深度学习中的并行策略概述:2 Data Parallelism
深度学习中的并行策略概述:2 Data Parallelism

数据并行(Data Parallelism)的核心在于将模型的数据处理过程并行化。具体来说,面对大规模数据批次时,将其拆分为较小的子批次,并在多个计算设备上同时进行处理。每个设备负责处理一个子批次,实现并行计算。处理完成后,将各个设备上的计算结果汇总,以便对模型进行统一更新。由于其在深度学习中的普遍应用,数据并行成为了一种广泛支持的并行计算策略,并在主流框架中得到了良好的实现。
以下代码展示了如何在PyTorch中使用nn.DataParallel和DistributedDataParallel实现数据并行,以加速模型的训练过程。
使用nn.DataParallel实现数据并行
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader# 假设我们有一个简单的数据集类
class SimpleDataset(Dataset):def __init__(self, data, target):self.data = dataself.target = targetdef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx], self.target[idx]# 假设我们有一个简单的神经网络模型
class SimpleModel(nn.Module):def __init__(self, input_dim):super(SimpleModel, self).__init__()self.fc = nn.Linear(input_dim, 1)def forward(self, x):return torch.sigmoid(self.fc(x))# 假设我们有一些数据
n_sample = 100
n_dim = 10
batch_size = 10
X = torch.randn(n_sample, n_dim)
Y = torch.randint(0, 2, (n_sample,)).float()
dataset = SimpleDataset(X, Y)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# 初始化模型
device_ids = [0, 1, 2] # 指定使用的GPU编号
model = SimpleModel(n_dim).to(device_ids[0])
model = nn.DataParallel(model, device_ids=device_ids)# 定义优化器和损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
criterion = nn.BCELoss()# 训练模型
for epoch in range(10):for batch_idx, (inputs, targets) in enumerate(data_loader):inputs, targets = inputs.to('cuda'), targets.to('cuda')outputs = model(inputs)loss = criterion(outputs, targets.unsqueeze(1))optimizer.zero_grad()loss.backward()optimizer.step()print(f'Epoch {epoch}, Batch {batch_idx}, Loss: {loss.item()}')
使用DistributedDataParallel实现数据并行
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP# 假设我们有一个简单的数据集类
class SimpleDataset(Dataset):def __init__(self, data, target):self.data = dataself.target = targetdef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx], self.target[idx]# 假设我们有一个简单的神经网络模型
class SimpleModel(nn.Module):def __init__(self, input_dim):super(SimpleModel, self).__init__()self.fc = nn.Linear(input_dim, 1)def forward(self, x):return torch.sigmoid(self.fc(x))# 初始化进程组
def init_process(rank, world_size, backend='nccl'):dist.init_process_group(backend, rank=rank, world_size=world_size)# 训练函数
def train(rank, world_size):init_process(rank, world_size)torch.cuda.set_device(rank)model = SimpleModel(10).to(rank)model = DDP(model, device_ids=[rank])dataset = SimpleDataset(torch.randn(100, 10), torch.randint(0, 2, (100,)).float())sampler = torch.utils.data.distributed.DistributedSampler(dataset, num_replicas=world_size, rank=rank)data_loader = DataLoader(dataset, batch_size=10, sampler=sampler)optimizer = optim.SGD(model.parameters(), lr=0.01)criterion = nn.BCELoss()for epoch in range(10):for inputs, targets in data_loader:inputs, targets = inputs.to(rank), targets.to(rank)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets.unsqueeze(1))loss.backward()optimizer.step()if __name__ == "__main__":world_size = 4torch.multiprocessing.spawn(train, args=(world_size,), nprocs=world_size, join=True)
相关文章:
深度学习中的并行策略概述:2 Data Parallelism
深度学习中的并行策略概述:2 Data Parallelism 数据并行(Data Parallelism)的核心在于将模型的数据处理过程并行化。具体来说,面对大规模数据批次时,将其拆分为较小的子批次,并在多个计算设备上同时进行处…...

Python大数据可视化:基于Python对B站热门视频的数据分析与研究_flask+hive+spider
开发语言:Python框架:flaskPython版本:python3.7.7数据库:mysql 5.7数据库工具:Navicat11开发软件:PyCharm 系统展示 管理员登录 管理员功能界面 排行榜界面 系统管理界面 看板展示 摘要 本项目以对B站热…...

利用 Python 编写一个 VIP 音乐下载脚本
在这篇博客中,我们将介绍如何使用 Python 编写一个简单的 VIP 音乐下载脚本,利用网页爬虫技术从一个音乐网站下载歌曲。通过解析网页,获取歌曲的真实下载链接,并将音乐文件保存到本地。我们将使用 requests 和 BeautifulSoup 库来实现这个过程。 目标 本脚本的主要功能是…...

linux内核如何实现TCP的?
TCP(传输控制协议)是网络通信中的核心协议之一,实现了可靠的、面向连接的、基于字节流的通信。在Linux内核中,TCP的实现相对复杂,涉及多个模块和层次。以下是一些关键概念和机制: 1. 协议栈 Linux 内核中的网络协议栈(Network Stack)是分层设计的,包括链路层、网络层…...

【Spring】基于XML的Spring容器配置——FactoryBean的使用
随着Spring框架应用程序的复杂性增加,开发者需要更加灵活和强大的工具来创建和管理Bean。FactoryBean是Spring提供的一种强大机制,它允许开发者自定义Bean的创建过程。这种机制不仅提高了Bean的创建灵活性,还可以简化复杂对象的构建过程。 在…...

Docker使用——国内Docker的安装办法
文章目录 参考资料前言Mac安装办法Homebrew 安装1. 直接下报错2. 安装homebrew, 用国内镜像3. 安装Docker4. 启动docker服务5. 测试是否安装成功 参考资料 鸣谢大佬文章。 macOS系统中:Docker的安装:https://blog.csdn.net/sulia1234567890…...

电商会员门店消费数据分析
导包 import os import sqlite3 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from IPython.display import display_htmlpd.set_option(max_colwidth,200)%matplotlib inline前期准备 转义路径 # 获取Windows系统下的路…...

Vue.js 入门与进阶:打造高效的前端开发体验
Vue.js 是一款渐进式的 JavaScript 框架,凭借其轻量、易用、灵活的特点,已经成为了前端开发者的首选之一。从简单的交互到复杂的单页应用(SPA),Vue 为开发者提供了一套高效且易于上手的工具。在本文中,我们…...

Java包装类型的缓存
Java 基本数据类型的包装类型的大部分都用到了缓存机制来提升性能。 Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回 True or Fal…...

【蓝桥杯——物联网设计与开发】拓展模块4 - 脉冲模块
目录 一、脉冲模块 (1)资源介绍 🔅原理图 🔅采集原理 (2)STM32CubeMX 软件配置 (3)代码编写 (4)实验现象 二、脉冲模块接口函数封装 三、踩坑日记 &a…...

.NET平台用C#通过字节流动态操作Excel文件
在.NET开发中,通过字节流动态操作Excel文件提供了一种高效且灵活的方式处理数据。这种方法允许开发者直接在内存中创建、修改和保存Excel文档,无需依赖直接的文件储存、读取操作,从而提高了程序的性能和安全性。使用流技术处理Excel不仅简化了…...

SpringMVC详解
文章目录 1 什么是MVC 1.1 MVC设计思想1.2 Spring MVC 2 SpringMVC快速入门3 SpringMVC处理请求 3.1 请求分类及处理方式 3.1.1 静态请求3.1.2 动态请求 3.2 处理静态请求 3.2.1 处理html文件请求3.2.2 处理图片等请求 3.3 处理动态请求 3.3.1 注解说明3.3.2 示例 3.4 常见问题…...

springboot、spring、springmvc有哪些注解
Spring Boot 常用注解 虽然Spring Boot本身并没有引入大量新的注解,但它基于Spring框架,并整合了多种技术和库,使得开发者可以更方便地使用Spring框架的功能。在Spring Boot项目中,常用的注解主要来自于Spring框架本身。 Sprin…...

Apache Commons ThreadUtils 的使用与优化
Apache Commons ThreadUtils 的使用与优化 1. 问题背景 在 Java 系统中,跨系统接口调用通常需要高并发支持,尤其是线程池的合理配置至关重要。如果线程池使用不当,可能导致性能下降,线程等待或过载。 当前问题 使用了 Apache …...
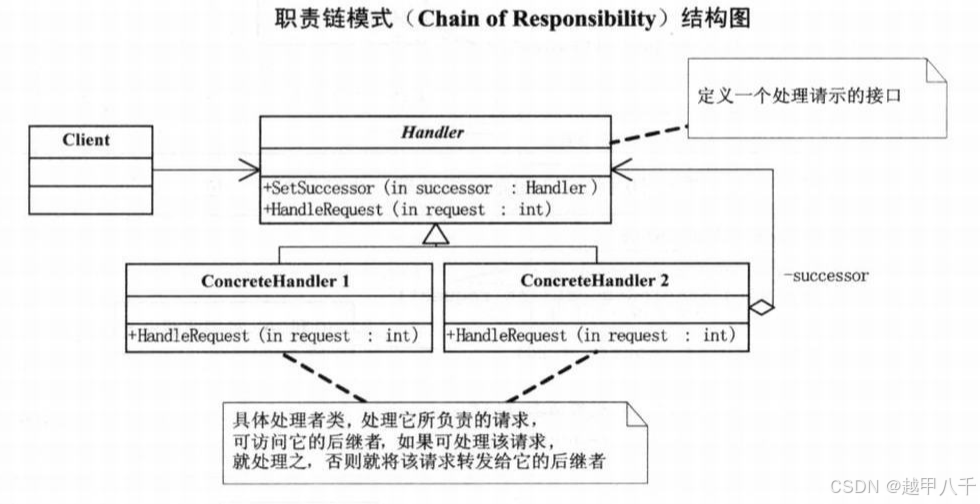
重温设计模式--5、职责链模式
文章目录 职责链模式的详细介绍C 代码示例C示例代码2 职责链模式的详细介绍 定义与概念 职责链模式(Chain of Responsibility Pattern)是一种行为型设计模式,它旨在将请求的发送者和多个接收者解耦,让多个对象都有机会处理请求&am…...

下午四点半
客户的员工竟然背着公司开发报表系统,是在密谋什么大事吗? 之前去线下给客户的员工培训,当时我就对这个小姑娘印象很深刻,因为她后面加了我们的技术人员,问了很多问题,不同于从来没有用过低代码平台的人&a…...

嵌入式单片机中Flash存储器控制与实现
第一:嵌入式单片机内部Flash概述 1.存储器的概念 存储器指的是若干个存储单元的集合,每个存储单元都可以存储若干个二进制数,为了方便的操作存储单元,就为每个存储单元都分配了地址,就可以通过寻址来访问存储单元。由于计算机的处理的数据量较大,并且运算速度都很快,就…...

loki failed to flush
loki 报错 levelerror ts2024-12-27T08:13:10.450140686Z callerflush.go:143 org_idfake msg"failed to flush" err"failed to flush chunks: store put chunk: open /data/loki/chunks/ZmFrZS85ODBmM2U3NzliODg2MjY1OjE5M2VhNDVkYTc4OjE5M2VhNDVlNDdkOjVmMjA…...

微信小程序打印生产环境日志
微信小程序打印生产环境日志 新建一个log.js文件,写入以下代码: let log wx.getRealtimeLogManager ? wx.getRealtimeLogManager() : nullmodule.exports {debug() {if (!log) returnlog.debug.apply(log, arguments)},info() {if (!log) returnlog.i…...

利用 deepin-IDE 的 AI 能力,我实现了文件加密扩展
经过多轮迭代,deepin 文件管理器(dde-file-manager)的扩展功能已经趋于稳定,看到越来越丰富的文管新功能,作为一名技术爱好者,也想自己动手写个插件扩展一下文管的功能。 我选择的开发工具是 deepin-IDE&a…...

面向对象分析模型深入分析
面向对象分析模型深入分析 面向对象分析(Object-Oriented Analysis, OOA)是系统分析师在需求阶段的核心工作方法。它强调从问题域中的客观实体出发,以“对象”为基本单元建立业务模型,而不是从功能或数据流出发。下面从核心概念、三大模型、建模流程到实战案例进行全面解析…...

【Python内存管理终极指南】:20年专家亲授智能内存优化策略与OOM报错秒级修复方案
第一章:Python智能体内存管理策略Python智能体(如基于LLM的Agent、ReAct框架实例或自主任务规划器)在运行过程中常面临对象生命周期动态、引用关系复杂、中间状态缓存频繁等挑战。其内存管理不能仅依赖CPython默认的引用计数与循环垃圾回收&a…...

4.1第一次练习作业
1.在root用户的主目录下创建两个目录分别为haha和hehe,复制hehe目录到haha目录并重命名为apple。[rootlocalhost ~]# mkdir {haha,hehe} [rootlocalhost ~]# cp -r hehe haha [rootlocalhost ~]# cd haha [rootlocalhost haha]# mv hehe apple2.将hehe目录移动到app…...

Spring Boot 3.x面试全攻略:自动配置+事务+AOT,2026最新考点
文章目录一、开场:Spring Boot面试,你真的准备好了吗?二、自动配置:从"黑魔法"到"透明厨房"2.1 面试第一问:自动配置到底咋实现的?2.2 3.5版本新考点:TaskExecutor名称变更…...

小米设备集成终极测试指南:确保HomeAssistant稳定运行的7个关键步骤
小米设备集成终极测试指南:确保HomeAssistant稳定运行的7个关键步骤 【免费下载链接】hass-xiaomi-miot Automatic integrate all Xiaomi devices to HomeAssistant via miot-spec, support Wi-Fi, BLE, ZigBee devices. 小米米家智能家居设备接入Hass集成 项目地…...

G-Helper深度解析:华硕笔记本轻量级性能控制工具实战指南
G-Helper深度解析:华硕笔记本轻量级性能控制工具实战指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix,…...

Load-Use冒险避坑指南:为什么你的RISC流水线转发电路会失效?
Load-Use冒险避坑指南:为什么你的RISC流水线转发电路会失效? 在处理器设计的迷宫中,Load-Use冒险就像是一个精心设计的陷阱,等待着那些过分依赖转发电路的工程师。这种特殊的RAW(Read After Write)冒险场景…...

五大赛道齐亮相!第四届世界科学智能大赛启动报名,首设人文科学赛道
随着人工智能深入科研实践,它不仅在各领域课题的预测、计算等方面屡创新高,也正介入曾被认为高度依赖人类直觉与经验的文化阐释工作。继第四届世界科学智能大赛的创新赛道“AI4S智能体CNS挑战赛”在一个月前率先发布,吹响了自主科研智能体的攻…...

百度智能云千帆AppBuilder API调用全攻略:从密钥获取到实战代码示例
百度智能云千帆AppBuilder API深度集成指南:从密钥管理到高效调用实践 在人工智能应用开发领域,快速集成可靠的AI能力已成为开发者提升效率的关键。百度智能云千帆AppBuilder作为一站式AI原生应用开发平台,其API接口的灵活调用能力让开发者能…...

三维激光熔覆模拟技术:精准控制、高效制造的数字化解决方案
三维激光熔覆模拟最近在车间里看到工程师们调试激光熔覆设备时,我突然意识到这玩意儿和3D打印机完全不是一个难度级别——金属粉末被激光瞬间融化又凝固的过程,简直就是微观层面的魔法表演。今天咱们就来扒一扒这个魔法背后的代码咒语。先看这个温度场模…...