【RAG实战】语言模型基础
语言模型赋予了计算机理解和生成人类语言的能力。它结合了统计学原理和深度神经网络技术,通过对大量的样本数据进行复杂的概率分布分析来学习语言结构的内在模式和相关性。具体地,语言模型可根据上下文中已出现的词序列,使用概率推断来预测接下来可能出现的词汇。接下来主要介绍一些基础的语言模型,如Transformer、自动编码器、自回归模型等。
2.1 Transformer
Transformer模型是深度学习,尤其是自然语言处理(NLP)领域的一次重大突破。
从概念上看,Transformer模型可以被视为一个黑盒子,以极其翻译任务为例,它能够接收某种语言的输入文本,并输出对应语言的翻译版本

从内部结构来看,Transformer由编码器(encoder)和解码器(decoder)量大部分构成,这两部分在原始的"Attention is all you need"论文中包含6个模块,但在实际应用中,这个数字可以根据具体任务进行调整。
以机器翻译为例,Transformer的工作流程大致分为以下几个步骤:
-
获取句子中每个单词的表示向量X,X可以通过词嵌入(embedding)得到。X中包含单词数据特征和位置信息。如果以简单的框来表示向量,则每个单词都可以被表示为一个高纬向量,最终的输入句子被表示为一个词向量矩阵。
-
将得到的词向量矩阵传入编码器部分,每个单词的词向量都会经过编码块,在经过6个编码块后可以得到编码矩阵C。单词向量矩阵表示为Xn*d,n代表输入语句中的单词个数,d代表向量的维度。
-
解码器部分也是由6个完全相同的解码块堆叠而成,解码时,解码块会接收编码器部分输出的编码矩阵C和上一个解码块的输出,即解码层会根据当前词i和i之前的词信息翻译下一个单词i+1。在实际的执行过程中,i+1位置后的单词需要被掩盖点以防止i+1知道后面的信息。
Transformer的核心结构由词嵌入、编码器、解码器、输出生成四个部分组成,如下图所示

2.1.1 词嵌入
Transformer中输入单词的词嵌入包含单词编码和位置编码。单词编码用于编码单词的语义,位置编码用于编码单词的位置
1. 单词编码
单词编码(word embedding)是一种以数字方式表示句子中单词的方法,该方法用来表示单词语义特征。这里介绍三种编码方式:神经网络编码、词向量编码和全局词向量表示
(1)神经网络编码
基于神经网络语言模型(Neural Network Language Model,NNLM)的编码方式最早由Bengio等人提出,用于解决统计语言模型中常见的维度灾难问题。该方法是训练一个神经网络,在训练中,每个参与的句子告诉模型由哪些单词在语义上相近,最终模型为每个单词生成一种分布式表示,这种表示能够捕捉并保留单词的语义和语法关系
Bengio的神经网络主要由三个部分组成:一个词嵌入层,用于生成词嵌入表示,且单词之间参数共享;一个或多个隐藏层,用于生成词嵌入的非线性关系;一个激活层,用于生成整个词汇表中每个单词的概率分布
该网络使用损失函数在反向传播过程中更新参数,并尝试找到单词之间相对较好的依赖关系,同时保留语义和语法属性。下面通过简单的代码来理解其训练过程
1)单词索引
对单词建立索引,句子中每个单词都会被分配一个数字
word_list = " ".join(raw_sentence).split()
word_list = list(set(word_list))
word2id = {w: i for i, w in enumerate(word_list)}
id2word = {i: w for i, w in enumerate(word_list)}
n_class = len(word2id)
2)构建模型
class NNLM(nn.Module):def __init__(self):super(NNLM, self).__init__()self.embeddings = nn.Embedding(n_class, m)self.hidden1 = nn.Linear(n_step * m, n_hidden, bias=False)self.ones = nn.Parameter(torch.ones(n_hidden))self.hidden2 = nn.Linear(n_hidden, n_class, bias=False)self.hidden2 = nn.Linear(n_step * m, n_class, bias=False) #final layerself.bias = nn.Parameter(torch.ones(n_class))def forward(self, x):X = self.embedding(X)X = X.view(-1, n_step * m)tanh = torch.tanh(self.bias + self.hidden1(X))output = self.bias + self.hidden3(X) + self.hidden2(tanh)return output
在该过程中,首先初始化词嵌入层。词嵌入层相当于一个查找表,被索引表示的单词通过词嵌入层,然后再通过第一个隐藏层并与偏置量求和,求和结果传递给tanh函数。最后计算输出,代码如下:
output = self.b + self.hidden3(X) + self.hidden2(tanh)
3)损失函数
这里使用交叉熵损失函数,并将模型输出传递给softmax函数获得单词的概率分布
criterion = nn.CrossEntropyLoss()
4)进行训练
经过训练最终得到单词的编码结果
(2)词向量编码
词向量(Word2vector)模型由Mikolov等人在2013年提出,比Bengio的神经网络语言模型的复杂性更小。词向量模型可以在更大的数据集中训练,但缺点是如果数据较少,就无法像神经网络语言模型那样精确地表征数据。词向量模型包含两种模式:词袋(Bag-of-Words)模型和跳跃(Skip-gram)模型。
词袋模型又称为CBOW模型,它基于目标词前后的n个单词来预测目标单词。假设句子为:“她在踢毽子”,以"毽子"作为目标词,取n=2,那么[正,在,毽,子]等前后单词及目标单词踢将被一起输入给模型。CBOW模型通过计算log2V来降低计算词表中单词分布概率的复杂性,V代表词汇表大小。该模型速度更快,效率更高。

同样的,通过代码来理解CBOW模型,其训练过程如下:
1)定义一个窗口函数,该函数提取目标单词的左右各n个单词
def CBOW(raw_text, window_size=2):data = []for i in range(window_size, len(raw_text) - window_size):context = [raw_text[i - window_size], raw_text[i - (window_size - 1)], raw_text[i + (window_size - 1)], raw_text[i + window_size]]target = raw_text[i]data.append((context, target))return data
上述CBOW函数包含两个输入参数:数据和窗口大小。窗口大小定义了应该从单词左侧和右侧提取多少个单词。for循环首先定义了句子中迭代的开始索引和结束索引,即从句子中的第3个单词开始到倒数第3个单词结束。在循环内部将窗口提取到窗口大小为2,此时窗口提取到的单词为"正" “在” “毽"和"子”,目标单词是"踢",当i=2(窗口大小)时,代码如下:
context = [raw_text[2-2], raw_text[2 - (2-1)], raw_text[i + (2-1)], raw_text[i + 2]]
target = raw_text[2]
执行CBOW函数:
data = CBOW(raw_text)
print(data[0])
上述输出为:
Output:
(["正","在","毽","子"], "踢")
2)构造模型
CBOW模型只包含一个词嵌入层、一个经过ReLU层的隐藏层和一个输出层。代码如下:
class CBOW_Model(torch.nn.Module):def __init__(self, vocab_size, embedding_dim):super(CBOW_Model, self).__init__()self.embeddings = nn.Embbeding(vocab_size, embedding_dim)self.linear1 = nn.Linear(embedding_dim, 128)self.activation_function1 = nn.ReLU()self.linear2 = nn.Linear(128, vocab_size)def forward(self, inputs):embeds = sum(self.embeddings(inputs)).view(1, -1)out = self.linear1(embeds)out = self.activation_function1(out)out = self.linear2(out)return out
该模型非常简单,单词索引输入层嵌入层,之后经过隐藏层,隐藏层输出经过一个非线性层ReLU之后经过输出层得到最终结果。
3)损失函数
与神经网络语言模型一样,采用交叉熵损失函数。优化器选择随机梯度下降,代码如下:
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
4)训练模型
训练代码与神经网络语言模型袋代码一致,具体如下:
for epoch in range(50):total_loss = 0for context, target in data:context_vector = make_context_vector(context, word_to_ix)output = model(context_vector)target = torch.tensor([word_to_ix[target]])total_loss += loss_function(output, target)optimizer.zero_grad()total_loss.backward()optimizer.step()
最终将语句单词转化为数字序列
对比词向量模型,跳跃模型是基于目标单词预测目标单词的上下邻近单词。假设目标单词n=2,同样以句子"她正在踢毽子"为例,单词"踢"将被输入模型用于预测目标单词(“正”,“在”,“毽”,“子”)。其结构如下图:

跳跃模型与词袋模型类似,不同点在于创建上下文和目标单词。
相比词袋模型,跳跃模型增加了计算的复杂度,因为它必须根据一定数量的相邻单词来预测邻近单词。在实际的语句中,距离较远的单词相关性往往比较差
(3)全局词向量表示
全局词向量表示(Global Vectors for Word Representation,GloVe)是一种基于全局信息来获得词向量的方法。该方法使用了语料库的全局统计特征,也使用了局部的上下文特征,GloVe通过引入共现矩阵(Co-occurrence Probabilities Matrix)来表征。
定义词到词的共现矩阵为X,Xij代表单词j出现在单词i的上下文的次数,Xi表示出现在单词i的上下文的词的总数。Pij = P(j|i) = Xij/Xi表示单词j出现在单词i的上下文中的概率。
定义词i、j与词k的共现概率为P = Pik / Pjk,词与词之间的关系可以通过共现概率体现,即如果词k与词i相近,与词j较远,则希望Pik / Pjk越大越好,如果词k与词j相近,与词i较远,则希望Pik / Pjk越小越好,如果词k与词i和词j都相近或都较远,则Pik / Pjk趋近于1
共现概率既很好地区分了相关词和不相关词,又反映了相关词的关联程度。GloVe模型就是基于该共现概率的信息构建的,其核心目标是为了每一个词生成一个词向量,这样词向量就能映射出词与词之间的共现概率,以此捕捉它们的语义关系。假设定义GloVe模型为F,则上述共现概率可以使用如下公式来表示:
F(wi, wj, wk) = Pik / Pjk
其中,w 代表词向量
综上,单词词嵌入编码方法的特点如下:
- 神经网络语言模型的性能优于早期的统计模型
- 神经网络语言模型解决了维度灾难问题,并通过其分布式表示保留了上下文语义和句法属性,但计算成本很高
- 词向量模型降低了计算复杂性,比神经网络语言模型效率更高,它可以在大量数据上进行训练,用高维向量表示
- 词向量模型有两种:词袋模型和跳跃模型。前者比后者运算更快
- GloVe纳入了全局信息但无法解决一词多义和陌生词问题
2. 位置编码
位置编码(Position Embedding)用来表示句子中单词的位置,且每个位置被赋予唯一的表示。位置编码要满足以下特点:
- 编码值可以表示单词在句子中的绝对位置,且是有界的
- 句子长度不一致时单词间的相对位置距离也要保持一致
- 可以表示从未见过的句子长度
Transformer使用正余弦函数来进行位置编码。其公式如下:
PE(pos, 2i) = sin(pos/10000^2i/d model)PE(pos, 2i+1) = cos(pos/10000^2i/d model)
其中,pos表示单词在句子中的位置,d表示PE的维度(与单词编码一样),2i表示偶数的维度,2i+1表示奇数维度(即2i<=d, 2i+1 <=d)。使用这种公式计算PE有以下的好处:
- 能够适应比训练集中所有句子更长的句子。假设训练集中最长的句子有20个单词,此时有一个长度为21的句子,则使用公式计算的方法可以计算出第21位的编码
- 能够较容易地计算出相对位置。对于固定长度的间距k,PE(pos+k)可以用PE(pos)计算得到
接下来通过代码来理解位置编码
import numpy as np
import matplotlib.pyplot as plt
def getPositionEncoding(seq_len, d, n=10000):P = np.zeros((seq_len, d))for k in range(seq_len):for i in np.arange(int(d/2)):denominator = np.power(n, 2*i/d)P[k, 2*i] = np.sin(k/denominator)P[k, 2*i+1] = np.cos(k/denominator)return PP = getPositionEncoding(seq_len=4, d=4, n=100)print(P)[
[0. 1. 0. 1. ]
[0.84147098 0.54030231 0.09983342 0.99500417]
[0.90929743 -0.41614684 0.19866933 0.98006658]
[0.14112001 -0.9899925. 0.29552021 0.95533649]
]
看一下n=10000和d=512的不同位置正弦曲线
def plotSinusoid(k, d=512, n=10000):x = np,arange(0, 100, 1)denominator = np.power(n, 2*x/d)y = np.sin(k/denominator)plt.plot(x, y)plt.title('k = ' + str(k))
fig = plt.figure(figsize=(15, 4))
for i in range(4):plt.subplot(141 + i)plotSinusoid(i*4)
每个位置k对应于不同位置的正弦曲线,它将位置编码为向量。
即正弦曲线的波长形成几何级数,并且变化范围为2pai到2pai n,该方案的优点如下:
- 正弦和余弦函数的值在[-1, 1]范围内,即编码值是有界的
- 由于每个位置的正弦曲线不同,因此可以采用独特的方式对每个位置进行编码,即每个位置的编码都是唯一的
- 基于正弦变化可以测量或量化不同位置之间的相似性,从而能够对单词的相对位置进行编码
进一步,通过Matplotlib来可视化位置矩阵
P = getPositionEncoding(seq_len=100, d=512, n=10000)
cat = plt.matshow(P)
plt.gcf().colorbar(cax)
综上,将整个句子所有单词的位置编码向量与单词编码向量相加得到输出矩阵,整个流程如下图:

2.1.2 编码器
编码器由多头注意力、加法和归一化、前馈层组成

1. 多头注意力
在介绍多头注意力之前,首先介绍一下自注意力
自注意力是机器学习使用的一种学习机制,属于仿生学的一种应用,即人类会把注意力放在重点关注的信息上。在自然语言处理任务中,自注意力用于捕获输入序列内的依赖性和关系,让模型通过关注自身来识别和权衡输入序列不同部分的重要性。在编码器中,自注意力的输入参数有三个:查询(query)、键(key)、值(value)
这三个参数在结构上很相似,都是被参数化的向量。每个单词的词嵌入向量都由这三个矩阵向量来表征,帮助计算机理解和处理句子中单词之间的关系。这三个矩阵向量的作用各不相同。
1)查询
该矩阵表示正在评估其上下文的目标单词。系统通过使用查询矩阵转换该目标单词的表示形式,生成一个查询向量。此查询向量用于衡量其与句子中其他单词的关联度
2)键
该矩阵用于生成句子中每个单词对应的键向量。通过对每个键向量和目标单词的查询向量进行比较,计算得出目标单词与句子中其他词之间的相关性。查询向量和关键向量之间的相似度分数越高,表示相应单词之间的关系越紧密
3)值
该矩阵用于生成句子中所有单词的值向量,这些向量保存每个单词的上下文信息。使用查询向量和键向量计算相似度分数后,系统计算值向量的加权和。每个值向量的权重由相似度分数确定,确保最终的上下文表示更多地受到相关单词的影响
如下图所示,语句中单词"一"的查询矩阵向量q3与所有词的键矩阵向量k进行计算,得到注意力得分y31、y32、y33、y34。之后分别与自身的值矩阵向量做乘积,得到每个词抽取信息完毕的向量,最后所有向量求和得到z3,即为单词"一"经过注意力后的结果

Transformer中的自注意力使用的是多头注意力,即通过组合多个类似的注意力计算给予了Transformer更大的辨别能力。多头注意力结构如下:

在多头注意力中,查询、键和值分别通过单独的线性层,每个层都有自己的权重,产生三个结果,分别称为Q、K、V。然后在缩放点积注意力中基于注意力公式进行组合运算。
在上述过程中,Q、K、V携带了序列中每个单词的编码表示,之后注意力计算将每个单词与序列中的其他单词结合起来,以便注意力分数对序列中每个单词的分数进行编码。在该过程中提到了掩码。由于输入的序列可能具有不同的长度,因此需要使用填充标记对句子进行扩展对齐长度,以便可以将固定的向量输入Transformer中,这里的掩码主要是为了填充部分的注意力输出为0,确保填充标记不会对注意力分数产生影响。
2. 加法和归一化
加法过程是一种残差机制,主要为了解决深层神经网络训练过程的不稳定性,即深度神经网络随着层数的增加,损失逐渐减小然后趋于稳定,继续增加层数损失反而增大的现象。简单来说就是用来防止梯度消失。
归一化用来归一化参数,加快训练速度,提高训练的稳定性。
3. 前馈层
前馈层作为注意力层后面的子层,由两个线性层或致密层构成。第一层的大小为(d_model, d_ffn),第二层的大小为(d_ffn,d_model)。
通过以下代码来理解这个过程
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model: int, d_ffn: int, dropout: float = 0.1):"""Args:d_model: dimension of embeddingsd_ffn: dimension of feed-forward networkdropout: probablity of dropout occurring"""super().__init__()self.w_1 = nn.Linear(d_model, d_ffn)self.w_2 = nn.Linear(d_ffn, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):"""Args:x: output from attention (batch_size, seq_length, d_model)Returns:expanded-and-contracted representation (batch_size, seq_length, d_model)"""return self.w_2(self.dropout(self.w_1(x).relu()))2.1.3 解码器
解码器也由多头注意力、加法和归一化、前馈层组成,每个解码器包含两层多头注意力,这两个多头注意力与编码器中的多头注意力作用不同。

1. 掩码多头注意力
掩码多头注意力与编码器不一致的地方在于掩盖的步骤,此处的掩码过程主要为了防止解码器在预测下一个单词时"偷看"目标语句的其余部分
2. 多头注意力
解码器中的多头注意力与编码器中的主要区别在于,它的K、V矩阵不是基于上一个解码器的输出计算而来的,而是来自编码器的输入,但Q矩阵还是根据解码器的输出计算得到的。计算过程与编码器中的一样,掩码步骤也与编码器的一致
2.1.4 解码头
解码器将输出传递给解码头,解码头将接收到的解码器输出向量映射为单词分数。词库中的每个单词在句子中的每个位置都会有一个分数。假设最终输出的句子有4个词,词库中有1000个词,那么在这4个词的每个位置都会生成1000个分数,这些分数代表词库中每个词出现在句子中每个位置的可能性。之后这些分数将送入softmax层,softmax将这些分数转换为概率(加起来为1.0)。在每个位置上,找到概率最高的单词的索引,然后将该索引映射到词汇表中相应的单词。最后,这些单词形成Transformer的输出序列。
相关文章:
【RAG实战】语言模型基础
语言模型赋予了计算机理解和生成人类语言的能力。它结合了统计学原理和深度神经网络技术,通过对大量的样本数据进行复杂的概率分布分析来学习语言结构的内在模式和相关性。具体地,语言模型可根据上下文中已出现的词序列,使用概率推断来预测接…...

【MySQL】7.0 入门学习(七)——MySQL基本指令:帮助、清除输入、查询等
1.0 help ? 帮助指令,查询某个指令的解释、用法、说明等。详情参考博文: 【数据库】6.0 MySQL入门学习(六)——MySQL启动与停止、官方手册、文档查询 https://www.cnblogs.com/xiaofu007/p/10301005.html 2.0 在cmd命…...

我的 2024 年终总结
2024 年,我离开了待了两年的互联网公司,来到了一家聚焦教育机器人和激光切割机的公司,没错,是一家硬件公司,从未接触过的领域,但这还不是我今年最重要的里程碑事件 5 月份的时候,正式提出了离职…...

STM32CUBEMX+STM32H743ZIT6+IAP+UART在线升级初始化和代码解析
1、STM32H7带的ITCM,DTCM,AXI SRAM,SRAM1,SRAM2,SRAM3,SRAM4和备份SRAM五块。 其中, ①TCM区包括ITCM和DTCM,这两个是直连CPU的。 速率与CPU一致,最高能到480MHz。 DTCM地…...

半连接转内连接 | OceanBase SQL 查询改写
查询优化器是关系型数据库系统的核心模块,是数据库内核开发的重点和难点,也是衡量整个数据库系统成熟度的“试金石”。为了帮助大家更好地理解 OceanBase 查询优化器,我们撰写了查询改写系列文章,带大家更好地掌握查询改写的精髓&…...

Git使用经历
目录 1、先创建文件夹 2、仓库初始化 3、配置gitee用户名和密码 4、克隆指定仓库的中指定分支到本地仓库 5、查看当前所在分支、切换分支 6、查看状态,判断是否有修改 7、把更新的内容添加到缓存区 8、把缓存区的数据提交 9、把数据推送到远程仓库 10、把…...
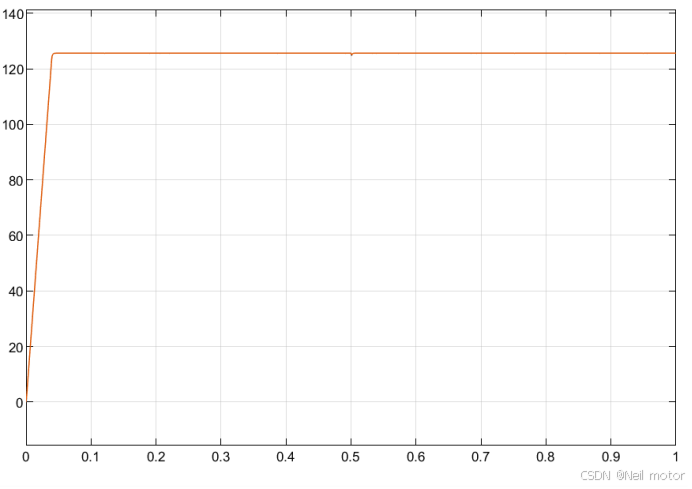
永磁同步电机控制算法-自适应带宽LADRC转速控制器
一、原理介绍 设计了自适应带宽 LADRC 控制方法,继承了 LADRC 优点的同时,加入自适应带宽控制,提出运用 Softsign 函数设计带宽自适应函数,根据电机转速自动调节控制带宽,解决了永磁同步电机在复杂且多变的环境下受到…...

基于springboot+vue实现的博物馆游客预约系统 (源码+L文+ppt)4-127
摘 要 旅游行业的快速发展使得博物馆游客预约系统成为了一个必不可少的工具。基于Java的博物馆游客预约系统旨在提供高效、准确和便捷的适用博物馆游客预约服务。本文讲述了基于java语言开发,后台数据库选择MySQL进行数据的存储。该软件的主要功能是进行博物馆游客…...
 - 清晰题解)
LeetCode 1705.吃苹果的最大数目:贪心(优先队列) - 清晰题解
【LetMeFly】1705.吃苹果的最大数目:贪心(优先队列) - 清晰题解 力扣题目链接:https://leetcode.cn/problems/maximum-number-of-eaten-apples/ 有一棵特殊的苹果树,一连 n 天,每天都可以长出若干个苹果。在第 i 天,…...

vim多窗格
vim打开文件分为三个阶段:buffer、window与tab buffer就是在同一个界面打开的文件window就是使用水平分割与垂直分割的窗口tab则是可以是上述两者的总集合 buffer :e filename在已打开文件的界面中再打开一个新文件,显示这个新文件,原文件被隐…...

ubuntu paddle ocr 部署bug问题解决
ubuntu paddle ocr 部署会出现异常报错。 尝试安装以下版本: pip install paddlepaddle2.5.2 -i https://pypi.tuna.tsinghua.edu.cn/simpl 助力快速掌握数据集的信息和使用方式。 数据可以如此美好!...

OpenFeign快速入门 示例:黑马商城
使用起因 之前我们利用了Nacos实现了服务的治理,利用RestTemplate实现了服务的远程调用。这样一来购物车虽然通过远程调用实现了调用商品服务的方法,但是远程调用的代码太复杂了: 解决方法 并且这种调用方式比较复杂,一会儿远程调用,一会儿本地调用。 因…...

【C++】ceil 和 floor 函数的实现与分析
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C 文章目录 💯前言💯ceil 和 floor 函数的基础介绍1. ceil 函数定义与功能示例代码输出结果功能分析使用场景 2. floor 函数定义与功能示例代码输出结果功能分析使用场景 💯自行实现…...

zabbix监控山石系列Hillstone配置模版(适用于zabbix6及以上)
监控项: 触发器: 监控数据:...

在瑞芯微RK3588平台上使用RKNN部署YOLOv8Pose模型的C++实战指南
在人工智能和计算机视觉领域,人体姿态估计是一项极具挑战性的任务,它对于理解人类行为、增强人机交互等方面具有重要意义。YOLOv8Pose作为YOLO系列中的新成员,以其高效和准确性在人体姿态估计任务中脱颖而出。本文将详细介绍如何在瑞芯微RK3588平台上,使用RKNN(Rockchip N…...

CTFHub disable_functions通关
LD_PRELOAD 来到首页发现有一句话直接就可以用蚁剑连接 根目录里有/flag但是不能看;命令也被ban了就需要绕过了 绕过工具在插件市场就可以下载 如果进不去的话 项目地址: #本地仓库;插件存放 antSword\antData\plugins 绕过选择 上传后我们点进去可以看到多了一个绕过的文件;…...
Chromium GN 目标指南 - view_example 计数器示例 (七)
1. 引言 在前面的文章中,我们学习了如何在 views_examples 中添加自定义 Button 示例。在本篇文章中,我们将继续探索 Views 框架的应用,创建一个简单的计数器示例,以学习如何使用 Label 和 Button 控件进行交互,以及如…...

一步一步写线程之十六线程的安全退出之二例程
一、说明 在一篇分析了多线程的安全退出的相关机制和方式,那么本篇就针对前一篇的相关的分析进行举例分析。因为有些方法实现的方法类似,可能就不一一重复列举了,相关的例程主要以在Linux上的运行为主。 二、实例 线程间的同步,…...

【Linux系列】Shell 脚本中的条件判断:`[ ]`与`[[ ]]`的比较
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

ArcGIS+MIKE21 洪水淹没分析、溃坝分析,洪水淹没动态效果
洪水淹没分析过程: 一、所需数据: 1.分析区域DEM数据 二、ArcGIS软件 1.提取分析区域DEM(水库坝下区域) 2.DEM栅格转点 3.计算转换后几何点的x和y坐标值(精度20、小数位3) 4.导出属性表,形式…...

2026年全域聚合支付前景如何?一文揭秘!
在数字经济蓬勃发展的当下,全域聚合支付作为支付领域的重要创新模式,正深刻改变着我们的生活和商业运营方式。那么,2026年全域聚合支付的前景究竟怎样呢?让我们以财联支付为例,来深入探究一番。一、市场需求持续增长&a…...

免费AI视频生成工具技术解析与功能对比
AI视频生成技术在2026年取得了显著进展,从早期的简单动画到如今的高质量视频输出,底层技术架构经历了多次迭代。本文将从技术角度解析当前主流免费AI视频生成工具的技术原理、架构特点和功能参数,为开发者和技术从业者提供参考。AI视频生成技…...

AUTOSAR SoAd配置避坑指南:TCP/UDP模式、自动启动与Fanout发送的那些‘坑’
AUTOSAR SoAd实战避坑手册:从TCP连接异常到Fanout发送失效的深度解析 车载以太网通信作为智能汽车的中枢神经系统,其稳定性直接关系到整车功能的可靠性。在AUTOSAR架构中,SoAd模块作为TCP/IP协议栈与上层应用之间的桥梁,其配置复杂…...

OpenClaw智能截图工具:Qwen3-14b_int4_awq自动识别图片内容并分类保存
OpenClaw智能截图工具:Qwen3-14b_int4_awq自动识别图片内容并分类保存 1. 为什么需要智能截图工具? 作为一名经常需要收集研究资料的技术博主,我长期被一个问题困扰:每次截取大量图片后,总需要手动整理、重命名和分类…...
)
手把手教你用Vivado为Microblaze软核搭建Linux最小系统(含DDR3、UART、以太网配置)
从零构建Microblaze软核Linux硬件系统:Vivado实战指南 在FPGA上运行Linux系统一直是嵌入式开发者的进阶挑战,而Xilinx的Microblaze软核处理器为这一目标提供了灵活高效的解决方案。不同于传统ARM架构的固定硬件,Microblaze允许开发者根据项目…...

DeepSeek-OCR-2部署教程:如何在多卡服务器上分配显存并行处理批量文档
DeepSeek-OCR-2部署教程:如何在多卡服务器上分配显存并行处理批量文档 1. 项目概述 DeepSeek-OCR-2是一个基于多模态视觉大模型的智能文档解析系统,能够将图像中的文档内容转换为结构化的Markdown格式。与传统OCR技术相比,它不仅能够识别文…...

PLC立体车库智能仿真系统:博途V15 3×2车库模型,西门子PLC控制,触摸屏操作,自动出入...
PLC立体车库智能仿真 博途V15 32立体车库 西门子1200PLC 触摸屏仿真 不需要实物 自带人机界面 小车上下行有电梯效果 每一个程序段都有注释 FC块标准化编写 自带变频器输出也可以仿真 现在拥有自动出入仓库的功能 IO表已列出最近在搞的32立体车库仿真项目挺有意思,用…...

OpenClaw文件管理机器人:千问3.5-9B智能归类200+技术文档
OpenClaw文件管理机器人:千问3.5-9B智能归类200技术文档 1. 为什么需要文件管理机器人 我的下载文件夹已经变成了一个数字黑洞——里面堆积着超过200份未分类的技术文档,包括PDF白皮书、Markdown笔记、代码片段和会议录音。每次寻找特定文件都需要在混…...

OpenClaw隐私保护:Qwen3.5-9B本地处理敏感数据的实践
OpenClaw隐私保护:Qwen3.5-9B本地处理敏感数据的实践 1. 为什么需要本地化处理敏感数据? 去年我在处理一批客户调研报告时,曾遇到一个尴尬场景:当我把包含联系方式和消费习惯的Excel表格上传到某云端AI分析平台后,突…...

Lixie数码管驱动库深度解析:WS2812B嵌入式显示控制实践
1. Lixie 数码管驱动库技术解析:面向嵌入式工程师的深度实践指南Lixie 是一款专为驱动“Lixie 边缘导光数码管”(Edge-Lit Digit Display)设计的 Arduino 兼容库。它并非传统真空管或七段 LED,而是一种融合光学设计与现代 LED 控制…...