚项地特征选择法
- 基于树模型的特征选择法
良好特征的特点包括:
- 避免很少使用的离散特征值:良好的特征值应该再数据集中出现大约5次以上
- 最好具有清晰的定义
- 良好的浮点特征不包含超出范围的异常断点或“神奇”的值
- 特征的定义不应随时间变化
特征组合
特征组合称为特征交叉,通过将两个或多个输入特征相乘来对特征空间中的非线性规律进行编码的合成特征。
常见的特征组合方程:
- A X B
- A X B X C X D X E
- A X A
CV的深入理解
有一个问题:CV可以用在最终评估和超参数调优的网格化搜索过程中,但是如果这两个过程都使用同一个数据集进行CV。就是最终验证要用到的数据参与到了模型的建模(调优)过程中,这样是可以的吗?
集成建模
模型集成是一种通过结合多个独立训练的机器学习模型来提高整体性能的技术。这种方法通过利用多个模型的额不同优势和学习特征,以期望在继承后获得更好的泛化能力、稳健性和性能表现。
常见类型:
- 投票集成:多个模型独立训练,预测时每个模型投票,最终的预测结果有多数投票决定
- 平均集成,多个模型的预测结果取平均值,分类问题可以使用概率的平均值
- 自适应集成:这种方法动态地选择哪个模型对于给定输入更合适。这可以基于输入数据的特性,例如使用某个模型在某些特定子集上表现更好
- Stacking :更复杂的集成方法,在一个一元模型的框架下结合多个基本模型。基本模型的预测结果成为元模型的输入。元模型通过学习如何结合基本模型的输出来产生最终预测结果
- Boosting,其中弱分类器按顺序进行训练,每个新模型都试图纠正前一个模型的错误,最终的预测结果时所有模型的加权组合。
- Bagging,通过在训练集上进行重采样,训练多个模型,然后将它们的预测结果平均或投票
优势如下:
- 提高泛化能力
- 降低过拟合风险
- 提高鲁棒性
- 性能提升
模型融合
模型融合是指将多个模型的输出结果结合起来,以产生最终的预测结果。模型融合通常是集成建模的一个具体实现,强调如何将不同模型的结果进行合并。
集成建模更强调模型的组合策略和训练过程,通常涉及多种模型和集成方法。
模型融合侧重于如何将多个模型的输出结果结合在一起,强调的是结果的整合。
附录
有关EDA和特征工程的思考
EDA更多的是查询数据,发现数据模式和异常,而实际的对数据的各种修改操作都算是特征工程的范畴。
二者相互促进:
EDA为特征工程和模型选择提供直到,特征工程构建新的特征后可以再次EDA,以验证新特征对模型性能的影响。
相关文章:

Kaggler日志--Day9
进度24/12/18 昨日复盘: 补充并解决Day7Kaggler日志–Day7统计的部分问题 今日进度: 继续完成Day8Kaggler日志–Day8统计问题的解答 明日规划: 今天报名了Regression with an Insurance Dataset算是新手村练习比赛,截止时间是2…...

OpenCVE:一款自动收集NVD、MITRE等多源知名漏洞库的开源工具,累计收录CVE 27万+
漏洞库在企业中扮演着至关重要的角色,不仅提升了企业的安全防护能力,还支持了安全决策、合规性要求的满足以及智能化管理的发展。前期博文《业界十大知名权威安全漏洞库介绍》介绍了主流漏洞库,今天给大家介绍一款集成了多款漏洞库的开源漏洞…...

麒麟信安参编的《能源企业数字化转型能力评价 技术可控》团体标准发布
近日,中国能源研究会发布公告,《能源企业数字化转型能力评价 技术可控》团体标准发布。该标准由麒麟信安与国网湖北省电力有限公司武汉供电公司、国网智能电网研究院有限公司、中能国研(北京)电力科学研究院等单位联合编制。 《能…...
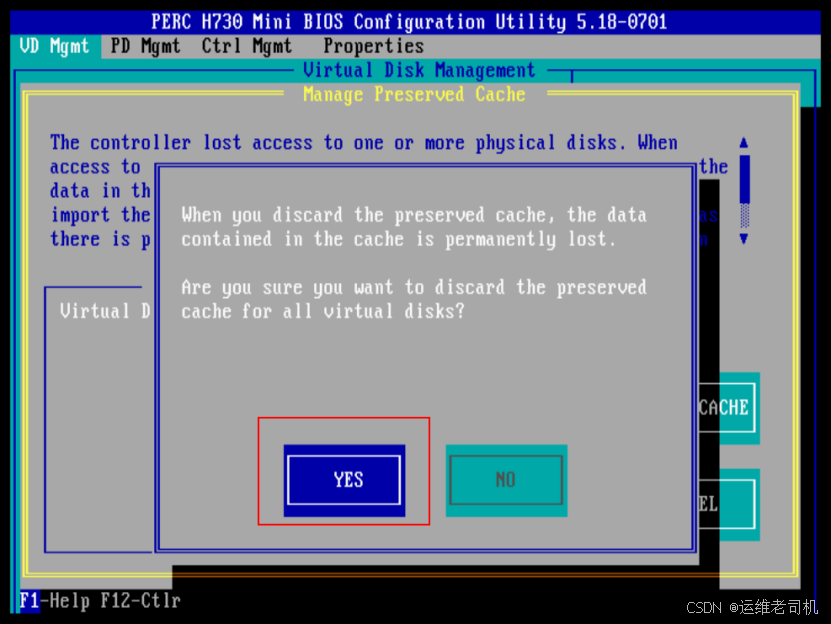
戴尔物理机更换完Raid控制器(阵列卡),启动服务器失败
背景 我们使用的物理机是戴尔的POWEREDGE R730机器,由于硬件损坏导致该问题的延申,再更换完Raid的控制器(阵列卡)之后导致启动服务器报错。 报错: There are offline or missing virtual drives with preserved cac…...

计算机基础知识——数据结构与算法(二)(山东省大数据职称考试)
大数据分析应用-初级 第一部分 基础知识 一、大数据法律法规、政策文件、相关标准 二、计算机基础知识 三、信息化基础知识 四、密码学 五、大数据安全 六、数据库系统 七、数据仓库. 第二部分 专业知识 一、大数据技术与应用 二、大数据分析模型 三、数据科学 大数据相关标准…...

docsify
macos ➜ ~ node -v v16.20.2➜ ~ npm --version 8.19.4全局安装 docsify-cli 工具 npm i docsify-cli -g➜ ~ docsify -vdocsify-cli version:4.4.4初始化项目 docsify init ./docsls -ah docs . .. .nojekyll README.md index.htmlindex.html 入口文件README.md 会…...

GEE教程——使用 CHIRPS 和 GSMaP 数据集计算并可视化了特定区域的降水量
目录 简介 函数 ee.Image.pixelLonLat() No arguments. Returns: Image visualize(bands, gain, bias, min, max, gamma, opacity, palette, forceRgbOutput) Arguments: Returns: Image 代码解释 代码 结果 简介 GEE教程——使用 CHIRPS 和 GSMaP 数据集计算并可视…...

前端实现页面自动播放音频方法
前端实现页面视频在谷歌浏览器中自动播放音频方法 了解Chrome自动播放策略 在Chrome和其他现代浏览器中,为了改善用户体验,自动播放功能受到了限制。Chrome的自动播放策略主要针对有声音的视频,目的是防止页面在用户不知情的情况下自动播放声…...

【Nginx-5】Nginx 限流配置指南:保护你的服务器免受流量洪峰冲击
在现代互联网应用中,流量波动是常态。无论是突发的用户访问高峰,还是恶意攻击,都可能导致服务器资源耗尽,进而影响服务的可用性。为了应对这种情况,限流(Rate Limiting)成为了一种常见的保护措施…...

【芯片设计- RTL 数字逻辑设计入门 番外篇 7.1 -- 基于ATE的IC测试原理】
文章目录 ATE 测试概述Opens/Shorts测试Leakage测试AC测试转自:漫谈大千世界 漫谈大千世界 2024年10月23日 23:17 湖北 ATE 测试概述 ATE(Automatic Test Equipment)是用于检测集成电路(IC)功能完整性的自动测试设备。它在半导体产业中扮演着至关重要的角色,主要用于检…...

SurfaceFlinger 学习
Android 图形系统之七:SurfaceFlinger-CSDN博客 CSDN...

Flink SQL 从一个SOURCE 写入多个Sink端实例
一. 背景 FLINK 任务从一个数据源读取数据, 写入多个sink端. 二. 官方实例 写入多个Sink语句时,需要以BEGIN STATEMENT SET;开头,以END;结尾。--源表 CREATE TEMPORARY TABLE datagen_source (name VARCHAR,score BIGINT ) WITH (connector datagen …...

python飞机大战游戏.py
python飞机大战游戏.py import pygame import random# 游戏窗口大小 WINDOW_WIDTH 600 WINDOW_HEIGHT 800# 颜色定义 BLACK (0, 0, 0) WHITE (255, 255, 255)# 初始化Pygame pygame.init()# 创建游戏窗口 window pygame.display.set_mode((WINDOW_WIDTH, WINDOW_HEIGHT))…...

【C++】14___String容器
目录 一、string基本概念 二、string赋值操作 三、字符串拼接 四、 string查找和替换 五、 string字符串比较 六、string插入和删除 七、string子串 一、string基本概念 本质:string是C风格的字符串,而string本质上是一个类 string和char*区别&am…...

数据特性库 前言
文章目录 一、num-traits库简介二、核心功能三、更新功能四、使用方式五、应用示例六、结论 一、num-traits库简介 num-traits是Rust编程语言中的一个开源库,专注于为数值类型提供一系列的数学运算特性和接口。它支持泛型数学计算,允许开发者在不指定具…...

jdk和cglib动态代理区别
目标类不同 jdk目标类需要实现接口。 cglib不需要。 代理类生成方式不同 jdk内部字节码生成代理类。 cglib使用ASM字节码生成库生成代理类。 代理类和目标类关系不同 jdk代理类实现目标类接口,jdk无法代理目标类中static或private的方法。 cglib 代理类继承目标类…...

部署Mysql、镜像和容器、常见命令
目录 部署Mysql 镜像和容器 常见命令 部署Mysql 可以有多个容器 docker run -d \--name mysql \-p 3306:3306 \-e TZAsia/Shanghai \-e MYSQL_ROOT_PASSWORD123 \mysql docker run -d \--name mysql2 \-p 3307:3307 \-e TZAsia/Shanghai \-e MYSQL_ROOT_PASSWORD123 \mys…...

【数学】P2671 [NOIP2015 普及组] 求和
题目背景 NOIP2015 普及组 T3、深入浅出进阶1-5 题目描述 一条狭长的纸带被均匀划分出了 n n n 个格子,格子编号从 1 1 1 到 n n n。每个格子上都染了一种颜色 c o l o r i color_i colori 用 [ 1 , m ] [1,m] [1,m] 当中的一个整数表示)&…...

【AI图像生成网站Golang】项目测试与优化
AI图像生成网站 目录 一、项目介绍 二、雪花算法 三、JWT认证与令牌桶算法 四、项目架构 五、图床上传与图像生成API搭建 六、项目测试与优化 六、项目测试与优化 在开发过程中,性能优化是保证项目可扩展性和用户体验的关键步骤。本文将详细介绍我如何使用一…...
vue常用自定义指令
参考链接1https://blog.csdn.net/m0_67584973/article/details/139300966?spm1001.2014.3001.5501 参考链接2https://juejin.cn/post/7067051410671534116...

使用mcp-maker快速构建AI工具集成服务器:从MCP协议到实践
1. 项目概述:一个为AI应用注入“超能力”的MCP服务器工厂 如果你最近在折腾AI应用开发,特别是想给ChatGPT、Claude这类大模型配上“手和脚”,让它们能操作你的本地文件、查询数据库,甚至控制你的智能家居,那你大概率已…...

线程化笔记工具:重塑深度思考与知识管理的技术实践
1. 项目概述:一个为线程化思考而生的笔记工具最近在折腾个人知识管理工具时,发现了一个挺有意思的开源项目:alishobeiri/thread-notebook。乍一看名字,可能会以为是又一个普通的Markdown笔记本应用。但深入使用后,我发…...

DLP/SLA光固化3D打印技术解析与Ember打印机实战指南
1. DLP/SLA 3D打印技术深度解析:从光与树脂的对话说起如果你是从FDM(熔丝制造)打印转向树脂打印的,那感觉就像从开手动挡卡车换到了开精密数控机床。DLP(数字光处理)和SLA(立体光刻)…...
)
ElevenLabs葡语语音私密训练技巧(仅限白名单客户使用的SSML扩展语法+方言权重微调指令集)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs葡语语音私密训练的核心价值与白名单准入机制 ElevenLabs 的葡语语音私密训练(Private Voice Fine-tuning for Portuguese)专为高合规性场景设计,面向金融…...

ARM架构寄存器与参数管理核心技术解析
1. ARM架构寄存器与参数管理基础解析 在ARM架构的底层开发中,寄存器与参数管理是系统控制和调试的核心机制。作为嵌入式开发者,我经常需要与这两种资源打交道,它们虽然都用于存储数据,但在使用场景和特性上存在本质差异。 寄存器…...

基于MCP协议构建个人AI工作流:模块化套件配置与隐私优先实践
1. 项目概述:一个为个人工作流注入AI智能的MCP套件 最近在折腾AI Agent和自动化工作流的朋友,应该都绕不开一个词: MCP 。全称是Model Context Protocol,你可以把它理解成AI模型(比如Claude、ChatGPT)和外…...

Sunshine游戏串流架构深度解析:3种高效部署方案完全指南
Sunshine游戏串流架构深度解析:3种高效部署方案完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine作为一款开源自托管的游戏串流服务器,为Mo…...

体育科学论文降AI工具免费推荐:2026年体育科学研究毕业论文知网AIGC超标4.8元亲测达标完整指南
体育科学论文降AI工具免费推荐:2026年体育科学研究毕业论文知网AIGC超标4.8元亲测达标完整指南 帮同学选过降AI工具,综合价格、效果、保障来看,推荐嘎嘎降AI(www.aigcleaner.com)。 4.8元,达标率99.26%&a…...

ECHO:不止是播放器——一款完整的桌面音乐产品
下载地址:canghaiapp.com 软件介绍:不止是播放器 ECHO 将自己定位为一款“完整的桌面音乐产品”。从技术架构上看,它确实与此相符: 核心技术选型:项目基于 Electron React 技术栈构建。Electron 赋予了它调用原生系…...

基于CircuitPython的巨型机械键盘:从嵌入式开发到定制输入设备实践
1. 项目概述:当机械键盘遇上“巨无霸”如果你和我一样,对机械键盘那清脆的段落感和扎实的敲击感着迷,同时又是个喜欢动手折腾的硬件爱好者,那么这个项目绝对能让你眼前一亮。我们这次要做的,不是常规的60%或87键键盘&a…...