Python 爬取网页文字并保存为 txt 文件教程
引言
在网络数据获取的过程中,我们常常需要从网页中提取有用的文字信息。Python 提供了强大的库来帮助我们实现这一目标。本教程将以https://theory.gmw.cn/2023 - 08/31/content_36801268.htm为例,介绍如何使用requests库和BeautifulSoup库爬取网页文字并保存为txt文件。
1. 准备工作
1.1 安装必要的库
确保你已经安装了requests和BeautifulSoup库。如果没有安装,可以使用以下命令进行安装:
pip install requests
pip install beautifulsoup4
1.2 导入相关库
在 Python 脚本中导入所需的库:
import requests
from bs4 import BeautifulSoup
import os
2. 获取桌面路径
不同操作系统获取桌面路径的方式略有不同。我们使用os库来获取桌面路径,代码如下:
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")
3. 设置要爬取的网址和请求头
3.1 定义要爬取的网址
将要爬取的网页网址赋值给变量url:
url = "https://theory.gmw.cn/2023 - 08/31/content_36801268.htm"
3.2 设置请求头
设置请求头可以模拟浏览器访问,适当降低被识别为爬虫的概率。我们将请求头信息封装在一个字典中,赋值给变量headers:
headers = {"User - Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
4. 发送 HTTP 请求并获取响应
使用requests库的get方法发送 HTTP 请求,并获取响应对象。如果响应状态码为200,表示请求成功,否则表示请求失败:
response = requests.get(url, headers=headers)if response.status_code == 200:print("请求成功")
else:print(f"请求失败,状态码:{response.status_code}")
5. 解析 HTML 文档
如果请求成功,我们使用BeautifulSoup库来解析 HTML 文档。将响应内容传入BeautifulSoup的构造函数,并指定解析器为html.parser:
soup = BeautifulSoup(response.content, 'html.parser')
6. 获取网页的所有文本内容
通过BeautifulSoup对象的get_text方法获取网页的所有文本内容,并将其赋值给变量text_content:
text_content = soup.get_text()
7. 保存文本内容到 txt 文件
7.1 拼接保存文件的完整路径
将获取到的桌面路径和文件名output.txt拼接起来,得到保存文件的完整路径:
file_path = os.path.join(desktop_path, "output.txt")
7.2 将内容写入到 txt 文件中
使用with open语句以写入模式打开文件,并将文本内容写入文件中。注意要指定文件编码为utf - 8,以确保正确保存中文字符:
with open(file_path, 'w', encoding='utf - 8') as file:file.write(text_content)
print("内容已成功保存到桌面的output.txt文件中")
完整的代码如下:
import requests
from bs4 import BeautifulSoup
import os# 获取桌面路径(不同操作系统获取方式略有不同)
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")# 要爬取的网址
url = "https://theory.gmw.cn/2023 - 08/31/content_36801268.htm"# 设置请求头,模拟浏览器访问,可适当降低被识别为爬虫的概率
headers = {"User - Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}# 发送HTTP请求
response = requests.get(url, headers=headers)if response.status_code == 200:# 解析HTML文档soup = BeautifulSoup(response.content, 'html.parser')# 获取网页的所有文本内容text_content = soup.get_text()# 拼接保存文件的完整路径file_path = os.path.join(desktop_path, "output.txt")# 将内容写入到txt文件中with open(file_path, 'w', encoding='utf - 8') as file:file.write(text_content)print("内容已成功保存到桌面的output.txt文件中")
else:print(f"请求失败,状态码:{response.status_code}")
通过以上步骤,我们就可以成功爬取网页文字并保存为txt文件。你可以根据实际需求对代码进行修改和扩展,例如进一步处理文本内容、爬取多个网页等。在进行网络爬虫时,请遵守相关法律法规和网站的使用规则,避免过度爬取造成对网站的不良影响。
相关文章:

Python 爬取网页文字并保存为 txt 文件教程
引言 在网络数据获取的过程中,我们常常需要从网页中提取有用的文字信息。Python 提供了强大的库来帮助我们实现这一目标。本教程将以https://theory.gmw.cn/2023 - 08/31/content_36801268.htm为例,介绍如何使用requests库和BeautifulSoup库爬取网页文字…...

时间序列预测论文阅读和相关代码库
时间序列预测论文阅读和相关代码库列表 MLP-based的时间序列预测资料DLinearUnetTSFPDMLPLightTS 代码库以及论文库:Time-Series-LibraryUnetTSFLightTS MLP-based的时间序列预测资料 我会定期把我的所有时间序列预测论文有关的资料链接全部同步到这个文章中&#…...

Mamba安装环境和使用,anaconda环境打包
什么是mamba Mamba是一个极速版本的conda,它是conda的C重新实现,使用多线程并行处理来加速包和依赖项的下载。 Mamba旨在提高安装、更新和卸载Python包的速度,同时保持与conda相同的兼容性和命令行接口。 Mamba的核心部分使用C实现ÿ…...

SSH连接成功,但VSCode连接不成功
环境 在实验室PC上连接服务器234 解决方案:在VSCode中重新添加远程主机 删除旧的VSCode Server 在远程主机上,VSCode会安装一个‘vscode-server’服务来支持远程开发,有时旧的‘vscode-server’文件可能会导致问题,删除旧的&am…...

springboot结合AES和国密SM4进行接口加密
api接口加密 1.为什么需要api接口加密呢? 1.防止爬虫 2.防止数据被串改 3.确保数据安全 2.如何实现接口加密呢? 3.我们可以使用哪些加密算法来加密呢? AES 密码学中的高级加密标准(Advanced Encryption Standard,…...

iOS在项目中设置 Dev、Staging 和 Prod 三个不同的环境
在 Objective-C 项目中设置 Dev、Staging 和 Prod 三个不同的环境,并为每个环境使用不同的 Bundle ID,可以通过以下步骤实现: 步骤 1: 创建不同的 Build Configuration 打开项目: 启动 Xcode 并打开你的项目。 选择项目文件&…...

openeuler24.09 系统无需配置 docker 源即可安装 docker 和 docker-composer
准备工作 1、准备一台刚刚创建的 openeuler24.09 lxc 虚拟机 2、使用 dnf 更新到最新,安装常用 工具 dnf update -y dnf install vim net-tools wget3、设置 ssh 由于ssh 与通常网上教程大同小异,在此我们就略过。 从下图我们可以看到 openeuler24.09 已经远程连接上。 …...

Flask入门:打造简易投票系统
目录 准备工作 创建项目结构 编写HTML模板 编写Flask应用 代码解读 进一步优化 结语 Flask,这个轻量级的Python Web框架,因其简洁和易用性,成为很多开发者入门Web开发的首选。今天,我们就用Flask来做一个简单的投票系统,让你快速上手Web开发,同时理解Flask的核心概…...

日常思考笔记
技术管理, 团队管理,人才培养,梯队建设 项目管理,项目全生命周期,项目进度 考核规范, AQS 是CountDownLatch,ReentrantLock,Semaphore,ReentrantReadWriteLock的基础 vo…...

【JAVA】后台管理系统密码复杂度和修改密码处理
一、后台管理系统密码要求 后台管理系统密码要求 口令有效期:90天 口令长度8位及8位以上 口令复杂度要求,至少包含以下四类字符中的三类字符: 英文大写字母(A 到 Z)、英文小写字母(a 到 z)、10个基本数字(0 到 9)、特殊字符(例如 !、$、#、%、、^、&a…...

微服务SpringCloud链路追踪之Micrometer+Zipkin
视频教程: https://www.bilibili.com/video/BV12LBFYjEvR 效果演示 当我们发送一个请求给 Gateway 的时候,由 Micrometer trace 进行链路追踪和数据收集,由 Zipkin 进行数据展示。可以清楚的看到微服务的调用过程,以及每个微服务…...
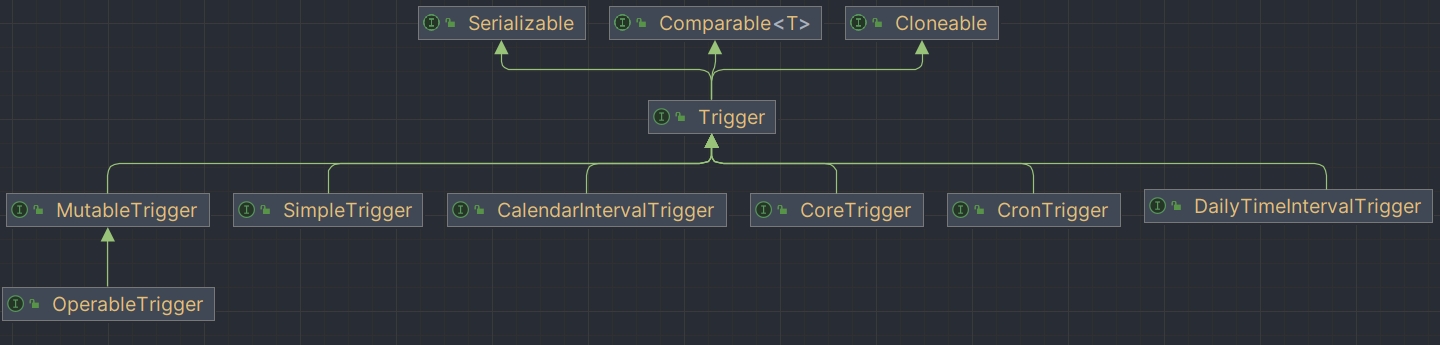
Quartz(2-Trigger)
相关文章链接 定时任务工具类(Cron Util)SpringBoot TaskQuartz(1-Job)Quartz(2-Trigger) Trigger 方法 优先级(priority) 如果你的 trigger 很多(或者 Quartz 线程…...

【微信小程序开发 - 3】:项目组成介绍
文章目录 项目组成介绍项目的基本组成结构小程序页面的组成部分JSON配置文件的作用app.json文件project.config.json文件sitemap.json文件页面的 .json 配置文件新建小程序页面修改项目首页 XWML模板XWML 和 HTML 的区别 WXSS样式WXSS 和 CSS 的区别 .js文件 项目组成介绍 项目…...

Leetcode 三角形最小路径和
算法思想与代码详解 这段代码采用的是**动态规划(Dynamic Programming)**的思想,用来解决“120. 三角形最小路径和”问题。动态规划通过将问题分解成更小的子问题,并通过保存子问题的解来避免重复计算,从而提高效率。…...
DataOps驱动数据集成创新:Apache DolphinScheduler SeaTunnel on Amazon Web Services
引言 在数字化转型的浪潮中,数据已成为企业最宝贵的资产之一。DataOps作为一种文化、流程和实践的集合,旨在提高数据管道的质量和效率,从而加速数据从源头到消费的过程。白鲸开源科技,作为DataOps领域的领先开源原生公司…...

Android Studio的笔记--BusyBox相关
BusyBox 相关 BusyBoxandroid上安装busybox和使用示例一、下载二、移动三、安装和设置环境变量四、使用 busybox源码下载和查看 BusyBox BUSYBOX BUSYBOX链接https://busybox.net/ 点击链接后如图 点击左边菜单栏的Get BusyBix中的Download Source 跳转到busybox 的下载源码…...

MySQL 存储过程与函数:增强数据库功能
一、MySQL 存储过程与函数概述 (一)存储过程的定义与特点 存储过程是一组预编译的 SQL 语句集合,它们被存储在数据库中,可根据需要被重复调用。例如,在一个电商系统中,经常需要查询某个时间段内的订单数据…...

网络安全(3)_安全套接字层SSL
4. 安全套接字层 4.1 安全套接字层(SSL)和传输层安全(TLS) (1)SSL/TLS提供的安全服务 ①SSL服务器鉴别,允许用户证实服务器的身份。支持SSL的客户端通过验证来自服务器的证书,来鉴别…...

Git 快速入门
Git 是什么? Git 是一个分布式版本控制系统四大区域: 工作区:项目文件的当前状态,即本地目录。暂存区:保存将要提交的文件快照,是一个中间层,使用git add将文件添加到暂存区。本地仓库…...

AI学习记录 - 依据 minimind 项目入门
想学习AI,还是需要从头到尾跑一边流程,最近看到这个项目 minimind, 我也记录下学习到的东西,需要结合项目的readme看。 1、github链接 https://github.com/jingyaogong/minimind?tabreadme-ov-file 2、硬件环境:英伟达4070ti …...

如何在英雄联盟国服免费体验所有皮肤:R3nzSkin换肤工具终极指南
如何在英雄联盟国服免费体验所有皮肤:R3nzSkin换肤工具终极指南 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 想要在英雄联盟国服中免费体…...

macOS微信防撤回终极指南:3分钟轻松安装WeChatIntercept插件
macOS微信防撤回终极指南:3分钟轻松安装WeChatIntercept插件 【免费下载链接】WeChatIntercept 微信防撤回插件,一键安装,仅MAC可用,支持v3.7.0微信 项目地址: https://gitcode.com/gh_mirrors/we/WeChatIntercept 还在为微…...

Kubernetes二进制文件管理工具:自动化安装与多版本切换实践
1. 项目概述与核心价值在云原生和容器化技术成为主流的今天,Kubernetes 无疑是这个领域的基石。无论是开发、测试还是生产环境,我们都需要一套稳定、可靠的 Kubernetes 集群。然而,对于很多开发者、运维工程师,甚至是刚开始接触云…...

md-wechat:让Markdown完美兼容微信公众号排版的工具实战
1. 项目概述:一个让Markdown在微信生态里“活”起来的工具如果你和我一样,是个重度Markdown爱好者,同时又需要在微信生态里频繁地分享技术文档、产品说明或者个人笔记,那你一定体会过那种割裂感。在Typora或VS Code里写得行云流水…...

CIMR-V架构:RISC-V与存内计算融合的边缘AI加速方案
1. CIMR-V架构设计背景与核心挑战在边缘AI设备领域,能效比和实时性是两个最关键的指标。传统冯诺依曼架构中"内存墙"问题尤为突出——数据在存储单元和计算单元之间的频繁搬运消耗了系统60%以上的能量。存内计算(CIM)技术通过将计算单元嵌入存储阵列&…...

Vercel反向代理实战:基于Serverless Functions构建安全API网关
1. 项目概述:一个反向代理的轻量级解决方案最近在折腾个人项目部署时,遇到了一个挺典型的问题:前端应用托管在 Vercel 上,但需要安全地调用一些部署在其他地方(比如家里的 NAS,或者某个有严格 IP 白名单限制…...

Python异步编程中的上下文管理:Ctxo工具的设计原理与实战应用
1. 项目概述:一个轻量级、高可用的上下文管理工具最近在折腾一个需要处理大量异步任务和复杂状态流转的后台服务,遇到了一个老生常谈但又很棘手的问题:如何在不同的函数调用、异步协程之间,安全、高效地传递和共享一些“上下文”信…...

IntelliJ IDEA实战:巧用Squash合并Git提交,打造清晰版本历史
1. 为什么需要合并Git提交? 刚入行那会儿,我特别喜欢频繁提交代码,每改几行就commit一次,美其名曰"版本控制"。结果一个月后回头看提交记录,满屏都是"修复bug"、"再修一下"、"最终…...

如何利用awesome-clothed-human资源构建你自己的虚拟试穿系统?
如何利用awesome-clothed-human资源构建你自己的虚拟试穿系统? 【免费下载链接】awesome-digital-human Digital Human Resource: 2D/3D/4D Human Modeling, Avatar Generation & Animation, Clothed People Digitalization, Virtual Try-On, etc. 项目地址: …...

如何用Python快速接入Taotoken平台调用多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何用Python快速接入Taotoken平台调用多模型API 对于希望快速体验不同大模型能力的开发者而言,逐一对接各家厂商的API…...