B站推荐模型数据流的一致性架构
01 背景
推荐系统的模型,通过学习用户历史行为来达到个性化精准推荐的目的,因此模型训练依赖的样本数据,需要包括用户特征、服务端推荐的视频特征,以及用户在推荐视频上是否有一系列的消费行为。
推荐模型数据流,即为推荐模型提供带特征和优化目标的训练样本,包括两个模块,一是Label Join模块,负责用户行为的采集。二是feature extract模块,从原始日志中抽取特征,并基于用户行为计算模型优化的目标label。
在B站早期的推荐模型数据流架构中,如下图所示,采样两阶段特征补齐设计。Label Join模块除了完成用户行为的采集,还需要查询实时特征,补齐训练样本依赖的部分原始特征数据,一般是秒级更新的实时特征,存储在Redis中。而Feature Extract模块在计算样本之前,补齐另外一部分原始特征数据,一般是批量更新的特征数据,存储在KFC中(B站自研的KV系统)

02 问题分析
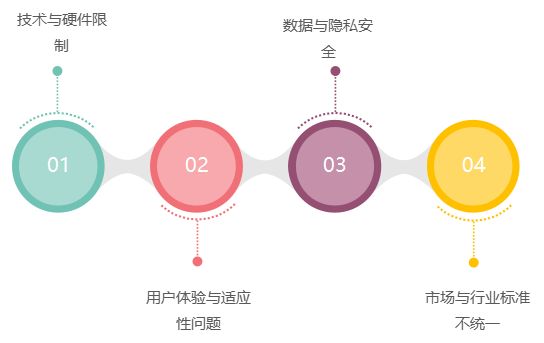
上述的推荐模型数据流架构,存在“不一致”问题,包括“数据不一致”和“计算不一致”
2.1 数据不一致
在这种自反馈系统中,推理输入的特征版本和训练输入的特征版本,如果有差异的话,会影响模型的准确性。数据不一致有3个原因:
-
访问时间差异。推理服务和Label Join/Feature Extract模块访问同一个特征的时间是不一样的。特别是秒级更新的实时特征,这种数据差异会被放的更大
-
新稿件问题。在线推理服务有稿件服务可获取新稿件的特征。而离线没有这个服务,所以离线缺少新稿件的特征,导致新稿件的推荐不准确
-
特征穿越问题。LabelJoin有N分钟的固定时间窗,所以Feature Extract在查询批量特征的时候,可能批量特征版本已经更新,查到的是最新版本特征,从而导致特征穿越。一般需要有经验的算法工程师,在离线批量特征更新上加上时间延迟,规避穿越问题。但这种规避可能会进一步加剧数据不一致
2.2 计算不一致
这里“计算”指的是从原始数据,生成特征的过程。特征可以用于在线推理和离线训练。特征计算有3个地方:
-
在线推理,一个c++的服务。特征计算使用c++实现
-
Online Feature Extract,实时的样本计算,基于FLINK,特征计算使用java实现
-
Offline Feature Extract,离线样本回溯,基于Spark,特征计算使用python实现
此外这3个地方的数据格式也是不一样的,不是简单的语言之间的转换。需要用户开发3种特征计算逻辑,并且要很小心的对齐
03. 一致性架构
为了解决上述的“数据不一致”和“计算不一致”,我们将B站推荐模型数据流升级成一致性架构:
-
数据一致性:将在线推理的原始特征现场snapshot,dump到近线。近线基于snapshot做Label Join和Feature Extract。因为在离线用的同一份数据,可保证数据完全一致
-
计算一致性:特征计算逻辑算子化,基于tenforflow实现一个c++ lib。推理服务直接调用特征抽取lib,离线Feature Extract通过java JNI调用c++ lib。特征计算都基于同一个c++ lib,用户只需要定义一次,可保证计算完全一致
3.1 整体架构
-推荐服务,将推理的原始特征现场,打包成snapshot,通过数据集成工具,从在线服务同步到近线Kafka
-在近线,基于flink latency join功能,实现Label Join,为每条请求join用户在稿件上的各种行为label,e.g. 点击、播放、后验等
-Label Join任务输出Shitu,同时写到kafka和hive
-在近线,基于flink实现实时样本计算,消费kafka Shitu,产出训练样本,写到kafka,再接入实时训练。产出模型用于线上推理
-在离线,基于flink/spark实现的批量样本计算,从hive表load Shitu,产出样本写到hive。训练任务依赖hive表作批量的模型训练

3.2 Label Join
Label Join,使用flink letency join(延时拼接)功能,完成每个请求稿件上的用户行为采集。用户行为作为训练样本的label,即模型的优化目标。
flink letency join基于时间驱动,以一个固定时间窗做数据下发。e.g.固定时间窗是N分钟,即每条请求数据到flink任务后,等待N分钟后输出数据
在最新的一致性数据流上,我们在Label Join上增加了事件驱动,增加数据下发的时效性,将数据流的时效性提升60%
-
定义下发事件:原则上按用户不会再看到视频作下发规则。对用户连续请求,按时间排序。如果最新的请求是清屏请求,那这次请求前的所有请求都可以下发。如果是普通请求,那这次请求往前第5个请求可以下发
-
采用事件驱动+时间驱动的数据下发方式,优先事件驱动下发,没有被事件触发的请求,走时间驱动,超时下发

3.3 样本计算
样本计算是基于Label Join产出的Shitu数据,计算训练样本,分两种模式:
-online extract:实时的样本计算,flink streaming计算引擎,读kafka写kafka
-offline extract:离线的批量样本计算,支持flink batch/spark batch两种计算引擎。offline extract支持两种样本计算模式:1) 无新增特征的样本计算,直接读Shitu hive table产也训练样本。2) 有新增特征的样本计算,用户挖掘的新特征,不在Shitu里。训练样本依赖Shitu和新挖掘特征
目前一致性的样本计算框架支持两种模型:
(1)直接计算:一般用于精排模型。整个样本计算过程抽象成几个算子:
-selector:数据筛选。过滤请求或者稿件
-calculate label : 通过用户行为label,计算每个视频的train label
-刷内item采样:在一刷请求内,对稿件进行采样,e.g. 按正负例
-pyfe:调用fealib,生成模型特征
每个算子,都可以支持算法同学根据业务需求自定义

(2)有外部采样的样本计算:一般在召回模型上使用
-calculate label : 通过用户行为label,计算每个视频的train label
-外接一个采样稿件候选池,根据稿件的train label,进行采样。采样逻辑按算法需求可定制
-从KFC查询采样稿件的特征,并组装一条完整的snapshot
-pyfe:调用fealib,生成模型特征

3.4 BackFill
BackFill特征回填,指的是算法同学调研新特征在模型上的收益,流程如下:
-
对于NoDelta模式,直接读Base Shitu,生成全量的训练样本
-
对HasDelta模式,用户挖掘一批新增的特征(delta snapshot)
-
基线Shitu join delta snapshot,生成一份新Shitu
-
基于新Shitu,作全量的特征计算,生成全量训练样本
-
模型训练样本并评估auc,效果不符合预期重新设计数据和特征
同时我们提供了一套python sdk,支持用户在镜像或者jupyter上自己订制特征回填特征的逻辑和流程

3.5 基于protobuf wireformat的partial decode优化
对于在线推理现场snapshot,采用了protobuf组织数据,包含了模型特征需要所有原始数据,单条数据超过250KB,有上千个字段。在样本计算阶段,对snapshot有两个处理逻辑:
调用protobuf ParseFrom接口,将snapshot bytes 反序列化成Message,平均耗时7~8ms
将snapshot所有稿件类的特征做裁剪:一刷请求n个稿件,其中m个稿件参与训练,平均耗时5~6ms
通过性能分析,样本计算中有50%的时间消耗在上述snapshot protobuf解析和处理上。但实际样本计算相关逻辑上,并不需要所有snapshot字段,所以我们使用protobuf wireformat,对snapshot做partial decode,只解析需要的field。最终将snapshot处理的性能从14ms优化到1.5ms,样本计算的cpu资源降低了30%+
04 未来工作
4.1 基于Iceberg批流一体的训练样本计算框架
如3.1章节的数据流架构中,通过FLINK实时计算产出的训练样本,会同时写到Kafka和Hive表,分别用于实时训练和批量训练。同时离线回溯也可以产出训练样本写到Hive表。这种架构存在两个问题:
(1) 需要额外的FLINK资源,把Kafka中的样本备份到Hive表中,即一个实验样本流,需要搭建两个FLINK任务
(2) 实时样本和离线样本,输入输出的介质不同,框架层面需要适配。下游训练模块也需要适配不同的样本源,无法做到批流一体
未来我们计划引入iceberg实现样本计算框架的批流一体,解决上述问题。Apache Iceberg 是一种用于大型分析表的高性能格式,旨在解决数据存储和计算引擎之间的适配问题,其核心特性之一是支持同时处理流数据和批数据,提供统一的读写接口
框架如下图所示:
-
Label Join产出数据,实时写到iceberg Shitu表
-
样本计算框架,从iceberg Shitu读数据,可以实时计算或批量计算,产出数据写到iceberg样本表
-
训练框架读iceberg样本表,可online training或者batch training

4.2 基于Iceberg MOR的增量特征回填优化
如3.4节的BackFill功能,将全量Shitu和Delta Snapshot拼接之后,再进行样本计算。这个逻辑存在2个问题,一是Shitu数据量比较多,拼接效率低。二是每次都需要全量计算所有特征,性能开销大。当然可以做增量特征计算,在和基线样本拼接。但样本数据量比较大,Hive表拼接性能较差,在某些情况下,可能比全量计算特征慢。
为此我们计划在4.1工作基础上,利用iceberg的MOR技术,优化BackFill的性能:
-
维护一份基线样本的iceberg表
-
在基线样本iceberg表新建一个branch,增加新特征列
-
基于Shitu和delta snapshot,只做增量特征计算,并将增量特征写到新特征列。这一步只计算增量特征,不需要join,可极大提升性能
-
训练模块读样本表,利用Iceberg MOR的能力,读基线特征+增量特征,再merge成完整的特征列表,完成训练
-End-
作者丨lixiaowei、正鼎
相关文章:
B站推荐模型数据流的一致性架构
01 背景 推荐系统的模型,通过学习用户历史行为来达到个性化精准推荐的目的,因此模型训练依赖的样本数据,需要包括用户特征、服务端推荐的视频特征,以及用户在推荐视频上是否有一系列的消费行为。 推荐模型数据流,即为…...

不安全物联网的轻量级加密:综述
Abstract 本文综述了针对物联网(IoT)的轻量级加密解决方案。这项综述全面覆盖了从轻量级加密方案到不同类型分组密码的比较等多个方面。同时,还对硬件与软件解决方案之间的比较进行了讨论,并分析了当前最受信赖且研究最深入的分组…...

mysql_init的概念和使用案例
mysql_init 是 MySQL C API 中的一个函数,用于初始化一个 MYSQL 结构,这个结构在后续的 MySQL 数据库操作中会被频繁使用。mysql_init 的调用是建立与 MySQL 数据库连接的第一步。 函数原型: MYSQL *mysql_init(MYSQL *mysql);参数说明&…...

3GPP R18 MT-SDT
Rel-17 指定MO-SDT允许针对UL方向的数据包进行小数据包传输。对于DL,MT-SDT(即DL触发的小数据)可带来类似的好处,即 通过不转换到 RRC_CONNECTED来减少信令开销和UE功耗,并通过允许快速传输(小而少见的)数据包(例如用于定位)来减少延迟。 在R17中,NR_SmallData_INACTIVE的工…...

时频转换 | Matlab暂态提取变换transient-extracting transform一维数据转二维图像方法
目录 基本介绍程序设计参考资料获取方式 基本介绍 时频转换 | Matlab暂态提取变换transient-extracting transform一维数据转二维图像方法 程序设计 clear clc % close all load x.mat % 导入数据 x x(1:5120); % 本数据只选择5120个点进行分析 fs 6400 ; % 数据采样频…...

.NET Framework 逐渐过时,.NET 8和 .NET 9引领未来
随着科技的不断进步,软件开发的工具和技术也在不断更新换代。.NET Framework,曾是微软的旗舰开发平台,曾经在软件开发领域占据了主导地位。然而,随着技术的演变和开发需求的变化,.NET Framework逐渐显得力不从心&#…...
从虚拟到现实:AI与AR/VR技术如何改变体验经济?
引言:体验经济的崛起 在当今消费环境中,产品与服务早已不再是市场竞争的唯一焦点,能够提供深刻感知和独特体验的品牌,往往更能赢得消费者的青睐。这种转变标志着体验经济的崛起。体验经济不仅仅是简单的买卖行为,而是通…...

在K8S中,Ingress该如何使用?
在Kubernetes中,Ingress是一种API对象,它提供了对外部请求进入集群内部服务的一种统一入口和路由机制。Ingress控制器是一个运行在集群中的守护进程,它监听Ingress对象的变化并配置相应的负载均衡器或代理服务,以便根据定义的规则…...

Ubuntu24.04安装NVIDIA驱动及工具包
Ubuntu24.04安装NVIDIA驱动及工具包 安装nvidia显卡驱动安装cuda驱动安装cuDNN安装Anaconda 安装nvidia显卡驱动 NVIDIA 驱动程序(NVIDIA Driver)是专为 NVIDIA 图形处理单元(GPU)设计的软件,它充当操作系统与硬件之间…...

【每日学点鸿蒙知识】组件封装通用方法、callback和await性能对比、Web组件下拉刷新、hsp包报错、WebView圆角
1、HarmonyOS 自定义的组件如何封装一些通用的属性和方法,例如 Java 中的继承? export class Animal{name:stringage:stringconstructor(name:string,age:string) {this.name namethis.age age} }export class Person extends Animal{reading:stri…...

Excel批量设置行高,Excel表格设置自动换行后打印显示不全,Excel表格设置最合适的行高后打印显示不全,完美解决方案!!!
文章目录 说个问题(很严重!!!)写个方案会Python看这里Python环境搭建不存在多行合并存在多行合并 不会Python看这里 说个问题(很严重!!!) 平时处理Excel表格…...

Web Bluetooth API 开发记录
搞了一天的蓝牙串口协议被几个软件和AI带沟里面去了。 1.00001101-0000-1000-8000-00805f9b34fb 是spp协议。但是我用的称是使用的49535343-fe7d-4ae5-8fa9-9fafd205e455蓝牙低功耗spp协议 2.推荐一款软件Android-nRF-Connect github地址:https://github.com/Nor…...

python基础知识(二)
元组 元组与列表类似,不同之处在于,元组的元素不能修改,元组使用()。 集合 集合是一个无序且不重复的元素列表。 基本功能是 进行成员关系测试和删除重复元素。 创建集合使用大括号或者set()函数。 例子: 注意:创建一…...

【每日学点鸿蒙知识】初始化BigInt、包体积瘦身、Tabs嵌套Grid、老年化适配、Release打包失败
1、HarmonyOS 在一个类中,怎么初始化一个BigInt类型的属性? 可以通过BigInt关键字来初始化,如: let a BigInt(1); let b BigInt("2"); 关于Uint8Array与string互转,示例: // string 转Uint8…...

Android service framework笔记
1. 网络摘录如何添加一个Application Framework Service(一)(without native code) 如何添加一个Application Framework Service(二)(with native code) 2.书籍摘录...

安全攻防:中间人攻击
1. 中间人攻击定义 中间人攻击(简称MITM)是攻击者在进行网络通信的双方中间,分别与两端建立独立的联系,并进行数据嗅探甚至篡改,而通信的双方却对中间人毫不知情,认为自己是直接在与对端通信。2. 常见中间人…...

【Rust自学】7.3. use关键字 Pt.1:use的使用与as关键字
喜欢的话别忘了点赞、收藏加关注哦,对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 7.3.1. use的作用 use的作用是将路径导入到当前作用域内。而引入的内容仍然是遵守私有性原则,也就是只有公共的部分引入进来才…...
)
变长的时间戳(第4版)
以32位为单位,一个时间戳可以是32位、64位、96位。 122932 113032 A类:(40036597)1000146097000≤229 B类:246060100086400000≤229 C类:1000100010001000000000≤230 每400年有40036597146097天,A类时间戳能表达1000…...

Intent--组件通信
组件通信1 获取子活动的返回值 创建Activity时实现自动注册!【Activity必须要注册才能使用】 默认 LinearLayout 布局,注意 xml 中约束布局的使用; 若需要更改 线性布局 只需要将标签更改为 LinearLayout 即可,记得 设置线性布局…...

Android14 OTA升级速度过慢问题解决方案
软件版本:Android14 硬件平台:QCS6115 问题:OTA整包升级接近20min,太长无法忍受。 该问题为Android高版本的虚拟AB分区压缩技术所致,其实就是时间换空间,个人推测AB分区压缩会节约硬件存储空间࿰…...

不止于教程:用QGIS 3.30 + PyQt5从零打造一个极简版GIS桌面应用
从零构建GIS桌面应用:QGIS 3.30与PyQt5深度整合实战 当我们需要开发一个轻量级地理信息系统时,QGIS的Python API提供了强大而灵活的选择。不同于简单的脚本编写,将QGIS作为引擎嵌入到自定义PyQt5应用中,能够实现高度定制化的GIS解…...

自动缝纫机SolidWorks
在自动缝纫机的设计过程中,往往需要处理大量精密零件的协同工作,从送布机构、针杆组件到旋梭系统,每个部件的尺寸精度和装配关系都直接影响设备的运行稳定性和缝纫效果。而SolidWorks作为三维设计工具,在这一过程中扮演着关键角色…...

能源企业必看:人力资源系统选用友、北森,还是红海云?
能源企业的人力资源系统选型,往往不是比功能多不多,而是看能否扛住集团级组织复杂度、倒班工时与薪酬联动、强合规审计,以及对私有化与信创的要求。用友、北森、红海云是常被放在同一张桌面上对比的选择,但适配路径并不相同。下面…...

影刀RPA与Python变量管理:全局与局部变量的实战应用
1. 全局变量与局部变量的核心区别 在影刀RPA中编写Python脚本时,变量管理是影响代码质量的关键因素。全局变量就像办公室的公告板,所有部门(函数)都能看到并修改;而局部变量则是员工个人笔记本上的临时记录,…...

告别复杂状态机:用C语言结构体数组为STM32设计可维护的多级菜单
用结构体数组重构STM32菜单系统:从状态机到模块化设计的进阶之路 在嵌入式开发中,菜单系统是许多产品不可或缺的交互界面。传统的状态机或switch-case实现方式虽然直接,但随着功能迭代,代码往往会变得臃肿难维护。我曾接手过一个使…...

自动驾驶模拟平台模型配置全指南:从技术选型到场景验证
自动驾驶模拟平台模型配置全指南:从技术选型到场景验证 【免费下载链接】alpasim 项目地址: https://gitcode.com/GitHub_Trending/al/alpasim 一、AlpaSim核心价值:构建自动驾驶研发闭环 AlpaSim作为开源自动驾驶模拟平台,通过模块…...

8.3ES-OAS-ERP-电子政务-企业信息化
一、专家系统 00:00 定义:基于知识的专家系统是人工智能的重要分支,其能力来源于专家知识,通过知识表示和推理方法实现应用。与传统程序区别: 属于AI范畴,解决半结构化/非结构化问题模拟专家推理而非问题本…...

DoubletFinder实战指南:精准识别单细胞测序中的双细胞干扰
1. 双细胞干扰:单细胞测序中的"隐形杀手" 做单细胞测序分析的朋友们应该都遇到过这种情况:明明细胞分群很清晰,但总有几个"奇怪"的cluster既表达A细胞标志物又表达B细胞特征。这种情况很可能就是遇到了双细胞干扰——两个…...

HARMONYOS应用实例247:七巧板拼图
14.七巧板拼图 功能:拖拽旋转七巧板组件拼成指定图形,训练几何直觉和面积守恒观念。 核心功能 七巧板组件:包含2个大三角形、1个中三角形、2个小三角形、1个正方形、1个平行四边形 拖拽操作:支持拖拽七巧板组件到目标位置 旋转功能:支持旋转七巧板组件(每次旋转45度) 目…...

终极指南:3分钟掌握原神圣遗物扫描工具Amenoma的完整使用技巧 [特殊字符]
终极指南:3分钟掌握原神圣遗物扫描工具Amenoma的完整使用技巧 🎯 【免费下载链接】Amenoma A simple desktop application to scan and export Genshin Impact Artifacts and Materials. 项目地址: https://gitcode.com/gh_mirrors/am/Amenoma 还…...