5.系统学习-PyTorch与多层感知机
PyTorch与多层感知机
- 前言
- PyTroch 简介
- 张量(Tensor)
- 张量创建
- 张量的类型
- 数据类型和 dtype 对应表
- 张量的维度变换:
- 张量的常用操作
- 矩阵或张量计算
- Dataset and DataLoader
- PyTorch下逻辑回归与反向传播
- 数据表格
- DNN(全连结网络)
- 回归案例
- 模型创建
- 保存和加载模型
- 模型训练与验证
前言
这里先了解简单的概念,直接上手尝试。
下一节进行实战
链接: minst数据集分类
在之后第7节会分部分进行说明。
线性回归/逻辑回归可以看成最简单的深度学习网络:
- 网络包含一层全联接层
- 采用梯度下降更新网络权重(回归参数)
- 直到设定的迭代次数终止训练
重新回顾一下线性回归的内容,我们可以更加简单直观的理解深度学习。我们将采用当下学术以及工业界最流行深度学习框架 PyTorch,其语法简介,并且借鉴了很多成功设计,比如 Numpy 数组的概念及函数,使得我们可以将很多其他库(Numpy 等)的使用经验迁移到 PyTorch 中来。
- 了解 PyTorch
- Tensor 创建、类型、维度与操作
- Dataset
- PyTorch 下逻辑回归与反向传播
- 深层网络、非线性拟合能力
- 模型保存、读取
- 模型的分类、回归模型构建与训练
PyTroch 简介
PyTorch是由Meta(原Facebook)开源的深度学习框架,得益于其简洁干净的接口封装,与Numpy几乎一致化的向量操作,灵活且Pythonic的语法,用户群体增长非常迅速,2019年开始主流AI会议统计中采用Pytorch框架论文数量已经超过Tensorflow。原生Pytorch已经提供了非常全面的能力,包括模型搭建、训练、部署、分布式、线性代数运算等。

Pytorch安装非常简单,只需要进入官网:https://pytorch.org/, 选择你的操作系统、安装方法、硬件环境后,复制安装命令在终端下(terminal 或CMD)执行即可。需要注意的是,GPU用户需要提前安装Nvidia驱动,但不必安装CUDNN等加速组建,CUDNN等在进行Pytorch安装时候会自动安装其必要部分。

张量(Tensor)
在实际使用PyTorch的过程中,Tensor是我们操作的基本数据类型,其特性与Numpy Array几乎完全一致,只不过在pytorch中,能够通过进行梯度的计算与传播。在正式使用PyTorch进行深度学习建模之前,我们需要熟练掌握PyTorch中张量的基本操作。
#
导入PyTorch包import torch
import numpy as np
print(torch.__version__)
张量创建
# 通过列表创建t = torch.tensor([1, 2])
t

# 通过numpy 数组创建张量a = np.array((1, 2))
t1 = torch.tensor(a)
t1

# 通过生成器创建,与numpy 完全一致
torch.arange(9)

np.arange(9)

# 随机创建一个均值为0、标准差为1的数据,与numpy 完全一致
torch.randn(3, 4)

np.random.randn(3, 4)

# torch.Tensor与np.ndarray转换tensor = torch.tensor([1, 2])
print(tensor)
# tensor > numpy array
array = tensor.numpy()
print(array)
# numpy array > tensor tensor = torch.tensor(array)
print(tensor)
tensor = torch.from_numpy(array)
print(tensor)

张量的类型
在神经网络建模过程中,最常用的是torch.float 和 torch.long类型,其中float类型用于连续变量,long类型用于整数变量。
数据类型和 dtype 对应表
| 数据类型 | dtype |
|---|---|
| 32bit 浮点数 | torch.float32 或 torch.float |
| 64bit 浮点数 | torch.float64 或 torch.double |
| 16bit 浮点数 | torch.float16 或 torch.half |
| 8bit 无符号整数 | torch.uint8 |
| 8bit 有符号整数 | torch.int8 |
| 16bit 有符号整数 | torch.int16 或 torch.short |
| 32bit 有符号整数 | torch.int32 或 torch.int |
| 64bit 有符号整数 | torch.int64 或 torch.long |
| 布尔类型 | torch.bool |
# 初始化一个tensor tensor = torch.arange(10)
print(tensor)
# 此时数据类型为long
tensor.dtype 
# 一般的,深度学习模型要求的输入大部分为float类型﴾float32,单精度﴿
# 转化为float 类型,有两种办法# 1﴿
tensor.float()
# 2﴿
tensor.type(torch.float)

# 转换为长整型t.long()

# 转化为双精度浮点型t.double()

张量的维度变换:
- tensor.reshape方法,能够灵活调整张量的 size,和numpy中的reshape 特性一致
- 舍弃维度 tensor.squeeze ,与 numpy.squeeze 特性一致
- 添加维度 tensor.unsqueeze ,与 numpy.expand_dims 特性一致
- 维度顺序转换, tensor.transpose适用于两个维度互换, tensor.permute 适用于对所有维度重新排序
# reshape
x = torch.rand(4, 3, 2) x_reshpae = x.reshape(4, 6) print(x.shape, x_reshpae.shape)

# squeeze x = torch.rand(4, 1) print(x.shape, x.squeeze().shape)

# unsqueeze x = torch.rand(4) print(x.shape, x.unsqueeze(0).shape, x.unsqueeze(1).shape)

# transpose x = torch.rand(4, 3, 2) print(x.shape, x.transpose(1, 2).shape, # 将dim=1, dim=2 维度互换x.transpose(0, 2).shape # 将dim=0, dim=2 维度互换)

# permute x = torch.rand(4, 3, 2) print(x.shape, x.permute(1, 2, 0).shape # 将原本的1,2,0维度按照顺序重新排列)

张量的常用操作
# 创建张量
t2 = torch.tensor([[1, 2], [3, 4]])# 查看张量的属性
print(t2.numel()) # 总共有多少个元素 (num elements)
print(t2.shape) # 张量的形状 (等价于 .size())
print(t2.size()) # 张量的形状 (同 .shape)
print(t2.ndim) # 张量的维度数量 (number of dimensions)
# 注意:当需要计算的结果张量转化为单独的数值进行输出,需要使用.item。
n = torch.tensor(1.0)
print(n.shape) # 这是一个0维张量
print(n) # 需要采用item 方法将0维张量转化为数值
n.item()

# 张量的索引、切片与Numpy Array完全一致
data_1 = torch.arange(1, 15)print(data_1[1: 6]) # 索引其中2-7号元素,并且左包含右不包含
print(data_1[2:10:2]) # 索引其中3-11号元素,左包含右不包含,且隔1个数取1个
print(data_1[2::3]) # 从第3个元素开始索引,一直到结尾,并且每隔2个数取1个

# 有类似numpy.zeros函数a = torch.zeros(2, 3)
a z

# 有类似numpy.ones
b = torch.ones(2, 3)
b

np.concatenate#的第一个参数必须是一个元组或列表

# 张量拼接 torch.cat ,完全类似于
np.concatenate
torch.cat([a, b], 0) # 在第0个维度进行拼接
torch.cat([a, b], dim=1) # 在第1个维度进行拼接

矩阵或张量计算
# 元素级别的四则运算﴾+ */﴿,要求矩阵shape完全一致或者可以进行广播,与numpy array特性一致。x = torch.rand(4, 3)
y = torch.rand(4, 3) print((x + y).shape) print((x * y).shape)

# 矩阵乘法,可以用魔法符号 @ 或者使用torch.mm 方法print(x.shape, y.T.shape) print((x @ y.T).shape)
print((torch.mm(x, y.T).shape))

# batch 矩阵乘法, 可以用魔法符号@ 或者使用torch.bmm 方法batch_size = 4
x = torch.rand(batch_size, 3, 2)
y = torch.rand(batch_size, 2, 3) print((x@y).shape)
print((torch.bmm(x, y).shape))

Dataset and DataLoader
在PyTorch中,我们需要构造Dataset和DataLoader来迭代数据,训练模型,首先通过一个简单的案例讲解一下Dataset的使用.
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):def __init__(self, x, y):# 初始化,保存数据self.x = xself.y = ydef __len__(self):# 返回数据集样本个数return len(self.y)def __getitem__(self, item):# 根据索引获取数据,并进行必要的类型转换xi = torch.tensor(self.x[item]).float() # 转为浮点型张量yi = torch.tensor(self.y[item]).float() # 转为浮点型张量return xi, yi
X = np.random.rand(200, 12)
Y = np.random.rand(200, 1) ds = MyDataset(X, Y)
ds[120]

xi, yi = ds[0] print(xi.shape)
print(yi.shape)

dl = DataLoader(ds, batch_size=4, shuffle=True, # 是否乱序)
for batch_x, batch_y in dl: break print(batch_x.shape, batch_y.shape)

PyTorch下逻辑回归与反向传播
在学习逻辑回归课程时,我们了解到其优化过程采用的是梯度下降方法,现在我们就以逻辑回归为案例,讲解PyTorch下如何搭建模型,并进行训练。因为逻辑回归只具备线性分类能力,因此我们构造一个线性可分的数据集,数据只有两个特征(x1,x2),当两个特征下的取值都为1时,分类标签为1,其他时候分类标签为0。
数据表格
| x1 | x2 | y |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 1 | 1 |
导入库import torch.nn as nn # 模型搭建import torch.nn.functional as F # 内部封装了非常多的计算函数import matplotlib.pyplot as plt
%matplotlib inline torch.manual_seed(1)

# 准备数据x = torch.tensor([[0,0],[1,0],[0,1],[1,1]]).float()
y = torch.tensor([0, 0, 1, 1]).float() class LRDataset(Dataset): def __init__(self, x, y): self.x = x self.y = y def __len__(self): return len(self.y) def __getitem__(self, item): return self.x[item], self.y[item] ds = LRDataset(x, y)
dl = DataLoader(ds, batch_size=4, shuffle=True) plt.scatter( x.data.numpy()[:, 0], #提取所有点的第一个坐标(x 轴坐标)x.data.numpy()[:, 1], #提取所有点的第二个坐标(y 轴坐标)c=y.data.numpy(), s=100, lw=0)
plt.show()

# 使用PyTorch中nn这个库来构建逻辑回归模型
import torch
import torch.nn as nnclass LogisticRegressionModel(nn.Module): def __init__(self, n_feature): super().__init__() # 必须执行的标准步骤self.linear = nn.Linear(n_feature, 1) # 线性层self.sigmoid = nn.Sigmoid() # sigmoid激活函数def forward(self, x): x = self.linear(x) pred = self.sigmoid(x) return pred # 初始化模型
model = LogisticRegressionModel(n_feature=2)
print(model)# 使用优化器SGD
optimizer = torch.optim.SGD(model.parameters(), # 需要优化的模型参数lr=0.1 # 学习率
)# 定义损失函数,采用二分类交叉熵损失
loss_func = torch.nn.BCELoss()
# 观察模型的输入与输出
for batch_x, batch_y in dl: # 从 DataLoader 中取出一个 batchbreak # 取出第一个 batch 后退出循环# 打印输入和输出的维度
print(f"输入维度: {batch_x.shape}") # 输入特征的维度
print(f"输出维度: {model(batch_x).shape}") # 模型输出的维度
print(f"标签维度: {batch_y.shape}") # 标签(真实值)的维度
print(f"model squeeze 输出维度: {model(batch_x).squeeze().shape}") # 模型输出的维度(降维后)# 说明
# 在计算损失函数时,将模型输出使用 squeeze 降低维度,以保持与标签的维度一致,从而正确计算 loss。

# 定义一个训练函数,训练过程中,根据loss,进行梯度下降
def train_fn(model, optimizer, dl):losses = [] # 用于存储每个批次的损失值for batch_x, batch_y in dl:# 模型预测pred = model(batch_x).squeeze() # 模型输出,并使用squeeze降维# 计算损失loss = loss_func(pred, batch_y)# 梯度清零optimizer.zero_grad()# 反向传播,计算梯度loss.backward()# 执行梯度下降,更新参数optimizer.step()# 获取损失值并保存到CPU中,避免GPU内存占用过多loss = loss.item() # 取出当前批次的损失值losses.append(loss) # 保存损失值# 返回平均损失和最后一次预测结果return np.mean(losses), pred
for t in range(1,201): loss, pred = train_fn(model, optimizer, dl) if t % 50 == 0: print(loss)

DNN(全连结网络)
逻辑回归&线性回归只包含一个线性层(需要注意,逻辑回归虽然对数据进行了sigmoid映射,但本质的分类平面依然是线性平面),不具备对非线性关系的拟合能力。DNN包括多个线性层和激活层,其中线性层通过学习一个映射矩阵,对输入进行线性映射,激活层使用ReLU,Tahn等非线性函数使得模型具备非线性建模能力。如果不加入激活层,只是简单的堆叠线性层,多层网络和单层网络本质上是等价的。
# ReLU 函数图像relu = torch.nn.ReLU() x = torch.arange(-1, 1, 0.1)
y = relu(x) plt.plot(x.numpy(), y.numpy())

# Tanh 函数图像tanh = torch.nn.Tanh()
x = torch.arange(-10, 10, 0.1)
y = tanh(x)
plt.plot(x.numpy(), y.numpy())

回归案例
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # 生成数据x
y = x.pow(2) + 0.2*torch.rand(x.size()) # 生成x对应的数据y plt.scatter(x.data.numpy(), y.data.numpy())
plt.show()

# 创建网络class Net(torch.nn.Module): def __init__(self, n_feature, n_hidden, n_output): super(Net, self).__init__() self.fc1 = torch.nn.Linear(n_feature, n_hidden) # 隐藏层self.activation = nn.ReLU() self.fc2 = torch.nn.Linear(n_hidden, n_output) # 输出层def forward(self, x): x = self.activation(self.fc1(x)) # 对隐藏层数据使用激活函数y = self.fc2(x) # 输出return y
net = Net(n_feature=1, n_hidden=10, n_output=1) # 定义网络print(net) # net architecture

optimizer = torch.optim.SGD(net.parameters(), lr=0.2) # 优化器loss_func = torch.nn.MSELoss() # 损失函数
# 这里我们没有使用Dataset和DataLoader,每次迭代使用全部数据。import matplotlib.pyplot as pltplt.ion() # 打开交互模式,便于动态更新绘图for t in range(100): # 训练100次prediction = net(x) # 将输入数据送入模型loss = loss_func(prediction, y) # 计算预测值和真实值的损失optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播optimizer.step() # 梯度优化,更新参数if t % 20 == 0: # 每隔20次迭代更新一次绘图# 显示学习过程plt.cla() # 清除当前图形plt.scatter(x.data.numpy(), y.data.numpy()) # 绘制训练数据的散点图plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5) # 绘制拟合曲线plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'}) # 显示当前损失plt.pause(0.1) # 暂停0.1秒,用于更新绘图plt.ioff() # 关闭交互模式
plt.show() # 显示最终图像




模型创建
- 定义模型类
- 使用nn.Sequential 快速创建简单的顺序执行的模型
# 通常在定义比较复杂的模型时,我们倾向与使用定义模型类的方法# 在__init__ 中定义所有模型的组件# 在forward 中定义模型的计算图class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.fc1 = torch.nn.Linear(2, 10) self.activation = nn.ReLU() self.fc2 = torch.nn.Linear(10, 1) def forward(self, x): x = self.activation(self.fc1(x)) x = self.fc2(x) return x net1 = Net()
print(net1) 
# 简单的按顺序执行的模型我们可以采用nn.Sequential 定义net2 = nn.Sequential( nn.Linear(2, 10), nn.ReLU(), nn.Linear(10, 1)
) print(net2)

x = torch.rand(4, 2) print(net1(x).shape)
print(net2(x).shape)

保存和加载模型
#保存和加载模型
# 1. 当模型训练好后,保存模型参数`state_dict` torch.save(net1.state_dict(), 'model.bin') # 2. 加载模型时,首先初始化模型,再加载模型参数net1 = Net()
net1.load_state_dict(torch.load('model.bin'))

模型训练与验证
#模型训练与验证
net1.train() # 该语句让模型进入训练状态net1.eval() # 该语句让模型进入验证/预测状态
相关文章:
5.系统学习-PyTorch与多层感知机
PyTorch与多层感知机 前言PyTroch 简介张量(Tensor)张量创建张量的类型数据类型和 dtype 对应表张量的维度变换:张量的常用操作矩阵或张量计算 Dataset and DataLoaderPyTorch下逻辑回归与反向传播数据表格 DNN(全连结网络&#x…...

AIGC与虚拟身份及元宇宙的未来:虚拟人物创作与智能交互
个人主页:云边有个稻草人-CSDN博客 目录 引言 一、AIGC在元宇宙中的作用 1.1 AIGC与虚拟人物创作 1.1.1 生成虚拟人物外观 1.1.2 个性化虚拟角色设计 1.2 AIGC与虚拟角色的行为与交互 1.2.1 行为生成与强化学习 1.2.2 对话生成与自然语言处理 二、AIGC实现…...

基于大模型LLM 应用方案
现如今LLM 应用 面临的主要问题 准确性,2. 高成本,3. 专业性,4. 时效性,5. 安全性 信息偏差/幻觉 (大模型由于数据缺陷/知识边界 会使用 可靠性下降)知识更新滞后性 (LLM 基于静态数据集训练,可能导致知识更…...

实用技巧:关于 AD修改原理图库如何同步更新到有原理图 的解决方法
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/144738332 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...

区块链平台安全属性解释
区块链平台安全属性解释 双向认证 解释:双向认证是指在通信过程中,**通信双方都需要对对方的身份进行验证,确保对方是合法的、可信任的实体。**只有双方身份都得到确认后,通信才会被允许进行,从而防止非法用户的接入和数据的窃取或篡改。举例:在基于区块链和联邦学习的数…...
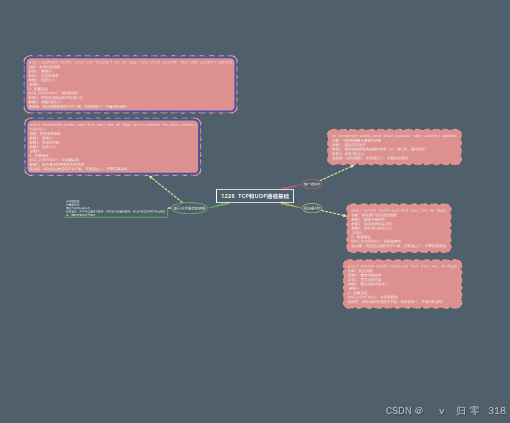
1228作业
思维导图 作业 TCP的cs模型 服务器 //服务器 #include <myhead.h> #define PORT 6667 #define IP "192.168.124.94" #define BACKLOG 128 int main(int argc, const char *argv[]) {//创建套接字int oldfd socket(AF_INET,SOCK_STREAM,0);if(oldfd-1){perro…...

Machine-learning the skill of mutual fund managers
Machine-learning the skill of mutual fund managers – 论文阅读 文章目录 Machine-learning the skill of mutual fund managers -- 论文阅读AbstractIntroductionQuestionMain findingscontributionsliterature reviewDataSampleHoldings-based characteristicsModelOptima…...
Windows下Python+PyCharm的安装步骤及PyCharm的使用
Windows下PythonPyCharm的安装步骤及PyCharm的使用 文章目录 Windows下PythonPyCharm的安装步骤及PyCharm的使用一、Python的安装(1)环境准备(2)Python安装(3)pip组件的安装 二、PyCharm的安装(…...

Anaconda+PyTorch(CPU版)安装
1.Anaconda下载 Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 如果已安装python,下载之前要彻底删除之前下载的python 2.Anaconda安装 3.添加环境变量 //根据实际安装路径进行更改 D:\Anaconda D:\Anaconda\Scripts D:\…...

第 28 章 - ES 源码篇 - Elasticsearch 启动与插件加载机制解析
前言 不管是什么框架,启动类里面做的一定是初始化的工作! 启动 ES 节点的启动逻辑,全部都在 org.elasticsearch.bootstrap 包下。 启动类为:Elasticsearch#main(final String[] args) 与大多数框架启动类一致。启动类主要负责的…...

机床数据采集网关在某机械制造企业的应用
随着工业4.0时代的到来,智能制造已成为制造业转型升级的重要方向。数控机床作为现代制造业的核心设备,其运行状态和加工参数的数据实时采集与分析对于提升生产效率、优化生产流程具有关键意义。 背景概述 某机械制造企业拥有多台数控机床,这…...
)
美团Android开发200道面试题及参考答案(上)
http 三次握手 / 四次挥手具体过程,信号量的变化,只有两次握手行不行 三次握手过程: 第一次握手:客户端向服务器发送一个 SYN(同步)标志位为 1 的 TCP 报文段,其中包含客户端的初始序列号(ISN),此时客户端进入 SYN_SENT 状态,表示客户端请求建立连接。第二次握手:服…...

MQTT协议的应用场景及特点和常见的概念03
发布者发送数据---》代理软件Broker---》订阅者接收数据 发布者和订阅者进行隔离 1.空间上的隔离 2.时间上的隔离 MQTT常见的应用场景:物联网行业 MQTT常见的特点: 1.轻量级:MQTT协议占用的系统资源较少,数据报文较小 2.可靠性较强࿱…...

电脑缺失sxs.dll文件要怎么解决?
一、文件丢失问题:以sxs.dll文件缺失为例 当你在运行某个程序时,如果系统提示“找不到sxs.dll文件”,这意味着你的系统中缺少了一个名为sxs.dll的动态链接库文件。sxs.dll文件通常与Microsoft的.NET Framework相关,是许多应用程序…...

数据处的存储与处理——添加数组
Numpy模块中的append()函数和insert()函数 1、append()函数的使用 append(arr,values,axisNone) arr 必选,要添加元素的数组 values 必选,要添加的元素数组 axis 可选,默认值为None。当省略该参数时,表示在…...

24-12-28-pytorch深度学习CUDA的GPU加速环境配置步骤
文章目录 pytorch深度学习CUDA的GPU加速环境配置步骤1. 更新cuda驱动2. 更新完成cuda驱动后,查看对应的驱动版本3. 根据驱动的版本号,下载对应的cuda-toolkit4. CUDA是否配置成功5. 配置CUDNN6. 配置torch pytorch深度学习CUDA的GPU加速环境配置步骤 1.…...

YOLO系列正传(五)YOLOv4论文精解(上):从CSPNet、SPP、PANet到CSPDarknet-53
系列文章 YOLO系列基础 YOLO系列基础合集——小白也看得懂的论文精解-CSDN博客 YOLO系列正传 YOLO系列正传(一)类别损失与MSE损失函数、交叉熵损失函数-CSDN博客 YOLO系列正传(二)YOLOv3论文精解(上)——从FPN到darknet-53-C…...

【AIGC-ChatGPT副业提示词指令 - 动图】魔法咖啡馆:一个融合创意与治愈的互动体验设计
引言 在当今快节奏的生活中,咖啡早已不仅仅是提神醒脑的饮品,更成为了一种情感寄托和生活态度的表达。本文将介绍一个独特的"魔法咖啡馆"互动体验设计,通过将咖啡与情感、魔法元素相结合,创造出一个充满想象力和治愈感…...

AIGC在电影与影视制作中的应用:提高创作效率与创意的无限可能
云边有个稻草人-CSDN博客 目录 引言 一、AIGC在剧本创作中的应用 1.1 剧本创作的传统模式与挑战 1.2 AIGC如何协助剧本创作 1.3 未来的剧本创作:AI辅助的协同创作 二、AIGC在角色设计中的应用 2.1 传统角色设计的挑战 2.2 AIGC如何协助角色设计 三、AIGC在…...

第三百四十六节 JavaFX教程 - JavaFX绑定
JavaFX教程 - JavaFX绑定 JavaFX绑定同步两个值:当因变量更改时,其他变量更改。 要将属性绑定到另一个属性,请调用bind()方法,该方法在一个方向绑定值。例如,当属性A绑定到属性B时,属性B的更改将更新属性A…...

Alibaba DASD-4B Thinking 对话工具在网络安全领域的应用:智能威胁分析与响应
Alibaba DASD-4B Thinking 对话工具在网络安全领域的应用:智能威胁分析与响应 每天,安全运维团队的工程师们都要面对海量的安全告警。防火墙日志、入侵检测系统的报警、终端防护软件的提示……这些信息像潮水一样涌来。传统的处理方式,往往依…...

Cursor 2.2的Visual Editor实战:如何像改Figma一样,5分钟重构一个Vue/React页面布局
Cursor 2.2的Visual Editor实战:如何像改Figma一样,5分钟重构一个Vue/React页面布局 重构老旧前端页面就像给老房子翻新——既要保留主体结构,又要让外观焕然一新。传统方式下,我们不得不在代码编辑器与浏览器之间反复切换&#x…...

从手机拍照到专业扫描:5种主流三维重建数据集的‘幕后’采集故事与技术选型
从手机拍照到专业扫描:5种主流三维重建数据集的‘幕后’采集故事与技术选型 在数字孪生和元宇宙技术快速发展的今天,高质量三维重建数据集已成为计算机视觉领域的战略资源。不同于普通用户随手拍摄的二维照片,专业级三维数据集背后隐藏着精密…...
:3.7GB模型显存占用仅18.2GB实测)
Graphormer部署教程(RTX 4090):3.7GB模型显存占用仅18.2GB实测
Graphormer部署教程(RTX 4090):3.7GB模型显存占用仅18.2GB实测 1. 项目介绍 Graphormer是一种基于纯Transformer架构的图神经网络,专门为分子属性预测任务设计。这个模型在分子图(原子-键结构)的全局结构…...

从省赛失误到国赛精进:十五届蓝桥杯EDA组PCB布局实战复盘与优化
1. 省赛翻车现场:一个封装错误引发的惨案 去年省赛那天,我永远记得提交作品前那种胸有成竹的感觉。直到成绩公布看到省二的结果,才发现自己犯了个低级错误——数码管封装绑定错了。打开设计文件一看,本该是标准尺寸的数码管&#…...

Mustache错误处理与调试:7个常见问题排查清单
Mustache错误处理与调试:7个常见问题排查清单 【免费下载链接】mustache Logic-less Ruby templates. 项目地址: https://gitcode.com/gh_mirrors/mu/mustache Mustache是一款流行的无逻辑Ruby模板引擎,但开发者在实际使用中经常会遇到各种错误和…...

SeqGPT-560M智能客服问答系统部署指南
SeqGPT-560M智能客服问答系统部署指南 1. 引言 想象一下这样的场景:你的电商平台每天收到上千条客户咨询,从"这个衣服有货吗"到"怎么申请退货",问题五花八门。传统客服需要一个个手动回复,效率低下还容易出…...

终极指南:如何实时监控Slonik连接池状态与性能指标
终极指南:如何实时监控Slonik连接池状态与性能指标 【免费下载链接】slonik A Node.js PostgreSQL client with runtime and build time type safety, and composable SQL. 项目地址: https://gitcode.com/gh_mirrors/sl/slonik Slonik作为一款为Node.js打造…...
)
手把手教你用TI F28P65X开发板实现LED定时闪烁(基于CPU Timer2,含完整源码)
从零玩转TI F28P65X开发板:CPU Timer2实现可调频LED闪烁实战指南 刚拿到TI F28P65X开发板时,面对密密麻麻的引脚和复杂的开发环境,很多嵌入式新手会感到无从下手。本文将带你用最直观的方式,通过控制LED闪烁这个经典入门项目&…...

5大核心能力解析:YimMenu如何重塑GTA5游戏体验与安全防护
5大核心能力解析:YimMenu如何重塑GTA5游戏体验与安全防护 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/Y…...