【PyTorch】(基础七)---- 完整训练流程
首先要明确一点,我们在编写模型、训练和使用模型的时候通常都是分开的,所以应该把Module的编写以及train方法和test方法分开编写。
调用gpu进行训练:在网络模型,数据,损失函数对象后面都使用.cuda()方法,如loss_fn = loss_fn.cuda()
【代码示例】完成完整CIFAR10模型的训练
按照官网给出的模型结构进行构建:

# model.py
class myModule(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, ingput):output = self.model(ingput)return output
导入自己创建的模型,实例化一个模型对象之后,导入CIFAR10数据集进行训练
# train.py
import torchvision
from torch.utils.tensorboard import SummaryWriter
from module import *
from torch import nn
from torch.utils.data import DataLoader# 使用Dataset来下载数据集
train_data = torchvision.datasets.CIFAR10(root="dataset/CIFAR10", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset/CIFAR10", train=False, transform=torchvision.transforms.ToTensor(),download=True)# 数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 创建网络模型,实例化自定义的模型
mymodule = myModule()
if torch.cuda.is_available():mymodule = mymodule.cuda()# 定义损失函数为交叉熵损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():loss_fn = loss_fn.cuda()# 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(mymodule.parameters(), lr=learning_rate)# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10# tensorboard配置日志目录
writer = SummaryWriter("logs_train")for i in range(epoch):print("-------第 {} 轮训练开始-------".format(i+1))# 训练步骤开始mymodule.train()for data in train_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = mymodule(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1 # 每读取一次图片+1if total_train_step % 100 == 0:print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 测试步骤开始mymodule.eval()total_test_loss = 0 # 损失函数值total_accuracy = 0 # 准确率with torch.no_grad():for data in test_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = mymodule(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss: {}".format(total_test_loss))print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)total_test_step = total_test_step + 1# 每轮都保存模型torch.save(mymodule, "mymodule{}.pth".format(i))print("模型已保存")writer.close()# test.py
import torch
import torchvision
from PIL import Image
from torch import nnimage_path = "imgs/airplane.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),torchvision.transforms.ToTensor()])image = transform(image)
print(image.shape)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return xmodel = torch.load("mymodule9.pth", map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():output = model(image)
print(output)print(output.argmax(1))
相关文章:
【PyTorch】(基础七)---- 完整训练流程
首先要明确一点,我们在编写模型、训练和使用模型的时候通常都是分开的,所以应该把Module的编写以及train方法和test方法分开编写。 调用gpu进行训练:在网络模型,数据,损失函数对象后面都使用.cuda(&#x…...

01- 三自由度串联机械臂位置分析
三自由度串联机械臂如下图所示(d180mm,L1100mm,L280mm),利用改进DH法建模,坐标系如下所示: 利用改进DH法建模,该机器人的DH参数表如下所示: 对该机械臂进行位置分析&…...

Flutter实现可拖拽操作Draggable
文章目录 1. Draggable 控件的构造函数主要参数: 2. Draggable 的工作原理3. 常见用法示例 1:基本的拖拽控件解释:示例 2:与 DragTarget 配合使用解释: 4. Draggable 的回调详解5. 总结 Draggable 是 Flutter 中一个用…...

Vue BPMN Modeler流程图
1、参考地址 git clone https://github.com/evanyangg/vue-bpmn-modeler.git 2、安装bpmn.js npm install bpmn-js --save 3、使用bpmn.js <template><div class"containers"><div class"canvas" ref"canvas"></div&g…...

写在公司40周年前夕
日子太快了,来这里工作六年多了。现在才知道原来入职的公司只是母公司的一小点。刚来一年就碰到疫情,三年疫情之后就迎来亏损,而后就是变了董事长,换了总经理。 这圣诞前,所有的子分又换了一把手。动作之大,…...

Python调用Elasticsearch更新数据库
文章目录 Elasticsearch介绍Python调用Elasticsearch更新数据库 Elasticsearch介绍 Elasticsearch是一个基于Lucene的搜索引擎,它提供了一个分布式、多租户能力的全文搜索引擎,具有HTTP web接口和无模式的JSON文档。Elasticsearch是用Java开发的&#x…...
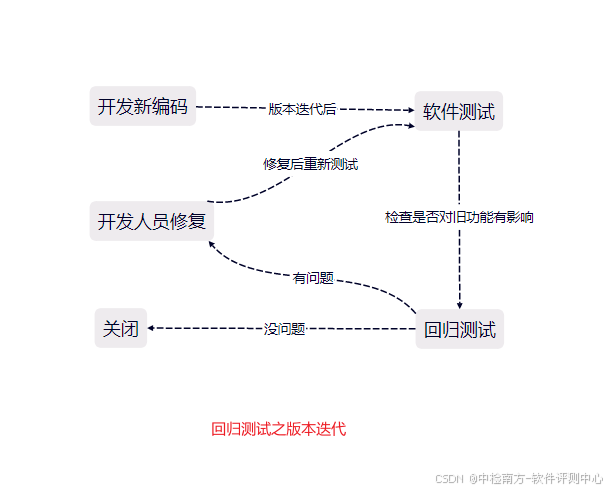
测试基础之测试分类
软件测试是确保软件产品满足预期功能、性能和用户体验要求的关键环节。它的主要目的是通过系统化的方法发现并修复软件中的缺陷,从而提高软件的质量和可靠性。在软件开发生命周期的不同阶段执行测试,以尽早发现潜在的错误或类型,早期发现缺陷…...

太阳能LED路灯智能控制系统(论文+源码)
1系统的功能及方案设计 本次课题为太阳能LED路灯智能控制系统,其系统整体架构如图2.1所示,太阳能板通过TP4056充电模块给锂电池进行充电,电池通过HX3001升压模块进行升压到5V给整个控制系统进行供电,控制系统由AT89C52单片机作为…...

文本数据处理
文本数据处理 一、数据转换与错误处理 (一)运维中的数据转换问题 在计算机审计及各类数据处理场景中,数据转换是关键步骤,涉及将被审计单位或其他来源的数据有效装载到目标数据库,并明确标示各表及字段含义与关系。…...
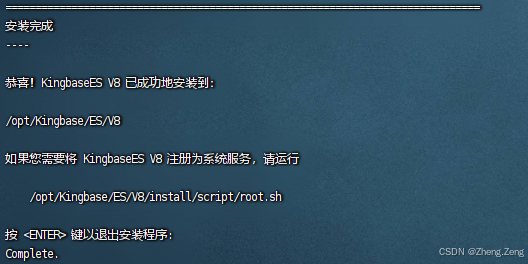
Liunx环境下安装人大金仓数据库V8R6版本
Liunx环境下安装人大金仓数据库V8R6版本 一:硬件环境要求二:软件环境要求三:安装包准备四:检测和配置环境4.1:检查操作系统信息4.2 检查系统内存与存储空间 五:配置内核参数六:预安装工作6.1 创…...
Android使用PorterDuffXfermode模式PorterDuff.Mode.SRC_OUT橡皮擦实现马赛克效果,Kotlin(3)
Android使用PorterDuffXfermode模式PorterDuff.Mode.SRC_OUT橡皮擦实现马赛克效果,Kotlin(3) import android.content.Context import android.graphics.Bitmap import android.graphics.BitmapFactory import android.graphics.Canvas impor…...

python 怎么引入类
一、导入单个类 from fun import Dog dogDog(husike) dog.bark() 二、导入多个类 多个类之间用逗号分隔 from fun import Dog,Cat dogDog(husike) dog.bark() catCat(maomi) cat.catch_mouse() 三、导入整个模块 import fun dogfun.Dog(husike) dog.bark() catfun.Cat(maomi) …...

Day35汉明距离
两个整数之间的 汉明距离 指的是这两个数字对应二进制位不同的位置的数目。 给你两个整数 x 和 y,计算并返回它们之间的汉明距离。 class Solution {public int hammingDistance(int x, int y) {int cnt 0;while (Math.max(x, y) ! 0) {if ((x & 1) ! (y &…...

中文学习系统:客户服务与学习支持
3.1 系统可行性分析 开发一款程序软件不仅需要时间,也需要人力,物力资源。而进行可行性分析这个环节就是解决用户这方面的疑问,看看程序在当前的条件下是否可以进行开发。 3.1.1 技术可行性分析 此程序选用的开发语言是Java,这种编…...

华为麦芒5(安卓6)termux记录 使用ddns-go,alist
下载0.119bate1版,不能换源,其他源似乎都用不了,如果root可以直接用面具模块 https://github.com/termux/termux-app/releases/download/v0.119.0-beta.1/termux-app_v0.119.0-beta.1apt-android-5-github-debug_arm64-v8a.apk 安装ssh(非必要) pkg install openssh开启ssh …...

餐厅下单助手系统(Java+MySQL)
项目概览 餐厅下单助手系统是一个采用 Java 实现的小型食品订单管理系统,并且以 SwingUI 打造视觉界面,数据库提供。本系统分为商家和顾客两类体验,有效地给予简洁性能。可用做课程设计,参考学习。 技术栈 Java: 核心开发语言S…...

Go操作MySQL
连接 Go语言中的database/sql包提供了保证SQL或类SQL数据库的泛用接口,并不提供具体的数据库驱动。使用database/sql包时必须注入(至少)一个数据库驱动。 我们常用的数据库基本上都有完整的第三方实现。例如:MySQL驱动 下载依赖…...
配置开机自启动服务)
Linux(Ubuntu/CentOS)配置开机自启动服务
systemd和systemctl的区别和联系 systemd:是现代Linux系统中的初始化系统和服务管理器。它主要负责系统引导和进程管理,支持并行化启动服务,并提供高级的服务管理和依赖控制。 systemctl:是systemd的命令行工具,用于与…...

springboot3版本结合knife4j生成接口文档
1.概述 knife4j官网为:介绍 | Knife4j (xiaominfo.com)https://doc.xiaominfo.com/docs/introduction 初步了解的码友可以初步了解一下官网的如下几个模块: 其中在快速开始模块中,不同的springboot版本都有一个使用的案例demo如下图位置&am…...

谈谈 Wi-Fi 的 RTS/CTS 设计
我不是专业的 Wi-Fi 技术工作者。但我可以谈谈作为统计复用网络的 Wi-Fi,通用的网络分布式协调功能在底层是相通的。 从一个图展开: 基于这底层逻辑,共享以太网可以用 CSMA/CD,而 Wi-Fi 只能用 CSMA/CA,区别在 CD(冲…...

vLLM部署ERNIE-4.5-0.3B-PT的批处理能力实测:batch_size=8时吞吐提升2.3倍
vLLM部署ERNIE-4.5-0.3B-PT的批处理能力实测:batch_size8时吞吐提升2.3倍 当我们需要同时处理多个用户的文本生成请求时,比如一个在线客服系统或者一个内容创作平台,传统的单条请求处理方式就会显得力不从心。服务器只能一个个排队处理&…...

WebDataset教学视频:从零开始学习WebDataset的10个系列课程
WebDataset教学视频:从零开始学习WebDataset的10个系列课程 【免费下载链接】webdataset A high-performance Python-based I/O system for large (and small) deep learning problems, with strong support for PyTorch. 项目地址: https://gitcode.com/gh_mirro…...
:Claude Code 最核心的 1729 行:一个 Agent Runtime 是怎么运转的)
Claude Code 源码架构深度解析(二):Claude Code 最核心的 1729 行:一个 Agent Runtime 是怎么运转的
一个请求进来,到底发生了什么 上一篇我们建立了一个认知:Claude Code 不是 CLI 工具,而是 Agent Operating System。 但知道它"是什么"还不够。这一篇,我们要打开它的引擎盖,看看里面到底怎么转的。 当你…...

UABEA:Unity游戏资源编辑与分析的终极解决方案
UABEA:Unity游戏资源编辑与分析的终极解决方案 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity游戏开发和模组制作领域,处理Asset Bundle资源文件是每个开发者都会面临的…...

2025年大中华区21个主要城市甲级写字楼市场数据
、大中华区主要城市甲级写字楼市场数据速览(2025年)美通社消息:全球领先的房地产服务公司戴德梁行发布《大中华区写字楼供应/需求前沿趋势》年度报告,针对2025年大中华区21个主要城市甲级写字楼市场的整体表现展开研究,聚焦市场供需关系深入分…...

Qwen3.5-2B轻量部署教程:适配Jetson/树莓派的2B多模态模型实测
Qwen3.5-2B轻量部署教程:适配Jetson/树莓派的2B多模态模型实测 1. 模型概述 Qwen3.5-2B是阿里云推出的轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。这个模型专为边缘计算设备优化,主打低功耗、低门…...

VMware虚拟机中部署Qwen3智能字幕对齐系统:Windows开发者的Linux环境方案
VMware虚拟机中部署Qwen3智能字幕对齐系统:Windows开发者的Linux环境方案 如果你和我一样,主要用Windows电脑工作,但时不时又需要折腾一下Linux环境来跑AI模型,那今天这个方案可能正合你意。直接在Windows上部署某些依赖复杂的AI…...

OpenClaw自动化报告:Qwen3-32B生成周报与数据可视化的整合
OpenClaw自动化报告:Qwen3-32B生成周报与数据可视化的整合 1. 为什么需要自动化周报系统 每周五下午3点,我的日历总会准时弹出提醒:"该写周报了"。这个看似简单的任务却总让我头疼——需要从Jira抓取任务进度、从GitHub收集代码提…...

SagerNet数据库架构完全指南:Room与DataStore在代理工具中的最佳实践
SagerNet数据库架构完全指南:Room与DataStore在代理工具中的最佳实践 SagerNet作为Android平台上的通用代理工具链,其强大的数据库架构设计是其核心竞争力的关键。通过深入分析SagerNet的Room数据库与DataStore的完美结合,我们可以了解现代A…...

**Compose Multiplatform:跨平台开发的新范式与实战解析**在现代移动应用开发中,**“一次编写,多端
Compose Multiplatform:跨平台开发的新范式与实战解析 在现代移动应用开发中,“一次编写,多端运行” 已不再是遥不可及的理想。随着 Kotlin 的崛起和 Jetpack Compose 的成熟,Google 推出的 Compose Multiplatform(CMP…...