详解磁盘IO、网络IO、零拷贝IO、BIO、NIO、AIO、IO多路复用(select、poll、epoll)
1、什么是I/O
在计算机操作系统中,所谓的I/O就是输入(Input)和输出(Output),也可以理解为读(Read)和写(Write),针对不同的对象,I/O模式可以划分为磁盘IO模型和网络IO模型。
IO操作会涉及到用户空间和内核空间的转换,先来理解以下规则:
内存空间分为用户空间和内核空间,也称为用户缓冲区和内核缓冲区
用户的应用程序不能直接操作内核空间,需要将数据从内核空间拷贝到用户空间才能使用
无论是read操作,还是write操作,都只能在内核空间里执行
磁盘IO和网络IO请求加载到内存的数据都是先放在内核空间的
再来看看所谓的读(Read)和写(Write)操作:
读操作:操作系统检查内核缓冲区有没有需要的数据,如果内核缓冲区已经有需要的数据了,那么就直接把内核空间的数据copy到用户空间,供用户的应用程序使用。如果内核缓冲区没有需要的数据,对于磁盘IO,直接从磁盘中读取到内核缓冲区(这个过程可以不需要cpu参与)。而对于网络IO,应用程序需要等待客户端发送数据,如果客户端还没有发送数据,对应的应用程序将会被阻塞,直到客户端发送了数据,该应用程序才会被唤醒,从Socket协议找中读取客户端发送的数据到内核空间,然后把内核空间的数据copy到用户空间,供应用程序使用。
写操作:用户的应用程序将数据从用户空间copy到内核空间的缓冲区中,这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘或通过网络发送出去,由操作系统决定。除非应用程序显示地调用了sync命令,立即把数据写入磁盘,或执行flush()方法,通过网络把数据发送出去。
绝大多数磁盘IO和网络IO的读写操作都是上述过程,除了后面要讲到的零拷贝IO。
2、 网络IO
网络IO的流程如下

2.1、读操作
网络IO的既可以从物理磁盘中读数据,也可以从socket中读数据(从网卡中获取)。当从物理磁盘中读数据的时候,其流程和磁盘IO的读操作一样。当从socket中读数据,应用程序需要等待客户端发送数据,如果客户端还没有发送数据,对应的应用程序将会被阻塞,直到客户端发送了数据,该应用程序才会被唤醒,从Socket协议找中读取客户端发送的数据到内核空间(这个过程也由DMA控制),然后把内核空间的数据copy到用户空间,供应用程序使用。
2.2、写操作
为了简化描述,我们假设网络IO的数据从磁盘中获取,读写操作的流程如下:
当应用程序调用read()方法时,通过DMA方式将数据从磁盘拷贝到内核缓冲区,由cpu控制,将内核缓冲区的数据拷贝到用户空间的缓冲区中,供应用程序使用
当应用程序调用write()方法时,cpu会把用户缓冲区中的数据copy到内核缓冲区的Socket Buffer中
最后通过DMA方式将内核空间中的Socket Buffer拷贝到Socket协议栈(即网卡设备)中传输。
网络IO的写操作也有四次缓冲区的copy,第一次是从磁盘缓冲区到内核缓冲区(由cpu控制),第二次是内核缓冲区到用户缓冲区(DMA控制),第三次是用户缓冲区到内核缓冲区的Socket Buffer(由cpu控制),第四次是从内核缓冲区的Socket Buffer到网卡设备(由DMA控制)。四次缓冲区的copy工作两次由cpu控制,两次由DMA控制。
2.3、 网络IO的延时
网络IO主要延时是由:服务器响应延时+带宽限制+网络延时+跳转路由延时+本地接收延时 决定。一般为几十到几千毫秒,受环境影响较大。所以,一般来说,网络IO延时要大于磁盘IO延时。
2.4. IO中断与DMA
以前传统的IO读写是通过中断由cpu控制的,为了减少CPU对I/O的干预,引入了直接存储器访问方式(DMA)方式。在DMA方式下,数据的传送是在DMA的控制下完成的,不需要cpu干预,所以CPU和I/O设备可以并行工作,提高了效率。现在来看看它们各自的原理:
IO中断原理

用户进程通过read等系统调用接口向操作系统(即CPU)发出IO请求,请求读取数据到自己的用户内存缓冲区中,然后该进程进入阻塞状态。
操作系统收到用户进程的请求后,进一步将IO请求发送给DMA,然后CPU就可以去干别的事了。
DMA将IO请求转发给磁盘。
磁盘驱动器收到内核的IO请求后,把数据读取到自己的缓冲区中,当磁盘的缓冲区被读满后,向DMA发起中断信号告知自己缓冲区已满。
DMA收到磁盘驱动器的信号,将磁盘缓存中的数据copy到内核缓冲区中,此时不占用CPU(IO中断这里是占用CPU的)。
如果内核缓冲区的数据少于用户申请读的数据,则重复步骤3、4、5,直到内核缓冲区的数据符合用户的要求为止。
内核缓冲区的数据已经符合用户的要求,DMA停止向磁盘IO请求。
DMA发送中断信号给CPU。
CPU收到DMA的信号,知道数据已经准备好,于是将数据从内核空间copy到用户空间,系统调用返回。
用户进程读取到数据后继续执行原来的任务。
跟IO中断模式相比,DMA模式下,DMA就是CPU的一个代理,它负责了一部分的拷贝工作,从而减轻了CPU的负担。
需要注意的是,DMA承担的工作是从磁盘的缓冲区到内核缓冲区或网卡设备到内核的soket buffer的拷贝工作,以及内核缓冲区到磁盘缓冲区或内核的soket buffer到网卡设备的拷贝工作,而内核缓冲区到用户缓冲区之间的拷贝工作仍然由CPU负责。
2.5、零拷贝IO
在上述IO中,读写操作要经过四次缓冲区的拷贝,并经历了四次内核态和用户态的切换。 零拷贝(zero copy)IO技术减少不必要的内核缓冲区跟用户缓冲区之间的拷贝,从而减少CPU的开销和状态切换带来的开销,达到性能的提升。
在zero copy下,如果从磁盘中读取文件然后通过网络发送出去,只需要拷贝三次,只发生两次内核态和用户态的切换。
下图是不使用zero copy的网络IO传输过程:

零拷贝的传输过程:硬盘 >> kernel buffer (快速拷贝到kernel socket buffer) >>Socket协议栈(网卡设备中)
当应用程序调用read()方法时,通过DMA方式将数据从磁盘拷贝到内核缓冲区
由cpu控制,将内核缓冲区的数据直接拷贝到另外一个与 socket相关的内核缓冲区,即kernel socket buffer,然后由DMA 把数据从kernel socket buffer直接拷贝给Socket协议栈(网卡设备中)。
这里,只经历了三次缓冲区的拷贝,第一次是从磁盘缓冲区到内核缓冲区,第二次是从内核缓冲区到kernel socket buffer,第三次是从kernel socket buffe到Socket协议栈(网卡设备中)。只发生两次内核态和用户态的切换,第一次是当应用程序调用read()方法时,用户态切换到内核到执行read系统调用,第二次是将数据从网络中发送出去后系统调用返回,从内核态切换到用户态。
零拷贝(zero copy)的应用:
Linux下提供了zero copy的接口:sendfile和splice,用户可通过这两个接口实现零拷贝传输
Nginx可以通过sendfile配置开启零拷贝
在linux系统中,Java NIO中FileChannel.transferTo的实现依赖于 sendfile()调用。
Apache使用了sendfile64()来传送文件,sendfile64()是sendfile()的扩展实现
kafka也用到了零拷贝的功能,具体我没有深究
注意:零拷贝要求输入的fd必须是文件句柄,不能是socket,输出的fd必须是socket,也就是说,数据的来源必须是从本地的磁盘,而不能是从网络中,如果数据来源于socket,就不能使用零拷贝功能了。我们看一下sendfile接口就知道了:
#include <sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count)out_fd:待写入文件描述符in_fd: 待读出文件描述符offset:从读入文件流的哪个位置开始读,如果为空,则默认从起始位置开始count:指定在文件描述符in_fd 和out_fd之间传输的字节数返回值:成功时,返回出传输的字节数,失败返回-1in_fd必须指向真实的文件,不能是socket和管道;而out_fd则必须是一个socket。由此可见,sendfile几乎是专门为在网络上传输文件而设计的。
在Linxu系统中,一切皆文件,因此socket也是一个文件,也有文件句柄(或文件描述符)。
3、 BIO
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;public class Server {public static void main(String[] args) throws IOException {ServerSocket serverSocket = new ServerSocket();serverSocket.bind(new InetSocketAddress(9999)); // 绑定端口号9999while (true) {Socket client = serverSocket.accept(); // 阻塞等待客户端连接new Thread(new Accept(client)).start(); // 为每个客户端连接创建一个新线程处理请求}}
}class Accept implements Runnable {private Socket client = null;public Accept(Socket client) {this.client = client;}@Overridepublic void run() {try (InputStream inputStream = client.getInputStream();BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream))) {String dataLine;while ((dataLine = reader.readLine()) != null) {System.out.println(dataLine); // 处理接收到的数据}} catch (IOException e) {e.printStackTrace();} finally {try {client.close(); // 关闭客户端连接} catch (IOException e) {e.printStackTrace();}}}
}
现在,我们就来讲解BIO、NIO、IO多路复用、AIO,在这之前,我必须强调,这些IO大多用于网络IO,并且这里主要介绍用户程序从网络中获取数据那一部分。一方面是为了方便描述,另一方式,更能体现出这些IO的区别。
网络IO从Socket获取数据的步骤:
1)用户进程执行系统调用转入内核态
2)操作系统等待远处客户端发送数据(前提是客户端和服务器通过TCP三次握手成功),客户端发送数据后,操作系统通过从网卡设备获取数据,并把数据从Socket协议栈拷贝到内核缓冲区
3)把内核缓冲区的数据拷贝到用户缓冲区
4)用户进程获取到数据,继续执行
BIO、NIO、AIO的主要区别在于:
步骤1里用户进程执行系统调用后的状态如何,是阻塞(或挂起),还是非阻塞。
步骤3里把内核缓冲区的数据拷贝到用户缓冲区,在拷贝过程中,用户进程的状态又如何,是阻塞,还是非阻塞。
如果用户进程在步骤1执行后的状态是阻塞的,且步骤3过程中,进程也是阻塞的,那么是BIO(同步阻塞IO)。
如果用户进程在步骤1执行后的状态是非阻塞的,且步骤3过程中,进程是阻塞的,那么是NIO(同步非阻塞IO)。
如果用户进程在步骤1执行后的状态是非阻塞的,且步骤3过程中,进程也是非阻塞的,也就是说真正读(或写)时,进程的状态是非阻塞的,那么是AIO(异步IO)。
至于多路复用IO和BIO、NIO、AIO的区别,后面会细细讲解。那么,我们就开始吧!
BIO (Blocking I/O),称之为同步阻塞I/O,其IO模型传输如下图所示:

上图红色表示进程处理阻塞状态,绿色表示进程处于非阻塞状态
我相信BIO模型的传输过程上图已经描述很清楚了,可以看到,BIO模型的用户进程在执行系统调用后,一直处于阻塞状态,等待内核数据到位后,进程继续阻塞,直到内核数据拷贝到用户空间。
该模式下,一个线程只能处理一个Socket IO连接,高并发时,服务端会启用大量的线程来处理多个Socket,由于是阻塞IO,会导致大量线程处于阻塞状态,导致cpu资源浪费,且大量线程会导致大量的上下文切换,造成过多的开销。
当前绝大操作系统都支持多线程,当操作系统引入多线程之后,进程的执行实际就是进程中的多个线程在执行,同一时刻,cpu只能执行一个线程,多个线程通过轮询的方式交替执行。
这时你可能会有疑问,用户进程都被阻塞(或挂起)了,在内核态还怎么操作呢?事实上,read和write都是内核级的操作,只要用户进程调用相应的系统调用接口后,内核进程(或线程)在真正执行读和写操作硬件时,与用户进程就没什么关系了。
4. NIO
NIO (Non-blocking IO),称之为非阻塞IO,其传输过程如下:

在NIO模式下,当用户进程执行系统调用后,如果当前数据还没有准备好,则会立即返回(NIO的非阻塞就提现在这里),然后再次进行系统调用,不断测试数据是否准备好。如果数据准备好了,当前进程会进入阻塞转态,直到数据从内核空间拷贝到用户空间,进程才会被唤醒,就可以处理数据了。
NIO模式下,一个线程就可以处理多个Socket连接,没必要开启多线程进行处理(如果多个NIO,会有多个线程一起执行多次系统调用,结果会很可怕)。但是,当有1000个Socket连接时,用户进程会以轮询的方式执行1000次系统调用判断数据有没有准备好,即会发生1000次用户态到内核态的切换,成本几何上升。即使当前只有一个Socket连接,也会重复进行系统调用,因为此时的用户进程不仅要接收新的Socket连接并把它拷贝到内核,还要判断已有的Socket连接是否准备好数据,这都会有系统调用,极大的浪费cpu资源。
5、 IO多路复用
IO多路复用的传输过程如下:

import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;public class NIOServer {public static void main(String[] args) throws IOException {// 打开SelectorSelector selector = Selector.open();// 打开ServerSocketChannelServerSocketChannel serverSocket = ServerSocketChannel.open();serverSocket.configureBlocking(false);serverSocket.socket().bind(new InetSocketAddress(8000));// 注册ServerSocketChannel到SelectorserverSocket.register(selector, SelectionKey.OP_ACCEPT);// 轮询就绪的通道while (true) {// 非阻塞地选择就绪的通道selector.select();// 获取就绪的SelectionKey集合Set<SelectionKey> selectedKeys = selector.selectedKeys();Iterator<SelectionKey> it = selectedKeys.iterator();// 迭代就绪的通道while (it.hasNext()) {SelectionKey key = it.next();it.remove();// 处理就绪的通道if (key.isAcceptable()) {ServerSocketChannel ssc = (ServerSocketChannel) key.channel();SocketChannel socketChannel = ssc.accept();socketChannel.configureBlocking(false);// 注册新接入的通道到SelectorsocketChannel.register(selector, SelectionKey.OP_READ);} else if (key.isReadable()) {SocketChannel socketChannel = (SocketChannel) key.channel();int count;StringBuilder buffer = new StringBuilder();// 读取数据while ((count = socketChannel.read(buffer)) > 0) {// 处理读取到的数据}}// 其他事件类型(如OP_WRITE等)可以在此处进行处理}}}
}由于NIO会多次执行系统调用进行测试,大大浪费系统的资源,而多路复用IO把轮询多个Socket文件句柄的事情放在内核空间里执行,即让内核负责轮询所有socket(这样就不会有用户态和系统态的切换),当某个或几个socket有数据到达了,返回所有就绪的Socket文件句柄给用户进程,然后用户进程执行read系统调用接口,并进入阻塞状态。内核进程(或线程)把数据从内核空间拷贝到用户空间,用户进程读取到数据就可以进行处理了。
多路复用IO在执行系统调用后,进程就处于阻塞状态,所以多路复用IO本质上也是同步阻塞IO,只不过它是在内核态轮询所有socket,大大提高了IO的处理速度,也减少了系统状态切换的开销。此外,它与同步阻塞的BIO不同,多路复用IO可以使用一个线程同时处理多个Socket的IO请求,这是BIO做不到的。而在BIO中,必须通过多线程的方式才能达到这个目的。
另外,大家可以思考一下,为什么用户进程从网络中获取数据的第一步就要执行系统调用,我举一个例子来说明。
假如一个服务端上的用户进程要读取客户端发来的数据,此时用户进程在用户态,当进程执行了accept()方法获取客户端的链接,此时就得到了客户端Socket的文件句柄(或文件描述符),但是该用户进程并不知道该Socket的文件句柄是否就绪(即是否可读),这就要执行系统调用进入内核态,并把当前网络连接的Socket文件句柄(或文件描述符)复制到内核态。为什么要进入内核态呢?因为数据是从Socket协议栈(或网卡设备)发过来的,要操作硬件设备才能读取数据,所以必须在内核态下判断客户端的Socket是否发来消息。进入内核态以后,内核进程会判断该Socket是否可读(即是否准备好数据),如果准备好了数据,就把数据从Socket协议栈(或网卡设备)拷贝到内核缓冲区,再把内核缓冲区的数据拷贝到用户缓冲区。所以只要有一个客户端的Socket连接到来,就会进入一次系统调用判断Socket的文件句柄是否就绪。这里可能不好理解,但对下面多路复用模式的理解很有用处。
多路复用模式包含三种,即select、poll和epoll,这几种模式主要区别在于获取可读Socket文件句柄的方式。
6、 select
select方法本质其实就是维护了一个文件描述符(fd)数组,以此为基础,实现IO多路复用的功能。这个fd数组有长度限制,在32位系统中,最大值为1024个,而在64位系统中,最
大值为2048个,这个配置可以调用。
select方法被调用,首先需要将fd_set从用户空间拷贝到内核空间,然后内核用poll机制(此poll机制非IO多路复用的那个poll方法)直到有一个fd活跃,或者超时了,方法返回。
fd_set在用户空间和内核空间的频繁复制,效率低。单个进程可监控的fd数量有限制,无论是1024还是2048,对于很多情景来说都是不够用的。基于轮询来实现,效率低。
7 poll
poll本质上和select没有区别,依然需要进行数据结构的复制,依然是基于轮询来实现,但区别就是,select使用的是fd数组,而poll则是维护了一个链表,所以从理论上,poll方法中,单个进程能监听的fd不再有数量限制。但是轮询,复制等select存在的问题,poll依然存在。
8 epoll
epoll就是对select和poll的改进了。它的核心思想是基于事件驱动来实现的,实现起来也并不难,就是给每个fd注册一个回调函数,当fd对应的设备发生IO事件时,就会调用这个回调函数,将该fd放到一个链表中,然后由客户端从该链表中取出一个个fd,以此达到O(1)的时间复度。
poll操作实际上对应着有三个函数:epoll_create,epoll_ctr,epoll_wait
epoll_create
相当于在内核中创建一个存放fd的数据结构。在select和poll方法中,内核都没有为fd准备存放其的数据结构,只是简单粗暴地把数组或者链表复制进来;而epoll则不一样,epoll_create会在内核建立一颗专门用来存放fd结点的红黑树,后续如果有新增的fd结点,都会注册到这个epoll红黑树上。
epoll_ctr
另一点不一样的是,select和poll会一次性将监听的所有fd都复制到内核中,而epoll不一样,当需要添加一个新的fd时,会调用epoll_ctr,给这个fd注册一个回调函数,然后将该fd结点注册到内核中的红黑树中。当该fd对应的设备活跃时,会调用该fd上的回调函数,将该结点存放在一个就绪链表中。这也解决了在内核空间和用户空间之间进行来回复制的问题。
epoll_wait
epoll_wait的做法也很简单,其实直接就是从就绪链表中取结点,这也解决了轮询的问题,时间复杂度变成O(1)所以综合来说,epoll的优点有:
没有最大并发连接的限制,远远比1024或者2048要大。(江湖传言1G的内存上能监听10W个端口)。
效率变高。epoll是基于事件驱动实现的,不会随着fd数量上升而效率下降。
减少内存拷贝的次数。

9. AIO
AIO ( Asynchronous I/O):异步非阻塞I/O模型。传输过程如下:

可以看到,异步非阻塞I/O在判断数据有没有准备好(即Socket是否就绪)和真正读数据两个阶段都是非阻塞的。AIO在第一次执行系统调用后,会注册一个回调函数,内核在检测到某Socket文件句柄就绪,调用该回调函数执行真正的读操作,将数据从内核空间拷贝到用户空间,然后返回给用户使用。在整个过程,用户进程都是非阻塞状态,可以做其它的事情。没有Linux系统采用AIO模型,只有windows的IOCP是此模型。
10、 总结
IO可以分为两个阶段,第一阶段,判断有没有事件发生(或判断数据有没有准备好,或判断Socket是否就绪),第二阶段,在数据准备好以后,执行真正的读(或写)操作,将数据从内核空间拷贝到用户空间。
这几个阶段:
同步阻塞IO(BIO):两个阶段的用户进程都阻塞。
同步非阻塞IO(NIO):第一阶段没有阻塞,但是用户进程(或线程)必须不断的轮询,判断有没有Socket就绪,这时cpu疯狂被占用。第二阶段,数据拷贝的过程是阻塞的。所以,所有的同步过程,在第二阶段都是阻塞的,尽管这是非阻塞的调用。
多路复用:NIO的第一阶段没有阻塞,但是由用户线程不断轮询多个Socket有没有就绪。而多路复用把这件事情交给一个内核线程去处理,速度非常快。select和poll机制下,第一阶段是也是阻塞的,而epoll机制,用户线程除了要执行epoll_create,还要执行epoll_ctl和epoll_wait,所以是非阻塞的。在第二阶段,所有的多路复用IO都是阻塞的。所以,多路复用IO也是同步IO。
异步IO(AIO):两个阶段都是非阻塞的。
另外,不得不提的是,上述的阻塞和非阻塞指的是IO模型,用户进程获取数据后执行业务逻辑的时候,也分异步和同步。比如,进程执行一段很复杂的业务逻辑,需要很长的时间才能返回,也可以注册一个回调函数,等待此段代码执行完毕后,就通知用户进程。例如,nginx在Linux2.6以后的内核中用的IO模型是epoll,即同步IO,而Nginx的worker进程的处理请求的时候是异步的。
业务逻辑的同步和异步概念如下:
同步:所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。
异步:异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
阻塞:阻塞调用是指调用结果返回之前,当前线程会被挂起,函数只有在得到结果之后才会返回。有人也许会把阻塞调用和同步调用等同起来,实际上它们是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是当前函数没有返回而已。
非阻塞:非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。
相关文章:
详解磁盘IO、网络IO、零拷贝IO、BIO、NIO、AIO、IO多路复用(select、poll、epoll)
1、什么是I/O 在计算机操作系统中,所谓的I/O就是输入(Input)和输出(Output),也可以理解为读(Read)和写(Write),针对不同的对象,I/O模式可以划分为…...

VPN技术-GRE隧道的配置
GRE隧道的配置 1, 在AR1上配置DHCP接口地址池,AR3上配置DHCP全局地址池 2, PC1获取的IP地址为10.10.10.253,PC2获取的IP地址为10.10.30.253 3,通过ip route-static将目的地址为10.10.30.253的流量引入到Tunnel #配…...

【spring-cloud-gateway总结】
文章目录 什么是gateway如何导入gateway依赖路由配置gateway配置断路器导包配置 什么是gateway 在微服务架构中,gateway网关是一个服务,它作为系统的唯一入口点,处理所有的客户端请求,然后将这些请求路由到适当的服务。提供了几个…...

数组相关简单算法
目录 1. 数据结构与算法 2. 数组中涉及的算法 2.1 2.2 数值型数组相关运算 2.3 数组赋值 2.4 数组复制/反转 2.5 数组查找 2.6 排序 1. 数据结构与算法 《数据结构与算法》是大学些许专业的必修或选修课,主要包含两方面知识: (1&#…...

在VBA中结合正则表达式和查找功能给文档添加交叉连接
在VBA中搜索文本有两种方式可用,一种是利用Range.Find对象(更常见的形式可能是Selection.Find,Selection是Range的子类,Selection.Find其实就是特殊的Range.Find),另一种方法是利用正则表达式,但…...
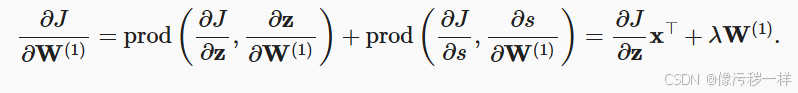
动手学深度学习-多层感知机-7前向传播、反向传播和计算图
目录 前向传播 前向传播计算图 反向传播 训练神经网络 小结 我们已经学习了如何用小批量随机梯度下降训练模型。 然而当实现该算法时,我们只考虑了通过前向传播(forward propagation)所涉及的计算。 在计算梯度时,我们只调用…...

【Python】基于Python的CI/CD工具链:实现自动化构建与发布
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 在现代软件开发中,持续集成(CI)和持续交付(CD)已经成为提高开发效率和软件质量的重要实践。CI/CD流程帮助开发团队自动化构建、测试、…...

FPGA-PS端编程1:
目标 在小梅哥的zynq 7015上,完成以下目标: 读取 S1 按键的电平, 当 S1 按键为按下状态时,驱动 PS LED 以 1S 的频率闪烁(注意理解 1S 的频率闪烁和 1S的时间翻转两种描述之间的差别), 当 S1 释放后,停止…...

自制数据库迁移工具-C版-06-HappySunshineV1.5-(支持南大Gbase8a、PostgreSQL、达梦DM)
目录 一、环境信息 二、简述 三、架构图 四、升级点 五、支持功能 六、后续计划支持功能 七、安装包下载地址 八、配置参数介绍 九、安装步骤 1、用户创建 2、安装包解压 3、环境变量配置 4、环境变量生效 5、动态库链接检验 (1)HsManage…...

了解RPC
本文来自智谱清言 --------- RPC(Remote Procedure Call,远程过程调用)是一种允许程序调用位于远程计算机上的子程序或服务的技术。这种技术使得构建分布式计算变得更加容易,因为它提供了强大的远程调用能力,同时保持…...

centos7 安装docker
文章目录 介绍docker特点安装1.前提准备2.下载1.移除旧版docker命令2.切换centos7的镜像源3.配置docker yum源4.安装最新docker5.输入命令验证docker 安装是否成功6.配置docker 镜像加速7.设置为开机自启 总结 介绍 Docker是一种开源的容器化平台,旨在简化应用…...

Docker 入门:如何使用 Docker 容器化 AI 项目(一)
引言 在人工智能(AI)项目的开发和部署过程中,环境配置和依赖管理往往是开发者遇到的挑战之一。开发者通常需要在不同的机器上运行同样的代码,确保每个人使用的环境一致,才能避免 “在我的机器上可以运行”的尴尬问题。…...

LLMs之rStar:《Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers》翻译与解读
LLMs之rStar:《Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers》翻译与解读 导读:这篇论文提出了一种名为rStar的自我博弈互推理方法,用于增强小型语言模型 (SLMs) 的推理能力,无需微调或依赖更强大的模型。rStar…...

【RK3588 Linux 5.x 内核编程】-内核中断与ThreadedIRQ
内核中断与ThreadedIRQ 文章目录 内核中断与ThreadedIRQ1、Threaded IRQ介绍2、Threaded IRQ相关API3、驱动实现4、驱动验证当 Interrupt 触发时,Interrupt handler 应该执行得非常快,它不应该运行更多的时间(它不应该执行耗时的任务)。 如果我们有执行更多任务的中断处理程…...

Message Processing With Spring Integration高级应用:自定义消息通道与端点
一、Spring Integration 简介 Spring Integration 是 Spring 框架的扩展,支持企业集成模式(EIP),提供轻量级的消息处理功能,帮助开发者构建可维护、可测试的企业集成解决方案。 核心目标: 提供简单的模型…...

S32K324 MCAL中的Postbuild和PreCompile使用
文章目录 前言Postbuild和PreCompile的概念MCAL中配置差异总结 前言 之前一直看到MCAL配置中有这个Postbuild和PreCompile的配置,但是不太清楚这两个的区别和使用方法。最近在使用中出现了相关问题,本文介绍一下MCAL中这两种配置的区别和使用。 Postbu…...

kubeadm_k8s_v1.31高可用部署教程
kubeadm_k8s_v1.31高可用部署教程 实验环境部署拓扑图**部署署架构****Load Balance****Control plane node****Worker node****资源分配(8台虚拟机)**集群列表 前置准备关闭swap开启ipv4转发更多设置 1、Verify the MAC address and product_uuid are u…...

【AI日记】24.12.22 容忍与自由 | 环境因素和个人因素
【AI论文解读】【AI知识点】【AI小项目】【AI战略思考】【AI日记】 工作 内容:看 OpenAi 这周的发布会和其他 AI 新闻,大佬视频时间:3 小时 读书 书名:富兰克林自传时间:1 小时评估:读完,总体…...

【Java基础面试题030】Java和Go的区别?
回答重点 可以从语言的设计理念、并发模型、内存管理、生态系统与应用场景来说: 1)语言设计理念: Java:Java是一种面向对象编程语言,强调继承、多态和封装等OOP特性。它运行在Java虚拟机(JVM)…...
)
学习嵩山版《Java 开发手册》:编程规约 - 常量定义(P5)
概述 《Java 开发手册》是阿里巴巴集团技术团队的集体智慧结晶和经验总结,他旨在提升开发效率和代码质量 《Java 开发手册》是一本极具价值的 Java 开发规范指南,对于提升开发者的综合素质和代码质量具有重要意义 学习《Java 开发手册》是一个提升 Jav…...

软件开发开源日报
📌 今日概览今日软件开发开源领域呈现多元化发展态势,各大科技公司持续推进AI基础设施、云原生平台和开发者工具的开源进程。字节跳动DeerFlow 2.0成为社区焦点,腾讯混元Hy3开源引发行业热议,华为openEuler发布超节点OS重大更新。…...
)
大模型时代,小白程序员如何抓住机遇?阿里高薪Offer背后的大模型学习指南(收藏版)
文章主要介绍了阿里在大模型领域的强势发展,包括高薪Offer和招聘趋势,强调了AI技能的重要性。作者建议小白和程序员学习大模型技术,并推荐了“派聪明RAG项目”作为学习资源。同时,文章还探讨了AI工具的实际应用和挑战,…...

技术赋能:BilibiliDown如何用智能解析引擎重塑视频下载工作流
技术赋能:BilibiliDown如何用智能解析引擎重塑视频下载工作流 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mi…...

LabVIEW生产者消费者模式:队列操作与多线程架构实战
1. 项目概述:从“单线程”到“流水线”的思维跃迁在LabVIEW的进阶之路上,生产者/消费者循环是一个绕不开的里程碑。很多朋友从基础的数据流编程走过来,习惯了顺序执行、平铺式的程序结构,一旦遇到需要同时处理多个任务、响应不同事…...

不止于存储:用GD32F407的片内FLASH实现一个简易的“EEPROM”数据管理系统
超越传统存储:基于GD32F407片内FLASH的智能数据管理方案 在嵌入式系统开发中,非易失性数据存储一直是个既基础又关键的环节。传统方案往往直接外挂EEPROM芯片,但这种方式不仅增加硬件成本,还占用宝贵的IO资源。而GD32F407这类高性…...

UnityPackage Extractor终极指南:快速提取Unity资源包的免费工具
UnityPackage Extractor终极指南:快速提取Unity资源包的免费工具 【免费下载链接】unitypackage_extractor Extract a .unitypackage, with or without Python 项目地址: https://gitcode.com/gh_mirrors/un/unitypackage_extractor 在Unity开发工作流中&…...

ComfyUI-Impact-Pack V8架构演进:模块化设计与智能内存管理突破
ComfyUI-Impact-Pack V8架构演进:模块化设计与智能内存管理突破 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址:…...

基于ARM核心板的T-BOX系统设计:从硬件选型到软件实现
1. 项目概述与核心价值最近几年,车联网的概念已经从实验室和展会,实实在在地走进了我们的日常生活。作为一名在嵌入式领域摸爬滚打了十几年的工程师,我亲眼见证了从简单的GPS定位模块,到如今功能高度集成的车载T-BOX(T…...
)
别再只会拖控件了!FastReport 实战:手把手教你用代码搞定复杂报表(含分组、过滤、合计)
代码驱动报表革命:FastReport高级开发实战指南 在电商后台系统中,销售报表往往需要处理动态分组、条件过滤和跨页合计等复杂需求。传统拖拽式设计工具虽然入门简单,但面对这类业务场景时常常捉襟见肘。本文将带你突破界面限制,通过…...

RISC-V系统调用拦截技术解析与优化实践
1. RISC-V系统调用拦截技术概述系统调用拦截(Syscall Interception)是操作系统层面的关键技术,它允许在用户态与内核态的交互过程中插入自定义处理逻辑。这项技术在高性能计算、安全监控、虚拟化等领域有着广泛应用。在x86架构上,…...