新浪微博C++面试题及参考答案
多态是什么?请详细解释其实现原理,例如通过虚函数表实现。
多态是面向对象编程中的一个重要概念,它允许不同的对象对同一消息或函数调用做出不同的响应,使得程序具有更好的可扩展性和灵活性。
在 C++ 中,多态主要通过虚函数来实现,其底层原理与虚函数表密切相关。当一个类中包含虚函数时,编译器会为该类创建一个虚函数表,虚函数表是一个存储类中虚函数地址的数组。在类的对象内存布局中,会有一个额外的指针,通常称为虚指针,它指向该类的虚函数表。当通过基类指针或引用调用虚函数时,实际上是通过虚指针找到对应的虚函数表,再根据虚函数在表中的偏移量找到并调用具体的虚函数。这样,在运行时就可以根据对象的实际类型来决定调用哪个类的虚函数,从而实现多态性。例如,有一个基类Shape和两个派生类Circle和Rectangle,它们都重写了draw虚函数。当通过基类指针调用draw函数时,会根据指针所指向的实际对象类型来调用相应派生类的draw函数,这就是多态的体现。
解释智能指针的概念,并说明 C++11 中新增的智能指针有哪些?
智能指针是一种用于管理动态分配内存的对象,它能够自动地进行内存的分配和释放,有效地避免了内存泄漏等问题,同时也简化了动态内存管理的过程。
C++11 中新增了三种智能指针:
std::unique_ptr:它是一种独占式智能指针,意味着同一时刻只能有一个unique_ptr指向特定的对象。当unique_ptr被销毁时,它所指向的对象也会被自动释放。这种智能指针适用于对象的所有权明确且唯一的情况,例如在函数中创建并返回一个动态分配的对象,使用unique_ptr可以确保对象在函数返回后自动释放内存,避免资源泄露。std::shared_ptr:它是一种共享式智能指针,多个shared_ptr可以指向同一个对象,通过引用计数来管理对象的生命周期。当最后一个指向该对象的shared_ptr被销毁时,对象才会被释放。适用于多个对象需要共享同一块内存的情况,如在多个类之间共享一个资源,或者在函数参数和返回值中传递对象的所有权。std::weak_ptr:它是一种弱引用智能指针,主要用于解决shared_ptr可能出现的循环引用问题。weak_ptr不增加对象的引用计数,它可以观察shared_ptr所管理的对象,但不会影响对象的生命周期。当需要访问shared_ptr所管理的对象时,可以通过weak_ptr的lock函数获取一个有效的shared_ptr,如果对象已经被释放,则lock函数返回nullptr。
vector、list、map 的底层数据结构分别是什么?各自适用于哪些应用场景?
vector:底层数据结构是动态数组。它在内存中是连续存储的,这使得随机访问元素的效率非常高,时间复杂度为 O (1)。但是在插入和删除元素时,可能需要移动大量的元素,特别是在中间位置插入或删除元素时,效率较低,平均时间复杂度为 O (n)。适用于需要频繁随机访问元素,且对插入和删除操作相对较少的场景,如对数组进行排序、查找特定元素等操作,因为可以利用其随机访问的高效性进行快速的算法实现。list:底层数据结构是双向链表。它的每个节点包含指向前一个节点和后一个节点的指针,以及存储的数据。在插入和删除元素时,只需要修改节点之间的指针,时间复杂度为 O (1)。但是随机访问元素的效率较低,需要遍历链表,时间复杂度为 O (n)。适用于需要频繁进行插入和删除操作,而对随机访问要求不高的场景,如实现一个任务队列,在队列的头部和尾部频繁地添加和删除任务。map:底层数据结构通常是红黑树。红黑树是一种自平衡二叉搜索树,它保证了插入、删除和查找操作的时间复杂度都为 O (log n)。适用于需要快速查找、插入和删除元素,并且元素之间有一定的顺序关系的场景,如存储学生的成绩信息,以学生的学号作为键,成绩作为值,可以方便地根据学号快速查找、插入和删除学生的成绩记录。
unordered_map 的底层实现是怎样的?
unordered_map的底层实现是哈希表。它通过一个哈希函数将键值对中的键映射到一个特定的桶中,然后在桶中存储键值对。当插入一个键值对时,首先根据键计算出对应的哈希值,然后根据哈希值找到对应的桶,将键值对插入到桶中。在查找一个键值对时,同样先计算键的哈希值,然后在对应的桶中查找键值对。如果哈希函数设计得好,能够将键均匀地分布到各个桶中,那么unordered_map的查找、插入和删除操作的平均时间复杂度可以接近 O (1)。但是在最坏情况下,所有的键都映射到同一个桶中,此时操作的时间复杂度会退化为 O (n)。为了避免这种情况,unordered_map通常会根据实际情况调整哈希表的大小和哈希函数,以保证哈希表的性能。
vector 的迭代器在什么情况下会失效?
- 插入操作导致的失效:当在
vector中插入元素时,如果插入操作导致了内存的重新分配,那么所有指向该vector的迭代器都会失效。因为重新分配内存后,vector中的元素可能会被移动到新的内存地址,原有的迭代器指向的位置就不再有效。即使插入操作没有导致内存重新分配,但如果在插入位置之前的迭代器,在插入后可能仍然指向原来的元素,但这些元素的相对位置可能已经改变,所以在使用这些迭代器时需要谨慎。 - 删除操作导致的失效:当删除
vector中的元素时,指向被删除元素的迭代器以及该迭代器之后的所有迭代器都会失效。因为删除元素后,后面的元素会向前移动填补被删除元素的位置,导致迭代器指向的位置发生变化。 - 容量变化导致的失效:当调用
vector的resize、reserve等函数改变vector的容量时,如果容量发生了变化,那么所有的迭代器都会失效。因为这些操作可能会导致内存的重新分配和元素的移动。 - 范围外的操作导致的失效:如果使用迭代器进行越界访问,或者在迭代器已经到达
vector末尾之后继续使用,那么迭代器就会失效。这种情况下,程序的行为是未定义的,可能会导致程序崩溃或产生错误的结果。
C++11 相比 C++98 新增了哪些重要特性?(除了 auto 和智能指针)
C++11 新增了许多重要特性。首先是右值引用,它解决了 C++98 中临时对象的效率问题,通过引入 && 符号表示右值引用,实现了移动语义和完美转发,使得在对象赋值、传递等操作中可以避免不必要的拷贝,提高了程序的运行效率。例如,在函数返回值为大对象时,使用右值引用可以直接将临时对象的资源转移给接收者,而不是进行拷贝。
其次是 lambda 表达式,它允许在代码中直接定义匿名函数,方便了在需要函数对象的地方快速创建简单的函数。比如在对容器进行排序时,可以直接使用 lambda 表达式指定排序规则,而不必再单独定义一个函数或函数对象。
还有初始化列表,它可以对数组、结构体、类等进行更简洁的初始化。例如,在创建一个包含多个元素的数组时,可以使用初始化列表一次性完成初始化,使代码更加清晰易懂。
另外,C++11 还引入了线程库,使得多线程编程更加方便和安全,不再需要依赖操作系统的原生线程 API。同时,类型推导功能除了 auto 外,还有 decltype,它可以根据表达式推导出变量的类型,在模板编程等场景中非常有用。
const 关键字的作用和用法是什么?特别是在类函数中的使用方法。
const 关键字主要有两个作用,一是修饰变量,表示该变量的值不能被修改,二是修饰函数,表示该函数不会修改类的成员变量。
在修饰变量时,例如 const int a = 10;,定义了一个常量 a,在程序运行期间其值不能被改变。对于指针,const 可以修饰指针本身或指针所指向的值,如 const int *p 表示指针 p 所指向的整数是常量,不能通过 p 修改其指向的值;而 int * const p 则表示指针 p 本身是常量,不能再指向其他地址。
在类中,const 关键字常用于修饰成员函数。在类的成员函数后面加上 const 关键字,表示该函数不会修改类的成员变量。例如,在一个表示矩形的类中,有一个计算面积的函数,它不需要修改矩形的长和宽等成员变量,就可以将其声明为 const 成员函数。这样可以保证在调用该函数时,不会意外地修改类的状态,同时也使得该函数可以被 const 对象调用。
static 关键字的用法有哪些?为什么类的静态成员函数内部只能使用静态变量?
static 关键字有多种用法。在函数内部,它可以定义静态局部变量,该变量在函数第一次调用时初始化,并且在函数调用结束后仍然存在,其生存期贯穿整个程序运行期间,但作用域仍然局限于函数内部。例如,在一个递归函数中,可以使用静态局部变量来记录递归的深度。
在类中,static 可以修饰成员变量和成员函数。静态成员变量属于类所有,而不属于类的某个具体对象,所有对象共享同一个静态成员变量。它在类的所有对象之外单独存储,只有一份副本。静态成员函数也不依赖于类的具体对象,只能访问类的静态成员变量和静态成员函数,不能访问非静态成员变量和非静态成员函数。
类的静态成员函数内部只能使用静态变量,这是因为静态成员函数不与类的具体对象相关联,没有 this 指针,无法确定要访问哪个对象的非静态成员变量和非静态成员函数。而静态变量是属于类的,在内存中只有一份,不依赖于具体对象,所以静态成员函数可以安全地访问静态变量。
new/delete 和 malloc/free 的用法和区别是什么?
new 和 delete 是 C++ 中的运算符,malloc 和 free 是 C 语言中的函数。
new 的用法是先分配内存,然后调用对象的构造函数进行初始化。例如,int *p = new int (10); 不仅分配了足够存储一个 int 类型的内存空间,还将该空间初始化为 10。delete 则用于释放 new 分配的内存,并调用对象的析构函数进行清理工作,如 delete p;。
malloc 的用法是 void *p = malloc (sizeof (int)); 它只负责分配指定大小的内存空间,不会进行初始化。free 则用于释放 malloc 分配的内存,如 free (p);。
它们的区别主要体现在以下几个方面。首先,new/delete 是 C++ 的运算符,具有类型安全性,会自动调用构造函数和析构函数,而 malloc/free 是 C 语言的函数,需要手动计算内存大小,且不会调用构造函数和析构函数。其次,new 可以进行更复杂的内存分配,如分配数组 new int [10]; 而 malloc 分配数组时需要手动计算总字节数。另外,new 返回的是指定类型的指针,而 malloc 返回的是 void * 类型的指针,需要进行强制类型转换。最后,在处理自定义类型时,new/delete 能更好地与类的特性结合,而 malloc/free 则相对较为简单直接,但缺乏对对象生命周期的管理。
指针和引用有什么区别?如何引用一个指针?
指针和引用有很多区别。首先,指针是一个变量,存储的是另一个变量的地址,可以通过指针间接访问所指向的变量,而引用是一个变量的别名,它本身不是一个独立的变量,而是对已存在变量的另一种称呼,使用引用就相当于直接使用原变量。
其次,指针可以在定义时不初始化,也可以在程序运行过程中改变其指向的地址,而引用在定义时必须初始化,并且一旦初始化后就不能再引用其他变量。例如,int *p; 是合法的,而 int &r; 是不合法的,必须在定义时就指定引用的对象,如 int a = 10; int &r = a;。
在内存占用上,指针本身需要占用一定的内存空间来存储地址,而引用在内存中并不占用额外的空间,它只是原变量的一个别名。
另外,指针可以进行算术运算,如指针的偏移、指针之间的减法等,而引用不可以进行算术运算。
引用一个指针有两种情况。一种是定义一个指针的引用,例如 int *p = new int (10); int *&rp = p; 这里 rp 就是指针 p 的引用,通过 rp 可以间接修改 p 的值。另一种是在函数参数传递中,将指针作为参数传递给函数,在函数内部可以通过引用该指针来修改指针所指向的值或指针本身的值。例如,void fun (int *&p) { *p = 20; p = new int (30); } 在调用该函数时,传入的指针可以在函数内部被修改。
指针和数组之间有什么关系?
指针和数组在 C++ 中有密切的关系。数组名在很多情况下可以看作是一个指针常量,它指向数组的首元素地址。例如,对于一个数组int arr[5],arr就相当于&arr[0],这意味着可以使用指针的方式来访问数组元素,如*(arr + 1)和arr[1]是等价的,它们都表示访问数组arr的第二个元素。
在函数参数传递中,数组会退化为指针。当把一个数组作为函数参数传递时,实际上传递的是数组的首地址,在函数内部,无法直接获取数组的大小,需要额外传递数组的长度信息。而指针可以指向数组中的任意元素,通过指针的移动和间接访问操作,可以灵活地操作数组中的数据。
另外,使用new操作符可以在堆上动态分配数组空间,并返回指向该数组首元素的指针,通过这个指针可以像使用普通数组一样访问和操作动态分配的数组元素。但需要注意的是,在使用完毕后,要使用delete []来释放动态分配的数组内存,以避免内存泄漏。
指针和数组的区别也很明显。数组在定义时就确定了大小和内存空间,而指针只是一个存储地址的变量,可以在运行时指向不同的内存地址。数组名是常量指针,不能进行赋值操作,而指针变量可以在程序运行过程中改变所指向的地址。
请解释堆和栈的使用,以及系统内部是如何分配堆栈的?
栈是一种由编译器自动分配和释放的内存区域,主要用于存储函数调用时的局部变量、函数参数、返回地址等。当一个函数被调用时,函数的局部变量和参数会被压入栈中,函数执行完毕后,这些变量会按照后进先出的顺序依次出栈,自动释放内存。栈的内存分配和释放是由编译器自动完成的,不需要程序员手动干预,具有较高的效率和安全性。栈的大小通常是有限的,在不同的系统和编译器中可能会有所不同,如果栈空间使用过多,可能会导致栈溢出错误。
堆是由程序员手动分配和释放的内存区域,用于存储动态分配的数据,如通过new操作符分配的对象或数组等。在堆上分配内存时,程序员需要使用delete或delete []操作符显式地释放内存,否则会导致内存泄漏。堆的内存空间相对较大,但分配和释放内存的速度相对较慢,因为需要进行更多的系统调用和内存管理操作。
系统内部对栈的分配是连续的内存空间,随着函数的调用和返回,栈指针会自动移动,实现内存的分配和释放。而堆的分配则相对复杂,系统会维护一个空闲内存块的链表,当需要分配内存时,会在链表中查找合适大小的空闲块进行分配,如果没有合适的块,则可能会进行内存碎片整理或向操作系统请求更多的内存。
内存中的几个区域(如.bss、.data 区)分别存储什么内容?
在 C++ 程序的内存布局中,通常有以下几个主要区域:
- .text 区:也称为代码区,用于存储程序的可执行代码,即函数的指令序列。这个区域的内容是只读的,在程序运行期间不会被修改。
- .data 区:用于存储已经初始化的全局变量和静态变量。这些变量在程序启动时就被初始化,并且在整个程序的运行过程中保持其初始值不变,直到程序结束。
- .bss 区:用于存储未初始化的全局变量和静态变量。这些变量在程序启动时会被自动初始化为 0 或空值,它们在程序运行期间占用内存空间,但不需要在可执行文件中存储初始值,从而减小了可执行文件的大小。
- 堆区:由程序员手动分配和释放的内存区域,用于存储动态分配的数据,如通过
new操作符分配的对象或数组等。 - 栈区:主要用于存储函数调用时的局部变量、函数参数、返回地址等。
此外,还有一些其他的内存区域,如常量区,用于存储常量字符串和常量数据等;程序运行时还可能会有动态链接库的内存区域等。
为什么析构函数通常要设计为虚函数?
在 C++ 中,析构函数通常被设计为虚函数主要是为了实现多态的资源释放和避免内存泄漏等问题。
当通过基类指针或引用指向派生类对象时,如果析构函数不是虚函数,那么在删除基类指针或引用时,只会调用基类的析构函数,而不会调用派生类的析构函数。这可能导致派生类中动态分配的资源无法得到正确释放,从而引发内存泄漏。
例如,有一个基类Base和一个派生类Derived,Derived类中动态分配了一些资源,如果Base类的析构函数不是虚函数,当通过Base类指针删除Derived类对象时,只会调用Base类的析构函数,Derived类中动态分配的资源就不会被释放。
而将析构函数设计为虚函数后,当通过基类指针或引用删除对象时,会根据对象的实际类型调用相应的析构函数,先调用派生类的析构函数,再调用基类的析构函数,从而保证了整个对象的资源能够得到正确释放,实现了多态的资源管理和清理,提高了代码的安全性和可维护性。
C++ 中的 struct 和 class 有什么区别?class 能否继承 struct?
在 C++ 中,struct和class主要有以下区别:
- 默认访问权限:在
struct中,默认的成员访问权限是public,而在class中,默认的成员访问权限是private。这意味着在struct中,成员变量和成员函数默认可以在外部访问,而在class中,默认情况下成员变量和成员函数只能在类内部访问。 - 继承方式:
struct默认的继承方式是public继承,而class默认的继承方式是private继承。这会影响到派生类对基类成员的访问权限和继承关系。 - 用途:一般来说,
struct常用于表示简单的数据结构,如存储一组相关的数据成员,通常不需要太多的成员函数和复杂的行为。而class则更常用于表示具有复杂行为和状态的对象,包含成员函数、构造函数、析构函数等,用于实现对象的封装、继承和多态等特性。
在 C++ 中,class可以继承struct,反之亦然。因为在 C++ 中,struct和class的本质区别主要在于默认的访问权限和继承方式,它们都可以作为基类或派生类来参与继承关系,只要遵循继承的语法规则和访问权限控制即可。
一个空的 class 占用多少内存?
在 C++ 中,一个空的 class 通常也会占用 1 个字节的内存空间。这主要是出于对象标识和内存布局的考量。从对象标识角度来说,即使类中没有定义任何成员变量和成员函数,为了能让不同的对象在内存中有唯一的表示,编译器需要给它分配一定的空间来区分不同的实例。比如在创建一个空类对象的数组时,如果空类不占任何内存,那数组中的多个对象就没办法在内存中进行区分和定位了。
从内存布局来看,C++ 中对象在内存中的放置需要遵循一定的规则,为了保证对象地址的连续性以及后续可能的继承、多态等机制能正常运转,即使是空类,也会分配最少 1 个字节的空间。不过不同的编译器在处理空类内存占用时可能存在细微差异,部分编译器在一些特定的优化场景下,若明确知道空类对象不会参与一些需要实际内存地址区分的操作(比如放入数组等情况),可能会采用一些特殊的处理方式,看似没有分配那 1 个字节,但只要涉及到常规的对象使用场景,基本都会保证其至少有 1 个字节的内存占用,以此来符合 C++ 对象模型的基本逻辑。
C++ 虚函数的机制是怎样的?
C++ 虚函数实现多态的核心机制是通过虚函数表(vtable)和虚指针(vptr)来达成的。当一个类中声明了虚函数时,编译器会为这个类创建一个虚函数表。这个虚函数表本质上就是一个函数指针数组,里面依次存放着该类中所有虚函数的地址。
然后,在类的每个对象的内存布局中,会额外包含一个虚指针(通常位于对象内存的开头部分),这个虚指针指向所属类的虚函数表。当通过基类指针或者引用去调用虚函数时,实际上是先通过对象中的虚指针找到对应的虚函数表,再依据虚函数在表中的偏移位置来确定具体要调用的虚函数版本。
例如,有基类 Base 和派生类 Derived,Base 类中有虚函数 func (),Derived 类重写了这个虚函数。当创建一个 Derived 类的对象,并用 Base 类指针指向它时,通过这个 Base 指针调用 func (),会根据对象中的虚指针找到 Derived 类的虚函数表,进而调用 Derived 类重写后的 func () 函数,实现了多态的行为。而且,这种机制在运行时动态决定调用哪个类的虚函数,使得程序可以根据对象的实际类型做出正确的响应,极大地增强了代码的灵活性和可扩展性,尤其是在处理继承层次结构比较复杂的情况时非常有用。
const 与 #define 有什么区别?
首先,从语法和语义层面来看,const 是 C++ 中的一个关键字,用于定义常量,它有明确的类型信息。例如,const int num = 10; 这里明确表示 num 是一个 int 类型的常量,其值不能被修改,并且编译器会对其进行类型检查,保证使用方式符合 int 类型常量的规则。而 #define 是 C 语言中的预处理器指令,它只是简单地进行文本替换,不存在类型的概念。比如 #define PI 3.1415926,预处理器在处理代码时,只要遇到 PI 这个标识符,就会直接替换成 3.1415926,不会进行类型相关的检查。
其次,在作用域方面,const 定义的常量有明确的作用域规则,遵循 C++ 的块级作用域、类作用域等规则。比如在一个函数内部定义的 const 常量,只在该函数内有效;在类中定义的 const 成员变量,其作用域就是整个类内部等。而 #define 定义的宏没有像这样严格的作用域限制,它从定义的地方开始,在后续的预处理阶段的文本中都会进行替换,除非被 #undef 取消定义,所以很容易出现命名冲突等问题,需要特别小心使用范围,避免意外的替换情况。
再者,从调试角度来说,const 定义的常量在调试时,其信息可以被编译器更好地识别和展示,因为它是程序代码逻辑中的一部分,有类型等相关信息辅助调试。而 #define 定义的宏在调试时相对比较麻烦,因为它只是文本替换,很难直接追踪其替换后的具体情况以及对程序逻辑的影响。
另外,在处理复杂表达式方面,const 可以用于定义复杂类型的常量,比如 const std::string str = "hello";,并且可以参与一些运算、函数调用等符合其类型规则的操作。而 #define 只是简单替换文本,如果宏定义的内容涉及复杂运算等情况,很容易出现意外错误,因为替换过程可能不符合预期的运算优先级等规则,需要谨慎地加上括号等进行保护。
使用 new 分配的内存能否用 free 释放?
在 C++ 中,使用 new 分配的内存不能用 free 来释放,这样做会导致程序出现错误行为甚至崩溃。
new 操作符在 C++ 里不仅仅是简单地分配内存,它还会调用对象的构造函数来进行初始化工作。例如,当使用 new 创建一个自定义类的对象时,会先为对象分配足够的内存空间,然后调用该类的构造函数来初始化对象内部的成员变量等,让对象处于一个可用的初始状态。而 delete 操作符与之对应,它会先调用对象的析构函数进行清理工作,比如释放对象中动态分配的资源等,然后再释放内存空间。
free 函数来自 C 语言,它仅仅只是负责释放指定大小的内存块,它不会去执行任何构造函数或者析构函数相关的操作。如果用 free 去释放 new 分配的内存,那么对象的析构函数就不会被调用,对于那些在对象内部有动态分配资源的情况,这些资源就没办法正常回收,进而导致内存泄漏等问题。而且,从内存管理的底层机制来说,new 和 delete 在 C++ 中遵循一套特定的内存分配和释放规则,与 C 语言中 malloc 和 free 所遵循的规则并不完全兼容,随意混用会破坏这种内存管理的协调性,使得内存的状态变得不可控,最终影响程序的正常运行。
什么时候会出现 time_wait 状态?
在 TCP 连接中,当主动关闭连接的一方发送最后一个 ACK 确认报文段后,会进入 TIME_WAIT 状态,通常持续 2MSL(Maximum Segment Lifetime,最大报文段生存时间)时长。出现 TIME_WAIT 状态主要有以下几种情况:
首先,正常的 TCP 连接关闭过程中,主动关闭方在发送完对被动关闭方 FIN 的 ACK 确认后进入 TIME_WAIT 状态。这是为了确保被动关闭方能够收到 ACK 确认,如果被动关闭方没有收到 ACK,会在超时后重发 FIN,而主动关闭方在 TIME_WAIT 状态可以再次响应这个 FIN,从而保证连接的可靠关闭,防止上一次连接中的数据包在网络中延迟到达后干扰新的连接。
其次,当连接出现异常中断,如网络故障、进程崩溃等,操作系统无法正常完成四次挥手过程,也可能导致主动关闭方进入 TIME_WAIT 状态,以等待可能延迟到达的数据包,避免对后续连接产生影响。
另外,在一些高并发的服务器场景中,如果服务器频繁地建立和关闭连接,也会频繁出现 TIME_WAIT 状态。因为服务器作为主动关闭方关闭连接后,会进入 TIME_WAIT 状态等待一段时间,以确保网络中可能残留的该连接的数据包都能被正确处理。
如果系统中存在大量的 time_wait 状态,应该如何处理?
当系统中存在大量 TIME_WAIT 状态时,可以采取以下几种方法进行处理:
- 调整内核参数:通过修改内核参数 “tcp_tw_reuse” 和 “tcp_tw_recycle” 来优化 TIME_WAIT 状态的处理。“tcp_tw_reuse” 参数允许处于 TIME_WAIT 状态的连接被新的连接复用,前提是新连接的时间戳大于之前连接的时间戳,这样可以减少 TIME_WAIT 状态连接的数量。“tcp_tw_recycle” 参数则更加激进,它会快速回收处于 TIME_WAIT 状态的连接,但在某些情况下可能会导致一些问题,如 NAT 环境下可能出现连接异常,需要谨慎使用。
- 优化应用程序:在应用程序层面,可以通过长连接代替短连接的方式来减少连接的频繁建立和关闭,从而降低 TIME_WAIT 状态的出现频率。对于一些高并发的服务器,可以使用连接池技术,预先创建一定数量的连接并重复使用,避免频繁地创建和销毁连接。
- 增加系统资源:如果系统硬件资源允许,可以考虑增加系统的内存和网络带宽等资源,以提高系统的并发处理能力,减少因资源不足导致的连接积压和 TIME_WAIT 状态的大量出现。
- 负载均衡:采用负载均衡技术将连接均匀地分发到多个服务器上,避免单个服务器承受过多的连接请求,从而减少每个服务器上 TIME_WAIT 状态的数量。
解释拥塞控制和流量控制的概念。
拥塞控制和流量控制都是网络传输中的重要机制,用于确保网络的高效稳定运行,但它们的作用和目标有所不同。
拥塞控制主要是为了防止网络出现拥塞现象,避免过多的数据注入网络而导致网络性能下降甚至瘫痪。它是一种全局性的控制机制,涉及到网络中的所有节点和链路。当网络中的路由器或链路出现拥塞时,如队列已满、丢包率增加等,拥塞控制机制会通过调整发送方的发送速率来缓解拥塞。常见的拥塞控制算法有慢启动、拥塞避免、快重传和快恢复等。在慢启动阶段,发送方会以指数增长的方式增加发送窗口大小,快速探测网络的可用带宽;当检测到网络拥塞时,会进入拥塞避免阶段,缓慢增加发送窗口大小;快重传和快恢复则是在出现丢包等拥塞迹象时,快速调整发送窗口大小,以尽快恢复网络的正常传输。
流量控制则是为了控制发送方的发送速率,使其不超过接收方的接收能力,确保接收方能够及时处理接收到的数据,避免数据丢失。它是一种端到端的控制机制,主要在发送方和接收方之间进行。接收方会通过向发送方发送反馈信息,如窗口大小通知等,告知发送方自己的接收能力。发送方根据接收方的反馈信息调整自己的发送窗口大小,从而控制发送速率,保证接收方不会因为接收缓冲区溢出而丢失数据。
如何查看 Linux 系统的内存使用情况?
在 Linux 系统中,可以使用多种命令来查看内存使用情况:
- free 命令:这是最常用的查看内存使用情况的命令之一。它可以显示系统的物理内存、交换空间的使用情况,包括总内存、已使用内存、空闲内存、共享内存、缓存和缓冲等信息。例如,在终端中输入 “free -h” 命令,会以人类可读的格式显示内存使用情况,如以 GB、MB 等单位显示内存大小,方便用户快速了解系统内存的大致使用情况。
- top 命令:top 命令不仅可以查看系统的 CPU 使用率,还可以实时显示系统的内存使用情况。在 top 命令的输出中,有专门的区域显示内存的使用情况,包括总内存、已使用内存、空闲内存、缓存和缓冲等信息,同时还会显示各个进程占用的内存情况,方便用户了解系统整体的内存使用情况以及各个进程对内存的占用情况,从而及时发现内存占用过高的进程。
- vmstat 命令:vmstat 命令可以提供更详细的系统内存和虚拟内存的统计信息,包括内存的读写情况、交换空间的使用情况、内存分页情况等。通过分析 vmstat 命令输出的信息,可以了解系统内存的使用趋势和性能瓶颈,例如,如果 swap in 和 swap out 的值较高,说明系统可能存在内存不足的情况,需要进一步分析和优化。
- cat /proc/meminfo 命令:该命令可以查看系统内存的详细信息,包括系统总内存、可用内存、缓存内存、缓冲内存、交换空间大小等各种内存相关的参数。这些信息对于深入了解系统内存的使用情况和进行性能调优非常有帮助,但输出的信息较为详细和复杂,需要对 Linux 内存管理有一定的了解才能更好地理解和分析。
如何查看 Linux 系统的 CPU 使用率?
在 Linux 系统中,有多种方法可以查看 CPU 使用率:
- top 命令:top 命令是最常用的查看系统资源使用情况的命令之一,其中就包括 CPU 使用率。在终端中输入 “top” 命令后,会实时显示系统各个进程的 CPU 使用率以及系统整体的 CPU 使用率。在 top 命令的输出中,有专门的区域显示 CPU 的使用情况,包括用户空间占用 CPU 的百分比、内核空间占用 CPU 的百分比、空闲 CPU 的百分比等,同时还会显示各个进程占用 CPU 的具体百分比,方便用户快速了解系统 CPU 的使用情况以及哪个进程占用了较多的 CPU 资源。
- mpstat 命令:mpstat 命令可以提供更详细的 CPU 使用情况统计信息,特别是在多核心 CPU 系统中。它可以显示每个 CPU 核心的使用率、CPU 在用户态、内核态、空闲态等不同状态下的时间占比等。例如,在终端中输入 “mpstat -P ALL 1” 命令,会每隔 1 秒显示一次所有 CPU 核心的使用情况,包括每个核心的用户态使用率、内核态使用率、空闲态使用率等,方便用户了解各个 CPU 核心的负载情况,对于分析多核心 CPU 系统的性能和排查 CPU 相关的问题非常有帮助。
- sar 命令:sar 命令是一个系统活动报告工具,可以收集和报告系统的各种性能数据,包括 CPU 使用率。通过使用 “sar -u” 命令,可以查看系统在指定时间段内的 CPU 使用率情况,它会以一定的时间间隔记录 CPU 在用户态、内核态、空闲态等的使用率,并以表格的形式输出,方便用户进行历史数据分析和性能趋势观察,对于长期监控系统的 CPU 使用情况和发现潜在的 CPU 性能问题非常有用。
- ps 命令:ps 命令主要用于查看系统中的进程信息,但也可以通过一些参数来查看进程的 CPU 使用率。例如,在终端中输入 “ps -aux” 命令,会显示系统中所有进程的详细信息,其中包括每个进程的 CPU 使用率。通过查看各个进程的 CPU 使用率,可以了解哪些进程占用了较多的 CPU 资源,从而进一步分析和优化系统性能。
检查内存泄露的工具有哪些?
在 C++ 中,常用的检查内存泄露的工具有以下几种:
-
Valgrind:这是一款功能强大的开源内存调试和性能分析工具,它可以检测多种内存问题,包括内存泄露、越界访问、使用未初始化的内存等。在使用时,只需在编译好的程序前加上 valgrind 命令,它会在程序运行过程中监控内存的分配和释放情况,并在程序结束后生成详细的报告,指出可能存在的内存泄露位置和原因。例如,对于一个简单的 C++ 程序存在内存泄露,Valgrind 会准确地指出在哪个函数中分配的内存没有被释放以及泄露的字节数等信息。
-
AddressSanitizer(ASan):这是 GCC 和 Clang 编译器自带的一种内存错误检测工具,主要用于检测内存越界访问、使用已释放的内存、栈缓冲区溢出等问题,同时也能检测内存泄露。它通过在编译时对代码进行 instrumentation,在运行时检查内存访问的合法性,一旦发现问题就会立即报告错误并输出详细的栈跟踪信息,帮助开发者快速定位问题所在。
-
Visual Leak Detector(VLD):这是专门为 Visual C++ 设计的一款内存泄露检测工具,它可以与 Visual Studio 集成,在调试模式下运行程序时,能够自动检测并报告内存泄露情况。VLD 会在程序退出时列出所有未释放的内存块,包括分配的内存地址、大小、分配的位置等信息,方便开发者快速定位和解决内存泄露问题。
-
Cppcheck:这是一个静态分析工具,除了可以检查语法错误、代码风格问题外,还可以检测一些潜在的内存泄露问题。它通过对源代码进行分析,识别出可能导致内存泄露的代码模式,如未释放的动态分配内存、未正确关闭的文件或网络连接等。虽然它不能像 Valgrind 等工具那样在运行时检测内存泄露,但可以在代码编写阶段就发现一些潜在的问题,提高代码的质量。
Linux 下删除文件和文件夹的命令是什么?
在 Linux 系统中,删除文件和文件夹的常用命令有以下几个:
-
rm 命令:用于删除文件或目录。删除文件时,直接使用 “rm 文件名” 即可,例如 “rm test.txt” 将删除当前目录下的 test.txt 文件。如果要删除目录,需要加上 - r 或 - R 选项,用于递归删除目录及其内容,如 “rm -r dirname” 或 “rm -R dirname”,这将删除 dirname 目录以及其下的所有文件和子目录。如果要强制删除,不提示确认,可以加上 - f 选项,如 “rm -rf dirname”,但使用此命令时要特别小心,以免误删重要数据。
-
rmdir 命令:只能用于删除空目录,如果目录不为空,则会提示 “Directory not empty” 错误。例如 “rmdir emptydir” 可以删除名为 emptydir 的空目录。
如何修改 Linux 文件的权限?
在 Linux 系统中,可以使用 chmod 命令来修改文件或目录的权限,主要有两种方式:
-
符号模式:使用字母和符号来表示不同的权限设置。例如,“chmod u+rwx,g+rx,o+rx file.txt” 表示给文件 file.txt 的所有者添加读、写、执行权限,给所属组添加读、执行权限,给其他用户添加读、执行权限。其中,u 表示所有者,g 表示所属组,o 表示其他用户,a 表示所有用户;+ 表示添加权限,- 表示删除权限,= 表示设置权限;r 表示读权限,w 表示写权限,x 表示执行权限。还可以使用多个权限组合,如 “chmod ug+w,o-rwx file.txt” 表示给所有者和所属组添加写权限,同时删除其他用户的所有权限。
-
数字模式:使用三位八进制数字来表示权限,每一位数字分别对应所有者、所属组和其他用户的权限。例如,“chmod 755 file.txt”,其中 7 表示所有者具有读、写、执行权限(4+2+1),5 表示所属组具有读、执行权限(4+1),5 表示其他用户具有读、执行权限(4+1)。常用的权限数字组合有 777(所有用户都具有读、写、执行权限)、644(所有者具有读、写权限,所属组和其他用户具有读权限)、750(所有者具有读、写、执行权限,所属组具有读、执行权限,其他用户无权限)等。
请解释操作系统的内存管理机制。
操作系统的内存管理机制主要负责对内存资源进行合理的分配、使用和回收,以确保多个程序能够高效、安全地共享内存,其主要包括以下几个方面:
-
内存分配:操作系统需要为每个进程分配足够的内存空间,以保证进程能够正常运行。常见的内存分配方式有连续分配和离散分配。连续分配方式包括单一连续分配、固定分区分配和动态分区分配等,这种方式将内存划分为连续的区域,每个进程占用一个连续的内存块。离散分配方式则包括分页存储管理、分段存储管理和段页式存储管理等,它将内存划分为较小的单元,如页或段,进程的内存空间可以分散在不同的单元中,提高了内存的利用率。
-
内存保护:为了防止不同进程之间相互干扰和破坏,操作系统需要提供内存保护机制。通常采用的方法是设置内存访问权限,每个进程只能访问自己的内存空间,对其他进程的内存空间进行访问限制。例如,在分页存储管理中,通过页表中的访问权限位来控制对页面的读写执行权限,当进程试图访问超出其权限范围的内存时,操作系统会捕获并处理该异常,防止非法访问。
-
内存共享:允许多个进程共享同一段内存区域,以提高内存的利用率和实现进程间的通信。例如,多个进程可以共享同一个动态链接库的代码段,这样可以避免在内存中重复存储相同的代码,节省内存空间。操作系统通过维护共享内存区域的引用计数和访问控制等机制,确保共享内存的正确使用和安全性。
-
内存回收:当进程结束或不再需要使用某些内存空间时,操作系统需要及时回收这些内存,以便重新分配给其他进程。内存回收的方式主要有两种,一种是显式回收,即进程主动释放其占用的内存,如通过调用 free 或 delete 等函数;另一种是隐式回收,由操作系统在进程结束时自动回收其所有占用的内存资源。
为什么需要虚拟内存?
虚拟内存是操作系统为了满足多任务环境下对内存的高效利用和管理而引入的一种技术,其主要原因有以下几点:
-
地址空间隔离:在多任务操作系统中,多个进程同时运行,如果没有虚拟内存,每个进程都直接访问物理内存,那么很容易出现一个进程意外地访问或修改其他进程的内存空间,导致系统不稳定和数据安全问题。虚拟内存为每个进程提供了独立的、从零开始的虚拟地址空间,使得每个进程都认为自己拥有整个内存空间,而实际上这些虚拟地址空间是通过操作系统的内存管理机制映射到物理内存的不同区域,从而实现了进程之间的地址空间隔离,提高了系统的安全性和稳定性。
-
内存扩充:物理内存的容量是有限的,而现代应用程序对内存的需求却越来越大。虚拟内存可以将磁盘空间作为内存的扩展,当物理内存不足时,操作系统可以将暂时不使用的内存数据交换到磁盘上的交换空间(swap 空间),从而为当前运行的程序腾出更多的物理内存空间。这样,从应用程序的角度看,它似乎拥有比实际物理内存更大的内存空间,使得系统能够同时运行更多的程序或处理更大规模的数据,提高了系统的整体性能和资源利用率。
-
内存共享和保护:虚拟内存使得多个进程可以共享同一段物理内存,通过页表等机制可以方便地控制对共享内存的访问权限,实现进程间的高效通信和数据共享。同时,操作系统可以根据不同的需求为每个进程设置不同的内存访问权限,如只读、读写、可执行等,从而有效地保护了内存中的数据和代码,防止非法访问和修改。
-
方便程序的编写和调试:在编写程序时,程序员不需要关心物理内存的实际分配情况,只需要使用虚拟地址进行编程。虚拟内存提供了一种统一的、连续的地址空间,使得程序员可以更方便地组织和管理程序的内存结构,降低了编程的复杂性。在调试程序时,虚拟内存也使得调试工具能够更方便地跟踪和分析程序的内存使用情况,提高了调试的效率。
TCP 三次握手的过程是怎样的?为什么不能是两次或四次?
TCP 三次握手的过程如下:
- 第一次握手:客户端向服务器发送一个 SYN(同步)包,其中包含客户端的初始序列号(ISN),并进入 SYN_SENT 状态,此时客户端请求建立连接。
- 第二次握手:服务器收到客户端的 SYN 包后,会向客户端发送一个 SYN/ACK 包,其中包含服务器的初始序列号和对客户端 SYN 的确认号(ACK),确认号为客户端的 ISN 加 1,服务器进入 SYN_RCVD 状态,表示服务器同意建立连接并等待客户端的确认。
- 第三次握手:客户端收到服务器的 SYN/ACK 包后,会向服务器发送一个 ACK 包,确认号为服务器的 ISN 加 1,客户端进入 ESTABLISHED 状态,此时客户端和服务器都进入了连接建立状态,可以开始进行数据传输。

TCP 三次握手不能是两次的原因主要是为了防止已失效的连接请求报文段突然又传送到了服务器,从而产生错误。如果只有两次握手,当客户端发送的第一个连接请求在网络中滞留,客户端超时后重新发送连接请求并成功建立连接,而服务器在收到第一个滞留的连接请求后会认为客户端又发起了一次新的连接请求,从而导致错误的连接建立。
TCP 三次握手也不能是四次,因为三次握手已经能够完成双方的连接确认和初始化序列号的交换,足以确保连接的可靠性和双方的同步。四次握手会增加不必要的复杂性和延迟,而不会带来更多的好处。
TCP 四次挥手的过程是怎样的?为什么不能是三次?
TCP 四次挥手的过程如下:
- 第一次挥手:主动关闭方(通常是客户端)发送一个 FIN(结束)包,表示客户端不再发送数据,但仍可以接收数据,客户端进入 FIN_WAIT_1 状态。
- 第二次挥手:被动关闭方(通常是服务器)收到 FIN 包后,发送一个 ACK 包给客户端,确认收到客户端的 FIN 包,服务器进入 CLOSE_WAIT 状态,此时客户端进入 FIN_WAIT_2 状态,客户端到服务器的连接关闭,但服务器到客户端的连接仍然存在,服务器可能还有未发送完的数据需要继续发送给客户端。
- 第三次挥手:服务器发送完所有数据后,向客户端发送一个 FIN 包,表示服务器也不再发送数据,服务器进入 LAST_ACK 状态。
- 第四次挥手:客户端收到服务器的 FIN 包后,发送一个 ACK 包给服务器,确认收到服务器的 FIN 包,客户端进入 TIME_WAIT 状态,等待 2MSL(最长报文段寿命)后进入 CLOSED 状态,服务器收到客户端的 ACK 包后,立即进入 CLOSED 状态,至此双方的连接完全关闭。

TCP 四次挥手不能是三次的原因主要是因为在第二次挥手时,服务器收到客户端的 FIN 包后,可能还有未发送完的数据需要继续发送给客户端,所以不能立即关闭连接,需要先发送 ACK 包确认收到客户端的 FIN 包,然后在数据发送完毕后再发送 FIN 包给客户端,因此需要四次挥手来确保双方的数据都能正确传输和连接的正常关闭。
TCP 和 UDP 的主要区别是什么?

TCP 和 UDP 的主要区别如下:
- 连接性:TCP 是面向连接的协议,在数据传输之前需要先建立连接,数据传输完成后需要释放连接;UDP 是无连接的协议,发送数据之前不需要建立连接,直接将数据发送给目标主机。
- 可靠性:TCP 提供可靠的数据传输服务,通过序列号、确认号、重传机制等确保数据的顺序和完整性;UDP 不保证数据的可靠传输,数据可能会丢失、重复或乱序。
- 传输效率:由于 TCP 需要进行连接建立、维护和拆除等操作,并且有可靠传输机制,所以传输效率相对较低;UDP 没有这些额外的开销,传输效率相对较高。
- 应用场景:TCP 适用于对数据传输可靠性要求较高的场景,如文件传输、电子邮件、网页浏览等;UDP 适用于对实时性要求较高但对可靠性要求相对较低的场景,如视频会议、实时游戏、音频流等。
- 报文结构:TCP 的报文头较长,包含了序列号、确认号、窗口大小等多个字段,用于实现可靠传输和流量控制等功能;UDP 的报文头较短,只包含源端口、目的端口、长度和校验和等基本字段。
计算机网络基础中的网络分层是什么?视频会议的网络传输流程是如何实现的?
计算机网络分层是将网络通信的功能划分为不同的层次,每一层都有特定的功能和职责,并且为上一层提供服务,同时利用下一层的服务来实现自己的功能。常见的网络分层模型有 OSI 七层模型和 TCP/IP 四层模型。
视频会议的网络传输流程实现如下:
- 应用层:视频会议应用程序负责采集视频和音频数据,进行编码和压缩,然后将数据封装成应用层协议报文,如 RTP(实时传输协议)或 RTSP(实时流传输协议)报文,通过调用传输层的服务将数据发送出去。
- 传输层:根据应用层的需求,选择使用 TCP 或 UDP 协议。对于视频会议,通常优先选择 UDP 协议,因为 UDP 具有较低的延迟和较高的传输效率,能够更好地满足实时性要求。在 UDP 之上,可能还会使用一些应用层协议来实现数据的可靠传输和拥塞控制等功能。
- 网络层:主要负责将数据从源主机传输到目标主机,通过 IP 协议进行寻址和路由选择,将数据封装成 IP 数据包,并在网络中进行转发。
- 数据链路层:将网络层的 IP 数据包封装成数据链路层帧,通过物理层的网络接口发送出去。在数据链路层,还会进行差错检测和纠正等操作。
- 物理层:负责将数据链路层的帧转换为物理信号,在传输介质上进行传输,如通过光纤、双绞线等传输介质将信号传输到目标主机。
如何查询数据库表中有多少字段?
不同的数据库查询表中字段数量的方法有所不同,以下是一些常见数据库的查询方法:
MySQL:可以使用以下两种方法。一是使用 DESCRIBE 命令,例如 DESCRIBE table_name; ,它会返回表的详细结构信息,包括字段名、类型、是否可为空、键信息等,通过查看返回结果的行数即可知道字段数量。二是使用 SHOW COLUMNS FROM table_name; ,其功能与 DESCRIBE 类似,也可以通过查看结果的行数获取字段数量。
SQL Server:可以使用系统存储过程 sp_columns ,例如 EXEC sp_columns table_name; ,它会返回指定表的列信息,包括字段名、类型、长度等,通过查看返回结果的行数就能确定字段数量。也可以查询系统视图 INFORMATION_SCHEMA.COLUMNS ,如 SELECT COUNT(*) FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = 'table_name'; ,直接返回表的字段数量。
Oracle:可以查询数据字典视图 USER_TAB_COLUMNS ,例如 SELECT COUNT(*) FROM USER_TAB_COLUMNS WHERE TABLE_NAME = 'table_name'; ,其中 USER_TAB_COLUMNS 包含了当前用户下所有表的列信息,通过指定表名并计数就能得到该表的字段数量。还可以使用 DESCRIBE 命令,如 DESCRIBE table_name; ,然后手动数一下返回结果中的字段行数,但这种方法对于字段较多的表不太方便。
PostgreSQL:可以使用 \d table_name 命令,在命令行客户端中执行该命令会显示表的详细结构信息,包括字段名、类型、是否可为空等,通过查看返回结果的行数可知字段数量。也可以查询系统表 information_schema.columns ,如 SELECT COUNT(*) FROM information_schema.columns WHERE table_name = 'table_name'; ,来获取表的字段数量。
在 O (n log n) 时间复杂度和常数级空间复杂度下,如何对链表进行排序?
可以使用归并排序的思路来在 O (n log n) 时间复杂度以及常数级空间复杂度下对链表进行排序。
归并排序的核心在于不断地将链表分割然后再合并。首先,利用快慢指针的方法来找到链表的中间节点,以此将链表分成两部分,就如同数组归并排序中划分左右区间一样。快指针每次移动两步,当快指针到达链表末尾时,慢指针所在位置就是中间节点。
接着,递归地对划分出来的前后两个子链表进行同样的分割操作,直到子链表的长度为 1 或者 0,此时意味着划分到了最小的单元,也就是单个节点或者空链表,它们天然就是有序的。
然后就是合并阶段,在合并两个已排序的子链表时,通过比较节点的值,依次将较小值的节点取出重新构建链表,直到两个子链表都遍历完。这个过程需要额外维护几个指针,一个指针用于指向新构建链表的末尾,另外两个指针分别遍历两个待合并的子链表,不断比较并调整指针指向,将节点按顺序拼接起来,而且整个合并过程通过巧妙地调整指针,不需要额外开辟大量空间来存储中间结果,仅仅依靠常数个指针来完成操作,这样就能实现整体的归并排序,达到 O (n log n) 时间复杂度以及常数级空间复杂度对链表进行排序的效果。
例如,假设有一个无序链表,节点值分别为 [4,2,1,3],通过上述归并排序的步骤,先划分成 [4,2] 和 [1,3],再进一步划分,然后合并,最终会得到有序的链表 [1,2,3,4]。
如何找到两个单链表相交的起始节点?
要找到两个单链表相交的起始节点,可以采用以下方法。
首先,分别遍历两个链表,统计它们的长度,设两个链表长度分别为 len1 和 len2,这个过程可以通过定义两个指针,分别从头开始依次向后移动直到到达链表末尾同时记录走过的节点个数来实现。
然后,计算两个链表长度的差值,设为 diff。接着,让较长链表的指针先移动 diff 个节点,这样就能保证后续两个链表剩余部分长度是一样的。比如链表 A 长度为 5,链表 B 长度为 3,那么让链表 A 的指针先移动 2 个节点。
之后,同时移动两个链表的指针,逐一对节点进行比较,当两个指针指向的节点相同时,这个节点就是两个链表相交的起始节点。这是因为在将较长链表的指针提前移动一定距离后,剩余的部分长度相等了,只要它们相交,那么在同步移动比较过程中必然能找到第一个相同的节点。
例如,有链表 A:1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7,链表 B:3 -> 4 -> 5 -> 6 -> 7,先统计长度得到 A 长度为 7,B 长度为 5,计算差值为 2,让链表 A 的指针先移动 2 个节点到 3 这个位置,然后同步移动两个链表的指针,就会发现它们相交的起始节点就是 3 这个节点。
值得注意的是,如果两个链表没有相交,那么同步移动比较的过程中直到两个指针都到达各自链表末尾(也就是都为 nullptr),都不会找到相同的节点,这样就能判断出它们不相交。
给定一个字符串 s,如何将其分割成一些子串,使每个子串都是回文串,并返回所有可能的分割方案?
解决这个问题可以使用回溯算法来实现。
首先,定义一个辅助函数来判断一个子串是否是回文串,通过双指针的方式,一个指针从子串开头,一个指针从子串末尾,同时向中间移动,比较对应字符是否相等,如果在移动过程中所有对应字符都相等,那么这个子串就是回文串。
然后,从字符串的起始位置开始,尝试不同长度的子串分割。对于每一个可能的子串,先判断它是否是回文串,如果是回文串,就将其加入当前的分割方案中,接着对剩余的字符串继续进行同样的分割操作,这就是递归的过程,也就是回溯的向下探索阶段。
当剩余的字符串为空时,意味着找到了一种完整的分割方案,将这种方案保存起来。而如果在某个分割尝试中发现后续无法再找到合适的回文串分割了,那就回溯到上一步,撤销上一次的分割选择,尝试其他的分割长度,继续探索其他可能的分割方案,这就是回溯算法中回溯的过程,通过不断地尝试、撤销、再尝试,遍历所有可能的分割情况。
例如,对于字符串 “aab”,一开始尝试分割出 “a”,判断是回文串,然后对 “ab” 继续分割,又分割出 “a” 和 “b”,得到一种方案 [“a”,“a”,“b”],接着回溯,尝试其他分割方式,又可以得到 [“aa”,“b”] 等不同的分割方案,最终将所有符合要求的分割方案都收集起来并返回。
手写一个二分查找算法。
以下是用 C++ 语言实现的二分查找算法示例:
#include <iostream>
#include <vector>// 二分查找函数,在有序数组nums中查找目标值target
int binarySearch(const std::vector<int>& nums, int target) {int left = 0; // 左边界指针int right = nums.size() - 1; // 右边界指针while (left <= right) {int mid = left + (right - left) / 2; // 计算中间位置,防止溢出if (nums[mid] == target) {return mid; // 如果中间位置的值就是目标值,直接返回中间位置索引} else if (nums[mid] < target) {left = mid + 1; // 如果中间值小于目标值,说明目标值在右半部分,更新左边界} else {right = mid - 1; // 如果中间值大于目标值,说明目标值在左半部分,更新右边界}}return -1; // 如果没有找到目标值,返回 -1
}int main() {std::vector<int> nums = {1, 3, 5, 7, 9};int target = 5;int result = binarySearch(nums, target);if (result!= -1) {std::cout << "找到目标值,在数组中的索引为: " << result << std::endl;} else {std::cout << "未找到目标值" << std::endl;}return 0;
}
这个算法的基本思路是,对于一个给定的有序数组(这里假设是升序排列),定义两个指针分别指向数组的最左端(left)和最右端(right)。在每次循环中,计算中间位置(mid),通过比较中间位置的值和目标值的大小关系来决定下一步搜索的区间。如果中间值等于目标值,那就找到了目标值,直接返回中间位置索引。如果中间值小于目标值,说明目标值在右半部分,就把左边界更新为 mid + 1;反之,如果中间值大于目标值,说明目标值在左半部分,把右边界更新为 mid - 1。不断重复这个过程,直到左边界超过右边界,意味着整个数组都搜索完了还没找到目标值,此时返回 -1。
例如,在上述示例代码中,给定数组 {1, 3, 5, 7, 9} 去查找目标值 5,通过二分查找的过程,会先找到中间值 3,由于 3 小于 5,更新左边界,继续查找,最终找到目标值 5 并返回其在数组中的索引 2。
解释青蛙跳台阶问题的解决方案,例如使用斐波那契数列。
青蛙跳台阶问题通常描述为:一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级台阶,问青蛙跳上 n 级台阶有多少种不同的跳法。
可以用斐波那契数列的思路来解决这个问题。
我们来逐步分析跳台阶的情况,当只有 1 级台阶时,青蛙只有 1 种跳法,那就是直接跳 1 级上去,记跳法数量为 F (1) = 1;当有 2 级台阶时,青蛙可以一次跳 2 级,或者分两次每次跳 1 级,总共有 2 种跳法,记为 F (2) = 2。
而对于 n 级台阶(n > 2),青蛙在跳最后一步时,要么是从 n - 1 级台阶跳了 1 级上来的,要么是从 n - 2 级台阶跳了 2 级上来的。那么跳上 n 级台阶的不同跳法数量 F (n),就等于跳上 n - 1 级台阶的不同跳法数量 F (n - 1) 加上跳上 n - 2 级台阶的不同跳法数量 F (n - 2),这正好符合斐波那契数列的递推关系,即 F (n) = F (n - 1) + F (n - 2)。
所以,我们可以通过迭代或者递归的方式来计算出跳上 n 级台阶的不同跳法数量。
例如,通过迭代实现,我们可以定义两个变量,分别初始化为 F (1) 和 F (2) 的值,然后通过循环,不断根据 F (n) = F (n - 1) + F (n - 2) 这个递推公式来计算后续的跳法数量,比如要计算跳上 5 级台阶的跳法数量,先初始化变量 a = 1(对应 F (1)),b = 2(对应 F (2)),然后循环计算,第一次循环得到 F (3) = a + b = 3,接着更新变量 a = b,b = 3,第二次循环得到 F (4) = 5,再更新变量继续循环就能得到 F (5) = 8,也就是青蛙跳上 5 级台阶有 8 种不同的跳法。
如果采用递归方式,就按照 F (n) = F (n - 1) + F (n - 2) 这个递推关系去递归调用函数,不过递归方式可能存在重复计算的问题,在实际应用中可以结合备忘录等方式来优化,避免重复计算,提高效率。
如何求前 k 个最大的数?
可以采用多种方法来求前 k 个最大的数:
-
排序法:先对整个数据集进行排序,比如使用快速排序、归并排序等时间复杂度较好的排序算法,将数据从大到小或者从小到大排列,然后取前 k 个元素就是所求的前 k 个最大的数。但这种方法在数据量非常大的时候,对整个数据集排序的时间成本较高,比如有海量的数据,全部排序就会消耗大量时间和空间资源,不过如果数据量较小,是一种简单可行的办法。例如对于数组 [3, 5, 1, 7, 9],要找前 3 个最大的数,先排序得到 [9, 7, 5, 3, 1],然后取前 3 个即 9、7、5。
-
优先队列(堆)法:可以利用最大堆这种数据结构来解决,先将前 k 个元素构建成一个最大堆,然后从第 k + 1 个元素开始,依次与堆顶元素比较,如果大于堆顶元素,就替换堆顶元素,并重新调整堆使其保持最大堆的性质。遍历完所有元素后,堆中的元素就是前 k 个最大的数。例如对于一个很长的数组,先取前 k 个数构建最大堆,后续不断比较和调整,最终能高效地得到前 k 个最大的数,而且在处理大规模数据时效率优势明显,避免了对全部数据排序的高成本操作。
-
快速选择算法:这是一种基于快速排序思想的算法,它每次通过选择一个枢轴元素,将数组分成两部分,使得左边部分的元素都小于等于枢轴元素,右边部分的元素都大于等于枢轴元素。然后判断枢轴元素的位置,如果枢轴元素的位置正好是第 k 个位置,那么它左边的元素就是前 k - 1 个最大的数;如果小于 k,就在右边部分继续进行划分操作;如果大于 k,就在左边部分继续划分,通过不断这样的划分和判断来找到前 k 个最大的数,在平均情况下时间复杂度也比较理想,尤其适合求相对位置上的最大元素集合。
请解释线程与进程的区别和概念。
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,是操作系统进行资源分配和调度的一个独立单位。它包含了程序执行时的代码、数据、栈、堆以及进程控制块(PCB)等资源,有自己独立的地址空间,不同的进程之间相互隔离,一个进程的崩溃通常不会直接影响到其他进程的正常运行。例如在电脑上同时运行的浏览器进程、音乐播放器进程等,它们各自有自己的内存空间、文件句柄等资源,互不干扰。
线程则是进程中的一个执行单元,是进程内的可调度实体,它共享所属进程的地址空间以及大部分资源,比如同一个进程内的多个线程可以共享代码段、数据段、打开的文件等资源。线程比进程更加轻量级,创建和销毁线程所消耗的系统资源相对较少,切换线程的开销也比切换进程小很多。比如在一个文本编辑软件进程中,可能有一个线程负责接收用户的键盘输入,另一个线程负责实时保存文档内容,它们共同协作完成整个软件的功能,并且共享进程内的各种资源。
从调度角度来看,进程是由操作系统进行调度的,不同进程之间切换需要进行复杂的上下文切换,涉及到保存和恢复大量的资源状态;而线程是在进程内部由线程调度器进行调度,上下文切换时只需要保存和恢复少量的线程相关状态信息,比如线程的执行位置、寄存器值等,相对简单很多。
线程间通信和进程间通信的方式有哪些?如果用过,请详细说明。
线程间通信方式
-
共享变量:由于同一进程内的线程共享进程的地址空间,所以可以通过定义共享变量来进行通信。比如在一个多线程的计数器程序中,定义一个全局的整型变量 count,一个线程负责对其进行加操作,另一个线程负责对其进行减操作,通过对这个共享变量的读写来传递信息,实现协作。但使用共享变量时要注意线程安全问题,需要通过互斥锁、信号量等机制来保证在同一时刻只有一个线程能访问和修改共享变量,避免出现数据不一致等情况。
-
消息队列:在线程间也可以使用消息队列来传递消息,一个线程将消息放入消息队列,另一个线程从消息队列中取出消息进行处理。例如在一个网络服务器程序中,接收网络请求的线程可以把接收到的请求封装成消息放入消息队列,而处理请求的线程从消息队列中取出消息并进行相应的业务处理,消息队列可以按照先进先出等顺序来管理消息,保证通信的有序性。
-
条件变量:常和互斥锁一起配合使用,用于线程间的同步。比如有一个线程等待某个条件满足后再继续执行,另一个线程在满足条件时通过条件变量来通知等待的线程,等待的线程被唤醒后再继续执行后续操作。例如在一个生产者 - 消费者模型中,消费者线程等待仓库中有产品(条件变量等待),生产者线程生产出产品后通过条件变量通知消费者线程可以进行消费了,这样实现了线程间基于条件的通信和同步。
进程间通信方式
-
管道(无名管道和有名管道):无名管道用于具有亲缘关系(父子进程等)的进程间通信,它是半双工的通信方式,一端用于读,一端用于写,通过系统调用创建管道后,父子进程可以分别关闭不需要的读端或写端,然后通过剩下的一端进行数据传输。有名管道则可以在不相关的进程间通信,它有自己的文件名,不同的进程可以通过文件名来找到并打开管道进行通信,比如一个进程往有名管道里写数据,另一个进程可以通过文件名打开管道读取数据。
-
消息队列(与线程间消息队列不同,是系统级别的):不同进程可以通过向消息队列发送消息以及从消息队列接收消息来进行通信,消息队列有自己的标识符,进程通过这个标识符来访问消息队列,并且可以设置消息的类型等属性,接收方可以根据消息类型有选择地接收消息,在一些分布式系统或者多进程协同工作的场景中经常会用到。
-
共享内存:多个进程可以共享同一块物理内存区域,通过映射到各自的地址空间来访问和操作这块内存,实现数据的共享和通信。比如在数据库系统中,多个进程可能需要共享数据库缓存等数据,就可以利用共享内存来提高数据访问效率,但同样要注意进程间的同步和互斥问题,避免出现数据冲突,通常会配合信号量等机制来保证共享内存的正确使用。
-
信号量:主要用于进程间的同步和互斥,控制多个进程对共享资源的访问顺序和数量。比如在多个进程访问打印机这种独占资源时,通过信号量来限制同时访问的进程数量,保证资源的合理使用,同时也可以用于进程间的同步,让一个进程等待另一个进程完成某个操作后再继续执行。
-
套接字(Socket):广泛应用于网络通信场景下的进程间通信,不同主机上的进程或者同一主机上不同的进程都可以通过创建套接字,按照网络协议(如 TCP、UDP 等)来进行数据传输,实现跨网络或者本地的通信,常用于客户端 - 服务器架构等场景中,像网页浏览器和服务器之间就是通过套接字进行通信的。
请详细描述编译过程。
编译过程一般可以分为以下几个主要阶段:
-
预处理阶段:预处理器会对源文件进行处理,主要处理一些预处理指令。比如 #include 指令,预处理器会把相应的头文件内容复制到源文件中,将所有 #include 包含的头文件展开,这样就把分散的代码整合到一起;处理 #define 指令,进行文本替换,像 #define PI 3.1415926,会把代码中出现的 PI 都替换成 3.1415926;还有处理条件编译指令如 #if、#ifdef、#ifndef 等,根据条件判断来决定是否包含某些代码段,经过预处理后,源文件的内容得到了扩充和初步整理。
-
编译阶段:编译器会将预处理后的源文件(通常是.c 或.cpp 等文件)进行词法分析、语法分析、语义分析等操作。词法分析就是把源文件的字符流分解成一个个的单词,比如关键字、标识符、常量、运算符等;语法分析则是依据语法规则,将单词构建成抽象语法树(AST),检查代码的语法结构是否正确,比如语句的嵌套、表达式的构成等是否符合语法要求;语义分析会进一步检查代码的语义正确性,比如变量是否先声明后使用、类型是否匹配等。然后根据这些分析结果,将源文件翻译成中间表示形式,例如汇编语言或者某种中间代码,不同的编译器可能有不同的中间表示形式,但都是为了后续的进一步处理做准备。
-
汇编阶段:汇编器会将编译阶段得到的汇编语言或者中间代码转换为机器语言,也就是目标文件(.obj 或.o 文件),目标文件包含了机器指令以及一些相关的数据,比如全局变量、静态变量等的存储信息,但此时目标文件还不能直接运行,它只是编译过程中的一个中间产物,还需要经过链接等操作。
-
链接阶段:链接器会把多个目标文件以及可能用到的库文件(静态库或动态库)链接在一起,解决符号引用的问题。比如一个源文件中调用了另一个源文件中定义的函数或者使用了外部的全局变量,在各自的目标文件中这些都是符号引用,链接器会在其他目标文件或者库文件中找到对应的定义并将它们连接起来,最终生成可执行文件,这个可执行文件就可以在相应的操作系统和硬件平台上运行了。
例如,对于一个简单的 C++ 程序,包含了多个源文件和头文件,首先经过预处理把所有头文件展开等操作,然后每个源文件分别进行编译得到各自的目标文件,再通过链接器把这些目标文件以及可能用到的标准库文件链接起来,最终生成一个完整的可执行文件,整个编译过程涉及到多个工具和阶段,每个阶段都有其重要的作用,共同完成从源文件到可执行程序的转换。
二叉树先序遍历的非递归实现方式是怎样的?请描述递归入栈弹栈的过程。
二叉树先序遍历的非递归实现通常借助栈来完成,其基本思路如下:
首先,创建一个栈用于辅助遍历,然后将二叉树的根节点压入栈中。接着进入循环,只要栈不为空,就执行以下操作:取出栈顶节点,访问该节点(这就相当于先序遍历中先访问根节点的操作),然后判断该节点的右子树是否存在,如果存在就将右子树节点压入栈中,再判断该节点的左子树是否存在,若存在同样将左子树节点压入栈中。不断重复这个过程,直到栈为空,此时就完成了二叉树的先序遍历。
以一个简单的二叉树示例来说明,假设有如下二叉树:
1/ \2 3
/ \ / \
4 5 6 7
最开始将根节点 1 压入栈中,进入循环后,取出栈顶节点 1 并访问它,接着先将其右子树节点 3 压入栈,再将左子树节点 2 压入栈。此时栈内元素从上到下依次为 3、2。下一轮循环,取出栈顶节点 2 并访问,再将其右子树节点 5 和左子树节点 4 依次压入栈,此时栈内元素从上到下依次为 3、5、4。继续循环,依次取出并访问栈顶节点,不断压入相应子树节点,直到栈为空,就完成了整个二叉树的先序遍历,遍历顺序就是 1、2、4、5、3、6、7。
对于递归入栈弹栈的过程,在递归实现先序遍历中,当进入一个节点的递归调用时,就相当于将这个节点相关的信息压入了一个隐含的栈中,比如记录当前递归的状态、下一步要访问的子树等信息。以刚才的二叉树为例,当递归访问根节点 1 时,相当于把 1 相关信息压入栈,然后递归调用左子树,这时候就把左子树相关状态压入栈,在左子树递归结束返回后,就相当于从栈中弹出左子树相关状态,接着再去递归访问右子树,也就是把右子树相关状态压入栈,右子树递归结束后再弹出,整个递归过程就是不断地将节点相关的调用状态压入和弹出这个隐含的栈,和非递归借助显式栈来控制遍历顺序的本质是类似的,只不过递归由编译器等自动帮我们管理了这个栈的操作,而非递归是我们手动通过代码来控制栈的压入和弹出以及遍历的流程。
在递归的入栈过程中,随着不断深入到子树的递归调用,栈会不断积累各层节点的相关信息,而当子树的递归调用返回时,也就是完成了对应子树的遍历,就会从栈中弹出对应的信息,回到上一层的状态继续后续的遍历操作,通过这样不断地入栈弹栈,最终实现整个二叉树按照先序遍历的顺序完成遍历。
相关文章:
新浪微博C++面试题及参考答案
多态是什么?请详细解释其实现原理,例如通过虚函数表实现。 多态是面向对象编程中的一个重要概念,它允许不同的对象对同一消息或函数调用做出不同的响应,使得程序具有更好的可扩展性和灵活性。 在 C 中,多态主要通过虚函…...

计算机视觉目标检测-1
文章目录 摘要Abstract1.目标检测任务描述1.1 目标检测分类算法1.2 目标定位的简单实现思路1.2.1 回归位置 2.R-CNN2.1 目标检测-Overfeat模型2.1.1 滑动窗口 2.2 目标检测-RCNN模型2.2.1 非极大抑制(NMS) 2.3 目标检测评价指标 3.SPPNet3.1 spatial pyr…...

【物联网技术与应用】实验15:电位器传感器实验
实验15 电位器传感器实验 【实验介绍】 电位器可以帮助控制Arduino板上的LED闪烁的时间间隔。 【实验组件】 ● Arduino Uno主板* 1 ● 电位器模块* 1 ● USB电缆*1 ● 面包板* 1 ● 9V方型电池* 1 ● 跳线若干 【实验原理】 模拟电位器是模拟电子元件,模…...

java常用类(上)
笔上得来终觉浅,绝知此事要躬行 🔥 个人主页:星云爱编程 🔥 所属专栏:javase 🌷追光的人,终会万丈光芒 🎉欢迎大家点赞👍评论📝收藏⭐文章 目录 一、包装类 1.1包装类…...

包管理工具npm、yarn、pnpm、cnpm详解
1. 包管理工具 1.1 npm # 安装 $ node 自带 npm# 基本用法 npm install package # 安装包 npm install # 安装所有依赖 npm install -g package # 全局安装 npm uninstall package # 卸载包 npm update package # 更新包 npm run script #…...

CI/CD是什么?
CI/CD 定义 CI/CD 代表持续集成和持续部署(或持续交付)。它是一套实践和工具,旨在通过自动化构建、测试和部署来改进软件开发流程,使您能够更快、更可靠地交付代码更改。 持续集成 (CI):在共享存储库中自动构建、测试…...
)
[Java]合理封装第三方工具包(附视频)
-1.视频链接 视频版: 视频版会对本文章内容进行详细解释 [Java]合理封装第三方工具包_哔哩哔哩_bilibili 0.核心思想 对第三方工具方法进行封装,使其本地化,降低记忆和使用成本 1.背景 在我们的项目中,通常会引用一些第三方工具包,或者是使用jdk自带的一些工具类 例如: c…...

常规配置、整合IDEA
目录 Redis常规配置 tcp-keepalive security Jedis RedisTemplate 连接池技术 Lua脚本 Jedis集群 Redis应用问题&解决方案 缓存穿透 缓存击穿 缓存雪崩 分布式锁 Redis实现分布式锁 Redis新功能 ACL Redis常规配置 tcp-keepalive security redis.conf中…...

用Python写炸金花游戏
文章目录 **代码分解与讲解**1. **扑克牌的生成与洗牌**2. **给玩家发牌**3. **打印玩家的手牌**4. **定义牌的优先级**5. **判断牌型**6. **确定牌型优先级**7. **比较两手牌的大小**8. **计算每个玩家的牌型并找出赢家**9. **打印结果** 完整代码 以下游戏规则: 那…...

计算机的错误计算(一百九十二)
摘要 用两个大模型计算 csc(0.999), 其中,0.999是以弧度为单位的角度,结果保留5位有效数字。两个大模型均给出了 Python代码与答案。但是,答案是错误的。 例1. 计算 csc(0.999), 其中,0.999是以弧度为单位的角度,结…...

37 Opencv SIFT 特征检测
文章目录 Ptr<SIFT> SIFT::create示例 Ptr SIFT::create Ptr<SIFT> SIFT::create(int nfeatures 0,int nOctaveLayers 3,double contrastThreshold 0.04,double edgeThreshold 10,double sigma 1.6 );参数说明:nfeatures:类型&#x…...
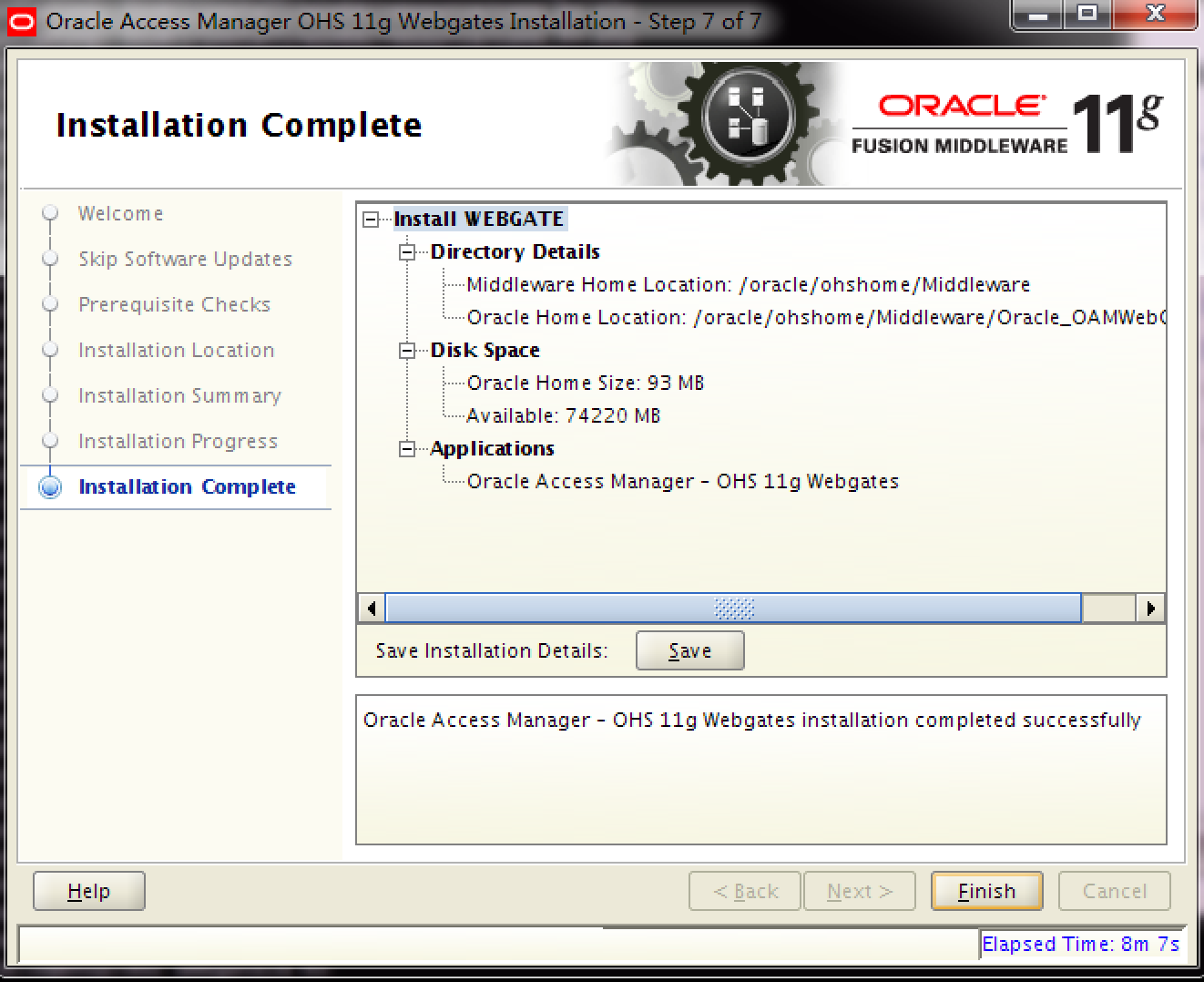
Nginx界的天花板-Oracle 中间件OHS 11g服务器环境搭建
环境信息 服务器基本信息 如下表,本次安装总共使用2台服务器,具体信息如下: 服务器IP DNS F5配置 OHS1 172.xx.xx.xx ohs01.xxxxxx.com ohs.xxxxxx.com OHS2 172.xx.xx.xx ohs02.xxxxxx.com 服务器用户角色信息均为:…...

域名解析协议
一、DNS简述 DNS协议是一种应用层协议,用于将域名转换为对应的IP地址,使得客户端可以通过域名来访问Internet上的各种资源 DNS的基础设施是由分层的DNS服务器实现的分布式数据库,它运行在UDP之上,通常使用端口号53 DN…...

微信小程序给外面的view设置display:flex;后为什么无法给里面的view设置宽度
如果父盒子view设置了display:flex,子view设置宽度值无效,宽度值都是随着内容多少而改变: 问题视图: 原因: flex布局元素的子元素,自动获得了flex-shrink的属性 解决方法: 给子view增加:fl…...

Maven怎么会出现一个dependency-reduced-pom.xml的文件
问题 今天打包时突然发现,多出了一个名为dependency-reduced-pom.xml的文件 解决方法 由于使用了maven-shade-plugin插件导致的,在 <plugin> 标签下添加 <configuration><createDependencyReducedPom>false</createDependencyR…...

突发!!!GitLab停止为中国大陆、港澳地区提供服务,60天内需迁移账号否则将被删除
GitLab停止为中国大陆、香港和澳门地区提供服务,要求用户在60天内迁移账号,否则将被删除。这一事件即将引起广泛的关注和讨论。以下是对该事件的扩展信息: 1. 背景介绍:GitLab是一家全球知名的软件开发平台,提供代码托…...

自学记录HarmonyOS Next DRM API 13:构建安全的数字内容保护系统
在完成了HarmonyOS Camera API的开发之后,我开始关注更复杂的系统级功能。在浏览HarmonyOS Next文档时,我发现了一个非常有趣的领域:数字版权管理(DRM)。最新的DRM API 13提供了强大的工具,用于保护数字内容…...

Vue 3 + Element Plus 实现文件上传组件:详细解析与实现指南
Vue 3 文件上传组件实现详解 在实际的前端开发中,文件上传是一个常见的需求,尤其是在需要处理文档、图片或其他类型文件的应用中。Vue 3 结合 Element Plus UI 组件库为我们提供了一个简单且灵活的文件上传解决方案。在这篇文章中,我们将详细…...

qt5.12.11+msvc编译器编译qoci驱动
1.之前编译过minGW编译器编译qoci驱动,很顺利就完成了,文章地址:minGW编译qoci驱动详解,今天按照之前的步骤使用msvc编译器进行编译,直接就报错了: 查了些资料,发现两个编译器在编译时,pro文件中引用的库不一样,下面是msvc编译器引用的库,其中编译引用的库我这里安装…...

Ubuntu 20.04 安装 LNMP
1. 更新系统 sudo apt update sudo apt upgrade2. 安装 Nginx sudo apt install nginx3. 安装 MariaDB (作为 MySQL 的替代) sudo apt install mariadb-server mariadb-client初始化 MariaDB 数据库(可选) sudo mysql_secure_installation4. 安装 PH…...

题目1514:蓝桥杯算法提高VIP-夺宝奇兵
#include<iostream> using namespace std; int dp[110][110]; int main(){ int n; cin>>n; for(int i1;i<n;i){ for(int j1;j<i;j){ cin>>dp[i][j]; } } //从倒数第二行向上推 for(int in-1;i&g…...

30分钟搭建个人AI助手:OpenClaw+千问3.5-35B-A3B-FP8极速体验
30分钟搭建个人AI助手:OpenClaw千问3.5-35B-A3B-FP8极速体验 1. 为什么选择这个组合? 上周六下午,我盯着电脑里散落的会议纪要、待办事项和未整理的截图发愁时,突然意识到:与其手动处理这些琐事,不如让AI…...

谱聚类实战:如何让声纹模型自动分辨一段录音里有几个人说话?
谱聚类在声纹识别中的应用:如何自动判断录音中的说话人数量 想象一下,你手头有一段长达两小时的会议录音,里面有五位不同声线的参与者交替发言。作为开发者,你需要设计一个系统,不仅能识别每个人的声音特征,…...

OpenClaw+Qwen3-14b_int4_awq内容创作:从大纲生成到公众号发布全自动
OpenClawQwen3-14b_int4_awq内容创作:从大纲生成到公众号发布全自动 1. 为什么需要全自动内容创作 作为一个技术博主,我经常面临一个困境:有太多想写的内容,但时间总是不够用。从构思大纲到完成写作,再到排版发布&am…...

终极指南:3天快速上手ALOHA开源双臂机器人系统,从零到实战操作
终极指南:3天快速上手ALOHA开源双臂机器人系统,从零到实战操作 【免费下载链接】aloha 项目地址: https://gitcode.com/gh_mirrors/al/aloha ALOHA(A Low-cost Open-source Hardware System for Bimanual Teleoperation)是…...

别再只盯着报点率了:聊聊电容触摸屏算法里那些不为人知的‘软实力’
电容触摸屏算法的隐秘战场:超越报点率的技术博弈 在智能家居面板的清晨唤醒中,工业HMI产线的精准操控里,或是车载中控的流畅滑动间,电容触摸屏已成为人机交互的核心界面。当大多数技术选型讨论聚焦于报点率、触控精度这些硬指标时…...

云原生应用的微服务架构设计
云原生应用的微服务架构设计 引言:微服务架构的重要性 哥们,别整那些花里胡哨的!作为一个前端开发兼摇滚鼓手,我最烦的就是单体应用的臃肿和难以维护。在云原生时代,微服务架构已经成为构建现代应用的最佳实践。今天&a…...

如何快速合并B站缓存视频?BilibiliCacheVideoMerge完整解决方案指南
如何快速合并B站缓存视频?BilibiliCacheVideoMerge完整解决方案指南 【免费下载链接】BilibiliCacheVideoMerge 项目地址: https://gitcode.com/gh_mirrors/bi/BilibiliCacheVideoMerge 你是否遇到过这样的困扰:在B站缓存了喜欢的视频准备离线观…...

S3DIS点云数据集:室内场景语义分割的实战指南
1. S3DIS数据集简介与下载指南 S3DIS(Stanford Large-Scale 3D Indoor Spaces Dataset)是斯坦福大学发布的室内场景点云数据集,包含6个大型室内区域(Area_1至Area_6),总计271个房间场景。每个点云数据包含…...
)
电子商城|基于springboot + vue电子商城管理系统(源码+数据库+文档)
电子商城管理系统 目录 基于springboot vue电子商城管理系统 一、前言 二、系统功能演示 详细视频演示 三、技术选型 四、其他项目参考 五、代码参考 六、测试参考 七、最新计算机毕设选题推荐 八、源码获取: 基于springboot vue电子商城管理系统 一、…...