为什么深度学习和神经网络要使用 GPU?
为什么深度学习和神经网络要使用 GPU?
本篇文章的目标是帮助初学者了解 CUDA 是什么,以及它如何与 PyTorch 配合使用,更重要的是,我们为何在神经网络编程中使用 GPU。
图形处理单元 (GPU)
要了解 CUDA,我们需要对图形处理单元 (GPU) 有一定的了解。GPU 是一种擅长处理 专门化 计算的处理器。
这与中央处理单元 (CPU) 形成对比,CPU 是一种擅长处理 通用 计算的处理器。CPU 是为我们的电子设备上大多数典型计算提供动力的处理器。
GPU 可以比 CPU 快得多,但并非总是如此。GPU 相对于 CPU 的速度取决于正在执行的计算类型。最适合 GPU 的计算类型是能够 并行 进行的计算。
并行计算
并行计算是一种将特定计算分解为可以同时进行的独立较小计算的计算类型。然后将得到的计算结果重新组合或同步,以形成原始较大计算的结果。

一个较大任务可以分解为的任务数量取决于特定硬件上包含的内核数量。内核是实际在给定处理器内进行计算的单元,CPU 通常有四、八或十六个内核,而 GPU 可能有数千个内核。
还有其他一些技术规格也很重要,但本描述旨在传达一般概念。
有了这些基础知识,我们可以得出结论,使用 GPU 进行并行计算,并且最适合使用 GPU 解决的任务是能够并行完成的任务。如果计算可以并行完成,我们就可以通过并行编程方法和 GPU 加速我们的计算。
神经网络是令人尴尬的并行
现在让我们关注神经网络,看看为何深度学习如此大量地使用 GPU。我们刚刚了解到 GPU 适合进行并行计算,而这一事实正是深度学习使用它们的原因。神经网络是 令人尴尬的并行。
在并行计算中,一个 令人尴尬的并行 任务是指几乎不需要将整体任务分解为一组可以并行计算的较小任务。
令人尴尬的并行任务是那些很容易看出一组较小任务彼此独立的任务。

神经网络之所以令人尴尬的并行,原因就在于此。我们使用神经网络进行的许多计算可以很容易地分解为较小的计算,使得一组较小的计算彼此不依赖。一个这样的例子是卷积。
卷积示例
让我们来看一个示例,卷积操作:
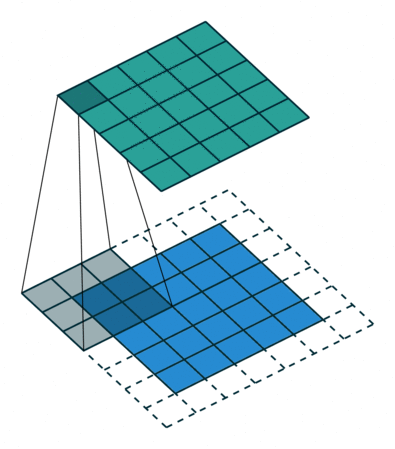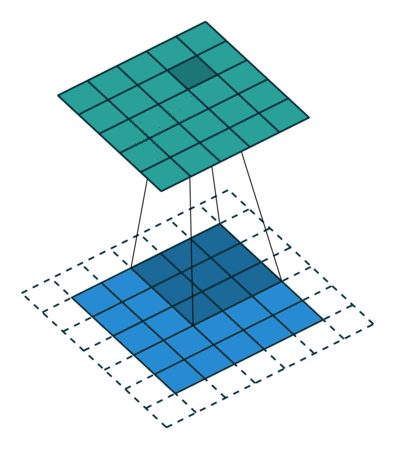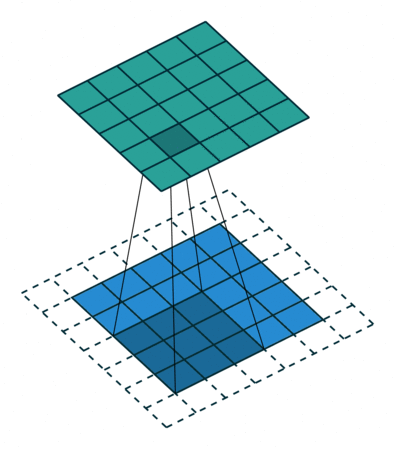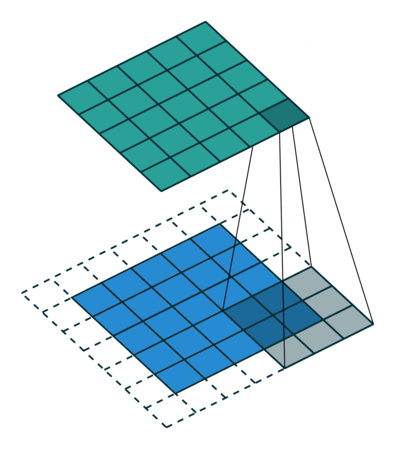
这个动画展示了没有数字的卷积过程。我们在底部有一个蓝色的输入通道。一个在底部阴影的卷积滤波器在输入通道上滑动,以及一个绿色的输出通道:
- 蓝色(底部) - 输入通道
- 阴影(在蓝色上方) -
3 x 3 卷积滤波器 - 绿色(顶部) - 输出通道
对于蓝色输入通道上的每个位置,3 x 3 滤波器都会进行一次计算,将蓝色输入通道的阴影部分映射到绿色输出通道的相应阴影部分。
在动画中,这些计算是依次一个接一个地进行的。然而,每次计算都与其他计算独立,这意味着没有计算依赖于其他任何计算的结果。
因此,所有这些独立的计算都可以在 GPU 上并行进行,并产生整体的输出通道。
这使我们能够看到,通过使用并行编程方法和 GPU,可以加速卷积操作。
Nvidia 硬件 (GPU) 和软件 (CUDA)
这就是 CUDA 发挥作用的地方。Nvidia 是一家设计 GPU 的技术公司,他们创建了 CUDA 作为一个软件平台,与他们的 GPU 硬件配合使用,使开发人员更容易构建利用 Nvidia GPU 并行处理能力加速计算的软件。

Nvidia GPU 是实现并行计算的硬件,而 CUDA 是为开发人员提供 API 的软件层。
因此,你可能已经猜到,要使用 CUDA,需要一个 Nvidia GPU,CUDA 可以从 Nvidia 的网站免费下载和安装。
开发人员通过下载 CUDA 工具包来使用 CUDA。工具包中包含专门的库,如 cuDNN,CUDA 深度神经网络库。

PyTorch 内置 CUDA
使用 PyTorch 或任何其他神经网络 API 的一个好处是并行性已经内置在 API 中。这意味着作为神经网络程序员,我们可以更多地专注于构建神经网络,而不是性能问题。
对于 PyTorch 来说,CUDA 从一开始就内置其中。不需要额外下载。我们只需要有一个支持的 Nvidia GPU,就可以使用 PyTorch 利用 CUDA。我们不需要直接了解如何使用 CUDA API。
当然,如果我们想在 PyTorch 核心开发团队工作或编写 PyTorch 扩展,那么直接了解如何使用 CUDA 可能会很有用。
毕竟,PyTorch 是用所有这些编写的:
- Python
- C++
- CUDA
在 PyTorch 中使用 CUDA
在 PyTorch 中利用 CUDA 非常容易。如果我们希望某个特定的计算在 GPU 上执行,我们可以通过在数据结构 (张量) 上调用 cuda() 来指示 PyTorch 这样做。
假设我们有以下代码:
> t = torch.tensor([1,2,3])
> t
tensor([1, 2, 3])以这种方式创建的张量对象默认在 CPU 上。因此,使用这个张量对象进行的任何操作都将在 CPU 上执行。
现在,要将张量移动到 GPU 上,我们只需编写:
> t = t.cuda()
> t
tensor([1, 2, 3], device='cuda:0')这种能力使 PyTorch 非常灵活,因为计算可以选择性地在 CPU 或 GPU 上执行。
GPU 可能比 CPU 慢
我们说我们可以选择性地在 GPU 或 CPU 上运行我们的计算,但为何不将 每个 计算都运行在 GPU 上呢?
GPU 不是比 CPU 快吗?
答案是 GPU 只对特定 (专门化) 任务更快。我们可能会遇到的一个问题是瓶颈,这会降低我们的性能。例如,将数据从 CPU 移动到 GPU 是代价高昂的,所以在这种情况下,如果计算任务很简单,整体性能可能会更慢。
将相对较小的计算任务移动到 GPU 上不会让我们加速很多,实际上可能会让我们变慢。记住,GPU 适合将任务分解为许多较小任务,如果计算任务已经很小,我们将不会通过将任务移动到 GPU 上获得太多好处。
因此,通常在刚开始时只使用 CPU 是可以接受的,随着我们解决更大更复杂的问题,开始更频繁地使用 GPU。
GPGPU 计算
起初,使用 GPU 加速的主要任务是计算机图形,因此得名图形处理单元,但在近年来,出现了许多其他种类的并行任务。我们已经看到的一个这样的任务是深度学习。
深度学习以及许多其他使用并行编程技术的科学计算任务,正在导致一种新的编程模型的出现,称为 GPGPU 或通用 GPU 计算。
GPGPU 计算现在更常见地仅称为 GPU 计算或加速计算,因为现在在 GPU 上执行各种任务变得越来越普遍。
Nvidia 在这个领域一直是先驱。Nvidia 的 CEO 黄仁勋很早就设想了 GPU 计算,这就是 CUDA 在大约十年前被创建的原因。
尽管 CUDA 已经存在很长时间了,但它现在才真正开始腾飞,Nvidia 直到目前为止在 CUDA 上的工作是 Nvidia 在深度学习 GPU 计算方面处于领先地位的原因。
当我们听到黄仁勋谈论 GPU 计算栈时,他指的是 GPU 作为底部的硬件,CUDA 作为 GPU 顶部的软件架构,最后是像 cuDNN 这样的库位于 CUDA 顶部。
这个 GPU 计算栈支持在芯片上进行通用计算能力,而芯片本身是非常专门化的。我们经常在计算机科学中看到像这样的栈,因为技术是分层构建的,就像神经网络一样。
位于 CUDA 和 cuDNN 顶部的是 PyTorch,这是我们将会工作的框架,最终支持顶部的应用程序。
相关文章:
为什么深度学习和神经网络要使用 GPU?
为什么深度学习和神经网络要使用 GPU? 本篇文章的目标是帮助初学者了解 CUDA 是什么,以及它如何与 PyTorch 配合使用,更重要的是,我们为何在神经网络编程中使用 GPU。 图形处理单元 (GPU) 要了解 CUDA,我们需要对图…...

Yocto 项目中的交叉编译:原理与实例
Yocto 项目是一个强大的工具集,它专注于为嵌入式系统生成定制的 Linux 发行版。交叉编译在 Yocto 项目中扮演着核心角色,它使得开发者能够在功能强大的宿主机上构建适用于资源受限目标设备的软件系统。这篇文章将从运行原理、实际案例和工具链组成等角度…...

Python入门:7.Pythond的内置容器
引言 Python 提供了强大的内置容器(container)类型,用于存储和操作数据。容器是 Python 数据结构的核心部分,理解它们对于写出高效、可读的代码至关重要。在这篇博客中,我们将详细介绍 Python 的五种主要内置容器&…...
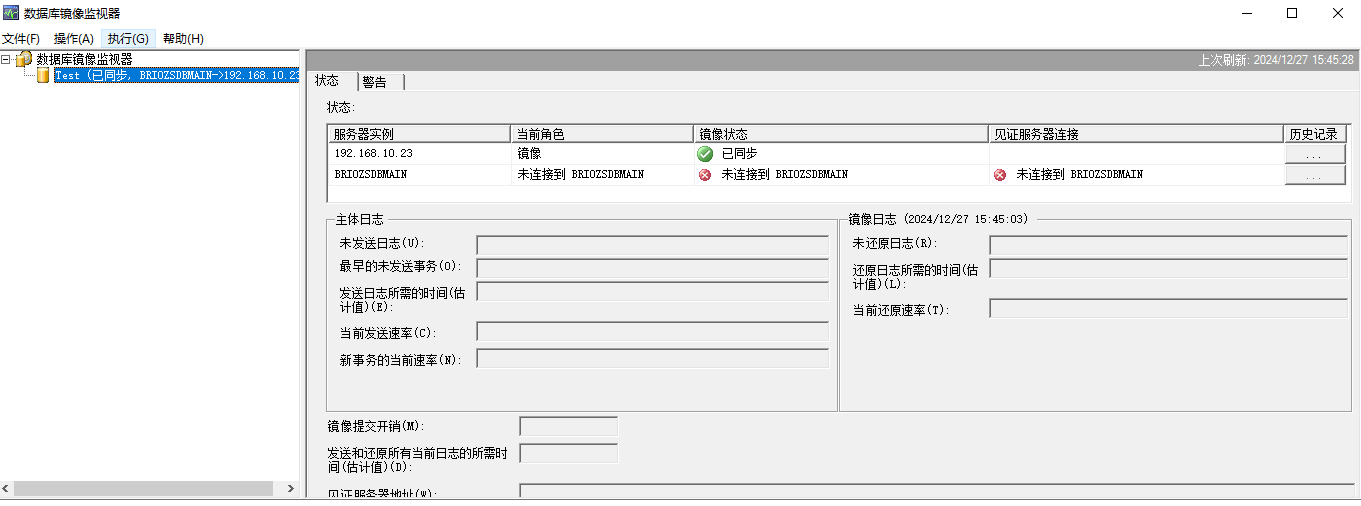
sqlserver镜像设置
本案例是双机热备,只设置主体服务器(主)和镜像服务器(从),不设置见证服务器 设置镜像前先检查是否启用了 主从服务器数据库的 TCP/IP协议 和 RemoteDAC (1)打开SQL Server配置管理器…...

Pandas04
Pandas01 Pandas02 Pandas03 文章目录 内容回顾1 数据的合并和变形1.1 df.append (了解)1.2 pd.concat1.3 merge 连接 类似于SQL的join1.4 join (了解) 2 变形2.1 转置2.2 透视表 3 MatPlotLib数据可视化3.1 MatPlotLib API 套路 &为什么要可视化3.2 单变量可视化3.3 双变量…...
)
农历节日倒计时:基于Python的公历与农历日期转换及节日查询小程序(升级版)
农历节日倒计时:基于Python的公历与农历日期转换及节日查询小程序升级版 调整的功能 上一个小程序只是能计算当年的农历节日的间隔时间,那么这次修改一下,任意年份的农历节日都可以,并且能输出农历节日对应的阳历日期࿰…...

c语言中void关键字的含义和用法
在 C 语言中,void 是一个特殊的关键字,主要有以下几个用途: 1. 表示函数没有返回值 当一个函数不需要返回任何值时,可以将其返回类型声明为 void。 #include <stdio.h>void printMessage() {printf("Hello, World!\…...

安卓音频之dumpsys audio
目录 概述 详述 dumpsys audio 1、音频服务生命周期的事件日志 2、音频焦点事件日志 3、音频流音量信息 4、音量组和设备的相关信息 5、铃声模式 6、音频路由 7、其他状态信息 8、播放活动监控信息 9、录音活动记录 10、AudioDeviceBroker 的记录 11、音效&#…...

玩客云v1.0 刷机时无法识别USB
v1.0刷机时公对公插头掉了,刷机失败,再次刷机,一直提示无法识别的USB设备,此时LED一直不亮,就像是刷成砖了一样,查了好多文章最后发现正面还有一个地方需要短接。 背面的短接点 【免费】玩客云刷机包s805-…...

影刀进阶指令 | Kimi (对标ChatGPT)
文章目录 影刀进阶指令 | Kimi (对标ChatGPT)一. 需求二. 流程三. 实现3.1 流程概览3.2 流程步骤讲解1\. 确定问题2\. 填写问题并发送3\. 检测答案是否出完 四. 运维 影刀进阶指令 | Kimi (对标ChatGPT) 简单讲讲RPA调用kimi实现…...

前端项目 node_modules依赖报错解决记录
1.首先尝试解决思路 npm报错就切换yarn , yarn报错就先切换npm删除 node_modules 跟 package-lock.json文件重新下载依 2. 报错信息: Module build failed: Error: Missing binding D:\vue-element-admin\node_modules\node-sass\vendor\win32-x64-8…...

数据科学团队管理
定位: 有核心竞争力的工业算法部门与PM、RD等深度合作 业务方向:(不同产品线) 工业预测性维护与数据挖掘视觉检测、OCR 工作内容 项目需求与交付内部框架(frameworks \packages)应用demo专利、竞赛、论文 日常管理 项目管理数据管理(原…...

一个简单的机器学习实战例程,使用Scikit-Learn库来完成一个常见的分类任务——**鸢尾花数据集(Iris Dataset)**的分类
机器学习实战通常是将理论与实践结合,通过实际的项目或案例,帮助你理解并应用各种机器学习算法。下面是一个简单的机器学习实战例程,使用Scikit-Learn库来完成一个常见的分类任务——**鸢尾花数据集(Iris Dataset)**的…...

攻防世界web第二题unseping
这是题目 <?php highlight_file(__FILE__);class ease{private $method;private $args;function __construct($method, $args) {$this->method $method;$this->args $args;}function __destruct(){if (in_array($this->method, array("ping"))) {cal…...

动手学深度学习-深度学习计算-3延后初始化
目录 实例化网络 小结 到目前为止,我们忽略了建立网络时需要做的以下这些事情: 我们定义了网络架构,但没有指定输入维度。 我们添加层时没有指定前一层的输出维度。 我们在初始化参数时,甚至没有足够的信息来确定模型应该包含…...
Linux | 零基础Ubuntu搭建JDK
目录 软件简介 在线文档 压缩包安装 下载地址 补:传输软件 传输等待 目录结构 解压安装 配置环境 更新环境 测试JDK结果 APT安装 软件简介 Java Development Kit (JDK) 是 Sun 公司(已被 Oracle 收购)针对 Java 开发员的软件开发工具包。自…...

Android `android.graphics` 包深度解析:架构与设计模式
Android android.graphics 包深度解析:架构与设计模式 目录 引言android.graphics 包概述核心类与架构 CanvasPaintBitmapColorPathShaderMatrix设计模式在 android.graphics 中的应用 工厂模式装饰者模式策略模式享元模式高级图形处理技术 硬件加速离屏渲染自定义 View 中的…...

WPF使用OpenCvSharp4
WPF使用OpenCvSharp4 创建项目安装OpenCvSharp4 创建项目 安装OpenCvSharp4 在解决方案资源管理器中,右键单击项目名称,选择“管理 NuGet 包”。搜索并安装以下包: OpenCvSharp4OpenCvSharp4.ExtensionsOpenCvSharp4.runtime.winSystem.Man…...

你不需要对其他成年人的情绪负责
在这个纷繁复杂的世界里,每个人都是独一无二的个体,背负着各自的故事、梦想与烦恼。在人际交往的广阔舞台上,我们时常会遇到这样的情境:朋友、同事、家人,甚至是陌生人,他们的情绪似乎总能不经意间影响到我…...

25秋招面试总结
秋招从八月底开始,陆陆续续面试了不少,现在也是已经尘埃落定,在这里做一些总结一些我个人的面试经历 腾讯 腾讯是我最早面试的一家,一开始捞我面试的是数字人民币,安全方向的岗位,属于腾讯金融科技这块。…...

Jupyter notebook打不开本地文件,有关目录存放问题
Jupyter notebook打不开本地文件,有关目录存放问题 基于Anaconda下载后,点击Jupyter notebook无法打开文件目录问题,或者需要更改打开的文件目录,主要解决方法:修改配置文件和路径。 第一步:修改配置文件 打…...
)
二、PXE+Kickstart 无人值守批量部署操作系统;使用物理路由器的dhcp:ProxyDHCP+TFTP+HTTP+Kickstart应答文件(VMware测试环境)
前文不使用物理设备的 DHCP ,选择自行安装 DHCP 服务进行的PXEKickstart 无人值守部署操作系统的方法难以适用于家庭或企业环境,本文尝试一种使用物理设备(家庭路由器、企业交换机)的DHCP功能批量部署物理机操作系统的方案。 建议…...

基于QGIS分区统计与栅格重分类的GlobeLand30地表覆盖面积精准测算
1. 数据准备与预处理 做地表覆盖分析的第一步就是获取高质量的数据源。GlobeLand30作为国产30米分辨率全球地表覆盖数据,在精度和易用性上都有不错的表现。我去年参与的一个省级生态评估项目就用到了这套数据,实测下来分类效果相当可靠。 下载数据时有个…...

八大网盘直链解析工具:如何绕过客户端限制实现高效文件下载
八大网盘直链解析工具:如何绕过客户端限制实现高效文件下载 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 /…...

算力基建工程:NVIDIA产业链下的求职机会——什么是CUDA编程,为什么它成为了2026年的“金饭碗”?
在2026年的北美科技求职市场中,AI 行业的红利正在经历一次极其冷酷的“底层沉淀”。当应用层的 AI 产品陷入残酷的同质化红海竞争,且大量依赖 API 调用的传统软件工程师岗位面临饱和风险时,大厂的巨额资金和核心 Headcount 正在疯狂向一个更硬…...
)
实践之漏洞挖掘(弱口令)
前言:经过我的不懈努力,也是挖到了弱口令,嘻嘻,学校的,虽然没有泄露什么隐私,但是我交了要更新就是学校的漏洞,过不过都没关系,没过我下次就找有隐私的后台再交嘻嘻正题:…...

KMS_VL_ALL_AIO企业级激活解决方案:从部署到合规的全流程指南
KMS_VL_ALL_AIO企业级激活解决方案:从部署到合规的全流程指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 一、问题诊断:企业批量激活的核心痛点 1.1 传统激活方式的…...

当stm32遇上ai:利用快马平台辅助开发嵌入式语音关键词识别原型
最近在做一个嵌入式语音识别的小项目,用STM32F4开发板实现关键词唤醒功能。作为一个嵌入式开发者,第一次尝试把AI算法部署到资源有限的MCU上,整个过程踩了不少坑,也发现了一些高效开发的技巧,特别是借助InsCode(快马)平…...

提升效率利器:用快马平台生成openclaw智能安装器,自动适配环境一键搞定
最近在折腾openclaw这个工具时,发现手动安装真是费时费力。不同操作系统、Python版本、网络环境都要适配不同的安装方案,光是查资料和试错就花了大半天。于是我用InsCode(快马)平台做了个智能安装配置器,把整个过程自动化了,效率提…...

DLT Viewer实战:破解汽车电子日志分析的3大技术挑战与解决方案
DLT Viewer实战:破解汽车电子日志分析的3大技术挑战与解决方案 【免费下载链接】dlt-viewer Diagnostic Log and Trace viewing program 项目地址: https://gitcode.com/gh_mirrors/dl/dlt-viewer 在汽车电子开发领域,面对海量ECU日志数据时&…...