Hadoop集群(HDFS集群、YARN集群、MapReduce计算框架)
一、 简介
Hadoop主要在分布式环境下集群机器,获取海量数据的处理能力,实现分布式集群下的大数据存储和计算。
其中三大核心组件: HDFS存储分布式文件存储、YARN分布式资源管理、MapReduce分布式计算。
二、工作原理
2.1 HDFS集群
Web访问地址:http://hadoop1:9870
HDFS由NameNode(主节点)、SecondaryNameNode(辅助节点)、DataNode(从节点)构成,
其中NameNode负责管理整个HDFS集群,SecondaryNameNode辅助NameNode管理元数据,DataNode负责存储实际的数据块(一个block块默认大小128MB)和对数据块的读、写操作。

2.1.1 block数据块
- 基本存储单位(一般64M)
- 一个大文件会被拆分成多个block块,然后存储到不通机器上
- 每块会备份到其他机器上,保证数据安全性,防止数据丢失(默认备份3份)。
2.1.2 NameNode
- 管理文件系统命名空间和客户端对文件访问
- 保存文件具体信息(文件信息、文件拆分block块信息、以及block和DataNode的信息)
- 接收用户请求
2.1.3 DataNode
- 保存具体的block数据
- 负责数据的读写操作和复制操作
- 向NameNode报告当前存储或者修改的数据信息
- DataNode之间进行相互通信,复制数据块
2.1.4 Secondary NameNode
- 定时与NameNode进行同步(合并fsimage和edits文件)
- 当NameNode失效时,需要手工将其设置成主机
2.1.5 文件写入步骤
1. Client(客户端)请求namenode保存文件。
2. NameNode接收到客户端请求后, 会校验客户端针对该文件是否有写的权利,文件是否存在,校验通过后告知客户端可以上传。
3. 接收到可以上传的指令后, 客户端会按照128MB(默认)对文件进行切块。
4. Client(客户端)再次请求namenode, 第1个Block块的上传位置。
5. namenode会根据副本机制, 负载均衡, 机架感知原理及网络拓扑图, 返回给客户端存储该Block块的DataNode列表。
例如: node1, node2, node3;
6. Client(客户端)会先连接就近的datanode机器, 然后依次和其他的datanode进行连接, 形成传输管道(Pipeline);
7. 采用数据报包(DataPacket)的形式传输数据, 每个包的大小不超过64KB, 并建立反向应答机制(ACK机制);
8. 具体的上传动作: node1 -> node2 -> node3, ACK反向应答机制: node3 => node2 => node1。
9. 重复上述的步骤, 直至第1个Block块上传完毕。
10. 第一个Bloc上传完毕客户端(Client)重新请求第二个Block的上传位置, 重复上述动作, 直至所有的Block块传输完毕。
至此, HDFS写数据流程结束。

2.1.6 文件读取步骤
1. Client(客户端)请求namenode, 读取文件。
2. NameNode校验该客户端是否有读权限, 及该文件是否存在, 校验成功后, 会返回给客户端该文件的块信息。
例如:
block1: node1, node2, node5
block2: node3, node6, node8
block3: node2, node5, node6 这些地址都是鲜活的;
......
3. Client(客户端)会连接上述的机器(节点), 并行的从中读取块的数据。
4. Client(客户端)读取完毕后, 会循环NameNode获取剩下所有的(或者部分的块信息), 并行读取, 直至所有数据读取完毕。
5. Client(客户端)根据Block块编号, 把多个Block块数据合并成最终文件即可。

2.1.7 数据备份
- NameNode负责管理block块的复制,它周期性地接收集群中所有DataNode的心跳数据包和Blockreport。心跳包表示DataNode正常工作,Blockreport描述了该DataNode上所有的block组成的列表。
- HDFS采用一种称为rack-aware的策略来决定备份数据的存放。通过一个称为Rack Awareness的过程,NameNode决定每个DataNode所属rack id。缺省情况下,一个block块会有三个备份,一个在NameNode指定的DataNode上,一个在指定DataNode非同一rack的DataNode上,一个在指定DataNode同一rack的DataNode上。这种策略综合考虑了同一rack失效、以及不同rack之间数据复制性能问题。
- 为了降低整体的带宽消耗和读取延时,HDFS会尽量读取最近的副本。如果在同一个rack上有一个副本,那么就读该副本。如果一个HDFS集群跨越多个数据中心,那么将首先尝试读本地数据中心的副本。
2.1.8 HDFS工作原理
1、NameNode初始化时会产生一个edits文件和一个fsimage文件。
2、随着edits文件不断增大,当达到设定的阀值时(1个小时或写入100万次),SecondaryNameNode把edits文件和fsImage文件复制到本地,同时NameNode会产生一个新的edits文件替换掉旧的edits文件,这样以保证数据不会出现冗余。
3、SecondaryNameNode拿到这两个文件后,会在内存中进行合并成一个fsImage.ckpt的文件(这个过程称为checkpoint),合并完成后,再将fsImage.ckpt文件推送给NameNode。
4、NameNode文件拿到fsImage.ckpt文件后,会将旧的fsimage文件替换掉(并不会立刻替换,而是达到一定阈值后被替换掉),并且改名成fsimage文件。
通过以上几步则完成了edits和fsimage文件的合并,依此不断循环,从而到达保证元数据的正确性。在紧急情况下, SecondaryNameNode可以用来恢复namenode的元数据。

2.2 YARN集群
Web访问地址:http://hadoop1:8088
YARN是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作平台,而Mapreduce等运算程序相当于运行在操作系统之上的应运程序。
YARN组成由ResourceManager、AppMaster进程、NodeManager组成
2.2.1 ResourceManager(主节点)
ResourceManager是master上的进程,负责整个分布式系统的资源管理和调度。他会处理来自client端的请求(包括提交作业/杀死作业);启动/监控Application Master;监控NodeManager的情况,比如可能挂掉的NodeManager。
2.2.2 NodeManager(从节点)
负责接收并执行ResourceManager分配的计算任务。相对应的,NodeManager时处在slave节点上的进程,他只负责当前slave节点的资源管理和调度,以及task的运行。他会定期向ResourceManager回报资源/Container的情况(heartbeat);接受来自ResourceManager对于Container的启停命令。
2.2.3 AppMaster进程
每一个提交到集群的作业都会有一个与之对应的Application Master来负责应用程序的管理。他负责进行数据切分;为当前应用程序向ResourceManager去申请资源(也就是Container),并分配给具体的任务;与NodeManager通信,用来启停具体的任务,任务运行在Container中;而任务的监控和容错也是由Application Master来负责的。
1个计算任务=1个AppMaster进程
由该AppMaster进程来监控和管理该计算任务
2.2.4 Container
它包含了Application Master向ResourceManager申请的计算资源,比如说CPU/内存的大小,以及任务运行所需的环境变量和队任务运行情况的描述。

2.3 MapReduce工作原理
MapReduce是一种分布式计算框架。MR的执行流程:
1. MR任务分为MapTask任务 ReduceTask任务两部分, 其中MapTask任务负责:分; ReduceTask任务负责:合。
- 1个切片(默认128MB) = 1个MapTask任务 = 1个分好区, 排好序, 规好约的磁盘文件;
2. 先对文件进行切片, 每个切片对应1个MapTask任务, 任务内部会逐行读取数据, 交由MapTask任务来处理。
3. MapTask对数据进行分区,排序,规约处理后, 会将数据放到1个 环形缓冲区中(默认大小: 100MB, 溢写比: 0.8), 达到80MB就会触发溢写线程。
4. 溢写线程会将环形缓冲区中的结果写到磁盘的小文件中, 当MapTask任务结束的时候, 会对所有的小文件(10个/次)合并, 形成1个大的磁盘文件。
5. ReduceTask任务会开启拷贝线程, 从上述的各个结果文件中, 拉取属于自己分区的数据, 进行分组、统计、聚合。
6. ReduceTask将处理后的结果, 写到结果文件中;
- 1个分区 = 1个ReduceTask任务 = 1个结果文件;

2.4 三者之间的关系
客户端Client提交任务到资源管理器(ResourceManager),资源管理器接收到任务之后去NodeManager节点开启任务(ApplicationMaster), ApplicationMaster向ResourceManager申请资源, 若有资源ApplicationMaster负责开启任务即MapTask。开始干活了即分析任务,每个map独立工作,各自负责检索各自对应的DataNode,将结果记录到HDFS, DataNode负责存储,NameNode负责记录,2nn负责备份部分数据。

相关文章:
Hadoop集群(HDFS集群、YARN集群、MapReduce计算框架)
一、 简介 Hadoop主要在分布式环境下集群机器,获取海量数据的处理能力,实现分布式集群下的大数据存储和计算。 其中三大核心组件: HDFS存储分布式文件存储、YARN分布式资源管理、MapReduce分布式计算。 二、工作原理 2.1 HDFS集群 Web访问地址&…...
经验总结(gtest+gmock))
单元测试(UT,C++版)经验总结(gtest+gmock)
最近做了一段测试工作,其中包括单元测试,编程语言是C。这里提供一些基本知识总结,方便入门单元测试。 1.单元测试介绍 单元测试(Unit Testing, 简称UT)是软件测试的一种方法,目的是通过对单个软件组件&am…...
)
Mysql高级部分总结(二)
MySQL的内部日志 binlog记载的是update/delete/insert这样的SQL语句,而redo log记载的是物理修改的内容(xxxx页修改了xxx)。 binlog无论MySQL用什么引擎,都会有,而redo log是MySQL的InnoDB引擎所产生的。 redo log事务开始的时候,就开始记录每次的变更信息,而binlog是在…...

纠正一下网络管理
先找到那个hrStorageType 这里我的值是 后面的值.1.3.6.1.2.1.25.2.1.4代表磁盘 我只有2个盘 C盘和D盘 所以这里只有2个 你们有E盘F盘的话 这里会多 .1.3.6.1.2.1.25.2.1.2 代表内存 .1.3.6.1.2.1.25.2.1.2 前面是 hrStorageType.4 所以 这里面.4后缀是表示内存的 之前…...

homebrew,gem,cocoapod 换源,以及安装依赖
安装homebrew /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" 再按照成功提示配置环境变量 ruby 更新ruby到最新 brew install ruby 如果安装了会自动升级 安装完成后根据提示配置环境变量 再执行命令使其生效 s…...

Java字符串的|分隔符转List实现方案
字符串处理 问题背景代码实现代码优化原因分析实现方案 注意事项异常处理Maven未识别异常 问题背景 在项目组对账流程中,接收对方系统的对账文件,数据以|为分隔符,读取文件内容,分条入库。 代码实现 Java中将字符串转给list&am…...

Kafka可视化工具 Offset Explorer (以前叫Kafka Tool)
数据的存储是基于 主题(Topic) 和 分区(Partition) 的 Kafka是一个高可靠性的分布式消息系统,广泛应用于大规模数据处理和实时, 为了更方便地管理和监控Kafka集群,开发人员和运维人员经常需要使用可视化工具…...
DeepWalk 原理详解
概述: DeepWalk 是一种流行的图嵌入方法,用于学习图结构数据中节点的低维表示。它通过将图的节点视作序列数据,利用自然语言处理中的技术(类似于word2vec算法)来捕捉节点间的关系,可以帮助我们理解和利用图…...

GitLab安装|备份数据|迁移数据及使用教程
作者: 宋发元 最后更新时间:2024-12-24 GitLab安装及使用教程 官方教程 https://docs.gitlab.com/ee/install/docker.html Docker安装GitLab 宿主机创建容器持久化目录卷 mkdir -p /docker/gitlab/{config,data,logs}拉取GitLab镜像 docker pull gi…...
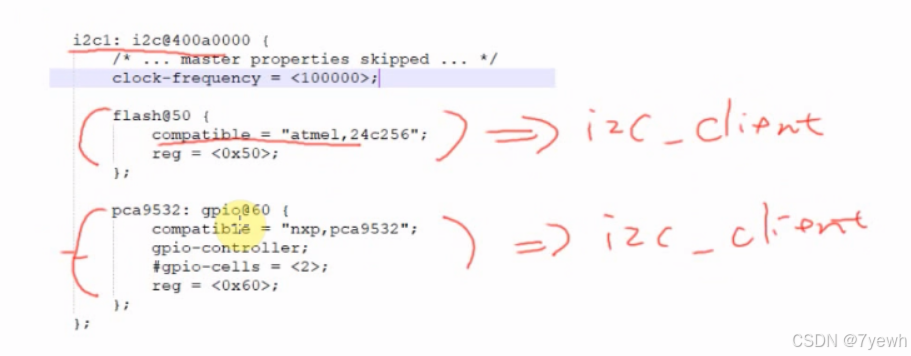
嵌入式linux驱动框架 I2C系统驱动程序模型分析
引言:在嵌入式 Linux 系统中,I2C(Inter-Integrated Circuit)是一种常用的通信协议,用于连接低速设备(如传感器、显示器、存储器等)与主控制器。I2C 系统驱动程序模型通过层次化的设计࿰…...

深度学习实验十七 优化算法比较
目录 一、优化算法的实验设定 1.1 2D可视化实验(被优化函数为) 1.2 简单拟合实验 二、学习率调整 2.1 AdaGrad算法 2.2 RMSprop算法 三、梯度修正估计 3.1 动量法 3.2 Adam算法 四、被优化函数变为的2D可视化 五、不同优化器的3D可视化对比 …...

一个双非选手的秋招总结
个人bg介绍 25届双非本硕(非杭电深大,垫底双非),两段实习经历,本科没学过Java,有c语言和408基础;2023年10月份中途转语言,Java速成选手。 战绩总结:实习秋招面试总论次…...

如何提高永磁电动机的节电效果
在现代工业和家庭应用中,永磁电动机因其优越的性能和节能特性,逐渐成为主流选择。随着能源日益紧缺和环境问题的日益严重,寻求高效的电动机节能方案显得尤为重要。 一、永磁电动机的基本原理 永磁电动机的核心是永磁体,这些永磁…...

在一个服务器上抓取 Docker 镜像并在另一个服务器上运行
要在一个服务器上抓取 Docker 镜像并在另一个服务器上运行,您可以按照以下步骤进行操作: 1. 保存 Docker 镜像 在源服务器上,您可以使用 docker save 命令将 Docker 镜像保存为一个 tar 文件。例如,如果您的镜像名称是 face_det…...

开源轮子 - Logback 和 Slf4j
spring boot内置:Logback 文章目录 spring boot内置:Logback一:Logback强在哪?二:简单使用三:把 log4j 转成 logback四:日志门面SLF4J1:什么是SLF4J2:SLF4J 解决了什么痛…...

内部知识库的未来展望:技术融合与用户体验的双重升级
在当今数字化飞速发展的时代,企业内部知识库作为知识管理的关键载体,正站在变革的十字路口,即将迎来技术融合与用户体验双重升级的崭新时代,这一系列变化将深度重塑企业知识管理的格局。 一、技术融合:开启知识管理新…...

【Linux系列】Shell 命令:`echo ““ > img.sh`及其应用
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

【RAG实战】语言模型基础
语言模型赋予了计算机理解和生成人类语言的能力。它结合了统计学原理和深度神经网络技术,通过对大量的样本数据进行复杂的概率分布分析来学习语言结构的内在模式和相关性。具体地,语言模型可根据上下文中已出现的词序列,使用概率推断来预测接…...

【MySQL】7.0 入门学习(七)——MySQL基本指令:帮助、清除输入、查询等
1.0 help ? 帮助指令,查询某个指令的解释、用法、说明等。详情参考博文: 【数据库】6.0 MySQL入门学习(六)——MySQL启动与停止、官方手册、文档查询 https://www.cnblogs.com/xiaofu007/p/10301005.html 2.0 在cmd命…...

我的 2024 年终总结
2024 年,我离开了待了两年的互联网公司,来到了一家聚焦教育机器人和激光切割机的公司,没错,是一家硬件公司,从未接触过的领域,但这还不是我今年最重要的里程碑事件 5 月份的时候,正式提出了离职…...

Qwen3.5-2B网络编程应用:构建基于WebSocket的实时多模态聊天服务
Qwen3.5-2B网络编程应用:构建基于WebSocket的实时多模态聊天服务 1. 实时聊天服务的价值与挑战 想象一下这样的场景:电商客服需要同时处理图片咨询和文字提问,在线教育平台要实时解答学生上传的题目截图,或是设计团队需要AI即时…...
:最新Ubuntu25 安装最新K8S (断电重启、断电重置)超详细步骤,安装不好你来打我~)
第零章(K8s启航):最新Ubuntu25 安装最新K8S (断电重启、断电重置)超详细步骤,安装不好你来打我~
Ubuntu安装K8S1. 服务器初始化(所有节点) vim /etc/hosts127.0.0.1 localhost # 127.0.1.1 yww# The following lines are desirable for IPv6 capable hosts ::1 ip6-localhost ip6-loopback fe00::0 ip6-localnet ff00::0 ip6-mcastprefix ff02::1…...

算法调度问题中的代价模型与优化方法的技术5
算法调度问题概述定义与基本概念:任务调度、资源分配、目标函数典型应用场景:云计算、分布式系统、实时系统核心挑战:多目标权衡、动态环境、不确定性代价模型的设计与分析代价模型的组成:时间代价、资源代价、经济代价常见模型分…...

HY-Motion 1.0保姆级教程:从零配置GPU环境生成文生3D动作
HY-Motion 1.0保姆级教程:从零配置GPU环境生成文生3D动作 想用一句话就让3D角色动起来吗?比如,输入“一个人从椅子上站起来,然后伸展双臂”,电脑就能自动生成一段流畅、自然的3D骨骼动画。这听起来像是未来科技&#…...
)
从一次Sigar崩溃看Java生态的‘版本地狱’:如何优雅管理JDK与本地库的兼容性矩阵(附jdk1.8.0_241下载与降级实操)
Java生态中的依赖兼容性管理:从Sigar崩溃案例到系统化解决方案 当你在Windows 10环境下运行一个看似简单的Java应用,突然遭遇EXCEPTION_ACCESS_VIOLATION错误,而问题根源指向一个名为sigar-amd64-winnt.dll的本地库文件时,这远不止…...

OpenClaw浏览器控制:Phi-3-mini-128k-instruct自动填写网页表单
OpenClaw浏览器控制:Phi-3-mini-128k-instruct自动填写网页表单 1. 为什么需要浏览器自动化 在日常工作中,我们经常遇到需要重复填写网页表单的场景。比如每周提交的周报系统、定期更新的数据录入页面,或是需要批量处理的问卷调查。这些任务…...

Kuikly实现Android iOS Web小程序一码覆盖实践
跨端开发趋势与“一码覆盖”的现实路径 在多终端普及与用户场景碎片化的背景下,移动、桌面、Web与小程序的并行发展让“一次开发、多端运行”成为开发者的核心诉求。传统方案中,React Native因桥接机制存在通信延迟与UI不一致问题,Flutter因…...

Level2行情接口全解析:从实时数据订阅到历史回测的量化实战指南
1. Level2行情接口入门:为什么量化交易离不开它 第一次接触Level2行情时,我也被那些专业术语搞得一头雾水。直到有次亲眼看到两个量化团队用相同策略回测,用Level1数据的团队年化收益12%,而用Level2数据的团队达到21%,…...

基于扩展卡尔曼滤波EKF和模型预测控制MPC,自动泊车场景建模开发,文复现。 MATLAB(工...
基于扩展卡尔曼滤波EKF和模型预测控制MPC,自动泊车场景建模开发,文复现。 MATLAB(工程项目线上支持)自动泊车这活儿看着简单,实际操作起来全是坑。今天咱们就掰开揉碎了聊聊怎么用EKF和MPC这对黄金搭档搞定车位里的毫米…...

1990~2024年各省市区区县水稻种植面积面板数据
各省市区县区县水稻种植面积面板数据1990~2024 数据文件包含如下: 1990~2024年各城市水稻种植面积面板数据.dta 1990~2024年各区县水稻种植面积面板数据.dta 1990~2024年各省份水稻种植面积面板数据.dta 除了省市…...