【计算机视觉基础CV-图像分类】01- 从历史源头到深度时代:一文读懂计算机视觉的进化脉络、核心任务与产业蓝图

1.计算机视觉定义
计算机视觉(Computer Vision)是一个多学科交叉的研究领域,它的核心目标是使计算机能够像人类一样“看”并“理解”视觉信息。换句话说,它希望赋予计算机从图像、视频中自动提取、有意义地分析、理解并解释视觉场景内容的能力。在这一过程中,计算机并不具备生物视觉系统的结构,而是通过摄像机、传感器等设备获取图像信息,然后利用图像处理算法、数学建模、统计学习以及深度学习方法,对影像数据进行解析与推断。
从图像到理解的过程
-
视觉输入的获取: 在生物视觉中,我们通过眼睛捕捉光信号,将其传递给大脑处理。同理,计算机视觉系统通过摄像头、传感器等设备获取原始图像或视频数据。这些设备相当于计算机的“眼睛”,将真实世界的视觉信号转化为可计算的像素数据(0和1的矩阵)。
-
数据的预处理(图像处理): 直接对原始图像进行理解是困难的。图像处理(Image Processing)技术在这里扮演重要的基础性角色。
-
图像平滑(去噪):去除图像中的随机噪声,让图像更清晰。
-
图像缩放、增强:对图像进行尺寸调整、亮度对比度提升、锐化等,使后续特征提取和分析更为稳定和易处理。
-
边缘检测、特征提取:通过提取边缘、角点、纹理、颜色等低层特征,为后续的物体识别和定位打下技术基础。
这些图像处理步骤并非计算机视觉任务的最终目的,而是为更高级的视觉分析——即真正的“理解”——做好准备。可以将图像处理看作清洁、裁剪和整理图像数据的过程,让计算机视觉“管道”后面的环节更有效地工作。
-
-
视觉特征分析与场景理解: 图像处理完成后,计算机视觉会尝试从图像中提取有意义的视觉特征并理解场景内容。这个过程包括:
-
场景识别:判断当前图像拍摄的场景类型是办公室、街道、咖啡厅还是卧室等。
-
物体检测与识别:在画面中找到人、动物、车辆、家具等特定物体,并为其分配类别标签(如“猫”、“汽车”、“人脸”)。
-
物体定位与边界框检测:不仅要识别出是什么物体,还要确定该物体在图像中的确切位置、大小、轮廓。这有助于进一步理解物体相互间的空间关系。
-
-
行为与关系理解: 进一步的计算机视觉任务包括理解物体之间的关系和图像所反映的情境:
-
关系分析:判断两个物体之间的相互作用,如两个人在交谈、一只猫正在注视窗外、一辆车正驶过斑马线。
-
场景语义理解:不仅仅是物体和场景的简单罗列,还要理解整个画面的语义,比如这是一张“庆祝生日”的照片还是“交通事故现场”的图像,画面给人的整体感受是欢乐、紧张或哀伤。
-
-
从图像到理解的闭环: 在生物视觉中,人类大脑通过长期的进化和学习,对输入的视觉信息进行复杂处理,不仅能分辨物体类别、定位物体位置,还能理解物体行为和关系,进而对环境做出反应。计算机视觉试图在数字世界中复刻这一流程:输入是摄像机拍摄的图像数据,经过图像处理与视觉分析算法的层层加工,最终输出对场景的深度理解和语义描述。
图像处理与计算机视觉的关系
-
图像处理是基础,计算机视觉是目标: 图像处理更多关注图像的“信号级”操作,比如降噪、增强、变换等,让图像数据更易于分析。 而计算机视觉更强调“理解”——即在信号层面之上构建语义层理解,从而让机器具备从图像中获得知识、推理和决策的能力。 两者可类比为:图像处理是清洗和打磨原材料的过程,计算机视觉则是用这些原材料雕塑出一个有意义的形象。
小结
计算机视觉的核心定义是赋予机器理解视觉信息的能力,就像人类用眼睛和大脑对周围世界进行感知和解释一样。其任务包括识别场景、检测和分类物体、确定物体位置与轮廓、理解物体间的交互和行为,并最终提炼出场景所表达的情绪、目的和含义。图像处理在这一过程中是重要的铺垫环节,通过基础操作和特征提取,为计算机视觉的更高级理解打下坚实基础。
2.常见任务
根据上述对计算机视觉目标任务的分解,可将其分为三大经典任务:图像分类、目标检测、图像分割


在计算机视觉领域中,最基础且常见的一些核心任务主要包括图像分类(Image Classification)、目标检测(Object Detection)、图像分割(Image Segmentation)以及进一步衍生出的各种细分任务。这些任务构成了理解视觉数据的基本框架,从单一物体类别判定到对图像中所有对象的精确定位与轮廓勾勒。下面将详细介绍这些任务,并结合给定的示意图进行说明。
1. 图像分类(Image Classification)
定义:图像分类任务是指给定一张图像,算法需要判断图像中最主要或最显著的对象类别是什么。这是计算机视觉最基础的任务之一。 特征与目标:
-
输入:一张完整图像
-
输出:一个或多个类别标签(通常是单一类别)
-
不关心物体在图像中的具体位置和数量,只关心类别本身。 例子:对于给定的猫的图片,图像分类算法只需要告诉你“这是一只猫”,而不需要指出猫在图像中位于何处。
在图示中(最左侧部分),分类仅返回CAT作为结果,无需位置框。
2. 分类+定位(Classification + Localization)
定义:在图像分类的基础上,多了定位的要求,即既要知道图像中是什么物体,又要给出其所在位置(通常用一个边界框Bounding Box来表示)。 特征与目标:
-
输入:一张完整图像
-
输出:物体类别以及单个物体的位置坐标(如Bounding Box)
-
通常假设图像中主要关注一个对象。 例子:对于猫的图片,算法不仅要说“这是一只猫”,还需要给出一个矩形框将猫圈出来。
在图示中(从左往右的第二部分),不仅有“CAT”的标签,还在猫的周围画了一个红色矩形框。
3. 目标检测(Object Detection)
定义:目标检测与分类+定位类似,但适用于图像中存在多个对象的情况。任务是找出所有感兴趣对象的类型和它们在图像中的位置框。 特征与目标:
-
输入:一张图中可能有多种物体
-
输出:每个物体所属类别的标签和该物体的边界框
-
典型输出是一个列表,包括物体类别和对应的Bounding Box坐标。 例子:在一张包含猫、狗、鸭子多个动物的图片中,目标检测算法会识别出所有对象,并用不同的框表示每个对象的位置,同时给出每个框中对象的类别。
在图示中(第三部分),可以看到多只动物(如图中标出“CAT”、“DOG”、“DUCK”)各有自己的边框。
4. 图像分割(Image Segmentation)
图像分割相较于目标检测更进一步,它不仅要知道物体的类别和位置,还要像素级地标注出物体的精确轮廓。图像分割又可分为两类:语义分割(Semantic Segmentation)和实例分割(Instance Segmentation)。
-
语义分割(Semantic Segmentation): 定义:将图像中的每个像素分配一个类别标签,即把整个图像分为若干语义区域。 特征:
-
对同一类别的所有像素不加区分地标记同一种颜色或同一标签。
-
不区分个体实例之间的差异(比如两只猫分别在哪,只知道该区域像素属于“猫”这一类别)。
举例:如果图中有两只猫,语义分割的结果会把所有猫像素涂成同样的颜色或标签,只区分类别,不区分实例间的差异。
-
-
实例分割(Instance Segmentation): 定义:在语义分割的基础上进一步区分同类物体的不同实例。 特征:
-
每个对象实例都有独立的像素级分割区域(即使属于同一类别的两个物体,在分割图中也会用不同颜色或标记来区分)。
-
可以同时做到语义层次的理解(类别)和实例层次的区分(个体差异)。
举例:如果图中有两只猫,实例分割会为每只猫的像素区域给予独立的标记,让你分辨出图中具体有哪两只猫,而不仅仅是“这儿有猫的像素”。
-
在图示中(最右侧部分),实例分割明确给出了三个对象(猫、狗、鸭子)各自的轮廓。注意同一类别物体的不同实例(如两只猫)也使用不同颜色进行标注,从而区分不同的个体。
总结
-
图像分类(Classification):单一对象类别识别,不关心位置。
-
分类+定位(Classification+Localization):单一对象类别识别并给出位置框。
-
目标检测(Object Detection):多个对象的分类与定位。
-
语义分割(Semantic Segmentation):按像素级别对图中每个区域进行类别分类,不区分同类物体的实例。
-
实例分割(Instance Segmentation):像语义分割一样按像素分割,但进一步区分相同类别物体的不同实例。
这些基础任务在实践中经常作为更复杂计算机视觉应用的基础。例如:自动驾驶中的行人检测与分割、医疗影像中的组织分类和分割、图像检索、机器视觉质检、AR/VR场景理解等。这张示意图帮助我们直观地理解从最基础的分类任务到更复杂细粒度的实例分割的渐进过程。
3.应用场景

人工智能时代下的视觉与图像产业图谱是对整个计算机视觉(Computer Vision, CV)和图像处理领域相关企业、应用方向、技术模块、行业解决方案的一个系统梳理与概览。通过这类产业图谱,我们可以看到从底层技术到上层应用、从通用场景到垂直行业的层层分布,以及相关公司和解决方案如何分布在各个板块中。
以下将从技术层面、应用领域以及产业结构三方面对“人工智能视觉与图像”产业图谱进行详细描述:
一、技术层面
-
基础算法与技术框架:
-
图像分类(Image Classification)、目标检测(Object Detection)、图像分割(Image Segmentation)、人脸识别(Face Recognition)、文本识别(OCR)、图像识别与检索等,这是计算机视觉的基础任务。
-
深度学习模型与框架:如TensorFlow、PyTorch、Caffe等深度学习框架为视觉算法的开发和训练提供支持;
-
传统图像处理与机器视觉软件:如Halcon、OpenCV等,用于工业级检测或传统机器视觉任务的算法组件和工具库。
-
-
感知与理解:
-
图像/视频编辑和增强:包括图像修复、风格迁移、图像质量提升、视频分析与处理等技术。
-
三维视觉(3D Vision):如结构光、TOF深度相机和激光雷达数据处理,用于机器人导航、AR/VR、3D重建、自动驾驶环境感知等。
-
多模态融合:将视觉与自然语言处理(NLP)、语音处理、传感器数据融合,以实现更丰富的场景理解和上下文关联分析。例如:图像描述生成、图像问答(VQA)。
-
-
平台与工具:
-
数据标注与管理平台:为训练视觉模型提供高质量标注数据的服务和工具;
-
模型训练与部署平台:如AutoML、Model-as-a-Service、推理加速器(GPU、ASIC、FPGA)以及云端部署和边缘部署方案;
-
安全与隐私保护技术:包括人脸脱敏、加密与匿名化处理,以符合数据隐私要求。
-
二、应用领域
-
工业制造与机器视觉:
-
质量检测、异常检测:自动检测产品外观缺陷、尺寸偏差等;
-
工业机器人视觉:为机器人提供定位和引导,提升自动化与灵活性;
-
安全生产:通过视觉识别安全帽、安全带佩戴情况,监测烟火等危险源。
-
-
智能安防与视频监控:
-
人流量检测、人脸识别、行为分析、异常事件报警;
-
适用于公共安全、智慧交通、楼宇监控、智能家居安防等场景。
-
-
医疗影像诊断:
-
利用医学影像(CT、MRI、X光等)的智能分析辅助医生诊断;
-
实现病灶检测、组织分割、辅助诊断建议,提高诊断效率与精准度。
-
-
零售与商业:
-
通过人流量统计、顾客行为分析、货架商品识别,实现智能门店管理;
-
商品识别与结算(如无人便利店)提高顾客体验与运营效率。
-
-
自动驾驶与智能出行:
-
视觉是自动驾驶感知层的关键模块,对道路、车辆、行人、障碍物进行识别和轨迹预测;
-
配合激光雷达、毫米波雷达等传感器提高环境感知精度和安全性。
-
-
农业、医疗、教育、文娱等其他场景:
-
农业:农作物生长情况识别、病虫害识别、产量预测;
-
教育:在线考试监考、课堂学生行为分析;
-
娱乐与传媒:图像特效处理、人脸变换、影像修复等。
-
-
OCR与自然语言融合应用:
-
识别图像中的文字信息用于证件审核、票据识别、文档电子化;
-
为法律、金融、保险、工商税务等行业提供效率提升和自动化服务。
-
三、产业结构与生态链条
-
算法与技术提供方:
-
初创公司、研究型团队和高校实验室提供原创算法、模型和技术研究成果;
-
行业领先企业(如各大科技巨头)提供通用平台、产品和技术解决方案。
-
-
数据与标注服务商:
-
专注为视觉模型训练提供高质量数据集标注、数据清洗及数据增强服务。
-
-
硬件及设备厂商:
-
提供摄像头、传感器、GPU加速卡、边缘计算设备;
-
智能相机、工业相机与视觉成像设备为视觉算法落地提供基础感知硬件。
-
-
系统集成与解决方案商:
-
将算法和硬件整合到行业场景中,为制造业、零售业、安防业、医疗等垂直领域定制整体方案;
-
通过项目实施、培训、维护等服务将技术最终转化为生产力。
-
-
行业用户与应用方:
-
工厂、医院、商场、政府机构、交通运输部门、农业企业、保险金融机构等终端用户,通过引入视觉智能方案实现降本增效和业务升级。
-
四、典型特征与趋势
-
多元融合与跨界应用:CV与NLP、时序数据分析、物联网传感器融合,打破单一数据模态局限。
-
边缘计算与隐私保护:随着5G与边缘计算的发展,将更多计算下沉至终端设备,降低带宽与延迟,并通过安全加密与隐私保护技术满足合规要求。
-
自动化与低门槛开发:平台化、工具化趋势降低了使用门槛,中小企业也能快速部署视觉解决方案。
-
行业标准化与生态成熟:随着市场成熟,出现更多标准接口、数据集和测试基准,有利于促进产业快速良性发展。
综上,“人工智能视觉与图像”产业图谱是一个横跨基础研究、技术平台与工具、数据服务、硬件支持、系统集成和垂直应用的庞大生态。各个模块之间形成互补和协作关系,推动视觉智能技术在各行各业深度渗透,产生广泛的经济与社会价值。

人脸识别技术现如今已广泛应用于各类场景,从安全门禁、金融认证到智能终端的人机交互。下面结合图片中列出的典型应用场景进行详细说明:
-
考勤、门禁: 人脸识别被广泛用于公司、学校及其他机构的考勤系统和门禁控制系统。传统的刷卡考勤和门禁容易出现代打卡或卡片遗失的问题,而通过摄像头实时识别人脸,可确保来访和出入人员的身份真实性,极大地提高了考勤和出入安全性。
-
身份认证(实名认证): 在金融服务、电子政务、电子商务等领域,人脸识别作为身份验证手段已经十分普及。例如,手机银行、支付APP会通过人脸比对用户身份;在办理网上业务(如SIM卡注册)时,人脸识别辅助实名制校验。这种方式比传统密码、验证码更加直观便捷,也减少了被盗用的可能。
-
人脸属性识别: 人脸识别不仅能判断一个人的身份,还能分析其年龄、性别、情绪、表情特征等。这种属性识别有助于市场分析、用户画像、精准广告投放等。同时,通过情绪分析可在教育、医疗、公共场所中实现更智能化的服务体验,如在课堂上检测学生专注度,在零售店分析顾客情绪以提升营销策略。
-
人脸检测与跟踪: 在视频监控、智能安防系统中,通过人脸检测和跟踪可实现实时监控对象的自动识别和定位。当一个人出现在摄像头画面中,系统可自动锁定并跟踪其面部,以便记录、预警或后续数据分析。 而对于“摔倒检测”,虽然图片中提到的是人体行为检测的延伸(并非纯人脸识别),但当结合人脸及肢体动作识别时,可以在养老院、医院、独居老人监护等场合实时发现摔倒事件,及时给予报警。
-
真人检测(活体检测): 又称“防伪识别”或“人脸活体检测”,可防止通过照片、视频、屏幕翻拍等方式伪装身份。活体检测常利用3D结构光、红外活体检测和眨眼、点头等动作分析来区分真人与假体。这对金融交易、重要门禁及敏感数据访问而言尤为关键。
-
人脸对比: 通过人脸对比技术可快速判断两张人脸图像是否属于同一人。这在安防、刑侦、签证审核等领域应用广泛。例如,警方可将监控拍到的嫌疑人照片与数据库中的人员信息进行比对,以快速锁定目标。
-
人脸搜索(大规模人脸检索): 利用特征提取与索引技术,在庞大的数据库中快速找到与给定人脸相匹配的对象。这可用于寻人启事、VIP客户识别、机场出入境审查等场合。
-
人脸关键点定位(Keypoint Detection): 人脸关键点检测是指对人脸的眼角、嘴角、鼻尖、下巴等特征点进行精确定位。这是很多高级任务的基础,如表情识别、3D重建以及美颜滤镜和AR特效(例如在自拍时根据面部关键点自动加特效、贴纸等)。
-
3D结构光与深度信息(图片中所标记的3D结构光): 在一些高安全级别场景中,会使用3D结构光或ToF(Time of Flight)摄像头,捕捉人脸的深度信息,从而更精准地构建人脸3D模型,提高识别精度与抗伪造能力。
综上,人脸识别的应用场景从最基础的身份核验、出入控制,逐渐扩展到金融安全验证、智能安防、营销分析、医疗护理、用户体验优化等各类领域。同时,相关技术如活体检测、属性分析、3D结构光应用、关键点定位的不断成熟与融合,为人脸识别行业创造更多可能性,推动其在各行各业深度落地。

视频监控是计算机视觉的典型应用场景之一,通过对实时或存档的视频流进行分析和理解,实现对人、车、物等各类目标的自动监测与识别。借助人工智能和深度学习技术,视频监控已从最初的简单影像记录与回放工具转变为集智能识别、实时预警、行为分析与预测为一体的综合解决方案。
核心技术与流程
-
视频采集与数据管理: 视频监控体系的基础是由分布在各个区域的摄像头(包括传统高清摄像头、全景相机、热成像相机等)持续获取视频流。通过网络和视频管理系统(VMS)将视频汇聚到中心服务器,实现统一的存储与管理。
-
目标检测与识别: 在视频中,计算机视觉算法(如基于深度学习的YOLO、Faster R-CNN、SSD、CenterNet等模型)可对画面中的人、车辆、物体进行实时检测,并识别其类别与属性。
-
人物识别:通过人脸识别技术,根据特征提取与比对实现快速定位特定嫌疑人或走失人员。还可识别人物的年龄段、性别、服饰颜色等属性,为人群统计和行为分析提供参考。
-
车辆识别:识别车辆类型(小轿车、货车、公交车等)、车牌号码、品牌型号,实现对车辆出入、行驶轨迹的准确记录。
-
物品检测:在特定场景中(如商场货架、仓库、车站安检口),通过对行李箱、包裹、商品、可疑物品的检测,实现精确的物品定位、库存盘点和异常预警。
-
-
行为分析与属性判定: 视频监控不仅要识别对象,还要理解其行为与状态:
-
人员行为分析:通过轨迹跟踪、姿态估计和动作识别技术,分析行人的运动路径、停留时间、聚集行为。可实现发现可疑行为(如奔跑、打斗、倒地)、异常事件(如非法越界、尾随进入、翻越围栏)等自动预警。
-
车流与交通行为监测:对公路、路口的车流量、车速、排队长度、闯红灯行为进行统计与分析,辅助交通管理与调度。
-
人群密度与客流分析:在商场、车站、体育场、展览会等人群聚集场所,监控系统可统计人群密度、客流走势和停留区域,以便场馆方进行疏导和优化服务。同时,当人群拥挤或异常聚集时,系统可触发警报,帮助安保人员及时介入。
-
-
多摄像头与跨场景跟踪: 现实中的监控网络通常由多台摄像机组成。为实现对目标跨场景、跨摄像头连续跟踪,需要多摄像头协同计算与信息融合技术。通过图像的时空关联、目标再识别(Re-ID)技术,可以在不同摄像头间识别同一目标的出现轨迹,形成完整的活动链路。
-
智能检索与回溯分析: 在海量视频数据中寻找某个人、某辆车或特定事件的传统方法往往是人工查看大量录像,非常耗时。 借助结构化视频分析技术,系统会在视频中自动标注出“人物”、“车牌”、“颜色”、“类型”等标签,用户可以通过查询条件(如某个时间段、穿红衣服的中年男性、白色轿车)快速检索相关视频片段,大大提高了事后分析的效率与准确性。
典型应用场景
-
公安与安防:
-
城市安防体系:借助视频监控智能分析,对重点区域、公共空间进行24小时不间断监控,一旦发生治安问题、犯罪行为或突发事件,系统可第一时间报警。
-
案件侦查与嫌疑人定位:利用人脸识别和目标再识别技术,警方可在数以万计的监控摄像头画面中快速定位嫌疑人行踪,提高破案效率。
-
-
交通运输与智能出行:
-
交通流量检测与信号优化:实时分析车流量、车速和拥堵程度,自动调整信号灯周期,提高道路通行效率。
-
违章识别与处罚:对闯红灯、逆行、占用应急车道等行为进行智能检测和记录,辅助交通执法。
-
-
商场与零售:
-
顾客行为分析:分析客户在商场中的行走路径、驻留时间、关注商品位置,为零售商提供布局优化建议。
-
商品盘点与防损:通过摄像头自动识别、记录货架商品数量,出现缺货或被盗情况立即报警。
-
-
公共安全与防控预警: 在地铁站、机场、会展中心等人流密集的场所,通过对人群异常变化和可疑人员行为进行实时监控与分析,及时启动疏导措施或安保干预。
技术趋势与发展方向
-
深度学习与模型优化:卷积神经网络(CNN)、Transformer等深度模型的持续进步使目标检测、分类、跟踪算法越来越精确、鲁棒。未来还将更加高效、轻量化,便于边缘计算。
-
多模态融合:除可见光摄像头外,热成像、激光雷达、雷达、3D传感器数据的融合可在低光、恶劣天气下仍保持较高的识别准确度。
-
隐私与安全:随着监控越来越智能化,对个人隐私与数据安全的关注不断提升。未来在算法设计、数据处理与法规方面将更加重视隐私保护。
结语
视频监控在计算机视觉中占有重要地位,通过对海量实时视频进行智能分析与结构化处理,已广泛应用于安防、交通、商业、公共服务等领域。借助不断发展的深度学习与多模态融合技术,视频监控系统正在从简单的“记录”迈向智慧的“洞察”,帮助社会各领域实现更高效、安全和便捷的运营管理。

图像识别分析是指利用计算机视觉与深度学习等人工智能技术,从图像中提取有用的语义信息,对图像内容进行理解和分类。通过对图像内的物体、场景、人物、商品等进行识别与分析,实现自动化的信息提取与处理。下面结合图片中列出的典型应用场景进行详细说明:
-
以图搜图(相似图片搜索): 在搜索引擎、电子商务平台以及图片库管理中常用的技术。用户不再需要通过输入关键词来检索,而是上传一张图片,系统通过提取该图片的视觉特征(如颜色、纹理、形状、深度特征)在图像数据库中寻找相似度较高的图片。当用户希望找到与所提供图片内容相似或相同的图像时,以图搜图能快速给出匹配结果。
-
应用示例:电商平台用户上传某件商品的照片,系统自动检索出相似款式或同款商品。
-
-
物体/场景识别: 这是图像识别最基础和广泛的应用之一。通过训练深度神经网络(如CNN、Transformer模型),系统可以识别图片中有哪些物体和场景,如识别图片中有“猫”“狗”或“山”“海滩”“城市街景”等。
-
应用示例:自动驾驶车载视觉系统识别前方场景和路牌;图片管理软件根据场景为照片打标签(如“海滩度假”)、提供相簿分类。
-
-
车型识别: 专门针对汽车进行识别与分析的任务。不仅能识别出图中是辆汽车,还能进一步识别出汽车品牌、车型与年份。该技术在智能交通、停车场管理、汽车保险理赔以及车辆大数据统计等场景中发挥重要作用。
-
应用示例:智慧停车系统通过车牌识别、车型识别自动扣费并统计车流量;交警部门通过车型识别进行特定车辆追踪。
-
-
人物属性、服装、时尚分析: 在人像识别基础上,进一步提取人物的属性特征,如性别、年龄段、表情、发型以及服装类型、服饰风格。同时,一些时尚相关的AI服务可根据服装风格为用户推荐搭配或相似款式,实现个性化的时尚分析和商品推荐。
-
应用示例:电商平台根据用户上传的街拍照,识别服装风格并推荐相似单品;社交媒体应用分析用户的穿搭风格,提供个性化时尚建议。
-
-
商品识别: 商品识别旨在通过图像直接识别商品类型、品牌、型号,或甚至标志、条码。这个技术广泛应用于零售、仓储和电商领域,可支持手机识别商品进行比价、AR购物应用中“看见即购买”的交互体验。
-
应用示例:消费者用手机摄像头扫描商品,识别商品信息并在线比价、查看评价。
-
-
鉴别违法、不良内容(如鉴黄、识别暴力内容): 在内容审查、社交媒体监控和媒体分发平台中,图像识别分析可识别图片中是否存在淫秽、色情、暴力、血腥等不良内容。通过自动过滤与标记,这类技术可以辅助平台方维护健康安全的网络环境。
-
应用示例:社交媒体在用户上传图片时自动审查内容,阻止不良信息传播;内容分发网络(CDN)根据图像分析为用户提供符合当地法律法规及文化规范的内容。
-
技术实现与发展趋势
-
底层技术:深度卷积神经网络(CNN)以及近年来兴起的Vision Transformer(ViT)模型显著提升了图像识别的精度和鲁棒性。
-
数据驱动与标注:大量高质量标注数据集(如ImageNet、COCO、OpenImages)推动图像识别技术进步。
-
多模态融合:图像识别与自然语言处理、多传感器数据相结合,可实现更丰富的图像理解,如图像描述生成、视频内容分析等。
-
边缘计算与低功耗部署:随着移动和嵌入式设备应用增多,轻量化模型与硬件加速技术使图像识别能够在终端设备实时运行。
总结
图像识别分析已经从最初的基本物体识别扩展到场景理解、属性提取、时尚分析、内容审查和多场景应用。从互联网搜索、电子商务到智能交通、智能安防和新媒体内容监管,图像识别技术正在深入各行各业,为人们提供更加智能、便捷、安全的服务体验。
驾驶辅助(ADAS,Advanced Driver Assistance Systems)是指利用计算机视觉、图像处理、深度学习、传感器融合(如摄像头、激光雷达、毫米波雷达、超声波雷达、GPS/IMU组合)以及高精地图等技术,为驾驶者在行车过程中提供实时帮助和预警,从而降低事故风险、提升行车安全与舒适性。这些功能最终目标是为实现高度自动驾驶奠定技术基础。
图片中列出的关键应用场景,具体介绍如下:
-
车辆及物体检测、碰撞预警:
-
应用场景:车道行驶中,系统通过摄像头、激光雷达或毫米波雷达实时检测前方及周围的汽车、摩托车、自行车、行李箱、路障等物体。
-
实现方式:计算机视觉算法(如目标检测模型 YOLO、Faster R-CNN 等)实时识别前方道路上的车辆及其他障碍物,同时估计其相对速度和距离。
-
作用:一旦检测到有潜在碰撞风险(如前车急刹、突然冲出的行人、静止障碍物),系统发出声光警报,提示驾驶员及时采取制动或转向动作。高级系统还可自动刹车(AEB,自动紧急制动),有效减少追尾事故。
-
-
车道检测、偏移预警:
-
应用场景:车辆高速行驶在道路上,驾驶者有时会因为疲劳、分心或者路况不佳而偏离车道。车道线检测技术可通过前视摄像头获取路面影像,定位车道线的位置与形态。
-
实现方式:采用图像处理、深度学习分割模型(如LaneNet)或传统Canny边缘检测+Hough变换等方法,识别出当前车道线。
-
作用:若系统检测到车辆正无意偏离车道,会通过方向盘震动、蜂鸣器报警或可视化提示提醒驾驶员校正方向。部分高级驾驶辅助还支持车道保持(LKA),在一定条件下自动微调方向盘,防止车辆偏离车道。
-
-
交通标识识别(Traffic Sign Recognition,TSR):
-
应用场景:行驶过程中遇到限速牌、禁止超车牌、指示标志、警告标志等交通标志,驾驶员可能会因为注意力不集中忽略这些信息。
-
实现方式:利用车载摄像头采集前方道路影像,通过图像识别算法(如基于卷积神经网络的分类模型)识别出交通标志的类别和含义。
-
作用:将识别结果显示在仪表盘或中控屏上,提醒驾驶员当前道路规则(如限速),从而帮助其规范行驶。这在跨区域驾驶、 unfamiliar 路段行驶时尤为有用。
-
-
行人检测:
-
应用场景:密集的城市街道、十字路口、商场停车场入口等地,行人随时可能穿行马路。驾驶员若视线被遮挡或注意力分散,容易引发碰撞事故。
-
实现方式:通过摄像头、行人检测模型(如SSD、YOLO或专门的人形检测模型)对图像进行分析,从背景中区分出行人的轮廓和位置。高级方案可能利用红外摄像头在夜间或低光条件下检测行人。
-
作用:一旦检测到行人突然闯入车前路径,系统及时发出警报甚至自动刹车,可大幅降低行人碰撞风险。
-
-
车距检测:
-
应用场景:在高速行驶或跟车状态下,保持安全跟车距离至关重要。若跟车过近,一旦前方车辆减速,后车可能无法及时反应而导致追尾事故。
-
实现方式:通过摄像头和深度估计算法,或利用毫米波雷达测出与前车的距离和相对速度。同时配合车速信息评估安全车距。
-
作用:系统根据实时车距信息提醒驾驶员保持合理车距,当距离过近或有潜在碰撞可能时及时预警。定速巡航中使用自适应巡航控制(ACC)技术,可自动调整车速以保持安全车距。
-
其他相关技术与趋势
-
SLAM(Simultaneous Localization and Mapping)技术: 在自动驾驶中,SLAM帮助车辆实时构建环境地图并定位自身位置。组合摄像头与激光雷达数据,精确实现车辆在动态环境下的自主导航和路径规划。
-
视觉+激光雷达(点云数据)融合: 将摄像头获取的二维图像信息与激光雷达的点云信息融合,可以得到更高精度的环境感知。这样不仅可区分物体种类,还能精确计算距离与三维轮廓,提高检测的稳定性和鲁棒性,特别是在光线和天气条件不佳的情况下。
-
高精地图与V2X通信: 配合高精度地图和车联网(V2X)技术,驾驶辅助系统可提前了解前方路况、交通标志位置、道路曲率及交叉口结构,提高预判能力。
总结
驾驶辅助主要应用场景涵盖车辆与障碍物检测、车道偏离预警、交通标志识别、行人检测以及车距保持。这些功能让驾驶员在行驶过程中更加安全、轻松。借助视觉、激光雷达、雷达、GPS/IMU以及智能算法的综合应用,ADAS系统为最终实现全自动驾驶做好技术铺垫。同时,随着技术不断演进,ADAS的功能将越来越丰富与智能,为行车安全、车辆管理和用户体验带来持续升级。

上图中列出的应用场景展示了计算机视觉技术在更广泛领域内的多样化应用。这些场景不仅包括传统的二维图像分析,还延伸到三维重建、工业仿真、地理信息系统(GIS)等高阶应用,以及各类垂直行业的具体需求。下面将对图片中提及的应用场景一一进行详细说明。
-
三维视觉与三维重建
-
应用背景:除了对二维图像的理解,计算机视觉可从多视角图像或深度传感器数据中恢复出场景或物体的三维结构。这类技术在机器人、AR/VR、无人驾驶和影视特效中都很常见。
-
典型技术:传统上使用多视图几何(Structure from Motion, SfM)、多视图立体(MVS)、激光雷达点云处理、RGB-D相机数据融合等方法;近年来,NeRF(Neural Radiance Fields)等神经渲染技术通过深度学习对场景进行建模与逼真渲染。
-
应用领域:
-
工业仿真和设计:帮助快速建立产品3D模型,辅助工业设计、质量检测与训练仿真。
-
文物保护与虚拟展示:扫描博物馆藏品或历史遗址,生成高精度3D模型用于数字化存档与在线虚拟漫游。
-
AR/VR应用:创建真实感强的虚拟场景,提升沉浸式体验。
-
-
-
工业仿真
-
利用计算机视觉技术获取工业生产线数据及设备外观的精确三维模型,实现生产过程模拟和优化。
-
在工业4.0背景下,视觉系统可实时监测设备状态,并在虚拟环境中对生产流程进行模拟、改进和故障诊断。
-
-
地理信息系统(GIS)
-
应用背景:GIS需要处理遥感影像、卫星图像、航拍图像等,获取地理、地形特征与变化趋势,进一步用于测绘、规划与决策。
-
典型任务:
-
植被覆盖率分析:利用遥感和卫星图像,通过图像分割、分类计算区域内植被、水体、建筑的比例与分布。
-
小目标检测:在卫星影像或航拍图中识别桥梁、车辆、船只、建筑等小规模目标,以用于监测交通流量、城市规划、灾害评估或军事侦察。
-
地物分类:对地表类型进行语义分割,将区域分为森林、农田、沙漠、水体、城市建设区等,从而支持土地利用分析和环境保护决策。
-
-
-
医疗影像诊断
-
应用背景:医疗成像技术(MRI、CT、X光、超声等)产生大量二维或三维医学影像数据。计算机视觉和深度学习技术可辅助医生对这些影像进行病灶检测、组织分割及手术规划等。
-
典型任务:
-
病灶检测与分割:自动识别肿瘤、心脏病变等特定组织或异常区域,辅助早期筛查和诊断。
-
器官与组织3D重建:帮助医生更直观地了解患者解剖结构,辅助精准手术导航。
-
-
-
文字识别(OCR)
-
应用背景:OCR(Optical Character Recognition)可从图像中自动提取文字信息。这在文档数字化、快递单据处理、交通标志识别等方面十分普及。
-
典型任务:
-
文档图像处理:识别与提取纸质文件中的文本,将其转化为可搜索、可编辑的电子文本。
-
场景文本识别:处理室外广告牌、路标、产品包装文字信息,为导航、盲人辅助、零售等应用提供便利。
-
-
-
图像及视频编辑
-
应用背景:计算机视觉技术为图像和视频的编辑、修复、增强、检索提供强大支持。
-
典型任务:
-
图像修复与超分辨率:通过智能补全、降噪、超分辨率重建等方法提升图像质量。
-
自动视频剪辑与内容分析:为传媒、影视制作中的智能化后期编辑、关键帧提取、镜头分析提供工具。
-
-
-
遥感与卫星图像分析
-
通过处理多光谱或高光谱卫星图像,可以分析农作物健康状况、森林火灾、冰川变化、海洋污染、城市扩张以及自然灾害的影响。
-
将计算机视觉与GIS相结合,可以对遥感数据进行特征提取与情景理解,为地理制图、生态监测、资源开发决策提供数据支持。
-
-
航拍图像与无人机视觉
-
无人机配备摄像头可实现实景建模、基础设施巡检(如电力线巡检、油气管道巡检)、救灾评估(地震、洪水后快速探测)和农业监测(农田长势、病虫害检测)。
-
小目标检测技术在无人机拍摄的高空影像中尤为重要,用于识别建筑缺陷、监控野生动物、跟踪非法活动等。
-
总结
图片中列举的应用场景展示了计算机视觉技术从基本的二维图像处理扩展到三维建模、场景理解以及更专业的行业应用(工业仿真、GIS、医疗诊断、遥感分析等)。各类技术(如3D重建、OCR、目标检测、图像分割、深度学习)与垂直领域知识相结合,为自动化决策支持、产业升级和社会治理提供了新的可能。这些场景的不断拓展与深化,体现出计算机视觉已经从实验室研究快速走向实用化和产业化,为我们构建一个更加高效、安全、智能的世界。
4.计算机视觉发展历史
在千禧年之前,计算机视觉(Computer Vision)从萌芽到初步成型经历了数十年的探索和发展。这个时期的研究多为理论与算法原型的奠基,为后续深度学习时代的崛起打下了扎实基础。在这一时期,研究者们主要集中于图像的基本特征提取、几何与光学模型的建立、以及对视觉成像过程的数学描述与分析。以下是对这一发展历程的详细说明:
1960年代:计算机视觉的萌芽

-
1963年,Larry Roberts的开创性工作: Larry Roberts在1963年发表了被视为计算机视觉领域首篇重要博士论文的研究成果。他利用数字图像处理(当时还十分初级)对简单几何体(如立方体、棱柱和简单多面体)进行边缘检测与轮廓提取,并尝试由此推断物体的三维结构。
-
意义:
-
将图像理解与三维几何推断联系起来,在最基本层面回答了“如何从二维图像中提取结构信息”的问题。
-
奠定了后续视觉几何分析的基础,启迪了今后通过边缘、线条、特征点构建三维模型的思路。
-
-
-
1966年MIT夏季项目: 麻省理工学院(MIT)于1966年发起的“夏季视觉项目”是计算机视觉成为正式研究领域的重要标志之一。该项目的初衷是在一个暑假内构建一套能够从图像中提取有用信息(如物体识别、场景理解)的系统。
-
结果与影响:
-
项目并未在短期内取得预期突破,但这是计算机视觉作为独立研究领域获得正式认可和关注的契机。
-
为后来的研究团队、实验室及国家项目指明了探索方向(如利用图像处理和模式识别理论,自动从视觉数据中获取高层语义信息)。
-
-
1970年代:理论奠基与方法探索
在这十年中,随着数字图像处理技术的进步,学者们开始深入研究如下方向:
-
基础图像处理与特征提取:
-
发展了Sobel算子、Prewitt算子等经典边缘检测方法。虽然Canny边缘检测是在1980年代提出,但70年代已经有不少针对图像基本特征(边缘、角点、线段)的提取方法奠定前期基础。
-
对二值图像的形态学处理(如腐蚀、膨胀)和区域分割的初步探索,为后续分割与识别算法打下重要基础。
-
-
立体视觉(Stereo Vision)与运动分析:
-
利用双目图像对场景进行深度估计与三维重构的早期方法出现。研究者开始意识到通过匹配两幅不同视点图像的特征,可以提取深度信息,从而获取初步的三维感知。
-
对光流(Optical Flow)的初步研究为后来的运动分析与目标跟踪奠定理论基础。
-
-
模式识别与初级语义理解:
-
将统计模式识别与图像处理相结合,通过模板匹配、简单的特征统计,实现了对数字字符、简单标志的识别。
-
这些研究虽然远未达到理解复杂场景的层次,但却揭示了视觉中“特征提取-特征匹配-识别”这条基本思路。
-
1980年代:David Marr及现代视觉理论雏形
-
David Marr的贡献(1982年): David Marr在1982年发表的著作《Vision》,成为计算机视觉发展史上的里程碑。Marr从视觉信息处理的本质出发,提出了多层次的视觉计算模型,将视觉过程分为多个阶段:
-
灰度图像(原始图像):最低层级的像素强度数据。
-
原始草图(Primal Sketch):通过边缘和零阶/一阶导数特征提取,获得基本轮廓和局部结构。
-
2.5D草图:引入深度、表面法线等局部三维信息的中间表示。
-
3D模型表示:最终形成对物体和场景的完整3D结构理解。 Marr的思想为计算机视觉提供了一个从底层像素到高层语义的系统化框架,影响深远。他强调视觉是信息处理过程,强调分层理解和数学建模,为后世众多算法和模型奠定了逻辑思路。
-
-
更加完善的边缘检测与特征提取: 1980年代的研究者提出更健壮的边缘检测方法,如Canny边缘检测(1986年)。虽然Canny属于80年代中后期的成果,但仍在千禧年前奠定了特征提取的经典标准。 此外,线段检测、角点检测算法(如Harris角点检测)也在80-90年代中期得到研究和完善。
-
基础几何与光照模型:
-
开始有学者对光照变化、阴影、表面反射特性进行建模,从而提高从图像中恢复表面形状和反射率的能力。
-
这些研究为光照不变性、颜色恒常性和材质识别等复杂主题打下了理论基础。
-
1990年代:稳健特征与多视图几何
-
多视图几何与稳健估计: 随着计算资源和图像采集设备质量提升,研究者在90年代逐渐将目光转向多视图图像融合与稳健特征匹配。RANSAC等稳健估计算法应运而生,用于在存在噪声和外点(outlier)的情况下估计单应性矩阵、基本矩阵与本质矩阵等几何关系。
-
1999年David Lowe提出SIFT特征: 虽然接近千禧年末尾才提出,但SIFT(尺度不变特征变换)的构想与实现出现在1999年,在深度学习兴起前被公认为特征提取领域的重大突破。

-
SIFT特征点在尺度、旋转、光照变化下依旧保持稳定,为图像配准、目标识别、3D重建提供了强有力的工具。这标志着传统计算机视觉在寻找稳健特征这一问题上达到了一个高峰。
-
总结
在千禧年前的几十年间,计算机视觉领域从单纯的二维图像处理与特征提取,慢慢向三维重建、光照与物理模型、层次化视觉解释以及稳健特征匹配方向演进。Larry Roberts开创性的研究为三维信息恢复打下基础,MIT的夏季项目使计算机视觉成为正式领域,David Marr的理论体系为视觉处理的分层结构提供了清晰框架,随后Canny、SIFT等算法的出现为特征检测和匹配问题提供了解决方案。
这些前期奠基性的理论与算法在2000年后被引入更强大的计算平台和深度学习框架中,推动了计算机视觉在21世纪的飞速发展。
下面将更为详尽地介绍千禧年之后,特别是从2000年初到2014年左右计算机视觉领域所经历的大事件、关键技术突破和影响深远的研究成果。在这一时期,计算机视觉从基于手工特征的传统方法迈向以深度学习为核心的新时代,并通过大规模数据集、标准化评测体系以及新型网络结构不断拓展其应用边界。
1. 大规模数据集与评测标准的建立
PASCAL VOC (2006-2012): 在计算机视觉的早期,多数研究团队使用的图像数据集往往数量有限、类别偏少、标注标准不统一,这不利于算法的客观对比和快速迭代。
-
事件概述: 从2006年至2012年,Everingham等人搭建并持续扩展了PASCAL Visual Object Classes (VOC) 数据集和挑战赛。PASCAL VOC包含20个常见物体类别(如人、车、猫、狗等),每种类别有数千至上万张不同场景下的图像,并附有精确标注(如边界框和类别标签)。
-
影响: PASCAL VOC为物体检测、分类等经典任务奠定了统一的评测基准,使研究者可以在同一平台上客观比较不同算法的优劣。通过年度挑战赛的形式,PASCAL VOC不断引导研究热点和方向,促使算法在数据集上的性能不断提升。在此期间,基于传统特征和模型的方法不断改进,涌现出一批优秀算法,为后来的深度学习方法提供了对照基线。
ImageNet(2009年发布): 在PASCAL VOC的基础上,研究人员意识到数据和类别规模对算法泛化能力和鲁棒性有关键影响。
-

 事件概述: 2009年,李飞飞教授及其团队在CVPR上发布了ImageNet数据集及相关论文《ImageNet: A Large-Scale Hierarchical Image Database》。ImageNet包含超过1000个类别、超过100万张带有严谨标注的真实世界图像,涵盖自然界中的广泛事物。
事件概述: 2009年,李飞飞教授及其团队在CVPR上发布了ImageNet数据集及相关论文《ImageNet: A Large-Scale Hierarchical Image Database》。ImageNet包含超过1000个类别、超过100万张带有严谨标注的真实世界图像,涵盖自然界中的广泛事物。 -
影响: ImageNet的推出是计算机视觉数据规模质的飞跃。如此宏大的数据集让算法的训练和测试在更接近真实世界的条件下进行,也为后来深度神经网络学习到更具通用性和抽象性的特征创造了条件。基于ImageNet的ImageNet Large Scale Visual Recognition Challenge (ILSVRC)成为国际公认的权威比赛,为评测图像分类和物体检测算法性能提供了标准。
2. 传统特征工程时代的巅峰
特征描述子与HOG、SIFT为代表的手工特征: 在深度学习普及之前,计算机视觉主流方法依赖于手工设计的特征,例如SIFT(1999年提出,但在21世纪初被广泛应用)和HOG(Histogram of Oriented Gradients)。
-
意义: SIFT特征不变性(对尺度、旋转、光照变化具有鲁棒性)使得研究者可以更稳定地在不同图像中找到相同对象对应的关键点。HOG特征则擅长捕捉局部梯度分布特性,被广泛用于人检测等任务。 这些手工特征的出现提升了传统视觉算法的性能,为后来的对象识别、检测和检索奠定了坚实的基础。
Deformable Parts Model (DPM)(2009年): Felzenszwalb教授等人提出的DPM模型是整合了HOG特征与可变形部件模型的创新之作。
-
事件概述: DPM通过将目标对象分解为多个具有弹性关系的部件并独立建模,最终在推理阶段组合各部件的得分和位置约束来识别完整物体。这是手工特征时代解决复杂对象检测问题的一个高峰。
-
影响: 在深度学习崛起前,DPM在PASCAL VOC挑战中取得过当时最好的检测成绩,被誉为传统方法时代最为成功和成熟的物体检测与识别算法之一。DPM的成功体现了精心设计的特征与模型在当时的局限条件下所能达到的顶点,也凸显了复杂场景理解对于精巧建模的需求。
3. 数据驱动方法的觉醒:ImageNet的影响
尽管DPM等传统方法已有不俗表现,但随着数据规模的扩张和任务复杂性的提高,人们开始认识到手工特征的局限性。ImageNet的宏大规模让许多传统方法难以再有突破性的进展,这刺激了研究者们重新审视特征提取和模型训练流程。
-
变化趋势: 随着计算能力(GPU算力)的提升和海量标注数据的获取,数据驱动的方法呼之欲出。研究者们开始尝试更深、更复杂的模型结构,以摆脱对人为手工特征的依赖。
4. 深度学习的显世之光:AlexNet革命(2012年)
AlexNet的横空出世: 2012年,Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在ILSVRC挑战赛中使用深度卷积神经网络(CNN)训练的AlexNet模型大幅降低了分类错误率(从传统方法的26%左右降低到16%左右)。
-
事件概述: AlexNet采用了多层卷积、池化和全连接结构,并通过GPU加速训练。这是深度学习技术在计算机视觉上的首次大规模成功应用。
-
影响: AlexNet成功后,学术界和工业界迅速转向深度学习方向,催生了后续的VGGNet、GoogLeNet、ResNet等一系列更优秀的CNN模型。深度卷积神经网络取代手工特征描述子,成为图像分类、检测、分割的主力军。 此后的数年间,ILSVRC的错误率不断下降,深度学习主导的研究范式在图像识别领域全面碾压传统方法。
5. 从识别到生成:GAN的提出(2014年)
GAN(Generative Adversarial Networks): 2014年,Ian Goodfellow等人提出了生成对抗网络(GAN),引入了两个对立博弈的神经网络(生成器和判别器)。
-
事件概述: 生成器尝试产出以假乱真的图像,而判别器试图分辨这些图像是真是伪。二者相互促进,不断提升生成质量。GAN为图像生成、图像修复、风格迁移、域适应等方向提供了强大工具。
-
影响: GAN的出现不仅是对视觉理解任务的补充,更为视觉创造、艺术生成与创新应用打开大门。随后不断涌现的CycleGAN、Pix2Pix、StyleGAN、BigGAN等方法,使得机器可以合成高质量、逼真的图像,甚至在视频合成(Video-to-Video synthesis)和三维场景生成上取得进展,为计算机视觉从“分析理解”扩展到“创造合成”提供了坚实支撑。
6. 后续拓展与加速(2018-2019)
视频到视频生成(2018年英伟达研究): 通过对GAN进行时空拓展,学者实现了高分辨率、照片级真实感并具备时间一致性的视频合成,赋予AI更强的时空理解与生成能力。
BigGAN(2019年): 在此基础上,更强大的训练策略与更大的模型参数使BigGAN生成的图像近乎真实无从分辨,标志着GAN模型的强大潜力和研究不断深入。
总结
从千禧年之初到2014年期间,计算机视觉领域的核心主线是从小数据、手工特征的传统方法向大数据深度学习范式转变,并在随后几年中逐渐成熟和普及。
-
2000-2010年代早期:数据集(PASCAL VOC)的出现和SIFT、HOG、DPM等算法将传统视觉技术推至极限。
-
2009-2012年:ImageNet数据集的发布与AlexNet的成功标志着深度学习时代来临,CNN在图像识别任务中大放异彩。
-
2014年之后:GAN的提出让视觉技术从识别拓展到生成领域,促使计算机视觉在合成、编辑和变换任务中持续创新。
这一系列重大事件共同塑造了计算机视觉在21世纪初期至中期的发展路径,为后来的无人驾驶、医疗影像分析、安防监控、虚拟/增强现实、智能制造、内容创意生产等领域大规模应用奠定坚实基础。
相关文章:
【计算机视觉基础CV-图像分类】01- 从历史源头到深度时代:一文读懂计算机视觉的进化脉络、核心任务与产业蓝图
1.计算机视觉定义 计算机视觉(Computer Vision)是一个多学科交叉的研究领域,它的核心目标是使计算机能够像人类一样“看”并“理解”视觉信息。换句话说,它希望赋予计算机从图像、视频中自动提取、有意义地分析、理解并解释视觉场…...

C# cad启动自动加载启动插件、类库编译 多个dll合并为一个
可以通过引用costura.fody的包,编译后直接变为一个dll 自动加载写入注册表、激活码功能: 【CAD二次开发教程-实例18-启动加载与自动运行-哔哩哔哩】 https://b23.tv/lKnki3f https://gitee.com/zhuhao1912/cad-atuo-register-and-active...

Mybatis增删改查(配置文件版)
准备环境 1、数据库表tb_brand 2、实体类Brand 3、测试用例 3、1在test包中的java包中创建测试类com.xyy.test.MybatisTest.java 4、安装MyBatisX插件 添加插件后,因为在Mapper代理开发时,Mapper接口要和Mapper.xml映射文件放在同一个报下࿰…...

【Spring Security系列】5 次密码错误触发账号锁定?Spring Security 高效实现方案详解
作者:后端小肥肠 🍇 我写过的文章中的相关代码放到了gitee,地址:xfc-fdw-cloud: 公共解决方案 🍊 有疑问可私信或评论区联系我。 🥑 创作不易未经允许严禁转载。 姊妹篇: 【Spring Security系列…...

笔记day5
文章目录 1 复习2 最完美的解决方案,解决轮播图问题3 开发Floor组件4 把首页中的轮播图拆分为一个共用全局组件5 search模块开发 1 复习 完成商品分类三级列表路由跳转一级路由传参(合并参数)完成search模块中对于typeNav的使用(…...

Linux快速入门-兼期末快速复习使用
Linux快速入门-兼期末快速复习使用 一小时快速入门linux快速一:Linux操作系统概述1. Linux概述1.1 定义与特点1.2 起源与发展1.3 Linux结构1.4 版本类别1.5 应用和发展方向 2. 安装与启动2.1 Windows下VMware安装Linux2.2 安装Ubuntu 快速二:linux的桌面…...

浅谈文生图Stable Diffusion(SD)相关模型基础
1.U-Net模型基础 1.基础概念 UNet模型是一种基于卷积神经网络的图像分割算法,它采用了U型的网络结构,由编码器(下采样路径)和解码器(上采样路径)两部分组成。 编码器负责提取输入图像的特征,…...
Vivado使用VScode编译器
旧版Vivado使用Vscode编译器偶尔会出现VScode界面卡死的情况,在新版的Vivado中(我的是Vivado 2023.2),可以使用如下方式: 在设置中选择Text Editor,选择Custom Editor 在对话框中输入以下语句:…...

CEF127 编译指南 MacOS 篇 - 拉取 CEF 源码(五)
1. 引言 在完成了所有必要工具的安装和配置后,我们进入到获取 CEF 源码的阶段。对于 macOS 平台,CEF 的源码获取过程需要特别注意不同芯片架构(Intel 和 Apple Silicon)的区别以及版本管理。本文将详细介绍如何在 macOS 系统上获…...

Jenkins 中 写 shell 命令执行失败,检测失败问题
由于项目的 依赖复杂,随着版本的增多,人工操作,手误几率太大,我们选取kenins 来自动化发布、更新。 这里主要解决,发布 的 每个阶段,确保每个阶段执行成功。 比如: js 运行,…...
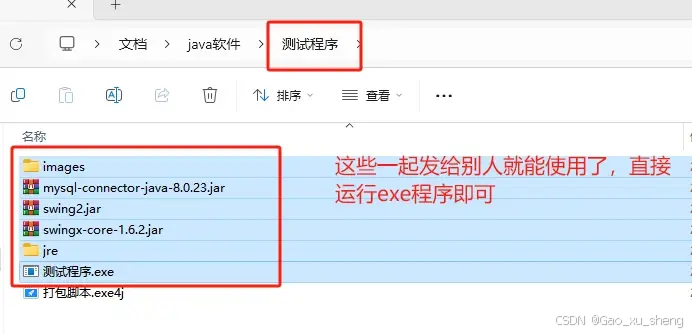
Java程序打包成exe,无Java环境也能运行
Java程序开发完成后,通常情况下以jar包的形式发布。但有时我们需要给非软件开发人员使用程序,如制作好窗体应用,把它发给没有java开发环境的人使用,此时就需要制作exe安装包。本文介绍如何将java程序制作成exe安装包,并…...

【java 正则表达式 笔记】
文章目录 快速入门匹配中文或数字或大小写字母(一个或多个) 正则表达式底层实现(重要)mather.find() 完成的任务mather.group(0) 分析 正则表达式基本语法元字符转义字符区分大小写限定字符选择匹配符特殊字符字符匹配符定位符 分组、捕获和反向引用捕获特别分组反向引用经典结…...

基于PWLCM混沌映射的麋鹿群优化算法(Elk herd optimizer,EHO)的多无人机协同路径规划,MATLAB代码
一、麋鹿群优化算法EHO 基本概念 麋鹿群优化算法(EHO,Elephant Herding Optimization)是2024年提出的一种启发式优化算法,它的灵感来自麋鹿群的繁殖过程。麋鹿有两个主要的繁殖季节:发情和产犊。在发情季节࿰…...

Vue2五、自定义指令,全局局部注册、指令的值 ,插槽--默认插槽,具名插槽 ( 作用域插槽)
一、自定义指令 使用步骤 1. 注册 (全局注册 或 局部注册) ,在 inserted 钩子函数中,配置指令dom逻辑 2. 标签上 v-指令名 使用 1、自定义指令(全局) Vue.directive("指令名",{ 指令的配置项 insert…...

Pika Labs技术浅析(五):商业智能技术
Pika Labs 的商业智能旨在通过联机分析处理(OLAP)和数据仓库(Data Warehouse)等技术,帮助企业用户高效地进行数据分析和决策支持。 一、商业智能技术模块概述 Pika Labs 的商业智能技术模块旨在通过集成数据仓库和联机…...

YOLO-World:Real-Time Open-Vocabulary Object Detection
目录 摘要 Abstract YOLO-World 1 模型架构 1.1 Text Encoder 1.2 YOLO Backbone 2 RepVL-PAN 2.1 T-CSPLayer 2.2 I-Pooling Attention 2.3 预测 3 消融实验 3.1 预训练数据 3.2 RepVL-PAN的消融实验 3.3 文本编码器 4 效果展示 4.1 零样本 4.2 根据词汇表检…...

Fastjson <= 1.2.47 反序列化漏洞复现
0x01 前言 Fastjson 是一个 Java 语言编写的高性能功能完善的 JSON 库,可以将 Java 对象转换为 JSON 格式,也可以将 JSON 字符串转换为 Java 对象,在中国和美国使用较为广泛。 0x02 漏洞成因 Fastjson < 1.2.68 版本在处理反序列化对象时…...

鸿蒙项目云捐助第二十一讲云捐助项目物联网IoT模拟器的使用
鸿蒙项目云捐助第二十一讲云捐助项目物联网IoT模拟器的使用 在前面的内容中,已经实现了云捐助物联网IoT的产品及设备设置,并且使用华为云Iot设备的在线调试工具进行命令下发的调试,这里也可以通过华为Iot物联网提供的MQTT模拟器进行连接。 …...

大数据技术原理与应用期末复习-知识点(二)
HBASE Hbase与传统关系数据库的对比分析 1.数据类型: 关系型数据库采用关系模型 Hbase采用更简单的数据模型(把数据存储为未经解释的字符串) 2.数据操作: 关系数据库:增删改查等 Hbase:插入 查询 删…...

高效准确的PDF解析工具,赋能企业非结构化数据治理
目录 准确性高:还原复杂版面元素 使用便捷:灵活适配场景 贴心服务:快速响应机制 在数据为王的时代浪潮中,企业数据治理已成为组织优化运营、提高竞争力的关键。随着数字化进程的加速,企业所积累的数据量呈爆炸式增长…...

五分钟搞定Python调用ChatGPT,使用Taotoken实现OpenAI兼容接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 五分钟搞定Python调用ChatGPT,使用Taotoken实现OpenAI兼容接入 对于刚接触大模型API的Python开发者来说,最…...

别再截图了!用AD21把PCB 3D模型直接塞进PDF,客户评审一目了然
用AD21将PCB 3D模型嵌入PDF:提升设计评审效率的终极方案 在硬件开发流程中,设计评审环节往往成为项目推进的瓶颈。传统方式下,工程师不得不反复截取多角度2D图纸,或录制繁琐的演示视频,既耗费时间又难以全面展示设计细…...

从Pikachu靶场看CSRF Token防护:为什么你的Token机制可能被绕过?聊聊设计缺陷与加固思路
从Pikachu靶场看CSRF Token防护:为什么你的Token机制可能被绕过?聊聊设计缺陷与加固思路 在Web安全领域,CSRF(跨站请求伪造)攻击一直是开发者需要重点防范的威胁之一。而CSRF Token作为最常用的防护手段,其…...

2026 在线水印去除工具怎么选?6款实用方法对比测评
在短视频时代,去水印需求越来越普遍。无论是想要收藏喜欢的视频素材、整理图片库存,还是创作内容时需要的参考素材,高效的在线水印去除方法已经成为必需品。本文盘点了6款在线水印去除工具和方法,从处理速度、平台覆盖、易用性等维…...

OpCore Simplify:30分钟完成专业Hackintosh配置的智能自动化工具终极指南
OpCore Simplify:30分钟完成专业Hackintosh配置的智能自动化工具终极指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 你是否曾经因为复…...

ChatGPTAPIFree代码架构深度剖析:从Express到OpenAI API的完整链路
ChatGPTAPIFree代码架构深度剖析:从Express到OpenAI API的完整链路 ChatGPTAPIFree是一个开源的代理API项目,让用户能够免费访问OpenAI的ChatGPT API服务。本文将深入剖析其代码架构,从Express服务器搭建到OpenAI API请求处理的完整链路&…...

如何掌握Il2CppDumper:Unity逆向工程实战指南与深度解析
如何掌握Il2CppDumper:Unity逆向工程实战指南与深度解析 【免费下载链接】Il2CppDumper Unity il2cpp reverse engineer 项目地址: https://gitcode.com/gh_mirrors/il/Il2CppDumper 你是否曾面对Unity游戏的il2cpp二进制文件感到无从下手?是否在…...

3个步骤,在VSCode中实现Mermaid图表实时预览的终极工作流
3个步骤,在VSCode中实现Mermaid图表实时预览的终极工作流 【免费下载链接】vscode-mermaid-preview Previews Mermaid diagrams 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-mermaid-preview 你是否曾在编写技术文档时,为了一个简单的流…...

重塑知识连接:探索Obsidian模板驱动的Zettelkasten思维系统
重塑知识连接:探索Obsidian模板驱动的Zettelkasten思维系统 【免费下载链接】Obsidian-Templates A repository containing templates and scripts for #Obsidian to support the #Zettelkasten method for note-taking. 项目地址: https://gitcode.com/gh_mirror…...

自动驾驶汽车三维路径规划与路径跟踪控制方法【附代码】
✨ 长期致力于自动驾驶汽车、三维路径规划、路径跟踪控制、深度强化学习、预瞄跟随、模糊推理、神经网络模型预测控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 ࿰…...