【大模型】使用DPO技术对大模型Qwen2.5进行微调
前言
- 定义
- DPO(Direct Preference Optimization)即直接偏好优化算法,是一种在自然语言处理领域,特别是在训练语言模型时使用的优化策略。它的主要目的是使语言模型的输出更符合人类的偏好。
- 背景和原理
- 在传统的语言模型训练中,通常是基于极大似然估计(MLE)来训练模型,让模型预测的下一个词的概率分布尽可能地接近训练数据中的真实分布。然而,这种方法没有直接考虑人类对于不同生成文本的偏好。
- DPO则不同,它通过直接优化人类对生成文本的偏好来训练语言模型。例如,给定一对生成文本(文本A和文本B),人类标注者会表明对它们的偏好(比如更喜欢文本A),DPO算法就会利用这种偏好信息来调整语言模型的参数。
- 从数学角度看,DPO的目标是最大化一个基于偏好的奖励函数。假设我们有一个语言模型 (p_{\theta}(y|x))(其中(\theta)是模型参数,(x)是输入,(y)是输出文本),奖励函数 (r(y)) 表示人类对生成文本 (y) 的偏好得分。DPO的目标是调整(\theta),使得生成的文本能够获得更高的奖励得分。
- 训练过程
- 首先,需要收集人类对生成文本的偏好数据。这可以通过人工标注来完成,例如让标注者比较两个由语言模型生成的文本片段,并选择更喜欢的一个。
- 然后,在训练过程中,DPO算法会根据这些偏好数据来计算损失函数。具体来说,它会比较语言模型生成的不同文本的概率和人类偏好的关系,使更受偏好的文本的生成概率相对更高。
- 例如,如果文本A比文本B更受偏好,DPO算法会调整模型参数,使得 (p_{\theta}(y = A|x)) 相对 (p_{\theta}(y = B|x)) 增大。
- 应用场景
- 对话系统:在聊天机器人的开发中,DPO可以用于训练模型,使其生成的回答更符合用户的偏好。比如,在一个客服聊天机器人中,通过DPO训练可以让机器人的回答更有礼貌、更准确,从而提高用户满意度。
- 文本生成:在故事生成、新闻写作等文本生成任务中,DPO可以帮助模型生成更吸引人、更符合人们期望的内容。例如,在生成小说情节时,使生成的情节更符合读者对于情节跌宕起伏、逻辑连贯等方面的偏好。
- 优势和局限性
- 优势
- 直接考虑人类偏好:与传统方法相比,DPO能够更直接地将人类对文本的偏好融入到模型训练中,从而生成更符合人类期望的文本。
- 灵活性:可以根据不同的任务和用户群体,灵活地收集和利用偏好数据来训练模型。
- 局限性
- 偏好数据收集困难:获取高质量的人类偏好数据是一个比较复杂和耗时的过程,需要大量的人工标注工作。
- 偏好的主观性:不同的人可能有不同的偏好,这可能会导致在训练数据收集和模型训练过程中出现不一致的情况。
- 优势
1-环境
pip install transformers trl2-数据集
- 选择数据集:根据具体的微调任务,选择合适的数据集。例如,可以选择与任务相关的文本分类数据集、对话数据集等 。确保数据集的格式符合 LLaMA-Factory 的要求,一般是 JSON 格式,包含输入文本、输出文本等必要信息.
- 数据预处理:对数据集进行必要的预处理,如清洗数据,去除噪声、重复或无效的样本等。还可以进行分词、标记化等操作,以便将文本数据转换为模型能够处理的格式.
- 标注偏好数据:对于 DPO 算法,需要人工标注或通过其他方式获取文本的偏好数据,即对于同一输入,哪一个输出更符合期望。标注数据应整理成包含 “prompt”(输入提示)、“chosen”(更优的生成响应)、“rejected”(次优的生成响应)三个键的字典形式.
1、选择数据集:lvwerra/stack-exchange-paired
2、下载数据集:可以使用 Hugging Face 的 datasets 库来加载数据集:
from datasets import load_dataset
dataset = load_dataset('lvwerra/stack-exchange-paired')
3、数据格式:将数据处理为 DPO 所需的格式。通常,DPO 需要一个包含对话对和相应偏好标签的数据集。
3-配置DPO训练
配置训练参数
你需要配置 DPO 的训练参数,包括模型配置、训练设置等。以下是一个基本的配置示例(通常保存在 YAML 文件中):
model:name_or_path: "Qwen2.5" # 替换为 Qwen2.5的模型路径或名称bos_token_id: 0 # 设置 bos_token_id,如果模型没有此 tokentraining:output_dir: "./output"per_device_train_batch_size: 8per_device_eval_batch_size: 8num_train_epochs: 3logging_dir: "./logs"logging_steps: 10evaluation_strategy: "steps"save_strategy: "epoch"dpo:draw_threshold: 0.25# 其他 DPO 特定配置创建 DPO 训练器
from trl import DPOTrainer
from transformers import AutoTokenizer, AutoModelForCausalLM
from datasets import load_dataset# 加载模型和 tokenizer
model_name = "Qwen2.5"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)# 加载数据集
dataset = load_dataset('lvwerra/stack-exchange-paired')# 配置 DPO 训练
dpo_trainer = DPOTrainer(model=model,args=train_args, # 训练参数从 YAML 文件中加载train_dataset=dataset["train"],eval_dataset=dataset["validation"],tokenizer=tokenizer
)# 执行训练
dpo_trainer.train()4-执行训练
终端运行
python train_dpo.py --config_path path/to/your/config.yaml5-评估和保存模型
训练完成后,你可以评估模型的性能,并保存微调后的模型:
# 保存模型
model.save_pretrained("./output")# 评估模型
results = dpo_trainer.evaluate()
print(results)
相关文章:

【大模型】使用DPO技术对大模型Qwen2.5进行微调
前言 定义 DPO(Direct Preference Optimization)即直接偏好优化算法,是一种在自然语言处理领域,特别是在训练语言模型时使用的优化策略。它的主要目的是使语言模型的输出更符合人类的偏好。 背景和原理 在传统的语言模型训练中&a…...

Maven 生命周期
文章目录 Maven 生命周期- Clean 生命周期- Build 生命周期- Site 生命周期 Maven 生命周期 Maven 有以下三个标准的生命周期: Clean 生命周期: clean:删除目标目录中的编译输出文件。这通常是在构建之前执行的,以确保项目从一个…...
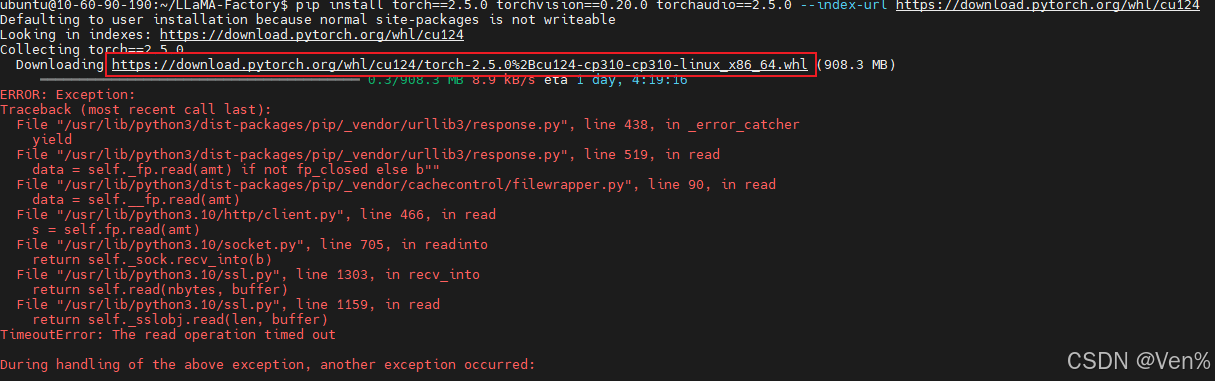
网络不通该如何手动下载torch
如果遇到pip install torch2.5.0 下载不了的情况,大部分是网络的问题.可以考虑下载wheel文件在去安装 查看对应的cuda版本(举个例子:cuda为12.4,找到这个版本的 复制到服务器上下载): 有conda和pip下载的两种方式,二者选其一:如果没有安装anaconda,就直接使用pip的方式下载 如…...

基础电路的学习
1、戴维南定理 ①左边的图可简化为一个电阻+一个电压源。② ③电压源可相当于开路。将R2移到左边,R1和R2相当于并联。RR1//R2 Rx和Rt相等时,灵敏度最大,因此使Rt10K。 104电容是0.1uf。 三位数字的前两位数字为标称容量的有效数…...

对 MYSQL 架构的了解
MySQL 是一种广泛使用的关系型数据库管理系统,其架构主要包括以下几个关键部分: 一、连接层 客户端连接管理:MySQL 服务器可以同时处理多个客户端的连接请求。当客户端应用程序(如使用 Java、Python 等语言编写的程序)…...

C#中方法参数传值和传引用的情况
对于引用类型 - 传类类型的具体值时 此时传的是引用 - 单纯传类类型 此时传的是个test引用的副本,在方法内修改的是这个副本的指向 传string,集合同理,只要是指向新对象,就是引用副本在指向 对于值类型 - 传普通值类型 …...
友好名称(FriendlyName))
获取显示器(主/副屏)友好名称(FriendlyName)
在开发涉及多显示器的应用程序时,获取显示器的友好名称(Friendly Name)是一个常见需求。本文将深入探讨GetMonitorFriendlyName 方法,了解其实现细节和工作原理。 方法签名 public static string GetMonitorFriendlyName(bool i…...

Apache Solr RCE(CVE-2017-12629)--vulhub
Apache Solr 远程命令执行漏洞(CVE-2017-12629) Apache Solr 是一个开源的搜索服务器。Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现。原理大致是文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过 http收到一个…...

2.3 携程的hook实现及dlsym函数
背景知识:(排除static 情况) 一个进程中可以有相同的命名吗? -- 不能 两个进程之间可以有相同的命名吗?--可以 一个进程和另一个静态库可以有相同的命名吗?--不能 一个进程和另一个动态库之间可以有相同…...

机器学习之KNN算法
K-Nearest Neighbors (KNN) 是一种常见的机器学习算法,广泛应用于分类和回归问题。KNN是一种基于实例的学习方法,它利用训练数据集的实例来进行分类或回归预测。在KNN中,预测的结果依赖于距离度量函数计算出的最近邻实例的标签或值。下面我们…...

《全排列问题》
题目描述 按照字典序输出自然数 11 到 nn 所有不重复的排列,即 nn 的全排列,要求所产生的任一数字序列中不允许出现重复的数字。 输入格式 一个整数 nn。 输出格式 由 1∼n1∼n 组成的所有不重复的数字序列,每行一个序列。 每个数字保留…...

pycharm 快捷键
PyCharm 是一款功能强大的集成开发环境(IDE),提供了丰富的快捷键来提高开发效率。以下是一些常用的 PyCharm 快捷键(基于 Windows/Linux 系统,Mac 系统可能略有不同): 通用快捷键 功能快捷键&a…...

若依微服务如何获取用户登录信息
文章目录 1、需求提出2、应用场景3、解决思路4、注意事项5、完整代码第一步:后端获取当前用户信息第二步:前端获取当前用户信息 5、运行结果6、总结 1、需求提出 在微服务架构中,获取当前用户的登录信息是开发常见的需求。无论是后端处理业务…...

RunCam WiFiLink连接手机图传测试
RunCam WiFiLink中文手册从这里下载 一、摄像头端 1.连接天线(易忘) 2.打开摄像头前面的盖子(易忘) 3.接上直流电源,红线为正,黑线为负 4.直流电源设置电压为14v,电流为3.15A, 通…...

TCP三次握手,四次挥手
三次握手 第一次握手:客户端向服务器发送一个 SYN 包,其中 SYN 标志位被设置为 1,表示客户端请求建立连接,并随机生成一个初始序列号 seqx 。此时客户端进入 SYN_SENT 状态,等待服务器的确认1.第二次握手:服…...

Mono里建立调试C#脚本运行环境
前面已经介绍了怎么样来执行一个嵌入式的脚本框架, 这个框架是mono编写的一个简单的例子。 如果不清楚,可以参考前文: https://blog.csdn.net/caimouse/article/details/144632391?spm=1001.2014.3001.5501 本文主要来介绍一下,我们的C#脚本是长得怎么样的,它大体如下…...

Linux dnf 包管理工具使用教程
简介 dnf 是基于 Red Hat Linux 发行版的下一代包管理工具,它代替 yum 提供更好的性能、更好的依赖处理和更好的模块化架构。 基础语法 dnf [options] [command] [package] 常用命令用法 更新元数据缓存 sudo dnf check-update# 检查已安装的包是否有可用的更…...

Java 创建线程的方式有哪几种
在 Java 中,创建线程的方式有四种,分别是:继承 Thread 类、实现 Runnable 接口、使用 Callable 和 Future、使用线程池。以下是详细的解释和通俗的举例: 1. 继承 Thread 类 通过继承 Thread 类并重写 run() 方法来创建线程。 步…...

计算机的错误计算(一百八十七)
摘要 用大模型计算 sin(123.456789). 其自变量为弧度。结果保留16位有效数字。第一个大模型是数学大模型。先是只分析,不计算;后经提醒,才给出结果,但是是错误结果。第二个大模型,直接给出了Python代码与结果…...
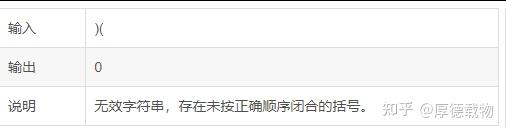
12. 最大括号深度
题目描述 现有一字符串仅由"(",")", "{","}", "[", "]"六种括号组成。若字符串满足以下条件之一, 则为无效字符串:任一类型的左右括号数量不相等 存在未按正确顺序(先左后右)闭合的括号输出…...

中兴光猫终极破解指南:3步解锁永久Telnet访问权限
中兴光猫终极破解指南:3步解锁永久Telnet访问权限 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 您是否曾经因为中兴光猫的高级功能被限制而感到困扰?无法配置…...
)
SAP ABAP SM30表维护:手把手教你实现‘运费类型’重复描述校验(附完整代码与避坑指南)
SAP ABAP SM30表维护实战:运费类型唯一性校验的深度解析 在物流管理系统中,运费类型的定义往往需要遵循严格的业务规则。一个常见的需求是确保"运输类型运费代码"与"运费描述"的组合具有唯一性,避免因描述重复导致的操作…...
)
Perplexity经济新闻搜索:5步构建专属财经情报流水线(附2024最新API调用参数)
更多请点击: https://intelliparadigm.com 第一章:Perplexity经济新闻搜索 Perplexity 是一款基于大语言模型的实时信息检索工具,其核心优势在于融合权威信源与语义理解能力,特别适用于高频更新、高时效性要求的经济新闻领域。用…...

如何深度优化Wand应用体验:Wand-Enhancer配置增强实践指南
如何深度优化Wand应用体验:Wand-Enhancer配置增强实践指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 在游戏修改工具的使用过程中&…...

N5105 4口2.5g V3 Intel i225 PVE 6.2下的Openclaw安装
一、Ubuntu 26.04安装 1. 从官网上下载ubuntu 26.04 LTS版本 下载地址:Download Ubuntu Desktop | Ubuntu 2. 将下载好的iso文件上传到pve中,登录PVE后台,点击local->ISO镜像->上传 3. 创建虚拟机 其他按默认配置即可。 4. 安装Ubu…...

Semi Design v2.98.0 发布:多项组件功能更新与问题修复,助力搭建美观 React 应用
【Feature】新增douyinfe/semi-vite-plugin包,提供 Vite 构建场景下的主题定制等能力,与douyinfe/semi-webpack-plugin特性对齐;Calendar 组件新增onMoreClickprop,支持自定义月视图下"还有几项"的点击事件;…...
)
别再死记硬背了!用Python+DEAP库5分钟搞定NSGA-II多目标优化(附完整代码)
用PythonDEAP库5分钟实现NSGA-II多目标优化实战 当我们需要同时优化多个相互冲突的目标时,比如在机器学习中既要模型精度高又要推理速度快,传统单目标优化方法就捉襟见肘了。NSGA-II(非支配排序遗传算法II)作为多目标优化领域的标…...
)
SpringBoot 2.7项目里,用Knife4j 4.3.0给API文档换个‘高级脸’(OpenAPI3实战)
SpringBoot 2.7项目里,用Knife4j 4.3.0给API文档换个‘高级脸’(OpenAPI3实战) 当你的SpringBoot项目已经完成了基础的API文档集成,接下来要思考的是如何让这份文档从"能用"变成"好用且好看"。Knife4j作为Swa…...

Vue-clipboard2 错误处理指南:如何优雅处理复制失败情况
Vue-clipboard2 错误处理指南:如何优雅处理复制失败情况 【免费下载链接】vue-clipboard2 A simple vue2 binding to clipboard.js 项目地址: https://gitcode.com/gh_mirrors/vu/vue-clipboard2 Vue-clipboard2 是一款简单的 Vue2 绑定 clipboard.js 的插件…...

从ERR_CERT_COMMON_NAME_INVALID错误,聊聊SSL证书里的Common Name和SAN到底有什么区别?
从ERR_CERT_COMMON_NAME_INVALID错误解析SSL证书中CN与SAN的演进逻辑 当你在Chrome浏览器中看到鲜红色的ERR_CERT_COMMON_NAME_INVALID警告页面时,背后隐藏的是一场持续二十年的证书标准进化史。这个看似简单的域名验证错误,实际上是现代网络安全体系对传…...