【NLP 17、NLP的基础——分词】
我始终相信,世间所有的安排都有它的道理;失之东隅,收之桑榆
—— 24.12.20
一、中文分词的介绍
1.为什么讲分词?
① 分词是一个被长期研究的任务,通过了解分词算法的发展,可以看到NLP的研究历程
② 分词是NLP中一类问题的代表
③ 分词很常用,很多NLP任务建立在分词之上
2.中文分词的难点
歧义切分
① 南京市长江大桥 ② 欢迎新老师生前来就餐 ③ 无线电法国别研究 ④ 乒乓球拍卖完了
新词/专用名词/改造词等
① 九漏鱼 ② 活性位点、受体剪切位点 ③ 虽迟但到、十动然拒
二、中文分词的方法
1.正向最大匹配
分词步骤:
① 收集一个词表
② 对于一个待分词的字符串,从前向后寻找最长的,在此表中出现的词,在词边界做切分
③ 从切分处重复步骤②,直到字符串末尾

实现方式一
1.找出词表中最大词长度
2.从字符串开头开始选取最大词长度的窗口,检查窗口内的词是否在词表中
3.如果在词表中,在词边界处进行切分,之后移动到词边界处,重复步骤2
4.如果不在词表中,窗口右边界回退一个字符,之后检查窗口词是否在词表中
#分词方法:最大正向切分的第一种实现方式import re
import time#加载词典
def load_word_dict(path):max_word_length = 0word_dict = {} #用set也是可以的。用list会很慢with open(path, encoding="utf8") as f:for line in f:word = line.split()[0]word_dict[word] = 0# 记录词的最大长度max_word_length = max(max_word_length, len(word))return word_dict, max_word_length#先确定最大词长度
#从长向短查找是否有匹配的词
#找到后移动窗口
def cut_method1(string, word_dict, max_len):words = []while string != '':lens = min(max_len, len(string))word = string[:lens]while word not in word_dict:if len(word) == 1:break# 词右边位置回退一位word = word[:len(word) - 1]words.append(word)string = string[len(word):]return words#cut_method是切割函数
#output_path是输出路径
def main(cut_method, input_path, output_path):word_dict, max_word_length = load_word_dict("dict.txt")writer = open(output_path, "w", encoding="utf8")start_time = time.time()with open(input_path, encoding="utf8") as f:for line in f:words = cut_method(line.strip(), word_dict, max_word_length)writer.write(" / ".join(words) + "\n")writer.close()print("耗时:", time.time() - start_time)returnstring = "测试字符串"
string1 = "王羲之草书《平安帖》共有九行"
string2 = "你到很多有钱人家里去看"
string3 = "金鹏期货北京海鹰路营业部总经理陈旭指出"
string4 = "伴随着优雅的西洋乐"
string5 = "非常的幸运"
word_dict, max_len = load_word_dict("dict.txt")
print(cut_method1(string, word_dict, max_len))
print(cut_method1(string1, word_dict, max_len))
print(cut_method1(string2, word_dict, max_len))
print(cut_method1(string3, word_dict, max_len))
print(cut_method1(string4, word_dict, max_len))
print(cut_method1(string5, word_dict, max_len))main(cut_method1, "corpus.txt", "cut_method1_output.txt")

实现方式二 利用前缀字典
1.从前向后进行查找
2.如果窗口内的词是一个词前缀则继续扩大窗口
3.如果窗口内的词不是一个词前缀,则记录已发现的词,并将窗口移动到词边界
4.相较于第一种方式,查找次数少很多,这就是其效率要大于第一种方式的原因,本质上是采取用更多的内存存储的前缀词典,来减少查询的次数,本质上采用空间换时间的思想
利用前缀词典,对遍历到的每一个词都进行判断,判断是否是一个词或是词的前缀,记录为1 / 0,如果遍历到的既不是一个词也不是一个词的前缀,则在当前这个词之前停下来,进行分词


#分词方法最大正向切分的第二种实现方式import re
import time
import json#加载词前缀词典
#用0和1来区分是前缀还是真词
#需要注意有的词的前缀也是真词,在记录时不要互相覆盖
def load_prefix_word_dict(path):prefix_dict = {}with open(path, encoding="utf8") as f:for line in f:word = line.split()[0]for i in range(1, len(word)):if word[:i] not in prefix_dict: #不能用前缀覆盖词prefix_dict[word[:i]] = 0 #前缀prefix_dict[word] = 1 #词return prefix_dict#输入字符串和字典,返回词的列表
def cut_method2(string, prefix_dict):if string == "":return []words = [] # 准备用于放入切好的词start_index, end_index = 0, 1 #记录窗口的起始位置window = string[start_index:end_index] #从第一个字开始find_word = window # 将第一个字先当做默认词while start_index < len(string):#窗口没有在词典里出现if window not in prefix_dict or end_index > len(string):words.append(find_word) #记录找到的词start_index += len(find_word) #更新起点的位置end_index = start_index + 1window = string[start_index:end_index] #从新的位置开始一个字一个字向后找find_word = window#窗口是一个词elif prefix_dict[window] == 1:find_word = window #查找到了一个词,还要在看有没有比他更长的词end_index += 1window = string[start_index:end_index]#窗口是一个前缀elif prefix_dict[window] == 0:end_index += 1window = string[start_index:end_index]#最后找到的window如果不在词典里,把单独的字加入切词结果if prefix_dict.get(window) != 1:words += list(window)else:words.append(window)return words#cut_method是切割函数
#output_path是输出路径
def main(cut_method, input_path, output_path):word_dict = load_prefix_word_dict("dict.txt")writer = open(output_path, "w", encoding="utf8")start_time = time.time()with open(input_path, encoding="utf8") as f:for line in f:words = cut_method(line.strip(), word_dict)writer.write(" / ".join(words) + "\n")writer.close()print("耗时:", time.time() - start_time)returnstring = "测试字符串"
string1 = "王羲之草书《平安帖》共有九行"
string2 = "你到很多有钱人家里去看"
string3 = "金鹏期货北京海鹰路营业部总经理陈旭指出"
string4 = "伴随着优雅的西洋乐"
string5 = "非常的幸运"
prefix_dict = load_prefix_word_dict("dict.txt")
print(cut_method2(string, prefix_dict))
print(cut_method2(string1, prefix_dict))
print(cut_method2(string2, prefix_dict))
print(cut_method2(string3, prefix_dict))
print(cut_method2(string4, prefix_dict))
print(cut_method2(string5, prefix_dict))
# print(json.dumps(prefix_dict, ensure_ascii=False, indent=2))
main(cut_method2, "corpus.txt", "cut_method2_output.txt")

3.反向最大匹配
从右向左进行,基于相同的词表切分出不同的结果
两者都依赖词表,都有多种实现方式
4.双向最大匹配
同时进行正向最大切分,和负向最大切分,之后比较两者结果,决定切分方式。
如何比较?
1.单字词:词表中可以有单字,从分词的角度,我们也会把它称为一个词
2.非字典词:未在词表中出现过的词,一般都会被分成单字
3.词总量:不同切分方法得到的词数可能不同
分析:我们一般认为,把词语切的很碎,分词后词的总量越少,单字字典词的数量越少,分词的效果越好
例
我们在野生动物园玩
词表:我们、在野、生动、动物、野生动物园、野生、动物园、在、玩、园
正向最大匹配法: “我们 / 在野 / 生动 / 物 / 园 / 玩”
词典词3个,单字字典词为2,非词典词为1。
逆向最大匹配法: “我们 / 在 / 野生动物园 / 玩”
词典词2个,单字字典词为2,非词典词为0。
5.jieba分词
jieba全切分词表
计算哪种切分方式总词频最高 词频事先根据分词后语料(语言材料)统计出来
依赖于一个全切分方式的词表,将基于词表的所有可能切分方式列出,计算哪种切分方式的总词频较高,把每个词的词频通过一份大的语料(语言材料)事先统计在一个文件中,然后计算哪种切分方式下的总词频最高
6.正向最大切分,负向最大切分,双向最大切分共同的缺点:
① 对词表极为依赖,如果没有词表,则无法进行;如果词表中缺少需要的词,结果也不会正确
② 切分过程中不会关注整个句子表达的意思,只会将句子看成一个个片段
③ 如果文本中出现一定的错别字,会造成一连串影响
④ 对于人名等的无法枚举实体词无法有效的处理
三、基于机器学习的中文分词
1.分词任务转化为机器学习任务
如果想要对一句话进行分词,我们需要对于每一个字,知道它是不是一个词的边界,用一个0 / 1 序列来表示某一文字是不是词边界
建立一个模型,通过这个模型对一句话中每一个字进行判断是否是词边界,并用0 / 1 表示,这种规律可以用神经网络学习
问题转化为:
对于句子中的每一个字,进行二分类判断,正类表示这句话中,它是词边界,负类表示它不是词边界
标注数据、训练模型,使模型可以完成上述判断,那么这个模型,可以称为一个分词模型
神经网络训练完成分词任务可以看作是一个序列标注问题,能够使分词任务脱离对于词表的依赖
2.构建模型
embedding嵌入层 + rnn + 线性层 + 交叉熵损失函数

① 继承父类
调用父类nn.Module的初始化方法。
② 嵌入层
创建一个嵌入层,初始化nn.Embedding,将词汇表中的每个词映射为固定维度的向量。
③ RNN层
创建一个多层RNN层,初始化nn.RNN,用于处理序列数据。
④ 线性层
创建一个线性层,初始化nn.Linear,将RNN输出映射到二维概率分布。
⑤ 损失函数
定义交叉熵损失函数,初始化nn.CrossEntropyLoss,并设置忽略padding位置的标签。
ignore_index:配合padding使用,设置padding位置值的标签label。
class TorchModel(nn.Module):def __init__(self, input_dim, hidden_size, num_rnn_layers, vocab):super(TorchModel, self).__init__()# embedding + rnn + 线性层 + 交叉熵self.embedding = nn.Embedding(len(vocab) + 1, input_dim, padding_idx=0) #shape=(vocab_size, dim)self.rnn_layer = nn.RNN(input_size=input_dim,hidden_size=hidden_size,batch_first=True,# 设置rnn的层数,两层rnnnum_layers=num_rnn_layers,)# 线性层,把每个 hidden_size 映射到二维的概率分布self.classify = nn.Linear(hidden_size, 2) # w = hidden_size * 2# ignore_index:配合padding使用,padding位置值的标签label是-100self.loss_func = nn.CrossEntropyLoss(ignore_index=-100)3.前向传播

① 输入嵌入
x = self.embedding(x):将输入 x 通过嵌入层转换为嵌入向量
输入形状:(batch_size, sen_len)
输出形状:(batch_size, sen_len, input_dim)
② RNN层处理:
x, _ = self.rnn_layer(x):将嵌入后的输入通过RNN层处理
输出形状:(batch_size, sen_len, hidden_size)
③ 分类
y_pred = self.classify(x):将RNN层的输出通过分类层进行分类
输出形状:(batch_size, sen_len, 2),重塑为:(batch_size * sen_len, 2)
④ 损失计算
if y is not None:如果提供了标签 y,则计算交叉熵损失
计算公式:self.loss_func(y_pred.reshape(-1, 2), y.view(-1)),返回损失值。
⑤ 返回预测结果:
else:如果没有提供标签 y,则直接返回预测结果 y_pred
view(): view 函数主要用于改变张量(Tensor)的维度,也就是对张量进行形状重塑(reshape),但不会改变张量中元素的存储顺序和数量
def forward(self, x, y=None):x = self.embedding(x) #input shape: (batch_size, sen_len), output shape:(batch_size, sen_len, input_dim)x, _ = self.rnn_layer(x) #output shape:(batch_size, sen_len, hidden_size) y_pred = self.classify(x) #output shape:(batch_size, sen_len, 2) -> y_pred.view(-1, 2) (batch_size*sen_len, 2)if y is not None:#cross entropy#y_pred : n, class_num [[1,2,3], [3,2,1]]#y : n [0, 1 ]#y:batch_size, sen_len = 2 * 5#[[0,0,1,0,1],[0,1,0, -100, -100]] y#[0,0,1,0,1, 0,1,0,-100.-100] y.view(-1) shape= n = batch_size*sen_lenreturn self.loss_func(y_pred.reshape(-1, 2), y.view(-1))else:return y_pred4.加载和处理数据集
① 初始化
__init__:初始化类的属性,包括词汇表 (vocab)、数据集路径 (corpus_path) 和最大序列长度 (max_length)。
调用 load 方法加载数据。
② 加载数据
load:从指定路径读取文本文件。
对每行文本进行处理:
sentence_to_sequence:将句子转换为字符序列
sequence_to_label:生成标签序列
padding:对序列和标签进行填充或截断
将处理后的序列和标签转换为 PyTorch 张量
将处理后的数据存储在 self.data 列表中
为了减少训练时间,只加载前 10000 条数据。
③ 填充或截断序列
padding():将序列和标签截断或补齐到固定长度 max_length。
序列不足的部分用 0 填充,标签不足的部分用 -100 填充。
④ 获取数据集长度
__len__:返回数据集的长度,即 self.data 列表的长度。
⑤ 获取数据项
__getitem__:根据索引返回数据集中的一个数据项。
class Dataset:def __init__(self, corpus_path, vocab, max_length):self.vocab = vocabself.corpus_path = corpus_pathself.max_length = max_lengthself.load()def load(self):self.data = []with open(self.corpus_path, encoding="utf8") as f:for line in f:sequence = sentence_to_sequence(line, self.vocab)label = sequence_to_label(line)sequence, label = self.padding(sequence, label)sequence = torch.LongTensor(sequence)label = torch.LongTensor(label)self.data.append([sequence, label])#使用部分数据做展示,使用全部数据训练时间会相应变长if len(self.data) > 10000:break#将文本截断或补齐到固定长度def padding(self, sequence, label):sequence = sequence[:self.max_length]sequence += [0] * (self.max_length - len(sequence))label = label[:self.max_length]label += [-100] * (self.max_length - len(label))return sequence, labeldef __len__(self):return len(self.data)def __getitem__(self, item):return self.data[item]
5.数据集处理

将一个文本句子转换为字符串
① 遍历句子
遍历输入的句子中的每个字符。
② 设定每个字的索引值
对于每个字符,使用字典 vocab 查找对应的索引值。如果字符不在字典中,则使用 vocab['unk'] 作为默认值。
③ 返回结果
将所有查找结果组成一个列表并返回。
#文本转化为数字序列,为embedding做准备
def sentence_to_sequence(sentence, vocab):sequence = [vocab.get(char, vocab['unk']) for char in sentence]return sequence④ 设置分词结果标注

1.分词得到词语列表
使用 jieba.lcut 对句子进行分词,得到词语列表
2.初始化标签列表
初始化一个与句子长度相同的全零标签列表
3.更新标签列表
遍历词语列表,更新标签列表中每个词语最后一个字符的位置为1
4.返回标签列表
返回最终的标签列表。
#基于jieba词表生成分级结果的标注
def sequence_to_label(sentence):words = jieba.lcut(sentence)label = [0] * len(sentence)pointer = 0for word in words:pointer += len(word)label[pointer - 1] = 1return label⑤ 加载字表

enumerate(): 是 Python 内置的一个函数,它的主要作用是在遍历可迭代对象(如列表、元组、字符串等)时,同时获取元素的索引和对应的值,通常用于需要知道元素在序列中的位置信息的情况。这可以让代码在迭代过程中更加简洁和方便,避免了手动去维护一个索引变量来记录位置。
strip():是字符串的一个方法,用于去除字符串开头和结尾的空白字符。空白字符包括空格、制表符(\t)、换行符(\n)等。
#加载字表
def build_vocab(vocab_path):vocab = {}with open(vocab_path, "r", encoding="utf8") as f:for index, line in enumerate(f):char = line.strip()vocab[char] = index + 1 #每个字对应一个序号vocab['unk'] = len(vocab) + 1return vocab⑥ 建立数据集

1.创建数据集对象
DataSet 类:通常作为一个抽象基类(在一些库中实现了基本功能框架,但常需继承扩展使用),用于对数据集进行封装和管理,将数据以及对应的标签(在有监督学习场景下)等信息以一种规范、便于操作的方式组织起来,方便后续传递给数据加载器(如 DataLoader),进而提供给模型进行训练、验证或测试等操作。
2.创建数据加载器
DataLoader类:是一个非常重要的数据加载工具。它的主要作用是将数据集(通常是继承自DataSet类的自定义数据集)按照指定的方式(如批次大小、是否打乱数据等)加载数据,使得数据能够以合适的格式和顺序高效地提供给模型进行训练、验证或测试。
3.返回数据加载器
返回搭建好的data_loader
#建立数据集
def build_dataset(corpus_path, vocab, max_length, batch_size):dataset = Dataset(corpus_path, vocab, max_length) #diy __len__ __getitem__# DataLoader:python专门用于读取数据的类,用指定的batch_size为一组对样本数据进行打乱data_loader = DataLoader(dataset, shuffle=True, batch_size=batch_size) #torchreturn data_loader6.模型训练


① 初始化参数
设置训练相关的超参数:训练轮数、每次训练的样本个数、每个字的维度、隐含层的维度、rnn的层数、样本最大长度、学习率、子表文件路径和语料文件路径
② 建立字表和数据集
调用build_vocab函数生成字符到索引的映射
调用build_dataset函数构建数据加载器
③ 创建模型和优化器
实例化第2步中构建的模型
实例化Adam优化器
④ 训练模型
在指定轮数内进行训练,每轮按批次处理数据,计算损失并更新模型参数
⑤ 保存模型
训练结束后保存模型参数
def main():epoch_num = 5 #训练轮数batch_size = 20 #每次训练样本个数char_dim = 50 #每个字的维度hidden_size = 100 #隐含层维度num_rnn_layers = 1 #rnn层数max_length = 20 #样本最大长度learning_rate = 1e-3 #学习率vocab_path = "chars.txt" #字表文件路径corpus_path = "../corpus.txt" #语料文件路径vocab = build_vocab(vocab_path) #建立字表data_loader = build_dataset(corpus_path, vocab, max_length, batch_size) #建立数据集model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型optim = torch.optim.Adam(model.parameters(), lr=learning_rate) #建立优化器#训练开始for epoch in range(epoch_num):model.train()watch_loss = []# 按照batch_size数量的数据为一组,按组进行训练for x, y in data_loader:optim.zero_grad() #梯度归零loss = model.forward(x, y) #计算lossloss.backward() #计算梯度optim.step() #更新权重watch_loss.append(loss.item())print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))#保存模型torch.save(model.state_dict(), "model.pth")returnif __name__ == "__main__":main()
7.用模型进行预测

① 初始化配置
设置字符维度、隐含层维度和RNN层数
② 建立词汇表
调用 build_vocab 函数读取词汇表文件并生成字典
③ 加载模型
创建模型实例并加载训练好的权重
load_state_dict(): 是在深度学习框架(如 PyTorch)中常用的一个方法,它主要用于加载模型的参数状态字典(state dictionary),使得模型能够恢复到之前保存的某个状态(例如之前训练好的状态,或者训练过程中某个特定阶段的状态),便于继续训练、进行模型评估或者在实际应用中使用已训练好的模型进行推理(预测)等操作。
④ 逐条预测
model.eval():将模型设置为评估模式,禁用 dropout 等训练时的行为
with torch.no_grad():不计算梯度,提高推理速度并减少内存消耗,然后对生成的测试数据进行预测
⑤ 输出预测结果
对每个输入字符串进行编码,通过模型预测,并根据预测结果切分字符串后输出
#最终预测
def predict(model_path, vocab_path, input_strings):#配置保持和训练时一致char_dim = 50 # 每个字的维度hidden_size = 100 # 隐含层维度num_rnn_layers = 1 # rnn层数vocab = build_vocab(vocab_path) #建立字表model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型model.load_state_dict(torch.load(model_path, weights_only=True)) #加载训练好的模型权重model.eval()for input_string in input_strings:#逐条预测x = sentence_to_sequence(input_string, vocab)with torch.no_grad():result = model.forward(torch.LongTensor([x]))[0]result = torch.argmax(result, dim=-1) #预测出的01序列#在预测为1的地方切分,将切分后文本打印出来for index, p in enumerate(result):if p == 1:print(input_string[index], end=" ")else:print(input_string[index], end="")print()if __name__ == "__main__":input_strings = ["同时国内有望出台新汽车刺激方案","沪胶后市有望延续强势","经过两个交易日的强势调整后","昨日上海天然橡胶期货价格再度大幅上扬","妈妈,我想你了"]predict("model.pth", "chars.txt", input_strings)

相关文章:
【NLP 17、NLP的基础——分词】
我始终相信,世间所有的安排都有它的道理;失之东隅,收之桑榆 —— 24.12.20 一、中文分词的介绍 1.为什么讲分词? ① 分词是一个被长期研究的任务,通过了解分词算法的发展,可以看到NLP的研究历程 ② 分词…...

uniapp blob格式转换为video .mp4文件使用ffmpeg工具
前言 介绍一下这三种对象使用场景 您前端一旦涉及到文件或图片上传Q到服务器,就势必离不了 Blob/File /base64 三种主流的类型它们之间 互转 也成了常态 Blob - FileBlob -Base64Base64 - BlobFile-Base64Base64 _ File uniapp 上传文件 现在已获取到了blob格式的…...

【无标题】 [蓝桥杯 2024 省 B] 好数
[蓝桥杯 2024 省 B] 好数 好数 一个整数如果按从低位到高位的顺序,奇数位(个位、百位、万位……)上的数字是奇数,偶数位(十位、千位、十万位……)上的数字是偶数,我们就称之为“好数”。 给定一…...

Leecode刷题C语言之同位字符串连接的最小长度
执行结果:通过 执行用时和内存消耗如下: bool check(char *s, int m) {int n strlen(s), count0[26] {0};for (int j 0; j < n; j m) {int count1[26] {0};for (int k j; k < j m; k) {count1[s[k] - a];}if (j > 0 && memcmp(count0, cou…...

Pytorch | 利用BIM/I-FGSM针对CIFAR10上的ResNet分类器进行对抗攻击
Pytorch | 利用BIM/I-FGSM针对CIFAR10上的ResNet分类器进行对抗攻击 CIFAR数据集BIM介绍基本原理算法流程特点应用场景 BIM代码实现BIM算法实现攻击效果 代码汇总bim.pytrain.pyadvtest.py 之前已经针对CIFAR10训练了多种分类器: Pytorch | 从零构建AlexNet对CIFAR1…...

音频进阶学习八——傅里叶变换的介绍
文章目录 前言一、傅里叶变换1.傅里叶变换的发展2.常见的傅里叶变换3.频域 二、欧拉公式1.实数、虚数、复数2.对虚数和复数的理解3.复平面4.复数和三角函数5.复数的运算6.欧拉公式 三、积分运算1.定积分2.不定积分3.基本的积分公式4.积分规则线性替换法分部积分法 5.定积分计算…...

将4G太阳能无线监控的视频接入电子监控大屏,要考虑哪些方面?
随着科技的飞速发展,4G太阳能无线监控系统以其独特的优势在远程监控领域脱颖而出。这种系统结合了太阳能供电的环保特性和4G无线传输的便捷性,为各种环境尤其是无电或电网不稳定的地区提供了一种高效、可靠的视频监控解决方案。将这些视频流接入大屏显示…...

使用docker拉取镜像很慢或者总是超时的问题
在拉取镜像的时候比如说mysql镜像,在拉取 时总是失败: 像这种就是网络的原因,因为你是连接到了外网去进行下载的,这个时候可以添加你的访问镜像源。也就是daemon.json文件,如果你没有这个文件可以输入 vim /etc/dock…...

Redis数据库笔记
Spring cache 缓存的介绍 在springboot中如何使用redis的缓存 1、使用Cacheable的例子【一般都是在查询的方法上】 /*** 移动端的套餐查询* value 就是缓存的名称* key 就是缓存id ,就是一个缓存名称下有多个缓存,根据id来区分* 这个id一般就是多个查询…...
U盘出现USBC乱码文件的全面解析与恢复指南
一、乱码现象初探:USBC乱码文件的神秘面纱 在数字时代,U盘已成为我们日常生活中不可或缺的数据存储工具。然而,当U盘中的文件突然变成乱码,且文件名前缀显示为“USBC”时,这无疑给用户带来了极大的困扰。这些乱码文件…...

多线程 - 自旋锁
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 多线程 - 自旋锁 收录于专栏[Linux学习] 本专栏旨在分享学习Linux的一点学习笔记,欢迎大家在评论区交流讨论💌 目录 概述 原理 优点与…...
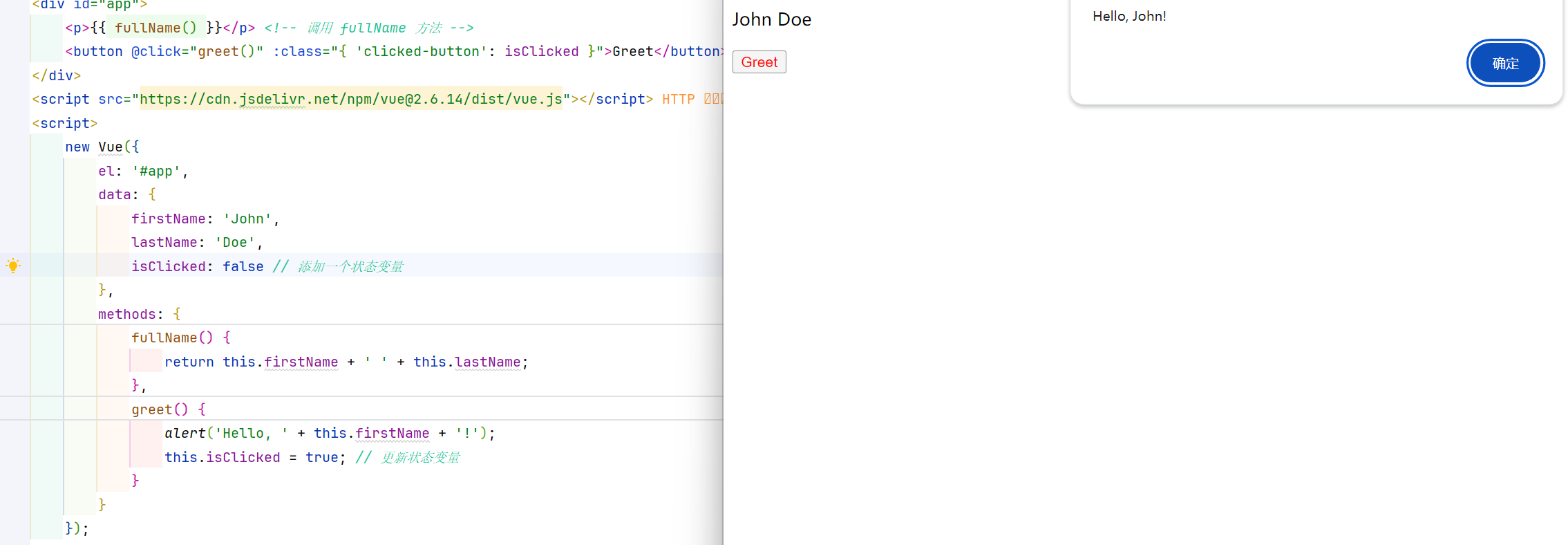
vue2 - Day02 -计算属性(computed)、侦听器(watch)和方法(methods)
在 Vue.js 中,计算属性(computed)、侦听器(watch)和方法(methods)都是响应式的数据处理方式 文章目录 1. 方法(Methods)1.1. 是什么1.2. 怎么用示例: 1.3. 特…...

Linux C 程序 【05】异步写文件
1.开发背景 Linux 系统提供了各种外设的控制方式,其中包括文件的读写,存储文件的介质可以是 SSD 固态硬盘或者是 EMMC 等。 其中常用的写文件方式是同步写操作,但是如果是写大文件会对 CPU 造成比较大的负荷,采用异步写的方式比较…...

Liveweb视频汇聚平台支持WebRTC协议赋能H.265视频流畅传输
随着科技的飞速发展和网络技术的不断革新,视频监控已经广泛应用于社会各个领域,成为现代安全管理的重要组成部分。在视频监控领域,视频编码技术的选择尤为重要,它不仅关系到视频的质量,还直接影响到视频的传输效率和兼…...

SQL组合查询
本文讲述如何利用 UNION 操作符将多条 SELECT 语句组合成一个结果集。 1. 组合查询 多数 SQL 查询只包含从一个或多个表中返回数据的单条 SELECT 语句。但是,SQL 也允许执行多个查询(多条 SELECT 语句),并将结果作为一个查询结果…...

方正畅享全媒体新闻采编系统 screen.do SQL注入漏洞复现
0x01 产品简介 方正畅享全媒体新闻生产系统是以内容资产为核心的智能化融合媒体业务平台,融合了报、网、端、微、自媒体分发平台等全渠道内容。该平台由协调指挥调度、数据资源聚合、融合生产、全渠道发布、智能传播分析、融合考核等多个平台组成,贯穿新闻生产策、采、编、发…...

【机器学习】【集成学习——决策树、随机森林】从零起步:掌握决策树、随机森林与GBDT的机器学习之旅
这里写目录标题 一、引言机器学习中集成学习的重要性 二、决策树 (Decision Tree)2.1 基本概念2.2 组成元素2.3 工作原理分裂准则 2.4 决策树的构建过程2.5 决策树的优缺点(1)决策树的优点(2)决策树的缺点(3࿰…...
如何选择)
Flink执行模式(批和流)如何选择
DataStream API支持不同的运行时执行模式(batch/streaming),你可以根据自己的需求选择对应模式。 DataStream API的默认执行模式就是streaming,用于需要连续增量处理并且预计会一直保持在线的无界(数据源输入是无限的)作业。 而batch执行模式则用于有界(输入有限)作业…...

LeetCode:101. 对称二叉树
跟着carl学算法,本系列博客仅做个人记录,建议大家都去看carl本人的博客,写的真的很好的! 代码随想录 LeetCode:101. 对称二叉树 给你一个二叉树的根节点 root , 检查它是否轴对称。 示例 1: 输…...

LDO输入电压不满足最小压差时输出会怎样?
1、LDO最小压差 定义:低压差稳压器(Low-dropout regulator,LDO)LDO的最小压差Vdo指的是LDO正常工作时,LDO的输入电压必须高于LDO输出电压的差值,即Vin≥VdoVout Vdo的值不是定值,会随着负载…...

ChatGPT插件开发者签证通道开放?深度解析2026年美国USCIS新增O-1B“AI原生应用架构师”认证路径
更多请点击: https://intelliparadigm.com 第一章:ChatGPT插件生态系统的演进脉络与O-1B新政战略定位 ChatGPT插件系统自2023年3月开放以来,经历了从封闭API集成到开放开发者协议、再到平台化治理的三阶段跃迁。早期插件依赖硬编码函数调用&…...

在多轮对话任务中实测 Taotoken 路由策略对响应成功率的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话任务中实测 Taotoken 路由策略对响应成功率的影响 1. 测试背景与场景设定 在开发需要长时间连续交互的对话型应用时&am…...

Windows下用Python调用CDS API下载ERA5数据,报错Missing/incomplete configuration?手把手教你创建.cdsapirc配置文件
Windows下Python调用CDS API下载ERA5数据报错排查指南:从配置文件创建到隐藏文件陷阱全解析 当你在Windows系统上首次尝试使用Python调用CDS API下载ERA5气象数据时,可能会遇到一个令人困惑的报错:"Missing/incomplete configuration f…...

用STM32F103C8T6驱动Ra-01SC模组:从接线到收发数据的保姆级避坑指南
STM32F103C8T6与Ra-01SC模组实战:从硬件搭建到数据收发的完整解决方案 1. 项目准备与环境搭建 第一次接触LoRa通信时,我拿着两块Ra-01SC模组和STM32开发板,满心期待能快速实现无线数据传输。但现实很快给我上了一课——接线错误导致模组发热、…...

Laravel-admin 数据权限审计终极指南:完整权限变更记录解决方案 [特殊字符]️
Laravel-admin 数据权限审计终极指南:完整权限变更记录解决方案 🛡️ 【免费下载链接】laravel-admin Build a full-featured administrative interface in ten minutes 项目地址: https://gitcode.com/gh_mirrors/la/laravel-admin 想要确保你的…...
怎么调才有效)
TCN实战避坑指南:从能源预测案例看超参数(kernel_size, dilation_base)怎么调才有效
TCN实战避坑指南:从能源预测案例看超参数调优的艺术 当你的TCN模型在能源预测任务中表现平平,先别急着换架构——很可能只是超参数没调对。上周我们团队刚用TCN完成了一个工业用电量预测项目,原始模型准确率只有72%,经过系统调参后…...

Vue2项目里,如何用DHTMLX Gantt实现任务搜索、今日线定位和视图切换?这些实用功能我帮你搞定了
Vue2项目中DHTMLX Gantt三大进阶功能实战:搜索、今日线与视图切换 在项目管理工具的开发中,甘特图作为核心可视化组件,其交互体验直接决定了用户的使用效率。本文将聚焦三个高频需求场景,手把手教你如何在已有DHTMLX Gantt集成的V…...

Java程序员什么时候要深入学习JVM底层原理?
当你工作多年之后,你遇到的项目会越来越复杂,遇到的问题也会越来越复杂:各种古怪的内存溢出,死锁,应用崩溃……这些都会迫使你不得不去深入学习JVM底层原理那么应该如何学JVM只靠周大神的JVM圣经吗?当然不够…...

AI IDE CLI:为AI编程助手打造的轻量级本地开发环境
1. 项目概述:一个为AI时代量身定制的本地开发环境CLI工具如果你是一名开发者,最近肯定没少和各类AI编程助手打交道。无论是GitHub Copilot、Cursor,还是各种本地部署的大模型,它们正在深刻地改变我们写代码的方式。但随之而来的一…...

3步轻松解锁Cursor Pro完整功能:免费使用AI编程助手的终极指南
3步轻松解锁Cursor Pro完整功能:免费使用AI编程助手的终极指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached …...