卷积神经网络入门指南:从原理到实践
目录
1 CNN的发展历史
2 CNN的基本原理
3 CNN核心组件
3.1 卷积操作基础
3.2 卷积层详解
3.3 高级卷积操作
3.3.1 分组卷积(Group Convolution)
3.3.2 深度可分离卷积(Depthwise Separable Convolution):
3.3 池化层
3.4 完整的简单CNN模型
4 现代CNN架构
4.1 经典架构
4.2 轻量级架构
4.3 注意力机制
5 CNN训练技巧
5.1 数据预处理与增强
5.2 优化器选择
5.3 学习率调度
5.4 正则化方法
1 CNN的发展历史
1959年,Hubel和Wiesel通过研究猫的视觉皮层,发现了视觉系统的分层处理机制。他们发现视觉皮层的神经元对特定区域的视觉刺激最为敏感,这就是"感受野"的概念,为CNN的设计提供了生物学基础。
1980年,Fukushima提出的Neocognitron是第一个基于分层结构的人工神经网络。它模仿了生物视觉系统的结构,包含了简单细胞层和复杂细胞层,这个设计直接启发了现代CNN的基本架构。
1998年是CNN发展的重要里程碑。Yann LeCun提出的LeNet-5成为了现代CNN的原型。它首次将卷积层、池化层和全连接层系统地组合在一起,用于手写数字识别,达到了商用水平的准确率。LeNet-5的成功证明了CNN在计算机视觉任务中的潜力。
2012年是深度学习爆发的转折点。Hinton团队的AlexNet在ImageNet竞赛中以显著优势胜出,将图像分类的错误率从26%降到了15%。AlexNet的成功归功于:
- 使用ReLU激活函数代替传统的sigmoid
- 引入Dropout防止过拟合
- 使用GPU加速训练
- 应用数据增强技术
2 CNN的基本原理
CNN的四个核心设计原则:
1.局部感受野
- 每个神经元只关注输入的一个局部区域
- 这模仿了生物视觉系统的工作方式
- 显著减少了网络参数量
- 使网络能够捕获局部特征
2.权重共享机制
- 同一个卷积核在整个输入特征图上共享参数
- 这使得网络具有平移不变性
- 进一步降低了参数量
- 提高了网络的泛化能力
3.空间降采样
- 通过池化操作逐层降低特征图的空间维度
- 减少计算量和内存占用
- 提供一定的位置不变性
- 扩大感受野范围
4.层次化特征学习
- 浅层学习低级特征(边缘、纹理)
- 中层学习中级特征(形状、局部模式)
- 深层学习高级特征(语义概念)
- 逐层抽象提取更有意义的特征表示
3 CNN核心组件
3.1 卷积操作基础
卷积操作是CNN的核心,让我们深入理解它的关键概念:
1. 卷积核的概念与作用
卷积核(kernel)是一个小型矩阵,用于提取图像特征。不同的卷积核可以检测不同的特征模式,如边缘、纹理等。例如:
- 3×3垂直边缘检测核: [[-1,0,1],[-1,0,1],[-1,0,1]]
- 3×3水平边缘检测核: [[-1,-1,-1],[0,0,0],[1,1,1]]
2. 步长(stride)与填充(padding)策略
- 步长: 控制卷积核在输入上滑动的距离
- 填充: 在输入周围添加额外的像素值(通常为0),以控制输出大小
- valid padding: 不添加填充
- same padding: 添加填充使输出维度与输入相同
- full padding: 允许卷积核与输入的每个可能位置进行卷积
3. 感受野计算 感受野是输出特征图上一个像素点对应输入图像上的区域大小。计算公式为:
- 对于单个卷积层: RF = K (K为卷积核大小)
- 对于多个卷积层: RF = RF_prev + (K - 1) * prod(strides_prev) 其中RF_prev是前一层的感受野,strides_prev是之前所有层的步长的乘积。
4. 特征图尺寸计算 输出特征图大小计算公式:
Output_size = [(Input_size - Kernel_size + 2 * Padding) / Stride] + 13.2 卷积层详解
先来看一个基本的卷积层实现:
import torch
import torch.nn as nnclass BasicConvLayer(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):super().__init__()self.conv = nn.Conv2d(in_channels=in_channels, # 输入通道数out_channels=out_channels, # 输出通道数kernel_size=kernel_size, # 卷积核大小stride=stride, # 步长padding=padding # 填充)self.bn = nn.BatchNorm2d(out_channels) # 批量归一化self.relu = nn.ReLU(inplace=True) # ReLU激活函数def forward(self, x):x = self.conv(x)x = self.bn(x)x = self.relu(x)return x# 使用示例
layer = BasicConvLayer(in_channels=3, out_channels=64)
dummy_input = torch.randn(1, 3, 224, 224) # batch_size=1, channels=3, height=224, width=224
output = layer(dummy_input)
print(output.shape) # torch.Size([1, 64, 224, 224])这个基本卷积层包含了现代CNN的标准组件:卷积、批量归一化和ReLU激活函数。
3.3 高级卷积操作
让我们看看几种现代卷积变体:
3.3.1 分组卷积(Group Convolution)
class GroupConv(nn.Module):def __init__(self, in_channels, out_channels, groups=4):super().__init__()self.group_conv = nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=3,padding=1,groups=groups # 关键参数:分组数)def forward(self, x):return self.group_conv(x)3.3.2 深度可分离卷积(Depthwise Separable Convolution):
class DepthwiseSeparableConv(nn.Module):def __init__(self, in_channels, out_channels):super().__init__()# 深度卷积self.depthwise = nn.Conv2d(in_channels=in_channels,out_channels=in_channels,kernel_size=3,padding=1,groups=in_channels # 每个通道单独卷积)# 逐点卷积self.pointwise = nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=1 # 1x1卷积)def forward(self, x):x = self.depthwise(x)x = self.pointwise(x)return x3.3 池化层
常见的池化操作实现:
class PoolingLayers(nn.Module):def __init__(self):super().__init__()# 最大池化self.max_pool = nn.MaxPool2d(kernel_size=2, stride=2)# 平均池化self.avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)# 全局平均池化self.global_avg_pool = nn.AdaptiveAvgPool2d((1, 1))def forward(self, x):max_pooled = self.max_pool(x)avg_pooled = self.avg_pool(x)globally_pooled = self.global_avg_pool(x)return max_pooled, avg_pooled, globally_pooled3.4 完整的简单CNN模型
工作流程:
- 输入图像(3×224×224)首先经过特征提取层
- 每个卷积块后的池化层将特征图尺寸减半
- 全局平均池化将特征压缩为固定维度
- 最后通过全连接层输出类别预测
让我们把这些组件组合成一个完整的CNN:
class SimpleCNN(nn.Module):def __init__(self, num_classes=1000):super().__init__()# 特征提取层self.features = nn.Sequential(# 第一个卷积块BasicConvLayer(3, 64),nn.MaxPool2d(2, 2),# 第二个卷积块BasicConvLayer(64, 128),nn.MaxPool2d(2, 2),# 第三个卷积块BasicConvLayer(128, 256),nn.MaxPool2d(2, 2),)# 分类层self.classifier = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)), # 全局平均池化nn.Flatten(),nn.Linear(256, num_classes))def forward(self, x):x = self.features(x)x = self.classifier(x)return x# 创建模型实例
model = SimpleCNN()
# 测试前向传播
x = torch.randn(1, 3, 224, 224)
output = model(x)
print(f"Input shape: {x.shape}")
print(f"Output shape: {output.shape}")这个简单的CNN模型展示了基本组件如何协同工作:
- 通过多个卷积块逐层提取特征
- 使用池化层降低特征图尺寸
- 最后通过全局池化和全连接层完成分类
4 现代CNN架构
卷积神经网络(CNN)的发展历程见证了深度学习领域的重要突破。从2012年AlexNet的横空出世,到如今轻量级网络和注意力机制的广泛应用,CNN架构在不断演进中展现出强大的潜力。
4.1 经典架构
经典CNN架构为现代深度学习奠定了坚实基础。2012年,AlexNet在ImageNet竞赛中以显著优势战胜传统计算机视觉方法,揭开了深度学习革命的序幕。AlexNet首次证明了深度卷积神经网络在大规模视觉识别任务上的潜力,它引入了多项开创性的技术:使用ReLU激活函数替代传统的Sigmoid,显著加快了训练速度;采用Dropout技术有效缓解过拟合;使用重叠池化增强特征提取能力;基于多GPU并行训练实现大规模模型训练。AlexNet的成功推动了深度学习在计算机视觉领域的广泛应用。
AlexNet的基本结构实现:
using UnityEngine;
using System;namespace CNNArchitectures
{public class AlexNet : MonoBehaviour {private class ConvLayer{public int Filters { get; private set; }public int KernelSize { get; private set; }public int Stride { get; private set; }public int Padding { get; private set; }public ConvLayer(int filters, int kernelSize, int stride = 1, int padding = 0){Filters = filters;KernelSize = kernelSize;Stride = stride;Padding = padding;}}private ConvLayer[] convLayers = new ConvLayer[]{new ConvLayer(96, 11, 4), // Conv1new ConvLayer(256, 5, 1, 2), // Conv2new ConvLayer(384, 3, 1, 1), // Conv3new ConvLayer(384, 3, 1, 1), // Conv4new ConvLayer(256, 3, 1, 1) // Conv5};private int[] fcLayers = new int[] { 4096, 4096, 1000 };// 在实际应用中需要实现前向传播等方法public float[] Forward(float[] input){// 实现前向传播逻辑throw new NotImplementedException();}}
}2015年,ResNet的出现是深度学习领域的一个重要里程碑。通过引入残差连接(跳跃连接),ResNet优雅地解决了深度网络的退化问题。残差学习框架使得超深网络(超过100层)的训练成为可能,极大地拓展了深度学习的应用边界。残差连接的核心思想是学习残差映射,而不是直接学习期望的底层映射,这种方式使得深层网络更容易优化。实践证明,残差连接不仅有助于训练更深的网络,还能提供更好的特征表示。
ResNet通过引入残差连接解决了深度网络的退化问题:
namespace CNNArchitectures
{public class ResidualBlock : MonoBehaviour {private int filters;private int stride;public ResidualBlock(int filters, int stride = 1){this.filters = filters;this.stride = stride;}public float[] Forward(float[] input){// 主路径float[] x = Conv2D(input, filters, 3, stride);x = BatchNorm(x);x = ReLU(x);x = Conv2D(x, filters, 3, 1);x = BatchNorm(x);// 短路连接float[] shortcut = input;if (stride != 1 || input.Length != x.Length){shortcut = Conv2D(input, filters, 1, stride);shortcut = BatchNorm(shortcut);}// 元素级加法return ReLU(Add(x, shortcut));}// 这些方法需要具体实现private float[] Conv2D(float[] input, int filters, int kernelSize, int stride) => throw new NotImplementedException();private float[] BatchNorm(float[] input) => throw new NotImplementedException();private float[] ReLU(float[] input) => throw new NotImplementedException();private float[] Add(float[] x, float[] y) => throw new NotImplementedException();}
}2017年提出的DenseNet进一步强化了特征重用的理念。通过密集连接模式,每一层都直接与之前所有层相连,形成了密集的特征传播网络。这种设计不仅加强了特征传播和梯度流动,还实现了参数的高效利用。DenseNet的成功表明,特征重用和多尺度特征融合对于提升模型性能至关重要。
4.2 轻量级架构
随着移动设备和边缘计算的普及,轻量级CNN架构成为研究热点。MobileNet系列网络通过深度可分离卷积显著降低计算成本,是轻量级网络的典型代表。MobileNetV1首次将深度可分离卷积应用于大规模视觉任务;MobileNetV2提出创新的倒置残差结构,进一步提升性能;MobileNetV3结合神经架构搜索和硬件感知优化,实现了更优的效率-性能平衡。
EfficientNet系列提出复合缩放方法,系统地研究了网络宽度、深度和分辨率三个维度的平衡关系。通过统一的缩放策略,EfficientNet在多个视觉任务上取得了优异的准确率和效率平衡。这一成果为轻量级网络的设计提供了重要的理论指导。
4.3 注意力机制
注意力机制的引入为CNN注入了新的活力。SENet率先将通道注意力机制引入CNN,通过自适应重标定通道特征响应,提升了特征表示能力。SE模块通过全局平均池化获取通道描述符,然后经过两层全连接网络学习通道间的相互关系,最后对特征图进行重标定。这种简单而有效的设计显著提升了模型性能。
SENet (Squeeze-and-Excitation)通过自适应重标定通道特征响应:
namespace CNNArchitectures
{public class SEBlock : MonoBehaviour {private int inChannels;private int reductionRatio;public SEBlock(int inChannels, int reductionRatio = 16){this.inChannels = inChannels;this.reductionRatio = reductionRatio;}public float[] Forward(float[] input){// Squeezefloat[] squeezed = GlobalAveragePooling(input);// Excitationint hidden = Math.Max(inChannels / reductionRatio, 1);float[] x = Dense(squeezed, hidden);x = ReLU(x);x = Dense(x, inChannels);x = Sigmoid(x);// Scalereturn Multiply(input, x);}// 这些方法需要具体实现private float[] GlobalAveragePooling(float[] input) => throw new NotImplementedException();private float[] Dense(float[] input, int units) => throw new NotImplementedException();private float[] ReLU(float[] input) => throw new NotImplementedException();private float[] Sigmoid(float[] input) => throw new NotImplementedException();private float[] Multiply(float[] input, float[] scale) => throw new NotImplementedException();}
}CBAM进一步拓展了注意力机制的应用,将通道注意力和空间注意力相结合。通道注意力关注"重要特征",空间注意力关注"重要位置",两者的协同作用提供了更全面的特征增强效果。这种串联的注意力机制不仅提升了性能,还保持了较低的计算开销。
Non-local Neural Networks引入了自注意力机制来捕获长程依赖关系。传统CNN的局部感受野限制了其建模长距离依赖的能力,而非局部操作通过计算任意两个位置的相关性,实现了全局上下文建模。
5 CNN训练技巧
卷积神经网络的训练过程充满挑战,掌握正确的训练技巧对于实现模型的最优性能至关重要。
5.1 数据预处理与增强
数据预处理和增强是提升模型泛化能力的基础。标准化处理能够使模型训练更加稳定,而数据增强则可以有效扩充训练集,降低过拟合风险。
在标准化方面,最常用的方法包括:
namespace CNNTraining
{public class ImagePreprocessing {// 零均值化public float[] ZeroMean(float[] input) {float mean = input.Average();return input.Select(x => x - mean).ToArray();}// Z-score标准化public float[] Standardize(float[] input) {float mean = input.Average();float std = (float)Math.Sqrt(input.Select(x => Math.Pow(x - mean, 2)).Average());return input.Select(x => (x - mean) / std).ToArray();}// Min-Max归一化public float[] MinMaxNormalize(float[] input) {float min = input.Min();float max = input.Max();return input.Select(x => (x - min) / (max - min)).ToArray();}}
}数据增强技术包括基础的几何变换(翻转、旋转、缩放)和像素级变换(亮度、对比度调整、噪声添加)。对于更复杂的场景,我们可以使用高级增强策略:
namespace CNNTraining
{public class DataAugmentation {private System.Random random = new System.Random();// Mixup增强public (float[] image, float[] label) Mixup(float[] image1, float[] label1, float[] image2, float[] label2,float alpha = 0.2f){float lambda = SampleBeta(alpha, alpha);var mixedImage = new float[image1.Length];var mixedLabel = new float[label1.Length];for (int i = 0; i < image1.Length; i++)mixedImage[i] = lambda * image1[i] + (1 - lambda) * image2[i];for (int i = 0; i < label1.Length; i++)mixedLabel[i] = lambda * label1[i] + (1 - lambda) * label2[i];return (mixedImage, mixedLabel);}private float SampleBeta(float alpha, float beta){// Beta分布采样实现throw new NotImplementedException();}}
}5.2 优化器选择
优化器的选择直接影响模型的收敛速度和最终性能。随机梯度下降(SGD)仍然是最可靠的选择之一,特别是在大规模视觉任务中:
public class SGDOptimizer
{private float learningRate;private float momentum;private Dictionary<string, float[]> velocities;public SGDOptimizer(float learningRate = 0.01f, float momentum = 0.9f){this.learningRate = learningRate;this.momentum = momentum;this.velocities = new Dictionary<string, float[]>();}public void UpdateParameters(Dictionary<string, float[]> parameters, Dictionary<string, float[]> gradients){foreach (var kvp in parameters){string paramName = kvp.Key;float[] param = kvp.Value;float[] grad = gradients[paramName];if (!velocities.ContainsKey(paramName))velocities[paramName] = new float[param.Length];for (int i = 0; i < param.Length; i++){velocities[paramName][i] = momentum * velocities[paramName][i] + learningRate * grad[i];param[i] -= velocities[paramName][i];}}}
}Adam优化器通过结合动量和自适应学习率,在许多任务中展现出优异的性能:
public class AdamOptimizer
{private float learningRate;private float beta1;private float beta2;private float epsilon;private Dictionary<string, float[]> momentums;private Dictionary<string, float[]> velocities;private int timeStep;public AdamOptimizer(float learningRate = 0.001f, float beta1 = 0.9f, float beta2 = 0.999f, float epsilon = 1e-8f){this.learningRate = learningRate;this.beta1 = beta1;this.beta2 = beta2;this.epsilon = epsilon;this.momentums = new Dictionary<string, float[]>();this.velocities = new Dictionary<string, float[]>();this.timeStep = 0;}public void UpdateParameters(Dictionary<string, float[]> parameters, Dictionary<string, float[]> gradients){timeStep++;float alpha = learningRate * (float)Math.Sqrt(1 - Math.Pow(beta2, timeStep)) / (1 - (float)Math.Pow(beta1, timeStep));foreach (var kvp in parameters){string paramName = kvp.Key;float[] param = kvp.Value;float[] grad = gradients[paramName];if (!momentums.ContainsKey(paramName)){momentums[paramName] = new float[param.Length];velocities[paramName] = new float[param.Length];}for (int i = 0; i < param.Length; i++){momentums[paramName][i] = beta1 * momentums[paramName][i] + (1 - beta1) * grad[i];velocities[paramName][i] = beta2 * velocities[paramName][i] + (1 - beta2) * grad[i] * grad[i];param[i] -= alpha * momentums[paramName][i] / ((float)Math.Sqrt(velocities[paramName][i]) + epsilon);}}}
}5.3 学习率调度
学习率的动态调整对模型训练至关重要。常用的学习率调度策略包括步衰减、余弦退火和循环学习率:
public class LearningRateScheduler
{// 步衰减public float StepDecay(float initialLR, int epoch, int stepSize, float gamma){return initialLR * (float)Math.Pow(gamma, Math.Floor(epoch / (double)stepSize));}// 余弦退火public float CosineAnneal(float initialLR, int epoch, int totalEpochs, float eta_min = 0f){return eta_min + (initialLR - eta_min) * (1 + (float)Math.Cos(Math.PI * epoch / totalEpochs)) / 2;}// One-Cycle策略public float OneCycle(float maxLR, int iteration, int totalIterations){float cycle = (float)iteration / totalIterations;if (cycle < 0.5f)return maxLR * (cycle * 2);elsereturn maxLR * (1 - (cycle - 0.5f) * 2);}
}5.4 正则化方法
正则化是防止过拟合的关键技术。常用的方法包括L1/L2正则化、Dropout和批量归一化:
public class Regularization
{// L2正则化public float L2Penalty(float[] weights, float lambda){return lambda * weights.Select(w => w * w).Sum() / 2;}// Dropout实现public float[] Dropout(float[] input, float dropRate, bool isTraining){if (!isTraining || dropRate == 0)return input;var random = new System.Random();var mask = input.Select(_ => random.NextDouble() > dropRate ? 1.0f : 0.0f).ToArray();var scale = 1.0f / (1.0f - dropRate);return input.Zip(mask, (x, m) => x * m * scale).ToArray();}// 批量归一化public (float[] output, float[] runningMean, float[] runningVar) BatchNorm(float[] input, float[] gamma, float[] beta, float[] runningMean, float[] runningVar, bool isTraining, float momentum = 0.9f, float epsilon = 1e-5f){if (isTraining){float mean = input.Average();float variance = input.Select(x => (x - mean) * (x - mean)).Average();// 更新运行时统计量for (int i = 0; i < runningMean.Length; i++){runningMean[i] = momentum * runningMean[i] + (1 - momentum) * mean;runningVar[i] = momentum * runningVar[i] + (1 - momentum) * variance;}// 标准化和缩放return (input.Select(x => gamma[0] * (x - mean) / (float)Math.Sqrt(variance + epsilon) + beta[0]).ToArray(), runningMean, runningVar);}else{// 测试时使用运行时统计量return (input.Select(x => gamma[0] * (x - runningMean[0]) / (float)Math.Sqrt(runningVar[0] + epsilon) + beta[0]).ToArray(), runningMean, runningVar);}}
}这些训练技巧的组合使用对于获得高性能的CNN模型至关重要。在实践中,需要根据具体任务和数据特点选择合适的技术组合。特别是在复杂的视觉任务中,合理的训练策略往往能带来显著的性能提升。
内容不全等,请各位理解支持!!
相关文章:

卷积神经网络入门指南:从原理到实践
目录 1 CNN的发展历史 2 CNN的基本原理 3 CNN核心组件 3.1 卷积操作基础 3.2 卷积层详解 3.3 高级卷积操作 3.3.1 分组卷积(Group Convolution) 3.3.2 深度可分离卷积(Depthwise Separable Convolution): 3.3 池…...

eNSP安装教程(内含安装包)
通过网盘分享的文件:eNSP模拟器.zip 链接: https://pan.baidu.com/s/1wPmAr4MV8YBq3U5i3hbhzQ 提取码: tefj --来自百度网盘超级会员v1的分享 !!!!解压后有四个文件,先安装Box,第二个安装cap&a…...
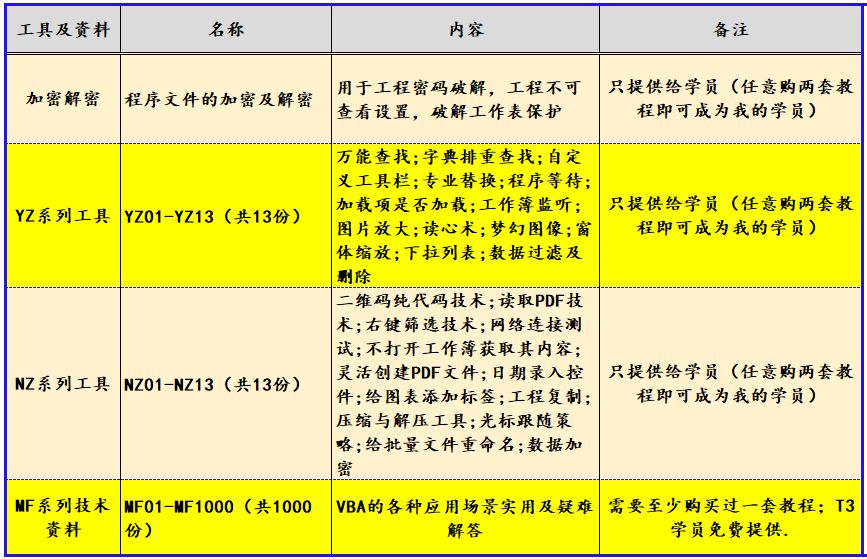
VBA技术资料MF244:利用VBA在图表工作表中创建堆积条形图
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。“VBA语言専攻”提供的教程一共九套,分为初级、中级、高级三大部分,教程是对VBA的系统讲解&#…...

【计算机网络安全】网络攻击
实验二 网络攻击 实验人员:第五组全体成员 一、实验目的: 1:掌握ARP欺骗的原理,实践ARP欺骗的过程。 2:掌握TCP劫持的原理,实践TCP劫持的过程。 3:掌握DNS欺骗的原理,实践DN…...
求解特征值(numpy, scipy))
20241230 基础数学-线性代数-(1)求解特征值(numpy, scipy)
所有代码实现,基于教程中的理论通过python实现出来的。效率不高,但有代码可以看。 由于scipy/sckitlearn/sparkx 底层的实现都被封装了(小白兔水平有限,fortran代码实在没看懂)这里的实现至少可以和理论公式对应的上。…...

基于图注意力网络的两阶段图匹配点云配准方法
Two-stage graph matching point cloud registration method based on graph attention network— 基于图注意力网络的两阶段图匹配点云配准方法 从两阶段点云配准方法中找一些图匹配的一些灵感。文章提出了两阶段图匹配点云配准网络(TSGM-Net) TSGM-Ne…...

【半导体光电子器件】课后习题答案和知识点汇总
关注作者了解更多 我的其他CSDN专栏 求职面试 大学英语 过程控制系统 工程测试技术 虚拟仪器技术 可编程控制器 工业现场总线 数字图像处理 智能控制 传感器技术 嵌入式系统 复变函数与积分变换 单片机原理 线性代数 大学物理 热工与工程流体力学 数字信号处…...

Unity命令行传递自定义参数 命令行打包
命令行参数增加位置 -executeMethod 某脚本.某方法 参数1 参数2 参数3 ... 例如执行EditorTest.GetCommandLineArgs方法 增加两个命令行参数 Version=125 CDNVersion=100 -executeMethod EditorTest.GetCommandLineArgs Version=125 CDNVersion=100 Unity测试脚本 需要放在…...

web-worker应用在大文件切片上传
当文件体积过大时,传统的文件上传方式往往会导致页面卡顿,用户体验不佳。为了解决这一问题,我们可以利用Web Worker技术来进行大文件的切片上传。本文将详细介绍如何使用Web Worker进行大文件切片上传,并通过具体的例子来演示其实…...

Django 模板分割及多语言支持案例【需求文档】-->【实现方案】
Django 模板分割及多语言支持案例 这个案例旨在提供一个清晰的示范,展示如何将复杂的页面分解为多个可复用的模板组件,使代码更加模块化和易于管理。希望这篇案例文章对你有所帮助。 概述 在 Django 项目开发中,使用模板分割和多语言支持能…...

C中设计不允许继承的类的实现方法是什么?
在C中,设计不允许继承的类可以通过多种方法实现。以下是详细的方法说明及示例: ### 方法一:将构造函数和析构函数设为私有 这种方法的核心思想是通过将构造函数和析构函数设为私有,使得子类无法调用这些函数,从而无法…...

面对小白的C语言学习方法
这是第20篇文章,不来弄一些技术的,弄一些最近的学习心得,怎么更有效地自学C语言 书籍 书籍可以很有效的告知我们专有函数,使用方法还有一些思考方式,缺点是实操差点意思,还是不太能解决实际问题ÿ…...

使用libgif库解码全过程(C语言)-包括扩展块的处理
我看到的所有例程,都把扩展部分的处理跳过了,而我的动画是有透明度的,这就导致解码后的图像在有透明色的像素部分,呈现了很多的黑点,或者闪白的情况出现。经过调试,终于成功。 文件格式 先了解一下GIF的文…...

blazor实现ASP.NET网站用户批量注册方法
ASP.NET网站用户批量注册是许多使用blazor系统开发遇到的问题,为了解决这个问题,我们提出比较完善的解决方法,通过代码实现了一个批量用户注册功能,用于解析一份用户名列表,并通过后台服务注册用户,同时对成功和失败的注册进行记录和反馈。以下是实现功能的详细工作原理描…...

SpringCloud 入门(4)—— 网关
上一篇:SpringCloud 入门(3)—— Nacos配置中心-CSDN博客 Spring Cloud Gateway 作为 Spring Cloud 生态系统的一部分,主要在微服务架构中充当 API 网关的角色。它提供了统一的入口点来处理所有的 HTTP 请求,并将这些请…...

什么是WebAssembly?怎么使用?
一、简述 WebAssembly,也称为Wasm,是基于堆栈的虚拟机的二进制指令格式。它被设计为一个可移植的目标,用于编译C、C和Rust等高级编程语言,允许代码以接近本机速度在web浏览器中运行。WebAssembly于2015年由包括谷歌、微软、Mozill…...

v3s点RGB屏 40pin 800x480,不一样的点屏,不通过chosen。
一、背景、目的、简介。 一般来说,通过uboot将屏幕参数传给kernel,是通过修改设备树。 uboot和kernel都需要屏幕点亮。uboot侧重于显示一张图片。而kernel则多是动画。 在这里,我先是找到了一个裸机点屏的代码。将其编译成静态库后&#x…...
某科技局国产服务器PVE虚拟化技术文档
环境介绍 硬件配置 服务器品牌:黄河 型号:Huanghe 2280 V2 Cpu型号:kunpeng-920 磁盘信息 :480SSD * 2 ,4T*4 网卡:板载四口千兆 如下表 四台服务器同等型号配置,均做单节点虚拟化,数据保护采用底层r…...

中科岩创边坡自动化监测解决方案
行业现状 由于边坡不稳定性因素,可能会造成斜坡上的岩土体沿着某个面不均匀向下向外滑动,形成滑坡;陡峭山坡上岩土体在重力作用下,发生陡然倾落运动,造成崩塌;在沟谷或山坡上产生的夹带大量泥沙、石块等固体…...

GPT-O3:简单介绍
GPT-O3:人工智能领域的重大突破 近日,OpenAI发布了其最新的AI模型GPT-O3,这一模型在AGI评估中取得了惊人的成绩,展现出强大的能力和潜力。GPT-O3的出现标志着人工智能领域的重大进步,预计将在2025年实现更大的突破。 …...

四座小水库的“智能体检”:广州创科大亚湾安全监测项目纪实
在惠州鱿鱼湾、龙尾山、格木洞、畲禾坑四座水库,如同镶嵌在群山之间的明珠,守护着下游的城镇与工业区。它们大多建于上世纪六七十年代,服役已超半个世纪。2023年冬,一场以“除险加固智慧监测”为核心的维修加固工程正式拉开帷幕。…...

TwiLiquidCrystal库:HD44780 LCD的I²C裸机级驱动解析
1. TwiLiquidCrystal 库概述:面向嵌入式工程师的 HD44780 LCD IC 驱动深度解析TwiLiquidCrystal 是由开发者 Arnakazim 维护的一个轻量级、高兼容性的 Arduino 兼容库,专为通过 IC(在 AVR 平台常称 TWI)总线驱动 HD44780 及其兼容…...

详细解析Spring如何解决循环依赖问题事
AI训练存储选型的演进路线 第一阶段:单机直连时代 早期的深度学习数据集较小,模型训练通常在单台服务器或单张GPU卡上完成。此时直接将数据存储在训练机器的本地NVMe SSD/HDD上。 其优势在于IO延迟最低,吞吐量极高,也就是“数据离…...

第十五节:启动序列——从 claude 命令到 REPL 就绪
知识图谱定位:前面两节我们分别拆解了终端 UI(第13节 React Ink)和命令系统(第14节 斜杠路由)——它们都假设一个前提:REPL 已经就绪。但从用户在终端敲下 claude 按回车,到他看到交互界面,这中间到底发生了什么?答案是一个精心设计的三阶段启动序列:cli.tsx::main()…...

深入剖析 Android 系统属性:从 build.prop 到 Selinux 安全机制
1. Android系统属性基础入门 第一次接触Android系统属性时,我也被各种.prop文件和复杂的配置搞得一头雾水。经过多年实战,我发现理解属性系统其实有个简单的方法 - 把它想象成Windows的注册表。就像注册表存储着Windows的配置信息一样,Androi…...

详细解析Spring如何解决循环依赖问题地
AI训练存储选型的演进路线 第一阶段:单机直连时代 早期的深度学习数据集较小,模型训练通常在单台服务器或单张GPU卡上完成。此时直接将数据存储在训练机器的本地NVMe SSD/HDD上。 其优势在于IO延迟最低,吞吐量极高,也就是“数据离…...

神秘“欢乐马“空降屠榜,碾压Seedance 2.0,视频AI又变天了?
文章目录 前言榜单突变:神秘模型空降第一查无此人?这匹马到底从哪儿来的技术深扒:这马到底强在哪儿第一个就是"稳"第二个是"快"第三个是"全" 对比Seedance 2.0:神仙打架开源普惠?这可能…...

OpenTAP硬件集成测试优势解析
OpenTAP 之所以在硬件和系统集成测试领域表现出色,主要得益于其独特的设计理念、灵活的架构以及强大的社区生态支持。以下将从核心架构、技术优势、应用场景和具体实施案例等多个维度进行详细阐述。 一、 核心架构与设计理念 OpenTAP 基于 .NET 平台构建ÿ…...

YOLO-Master 与 YOLO 开始奖
AI Agent 时代的沙箱需求 从 Copilot 到 Agent:执行能力的质变 在生成式 AI 的早期阶段,应用主要以“Copilot”形式存在,AI 仅作为辅助生成建议。然而,随着 AutoGPT、BabyAGI 以及 OpenAI Code Interpreter(现为 Advan…...

小白也能用的AI神器:Anything to RealCharacters 2.5D转真人引擎全流程体验
小白也能用的AI神器:Anything to RealCharacters 2.5D转真人引擎全流程体验 1. 从动漫到真人的神奇转换 你是否曾经想过,把自己喜欢的动漫角色变成真实人物会是什么样子?或者想把游戏中的虚拟形象变成一张可以打印的照片?现在&a…...