“深度学习”学习日记。--加深网络
2023.2.13
深度学习 是加深了层的深度神经网络的学习过程。基于之前介绍的网络,只需要通过 叠加层, 就可以创建深度网络
之前的学习,已经学习到了很多东西,比如构成神经网络的各种层、参数优化方法、误差反向传播法,卷积神经网络 现在将这些技术结合起来构建一个深度网络去完成MNIST识别任务。
一,构建一个更深的网络:
这个网络使用He初始值作为权重初始值,使用Adam作为权重参数的更新;
He值的相关内容参考文章: “深度学习”学习日记。与学习有关的技巧--权重的初始值_Anthony陪你度过漫长岁月的博客-CSDN博客权重的初始值https://blog.csdn.net/m0_72675651/article/details/128748314
Adam的相关内容可以参考:“深度学习”学习日记。与学习相关的技巧 -- 参数的更新_Anthony陪你度过漫长岁月的博客-CSDN博客_深度学习参数更新SGD函数的缺点;由于权重偏置参数更新的Momentum函数,AdaGrad函数,Adam函数https://blog.csdn.net/m0_72675651/article/details/128737715
这个网络有以下特点:
1,基于3×3的小型卷积核(滤波器)的卷积层;
2,激活函数是ReLU;
3,全连接层的后面使用Droput层;
实验代码:这里的epoch设置为20,可能神经网络训练(学习)耗时会在5小时以上,epoch可以减小或增大以缩减或增加雪莲时长,当然对正确率也有影响。
import os
import sys
import numpy as np
import matplotlib as plt
from collections import OrderedDictsys.path.append(os.pardir)# MNIST数据导入
try:import urllib.request
except ImportError:raise ImportError('You should use Python 3.x')
import os.path
import gzip
import pickleurl_base = 'http://yann.lecun.com/exdb/mnist/'
key_file = {'train_img': 'train-images-idx3-ubyte.gz','train_label': 'train-labels-idx1-ubyte.gz','test_img': 't10k-images-idx3-ubyte.gz','test_label': 't10k-labels-idx1-ubyte.gz'
}dataset_dir = os.path.dirname(os.path.abspath(__file__))
save_file = dataset_dir + "/mnist.pkl"train_num = 60000
test_num = 10000
img_dim = (1, 28, 28)
img_size = 784def _download(file_name):file_path = dataset_dir + "/" + file_nameif os.path.exists(file_path):returnprint("Downloading " + file_name + " ... ")urllib.request.urlretrieve(url_base + file_name, file_path)print("Done")def download_mnist():for v in key_file.values():_download(v)def _load_label(file_name):file_path = dataset_dir + "/" + file_nameprint("Converting " + file_name + " to NumPy Array ...")with gzip.open(file_path, 'rb') as f:labels = np.frombuffer(f.read(), np.uint8, offset=8)print("Done")return labelsdef _load_img(file_name):file_path = dataset_dir + "/" + file_nameprint("Converting " + file_name + " to NumPy Array ...")with gzip.open(file_path, 'rb') as f:data = np.frombuffer(f.read(), np.uint8, offset=16)data = data.reshape(-1, img_size)print("Done")return datadef _convert_numpy():dataset = {}dataset['train_img'] = _load_img(key_file['train_img'])dataset['train_label'] = _load_label(key_file['train_label'])dataset['test_img'] = _load_img(key_file['test_img'])dataset['test_label'] = _load_label(key_file['test_label'])return datasetdef init_mnist():download_mnist()dataset = _convert_numpy()print("Creating pickle file ...")with open(save_file, 'wb') as f:pickle.dump(dataset, f, -1)print("Done!")def _change_one_hot_label(X):T = np.zeros((X.size, 10))for idx, row in enumerate(T):row[X[idx]] = 1return Tdef load_mnist(normalize=True, flatten=True, one_hot_label=False):if not os.path.exists(save_file):init_mnist()with open(save_file, 'rb') as f:dataset = pickle.load(f)if normalize:for key in ('train_img', 'test_img'):dataset[key] = dataset[key].astype(np.float32)dataset[key] /= 255.0if one_hot_label:dataset['train_label'] = _change_one_hot_label(dataset['train_label'])dataset['test_label'] = _change_one_hot_label(dataset['test_label'])if not flatten:for key in ('train_img', 'test_img'):dataset[key] = dataset[key].reshape(-1, 1, 28, 28)return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])if __name__ == '__main__':init_mnist()# 函数部分
def softmax(x):if x.ndim == 2:x = x.Tx = x - np.max(x, axis=0)y = np.exp(x) / np.sum(np.exp(x), axis=0)return y.Tx = x - np.max(x) # 溢出对策return np.exp(x) / np.sum(np.exp(x))def cross_entropy_error(y, t):if y.ndim == 1:t = t.reshape(1, t.size)y = y.reshape(1, y.size)if t.size == y.size:t = t.argmax(axis=1)batch_size = y.shape[0]return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_sizedef im2col(input_data, filter_h, filter_w, stride=1, pad=0):N, C, H, W = input_data.shapeout_h = (H + 2 * pad - filter_h) // stride + 1out_w = (W + 2 * pad - filter_w) // stride + 1img = np.pad(input_data, [(0, 0), (0, 0), (pad, pad), (pad, pad)], 'constant')col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))for y in range(filter_h):y_max = y + stride * out_hfor x in range(filter_w):x_max = x + stride * out_wcol[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N * out_h * out_w, -1)return coldef col2im(col, input_shape, filter_h, filter_w, stride=1, pad=0):N, C, H, W = input_shapeout_h = (H + 2 * pad - filter_h) // stride + 1out_w = (W + 2 * pad - filter_w) // stride + 1col = col.reshape(N, out_h, out_w, C, filter_h, filter_w).transpose(0, 3, 4, 5, 1, 2)img = np.zeros((N, C, H + 2 * pad + stride - 1, W + 2 * pad + stride - 1))for y in range(filter_h):y_max = y + stride * out_hfor x in range(filter_w):x_max = x + stride * out_wimg[:, :, y:y_max:stride, x:x_max:stride] += col[:, :, y, x, :, :]return img[:, :, pad:H + pad, pad:W + pad]# 参数更新方法
class SGD:def __init__(self, lr=0.01):self.lr = lrdef update(self, params, grads):for key in params.keys():params[key] -= self.lr * grads[key]class Momentum:def __init__(self, lr=0.01, momentum=0.9):self.lr = lrself.momentum = momentumself.v = Nonedef update(self, params, grads):if self.v is None:self.v = {}for key, val in params.items():self.v[key] = np.zeros_like(val)for key in params.keys():self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]params[key] += self.v[key]class Nesterov:def __init__(self, lr=0.01, momentum=0.9):self.lr = lrself.momentum = momentumself.v = Nonedef update(self, params, grads):if self.v is None:self.v = {}for key, val in params.items():self.v[key] = np.zeros_like(val)for key in params.keys():self.v[key] *= self.momentumself.v[key] -= self.lr * grads[key]params[key] += self.momentum * self.momentum * self.v[key]params[key] -= (1 + self.momentum) * self.lr * grads[key]class AdaGrad:def __init__(self, lr=0.01):self.lr = lrself.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] += grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)class RMSprop:def __init__(self, lr=0.01, decay_rate=0.99):self.lr = lrself.decay_rate = decay_rateself.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] *= self.decay_rateself.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)class Adam:def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):self.lr = lrself.beta1 = beta1self.beta2 = beta2self.iter = 0self.m = Noneself.v = Nonedef update(self, params, grads):if self.m is None:self.m, self.v = {}, {}for key, val in params.items():self.m[key] = np.zeros_like(val)self.v[key] = np.zeros_like(val)self.iter += 1lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)for key in params.keys():self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)# 传递层(类)
class Affine:def __init__(self, W, b):self.W = Wself.b = bself.x = Noneself.original_x_shape = None# 权重和偏置参数的导数self.dW = Noneself.db = Nonedef forward(self, x):# 对应张量self.original_x_shape = x.shapex = x.reshape(x.shape[0], -1)self.x = xout = np.dot(self.x, self.W) + self.breturn outdef backward(self, dout):dx = np.dot(dout, self.W.T)self.dW = np.dot(self.x.T, dout)self.db = np.sum(dout, axis=0)dx = dx.reshape(*self.original_x_shape) # 还原输入数据的形状(对应张量)return dx# 输出与损失函数层
class SoftmaxWithLoss:def __init__(self):self.loss = Noneself.y = None # softmax的输出self.t = None # 监督数据def forward(self, x, t):self.t = tself.y = softmax(x)self.loss = cross_entropy_error(self.y, self.t)return self.lossdef backward(self, dout=1):batch_size = self.t.shape[0]if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况dx = (self.y - self.t) / batch_sizeelse:dx = self.y.copy()dx[np.arange(batch_size), self.t] -= 1dx = dx / batch_sizereturn dx# 正则化
class Dropout:def __init__(self, dropout_ratio=0.5):self.dropout_ratio = dropout_ratioself.mask = Nonedef forward(self, x, train_flg=True):if train_flg:self.mask = np.random.rand(*x.shape) > self.dropout_ratioreturn x * self.maskelse:return x * (1.0 - self.dropout_ratio)def backward(self, dout):return dout * self.mask# 激活函数
class Relu:def __init__(self):self.mask = Nonedef forward(self, x):self.mask = (x <= 0)out = x.copy()out[self.mask] = 0return outdef backward(self, dout):dout[self.mask] = 0dx = doutreturn dx# 卷积层
class Convolution:def __init__(self, W, b, stride=1, pad=0):self.W = Wself.b = bself.stride = strideself.pad = padself.x = Noneself.col = Noneself.col_W = Noneself.dW = Noneself.db = Nonedef forward(self, x):FN, C, FH, FW = self.W.shapeN, C, H, W = x.shapeout_h = 1 + int((H + 2 * self.pad - FH) / self.stride)out_w = 1 + int((W + 2 * self.pad - FW) / self.stride)col = im2col(x, FH, FW, self.stride, self.pad)col_W = self.W.reshape(FN, -1).Tout = np.dot(col, col_W) + self.bout = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)self.x = xself.col = colself.col_W = col_Wreturn outdef backward(self, dout):FN, C, FH, FW = self.W.shapedout = dout.transpose(0, 2, 3, 1).reshape(-1, FN)self.db = np.sum(dout, axis=0)self.dW = np.dot(self.col.T, dout)self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW)dcol = np.dot(dout, self.col_W.T)dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)return dxclass Pooling:def __init__(self, pool_h, pool_w, stride=1, pad=0):self.pool_h = pool_hself.pool_w = pool_wself.stride = strideself.pad = padself.x = Noneself.arg_max = Nonedef forward(self, x):N, C, H, W = x.shapeout_h = int(1 + (H - self.pool_h) / self.stride)out_w = int(1 + (W - self.pool_w) / self.stride)col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)col = col.reshape(-1, self.pool_h * self.pool_w)arg_max = np.argmax(col, axis=1)out = np.max(col, axis=1)out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)self.x = xself.arg_max = arg_maxreturn outdef backward(self, dout):dout = dout.transpose(0, 2, 3, 1)pool_size = self.pool_h * self.pool_wdmax = np.zeros((dout.size, pool_size))dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten()dmax = dmax.reshape(dout.shape + (pool_size,))dcol = dmax.reshape(dmax.shape[0] * dmax.shape[1] * dmax.shape[2], -1)dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad)return dx# 加深层的卷积神经网络的结构
class DeepConvNet:def __init__(self, input_dim=(1, 28, 28),conv_param_1={'filter_num': 16, 'filter_size': 3, 'pad': 1, 'stride': 1},conv_param_2={'filter_num': 16, 'filter_size': 3, 'pad': 1, 'stride': 1},conv_param_3={'filter_num': 32, 'filter_size': 3, 'pad': 1, 'stride': 1},conv_param_4={'filter_num': 32, 'filter_size': 3, 'pad': 2, 'stride': 1},conv_param_5={'filter_num': 64, 'filter_size': 3, 'pad': 1, 'stride': 1},conv_param_6={'filter_num': 64, 'filter_size': 3, 'pad': 1, 'stride': 1},hidden_size=50, output_size=10):# 初始化权重# 各层的神经元平均与前一层的几个神经元有连接(TODO:自动计算)pre_node_nums = np.array([1 * 3 * 3, 16 * 3 * 3, 16 * 3 * 3, 32 * 3 * 3, 32 * 3 * 3, 64 * 3 * 3, 64 * 4 * 4, hidden_size])wight_init_scales = np.sqrt(2.0 / pre_node_nums) # 使用ReLU的情况下推荐的初始值self.params = {}pre_channel_num = input_dim[0]for idx, conv_param in enumerate([conv_param_1, conv_param_2, conv_param_3, conv_param_4, conv_param_5, conv_param_6]):self.params['W' + str(idx + 1)] = wight_init_scales[idx] * np.random.randn(conv_param['filter_num'],pre_channel_num,conv_param['filter_size'],conv_param['filter_size'])self.params['b' + str(idx + 1)] = np.zeros(conv_param['filter_num'])pre_channel_num = conv_param['filter_num']self.params['W7'] = wight_init_scales[6] * np.random.randn(64 * 4 * 4, hidden_size)self.params['b7'] = np.zeros(hidden_size)self.params['W8'] = wight_init_scales[7] * np.random.randn(hidden_size, output_size)self.params['b8'] = np.zeros(output_size)# 生成层self.layers = []self.layers.append(Convolution(self.params['W1'], self.params['b1'],conv_param_1['stride'], conv_param_1['pad']))self.layers.append(Relu())self.layers.append(Convolution(self.params['W2'], self.params['b2'],conv_param_2['stride'], conv_param_2['pad']))self.layers.append(Relu())self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))self.layers.append(Convolution(self.params['W3'], self.params['b3'],conv_param_3['stride'], conv_param_3['pad']))self.layers.append(Relu())self.layers.append(Convolution(self.params['W4'], self.params['b4'],conv_param_4['stride'], conv_param_4['pad']))self.layers.append(Relu())self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))self.layers.append(Convolution(self.params['W5'], self.params['b5'],conv_param_5['stride'], conv_param_5['pad']))self.layers.append(Relu())self.layers.append(Convolution(self.params['W6'], self.params['b6'],conv_param_6['stride'], conv_param_6['pad']))self.layers.append(Relu())self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))self.layers.append(Affine(self.params['W7'], self.params['b7']))self.layers.append(Relu())self.layers.append(Dropout(0.5))self.layers.append(Affine(self.params['W8'], self.params['b8']))self.layers.append(Dropout(0.5))self.last_layer = SoftmaxWithLoss()def predict(self, x, train_flg=False):for layer in self.layers:if isinstance(layer, Dropout):x = layer.forward(x, train_flg)else:x = layer.forward(x)return xdef loss(self, x, t):y = self.predict(x, train_flg=True)return self.last_layer.forward(y, t)def accuracy(self, x, t, batch_size=100):if t.ndim != 1: t = np.argmax(t, axis=1)acc = 0.0for i in range(int(x.shape[0] / batch_size)):tx = x[i * batch_size:(i + 1) * batch_size]tt = t[i * batch_size:(i + 1) * batch_size]y = self.predict(tx, train_flg=False)y = np.argmax(y, axis=1)acc += np.sum(y == tt)return acc / x.shape[0]def gradient(self, x, t):self.loss(x, t)dout = 1dout = self.last_layer.backward(dout)tmp_layers = self.layers.copy()tmp_layers.reverse()for layer in tmp_layers:dout = layer.backward(dout)grads = {}for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):grads['W' + str(i + 1)] = self.layers[layer_idx].dWgrads['b' + str(i + 1)] = self.layers[layer_idx].dbreturn gradsdef save_params(self, file_name="params.pkl"):params = {}for key, val in self.params.items():params[key] = valwith open(file_name, 'wb') as f:pickle.dump(params, f)def load_params(self, file_name="params.pkl"):with open(file_name, 'rb') as f:params = pickle.load(f)for key, val in params.items():self.params[key] = valfor i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):self.layers[layer_idx].W = self.params['W' + str(i + 1)]self.layers[layer_idx].b = self.params['b' + str(i + 1)]# 训练模型(神经网络的学习过程)
class Trainer:def __init__(self, network, x_train, t_train, x_test, t_test,epochs=20, mini_batch_size=100,optimizer='SGD', optimizer_param={'lr': 0.01},evaluate_sample_num_per_epoch=None, verbose=True):self.network = networkself.verbose = verboseself.x_train = x_trainself.t_train = t_trainself.x_test = x_testself.t_test = t_testself.epochs = epochsself.batch_size = mini_batch_sizeself.evaluate_sample_num_per_epoch = evaluate_sample_num_per_epoch# optimzeroptimizer_class_dict = {'sgd': SGD, 'momentum': Momentum, 'nesterov': Nesterov,'adagrad': AdaGrad, 'rmsprpo': RMSprop, 'adam': Adam}self.optimizer = optimizer_class_dict[optimizer.lower()](**optimizer_param)self.train_size = x_train.shape[0]self.iter_per_epoch = max(self.train_size / mini_batch_size, 1)self.max_iter = int(epochs * self.iter_per_epoch)self.current_iter = 0self.current_epoch = 0self.train_loss_list = []self.train_acc_list = []self.test_acc_list = []def train_step(self):batch_mask = np.random.choice(self.train_size, self.batch_size)x_batch = self.x_train[batch_mask]t_batch = self.t_train[batch_mask]grads = self.network.gradient(x_batch, t_batch)self.optimizer.update(self.network.params, grads)loss = self.network.loss(x_batch, t_batch)self.train_loss_list.append(loss)if self.verbose: print("train loss:" + str(loss))if self.current_iter % self.iter_per_epoch == 0:self.current_epoch += 1x_train_sample, t_train_sample = self.x_train, self.t_trainx_test_sample, t_test_sample = self.x_test, self.t_testif not self.evaluate_sample_num_per_epoch is None:t = self.evaluate_sample_num_per_epochx_train_sample, t_train_sample = self.x_train[:t], self.t_train[:t]x_test_sample, t_test_sample = self.x_test[:t], self.t_test[:t]train_acc = self.network.accuracy(x_train_sample, t_train_sample)test_acc = self.network.accuracy(x_test_sample, t_test_sample)self.train_acc_list.append(train_acc)self.test_acc_list.append(test_acc)if self.verbose: print("=== epoch:" + str(self.current_epoch) + ", train acc:" + str(train_acc) + ", test acc:" + str(test_acc) + " ===")self.current_iter += 1def train(self):for i in range(self.max_iter):self.train_step()test_acc = self.network.accuracy(self.x_test, self.t_test)if self.verbose:print("=============== Final Test Accuracy ===============")print("test acc:" + str(test_acc))# 主函数
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)network = DeepConvNet()
trainer = Trainer(network, x_train, t_train, x_test, t_test,epochs=20, mini_batch_size=100,optimizer='Adam', optimizer_param={'lr': 0.001},evaluate_sample_num_per_epoch=1000)
trainer.train()# 保存参数
network.save_params("deep_convnet_params.pkl")
print("Saved Network Parameters!")
运行结果:
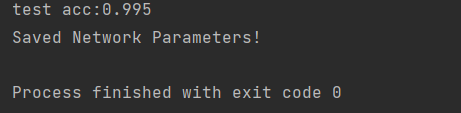
从这些特征看出,他的识别率达到0.995,可以说非常优秀了。
对比以前的神经网络的测试集正确率效果更加可观,
“深度学习”学习日记。卷积神经网络--用CNN的实现MINIST识别任务_Anthony陪你度过漫长岁月的博客-CSDN博客搭建CNN去实现MNIST数据集的识别任务https://blog.csdn.net/m0_72675651/article/details/128980999
二,进一步提高识别精度:
世界上有许多用于完成MNIST的神经网络模型,截至2016年6月,对MNIST数据集的最高识别精度是0.9979,该方发也是以CNN为基础的。不过,他用的CNN并不是特别深层的网络(两层卷积层、两层全连接层)
除了加深层神经网络以外,我们也可以从 集成学习、学习衰减、Data Augmentation(数据扩充) 等助于提高识别精度。 特别是数据扩充。
1,数据扩充:
Data Augmentation是基于算法“人为地”扩充输入图像(训练图像)相当于,把训练集图像,通过施加旋转、垂直、平移或水平方向上的移动等微小变化,增加图像数量。
2,加深层的动机:
根据教材的实验结果表示,性能优良的神经网络有,有逐渐加深网络的层趋势。也就是说,可以看到的层越深,识别性能也越高。
加深层有一个优点就是可以减少神经网络的参数数量。等价于用更少的参数权重去达到同等水平(或者更强)的表现力
关于卷积运算参考文章:“深度学习”学习日记。卷积神经网络--卷积层_Anthony陪你度过漫长岁月的博客-CSDN博客卷积层https://blog.csdn.net/m0_72675651/article/details/128861606
掌握了卷积的运算法则后,我们可以知道公式:
输入数据的形状大小为(H,W),滤波器(卷积核)的大小为(FH,FW),输出大小为(OH,OF);
当一个形状为(5,5)输入数据,只有一层卷积层将结果经过卷积运算变成一个(1,1),则需要一个5×5的卷积核,一共25个参数;
当我们有两层卷积层,可以在第一层先通过一个3×3的卷积核,第二层再通过一个3×3的卷积核,这时,我们值需要18的参数;
像这样,通过叠加小型滤波器来加深神经网络的好处就是可以减少参数的设置,扩大 感受视野 (receptive field,给神经元施加变化的某个局部空间区域)。并且,通过叠加层,将ReLU层,将ReLU的激活函数夹在卷积层的中见,进一步提高了网络的表现力。这是因为像网络添加了基于激活函数的“非线性”表现力,通过非线性函数的叠加,可以表现更加复杂的东西。
加深层的第二个好处就是是的学习更加高效:
这篇文章讲到 :“深度学习”学习日记。卷积神经网络--用CNN的实现MINIST识别任务_Anthony陪你度过漫长岁月的博客-CSDN博客搭建CNN去实现MNIST数据集的识别任务https://blog.csdn.net/m0_72675651/article/details/128980999
根据深度学习的可视化相关研究,随着层次的加深,提取的信息(反应强烈的神经元)也会缘来缘抽象。最开始是对简单的边缘有相应,接下来的层对纹理有反应,再后面的层会对更加复杂的物体部件有反应。也就是说,随着层次的加深,神经元从简单的形状向“高级”信息变化。
如果,我们想要写一个识别“狗”的神经网络,那我使用浅层神经网络的话我们就需要,在每一层神经网络中考虑很多参数(权重),导致耗时很长,正确率也差强人意;
如果通过加深网络去实现的化,就可以分层次地分解需要学习的问题。因此,在每一层卷积层中索要解决的问题就会变得简单。比如,最开始的层值要专注与学习边缘,只用较少的数据就可以高效的学习,通过加深层,可以使用上一次提取的边缘信息。
不够要注意的是,深层化是由大数据、计算能力等即便加深层也能正确地进行学习的新技术与环境支撑的。
相关文章:
“深度学习”学习日记。--加深网络
2023.2.13 深度学习 是加深了层的深度神经网络的学习过程。基于之前介绍的网络,只需要通过 叠加层, 就可以创建深度网络 之前的学习,已经学习到了很多东西,比如构成神经网络的各种层、参数优化方法、误差反向传播法,…...

2023前端面试总结含参考答案
文章目录1. 父子组件生命周期的执行顺序:2. 原型链:3. promise的理解:4. 数组循环,foreach,filter,map,reduce5. 数组去重,set6. 组件通信方式7. 路由钩子8. 首页首屏加载优化:9. th…...
总览 Java 容器--集合框架的体系结构
前言 我们在讲 Java 的数据类型的时候,单独介绍过数组,数组也确实是开发程序中常用的内存类型之一,不过 Java 内置的数组限制颇多,所以此后扩展出了List这种结构,与之类似的Set、Queue 这些内存中的容器都被放在了 Co…...

即便考分很好也不予录取的研究生复试红线,都是原则性问题
在浙大研究生招生录取政策文件中有这么一句话:坚持“按需招生、全面衡量、择优录取、宁缺毋滥”的原则,以提高人才选拔质量为核心,在确保安全性、公平性和科学性的基础上,做到统筹兼顾、精准施策、严格管理。字字体现出研究生招生…...

Android java创建子线程的几种方法
1.新建一个类继承自Thread,并重写run()方法,并在里面编写耗时逻辑。 1 2 3 4 5 6 7 class ThreadTest extends Thread { Override public void run() { //具体的耗时逻辑代码 } } new ThreadTest().st…...
UVa 11212 Editing a Book 编辑书稿 IDA* Iterative Deepening A Star 迭代加深搜剪枝
题目链接:Editing a Book 题目描述: 给定nnn个(1<n<10)1<n<10)1<n<10)数字,数字分别是1,2,3,...,n1, 2, 3, ...,n1,2,3,...,n,但是顺序是打乱的,你可以选择一个索引区间的数字进行剪切操作。问最少进…...
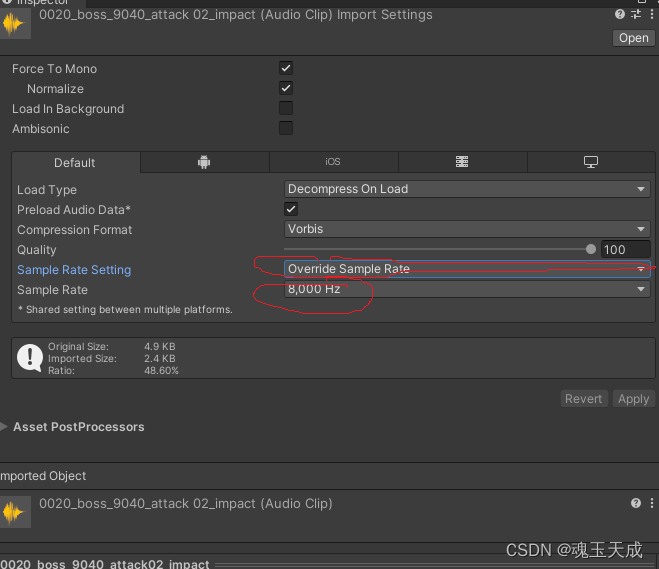
第一章:unity性能优化之内存优化
目录 前言 unity性能优化之内存的优化 一、unity Analysis工具的使用。 二、内存优化方法 1、设置和压缩图片 2、图片格式 3、动画文件 4、模型 5、RenderTexture(RT) 6、分辨率 7、资源的重复利用 8、shader优化 9、对bundle进行良好的管…...
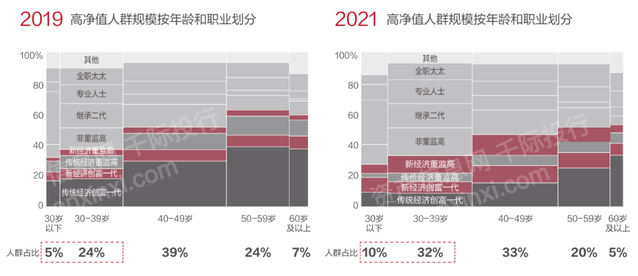
2023年家族办公室研究报告
第一章 概况 家族办公室最早起源于古罗马时期的大“Domus”(家族主管)以及中世纪时期的大“Domo”(总管家)。现代意义上的家族办公室出现于19世纪中叶,一些抓住产业革命机会的大亨将金融专家、法律专家和财务专家集合…...

Typescript快速入门
Typescript快速入门第一章 快速入门0、TypeScript简介1、TypeScript 开发环境搭建2、基本类型3、编译选项4、webpack5、Babel第二章:面向对象0、面向对象简介1、类(class)2、面向对象的特点3、接口(Interface)4、泛型&…...

如何激励你的内容团队产出更好的创意
对于一个品牌而言,如何创造吸引受众并对受众有价值内容是十分关键的。随着市场数字化的推进,优质的创意和内容输出对一个品牌在市场中有着深远的影响。对于很多内容策划和创作者来说,不断地产出高质量有创意的内容是一件非常有挑战性的事情。…...
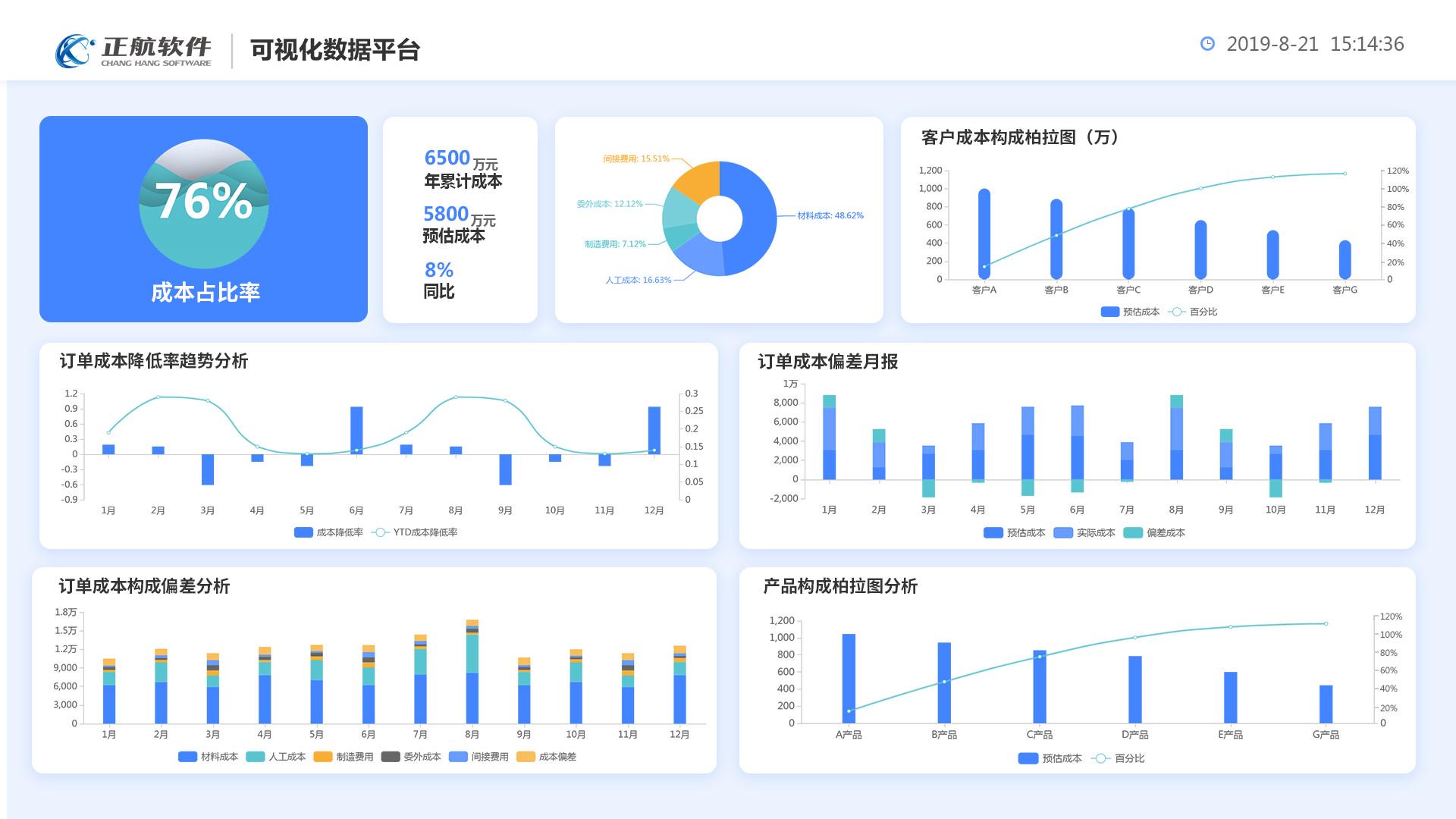
机械设备管理软件如何选择?机械设备管理软件哪家好?
随着信息化技术的进步与智能制造的发展趋势,很多机械设备制造企业也在一直探寻适合自己的数字化管理转型之路,而企业上ERP管理软件又是实现数字化管理的前提,机械设备管理软件对于企业来说就是关键一环。机械设备管理软件如何选择?…...
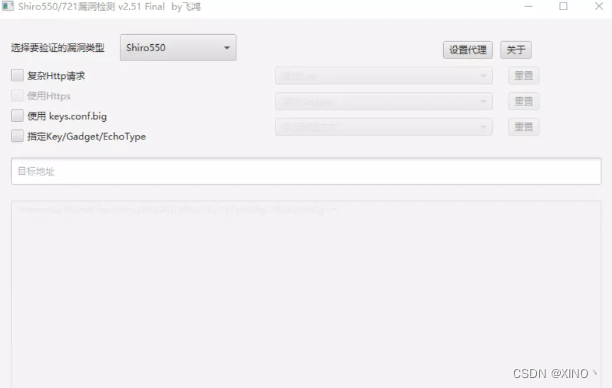
深入浅出带你学习shiro-550漏洞
//发点去年存货 前言 apache shiro是一个java安全框架,作用是提供身份验证,Apache Shiro框架提供了一个Rememberme的功能,存储在cookie里面的Key里面,攻击者可以使用Shiro的默认密钥构造恶意序列化对象进行编码来伪造用户的 Cookie…...

项目(今日指数之环境搭建)
一 项目架构1.1 今日指数技术选型【1】前端技术【2】后端技术栈【3】整体概览1.2 核心业务介绍【1】业务结构预览【2】业务结构预览1.定时任务调度服务XXL-JOB通过RestTemplate多线程动态拉去股票接口数据,刷入数据库; 2.国内指数服务 3.板块指数服务 4.…...

PCL 基于投影点密度的建筑物立面提取
目录 一、算法原理1、投影密度理论及方法2、参考文献二、代码实现三、结果展示一、算法原理 1、投影密度理论及方法 将3维坐标点直接垂直投影到水平面上或者将 Z Z Z 值取任意常数,统计和计算水平面任意位置处所含投影点的个数记为...

DDD 参考工程架构
1 背景 不同团队落地DDD所采取的应用架构风格可能不同,并没有统一的、标准的DDD工程架构。有些团队可能遵循经典的DDD四层架构,或改进的DDD四层架构,有些团队可能综合考虑分层架构、整洁架构、六边形架构等多种架构风格,有些在实…...

重建,是2023年的关键词
作者:俞敏洪 来源:老俞闲话(ID:laoyuxianhua) 01 重建,是2023年的关键词 1.重建,是2023年的关键词 2023年,以一种奇特的方式来临。 之所以说奇特,是因为我们谁都没有…...

动手写操作系统-00-环境搭建以及资料收集
文章目录 动手写操作系统内核目标编本教程适合什么样的人?一些简单的要求操作系统的功能环境搭建参考文档:动手写操作系统内核 一直以来想学习linux操作系统,读了很多关于操作系统的书籍,也想自己动手写个OS 目标编 编写一个操作系统内核;能正常的运行自己编写的OS本教程适合…...
【scipy.sparse包】Python稀疏矩阵详解
【scipy.sparse包】Python稀疏矩阵 文章目录【scipy.sparse包】Python稀疏矩阵1. 前言2. 导入包3. 稀疏矩阵总览4. 稀疏矩阵详细介绍4.1 coo_matrix4.2 dok_matrix4.3 lil_matrix4.4 dia_matrix4.5 csc_matrix & csr_matrix4.6 bsr_matrix5. 稀疏矩阵的存取5.1 用save_npz保…...

从写下第1个脚本到年薪30W,我的自动化测试心路历程
我希望我的故事能够激励现在的软件测试人,尤其是还坚持在做“点点点”的测试人。 你可能会有疑问:“我也能做到这一点的可能性有多大?”因此,我会尽量把自己做决定和思考的过程讲得更具体一些,并尽量体现更多细节。 …...
JAVA八股、JAVA面经
还有三天面一个JAVA软件开发岗,之前完全没学过JAVA,整理一些面经...... 大佬整理的:Java面试必备八股文_-半度的博客-CSDN博客 另JAVA学习资料:Java | CS-Notes Java 基础Java 容器Java 并发Java 虚拟机Java IO目录 int和Inte…...

OpenClaw开源项目深度体验:对比其与星图GPU平台Qwen3-14B-Int4-AWQ部署差异
OpenClaw开源项目深度体验:对比其与星图GPU平台Qwen3-14B-Int4-AWQ部署差异 1. 项目概览与核心功能 OpenClaw是近期备受关注的开源大模型项目,主打轻量化和易部署特性。它采用混合专家架构(MoE),在保持模型性能的同时显著降低了计算资源需求…...

3步告别桌面混乱:开源免费的NoFences桌面分区管理工具
3步告别桌面混乱:开源免费的NoFences桌面分区管理工具 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否每天都要在杂乱无章的桌面图标中浪费宝贵时间&#x…...
)
避坑指南:MoE训练中AllToAll通信的配置与性能调优(以DeepSpeed为例)
MoE训练实战:AllToAll通信性能调优与DeepSpeed配置避坑指南 当你在500张GPU的集群上启动MoE模型训练时,控制台突然刷出"AllToAll timeout"的红色警告——这不是假设场景,而是去年我们在训练千亿参数模型时真实遭遇的噩梦。AllToAll…...
)
别再死记硬背GAT公式了!用Python+PyTorch手把手图解注意力机制(附代码)
图解GAT:用PythonPyTorch拆解图注意力机制的实现奥秘 当你第一次听说图注意力网络(GAT)时,是否被那些复杂的数学公式和抽象概念吓退?本文将以全新的可视化方式,带你从零实现一个完整的GAT层,用代…...

快捷键冲突终结者:Hotkey Detective全方位排障指南
快捷键冲突终结者:Hotkey Detective全方位排障指南 【免费下载链接】hotkey-detective A small program for investigating stolen hotkeys under Windows 8 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 问题诊断:你的快捷键为…...

从零搭建无人船:两年实战后,我总结的ArduPilot+Pixhawk避坑全流程
从零搭建无人船:两年实战后,我总结的ArduPilotPixhawk避坑全流程 第一次把无人船放进水里时,GPS信号突然丢失,船体在河中央失控打转——这个惊心动魄的瞬间让我意识到,开源飞控的实战应用远不是下载代码、连接硬件那么…...

Phi-4-mini-reasoning部署实操手册:supervisor服务管理与日志排查指南
Phi-4-mini-reasoning部署实操手册:supervisor服务管理与日志排查指南 1. 模型概述 Phi-4-mini-reasoning 是一个专注于推理任务的文本生成模型,特别适合处理数学题、逻辑题、多步分析和简洁结论输出。与通用聊天模型不同,它采用"题目…...

零成本打造私有云盘:从PHPStudy安装到IPv6动态域名解析全攻略
零成本打造私有云盘:从PHPStudy安装到IPv6动态域名解析全攻略 在数字化时代,个人数据存储需求呈爆炸式增长。网盘限速、隐私泄露、订阅费用高昂等问题困扰着许多用户。本文将手把手教你如何利用闲置电脑和免费工具,打造一个完全由自己掌控的私…...

新手别怕!用Volatility 2.6分析WinXP内存镜像,一步步揪出隐藏的svchost木马
从零开始的内存取证实战:用Volatility 2.6解剖WinXP内存中的svchost木马 当你第一次接触内存取证时,面对黑底白字的命令行界面和陌生的术语,难免会感到无从下手。但别担心,今天我们就用一个真实的WinXP SP2内存镜像案例࿰…...

WaveTools实战:鸣潮性能优化的5个技术秘诀
WaveTools实战:鸣潮性能优化的5个技术秘诀 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 问题定位:帧率异常的底层原因分析 作为《鸣潮》玩家,你是否遇到过这样的困扰…...