YOLOv9-0.1部分代码阅读笔记-metrics.py
metrics.py
utils\metrics.py
目录
metrics.py
1.所需的库和模块
2.def fitness(x):
3.def smooth(y, f=0.05):
4.def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16, prefix=""):
5.def compute_ap(recall, precision):
6.class ConfusionMatrix:
7.class WIoU_Scale:
8.def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, MDPIoU=False, feat_h=640, feat_w=640, eps=1e-7):
9.def box_iou(box1, box2, eps=1e-7):
10.def bbox_ioa(box1, box2, eps=1e-7):
11.def wh_iou(wh1, wh2, eps=1e-7):
12.def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=()):
13.def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric'):
1.所需的库和模块
import math
import warnings
from pathlib import Pathimport matplotlib.pyplot as plt
import numpy as np
import torchfrom utils import TryExcept, threaded2.def fitness(x):
# 这段代码定义了一个名为 fitness 的函数,它计算模型的适应度,作为一系列度量指标的加权组合。这在机器学习模型的选择和超参数优化中是一个常见的做法。
# 定义了一个名为 fitness 的函数,它接受一个参数。
# 1.x :这个参数是一个二维数组或张量,其中每一行包含模型的不同度量指标。
def fitness(x):# Model fitness as a weighted combination of metrics 模型适应度作为指标的加权组合。# 定义了一个权重列表 w ,用于对不同的度量指标进行加权。这里的权重对应于以下度量指标 :# P :精确度(Precision)。# R :召回率(Recall)。# mAP@0.5 :在 IoU 阈值为 0.5 时的平均精度均值(Mean Average Precision)。# mAP@0.5:0.95 :在 IoU 阈值从 0.5 到 0.95 范围内的平均精度均值。w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]# 计算适应度 :# x[:, :4] :选择 x 的前四列,即前四个度量指标。# * w :将这四个度量指标与对应的权重相乘。# .sum(1) :沿着第一维(即行)求和,得到每个模型的适应度得分。# 返回值。函数返回一个包含每个模型适应度得分的数组。return (x[:, :4] * w).sum(1)
# fitness 函数提供了一种简单的方式来计算模型的适应度,通过将不同的度量指标组合成一个单一的得分。这种方法可以帮助在模型选择和超参数优化过程中评估和比较不同模型的性能。通过调整权重,可以控制不同度量指标对适应度得分的影响。3.def smooth(y, f=0.05):
# 这段代码定义了一个名为 smooth 的函数,它用于平滑一个数值数组 y 。这个函数使用了一种称为“Box滤波器”或“均值滤波器”的方法来平滑数据。
# 定义了一个名为 smooth 的函数,它接受两个参数。
# 1.y :要平滑的数据数组。
# 2.f :一个可选参数,默认值为0.05,表示滤波器的宽度占数据长度的比例。
def smooth(y, f=0.05):# Box filter of fraction f# 计算滤波器的元素数量。由于滤波器必须是奇数个元素,所以计算结果向上取整到最近的奇数。nf = round(len(y) * f * 2) // 2 + 1 # number of filter elements (must be odd)# 创建一个长度为 nf // 2 的数组,所有元素都是1。这个数组将用于在原始数据 y 的两端进行填充。p = np.ones(nf // 2) # ones padding# 将填充数组乘以 y 的第一个元素和最后一个元素,然后将它们与原始数组 y 连接起来,形成一个新的数组 yp 。这样做的目的是防止在边缘处的平滑效果不佳。yp = np.concatenate((p * y[0], y, p * y[-1]), 0) # y padded# numpy.convolve(in1, in2, mode='full', method='auto')# np.convolve 是 NumPy 库中的一个函数,用于执行一维卷积。卷积是一种数学运算,它将两个函数(信号)结合起来产生第三个函数,这个函数表达了一个函数的形状如何被另一个函数修改。在信号处理和图像处理中,卷积是一种常见的操作,用于平滑数据、滤波、边缘检测等。# 参数说明 :# in1 :第一个输入数组。# in2 :第二个输入数组,通常称为卷积核或滤波器。# mode :字符串,指定输出的类型。可以是以下几种之一 :# 'full' :返回完整的卷积结果,输出长度为 len(in1) + len(in2) - 1 。# 'valid' :返回只有完全包含两个输入数组部分的输出,输出长度为 len(in1) + len(in2) - 2 ,如果 in1 和 in2 长度相等,则输出长度为 len(in1) - 1 。# 'same' :返回输出结果,长度与 in1 相同。# method :字符串,指定计算卷积的方法。可以是以下几种之一 :# 'auto' :自动选择最快的方法。# 'direct' :直接计算(直接方法)。# 'fft' :使用快速傅里叶变换(FFT)计算卷积。# 返回值 :# 函数返回一个新的数组,该数组是输入数组 in1 和 in2 的卷积结果。# 使用 np.convolve 函数来对 yp 进行卷积操作,使用一个长度为 nf 、所有元素都为1的数组作为滤波器,并且每个元素都除以 nf ,以确保滤波器的总和为1。 mode='valid' 表示只返回卷积结果中完全由输入数组覆盖的部分。return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothed
# 这个函数的目的是减少数据中的噪声,使得数据更加平滑。它通过计算每个点周围一定范围内的平均值来实现这一点。这种方法简单且计算效率高,但可能会模糊数据中的一些细节。4.def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16, prefix=""):
# 这段代码定义了一个名为 ap_per_class 的函数,用于计算每个类别的平均精度(AP)并绘制相关的曲线图。
# 定义了 ap_per_class 函数,它接受以下参数 :
# 1.tp :真阳性(True Positives)数组。
# 2.conf :置信度(confidence)数组。
# 3.pred_cls :预测类别(predicted class)数组。
# 4.target_cls :目标类别(target class)数组。
# 5.plot :是否绘制曲线图,默认为 False 。
# 6.save_dir :保存图像的目录,默认为当前目录。
# 7.names :类别名称的字典或元组,默认为空。
# 8.eps :用于数值稳定性的小值,默认为 1e-16 。
# 9.prefix :保存图像时的前缀,默认为空字符串。
def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16, prefix=""):# 计算平均精度,给定召回率和准确率曲线。""" Compute the average precision, given the recall and precision curves.Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.# Argumentstp: True positives (nparray, nx1 or nx10).conf: Objectness value from 0-1 (nparray).pred_cls: Predicted object classes (nparray).target_cls: True object classes (nparray).plot: Plot precision-recall curve at mAP@0.5save_dir: Plot save directory# ReturnsThe average precision as computed in py-faster-rcnn."""# Sort by objectness# 根据置信度降序排序索引。i = np.argsort(-conf)# 根据排序后的索引重新排列 tp 、 conf 和 pred_cls 。tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]# Find unique classes# 找到目标类别中的唯一类别及其计数。# unique_classes :这是一个数组,包含了 target_cls 中的所有唯一类别标签。# nt :这是一个数组,包含了 unique_classes 中每个类别在 target_cls 中出现的次数。unique_classes, nt = np.unique(target_cls, return_counts=True)# 计算类别数量。nc = unique_classes.shape[0] # number of classes, number of detections# 这段代码是 ap_per_class 函数中的一部分,它负责计算每个类别的精确度(Precision)、召回率(Recall)和平均精度(AP)。# Create Precision-Recall curve and compute AP for each class 创建精确度-召回率曲线并计算每个类别的 AP 。# 创建一个从0到1的1000个点的数组 px ,用于绘制精确度-召回率曲线。 py 是一个空列表,用于存储每个类别在不同召回率水平下的精确度值,以便后续绘制曲线。px, py = np.linspace(0, 1, 1000), [] # for plotting# 初始化三个数组,分别用于存储每个类别的 平均精度 ( AP ) 、 精确度 ( P ) 和 召回率 ( R )。 nc 是类别的数量, tp.shape[1] 是度量的数量(例如,不同的IoU阈值)。ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))# 遍历每个唯一的类别 c 。for ci, c in enumerate(unique_classes):# 找到预测类别等于当前类别 c 的索引。i = pred_cls == c# 计算当前类别 c 的 标签数量 。 nt[ci] 表示 nt 数组中索引为 ci 的元素,即类别 c 的出现次数。n_l = nt[ci] # number of labels# 计算当前类别 c 的 预测数量 。n_p = i.sum() # number of predictions# 如果当前类别的 预测数量 或 标签数量 为0,则跳过当前类别的处理。if n_p == 0 or n_l == 0:continue# Accumulate FPs and TPs# np.cumsum(a, axis=None, dtype=None, out=None, *, where=True)# np.cumsum() 是 NumPy 库中的一个函数,用于计算沿指定轴的元素累积和(cumulative sum)。这个函数会返回一个新的数组,其中每个元素是原始数组中该位置及之前所有元素的和。# 参数说明 :# a :输入数组。# axis :沿哪个轴计算累积和。如果为 None ,则数组会被展平后再计算累积和。默认为 None 。# dtype :输出数组的类型。如果没有指定,则输出数组的类型与输入数组的类型相同。# out :输出数组。如果指定,则计算结果会被存储在这个数组中。# where :布尔数组,与 a 形状相同,用于选择性地计算累积和。只有在 a 的相应位置为 True 时,才会在该位置计算累积和。# 返回值 :# 累积和数组,与输入数组 a 形状相同,但数据类型可能不同,取决于 dtype 参数。# 计算假阳性(False Positives, FP)的累积和。fpc = (1 - tp[i]).cumsum(0)# 计算真阳性(True Positives, TP)的累积和。tpc = tp[i].cumsum(0)# Recall# 计算 召回率曲线 , eps 是一个很小的数,用于防止除以零。recall = tpc / (n_l + eps) # recall curve# 使用插值计算在不同置信度水平下的 召回率 , -px 和 -conf[i] 表示置信度是降序的。r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases# Precision# 计算精确度曲线。precision = tpc / (tpc + fpc) # precision curve# 使用插值计算在不同置信度水平下的 精确度 。p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score# AP from recall-precision curve# 遍历每个度量(例如,不同的IoU阈值)。for j in range(tp.shape[1]):# 计算当前类别和度量的 平均精度 (AP),并返回 精确度 和 召回率曲线 。# def compute_ap(recall, precision): -> 用于计算平均精度(AP)。返回计算的 平均精度 ( AP ) 以及 精确度 和 召回率的上包络 。 -> return ap, mpre, mrecap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])# 如果设置了绘图选项,并且当前是第一个度量(通常是IoU=0.5),则执行以下操作。if plot and j == 0:# 在 px 的召回率水平上插值,得到对应的精确度值,并添加到 py 列表中,用于后续绘制精确度-召回率曲线。py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5# 这段代码负责计算每个类别的精确度、召回率和平均精度,并在设置了绘图选项的情况下,为绘制精确度-召回率曲线准备数据。通过遍历每个类别和度量,它使用累积和和插值方法来计算精确度和召回率,然后计算AP。# 这段代码是 ap_per_class 函数的后半部分,它负责计算 F1 分数,并根据需要绘制相关的曲线图。# Compute F1 (harmonic mean of precision and recall)# 计算 F1 分数,它是精确度(p)和召回率(r)的调和平均值。 eps 是一个很小的数,用于防止除以零。f1 = 2 * p * r / (p + r + eps)# 如果 names 是一个字典,这行代码会筛选出 unique_classes 中存在的类别的名称。names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data# 将筛选后的名称列表转换为一个从 0 开始的索引到类别名称的字典。names = dict(enumerate(names)) # to dict# 如果设置了绘图选项,则执行以下操作。if plot:# 绘制精确度-召回率曲线,并保存为 PNG 文件。plot_pr_curve(px, py, ap, Path(save_dir) / f'{prefix}PR_curve.png', names)# 绘制 F1 分数曲线,并保存为 PNG 文件。plot_mc_curve(px, f1, Path(save_dir) / f'{prefix}F1_curve.png', names, ylabel='F1')# 绘制精确度曲线,并保存为 PNG 文件。plot_mc_curve(px, p, Path(save_dir) / f'{prefix}P_curve.png', names, ylabel='Precision')# 绘制召回率曲线,并保存为 PNG 文件。plot_mc_curve(px, r, Path(save_dir) / f'{prefix}R_curve.png', names, ylabel='Recall')# 对 F1 分数的平均值进行平滑处理,并找到平滑后 F1 分数最大的索引。# def smooth(y, f=0.05): -> 用于平滑一个数值数组 y 。只返回卷积结果中完全由输入数组覆盖的部分。 -> return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothedi = smooth(f1.mean(0), 0.1).argmax() # max F1 index# 选择 F1 分数最大的列,用于后续计算。p, r, f1 = p[:, i], r[:, i], f1[:, i]# 计算真阳性(True Positives)的数量,即召回率乘以每个类别的标签数量。tp = (r * nt).round() # true positives# 计算假阳性(False Positives)的数量,即真阳性除以精确度减去真阳性。fp = (tp / (p + eps) - tp).round() # false positives# 返回计算结果,包括 真阳性tp 、 假阳性fp 、 精确度p 、 召回率r 、 F1 分数f1 、 平均精度ap 和 类别索引unique_classes.astype(int) 。return tp, fp, p, r, f1, ap, unique_classes.astype(int)# 这段代码负责计算 F1 分数,并根据设置的绘图选项绘制相关的曲线图。它还计算真阳性和假阳性的数量,并返回所有计算结果。通过平滑 F1 分数的平均值,它能够找到最有代表性的 F1 分数,并据此选择精确度和召回率的值。
# 这个函数 ap_per_class 用于计算每个类别的AP,并根据需要绘制相关的曲线图。它首先根据置信度对预测进行排序,然后计算每个类别的精确度、召回率和F1分数,并计算AP。如果设置了 plot 参数,它还会绘制精确度-召回率曲线、F1曲线和精确度曲线。最后,它返回计算的统计数据和类别信息。5.def compute_ap(recall, precision):
# 这段代码定义了一个名为 compute_ap 的函数,用于计算平均精度(AP)。平均精度是信息检索和计算机视觉领域中常用的性能指标,特别是在目标检测任务中。
# 定义了 compute_ap 函数,它接受两个参数。
# 1.recall :召回率数组。
# 2.precision :精确度数组。
def compute_ap(recall, precision):# 根据召回率和准确率曲线计算平均准确率。""" Compute the average precision, given the recall and precision curves# Argumentsrecall: The recall curve (list)precision: The precision curve (list)# ReturnsAverage precision, precision curve, recall curve"""# Append sentinel values to beginning and end# 将 0.0 和 1.0 作为哨兵值分别添加到 召回率 数组的开始和结束,以便计算整个召回率范围的AP。mrec = np.concatenate(([0.0], recall, [1.0]))# 将 1.0 和 0.0 作为哨兵值分别添加到 精确度 数组的开始和结束,以便计算整个精确度范围的AP。mpre = np.concatenate(([1.0], precision, [0.0]))# Compute the precision envelope# numpy.maximum.accumulate(array, axis=None, dtype=None)# np.maximum.accumulate() 是 NumPy 库中的一个函数,它沿着指定的轴计算输入数组元素的最大累积值。这个函数返回一个新的数组,其中每个元素是输入数组中直到该位置的元素的最大值。# 参数说明 :# array :输入的数组。# axis :沿哪个轴计算最大累积值。如果为 None ,则计算扁平化后的数组的最大累积值。# dtype :输出数组的数据类型。如果为 None ,则数据类型与输入数组相同。# 返回值 :# 返回一个新的数组,其中每个元素是输入数组中直到该位置的元素的最大值。# 计算精确度的上包络。首先翻转 mpre 数组,然后计算累积最大值,最后再次翻转结果,得到精确度的上包络。mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))# Integrate area under curve# 设置积分方法为 插值 ( 'interp' ),另一种方法是 连续 ( 'continuous' )。method = 'interp' # methods: 'continuous', 'interp'# 如果选择插值方法,则执行以下操作。if method == 'interp':# 创建一个从0到1的101个点的数组,用于插值。x = np.linspace(0, 1, 101) # 101-point interp (COCO)# numpy.trapz(y, x=None, dx=1.0, axis=-1)# np.trapz 是 NumPy 库中的一个函数,用于使用梯形规则计算数值积分。这个函数可以近似计算函数的定积分,即曲线下的面积,通过将区间划分为多个小梯形并计算它们的面积之和。# 参数说明 :# y :待积分的函数值数组。# x :对应于 y 中的函数值的点,如果为 None ,则假定 y 中的点均匀分布在 [0, n] 区间内,其中 n 是 y 的长度。# dx : x 轴上每对相邻点之间的间隔,默认为 1.0 。# axis :沿哪个轴进行积分,默认为 -1 ,即最后一个轴。# 返回值 :# 返回沿指定轴的积分结果。# 使用插值计算AP, np.interp 用于在 mrec 和 mpre 之间进行插值, np.trapz 用于计算梯形积分。ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate# 如果选择连续方法,则执行以下操作。else: # 'continuous'# numpy.where(condition, [x, y])# np.where 是 NumPy 库中的一个函数,它返回输入条件为真的元素的索引。这个函数可以用于查找满足特定条件的数组元素的位置,类似于 Python 内置的 filter 函数,但它返回的是元素的索引而不是元素本身。# 参数说明 :# condition :一个布尔数组,表示要检查的条件。# x 和 y :可选参数,用于指定当条件为真和为假时分别返回的值。如果未提供 x 和 y ,则只返回条件为真的元素的索引。# 返回值 :# 如果没有提供 x 和 y ,则返回一个元组,其中包含满足条件的元素的索引数组。# 如果提供了 x 和 y ,则返回一个元组,其中包含两个数组 :第一个数组包含条件为真的位置的 x 值,第二个数组包含条件为假的位置的 y 值。# 找到召回率数组中值变化的索引。i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes# 计算召回率变化点之间的面积,即AP。ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve# 返回计算的 平均精度 ( AP ) 以及 精确度 和 召回率的上包络 。return ap, mpre, mrec
# 这个函数 compute_ap 用于计算给定召回率和精确度曲线的平均精度(AP)。它通过添加哨兵值、计算精确度的上包络、选择积分方法(插值或连续),并计算梯形积分来实现。最终返回计算得到的AP值,以及精确度和召回率的上包络。6.class ConfusionMatrix:
# 这段代码定义了一个名为 ConfusionMatrix 的类,用于在目标检测任务中计算和处理混淆矩阵。混淆矩阵是一个表格,用于显示模型预测的类别与真实类别之间的关系。
# 声明了一个名为 ConfusionMatrix 的新类。这是一个Python类,用于构建和处理混淆矩阵,常用于评估分类模型的性能。
class ConfusionMatrix:# Updated version of https://github.com/kaanakan/object_detection_confusion_matrix# 这段代码是 ConfusionMatrix 类的构造函数 __init__ ,它在创建类的实例时被调用。# 这是类的构造函数的定义。它接受三个参数.# 1.self :一个对类的当前实例的引用,总是作为第一个参数传递。# 2.nc :一个整数,表示类别的数量。# 3.conf :一个浮点数,默认值为0.25,表示置信度阈值。# 4.iou_thres :一个浮点数,默认值为0.45,表示交并比(IoU)阈值。def __init__(self, nc, conf=0.25, iou_thres=0.45):# 创建一个形状为 (nc + 1) x (nc + 1) 的二维数组,并使用 np.zeros 函数将其初始化为零。这个数组将被用作混淆矩阵,其中 nc 是类别的数量,额外的一行和一列用于处理背景或未分类的预测。self.matrix = np.zeros((nc + 1, nc + 1))# 将传入的 nc 参数值保存到实例变量 self.nc 中,表示 类别的数量 。这个值用于后续的矩阵索引和维度检查。self.nc = nc # number of classes# 将传入的 conf 参数值保存到实例变量 self.conf 中,表示 置信度阈值 。这个阈值用于确定哪些检测结果是可信的,即只有置信度高于这个阈值的检测结果才会被考虑。self.conf = conf# 将传入的 iou_thres 参数值保存到实例变量 self.iou_thres 中,表示 交并比(IoU)阈值 。这个阈值用于确定检测框和真实框之间的匹配程度,只有当IoU高于这个阈值时,检测才被认为是正确的。self.iou_thres = iou_thres# 构造函数 __init__ 初始化了 ConfusionMatrix 类的一个实例,设置了混淆矩阵的大小,以及用于后续处理的置信度和交并比阈值。这个初始化过程为后续的方法提供了必要的基础数据结构和参数,使得类可以处理和更新混淆矩阵,以及计算和返回真阳性和假阳性的数量。# 这段代码是 ConfusionMatrix 类的 process_batch 方法,用于处理一批检测结果和对应的标签,更新混淆矩阵。# 定义了一个名为 process_batch 的方法,它接受三个参数。# 1.self :类的实例自身。# 2.detections :检测结果。# 3.labels :真实标签。def process_batch(self, detections, labels):# 返回框的交并比(Jaccard 索引)。"""Return intersection-over-union (Jaccard index) of boxes.Both sets of boxes are expected to be in (x1, y1, x2, y2) format.Arguments:detections (Array[N, 6]), x1, y1, x2, y2, conf, classlabels (Array[M, 5]), class, x1, y1, x2, y2Returns:None, updates confusion matrix accordingly"""# 检查 detections 是否为 None ,如果是,则表示没有检测结果。if detections is None:# 如果 detections 为 None ,则将 labels 转换为整数类型,并存储在 gt_classes 中。gt_classes = labels.int()# 遍历 gt_classes 中的每个元素。for gc in gt_classes:# 对于每个 真实类别 gc ,在混淆矩阵的背景行( self.nc 索引)和类别列上加一,表示背景误检(False Negative, FN)。self.matrix[self.nc, gc] += 1 # background FN# 如果 detections 为 None ,则结束方法执行。return# 筛选出置信度高于阈值 self.conf 的检测结果。detections = detections[detections[:, 4] > self.conf]# 提取 labels 中的真实类别,并转换为整数类型。gt_classes = labels[:, 0].int()# 提取 detections 中的预测类别,并转换为整数类型。detection_classes = detections[:, 5].int()# 计算 labels 和 detections 之间的交并比(IoU)。# def box_iou(box1, box2, eps=1e-7): -> 用于计算两组边界框之间的交并比(IoU)。inter / (...) 计算最终的 IoU 值,即交集面积除以并集面积。 -> return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)iou = box_iou(labels[:, 1:], detections[:, :4])# 找出 IoU 大于阈值 self.iou_thres 的索引。x = torch.where(iou > self.iou_thres)# 检查是否有满足 IoU 阈值条件的匹配。if x[0].shape[0]:# 如果存在匹配,则将匹配的索引和对应的 IoU 值合并,并转换为 NumPy 数组。# 这行代码执行了几个操作,用于处理和组合匹配的索引以及它们对应的交并比(IoU)值。# torch.stack(x, 1) : x 是一个包含两个元素的元组, x[0] 和 x[1] 分别代表满足 IoU 阈值条件的 预测框 和 真实框 的索引。 torch.stack(x, 1) 将这两个索引堆叠起来形成一个新维度,得到的张量形状为 (匹配数量, 2) ,其中每一行包含一对匹配的索引。# iou[x[0], x[1]][:, None] :从 iou 张量中选取满足条件的 IoU 值。 iou[x[0], x[1]] 取出位于索引 x[0] 和 x[1] 处的 IoU 值,形成一个一维张量。 [:, None] 将这个一维张量增加一个新的维度,使其形状变为 (匹配数量, 1) ,以便于与其他张量进行拼接。# torch.cat(..., 1) : torch.cat 是 PyTorch 中的张量连接函数,用于沿着指定的维度将多个张量连接起来。在这里,它将上两步得到的张量沿着第二维(索引为 1)连接起来,形成一个形状为 (匹配数量, 3) 的新张量,其中包含了匹配的预测框索引、真实框索引和对应的 IoU 值。# .cpu() :如果张量是在 GPU 上创建的, .cpu() 方法将其移动到 CPU 内存中。这是因为 NumPy 不能直接处理存储在 GPU 内存中的张量。# .numpy() :将 PyTorch 张量转换为 NumPy 数组,以便后续可以进行 NumPy 操作,如索引、排序等。# 将满足 IoU 阈值条件的预测框和真实框的索引以及它们对应的 IoU 值合并成一个 NumPy 数组,以便于后续的处理。这个数组的每一行都包含了一对匹配的索引和它们的 IoU 值,格式为 [预测框索引, 真实框索引, IoU值] 。matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()# 如果存在多个匹配,则进行排序和去重。if x[0].shape[0] > 1:# 根据 IoU 值对匹配进行降序排序。# 这行代码对 matches 数组进行操作,目的是根据第三列(即索引为2的列,因为Python索引是从0开始的)的值进行降序排序。# matches[:, 2] :这个表达式取出 matches 数组的第三列,即每一行的第三个元素。在这个上下文中,这个元素代表的是交并比(IoU)值。# matches[:, 2].argsort() : argsort() 函数返回的是数组元素从小到大排序后的索引值。因此, matches[:, 2].argsort() 返回的是 IoU 值从小到大排序的索引。# matches[:, 2].argsort()[::-1] : [::-1] 是 Python 中切片的一种用法,表示将数组逆序。所以,这个表达式将 argsort() 得到的索引数组逆序,即从大到小排序。# matches[matches[:, 2].argsort()[::-1]] :最后,这个表达式使用上一步得到的逆序索引数组来索引 matches 数组,从而得到一个新的数组,这个新数组是按照 IoU 值从大到小排序的。# 将 matches 数组按照 IoU 值从高到低进行排序。这样,具有最高 IoU 值的匹配会排在数组的前面,这在后续选择最佳匹配时非常有用。matches = matches[matches[:, 2].argsort()[::-1]]# 去除重复的真实类别匹配。matches = matches[np.unique(matches[:, 1], return_index=True)[1]]# 再次根据 IoU 值对匹配进行降序排序。matches = matches[matches[:, 2].argsort()[::-1]]# 去除重复的预测类别匹配。matches = matches[np.unique(matches[:, 0], return_index=True)[1]]# 如果没有匹配,则设置 matches 为一个空的 NumPy 数组。else:# 如果没有匹配,则设置 matches 为一个空的 NumPy 数组。matches = np.zeros((0, 3))# 检查是否有匹配。n = matches.shape[0] > 0# 转置 matches 数组,并转换为整数类型,分别得到 真实类别索引 m0 和 预测类别索引 m1 。m0, m1, _ = matches.transpose().astype(int)# 遍历真实类别。for i, gc in enumerate(gt_classes):# 找出与当前真实类别匹配的索引。j = m0 == i# 如果存在匹配且匹配数量为1,则更新混淆矩阵。if n and sum(j) == 1:# 在混淆矩阵的正确预测位置加一。self.matrix[detection_classes[m1[j]], gc] += 1 # correct# 如果没有匹配,则更新背景行。else:# 在混淆矩阵的背景行加一。self.matrix[self.nc, gc] += 1 # true background# 如果存在匹配,则检查预测类别。if n:# 遍历预测类别。for i, dc in enumerate(detection_classes):# 如果预测类别没有匹配的真实类别,则更新预测背景列。if not any(m1 == i):# 在混淆矩阵的预测背景列加一。self.matrix[dc, self.nc] += 1 # predicted background# process_batch 方法处理一批检测结果和真实标签,通过计算 IoU 和应用置信度及 IoU 阈值来更新混淆矩阵。它考虑了检测结果为空的情况,并正确地处理了匹配和未匹配的情况,包括正确预测、背景误检和预测背景。这个方法是评估目标检测模型性能的关键步骤,因为它允许模型的性能以混淆矩阵的形式被量化和可视化。# 这段代码定义了 ConfusionMatrix 类中的一个方法 matrix ,它的作用是返回类的实例变量 self.matrix 的当前值。# 定义了一个名为 matrix 的方法,它只接受一个参数 self ,代表类的实例自身。def matrix(self):# 返回 self.matrix 的值。 self.matrix 是在类的构造函数 __init__ 中初始化的,它是一个二维 NumPy 数组,用于存储混淆矩阵的值。return self.matrix# matrix 方法提供了一个简单的接口来获取当前混淆矩阵的状态。这个状态可以用来进一步分析模型的性能,或者用于可视化和报告。调用这个方法时,不需要传递任何参数,它将返回一个包含混淆矩阵数据的 NumPy 数组。# 这段代码定义了 ConfusionMatrix 类中的一个方法 tp_fp ,用于从混淆矩阵中提取真阳性(True Positives, TP)和假阳性(False Positives, FP)。# 定义了一个名为 tp_fp 的方法,它只接受一个参数 self ,代表类的实例自身。def tp_fp(self):# np.ndarray.diagonal(offset=0, axis1=0, axis2=1)# .diagonal() 是 NumPy 数组对象的一个方法,用于返回数组的对角线元素。这个方法可以从二维数组中提取主对角线上的元素,也可以从多维数组中提取对角线元素,具体取决于参数的设置。# 参数 :# offset :偏移量,指定要提取的对角线。默认为0,表示主对角线。正值表示主对角线上方的对角线,负值表示主对角线下方的对角线。# axis1 和 axis2 :指定要沿着哪个轴提取对角线元素。默认分别为0和1,适用于二维数组。# 返回值 :# 返回一个一维数组,包含指定对角线上的元素。# 使用 diagonal 方法从 self.matrix (混淆矩阵)中提取对角线元素。对角线元素代表每个类别正确预测的数量,即真阳性(TP)。tp = self.matrix.diagonal() # true positives# 首先,使用 sum(1) 方法计算混淆矩阵每一列的总和,这代表了每个类别的预测总数。然后,从这个总数中减去对应的真阳性(TP),得到每个类别的假阳性(FP)数量。fp = self.matrix.sum(1) - tp # false positives# 这行代码被注释掉了,但它说明了如何计算假阴性(False Negatives, FN),即错过的检测。这可以通过计算每一行的总和(代表每个真实类别的总数),然后减去对应的真阳性(TP)来实现。# fn = self.matrix.sum(0) - tp # false negatives (missed detections)# 返回真阳性(TP)和假阳性(FP)的数组,但是排除了最后一个元素。由于混淆矩阵的最后一行和最后一列通常用于表示背景类或未分类的预测,所以这里使用 [:-1] 来去除背景类的计数。return tp[:-1], fp[:-1] # remove background class# tp_fp 方法提供了一个接口来获取混淆矩阵中的真阳性和假阳性计数,这些计数可以用来评估分类模型的性能。通过排除背景类的计数,这个方法专注于返回有意义的类别的性能指标。# 这段代码是 ConfusionMatrix 类中的 plot 方法,用于绘制混淆矩阵的热力图,并提供了一个 print 方法来打印混淆矩阵。# 装饰器,用于捕获 plot 方法执行过程中可能出现的任何异常。如果发生异常,它将打印出警告信息:“WARNING ⚠️ ConfusionMatrix plot failure”,意味着混淆矩阵绘图失败。# class TryExcept(contextlib.ContextDecorator):# -> 这个上下文管理器的作用是在代码块执行过程中捕获异常,并在异常发生时打印一条包含自定义消息和异常值的消息。# -> def __init__(self, msg=''):@TryExcept('WARNING ⚠️ ConfusionMatrix plot failure') # 警告⚠️ConfusionMatrix 绘图失败。# plot 方法的定义,它接受三个参数。# 1.self :类的实例自身。# 2.normalize :一个布尔值,指示是否对混淆矩阵进行归一化处理,默认为 True 。# 3.save_dir :一个字符串,指定保存热力图图像的目录,默认为空字符串,即不保存。# 4.names :一个列表,包含每个类别的名称,默认为空列表。def plot(self, normalize=True, save_dir='', names=()):# 导入 Seaborn 库,并将其别名设置为 sn 。Seaborn 是一个基于 Matplotlib 的统计数据可视化库,非常适合绘制热力图。import seaborn as sn# 如果 normalize 参数为 True ,则对混淆矩阵进行归一化处理。# self.matrix.sum(0) :计算混淆矩阵每一列的元素和,即每个真实类别的预测总数。# reshape(1, -1) :将列和的结果重塑为一个行向量,以便进行广播运算。# + 1E-9 :添加一个非常小的数,以避免除以零的情况。# if normalize else 1 :如果 normalize 为 True ,则使用列和进行归一化;否则,直接使用 1,不对矩阵进行归一化。# self.matrix / (...) :将混淆矩阵的每个元素除以对应的归一化值。array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns# 将归一化后的矩阵中小于 0.005 的值设置为 np.nan (Not a Number),这样在绘制热力图时,这些值不会被标注,因为它们太小,标注出来没有意义。array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)# 这部分代码负责准备绘制热力图所需的数据,包括归一化混淆矩阵和处理小值。通过归一化,可以更直观地比较不同类别之间的预测性能。而将小值设置为 np.nan 则可以避免在热力图上显示过多的小数值,使图表更加清晰。# 这段代码继续实现了 ConfusionMatrix 类的 plot 方法,用于绘制并保存归一化混淆矩阵的热力图。# 使用 Matplotlib 创建一个图形和子图对象,设置图形大小为 12x9 英寸,并启用紧凑布局以减少子图之间的空白。fig, ax = plt.subplots(1, 1, figsize=(12, 9), tight_layout=True)# 获取类 别的数量 nc 和提供的 类别名称列表 names 的长度 nn 。nc, nn = self.nc, len(names) # number of classes, names# 根据类别数量设置 Seaborn 的字体缩放比例,如果类别少于 50 个,则字体大小为 1.0,否则为 0.8。sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size# 确定是否有足够的类别名称提供,并且数量与类别数量相匹配,以决定是否使用这些名称作为刻度标签。labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels# 如果决定使用提供的名称作为刻度标签,则将 'background' 添加到名称列表中;否则,使用自动生成的刻度标签。ticklabels = (names + ['background']) if labels else "auto"# 使用警告上下文管理器来捕获并忽略可能发生的警告,例如当热力图包含全为 NaN 的行或列时。with warnings.catch_warnings():# 使用警告上下文管理器来捕获并忽略可能发生的警告,例如当热力图包含全为 NaN 的行或列时。warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered# 使用 Seaborn 的 heatmap 函数绘制热力图,其中 array 是归一化后的混淆矩阵。 annot 参数决定是否在热力图上显示数值, annot_kws 设置注释的字体大小, cmap 设置颜色图, fmt 设置数值格式, square 设置每个单元格为正方形, vmin 设置颜色图的最小值, xticklabels 和 yticklabels 设置 x 轴和 y 轴的刻度标签。sn.heatmap(array,ax=ax,annot=nc < 30,annot_kws={"size": 8},cmap='Blues',fmt='.2f',square=True,vmin=0.0,xticklabels=ticklabels,yticklabels=ticklabels).set_facecolor((1, 1, 1))# 设置 y 轴的标签为 'True'。ax.set_ylabel('True') # ❌⚠️ 应该修改为 ax.set_xlabel('True') 。# 设置 y 轴的标签为 'Predicted'。注意这里重复设置了 y 轴标签,可能是一个错误,通常只需要设置一次。ax.set_ylabel('Predicted')# 设置图形的标题为 'Confusion Matrix'。ax.set_title('Confusion Matrix')# 将图形保存为 PNG 文件,文件名为 'confusion_matrix.png',保存在 save_dir 指定的目录下,设置分辨率为 250 dpi。fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)# 关闭图形,释放资源。plt.close(fig)# 这段代码负责绘制混淆矩阵的热力图,并提供了灵活的配置选项,如归一化、自定义刻度标签和保存图形。通过忽略警告,它能够处理包含 NaN 值的情况,确保即使在数据不完整时也能顺利绘制热力图。# plot 方法提供了一个功能强大的工具,用于可视化混淆矩阵,支持归一化和自定义类别名称。 print 方法则提供了一个简单的文本输出,用于直接查看混淆矩阵的内容。# 这段代码定义了 ConfusionMatrix 类中的 print 方法,用于将混淆矩阵的内容以文本格式打印到控制台。# 定义了一个名为 print 的方法,它只接受一个参数 self ,代表类的实例自身。def print(self):# 使用一个 for 循环遍历混淆矩阵的每一行, self.nc + 1 确保包括了代表背景或未分类预测的额外一行。for i in range(self.nc + 1):# 对于每一行 i ,使用 map(str, self.matrix[i]) 将该行中的每个元素转换为字符串格式。 map 函数将给定函数(在这里是 str )应用于可迭代对象(在这里是矩阵的一行)的每个元素。# join 方法将转换后的字符串列表连接成一个单一的字符串,每个元素之间用空格分隔。# print 函数将这个字符串打印到控制台。print(' '.join(map(str, self.matrix[i])))# print 方法提供了一个简单的方式,将混淆矩阵的每一行以文本形式输出。这对于快速检查模型性能或进行初步分析非常有用。通过打印整个混淆矩阵,开发者可以直观地看到每个类别的预测结果,包括正确预测和误分类的数量。
# 这个 ConfusionMatrix 类提供了一个工具来跟踪和可视化目标检测模型的性能。它允许用户处理一批检测结果和真实标签,计算TP和FP,并最终通过热力图可视化混淆矩阵。这个类特别适用于评估和调试目标检测模型,帮助开发者理解模型在不同类别上的表现。7.class WIoU_Scale:
# 这段代码定义了一个名为 WIoU_Scale 的类,它用于计算加权的交并比(Weighted IoU, WIoU)尺度因子,这在某些目标检测任务中可以用来调整损失函数,以提高模型性能。
# 声明了一个名为 WIoU_Scale 的新类。
class WIoU_Scale:''' monotonous: {None: origin v1True: monotonic FM v2False: non-monotonic FM v3}momentum: The momentum of running mean'''# 一个类变量,用于存储交并比(IoU)的平均值。初始值设置为 1.0,表示开始时IoU的平均值被假设为1。iou_mean = 1.# 一个类变量,用于指示计算WIoU尺度因子时是否使用 单调函数 。初始值设置为 False ,意味着默认情况下使用的是非单调函数。monotonous = False# 一个类变量,用于计算 动量 ,它影响IoU平均值更新的速度。动量值接近于1,意味着新的IoU值对平均值的影响较小,而历史平均值的影响较大。_momentum = 1 - 0.5 ** (1 / 7000)# 一个类变量,指示当前 是否处于训练模式 。初始值设置为 True ,表示默认情况下类将执行训练时的操作。_is_train = True# WIoU_Scale 类包含了几个关键的类变量,用于控制和调整交并比的尺度计算。这些变量共同决定了如何根据历史数据和当前IoU值动态调整尺度因子,这对于优化目标检测模型的性能至关重要。通过调整这些参数,开发者可以根据具体的应用场景和模型表现来优化损失函数,从而提高模型的准确度和鲁棒性。# 这段代码是 WIoU_Scale 类的构造函数 __init__ ,用于初始化类的实例。# 构造函数的定义。它接受两个参数。# 1.self :指向类的实例。# 2.iou :一个传入的交并比值。def __init__(self, iou):# 将传入的 iou 参数赋值给实例变量 self.iou 。这个变量用于存储当前实例的交并比值。self.iou = iou# 调用了一个实例方法 _update ,并传入 self 作为参数。这个方法用于更新类的 iou_mean (交并比平均值)。self._update(self)# 构造函数 __init__ 在创建 WIoU_Scale 类的新实例时被调用。它接收一个交并比值,并将其存储为实例变量。随后,它调用 _update 方法来根据传入的交并比值更新类的 iou_mean 。这个过程是类的初始化和配置的一部分,确保每个实例都能正确地跟踪和使用交并比的平均值。# 这段代码定义了 WIoU_Scale 类中的一个类方法 _update 。# 一个装饰器,表示接下来的方法是类方法。类方法属于类而不是类的实例,它们可以通过类直接调用,也可以通过实例调用。@classmethod# 类方法的定义。它接受两个参数。# 1.cls :指向类自身的引用。# 2.self :指向类的实例。def _update(cls, self):# if cls._is_train :这个条件判断是否当前类处于训练模式。 cls._is_train 是一个类变量,用于指示是否应该更新 iou_mean 。# cls.iou_mean = (1 - cls._momentum) * cls.iou_mean + cls._momentum * self.iou.detach().mean().item() 如果类处于训练模式,这行代码会更新 iou_mean 。更新的计算方式如下 :# 1 - cls._momentum :计算保留历史 iou_mean 的比例。# cls.iou_mean :当前的 iou_mean 值。# cls._momentum :动量因子,用于更新 iou_mean 时考虑新 iou 值的比例。# self.iou.detach().mean().item() :计算当前实例的 iou 值的平均数,并将其从计算图中分离( detach() ),然后转换为Python数值( item() )。if cls._is_train: cls.iou_mean = (1 - cls._momentum) * cls.iou_mean + \cls._momentum * self.iou.detach().mean().item()# _update 类方法用于在训练模式下更新类的 iou_mean 变量。它结合了历史平均值和当前实例的 iou 值的平均数,使用动量因子来平滑更新过程。这种方法有助于减少训练过程中的波动,使得 iou_mean 更稳定,更好地反映模型在训练过程中的性能变化。# 这段代码定义了 WIoU_Scale 类中的另一个类方法 _scaled_loss 。# 一个装饰器,表示接下来的方法是类方法。类方法属于类而不是类的实例,可以通过类直接调用,也可以通过实例调用。@classmethod# 这是类方法的定义。它接受四个参数。# 1.cls :指向类自身的引用。# 2.self :指向类的实例。# 3.gamma :一个浮点数,默认值为1.9。# 4.delta :一个整数,默认值为3。def _scaled_loss(cls, self, gamma=1.9, delta=3):# 判断 self.monotonous 是否是一个布尔值。 self.monotonous 是一个实例变量,用于指示是否使用单调函数来计算尺度因子。if isinstance(self.monotonous, bool):# 如果 self.monotonous 为 True ,则执行以下操作。if self.monotonous:# 计算当前实例的 iou 值除以 iou_mean 的比值,并取平方根作为尺度因子。return (self.iou.detach() / self.iou_mean).sqrt()# 如果 self.monotonous 为 False ,则执行以下操作。else:# 计算当前实例的 iou 值除以 iou_mean 的比值。beta = self.iou.detach() / self.iou_mean# torch.pow(input, exponent, *, out=None) -> Tensor# torch.pow() 是 PyTorch 库中的一个函数,用于对输入的张量(tensor)进行幂运算。这个函数可以对张量中的每个元素进行指定指数的幂运算。# 参数说明 :# input :输入的张量,可以是标量、向量或者多维张量。# exponent :指数,可以是标量、张量,或者是 torch.Size ,指定每个元素的幂。# out :可选参数,用于指定输出张量的张量。如果提供,输出将被写入此张量中。# 返回值 :# 返回一个新的张量,其中的每个元素是输入张量对应元素的 exponent 次幂。# 根据给定的 gamma 和 delta 值,计算 alpha ,这是一个根据 beta 调整的指数因子。alpha = delta * torch.pow(gamma, beta - delta)# 返回 beta 除以 alpha 的结果作为尺度因子。return beta / alpha# 如果 self.monotonous 不是一个布尔值,则默认返回 1,意味着不应用任何尺度因子。return 1# _scaled_loss 类方法根据 self.monotonous 的值决定如何计算尺度因子。如果 self.monotonous 为 True ,则尺度因子是 iou 值除以 iou_mean 的平方根;如果为 False ,则使用一个更复杂的指数函数来计算尺度因子。这个尺度因子可以用来调整损失函数,以鼓励模型在训练过程中提高 iou 值,从而提高目标检测的准确性。
# WIoU_Scale 类提供了一种方法来动态调整交并比的尺度,这可以帮助目标检测模型在训练过程中更好地学习。通过计算交并比的平均值并根据这个平均值调整尺度因子,可以鼓励模型在训练过程中提高交并比的性能。这个类可以与损失函数结合使用,以改进模型的训练效果。
# L_WIoUV3 = γ·L_WIoUv1 γ = β/(δ+α^(β-δ)) β = (L_IoU/L_IoU_mean) L_IoU_mean :为动量m的滑动平均值。
# L_WIoUv1 = R_WIoU·L_IoU R_WIoU = e^(((x-x_gt)^2+(y-y_gt)^2)/(W_g^2-H_g^2)) L_IoU = 1-IoU = 1-(w_i·h_i)/S_u S_u = w·h+w_gt·h_gt-W_i·H_i
# w、h :真实框宽高。 w_gt、h_gt :预测框宽高。 W_i、H_i :重叠区域宽高。 W_g、H_g :真实框和预测框最小外接矩形的宽高。 x、y :真实框中心点坐标。 x_gt、y_gt :预测框中心点坐标。
# class WIoU_Scale: 类中没有完全实现 L_WIoUV3 。 实现的部分包括 : γ = β/(δ+α^(β-δ)) 、 β = (L_IoU/L_IoU_mean) 、 L_IoU_mean 。8.def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, MDPIoU=False, feat_h=640, feat_w=640, eps=1e-7):
# 这段代码定义了一个函数 bbox_iou ,用于计算两个边界框之间的交并比(IoU)以及其变体,如GIoU、DIoU、CIoU和MDPIoU。
# 定义函数 bbox_iou ,它接受10个参数。
# 1.box1 和 2.box2 :是两个边界框。
# 3.xywh 参数指定边界框的坐标格式是 (x, y, w, h) 还是 (x1, y1, x2, y2) 。
# 4.GIoU 、 5.DIoU 、 6.CIoU 和 7.MDPIoU :及一系列参数来指定使用哪种IoU计算方式。参数分别指定是否使用GIoU、DIoU、CIoU和MDPIoU计算方式。
# 8.feat_h 和 9.feat_w :是特征图的高度和宽度。
# 10.eps :是一个很小的数,用于避免除以0。
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, MDPIoU=False, feat_h=640, feat_w=640, eps=1e-7):# Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4) 返回 box1(1,4) 和 box2(n,4) 的并集交集 (IoU) 。# Get the coordinates of bounding boxes# 根据 xywh 参数的值,将边界框的坐标转换为 (x1, y1, x2, y2) 格式。如果 xywh 为 True ,则从 (x, y, w, h) 格式转换;否则,直接使用 (x1, y1, x2, y2) 格式。if xywh: # transform from xywh to xyxy(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_else: # x1, y1, x2, y2 = box1b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + epsw2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps# Intersection area# 计算两个边界框的交集面积。inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)# Union Area# 计算两个边界框的并集面积。union = w1 * h1 + w2 * h2 - inter + eps# IoU# 计算交并比(IoU)。iou = inter / union# 这段代码是 bbox_iou 函数的一部分,它负责计算 广义交并比 (Generalized IoU, GIoU)、 距离交并比 (Distance IoU, DIoU)和 完全交并比 (Complete IoU, CIoU)。# 检查是否需要计算 GIoU、DIoU 或 CIoU。如果任意一个为真,则进入该条件块。if CIoU or DIoU or GIoU:# 计算两个边界框能够包含的最小凸框(convex box)的宽度 cw 。这是通过取两个边界框右边界的最右点和左边界的最左点来实现的。cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width# 计算两个边界框能够包含的最小凸框的高度 ch 。这是通过取两个边界框上边界的最上点和下边界的最下点来实现的。ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height# 这个条件块检查是否需要计算 CIoU 或 DIoU。if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1# 计算凸框的对角线长度的平方 c2 ,并添加一个小的常数 eps 以避免数值计算中的除以零错误。c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared# 计算两个边界框中心点之间的距离的平方 rho2 ,并除以 4,因为公式中的距离是边界框对角线的一半。rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2# 检查是否需要计算 CIoU。if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47# 计算 CIoU 中的角度因素 v ,它基于两个边界框的宽高比的差异。v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)# 在不需要计算梯度的上下文中计算 alpha ,它是 CIoU 公式中的一个参数。with torch.no_grad():alpha = v / (v - iou + (1 + eps))# 返回 CIoU 的值,它是 IoU 减去由中心点距离和角度因素调整的惩罚项。return iou - (rho2 / c2 + v * alpha) # CIoU# 如果不需要计算 CIoU,但需要计算 DIoU,则返回 DIoU 的值,它是 IoU 减去由中心点距离调整的惩罚项。return iou - rho2 / c2 # DIoU# 如果只需要计算 GIoU,则计算凸框的面积 c_area ,并添加一个小的常数 eps 。c_area = cw * ch + eps # convex area# 返回 GIoU 的值,它是 IoU 减去凸框面积与并集面积差异的比例。return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf# 这段代码实现了 IoU 的几种变体,每种变体都在尝试提供一种更准确的方法来衡量两个边界框之间的相似度,特别是在目标检测和图像分割任务中。# 这段代码是 bbox_iou 函数中计算 MDPIoU (Modified Diagonal IoU, MDPIoU )的部分。# 检查是否需要计算 MDPIoU。如果 MDPIoU 参数为真,则执行该条件块中的代码。elif MDPIoU:# 计算两个边界框左上角点之间的距离的平方 d1 。这里 b1_x1 , b1_y1 是第一个边界框的左上角坐标, b2_x1 , b2_y1 是第二个边界框的左上角坐标。d1 = (b2_x1 - b1_x1) ** 2 + (b2_y1 - b1_y1) ** 2# 计算两个边界框右下角点之间的距离的平方 d2 。这里 b1_x2 , b1_y2 是第一个边界框的右下角坐标, b2_x2 , b2_y2 是第二个边界框的右下角坐标。d2 = (b2_x2 - b1_x2) ** 2 + (b2_y2 - b1_y2) ** 2# 计算特征图的宽度和高度的平方和 mpdiou_hw_pow 。这个值用于后续的归一化计算,其中 feat_h 和 feat_w 分别是特征图的高度和宽度。mpdiou_hw_pow = feat_h ** 2 + feat_w ** 2# 计算并返回 MDPIoU 的值。MDPIoU 是 IoU 减去两个距离项的加权和,这两个距离项分别是边界框对角线两端点之间的距离。通过除以 mpdiou_hw_pow ,这个计算实现了距离的归一化。return iou - d1 / mpdiou_hw_pow - d2 / mpdiou_hw_pow # MPDIoU# 如果不需要计算任何特殊的 IoU 变体(GIoU、DIoU、CIoU 或 MDPIoU),则函数返回标准的 IoU 值。return iou # IoU# 这段代码提供了 MDPIoU 的计算实现,它是一种考虑了边界框对角线两端点之间距离的 IoU 变体。通过这种方式,MDPIoU 旨在提供一种更全面的相似度度量,特别是在边界框对角线方向上的距离变化较大时。如果没有指定特殊的 IoU 变体,则函数返回标准的 IoU 值。
# bbox_iou 函数提供了多种IoU计算方式,包括标准的IoU、GIoU、DIoU、CIoU和MDPIoU。这些计算方式在目标检测任务中用于衡量预测边界框与真实边界框之间的匹配程度,是损失计算和模型评估的重要组成部分。9.def box_iou(box1, box2, eps=1e-7):
# 这段代码定义了一个名为 box_iou 的函数,用于计算两组边界框之间的交并比(IoU)。IoU 是目标检测和计算机视觉中常用的度量,用于评估预测边界框与真实边界框之间的重叠程度。
# 定义了一个名为 box_iou 的函数,接受两个边界框数组 box1 和 box2 ,以及一个用于数值稳定性的小常数 eps ,默认值为 1e-7 。
def box_iou(box1, box2, eps=1e-7):# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py# 返回框的交并比(Jaccard 指数)。 两组框均应为 (x1, y1, x2, y2) 格式。"""Return intersection-over-union (Jaccard index) of boxes.Both sets of boxes are expected to be in (x1, y1, x2, y2) format.Arguments:box1 (Tensor[N, 4])box2 (Tensor[M, 4])Returns:iou (Tensor[N, M]): the NxM matrix containing the pairwiseIoU values for every element in boxes1 and boxes2"""# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)# box1.unsqueeze(1) 和 box2.unsqueeze(0) 分别在 box1 和 box2 中增加一个维度,以便进行广播操作。 .chunk(2, 2) 将扩展后的边界框数组分成两部分,分别对应于边界框的左上角 (a1, a2) 和右下角 (b1, b2) 。(a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)# torch.min(a2, b2) 计算两组边界框的右下角的最小值。 torch.max(a1, b1) 计算两组边界框的左上角的最大值。 torch.min(a2, b2) - torch.max(a1, b1) 计算交集的宽度和高度。 .clamp(0) 确保宽度和高度的值不小于0。 .prod(2) 计算交集的面积。inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)# IoU = inter / (area1 + area2 - inter)# (a2 - a1).prod(2) 计算 box1 的面积。# (b2 - b1).prod(2) 计算 box2 的面积。# - inter 从两组边界框的面积中减去交集的面积。# + eps 添加一个小常数 eps 以提高数值稳定性,防止除以零。# inter / (...) 计算最终的 IoU 值,即交集面积除以并集面积。return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
# box_iou 函数通过计算两组边界框的交集面积和并集面积,进而计算它们的交并比(IoU)。这个函数在目标检测任务中非常重要,因为它可以用来评估模型预测的准确性。通过比较预测边界框和真实边界框之间的 IoU 值,可以确定预测的可靠性。10.def bbox_ioa(box1, box2, eps=1e-7):
# 这段代码定义了一个名为 bbox_ioa 的函数,用于计算两个边界框之间的交集面积比(Intersection over Area, IoA)。这个指标衡量了一个边界框在另一个边界框内部的部分所占的比例。
# 这个函数接受三个参数。
# 1.box1 和 2.box2 :两个边界框的坐标数组,每个数组的形状应该是 (4, n) ,其中 n 是边界框的数量,四个元素分别代表 [x1, y1, x2, y2] ,即边界框的左上角和右下角坐标。
# 3.eps :一个非常小的数,用于防止除以零的情况,默认值为 1e-7 。
def bbox_ioa(box1, box2, eps=1e-7):# 返回给定 box1、box2 的 box2 区域的交集。框为 x1y1x2y2。"""Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2box1: np.array of shape(nx4)box2: np.array of shape(mx4)returns: np.array of shape(nxm)"""# Get the coordinates of bounding boxes# 将输入的边界框坐标数组转置,并解包为各自的坐标变量。b1_x1, b1_y1, b1_x2, b1_y2 = box1.Tb2_x1, b2_y1, b2_x2, b2_y2 = box2.T# Intersection area# 算两个边界框的交集面积。首先,使用 np.minimum 和 np.maximum 计算在 x 轴和 y 轴上的交集边界。然后,通过相减得到交集的宽度和高度,并乘起来得到面积。 .clip(0) 确保面积不会是负数。inter_area = (np.minimum(b1_x2[:, None], b2_x2) - np.maximum(b1_x1[:, None], b2_x1)).clip(0) * \(np.minimum(b1_y2[:, None], b2_y2) - np.maximum(b1_y1[:, None], b2_y1)).clip(0)# box2 area# 计算第二个边界框 box2 的面积,并加上 eps 以避免除以零。box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps# Intersection over box2 area# 返回交集面积除以 box2 面积的比例,即 IoA。# 返回值。返回一个数组,包含每个 box1 中的边界框与对应 box2 中的边界框之间的 IoA 值。return inter_area / box2_area
# 这个 bbox_ioa 函数通过计算两个边界框的交集面积与 box2 面积的比例,来衡量 box1 中的边界框在 box2 中所占的比例。这个指标在目标检测和图像分割任务中非常有用,特别是在评估模型性能时,用于确定预测的边界框与真实边界框之间的重叠程度。11.def wh_iou(wh1, wh2, eps=1e-7):
# 这段代码定义了一个名为 wh_iou 的函数,用于计算两个宽度和高度数组之间的交并比(IoU)。这在目标检测任务中常用于评估预测边界框和真实边界框之间的重叠程度。
# 定义了一个名为 wh_iou 的函数,接受三个参数。
# 1.wh1 和 2.wh2 :分别是两个边界框的宽度和高度。
# 3.eps :是一个用于数值稳定性的小常数,默认值为 1e-7 。
def wh_iou(wh1, wh2, eps=1e-7):# Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2 返回 nxm IoU 矩阵。wh1 是 nx2,wh2 是 mx2 。# 将 wh1 张量增加一个新的维度,使其形状变为 [N, 1, 2] ,其中 N 是 wh1 中边界框的数量。这样做是为了使 wh1 能够在接下来的广播操作中与 wh2 兼容。wh1 = wh1[:, None] # [N,1,2]# 将 wh2 张量增加一个新的维度,使其形状变为 [1, M, 2] ,其中 M 是 wh2 中边界框的数量。这样处理后, wh2 也能够在广播操作中与 wh1 兼容。wh2 = wh2[None] # [1,M,2]# torch.min(input, dim=None, keepdim=False, *, out=None) -> Tensor 或者 (Tensor, Tensor)# torch.min() 是 PyTorch 库中的一个函数,用于返回输入张量中的最小值。这个函数可以沿着指定的维度或者在张量的整个范围内寻找最小值,取决于是否指定了维度参数。# 参数说明 :# input :输入的张量。# dim :可选参数,指定沿哪个维度寻找最小值。如果不指定,则返回整个张量的最小值。# keepdim :布尔值,如果为 True ,则输出张量会保持输入张量的维度,即保留单一的维度。# out :可选参数,用于指定输出张量的张量。如果提供,输出将被写入此张量中。# 返回值 :# 如果不指定 dim 参数,返回输入张量的最小值。# 如果指定了 dim 参数,返回一个元组,包含两个张量 :第一个张量包含沿 dim 维度的最小值,第二个张量包含这些最小值的索引。# 使用 torch.min 函数计算 wh1 和 wh2 中每个对应维度的最小值,这代表了交集的宽度和高度。然后使用 prod(2) 计算交集的面积,结果是一个形状为 [N, M] 的张量,其中 N 和 M 分别是 wh1 和 wh2 中边界框的数量。inter = torch.min(wh1, wh2).prod(2) # [N,M]# 计算 IoU 值。首先计算 wh1 和 wh2 的面积,然后从它们的和中减去交集的面积,得到并集的面积。最后,将交集的面积除以并集的面积,得到 IoU 值。 eps 被添加到分母中以提高数值稳定性,防止除以零的情况。return inter / (wh1.prod(2) + wh2.prod(2) - inter + eps) # iou = inter / (area1 + area2 - inter)
# wh_iou 函数通过计算两个边界框集合的交集和并集面积,来计算它们之间的交并比(IoU)。这个函数特别适用于目标检测任务中,用于评估预测边界框与真实边界框之间的重叠程度。通过广播机制,这个函数能够高效地处理多个边界框的 IoU 计算,使得它在实际应用中非常高效。12.def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=()):
# Plots ----------------------------------------------------------------------------------------------------------------# 这段代码定义了一个名为 plot_pr_curve 的函数,用于绘制精确度-召回率曲线(Precision-Recall Curve),并保存为图像文件。
# 这是一个装饰器,用于将函数的执行放在一个线程中,以便它可以并行执行而不阻塞主线程。
# def threaded(func):
# -> threaded 的装饰器,它用于将一个函数转换为多线程执行。wrapper 函数返回创建的线程对象,这样调用者可以对线程进行进一步的操作,比如等待线程结束。装饰器 threaded 返回 wrapper 函数,这样当 @threaded 装饰器应用到一个函数上时,实际上是用 wrapper 函数包装了原始函数。
# -> return wrapper
@threaded
# 定义了 plot_pr_curve 函数,它接受以下参数 :
# 1.px :x轴数据,通常是召回率(recall)的值。
# 2.py :y轴数据,通常是精确度(precision)的值。
# 3.ap :平均精确度(Average Precision)的值,用于计算模型的整体性能。
# 4.save_dir :保存图像的路径,默认为当前目录下的 pr_curve.png 。
# 5.names :类别名称的列表,用于图例显示。
def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=()):# Precision-recall curve# 使用 matplotlib 创建一个图形和一个轴对象,设置图形大小为 9x6 英寸,并启用紧凑布局。fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)# 将 py 数据堆叠起来,以便可以按列处理。py = np.stack(py, axis=1)# 检查类别名称的数量是否在 0 到 20 之间,如果是,则为每个类别绘制一条线并添加图例。if 0 < len(names) < 21: # display per-class legend if < 21 classes# 遍历 py 的每一列(每个类别)。for i, y in enumerate(py.T):# 为每个类别绘制精确度-召回率曲线,并设置图例标签。ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)# 如果类别数量不满足上述条件,则绘制所有类别的灰色曲线。else:ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)# 绘制所有类别的平均精确度-召回率曲线,并设置图例标签。ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())# 设置 x 轴和 y 轴的标签。ax.set_xlabel('Recall')ax.set_ylabel('Precision')# 设置 x 轴和 y 轴的显示范围。ax.set_xlim(0, 1)ax.set_ylim(0, 1)# 设置图例的位置。ax.legend(bbox_to_anchor=(1.04, 1), loc="upper left")# 设置图形的标题。ax.set_title('Precision-Recall Curve') # 精确度-召回率曲线。# 将图形保存到指定路径,设置分辨率为 250 DPI。fig.savefig(save_dir, dpi=250)# 关闭图形,释放资源。plt.close(fig)
# 这个函数 plot_pr_curve 用于绘制精确度-召回率曲线,它可以处理多个类别的数据,并根据类别数量决定是否显示每个类别的图例。如果类别数量少于21,它会为每个类别绘制一条线并显示图例;否则,它只显示所有类别的平均曲线。最后,函数将绘制的图形保存为图像文件,并关闭图形以释放资源。13.def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric'):
# 这段代码定义了一个名为 plot_mc_curve 的函数,用于绘制度量-置信度曲线(Metric-Confidence Curve),并保存为图像文件。
# 这是一个装饰器,用于将函数的执行放在一个线程中,以便它可以并行执行而不阻塞主线程。
# def threaded(func):
# -> threaded 的装饰器,它用于将一个函数转换为多线程执行。wrapper 函数返回创建的线程对象,这样调用者可以对线程进行进一步的操作,比如等待线程结束。装饰器 threaded 返回 wrapper 函数,这样当 @threaded 装饰器应用到一个函数上时,实际上是用 wrapper 函数包装了原始函数。
# -> return wrapper
@threaded
# 定义了 plot_mc_curve 函数,它接受六个参数。
# 1.px :x轴数据,通常是置信度(Confidence)的值。
# 2.py :y轴数据,通常是度量(Metric)的值。
# 3.save_dir :保存图像的路径,默认为当前目录下的 mc_curve.png 。
# 4.names :一个元组,包含每个类别的名称,默认为空。
# 5.xlabel :x轴标签,默认为 'Confidence'。
# 6.ylabel :y轴标签,默认为 'Metric'。
def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric'):# Metric-confidence curve# 使用 matplotlib 创建一个图形和一个子图,设置图形大小为9x6英寸,并启用紧凑布局。fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)# 检查 names 元组的长度是否在1到20之间,如果是,则为每个类别绘制一条线并显示图例。if 0 < len(names) < 21: # display per-class legend if < 21 classes# 遍历 py 中的每个元素(每个类别的度量-置信度曲线)。for i, y in enumerate(py):# 为每个类别绘制度量-置信度曲线,并设置图例标签,包括类别名称。ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)# 如果类别数量不满足显示图例的条件,则执行以下操作。else:# 为所有类别绘制灰色的度量-置信度曲线。ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)# 对所有类别的平均度量值进行平滑处理,使用 smooth 函数,平滑系数为0.05。# def smooth(y, f=0.05): -> 用于平滑一个数值数组 y 。只返回卷积结果中完全由输入数组覆盖的部分。 -> return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothedy = smooth(py.mean(0), 0.05)# 绘制所有类别的平均度量-置信度曲线,并设置图例标签,包括最大度量值及其对应的置信度。ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')# 设置x轴标签。ax.set_xlabel(xlabel)# 设置y轴标签。ax.set_ylabel(ylabel)# 设置x轴的范围为0到1。ax.set_xlim(0, 1)# 设置y轴的范围为0到1。ax.set_ylim(0, 1)# 设置图例的位置在图形的右上角。ax.legend(bbox_to_anchor=(1.04, 1), loc="upper left")# 设置图形的标题为度量-置信度曲线。ax.set_title(f'{ylabel}-Confidence Curve')# 将图形保存为指定路径的图像文件,设置分辨率为250dpi。fig.savefig(save_dir, dpi=250)# 关闭图形,释放资源。plt.close(fig)
# 这个函数 plot_mc_curve 用于绘制度量-置信度曲线,它可以处理多个类别的数据,并根据类别数量决定是否显示每个类别的图例。如果类别数量少于21,它会为每个类别绘制一条线并显示图例;否则,它只显示所有类别的平均曲线。函数还对平均度量值进行平滑处理以减少噪声。最后,函数将绘制的图形保存为图像文件,并关闭图形以释放资源。相关文章:

YOLOv9-0.1部分代码阅读笔记-metrics.py
metrics.py utils\metrics.py 目录 metrics.py 1.所需的库和模块 2.def fitness(x): 3.def smooth(y, f0.05): 4.def ap_per_class(tp, conf, pred_cls, target_cls, plotFalse, save_dir., names(), eps1e-16, prefix""): 5.def compute_ap(recall, prec…...
KaiOS 4.0 | DataCall and setupData implemention
相关文档 1、KaiOS 3.1 系统介绍 KaiOS 系统框架和应用结构(APP界面逻辑)文章浏览阅读842次,点赞17次,收藏5次。对于Java开发者而言,理解JS的逻辑调用是有点困难的。而KaiOS webapp开发又不同于现代的web开发,更像chrome浏览器内嵌模式。在这里梳理一下kaios平台web应用…...

nginx-rtmp服务器搭建
音视频服务器搭建 本文采用 nginx/1.18.0和nginx-rtmp-module模块源代码搭建RTMP流媒体服务器 流程 查看当前服务器的nginx版本下载nginx和nginx-rtmp-module源代码重新编译nginx,并进行相关配置(nginx.conf、防火墙等)客户端测试连接测试搭…...

[c++进阶(三)]单例模式及特殊类的设计
1.前言 在实际场景中,总会遇见一些特殊情况,比如设计一个类,只能在堆上开辟空间, 或者是设计一个类只能实例化一个对象。那么我们应该如何编写代码呢?本篇将会详细的介绍 本章重点: 本篇文章着重讲解如何设计一些特殊 的类,包括不能被拷贝,只能在栈/堆上…...

企业内训|高智能数据构建和多模态数据处理、Agent研发及AI测评技术内训-吉林省某汽车厂商
吉林省某汽车厂商为提升员工在AI大模型技术方面的知识和实践能力,举办本次为期8天的综合培训课程。本课程涵盖“高智能数据构建与智驾云多模态数据处理”、“AI Agent的研发”和“大模型测评”三大模块。通过系统梳理从非结构化数据的高效标注与融合,到L…...

009 Qt_显示类控件_QLCDNumber、ProgressBar、Calendar
文章目录 前言LCD NumberProgressBarCalendar Widget 小结 前言 本文将会向你介绍显示类控件中QLCDNumber显示数字、ProgressBar进度条、Calendar日历 LCD Number QLCDNumer 是⼀个专门用来显示数字的控件. 类似于 “老式计算器” 的效果. 属性说明intValueQLCDNumber 显示…...

--spring.profiles.active=prod
rootproduct-qualification:~# ps -ef | grep java root 5110 1 3 16:57 ? 00:00:54 java -jar productQualification.jar --spring.profiles.activeprod root 6476 5797 0 17:26 pts/0 00:00:00 grep --colorauto java好的,你使用 ps …...

深入解析JVM中对象的创建过程
1. 引言 对象是面向对象编程的核心概念之一,它们封装了数据和行为,构成了应用程序的基本构建块。然而,在Java语言中,每当使用new关键字或其他方式创建一个新对象时,背后发生了什么?这个问题的答案隐藏在JV…...
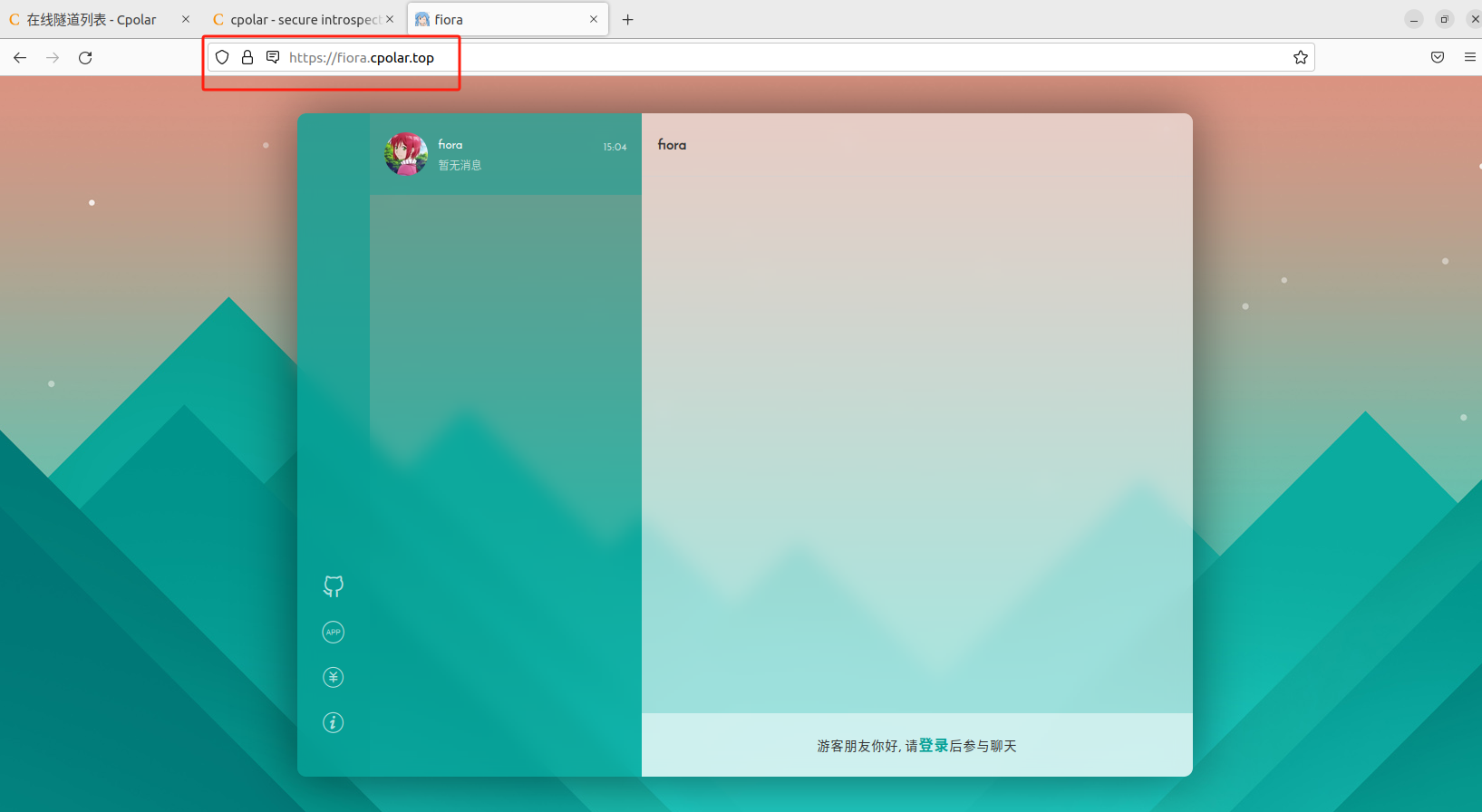
使用开源在线聊天工具Fiora轻松搭建个性化聊天平台在线交流
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:人工智能教程 文章目录 前言1.关于Fiora2.安装Docker3.本地部署Fiora4.使用Fiora5.cpolar内网穿透工具安装6.创建远程连接公网地址7.固定Uptime …...

ffmpeg之显示一个yuv照片
显示YUV图片的步骤 1.初始化SDL库 目的:确保SDL库正确初始化,以便可以使用其窗口、渲染和事件处理功能。操作:调用 SDL_Init(SDL_INIT_VIDEO) 来初始化SDL的视频子系统。 2.创建窗口用于显示YUV图像: 目的:创建一个…...

MySQL中Performance Schema库的详解(下)
昨天说了关于SQL语句相关的,今天来说说性能相关的,如果没有看过上篇请点传送门https://blog.csdn.net/2301_80479959/article/details/144693574?fromshareblogdetail&sharetypeblogdetail&sharerId144693574&sharereferPC&sharesource…...

【Rust自学】7.1. Package、Crate和定义Module
喜欢的话别忘了点赞、收藏加关注哦,对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 7.1.1. Rust的代码组织 代码组织主要包括: 那些细节可以对外暴露,而哪些细节是私有的在作用域内哪些名称有效… …...

【Git】-- 版本说明
Alpha:是内部测试版,一般不向外部发布,会有很多 Bug .一般只有测试人员使用。Beta:也是测试版,这个阶段的版本会一直加入新的功能。在 Alpha 版之后推出。RC:(Release Candidate) 顾名思义么 ! 用在软件上就是候选版本。系统平台…...

1919C. Grouping Increases
问题描述 序列 X X X,划分成两个字序列 A , B A,B A,B,其中惩罚是 A , B A,B A,B之中, A [ i ] < A [ i 1 ] , B [ i ] < B [ i 1 ] A[i] < A[i1], B[i] < B[i1] A[i]<A[i1],B[i]<B[i1]的个数 思路 拆分 X X X…...

Pion WebRTC 项目教程
Pion WebRTC 项目教程 webrtc Pure Go implementation of the WebRTC API [这里是图片001] 项目地址: https://gitcode.com/gh_mirrors/we/webrtc 1. 项目目录结构及介绍 Pion WebRTC 项目的目录结构如下: pion/webrtc ├── api ├── examples ├── inter…...

【安全编码】Web平台如何设计防止重放攻击
我们先来做一道关于防重放的题,答案在文末 防止重放攻击最有效的方法是( )。 A.对用户密码进行加密存储使用 B.使用一次一密的加密方式 C.强制用户经常修改用户密码 D.强制用户设置复杂度高的密码 如果这道题目自己拿不准,或者…...

VUE3+django接口自动化部署平台部署说明文档(使用说明,需要私信)
网址连接:http://118.25.110.213:5200/#/login 账号/密码:renxiaoyong 1、VUE3部署本地。 1.1本地安装部署node.js 1.2安装vue脚手架 npm install -g vue/cli # 或者 yarn global add vue/cli1.3创建本地项目 vue create my-vue-project1.4安装依赖和插…...
)
Python爬虫(入门+进阶)
简介 围绕 Python 爬虫展开,包括四个章节。第一章从 Python 爬虫入门,涵盖爬虫概念、Requests 爬取、Xpath 解析、数据保存及入库等知识,并结合知乎、豆瓣、淘宝等案例讲解浏览器抓包及 Selenium 爬取动态网页。第二章介绍 Scrapy 框架&…...
保姆级教程Docker部署RabbitMQ镜像
目录 1、安装Docker及可视化工具 2、创建挂载目录 3、运行RabbitMQ容器 4、Compose运行RabbitMQ容器 5、开启界面插件 6、查看RabbitMQ运行状态 7、常见问题处理 1、安装Docker及可视化工具 Docker及可视化工具的安装可参考:Ubuntu上安装 Docker及可视化管理…...

【RAII | 设计模式】C++智能指针,内存管理与设计模式
前言 nav2系列教材,yolov11部署,系统迁移教程我会放到年后一起更新,最近年末手头事情多,还请大家多多谅解。 上一节我们讲述了C移动语义相关的知识,本期我们来看看C中常用的几种智能指针,并看看他们在设计模式中的运…...

从开发到上线,基于快马平台构建可部署于ubuntu24.04的django博客系统
最近在折腾个人博客系统,想找一个既能快速开发又能轻松部署的方案。试了几个平台后,发现InsCode(快马)平台特别适合这种需求,尤其是配合Ubuntu 24.04服务器部署的场景。下面记录下我的实战过程,从开发到上线全流程走通的经验。 项…...

3分钟掌握:高效全能资源下载工具res-downloader实战指南
3分钟掌握:高效全能资源下载工具res-downloader实战指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否曾…...
)
从零开始:如何用AutoModelForCausalLM.from_pretrained加载自定义模型(含本地模型和私有模型)
从零开始:AutoModelForCausalLM.from_pretrained加载自定义模型实战指南 当你第一次尝试加载一个自定义的因果语言模型时,可能会被各种参数和配置选项搞得晕头转向。作为一位经历过无数次模型加载失败的开发者,我深知那种看着报错信息却不知…...

终极指南:MFE-starter如何让Angular与React和平共存的实战方案
终极指南:MFE-starter如何让Angular与React和平共存的实战方案 【免费下载链接】MFE-starter MFE Starter 项目地址: https://gitcode.com/gh_mirrors/mf/MFE-starter 在现代前端开发中,框架冲突是许多开发者面临的头疼问题,尤其是当项…...

Maven证书验证难题:彻底绕过PKIX path building failed的实战指南
1. 遇到PKIX path building failed?别慌,这是证书验证的锅 最近在项目编译时突然蹦出个"PKIX path building failed"的错误,是不是让你一头雾水?这其实是Maven在下载依赖时遇到了证书验证问题。简单来说,就…...
3大核心技术突破语言壁垒:LunaTranslator高效视觉小说翻译解决方案
3大核心技术突破语言壁垒:LunaTranslator高效视觉小说翻译解决方案 【免费下载链接】LunaTranslator 视觉小说翻译器 / Visual Novel Translator 项目地址: https://gitcode.com/GitHub_Trending/lu/LunaTranslator 在全球化游戏市场中,语言差异往…...

Qwen-Image-Edit-F2P实战:QT图形界面开发指南
Qwen-Image-Edit-F2P实战:QT图形界面开发指南 1. 学习目标与前置准备 今天咱们来聊聊怎么用QT给Qwen-Image-Edit-F2P模型做个图形界面。这个模型挺有意思的,它能根据一张人脸照片生成全身像,比如你把自拍照传进去,它能给你生成在…...

不升级系统也能用VSCode远程开发:老版本Linux的glibc兼容方案大全
老版本Linux系统下VSCode远程开发的五大兼容方案 在企业开发环境中,生产服务器往往运行着CentOS 7或Ubuntu 18.04等长期支持版本,这些系统的glibc库版本可能无法满足最新VSCode远程开发组件的需求。本文将深入探讨五种无需升级系统即可解决glibc兼容性问…...

全原子设计驱动的蛋白质工程:RFDiffusionAA技术原理与实战指南
全原子设计驱动的蛋白质工程:RFDiffusionAA技术原理与实战指南 【免费下载链接】rf_diffusion_all_atom Public RFDiffusionAA repo 项目地址: https://gitcode.com/gh_mirrors/rf/rf_diffusion_all_atom 在药物研发与蛋白质工程领域,如何高效设计…...

安装paperclip
介绍: # aperclip - 一人工公司的开源编排工具 ## 项目概述 Paperclip 是一个基于 Node.js 的服务器和 React UI,用于编排 AI 代理团队来运营业务。它允许用户导入自定义代理、分配目标,并通过一个仪表板跟踪代理的工作和成本。 核心价值主…...