Elasticsearch-DSL高级查询操作
一、禁用元数据和过滤数据
1、禁用元数据_source
GET product/_search
{"_source": false, "query": {"match_all": {}}
}
查询结果不显示元数据
禁用之前:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 5,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "product","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "xiaomi phone","desc" : "shouji zhong de zhandouji","date" : "2021-06-01","price" : 3999,"tags" : ["xingjiabi","fashao","buka"]}},{"_index" : "product","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"name" : "xiaomi nfc phone","desc" : "zhichi quangongneng nfc,shouji zhong de jianjiji","date" : "2021-06-02","price" : 4999,"tags" : ["xingjiabi","fashao","gongjiaoka"]}},{"_index" : "product","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"name" : "nfc phone","desc" : "shouji zhong de hongzhaji","date" : "2021-06-03","price" : 2999,"tags" : ["xingjiabi","fashao","menjinka"]}},{"_index" : "product","_type" : "_doc","_id" : "4","_score" : 1.0,"_source" : {"name" : "xiaomi erji","desc" : "erji zhong de huangmenji","date" : "2021-04-15","price" : 999,"tags" : ["low","bufangshui","yinzhicha"]}},{"_index" : "product","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"name" : "hongmi erji","desc" : "erji zhong de kendeji 2021-06-01","date" : "2021-04-16","price" : 399,"tags" : ["lowbee","xuhangduan","zhiliangx"]}}]}
}禁用之后:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 5,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "product","_type" : "_doc","_id" : "1","_score" : 1.0},{"_index" : "product","_type" : "_doc","_id" : "2","_score" : 1.0},{"_index" : "product","_type" : "_doc","_id" : "3","_score" : 1.0},{"_index" : "product","_type" : "_doc","_id" : "4","_score" : 1.0},{"_index" : "product","_type" : "_doc","_id" : "5","_score" : 1.0}]}
}
2、数据源过滤器
Including:结果中返回哪些field
Excluding:结果中不要返回哪些field,不返回的field不代表不能通过该字段进行检索,因为元数据不存在不代表索引不存在
两种实现方式,
1:在创建索引的时候,mapping中配置;
这样配置映射,在查询的时候只显示name和price,不显示desc和tags
PUT product2
{"mappings": {"_source": {"includes": ["name","price"],"excludes": ["desc","tags"]}}
}
查看映射信息:GET product2/_mapping
{"product2" : {"mappings" : {"_source" : {"includes" : ["name","price"],"excludes" : ["desc","tags"]},"properties" : {"desc" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"name" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"owner" : {"properties" : {"age" : {"type" : "long"},"name" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"sex" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}},"price" : {"type" : "long"},"tags" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}
}插入数据:
PUT /product2/_doc/1
{"owner":{"name":"zhangsan","sex":"男","age":18},"name": "hongmi erji","desc": "erji zhong de kendeji","price": 399,"tags": ["lowbee","xuhangduan","zhiliangx"]
}
查询数据:
GET product2/_search
可以看到查询的结果没有上面excludes的数据
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "product2","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"price" : 399,"name" : "hongmi erji"}}]}
}
2:在写get search查询的时候指定;
基于上面的测试数据,先DELETE product2删除索引 再重新PUT /product2/_doc/1创建索引直接自动映射。
两种写法:
1.“_source”: 直接写展示的字段,
只展示owner.name和owner.sex
GET product2/_search
{"_source": ["owner.name","owner.sex"], "query": {"match_all": {}}
}
结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "product2","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"owner" : {"sex" : "男","name" : "zhangsan"}}}]}
}
2.source里用includes和excludes
GET product2/_search
{"_source": {"includes": ["owner.*","name"],"excludes": ["name", "desc","price"]},"query": {"match_all": {}}
}
结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "product2","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"owner" : {"sex" : "男","name" : "zhangsan","age" : 18}}}]}
}二、query string search
1.查看索引的结构
GET product/_mapping
2.查询索引的数据 默认10条
GET product/_search
3.查询索引的数据 限制条数20条
GET /product/_search?size=20
4.查询name分词后含有nfc的数据
GET /product/_search?q=name:nfc
5.查询前20条数据并且按照价格降序排列
GET /product/_search?from=0&size=20&sort=price:desc
6.createtime的数据类型是date,不会索引,所以这里是精准匹配createtime:2020-08-19的数据
GET /product/_search?q=createtime:2020-08-19
7.查询所有text分词后的词条中包含炮这个单词的
GET /product/_search?q=炮
三、全文检索-Fulltext query
查询模板:
GET index/_search
{"query": {"match": {"field": "searchContent"}}
}
造测试数据:
put mapping 就像关系型数据库的表结构:ddl语句
PUT product
{"mappings" : {"properties" : {"createtime" : {"type" : "date"},"date" : {"type" : "date"},"desc" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}},"analyzer":"ik_max_word"},"lv" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"name" : {"type" : "text","analyzer":"ik_max_word","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"price" : {"type" : "long"},"tags" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"type" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}
}
插入数据:就像关系型数据库的insert
PUT /product/_doc/1
{"name" : "小米手机","desc" : "手机中的战斗机","price" : 3999,"lv":"旗舰机","type":"手机","createtime":"2020-10-01T08:00:00Z","tags": [ "性价比", "发烧", "不卡顿" ]
}
PUT /product/_doc/2
{"name" : "小米NFC手机","desc" : "支持全功能NFC,手机中的滑翔机","price" : 4999,"lv":"旗舰机","type":"手机","createtime":"2020-05-21T08:00:00Z","tags": [ "性价比", "发烧", "公交卡" ]
}
PUT /product/_doc/3
{"name" : "NFC手机","desc" : "手机中的轰炸机","price" : 2999,"lv":"高端机","type":"手机","createtime":"2020-06-20","tags": [ "性价比", "快充", "门禁卡" ]
}
PUT /product/_doc/4
{"name" : "小米耳机","desc" : "耳机中的黄焖鸡","price" : 999,"lv":"百元机","type":"耳机","createtime":"2020-06-23","tags": [ "降噪", "防水", "蓝牙" ]
}
PUT /product/_doc/5
{"name" : "红米耳机","desc" : "耳机中的肯德基","price" : 399,"type":"耳机","lv":"百元机","createtime":"2020-07-20","tags": [ "防火", "低音炮", "听声辨位" ]
}
PUT /product/_doc/6
{"name" : "小米手机10","desc" : "充电贼快掉电更快,超级无敌望远镜,高刷电竞屏","price" : "","lv":"旗舰机","type":"手机","createtime":"2020-07-27","tags": [ "120HZ刷新率", "120W快充", "120倍变焦" ]
}
PUT /product/_doc/7
{"name" : "挨炮 SE2","desc" : "除了CPU,一无是处","price" : "3299","lv":"旗舰机","type":"手机","createtime":"2020-07-21","tags": [ "割韭菜", "割韭菜", "割新韭菜" ]
}
PUT /product/_doc/8
{"name" : "XS Max","desc" : "听说要出新款12手机了,终于可以换掉手中的4S了","price" : 4399,"lv":"旗舰机","type":"手机","createtime":"2020-08-19","tags": [ "5V1A", "4G全网通", "大" ]
}
PUT /product/_doc/9
{"name" : "小米电视","desc" : "70寸性价比只选,不要一万八,要不要八千八,只要两千九百九十八","price" : 2998,"lv":"高端机","type":"耳机","createtime":"2020-08-16","tags": [ "巨馍", "家庭影院", "游戏" ]
}
PUT /product/_doc/10
{"name" : "红米电视","desc" : "我比上边那个更划算,我也2998,我也70寸,但是我更好看","price" : 2999,"type":"电视","lv":"高端机","createtime":"2020-08-28","tags": [ "大片", "蓝光8K", "超薄" ]
}
PUT /product/_doc/11
{"name": "红米电视","desc": "我比上边那个更划算,我也2998,我也70寸,但是我更好看","price": 2998,"type": "电视","lv": "高端机","createtime": "2020-08-28","tags": ["大片","蓝光8K","超薄"]
}
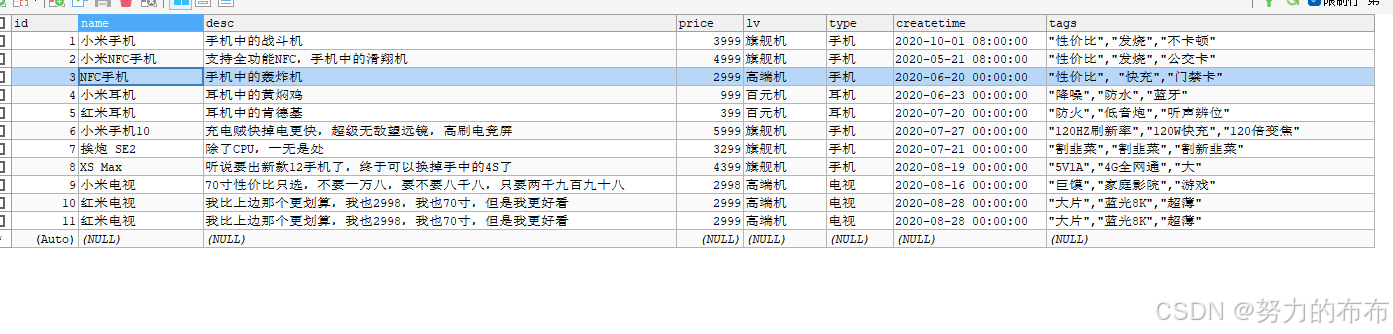
在构造mapping映射的时候,对text类型的字段指定了"analyzer":"ik_max_word"分词器,这里用的是IK分词器,插入数据会对该字段进行分词,建立倒排索引。*“type” : “keyword”*是用来后续精准查询的时候通过field.keyword来精准匹配。
1、query->match->text类型字段
进行全文搜索,会对查询的文本进行分词。
query match 这个name会被分词 name是txt类型 会被分词 所以搜索条件被分词后会和这个查询字段的词项进行匹配 匹配到的都返回
查询条件和索引中的字段数据都会进行分词 后 进行匹配 按照score返回
GET product/_search?_source=false
{"query": {"match": {"name": "NFC手机"}}
}
query->match->text.keyword类型字段
name是text类型字段,name.keyword做为查询条件不会进行分词,直接和索引数据中的name进行匹配,id为3的数据可以查询匹配。
GET product/_search
{"query": {"match": {"name.keyword": "NFC手机"}}
}
2、query->match_all查询全部数据
默认查询返回10条,这里指定20条,禁用元数据不返回太多
GET product/_search?size=20&_source=false
{"query": {"match_all": {}}
}
3、query->multi_match 多个字段匹配
多个字段匹配 name或者desc 包含 query中的任意一个就行,name或者desc分词后的数据包含手机就返回
GET product/_search?size=20&_source=false
{"query": {"multi_match": {"query": "手机","fields": ["name","desc"]}}
}
4、query->match_phrase 短语查询
搜索与指定短语匹配的文档,保留短语中词语的相对位置。
name的分词器是ik_max_word,看下name会被分为哪些词
GET _analyze
{"analyzer": "ik_max_word","text": "小米NFC手机"
}
结果:
{"tokens" : [{"token" : "小米","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "nfc","start_offset" : 2,"end_offset" : 5,"type" : "ENGLISH","position" : 1},{"token" : "手机","start_offset" : 5,"end_offset" : 7,"type" : "CN_WORD","position" : 2}]
}GET _analyze
{"analyzer": "ik_max_word","text": "NFC手机"
}结果:
{"tokens" : [{"token" : "nfc","start_offset" : 0,"end_offset" : 3,"type" : "ENGLISH","position" : 0},{"token" : "手机","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 1}]
}短语查询 索引里面name字段要有NFC手机这个短语 顺序不能颠倒,NFC手机会被分为nfc 手机
分词后能和索引字段name分词后的数据匹配到且顺序不乱 就可以做为结果展示
GET product/_search
{"query": {"match_phrase": {"name": "NFC手机"}}
}
结果:
{"took" : 5,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 2.8616219,"hits" : [{"_index" : "product","_type" : "_doc","_id" : "3","_score" : 2.8616219},{"_index" : "product","_type" : "_doc","_id" : "2","_score" : 2.4492486}]}
}
5、Term 对字段进行精确匹配。
GET /my_index/_search
{"query": { // "query"定义查询条件"term": { // "term"查询执行精确匹配"field_name": "exact_value" // "field_name"是要匹配的字段; "exact_value"是精确查询的精确值,通常用于keyword标签或其他不分析的文本字段}}
}
6、Bool 多条件组合查询
组合多个查询条件,支持must(必须)、should(至少一个)和must_not(必须不)关键字。
match支持全文检索,对查询条件分词然后匹配索引中的分词后的词项
term精准查询,不会分词检索,和非text类型或者text.keyword使用
range gte大于等于lte小于等于
minimum_should_match should默认至少满足一个,这里表示至少满足的数量自己控制
GET product/_search
{"query": {"bool": {"must": [{"match": {"name": "手机"}},{"match": {"desc": "手机"}}],"should": [{"term": {"type.keyword": {"value": "手机"}}},{"range": {"price": {"gte": 100,"lte": 300}}}],"minimum_should_match": 2,"must_not": [{"range": {"price": {"gte": 2999,"lte": 4500}}}]}}
}
filter:条件过滤查询,过滤满足条件的数据 不计算相关度得分
GET product/_search
{"query": {"bool": {"filter": [{"term": {"type.keyword": {"value": "手机"}}}]}}
}
7、terms
索引中tags含有性价比或者大片任意一个就行
GET product/_search
{"query": {"terms": {"tags.keyword": [ "性价比", "大片" ],"boost": 2.0}}
}
8、constant_score 意为固定得分
避免算分 提高性能
GET product/_search
{"query": {"constant_score": {"filter": {"term": {"type.keyword": "手机"}},"boost": 1.2}}
}
9、(must或者filter)和should组合 这时should满足0也行 如果should单用 要至少满足一个
GET product/_search
{"query": {"bool": {"filter": [{"range": {"price": {"gte": 10,"lte": 4000}}}],"should": [{"match": {"name": "哈哈哈哈哈哈哈哈哈哈哈哈"}},{"range": {"price": {"gte": 4001,"lte": 9000}}}],"minimum_should_match": 1}}
}
minimum_should_match不设置或者设置为0,即使should两个条件一个都不符合也可以查出数据
相关文章:
Elasticsearch-DSL高级查询操作
一、禁用元数据和过滤数据 1、禁用元数据_source GET product/_search {"_source": false, "query": {"match_all": {}} }查询结果不显示元数据 禁用之前: {"took" : 0,"timed_out" : false,"_shards" : {&quo…...

【Linux】重启系统后开不开机(内核模块丢失问题)
问题 重启后开不开机报错如下: FAILED failed to start load kernel moduiles 可以看到提示module dm_mod not found 缺少了dm_mod 在内核module目录中 reboot重启可以看到这个现象: 可以看到重启启动磁盘,加载不到root 原因 dm_mod模块…...
对golang的io型进程进行off-cpu分析
背景: 对于不能占满所有cpu核数的进程,进行on-cpu的分析是没有意义的,因为可能程序大部分时间都处在阻塞状态。 实验例子程序: 以centos8和golang1.23.3为例,测试下面的程序: pprof_netio.go package m…...

Springboot中使用Retrofit
Retrofit官网 https://square.github.io/retrofit/ 配置gradle implementation("com.squareup.okhttp3:okhttp:4.12.0")implementation ("com.squareup.retrofit2:retrofit:2.11.0")implementation ("com.squareup.retrofit2:converter-gson:2.11.0…...

Ubuntu中配置内网固定IP
文章目录 背景一、配置步骤(一)首先确认网卡名称(二)确认网关(三)备份配置文件(四)编辑配置文件(五)应用配置(六)验证配置 二、注意事…...

ExcelVBA编程输出ColorIndex与对应颜色色谱
标题 ExcelVBA编程输出ColorIndex与对应颜色色谱 正文 解决问题编程输出ColorIndex与对应色谱共56,打算分4纵列输出,标题是ColorIndex,Color,Name 1. 解释VBA中的ColorIndex属性 在VBA(Visual Basic for Applications)中ÿ…...

MySQL中in和exists的使用场景
在MySQL中,IN 和 EXISTS 是用于子查询的两种常见方法,它们在不同的场景下有不同的表现和适用性。下面我将详细介绍这两种方法的使用场景、优劣,并通过实验来说明问题。 IN 子查询 使用场景: 当子查询返回的结果集较小且不包含 …...

【多线程2】start 和 run 区别,终止线程,等待线程
Thread 类使用 start 方法,启动一个线程,对于同一个 Thread 对象来说,start 只能调用一次!!! 不怕名字起的长,就怕含义不清楚! 想要启动更多线程,就是得创建新的对象&am…...

富途证券C++面试题及参考答案
C++ 中堆和栈的区别 在 C++ 中,堆和栈是两种不同的内存区域,它们有许多区别。 从内存分配方式来看,栈是由编译器自动分配和释放的内存区域。当一个函数被调用时,函数内的局部变量、函数参数等会被压入栈中,这些变量的内存空间在函数执行结束后会自动被释放。例如,在下面的…...

Go使用sqlx操作MySQL完整指南
# Go使用sqlx操作MySQL完整指南## 1. 安装依赖bash go get github.com/go-sql-driver/mysql go get github.com/jmoiron/sqlx2. 数据库基础操作 package mainimport ("fmt"_ "github.com/go-sql-driver/mysql""github.com/jmoiron/sqlx" )// 定…...

Python 爬取网页文字并保存为 txt 文件教程
引言 在网络数据获取的过程中,我们常常需要从网页中提取有用的文字信息。Python 提供了强大的库来帮助我们实现这一目标。本教程将以https://theory.gmw.cn/2023 - 08/31/content_36801268.htm为例,介绍如何使用requests库和BeautifulSoup库爬取网页文字…...

时间序列预测论文阅读和相关代码库
时间序列预测论文阅读和相关代码库列表 MLP-based的时间序列预测资料DLinearUnetTSFPDMLPLightTS 代码库以及论文库:Time-Series-LibraryUnetTSFLightTS MLP-based的时间序列预测资料 我会定期把我的所有时间序列预测论文有关的资料链接全部同步到这个文章中&#…...

Mamba安装环境和使用,anaconda环境打包
什么是mamba Mamba是一个极速版本的conda,它是conda的C重新实现,使用多线程并行处理来加速包和依赖项的下载。 Mamba旨在提高安装、更新和卸载Python包的速度,同时保持与conda相同的兼容性和命令行接口。 Mamba的核心部分使用C实现ÿ…...

SSH连接成功,但VSCode连接不成功
环境 在实验室PC上连接服务器234 解决方案:在VSCode中重新添加远程主机 删除旧的VSCode Server 在远程主机上,VSCode会安装一个‘vscode-server’服务来支持远程开发,有时旧的‘vscode-server’文件可能会导致问题,删除旧的&am…...

springboot结合AES和国密SM4进行接口加密
api接口加密 1.为什么需要api接口加密呢? 1.防止爬虫 2.防止数据被串改 3.确保数据安全 2.如何实现接口加密呢? 3.我们可以使用哪些加密算法来加密呢? AES 密码学中的高级加密标准(Advanced Encryption Standard,…...

iOS在项目中设置 Dev、Staging 和 Prod 三个不同的环境
在 Objective-C 项目中设置 Dev、Staging 和 Prod 三个不同的环境,并为每个环境使用不同的 Bundle ID,可以通过以下步骤实现: 步骤 1: 创建不同的 Build Configuration 打开项目: 启动 Xcode 并打开你的项目。 选择项目文件&…...

openeuler24.09 系统无需配置 docker 源即可安装 docker 和 docker-composer
准备工作 1、准备一台刚刚创建的 openeuler24.09 lxc 虚拟机 2、使用 dnf 更新到最新,安装常用 工具 dnf update -y dnf install vim net-tools wget3、设置 ssh 由于ssh 与通常网上教程大同小异,在此我们就略过。 从下图我们可以看到 openeuler24.09 已经远程连接上。 …...

Flask入门:打造简易投票系统
目录 准备工作 创建项目结构 编写HTML模板 编写Flask应用 代码解读 进一步优化 结语 Flask,这个轻量级的Python Web框架,因其简洁和易用性,成为很多开发者入门Web开发的首选。今天,我们就用Flask来做一个简单的投票系统,让你快速上手Web开发,同时理解Flask的核心概…...

日常思考笔记
技术管理, 团队管理,人才培养,梯队建设 项目管理,项目全生命周期,项目进度 考核规范, AQS 是CountDownLatch,ReentrantLock,Semaphore,ReentrantReadWriteLock的基础 vo…...

【JAVA】后台管理系统密码复杂度和修改密码处理
一、后台管理系统密码要求 后台管理系统密码要求 口令有效期:90天 口令长度8位及8位以上 口令复杂度要求,至少包含以下四类字符中的三类字符: 英文大写字母(A 到 Z)、英文小写字母(a 到 z)、10个基本数字(0 到 9)、特殊字符(例如 !、$、#、%、、^、&a…...

Arduino库持续集成实战:Travis CI自动化编译测试指南
1. 项目概述:为什么Arduino库需要持续集成? 如果你和我一样,维护过几个甚至几十个Arduino库,那你一定对下面这个场景深恶痛绝:你修复了一个库里的Bug,或者添加了一个新功能,满怀信心地提交了代…...

5个简单步骤彻底解决MoviePilot连接TheMovieDb异常问题
5个简单步骤彻底解决MoviePilot连接TheMovieDb异常问题 【免费下载链接】MoviePilot NAS媒体库自动化管理工具 项目地址: https://gitcode.com/gh_mirrors/mo/MoviePilot MoviePilot作为一款优秀的NAS媒体库自动化管理工具,为你提供了便捷的影视资源管理体验…...
)
仅限本周开放|DeepSeek Chat V3.2功能测试黄金 checklist(含17个边界Case+响应时延基线数据)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Chat V3.2功能测试黄金 checklist 发布说明 DeepSeek Chat V3.2 已正式面向开发者开放灰度测试,本次版本聚焦多模态理解增强、长上下文稳定性优化及企业级安全策略集成。为保障测试…...

GeoJSON世界地图数据实战指南:从数据获取到高级可视化
GeoJSON世界地图数据实战指南:从数据获取到高级可视化 【免费下载链接】world.geo.json Annotated geo-json geometry files for the world 项目地址: https://gitcode.com/gh_mirrors/wo/world.geo.json 想要构建专业级的地理信息可视化应用却苦于找不到高质…...

AI短剧拉片应用软件2026推荐,助力高效内容分析
AI短剧拉片应用软件2026推荐,助力高效内容分析在当今的娱乐市场中,AI短剧凭借其紧凑的剧情、便捷的观看方式,受到了广大观众的喜爱。据艾瑞咨询《2026 年中国短剧行业发展报告》显示,2026 年 AI 短剧市场规模持续增长,…...

大语言模型本地化部署利器:Synaptic-Link 模型文件管理工具详解
1. 项目概述与核心价值最近在折腾一些AI相关的本地化部署和模型管理,发现一个挺有意思的项目,叫dlxeva/synaptic-link。乍一看这个名字,可能有点摸不着头脑,“突触链接”?听起来像是神经科学或者生物信息学的东西。但如…...

别再只盯着波形了!用IC617的gmid曲线,帮你快速评估工艺角下的MOS管性能
用gmid曲线簇破解工艺角难题:IC617高效评估MOS性能实战 在模拟电路设计的江湖里,工艺角(PVT)分析就像一场永无止境的攻防战。每次流片前,工程师们都要面对那个灵魂拷问:"这个偏置点在FF/SS角落下会不会…...

深入PEX8796:从Serdes到Virtual Switch,图解PCIe交换芯片的三种工作模式
深入解析PEX8796:PCIe交换芯片的架构设计与模式创新 在高速数据传输领域,PCIe交换芯片如同交通枢纽般连接着计算系统的各个组件。作为PLX公司(现已被博通收购)的经典之作,PEX8796凭借其灵活的架构设计和多样化的操作模…...

2026年国内数字人平台推荐:有哪些创作者与企业的高效创作利器?
一、引文/摘要在数字人领域,制作成本高、技术门槛高、生产效率低已成为内容创作的核心痛点。 2026年,AI数字人市场持续扩张,创作者与企业对低成本、易上手、全链路的数字人解决方案需求激增。但市场平台繁杂,功能与技术差异显著&a…...
SPI驱动NeoPixel:硬件时序优化与跨平台控制方案
1. 项目概述:当NeoPixel遇上SPI,一个关于时序的优雅解法玩过智能LED,比如Adafruit的NeoPixel或者国内常见的WS2812B灯带的朋友,大概都体会过那种又爱又恨的感觉。爱的是它单线控制、色彩绚烂,恨的是那娇贵到令人头疼的…...