深度神经网络(DNN)在时序预测中的应用与缺陷
目录
编辑
一、DNN在时序预测中的应用
二、DNN的缺陷
三、技术挑战与未来趋势
四、结论
随着大数据时代的到来,深度学习技术在时序预测领域扮演着越来越重要的角色。深度神经网络(DNN)因其强大的非线性拟合能力和自动特征提取能力,在时序预测中显示出巨大的潜力。然而,DNN在实际应用中也面临着一系列挑战和缺陷。本文将详细探讨DNN在时序预测中的应用、面临的挑战以及潜在的缺陷,并展望未来的发展趋势。
一、DNN在时序预测中的应用
- 模型构建与训练DNN通过多层结构来捕捉时序数据中的复杂模式。在构建模型时,常见的模型包括卷积神经网络(CNN)和循环神经网络(RNN)。以下是一个简单的RNN模型构建和训练的代码示例:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM# 设置随机种子以确保可复现性
np.random.seed(42)# 生成样本数据
n_samples = 1000
time_steps = np.arange(n_samples)
var1 = np.sin(0.1 * time_steps) + np.random.normal(scale=0.1, size=n_samples)
var2 = np.cos(0.1 * time_steps) + np.random.normal(scale=0.1, size=n_samples)
var3 = np.sin(0.1 * time_steps + np.pi/4) + np.random.normal(scale=0.1, size=n_samples)# 创建数据框
data = pd.DataFrame({'Time': time_steps, 'Var1': var1, 'Var2': var2, 'Var3': var3})# 时间步长
n_time_steps = 10# 创建输入和输出数据集
def create_dataset(data, n_time_steps):X, y = [], []for i in range(len(data) - n_time_steps):X.append(data[i:(i + n_time_steps), :-1])y.append(data[i + n_time_steps, -1])return np.array(X), np.array(y)# 使用数值数据生成特征和目标
values = data[['Var1', 'Var2', 'Var3']].values
X, y = create_dataset(values, n_time_steps)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建DNN模型
def create_dnn_model(input_shape):model = Sequential()model.add(LSTM(64, activation='relu', input_shape=input_shape))model.add(Dropout(0.2)) # 防止过拟合model.add(LSTM(32, activation='relu'))model.add(Dropout(0.2))model.add(Dense(1)) # 输出层model.compile(optimizer='adam', loss='mse')return model# 创建模型
model = create_dnn_model((X_train.shape[1], X_train.shape[2]))# 训练模型
history = model.fit(X_train, y_train, epochs=50, batch_size=32, validation_split=0.1, verbose=1)# 评估模型
loss = model.evaluate(X_test, y_test, verbose=0)
print(f"测试集均方误差: {loss:.4f}")在训练过程中,模型通过大量的历史数据进行学习,使用损失函数(如均方误差MSE)来评估预测性能。优化算法(如Adam、SGD等)被用来更新模型参数,以提高预测精度。此外,批量归一化和Dropout等技术也被广泛应用,以防止过拟合并提高模型的泛化能力。
- 模型评估在模型训练完成后,使用测试数据集对模型进行评估是至关重要的。以下是评估模型性能的代码示例:
# 评估模型
loss = model.evaluate(X_test, y_test, verbose=0)
print(f"测试集均方误差: {loss:.4f}")常用的评估指标包括平均绝对误差(MAE)、均方根误差(RMSE)和平均绝对百分比误差(MAPE)等。这些指标帮助研究人员了解模型在实际应用中的表现。
- 输入输出长度的影响输入和输出的长度对时序预测的效果有显著影响。研究表明,选择合适的输入长度和输出长度可以提高模型的性能。通常,较大的批量大小(batch size)和较短的输入输出方式能够有效提升训练效率和预测准确性。
- Attention机制的应用除了传统的卷积和循环结构,Attention机制也被引入到时序预测中。以下是一个简单的Attention机制的代码示例:
from tensorflow.keras.layers import Attention# 在模型中添加Attention层
model.add(Attention())例如,TACTiS-2模型简化了attentional copulas,在不同的预测任务中具有最先进的精度,同时支持插值和从不规则数据中学习。
二、DNN的缺陷
- 模型复杂度高DNN的模型结构通常较为复杂,这导致训练和推理过程中的计算成本和时间成本较高。在资源有限的情况下,训练深度模型可能会面临困难。
- 训练难度大DNN的训练过程需要大量的数据和计算资源,且超参数的调整往往需要经验和反复试验。以下是一个简单的超参数调整的代码示例:
from tensorflow.keras.callbacks import EarlyStopping# 使用EarlyStopping来防止过拟合
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)# 训练模型
history = model.fit(X_train, y_train, epochs=100, batch_size=32, validation_split=0.2, callbacks=[early_stopping], verbose=1)对于初学者而言,训练深度学习模型可能会显得较为棘手。
- 可解释性低DNN被称为“黑箱”模型,其内部机制和决策过程难以解释。这使得在某些需要高可解释性的应用场景中,DNN的使用受到限制。
- 对数据集大小的依赖深度学习模型通常需要大量的数据才能发挥其优势。在数据量不足的情况下,DNN可能无法充分学习到有效的特征,导致性能下降。
- 过拟合风险DNN由于其强大的拟合能力,存在过拟合的风险,尤其是在数据量不足时。过拟合会导致模型在训练集上表现良好,但在测试集上效果不佳。
- 对异常值的敏感性DNN对异常值较为敏感,异常值可能会对模型的训练和预测性能产生较大影响。因此,在数据预处理阶段,需对异常值进行合理处理。
三、技术挑战与未来趋势
- 非平稳性时序数据的非平稳性是时序预测中的一个主要挑战。非平稳性意味着数据的统计特性(如均值和方差)随时间变化,这对于模型的预测能力提出了更高的要求。
- 多步预测多步预测是另一个挑战,它要求模型能够预测未来多个时间点的值。这不仅需要模型捕捉短期的模式,还需要理解长期的趋势和周期性。
- 极值预测对极端事件的预测在某些领域(如金融、气象等)尤为重要。DNN需要能够识别和预测这些罕见但影响重大的事件。
- 额外依赖时序预测往往依赖于额外的变量,如季节性因素、外部事件等。如何有效地整合这些信息是提高预测准确性的关键。
- 变点检测变点(Change Point)检测是识别时序数据中分布变化点的重要任务。这对于适应新的数据分布和提高预测准确性至关重要。
- 低信噪比在某些情况下,时序数据的信号可能被噪声所掩盖,导致信噪比较低。DNN需要能够从噪声中提取有用的信号。
- 小样本量在某些情况下,时间序列包含少量的观测值,这限制了模型学习的能力。小样本量问题可以通过使用全局预测模型来缓解,这些模型利用多个时间序列来构建模型。
四、结论
深度神经网络在时序预测中展现出强大的性能,能够有效捕捉数据中的复杂模式。然而,DNN也存在一些缺陷,如模型复杂度高、训练难度大、可解释性低等。在实际应用中,研究人员需要根据具体问题和数据集的特点,合理选择模型结构和训练策略,以克服这些缺陷,提高模型的性能和泛化能力。未来,随着技术的不断发展,DNN在时序预测中的应用将更加广泛,相关的缺陷也有望得到改善。同时,研究者们也在不断探索新的模型架构和训练方法,以应对时序预测中的技术挑战,推动时序预测技术的发展。
相关文章:

深度神经网络(DNN)在时序预测中的应用与缺陷
目录 编辑 一、DNN在时序预测中的应用 二、DNN的缺陷 三、技术挑战与未来趋势 四、结论 随着大数据时代的到来,深度学习技术在时序预测领域扮演着越来越重要的角色。深度神经网络(DNN)因其强大的非线性拟合能力和自动特征提取能力&…...
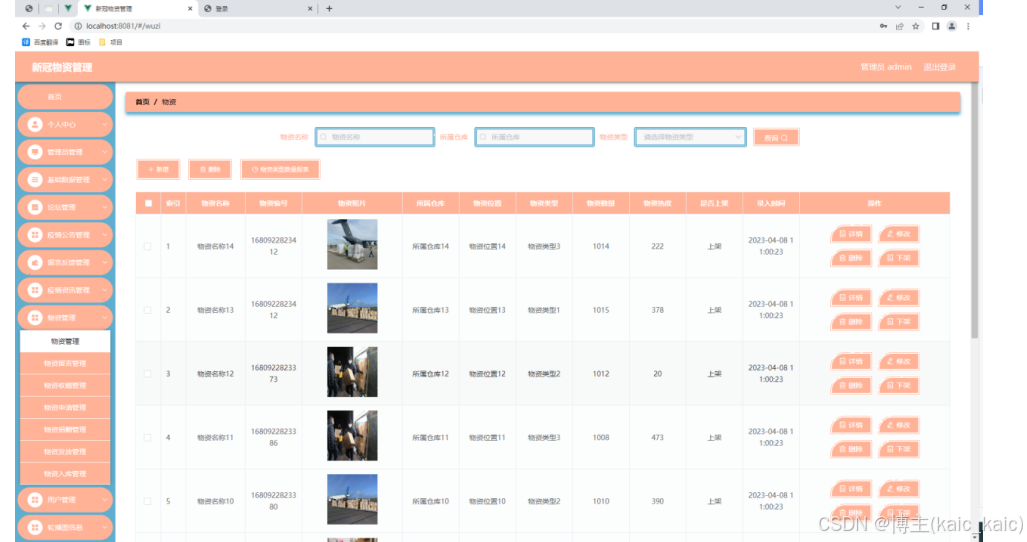
springboot445新冠物资管理(论文+源码)_kaic
摘 要 使用旧方法对新冠物资管理的信息进行系统化管理已经不再让人们信赖了,把现在的网络信息技术运用在新冠物资管理的管理上面可以解决许多信息管理上面的难题,比如处理数据时间很长,数据存在错误不能及时纠正等问题。这次开发的新冠物资管…...

C++算法第十一天
本篇文章我们继续学习动态规划 目录 第一题 题目链接 题目解析 代码原理 代码编写 第二题 题目链接 题目解析 代码原理 代码编写 第三题 题目链接 题目解析 代码原理 代码编写 第四题 题目链接 题目解析 代码原理 代码编写 第五题 题目链接 题目解析 代…...

常 用 类
一、 Object 类 1. Object 类的介绍 (1) Object 类位于 java.lang 包中,是继承关系的根类、超类,是所有类的父类 ( 直接的父类或是间接父类 ) (2) Object 类型的引用可以用于存储任意类型的对象。 (3) Object 类中定义方法,所有类都可以…...
ACL(访问控制列表)
ACL技术概述 • 随着网络的飞速发展,网络安全和网络服务质量 QoS ( Quality of Service )问题日益突出。 ▫ 园区重要服务器资源被随意访问,园区机密信息容易泄露,造成安全隐患。 ▫ Internet 病毒肆意侵略园区内网&am…...

json字符串转json
问题 Json格式化后,存在各种\n ,\r,以及空格,怎么办? 直接replaceAlll(“\s”,“”) 吗? 解决办法: //使用hutool的jsonutil工具,直接将其转换为json,再转string, //这样就不需要使用 各种re…...

GPT-Omni 与 Mini-Omni2:创新与性能的结合
近年来,随着人工智能技术的飞速发展,各种模型和平台应运而生,以满足从个人用户到企业级应用的多样化需求。在这一领域,GPT-Omni 和 Mini-Omni2 是两款备受瞩目的技术产品,它们凭借独特的设计和强大的功能,在…...

探秘 JSON:数据交互的轻盈使者
文章目录 一、JSON是什么二、JSON的语法规则三、应用场景四、性能优化五、总结 一、JSON是什么 JSON(JavaScript Object Notation)即 JavaScript 对象表示法,是一种轻量级的数据交换格式。JSON 以键值对的形式组织数据,键是字符串…...

源码分析之Openlayers中的Attribution属性控件
概述 本文主要介绍 Openlayers 中Attribution属性控件的源码实现,该控件也是 Openlayers 中三个默认控件之一。默认情况下,控件会显示在地图的右下角,可以通过控件的类名设置CSS属性控制。实际应用中该控件主要显示与图层源source相关的所有…...
)
Shell自定义(二)
1.Shell自定义 1.初始化 定义全局变量environ,把g_env的内容用memset初始化为0,这里用malloc开辟的空间为对应环境变量的长度1,多1位置是最后结束符0,strcpy把此时的对应的环境变量拷贝到g_env里面,下面是新增一个环…...

自然语言处理:我的学习心得与笔记
Pytorch 1.Pytorch基本语法 1.1 认识Pytorch 1.2 Pytorch中的autograd 2.Pytorch初步应用 2.1 使用Pytorch构建一个神经网络 2.2 使用Pytorch构建一个分类器 小节总结 学习了什么是Pytorch. 。Pytorch是一个基于Numpy的科学计算包,作为Numpy的替代者,向用户提供使用GPU强大…...

Oracle 中什么情况下 可以使用 EXISTS 替代 IN 提高查询效率
为什么 EXISTS 更高效? EXISTS 提前终止: EXISTS 一旦在子查询中找到第一个匹配项,就会立即返回 TRUE,不再继续扫描子查询中的其他记录。IN 必须扫描整个子查询的结果集,将所有结果与主查询的每一行进行对比。大数据集…...

Spring基础分析08-集成JPA/Hibernate进行ORM操作
大家好,今天和大家一起分享一下Spring集成JPAHibernate进行ORM操作的流程~ JPA(Java Persistence API)作为Java EE标准的一部分,提供了统一的API来管理实体类和持久化上下文;Hibernate则是最流行的JPA实现之一&#x…...
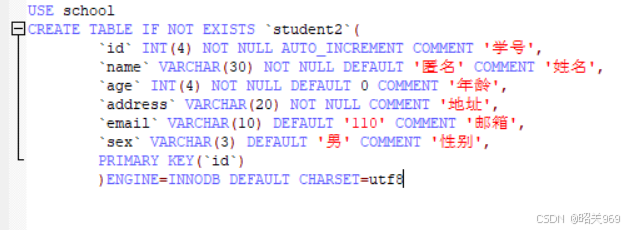
MySQL知识汇总(一)
一些命令行操作注意加 分号 “ ; ” show databases 查看所有数据库 use 数据库名 切换数据库 show tables 查看数据库中所有表 describe 表名 显示表中所有信息 create database [if not exists] 新库名 创…...
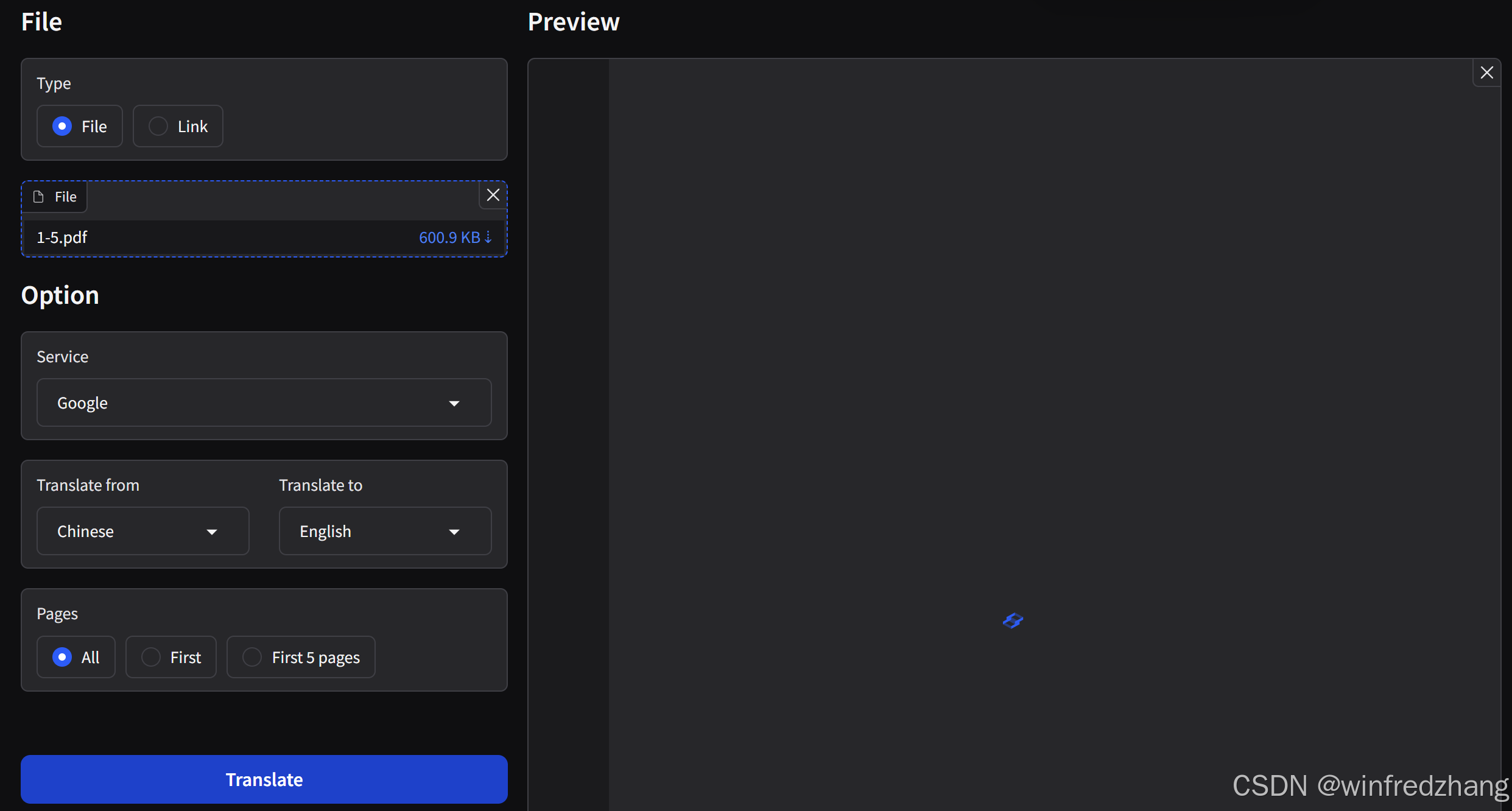
PDFMathTranslate 一个基于AI优秀的PDF论文翻译工具
PDFMathTranslate 是一个设想中的工具,旨在翻译PDF文档中的数学内容。以下是这个工具的主要特点和使用方法: 链接:https://www.modelscope.cn/studios/AI-ModelScope/PDFMathTranslate 功能特点 数学公式识别:利用先进的OCR&…...

React+Vite从零搭建项目及配置详解
相信很多React初学者第一次搭建自己的项目,搭建时会无从下手,本篇适合快速实现功能,熟悉React项目搭建流程。 目录 一、创建项目react-item 二、调整项目目录结构 三、使用scss预处理器 四、组件库Ant Design 五、配置基础路由 六、配置…...
 跟 @pytest.fixture有区别吗?)
@pytest.fixture() 跟 @pytest.fixture有区别吗?
在iOS UI 自动化工程里面最早我用的是pytest.fixture(),因为在pycharm中联想出来的fixture是带()的,后来偶然一次我没有带()发现也没有问题,于是详细查了一下pytest.fixture() 和 pytest.fixtur…...

Google Cloud Architect 认证考试错题集5
Google Cloud Architect 认证考试错题集5 D. Store static content such as HTML and images in a Cloud Storage bucket. Use Cloud Functions to host the APIs and save the user data in Firestore. - Storing static content in a Cloud Storage bucket is a cost-effecti…...
)
【Maven】基础(一)
【Maven】基础一 1. 虽然工作有段时间了,但是深感maven了解的不深入,所以这次开始深入的学习。 课程地址: https://www.bilibili.com/video/BV1JN411G7gX?spm_id_from333.788.player.switch&vd_source240d9002f7c7e3da63cd9a975639409a&p2 1.…...

多模态抽取图片信息的 Prompt
多模态抽取图片信息的 Prompt 1. 中文版2. 日文版3. 英文原版 下面使用多模态从图片中抽取文章,表格,Flowcharts的Prompt。 1. 中文版 你是一位擅长提取图片、图表、文本并对其进行解释的专家,能够保持原始语言不变。## 指南- 针对输入内容…...

轻量级协作平台设计:集成Git与敏捷开发的项目管理实践
1. 项目概述与核心价值最近在团队协作和项目管理工具选型上,又和几个技术负责人聊了一圈。大家普遍的感受是,市面上的工具要么太重,像Jira、Confluence,配置复杂,学习成本高,小团队用起来像“杀鸡用牛刀”&…...

MacOS光标增强工具:命令行驱动,实现自动化与个性化配置
1. 项目概述:当光标成为生产力工具如果你是一名长期在macOS上工作的开发者、设计师或者文字工作者,你肯定对系统自带的光标功能又爱又恨。爱的是它简洁流畅,恨的是它在某些高强度、多任务场景下显得力不从心。比如,当你需要在多个…...
基于PWM舵机与NeoPixel的万圣节互动蝙蝠制作全解析
1. 项目概述:一个会动的万圣节蝙蝠又快到万圣节了,想给家里的装饰来点不一样的“活物”吗?每年都摆静态的南瓜灯和蜘蛛网,总觉得少了点气氛。今年我琢磨着,不如自己动手做一个能扑腾翅膀、眼睛还会发光的机械蝙蝠&…...

如何用Kafka-King轻松管理Kafka集群:5分钟上手完整指南
如何用Kafka-King轻松管理Kafka集群:5分钟上手完整指南 【免费下载链接】Kafka-King A modern and practical kafka GUI client 💕🎉Kafka-King 是一款现代化、实用的 Kafka GUI 客户端,旨在通过直观的桌面界面简化 Apache Kafka …...

技能即代码:用自动化工具构建个人技能维护系统
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“skill-guardian”,作者是0xtresser。乍一看这个名字,可能有点摸不着头脑,但点进去研究了一下,发现这其实是一个关于“技能守护”或者说“技能管理”的…...

AI科技热点日报 | 2026年5月16日
文章目录AI科技热点日报 | 2026年5月16日一、大模型与基础技术《人工智能终端智能化分级》系列国家标准发布"九章四号"量子计算原型机刷新世界纪录二、AI政策与监管人工智能科技伦理审查与服务先导计划启动工信部部署高质量行业数据集建设三、Agent与应用"AI教育…...
)
计算机毕业设计OpenCV多特征融合的疲劳驾驶检测系统 图像处理 深度学习 大数据毕业设计(源码+LW+PPT+讲解)
温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台…...

深度学习训练理论:初始化与梯度消失
深度学习训练理论:初始化与梯度消失 1. 技术分析 1.1 训练挑战概述 深度学习训练面临多种挑战: 训练挑战梯度消失: 梯度趋近于0梯度爆炸: 梯度过大参数初始化: 权重初始化影响激活函数选择: 影响梯度流动1.2 梯度消失原因 原因机制影响激活函数sigmoid/t…...

基于RK3568核心板的智能家居控制器:从硬件选型到软件架构实战
1. 项目概述:当智能家居控制器遇上国产高性能核心板最近在做一个智能家居中控的案子,客户对性能、成本和本地化能力要求都比较高。选型阶段,我们团队把市面上主流的几款ARM核心板都摸了一遍,从传统的树莓派CM4到全志、瑞芯微的方案…...

AI智能体工具搜索系统:从MCP协议到语义检索的工程实践
1. 项目概述:从“工具搜索”到“智能体工具箱”的进化 最近在折腾AI智能体(Agent)开发的朋友,估计都绕不开一个核心问题:如何让智能体高效、准确地调用外部工具?无论是让它帮你查天气、发邮件,还…...