【机器学习】SVM支持向量机(一)
介绍
支持向量机(Support Vector Machine, SVM)是一种监督学习模型,广泛应用于分类和回归分析。SVM 的核心思想是通过找到一个最优的超平面来划分不同类别的数据点,并且尽可能地最大化离该超平面最近的数据点(支持向量)之间的间隔。这使得 SVM 具有良好的泛化能力,即能够很好地处理未见过的数据。
SVM 的工作原理
- 线性可分情况:
- 在最简单的情况下,如果数据集是线性可分的,SVM 试图找到一个最佳的直线(在二维空间中)或超平面(在多维空间中),它能将两个类别完全分开。
- 这个超平面的选择不仅取决于它可以正确分类训练数据,还在于它能够使两类样本到超平面的距离最大。这样的决策边界被称为最大间隔超平面。
- 非线性可分情况:
- 当数据不是线性可分时,可以通过核函数(Kernel Function)将原始特征映射到更高维度的空间,在这个新的空间中寻找线性分离的可能性。
- 常见的核函数包括多项式核、径向基函数(RBF Kernel)、Sigmoid 核等。选择合适的核函数对于提高 SVM 的性能至关重要。
- 软间隔与正则化:
- 现实世界的数据往往存在噪声或者异常值,严格的线性分割可能会导致过拟合问题。因此,引入了软间隔的概念,允许一些数据点位于错误的一侧。
- 正则化参数 C 控制着对误分类的惩罚程度;较小的 C 值意味着更宽的间隔但可能更多的容许误差,而较大的 C 则追求更高的准确率但可能导致过拟合。
- 支持向量:
- 决定最终超平面位置的关键数据点称为支持向量。这些点位于间隔边界上,或者是在软间隔设定下违反边界的点。
- 只有支持向量影响了模型的学习过程,其他不在间隔内的点对构建超平面没有贡献。
- 多分类问题:
- 对于多于两个类别的分类任务,可以采用一对多(One-vs-Rest, OvR)或一对一(One-vs-One, OvO)的方法构建多个二分类器,然后根据投票或其他策略确定最终类别标签。
SVM 的优点
- 高效率:在高维空间表现良好,即使当特征数量超过样本数量时也能有效工作。
- 强大的数学基础:基于凸优化理论,保证了全局最优解的存在性和唯一性。
- 适用于小规模数据集:不需要大量的训练数据即可获得较好的效果。
- 灵活性:通过不同的核函数可以适应各种类型的数据分布。
SVM 的局限性
- 计算复杂度:随着训练样本数目的增加,训练时间和内存消耗也会显著增长。
- 对参数敏感:如核函数的选择、正则化参数 C 和核参数(例如 RBF 的 gamma 参数),需要仔细调整以达到最佳性能。
- 解释性差:相比于决策树之类的算法,SVM 提供的模型通常难以直观理解。
1、支持向量机SVM
对两类样本点进行分类,如下图,有a线、b线、c线三条线都可以将两类样本点很好的分开类,我们可以观察到b线将两类样本点分类最好,原因是我们训练出来的分类模型主要应用到未知样本中,虽然a、b、c三条线将训练集都很好的分开类,但是当三个模型应用到新样本中时,b线抗干扰能力最强,也就是泛化能力最好,样本变化一些关系不大,一样能被正确的分类。那么如何确定b线的位置呢?我们可以使用支持向量机SVM来确定b线的位置。
支持向量机(support vector machines,SVM)是一种二分类算法,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,如果对应的样本特征少,一个普通的SVM就是一条线将样本分隔开,但是要求线到两个类别最近样本点的距离要最大。
b线就是我们根据支持向量机要找到的分割线,这条线需要到两个类别最近的样本点最远,图上的距离就是d,由于这条线处于两个类别的中间,所以到两个类别的距离都是d。
支持向量机SVM算法就是在寻找一个最优的决策边界(上图中的两条虚线)来确定分类线b,所说的支持向量(support vector)就是距离决策边界最近的点(上图中p1、p2、p3点,只不过边界穿过了这些点)。如果没有这些支持向量点,b线的位置就要改变,所以 SVM就是根据这些支持向量点来最大化margin,来找到了最优的分类线(machine,分类器) ,这也是SVM分类算法名称的由来。
2、构建SVM目标函数
接着上面的分类问题来分析,假设支持向量机最终要找的线是 l 2 l_2 l2,决策边界两条线是 l 1 l_1 l1和 l 3 l_3 l3,那么假设 l 2 l_2 l2的方程为 w T ⋅ x + b = 0 w^T \cdot x + b =0 wT⋅x+b=0,这里 w w w表示 ( w 1 , w 2 ) T (w_1,w_2)^T (w1,w2)T, x x x表示 ( x 1 , x 2 ) T (x_1,x_2)^T (x1,x2)T,我们想要确定 l 2 l_2 l2直线,只需要确定w和b即可,此外,由于 l 1 l_1 l1和 l 3 l_3 l3线是 l 2 l_2 l2的决策分类边界线,一定与 l 2 l_2 l2是平行的,平行就意味着斜率不变,b变化即可,所以我们可以假设 l 1 l_1 l1线的方程为 w T ⋅ x + b = c w^T \cdot x +b = c wT⋅x+b=c, l 3 l_3 l3线的方位为 w T ⋅ x + b = − c w^T\cdot x + b = -c wT⋅x+b=−c。
【知识补充】:
- 二维空间点 ( x 1 , y 1 ) (x_1,y_1) (x1,y1)到直线 A x + B y + C = 0 Ax + By + C = 0 Ax+By+C=0的距离公式是:
d = ∣ A x 1 + B y 1 + C ∣ A 2 + B 2 d = \frac{|Ax_1 + By_1 + C|}{\sqrt{A^2 + B^2}} d=A2+B2∣Ax1+By1+C∣
- 两条平行线 A x + B y + C 1 = 0 Ax + By + C_1 = 0 Ax+By+C1=0与 A x + B y + C 2 = 0 Ax + By + C_2= 0 Ax+By+C2=0之间的距离公式为:
d = ∣ C 1 − C 2 ∣ A 2 + B 2 d = \frac{|C_1 - C_2|}{\sqrt{A^2 + B^2}} d=A2+B2∣C1−C2∣
我们希望的是决策边界上的样本点到 l 2 l_2 l2直线的距离d越大越好。我们可以直接计算 l 1 l_1 l1或 l 3 l_3 l3上的点到直线 l 2 l_2 l2的距离,假设将空间点扩展到n维空间后,点 x i = ( x 1 , x 2 , ⋯ , x n ) x_i = (x_1,x_2,\cdots,x_n) xi=(x1,x2,⋯,xn)到直线 w T ⋅ x + b = 0 w^T \cdot x +b = 0 wT⋅x+b=0(严格意义上来说直线变成了超平面)的距离为:
d = ∣ w T ⋅ x i + b ∣ ∣ ∣ w ∣ ∣ d = \frac{|w^T\cdot x_i +b|}{||w||} d=∣∣w∣∣∣wT⋅xi+b∣
以上 ∣ ∣ w ∣ ∣ = w 1 2 + w 2 2 + ⋯ + w n 2 ||w|| = \sqrt{w_1^2 + w_2^2 + \cdots + w_n^2} ∣∣w∣∣=w12+w22+⋯+wn2,读作“w的模”。
由于 l 1 l_1 l1、 l 2 l_2 l2和 l 3 l_3 l3三条直线平行,d也是两条平行线之间的距离,我们可以根据两条平行线之间的距离公式得到d值如下:
d = ∣ C − 0 ∣ ∣ ∣ w ∣ ∣ = ∣ − C − 0 ∣ ∣ ∣ w ∣ ∣ = ∣ C ∣ ∣ ∣ w ∣ ∣ = ∣ w T ⋅ x i + b ∣ ∣ ∣ w ∣ ∣ d = \frac{|C - 0|}{||w||} = \frac{|-C - 0|}{||w||} = \frac{|C|}{||w||} = \frac{|w^T\cdot x_i +b|}{||w||} d=∣∣w∣∣∣C−0∣=∣∣w∣∣∣−C−0∣=∣∣w∣∣∣C∣=∣∣w∣∣∣wT⋅xi+b∣
我们可以看到无论计算点到直线的距离还是两个平行线之间的距离,最终结果是一致的。对于 l 1 l_1 l1直线 w T ⋅ x + b = c w^T\cdot x +b = c wT⋅x+b=c,我们可以相对应成比例的缩小各项的系数,例如变成 w T 2 ⋅ x + b 2 = c 2 \frac{w^T}{2}\cdot x + \frac{b}{2}=\frac{c}{2} 2wT⋅x+2b=2c,这条直线还是原来本身的直线,现在我们可以把它变成 w T c ⋅ x + b c = c c = 1 \frac{w^T}{c}\cdot x + \frac{b}{c}=\frac{c}{c}=1 cwT⋅x+cb=cc=1,即改写后的 l 1 l_1 l1直线 w T ⋅ x + b = 1 w^T\cdot x +b = 1 wT⋅x+b=1还是原来的直线,同理,对于 l 3 l_3 l3直线我们也可以变换成 w T ⋅ x + b = − 1 w^T\cdot x +b = -1 wT⋅x+b=−1,所以上图可以改变成如下:
那么变换之后的d可以根据两条平行线之间的距离得到:
d = 1 ∣ ∣ w ∣ ∣ = 1 ∣ ∣ w ∣ ∣ d = \frac{1}{||w||} = \frac{1}{||w||} d=∣∣w∣∣1=∣∣w∣∣1
我们希望决策边界上的点到超平面 l 2 l_2 l2距离d越大越好。我们将 l 3 l_3 l3上方的点分类标记为“1”类别,将 l 1 l_1 l1下方的点分类标记为“-1”类别,那么我们可以得到如下公式:
{ w T ⋅ x i + b ≥ 1 y = 1 ( 1 ) 式 w T ⋅ x i + b ≤ 1 y = − 1 ( 2 ) 式 \left \{\begin{aligned}&w^T\cdot x_i +b \ge 1 \quad y = 1 \quad (1)式\\\\&w^T\cdot x_i +b \le 1\quad y = -1\quad (2)式 \end{aligned}\right. ⎩ ⎨ ⎧wT⋅xi+b≥1y=1(1)式wT⋅xi+b≤1y=−1(2)式
两式两侧分别乘以对应的类别可以合并为一个式子:
y ⋅ ( w T ⋅ x i + b ) ≥ 1 ( 3 ) 式 y\cdot (w^T\cdot x_i +b) \ge 1 \quad (3)式 y⋅(wT⋅xi+b)≥1(3)式
所以在计算d的最大值时,是有限制条件的,这个限制条件就是(3)式。
所以对于所有样本点我们需要在满足 y ⋅ ( w T ⋅ x i + b ) ≥ 1 y\cdot (w^T\cdot x_i +b) \ge 1 y⋅(wT⋅xi+b)≥1条件下,最大化 d = 1 ∣ ∣ w ∣ ∣ d = \frac{1}{||w||} d=∣∣w∣∣1,就是最小化 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣,等效于最小化 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2,这样转换的目的就是为了后期优化过程中求导时方便操作,不会影响最终的结果,所以在支持向量机SVM中要确定一个分类线,我们要做的就是在 y ⋅ ( w T ⋅ x i + b ) ≥ 1 y\cdot (w^T\cdot x_i +b) \ge 1 y⋅(wT⋅xi+b)≥1条件下最小化 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2,记为:
m i n 1 2 ∣ ∣ w ∣ ∣ s . t y ⋅ ( w T ⋅ x i + b ) ≥ 1 , i = 1 , 2 , ⋯ , n min\frac{1}{2}||w||\quad s.t\quad y\cdot (w^T\cdot x_i +b) \ge 1,\quad i = 1,2,\cdots,n min21∣∣w∣∣s.ty⋅(wT⋅xi+b)≥1,i=1,2,⋯,n
以上n代表样本总数,缩写 s . t s.t s.t表示“Subject to”是“服从某某条件”的意思,上述公式描述的是一个典型的不等式约束条件下的二次型函数优化问题,同时也是支持向量机的基本数学模型,这里我们称支持向量机的目标函数。
3、拉格朗日乘数法、KKT条件、对偶
3.1、拉格朗日乘数法
拉格朗日乘数法主要是将有等式约束条件优化问题转换为无约束优化问题 ,拉格朗日乘数法如下:
假设 x = [ x 1 , x 2 , ⋯ , x n ] x = [x_1,x_2,\cdots,x_n] x=[x1,x2,⋯,xn]是一个n维向量, f ( x ) f(x) f(x)和 h ( x ) h(x) h(x)含有x的函数,我们需要找到满足 h ( x ) = 0 h(x)=0 h(x)=0条件下 f ( x ) f(x) f(x)最小值,如下:
m i n f ( x ) s . t h ( x ) = 0 minf(x)\quad s.t \quad h(x) = 0 minf(x)s.th(x)=0
可以引入一个自变量 λ \lambda λ,其可以取任意值,则上式严格等价于下式:
L ( x , λ ) = f ( x ) + λ h ( x ) L(x,\lambda) = f(x) + \lambda h(x) L(x,λ)=f(x)+λh(x)
L ( x , λ ) L(x,\lambda) L(x,λ)叫做Lagrange函数(拉格朗日函数), λ \lambda λ叫做拉格朗日乘子(其实就是系数)。令 L ( x , λ ) L(x,\lambda) L(x,λ)对x的导数为0,对 λ \lambda λ的导数为0,求解出 x , λ x,\lambda x,λ 的值,那么x就是函数 f ( x ) f(x) f(x)在附加条件 h ( x ) h(x) h(x)下极值点。
以上就是拉格朗日乘数法,通俗理解拉格朗日乘数法就是将含有等式条件约束优化问题转换成了无约束优化问题构造出拉格朗日函数 L ( x , λ ) L(x,\lambda) L(x,λ),让 L ( x , λ ) L(x,\lambda) L(x,λ)对未知数x和 λ \lambda λ进行求导,得到一组方程式,可以计算出对应的x和 λ \lambda λ结果,这个x对应的 f ( x ) f(x) f(x)函数值就是在条件 h ( x ) = 0 h(x) = 0 h(x)=0下的最小值点。
拉格朗日函数转换成等式过程的证明涉及到导数积分等数学知识,这里不再证明。
3.2、KKT条件
假设我们面对的是不等式条件约束优化问题,如下:
假设 x = [ x 1 , x 2 , ⋯ , x n ] x = [x_1,x_2,\cdots,x_n] x=[x1,x2,⋯,xn]是一个n维向量, f ( x ) f(x) f(x)和 h ( x ) h(x) h(x)是含有x的函数,我们需要找到满足 h ( x ) ≤ 0 h(x) \le 0 h(x)≤0条件下 f ( x ) f(x) f(x)最小值,如下:
m i n f ( x ) s . t h ( x ) ≤ 0 − − − 式① minf(x)\quad s.t \quad h(x) \le 0\quad ---式① minf(x)s.th(x)≤0−−−式①
针对上式,显然是一个不等式约束最优化问题,不能再使用拉格朗日乘数法,因为拉格朗日乘数法是针对等式约束最优化问题。
那我们可以考虑加入一个“松弛变量” α 2 \alpha^2 α2让条件 h ( x ) ≤ 0 h(x) \le0 h(x)≤0来达到等式的效果,即使条件变成 h ( x ) + α 2 = 0 h(x) + \alpha^2 =0 h(x)+α2=0,这里加上 α 2 \alpha^2 α2的原因是保证加的一定是非负数,即: α 2 ≥ 0 \alpha^2 \ge 0 α2≥0,但是目前不知道这个 α 2 \alpha^2 α2值是多少,一定会找到一个合适的 α 2 \alpha^2 α2值使 h ( x ) + α 2 = 0 h(x) +\alpha^2 = 0 h(x)+α2=0成立,所以将①式改写成如下:
m i n f ( x ) s . t h ( x ) + α 2 = 0 − − − 式② minf(x)\quad s.t\quad h(x) + \alpha^2 =0 \quad ---式② minf(x)s.th(x)+α2=0−−−式②
以上②式变成了等式条件约束优化问题,我们就可以使用拉格朗日乘数法来求解满足等式条件下 f ( x ) f(x) f(x)最小值对应的x值。
通过拉格朗日乘数法,将②式转换为如下:
L ( x , λ , α ) = f ( x ) + λ ( h ( x ) + α 2 ) L(x,\lambda,\alpha) = f(x) + \lambda(h(x) + \alpha^2) L(x,λ,α)=f(x)+λ(h(x)+α2)
但是上式中 λ \lambda λ值必须满足 λ ≥ 0 \lambda \ge 0 λ≥0,由于 L ( x , λ , α ) L(x,\lambda,\alpha) L(x,λ,α)变成了有条件的拉格朗日函数,这里需要求 m i n L ( x , λ , α ) minL(x,\lambda,\alpha) minL(x,λ,α) 对应下的x值 。至于为什么 λ ≥ 0 \lambda \ge 0 λ≥0及为什么计算的是 m i n L ( x , λ , α ) minL(x,\lambda,\alpha) minL(x,λ,α)下对应的x值,这里证明涉及到很多几何性质,这里也不再证明。
所以将上式转换成如下拉格朗日函数:
m i n L ( x , λ , α ) = f ( x ) + λ ( h ( x ) + α 2 ) λ ≥ 0 − − − 式③ minL(x,\lambda,\alpha) = f(x) + \lambda(h(x) + \alpha^2) \quad \lambda \ge 0\quad---式③ minL(x,λ,α)=f(x)+λ(h(x)+α2)λ≥0−−−式③
以上我们可以看到将不等式条件约束优化问题加入“松弛变量”转换成等式条件约束优化问题,使用拉格朗日乘数法进行转换得到 L ( x , λ , α ) L(x,\lambda,\alpha) L(x,λ,α),我们先抛开min,下面我们可以对拉格朗日函数 L ( x , λ , α ) L(x,\lambda,\alpha) L(x,λ,α)对各个未知数 x , λ , α x,\lambda,\alpha x,λ,α进行求导,让对应的导数为零,得到以下联立方程:
{ ∂ L ∂ x = ∂ f ( x ) ∂ x + λ ∂ h ( x ) ∂ x = 0 − − − 式④ ∂ L ∂ λ = h ( x ) + α 2 = 0 − − − 式⑤ ∂ L ∂ α = 2 λ α = 0 − − − 式⑥ λ ≥ 0 − − − 式⑦ \left \{\begin{aligned}&\frac{\partial L}{\partial x} = \frac{\partial f(x)}{\partial x} + \lambda \frac{\partial h(x)}{\partial x} = 0\quad ---式④\\\\&\frac{\partial L}{\partial \lambda} = h(x) + \alpha^2 = 0\quad ---式⑤\\\\&\frac{\partial L}{\partial \alpha} = 2\lambda\alpha = 0\quad---式⑥\\\\&\lambda \ge 0\quad ---式⑦ \end{aligned}\right. ⎩ ⎨ ⎧∂x∂L=∂x∂f(x)+λ∂x∂h(x)=0−−−式④∂λ∂L=h(x)+α2=0−−−式⑤∂α∂L=2λα=0−−−式⑥λ≥0−−−式⑦
从上式⑥式可知 λ α = 0 \lambda\alpha=0 λα=0,我们分两种情况讨论:
- λ = 0 , α ≠ 0 \lambda =0,\alpha \neq 0 λ=0,α=0
由于 λ = 0 \lambda = 0 λ=0,根据③式可知,约束不起作用,根据①式可知 h ( x ) ≤ 0 h(x) \le 0 h(x)≤0。
- λ ≠ 0 , α = 0 \lambda \neq 0,\alpha =0 λ=0,α=0
由于 λ ≠ 0 \lambda \neq 0 λ=0,根据③式可知 λ > 0 \lambda > 0 λ>0。由于 α = 0 \alpha =0 α=0,约束条件起作用,根据⑤式可知, h ( x ) = 0 h(x) = 0 h(x)=0。
综上两个步骤我们可以得到 λ ⋅ h ( x ) = 0 \lambda \cdot h(x) = 0 λ⋅h(x)=0,且在约束条件起作用时, λ > 0 , h ( x ) = 0 \lambda >0,h(x) = 0 λ>0,h(x)=0;约束条件不起作用时, λ = 0 , h ( x ) ≤ 0 \lambda =0,h(x) \le 0 λ=0,h(x)≤0。
上面方程组中的⑥式可以改写成 λ ⋅ h ( x ) = 0 \lambda\cdot h(x) = 0 λ⋅h(x)=0。由于 α 2 ≥ 0 \alpha^2 \ge 0 α2≥0,所以将⑤式也可以改写成 h ( x ) ≤ 0 h(x) \le 0 h(x)≤0,所以上面方程组也可以转换成如下:
{ ∂ L ∂ x = ∂ f ( x ) ∂ x + λ ∂ h ( x ) ∂ x = 0 h ( x ) ≤ 0 λ ⋅ h ( x ) = 0 λ ≥ 0 \left \{\begin{aligned}&\frac{\partial L}{\partial x} = \frac{\partial f(x)}{\partial x} + \lambda \frac{\partial h(x)}{\partial x} = 0\\\\&h(x) \le 0\\\\&\lambda \cdot h(x) =0\\\\&\lambda \ge 0 \end{aligned}\right. ⎩ ⎨ ⎧∂x∂L=∂x∂f(x)+λ∂x∂h(x)=0h(x)≤0λ⋅h(x)=0λ≥0
以上便是不等式约束优化问题的KKT(Karush-Kuhn-Tucker)条件 ,我们回到最开始要处理的问题上,根据③式可知,我们需要找到合适的 x , λ , α x,\lambda,\alpha x,λ,α值使 L ( x , λ , α ) L(x,\lambda,\alpha) L(x,λ,α)最小,但是合适的 x , λ , α x,\lambda,\alpha x,λ,α必须满足KKT条件。
我们对③式的优化问题可以进行优化如下:
m i n L ( x , λ , α ) = f ( x ) + λ ( h ( x ) + α 2 ) λ ≥ 0 − − − 式③ minL(x,\lambda,\alpha) = f(x) + \lambda(h(x) + \alpha^2) \quad \lambda \ge 0\quad---式③ minL(x,λ,α)=f(x)+λ(h(x)+α2)λ≥0−−−式③
m i n L ( x , λ , α ) = f ( x ) + λ ⋅ h ( x ) + λ α 2 minL(x,\lambda,\alpha) = f(x) +\lambda \cdot h(x) +\lambda \alpha^2 minL(x,λ,α)=f(x)+λ⋅h(x)+λα2
由于 α 2 ≥ 0 \alpha^2 \ge 0 α2≥0且 λ ≥ 0 \lambda \ge 0 λ≥0, λ α 2 \lambda \alpha^2 λα2一定大于零,所以进一步可以简化为如下:
m i n L ( x , λ ) = f ( x ) + λ h ( x ) − − − 式⑧ minL(x,\lambda) = f(x) + \lambda h(x) \quad \quad---式⑧ minL(x,λ)=f(x)+λh(x)−−−式⑧
满足最小化⑧式对应的 x , λ x,\lambda x,λ值一定也要满足KKT条件,假设现在我们找到了合适的参数 x x x值使 f ( x ) f(x) f(x)取得最小值P【注意:这里根据①式来说,计算 f ( x ) f(x) f(x)的最小值,这里假设合适参数 x x x值对应的 f ( x ) f(x) f(x) 的值P就是最小值,不存在比这更小的值。 】 ,由于⑧式中 λ h ( x ) \lambda h(x) λh(x)一定小于等于零,所以一定有:
L ( x , λ ) = f ( x ) + λ h ( x ) ≤ P L(x,\lambda) = f(x) + \lambda h(x)\le P L(x,λ)=f(x)+λh(x)≤P
也就是说一定有:
L ( x , λ ) ≤ P L(x,\lambda) \le P L(x,λ)≤P
为了找到最优的 λ \lambda λ值,我们一定想要 L ( x , λ ) L(x,\lambda) L(x,λ)接近P,即找到合适的 λ \lambda λ最大化 L ( x , λ ) L(x,\lambda) L(x,λ),可以写成 max λ L ( x , λ ) \max\limits_{\lambda} L(x,\lambda) λmaxL(x,λ),所以⑧式求解合适的 x , λ x,\lambda x,λ值最终可以转换成如下:
min x max λ L ( x , λ ) s . t λ ≥ 0 − − − 式⑨ \min\limits_{x}\max\limits_{\lambda} L(x,\lambda)\quad s.t\quad \lambda \ge 0\quad ---式⑨ xminλmaxL(x,λ)s.tλ≥0−−−式⑨
3.3、对偶问题
对偶问题是我们定义的一种问题,对于一个不等式约束的原问题:
min x max λ L ( x , λ ) s . t λ ≥ 0 \min\limits_x\max\limits_{\lambda}L(x,\lambda)\quad s.t\quad\lambda \ge 0 xminλmaxL(x,λ)s.tλ≥0
我们定义对偶问题为(对上面方程的求解等效求解下面方程):
max λ min x L ( x , λ ) s . t λ ≥ 0 \max\limits_{\lambda}\min\limits_{x}L(x,\lambda)\quad s.t\quad\lambda \ge 0 λmaxxminL(x,λ)s.tλ≥0
其实就是把min和max对调了一下,当然对应的变量也要变换。
对偶问题有什么好处呢?对于原问题,我们要先求里面的max,再求外面的min。而对于对偶问题,我们可以先求里面的min。有时候,先确定里面关于x的函数最小值,比原问题先求解关于 λ \lambda λ的最大值,要更加容易解。
但是原问题跟对偶问题并不是等价的,这里有一个强对偶性、弱对偶性的概念,弱对偶性是对于所有的对偶问题都有的一个性质。
这里给出一个弱对偶性的推导过程:
max λ min x L ( x , λ ) = min x L ( x , λ ∗ ) ≤ L ( x ∗ , λ ∗ ) ≤ max λ L ( x ∗ , λ ) = min x max λ L ( x , λ ) \max\limits_{\lambda}\min\limits_{x}L(x,\lambda) = \min\limits_xL(x,\lambda^*) \le L(x^*,\lambda^*) \le \max\limits_{\lambda}L(x^*,\lambda)=\min\limits_x\max\limits_{\lambda}L(x,\lambda) λmaxxminL(x,λ)=xminL(x,λ∗)≤L(x∗,λ∗)≤λmaxL(x∗,λ)=xminλmaxL(x,λ)
其中 x ∗ , λ ∗ x^*,\lambda^* x∗,λ∗是函数取最大值最小值的时候对应的最优解,也就是说,原问题始终大于等于对偶问题:
max λ min x L ( x , λ ) ≤ min x max λ L ( x , λ ) \max\limits_{\lambda}\min\limits_{x}L(x,\lambda) \le \min\limits_x\max\limits_{\lambda}L(x,\lambda) λmaxxminL(x,λ)≤xminλmaxL(x,λ)
如果两个问题是强对偶的,那么这两个问题其实是等价的问题:
max λ min x L ( x , λ ) = min x max λ L ( x , λ ) \max\limits_{\lambda}\min\limits_{x}L(x,\lambda) = \min\limits_x\max\limits_{\lambda}L(x,\lambda) λmaxxminL(x,λ)=xminλmaxL(x,λ)
所有的下凸函数都满足强对偶性,也就是说所有下凸函数都满足上式。
4、目标函数优化【硬间隔】
通过2小节【构建SVM目标函数】我们知道SVM目标函数如下:
m i n 1 2 ∣ ∣ w ∣ ∣ s . t y ⋅ ( w T ⋅ x i + b ) ≥ 1 , i = 1 , 2 , ⋯ , n min\frac{1}{2}||w||\quad s.t\quad y\cdot (w^T\cdot x_i +b) \ge 1,\quad i = 1,2,\cdots,n min21∣∣w∣∣s.ty⋅(wT⋅xi+b)≥1,i=1,2,⋯,n
根据拉格朗日乘数法、KKT条件、对偶问题我们可以按照如下步骤来计算SVM目标函数最优的一组w值。
4.1、构造拉格朗日函数
将SVM目标函数转换为如下:
m i n 1 2 ∣ ∣ w ∣ ∣ s . t 1 − y ⋅ ( w T ⋅ x i + b ) ≥ 0 , i = 1 , 2 , ⋯ , n min\frac{1}{2}||w||\quad s.t\quad 1-y\cdot (w^T\cdot x_i +b) \ge 0,\quad i = 1,2,\cdots,n min21∣∣w∣∣s.t1−y⋅(wT⋅xi+b)≥0,i=1,2,⋯,n
根据3.2【KKT条件】中的⑨式构建拉格朗日函数如下:
min w , b max λ L ( w , b , λ ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 n λ i [ 1 − y i ( w T ⋅ x i + b ) ] s . t λ i ≥ 0 − − − 式 a \min\limits_{w,b}\max\limits_{\lambda}L(w,b,\lambda) = \frac{1}{2}||w||^2 + \sum\limits_{i=1}^n\lambda_i[1-y_i(w^T\cdot x_i +b)] \quad s.t \quad \lambda_i \ge 0\quad ---式a w,bminλmaxL(w,b,λ)=21∣∣w∣∣2+i=1∑nλi[1−yi(wT⋅xi+b)]s.tλi≥0−−−式a
以上不等式转换成拉格朗日函数必须满足KKT条件,详见3.2【KKT条件】,这里满足的KKT条件如下:
{ 1 − y i ( w T ⋅ x i + b ) ≤ 0 λ ( 1 − y i ( w T ⋅ x i + b ) ) = 0 λ ≥ 0 \left\{\begin{aligned}&1-y_i(w^T\cdot x_i + b) \le 0\\\\&\lambda (1-y_i(w^T\cdot x_i + b)) = 0\\\\&\lambda \ge 0\end{aligned}\right. ⎩ ⎨ ⎧1−yi(wT⋅xi+b)≤0λ(1−yi(wT⋅xi+b))=0λ≥0
4.2、对偶转换
由于原始目标函数 1 2 ∣ ∣ w ∣ ∣ \frac{1}{2}||w|| 21∣∣w∣∣是个下凸函数,根据3.3【对偶问题】可知 L ( w , b , λ ) L(w,b,\lambda) L(w,b,λ)一定是强对偶问题,所以可以将a式改写成如下:
max λ min w , b L ( w , b , λ ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 n λ i [ 1 − y i ( w T ⋅ x i + b ) ] s . t λ i ≥ 0 − − − 式 b \max\limits_{\lambda}\min\limits_{w,b}L(w,b,\lambda) = \frac{1}{2}||w||^2 + \sum\limits_{i=1}^n\lambda_i[1-y_i(w^T\cdot x_i +b)] \quad s.t \quad \lambda_i \ge 0\quad ---式b λmaxw,bminL(w,b,λ)=21∣∣w∣∣2+i=1∑nλi[1−yi(wT⋅xi+b)]s.tλi≥0−−−式b
针对b式,我们假设参数 λ \lambda λ固定,使 L ( w , b , λ ) L(w,b,\lambda) L(w,b,λ)对参数w和b进行求导得到如下:
{ ∂ L ∂ w = w − ∑ i = 1 n λ i ⋅ x i ⋅ y i = 0 ∂ L ∂ b = ∑ i = 1 n λ i ⋅ y i = 0 \left\{\begin{aligned}&\frac{\partial L}{\partial w}=w - \sum\limits_{i=1}^n\lambda_i\cdot x_i\cdot y_i = 0\\\\&\frac{\partial L}{\partial b}=\sum\limits_{i=1}^n\lambda_i\cdot y_i = 0\end{aligned}\right. ⎩ ⎨ ⎧∂w∂L=w−i=1∑nλi⋅xi⋅yi=0∂b∂L=i=1∑nλi⋅yi=0
进一步可以得到:
{ ∑ i = 1 n λ i ⋅ x i ⋅ y i = w ∑ i = 1 n λ i ⋅ y i = 0 − − − 式 c \left\{\begin{aligned}&\sum\limits_{i=1}^n\lambda_i\cdot x_i\cdot y_i = w\\\\&\sum\limits_{i=1}^n\lambda_i\cdot y_i = 0\end{aligned}\right.\quad --- 式c ⎩ ⎨ ⎧i=1∑nλi⋅xi⋅yi=wi=1∑nλi⋅yi=0−−−式c
按照解方程组的思想,我们现在将以上计算得到的结果代入到b式中得到:
max λ L ( w , b , λ ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 n λ i [ 1 − y i ( w T ⋅ x i + b ) ] = 1 2 ∑ i = 1 n ∑ j = 1 n λ i λ j y i y j ( x i ⋅ x j ) + ∑ i = 1 n λ i − ∑ i = 1 n λ i y i ( ∑ j = 1 n λ j x j y j ⋅ x i + b ) = 1 2 ∑ i = 1 n ∑ j = 1 n λ i λ j y i y j ( x i ⋅ x j ) + ∑ i = 1 n λ i − ∑ i = 1 n ∑ j = 1 n λ i y i λ j y j ( x i ⋅ x j ) − ∑ i = 1 n λ i y i b = ∑ i = 1 n λ i − 1 2 ∑ i = 1 n ∑ j = 1 n λ i λ j y i y j ( x i ⋅ x j ) s . t ∑ i = 1 n λ i y i = 0 , λ i ≥ 0 \begin{aligned}&\max\limits_{\lambda}L(w,b,\lambda) = \frac{1}{2}||w||^2 +\sum\limits_{i=1}^n\lambda_i[1 - y_i(w^T\cdot x_i + b)]\\\\&=\frac{1}{2}\sum\limits_{i=1}^n\sum\limits_{j=1}^n\lambda_i\lambda_j y_i y_j(x_i\cdot x_j) +\sum\limits_{i=1}^n\lambda_i -\sum\limits_{i=1}^n\lambda_iy_i(\sum\limits_{j=1}^n\lambda_jx_jy_j\cdot x_i +b)\\\\&=\frac{1}{2}\sum\limits_{i=1}^n\sum\limits_{j=1}^n\lambda_i\lambda_j y_i y_j(x_i\cdot x_j) +\sum\limits_{i=1}^n\lambda_i -\sum\limits_{i=1}^n\sum\limits_{j=1}^n\lambda_iy_i\lambda_jy_j(x_i\cdot x_j)-\sum\limits_{i=1}^n\lambda_i y_i b\\\\&=\sum\limits_{i=1}^n\lambda_i-\frac{1}{2}\sum\limits_{i=1}^n\sum\limits_{j=1}^n\lambda_i\lambda_j y_i y_j(x_i\cdot x_j)\quad s.t \quad \sum\limits_{i=1}^n\lambda_iy_i = 0,\lambda_i \ge 0\end{aligned} λmaxL(w,b,λ)=21∣∣w∣∣2+i=1∑nλi[1−yi(wT⋅xi+b)]=21i=1∑nj=1∑nλiλjyiyj(xi⋅xj)+i=1∑nλi−i=1∑nλiyi(j=1∑nλjxjyj⋅xi+b)=21i=1∑nj=1∑nλiλjyiyj(xi⋅xj)+i=1∑nλi−i=1∑nj=1∑nλiyiλjyj(xi⋅xj)−i=1∑nλiyib=i=1∑nλi−21i=1∑nj=1∑nλiλjyiyj(xi⋅xj)s.ti=1∑nλiyi=0,λi≥0
即:
max λ L ( w , b , λ ) = ∑ i = 1 n λ i − 1 2 ∑ i = 1 n ∑ j = 1 n λ i λ j y i y j ( x i ⋅ x j ) − − − 式 d s . t ∑ i = 1 n λ i y i = 0 , λ i ≥ 0 \begin{aligned}&\max\limits_{\lambda}L(w,b,\lambda) = \sum\limits_{i=1}^n\lambda_i-\frac{1}{2}\sum\limits_{i=1}^n\sum\limits_{j=1}^n\lambda_i\lambda_j y_i y_j(x_i\cdot x_j)\quad---式d\\\\& s.t \quad \sum\limits_{i=1}^n\lambda_iy_i = 0,\lambda_i \ge 0\end{aligned} λmaxL(w,b,λ)=i=1∑nλi−21i=1∑nj=1∑nλiλjyiyj(xi⋅xj)−−−式ds.ti=1∑nλiyi=0,λi≥0
我们可以发现以上公式经过转换只含有 λ \lambda λ的方程求极值问题,但是 λ \lambda λ含有 λ i , λ j , ⋯ \lambda_i,\lambda_j,\cdots λi,λj,⋯这些未知数(注意不是2个),那么我们要求的一组w如何得到呢?只要针对以上公式得到 λ \lambda λ值后,我们可以根据c式进一步求解到对应的一组w值。针对上式求极值问题,我们常用 SMO(Sequential Minimal Optimization) 算法求解 λ i , λ j , ⋯ \lambda_i,\lambda_j,\cdots λi,λj,⋯。
注意:d式中 ( x i ⋅ x j ) (x_i\cdot x_j) (xi⋅xj)代表两个向量的点积,也叫内积,例如: x i = ( x i 1 , x i 2 ) , x j = ( x j 1 , x j 2 ) x_i = (x_{i1},x_{i2}),x_j = (x_{j1},x_{j2}) xi=(xi1,xi2),xj=(xj1,xj2)那么两个向量点积结果为 x i 1 ∗ x j 1 + x i 2 ∗ x j 2 x_{i1} * x_{j1} + x_{i2} * x_{j2} xi1∗xj1+xi2∗xj2。
4.3、SMO算法求解(了解)
SMO(Sequential Minimal Optimization),序列最小优化算法,其核心思想非常简单:每次只优化一个参数,其他参数先固定住,仅求当前这个优化参数的极值。下面我们只说SVM中如何利用SMO算法进行求解最终结果的,这里不再进行公式推导。
max λ L ( w , b , λ ) = ∑ i = 1 n λ i − 1 2 ∑ i = 1 n ∑ j = 1 n λ i λ j y i y j ( x i ⋅ x j ) − − − 式 d s . t ∑ i = 1 n λ i y i = 0 , λ i ≥ 0 \begin{aligned}&\max\limits_{\lambda}L(w,b,\lambda) = \sum\limits_{i=1}^n\lambda_i-\frac{1}{2}\sum\limits_{i=1}^n\sum\limits_{j=1}^n\lambda_i\lambda_j y_i y_j(x_i\cdot x_j)\quad---式d\\\\& s.t \quad \sum\limits_{i=1}^n\lambda_iy_i = 0,\lambda_i \ge 0\end{aligned} λmaxL(w,b,λ)=i=1∑nλi−21i=1∑nj=1∑nλiλjyiyj(xi⋅xj)−−−式ds.ti=1∑nλiyi=0,λi≥0
我们根据d式可以看到有 λ i , λ j , i = 1 , 2 , ⋯ , n , j = 1 , 2 , ⋯ , n \lambda_i,\lambda_j,i = 1,2,\cdots,n,j = 1,2,\cdots,n λi,λj,i=1,2,⋯,n,j=1,2,⋯,n 很多参数,由于优化目标中含有约束条件: ∑ i = 1 n λ i y i = 0 \sum\limits_{i=1}^n\lambda_iy_i = 0 i=1∑nλiyi=0,此约束条件中 i = 1 , 2 , ⋯ , n i = 1,2,\cdots,n i=1,2,⋯,n, y i y_i yi代表每个样本所属类别-1或者1。
根据SMO算法假设将 λ 3 , λ 4 , ⋯ , λ n \lambda_3,\lambda_4,\cdots,\lambda_n λ3,λ4,⋯,λn参数固定,那么 λ 1 , λ 2 \lambda_1,\lambda_2 λ1,λ2之间的关系也确定了,可以将约束条件: ∑ i = 1 n λ i y i = 0 \sum\limits_{i=1}^n\lambda_iy_i = 0 i=1∑nλiyi=0改写成
λ 1 y + λ 2 y 2 + c = 0 − − − 式 e \lambda_1y_ + \lambda_2y_2 +c = 0 \quad ---式e λ1y+λ2y2+c=0−−−式e
我们可以将上式中c看成是 λ 3 , λ 4 , ⋯ , λ n \lambda_3,\lambda_4,\cdots,\lambda_n λ3,λ4,⋯,λn乘以对应的类别 y y y得到的常数,根据e式我们发现 λ 1 , λ 2 \lambda_1,\lambda_2 λ1,λ2之间有等式关系,即: λ 2 = − c − λ 1 y 1 y 2 \lambda_2 = \frac{-c - \lambda_1 y_1}{y_2} λ2=y2−c−λ1y1,也就是说我们可以使用 λ 1 \lambda_1 λ1的表达式代替 λ 2 \lambda_2 λ2,这样我们就可以将d式看成只含有 λ 1 ≥ 0 \lambda_1 \ge 0 λ1≥0这一个条件下最优化问题,并且我们可以将 λ 2 = − c − λ 1 y 1 y 2 \lambda_2 = \frac{-c - \lambda_1 y_1}{y_2} λ2=y2−c−λ1y1代入到d式,d式中只含有 λ 1 \lambda_1 λ1一个未知数求极值问题,可以对函数进行求导,令导数为零,得到 λ 1 \lambda_1 λ1的值,然后根据 λ 1 \lambda_1 λ1的值计算出 λ 2 \lambda_2 λ2的值。通过以上固定参数方式多次迭代计算得到一组 λ \lambda λ值。
然后对其他的 λ \lambda λ组【 λ 3 , λ 4 \lambda_3,\lambda_4 λ3,λ4】,进行相同操作,多次执行,即可得到全部 λ \lambda λ,for循环迭代优化,即可!
4.4、计算分割线w和b的值
根据4.2中的c式,如下:
{ ∑ i = 1 n λ i ⋅ x i ⋅ y i = w ∑ i = 1 n λ i ⋅ y i = 0 − − − 式 c \left\{\begin{aligned}&\sum\limits_{i=1}^n\lambda_i\cdot x_i\cdot y_i = w\\\\&\sum\limits_{i=1}^n\lambda_i\cdot y_i = 0\end{aligned}\right.\quad --- 式c ⎩ ⎨ ⎧i=1∑nλi⋅xi⋅yi=wi=1∑nλi⋅yi=0−−−式c
我们可以知道获取了一组 λ \lambda λ的值,我们可以得到一组w对应的值。根据4.1中的KKT条件:
{ 1 − y i ( w T ⋅ x i + b ) ≤ 0 λ ( 1 − y i ( w T ⋅ x i + b ) ) = 0 − − − 式 f λ ≥ 0 \left\{\begin{aligned}&1-y_i(w^T\cdot x_i + b) \le 0\\\\&\lambda (1-y_i(w^T\cdot x_i + b)) = 0\quad ---式f\\\\&\lambda \ge 0\end{aligned}\right. ⎩ ⎨ ⎧1−yi(wT⋅xi+b)≤0λ(1−yi(wT⋅xi+b))=0−−−式fλ≥0
根据f式中式可知,当 λ \lambda λ时,一定有$ 1-y_i(w^T\cdot x_i + b) = 0$,对于这样的样本就属于支持向量点,就在分类边界上,我们将对应的w代入到下式中
y i ( w T ⋅ x i + b ) = 1 − − − 式 g y_i(w^T\cdot x_i + b) = 1 \quad ---式g yi(wT⋅xi+b)=1−−−式g
一定可以计算出b的值。我们将g式两边乘以 y i y_i yi,得到
y i 2 ( w T ⋅ x i + b ) = y i y_i^2(w^T\cdot x_i + b) = y_i yi2(wT⋅xi+b)=yi
由于 y i 2 = 1 y_i^2 = 1 yi2=1,所以得到最终b的结果如下:
b = y i − w T ⋅ x i b = y_i - w^T\cdot x_i b=yi−wT⋅xi
假设我们有S个支持向量,以上b的计算可以使用任意一个支持向量代入计算即可,如果数据严格是线性可分的,这些b结果是一致的。对于数据不是严格线性可分的情况,参照后面的软间隔问题,一般我们可以采用一种更健壮的方式,将所有支持向量对应的b都求出,然后将其平均值作为最后的结果,最终b的结果如下:
b = 1 S ∑ i ∈ S ( y i − w T ⋅ x i ) b = \frac{1}{S}\sum\limits_{i \in S}(y_i - w^T \cdot x_i) b=S1i∈S∑(yi−wT⋅xi)
S代表支持向量点的集合,也就是在边界上点的集合。
综上所述,我们可以的到最终的w和b的值如下:
{ w = ∑ i = 1 n λ i ⋅ x i ⋅ y i b = 1 S ∑ i ∈ S ( y i − w T ⋅ x i ) \left\{\begin{aligned}&w = \sum\limits_{i=1}^n\lambda_i\cdot x_i\cdot y_i \\\\&b = \frac{1}{S}\sum\limits_{i \in S}(y_i - w^T \cdot x_i)\end{aligned}\right. ⎩ ⎨ ⎧w=i=1∑nλi⋅xi⋅yib=S1i∈S∑(yi−wT⋅xi)
确定w和b之后,我们就能构造出最大分割超平面: w T ⋅ x + b = 0 w^T\cdot x + b = 0 wT⋅x+b=0,新来样本对应的特征代入后得到的结果如果是大于0那么属于一类,小于0属于另一类。
原理与可视化
# 超平面,怎么找到的
导包
import numpy as np
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
创建数据
X = np.random.randn(3000,2) # 训练数据y = [1 if i > 0 else 0 for i in X[:,0] * X[:,1]]plt.scatter(X[:,0],X[:,1],c = y)
<matplotlib.collections.PathCollection at 0x189e97eb760>

建模学习
svc = SVC(kernel='poly',degree=2)# 高斯核函数,数据变换,变形,升维
svc.fit(X,y)
svc.score(X,y)
0.9943333333333333
创建预测数据
a = [2,3,5]
b = [1,4,7,9]print(a,b)
[2, 3, 5] [1, 4, 7, 9]
A,B = np.meshgrid(a,b)
print(A)
print('---------')
print(B)
plt.scatter(A,B)
[[2 3 5][2 3 5][2 3 5][2 3 5]]
---------
[[1 1 1][4 4 4][7 7 7][9 9 9]]<matplotlib.collections.PathCollection at 0x189e9270400>
f1 = np.linspace(-3,3,200)
f2 = np.linspace(-3,3,180)F1,F2 = np.meshgrid(f1,f2) # 网格交叉
X_test = np.column_stack([F1.ravel(),F2.reshape(-1)])plt.scatter(X_test[:,0],X_test[:,1])
<matplotlib.collections.PathCollection at 0x189ea04bb80>
算法预测
# 算法给我们的预测的类别
y_pred = svc.predict(X_test)plt.scatter(X_test[:,0],X_test[:,1],c = y_pred)
<matplotlib.collections.PathCollection at 0x189e98b30a0>
算法原理可视化【超平面】
d = svc.decision_function(X_test)
d
array([102.28708056, 101.26529785, 100.24339038, ..., 100.24339038,101.26529785, 102.28708056])
d.min()
-103.5053953169917
绘制轮廓线
plt.figure(figsize=(6,6))
plt.contour(F1,F2,d.reshape(180,200))# 等高线
<matplotlib.contour.QuadContourSet at 0x189eb1e1b50>
轮廓面
plt.figure(figsize=(6,6))
plt.contourf(F1,F2,d.reshape(180,200))
<matplotlib.contour.QuadContourSet at 0x189ed0713d0>
3D显示距离
plt.figure(figsize=(12,9))
ax = plt.subplot(111,projection = '3d')ax.contourf(F1,F2,d.reshape(-1,200))
ax.view_init(50,-30)

相关文章:
【机器学习】SVM支持向量机(一)
介绍 支持向量机(Support Vector Machine, SVM)是一种监督学习模型,广泛应用于分类和回归分析。SVM 的核心思想是通过找到一个最优的超平面来划分不同类别的数据点,并且尽可能地最大化离该超平面最近的数据点(支持向量…...

Spring Boot介绍、入门案例、环境准备、POM文件解读
文章目录 1.Spring Boot(脚手架)2.微服务3.环境准备3.1创建SpringBoot项目3.2导入SpringBoot相关依赖3.3编写一个主程序;启动Spring Boot应用3.4编写相关的Controller、Service3.5运行主程序测试3.6简化部署 4.Hello World探究4.1POM文件4.1.1父项目4.1.2父项目的父…...

基于Spring Boot + Vue3实现的在线商品竞拍管理系统源码+文档
前言 基于Spring Boot Vue3实现的在线商品竞拍管理系统是一种现代化的前后端分离架构的应用程序,它结合了Java后端框架Spring Boot和JavaScript前端框架Vue.js的最新版本(Vue 3)。该系统允许用户在线参与商品竞拍,并提供管理后台…...
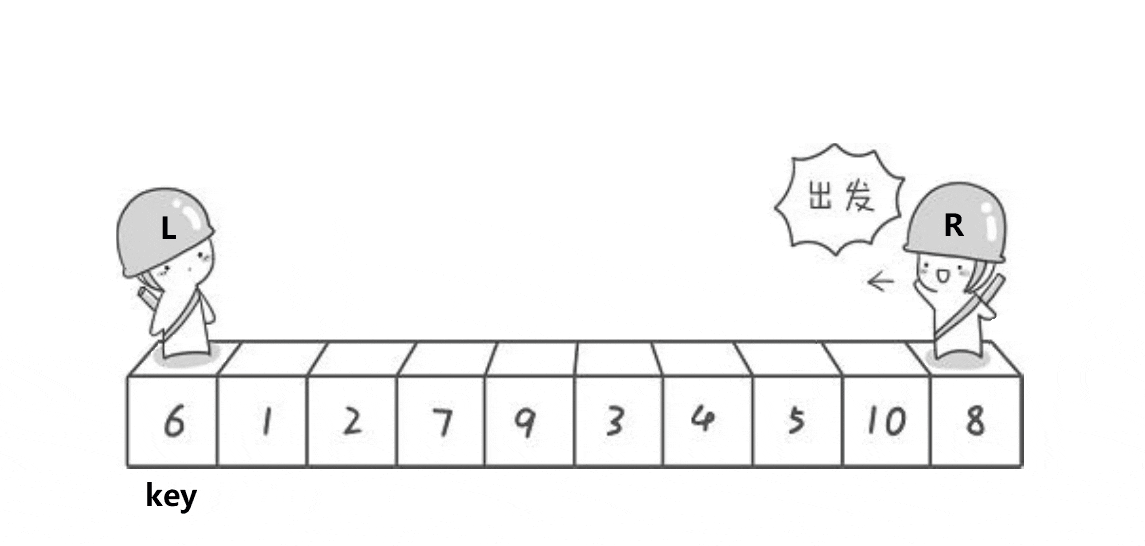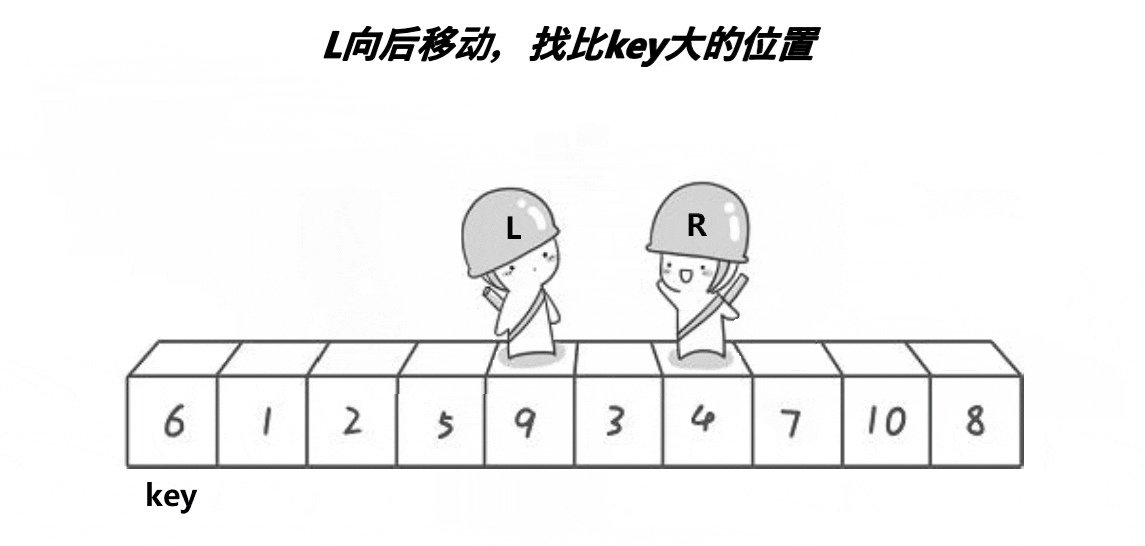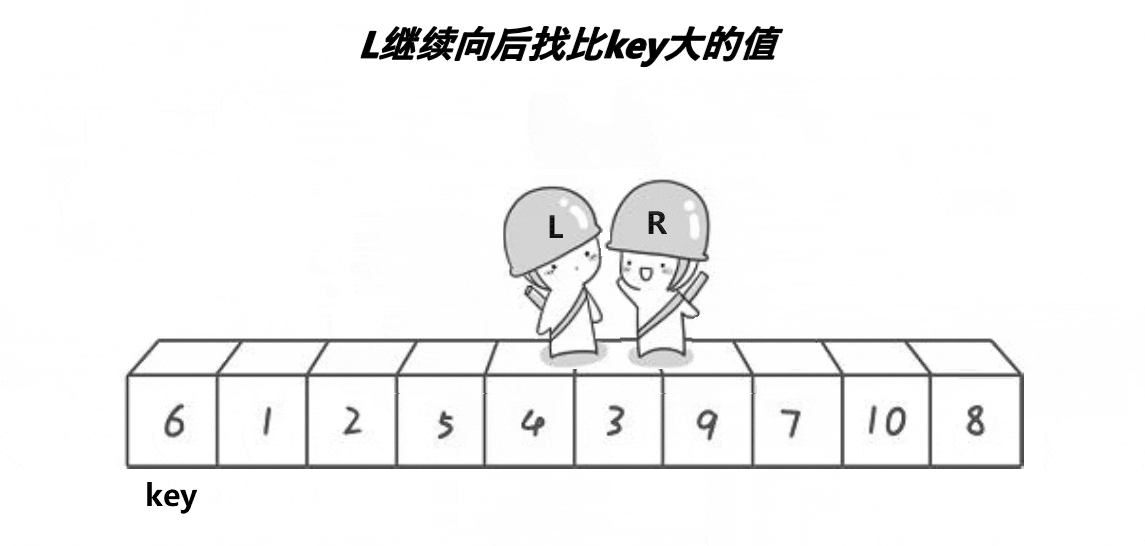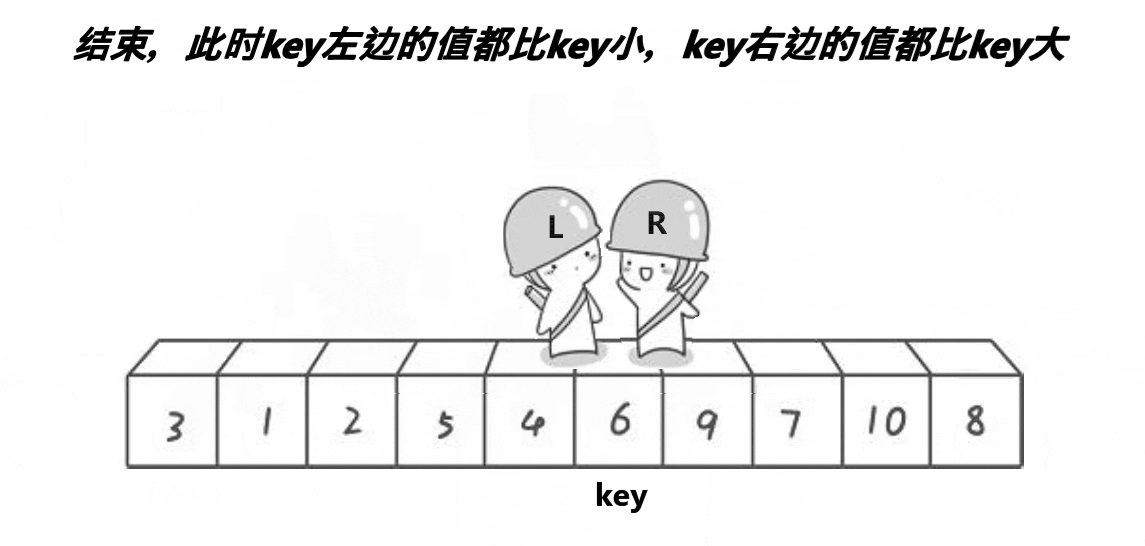
LeetCode--排序算法(堆排序、归并排序、快速排序)
排序算法 归并排序算法思路代码时间复杂度 堆排序什么是堆?如何维护堆?如何建堆?堆排序时间复杂度 快速排序算法思想代码时间复杂度 归并排序 算法思路 归并排序算法有两个基本的操作,一个是分,也就是把原数组划分成…...

华诺星空 Java 开发工程师笔试题 - 解析
单选题 1.Math.round(-11.5)等于多少?(B) A.-11.5 B.-11 C.-12 D.11.5 2.下列哪个没有继承自Collection接口。( C ) A.List B.Set C.Map D.全部 3.下列说法正确的有(B) A.在类方法中可用this来调用本类的类方法 B.在类方法中调用本类的类方法时可直接调用 C.在类…...

QT:一个TCP客户端自动连接的测试模型
版本 1:没有取消按钮 测试效果: 缺陷: 无法手动停止 测试代码 CMakeLists.txt cmake_minimum_required(VERSION 3.19) project(AutoConnect LANGUAGES CXX)find_package(Qt6 6.5 REQUIRED COMPONENTS Core Widgets Network)qt_standard_project_setup(…...

关于启动vue项目,出现:Error [ERR_MODULE_NOT_FOUND]: Cannot find module ‘xxx‘此类错误
目录 一、问题报错 二、原因分析 三、解决方法 一、问题报错 node环境变量配置有问题: (base) xxxM73H-15:~/VueProject/pproject-vue$ npm run dev /usr/bin/env: “node”: 没有那个文件或目录vue项目启动有问题: (base) xxx:~/VueProject/pproj…...

电路元件与电路基本定理
电流、电压和电功率 电流 1 定义: 带电质点的有序运动形成电流 。 单位时间内通过导体横截面的电量定义为电流强度, 简称电流,用符号 i 表示,其数学表达式为:(i单位:安培(A&#x…...

指针之矢:C 语言内存幽境的精准飞梭
一、内存和编码 指针理解的2个要点: 指针是内存中一个最小单元的编号,也就是地址平时口语中说的指针,通常指的是指针变量,是用来存放内存地址的变量 总结:指针就是地址,口语中说的指针通常指的是指针变量。…...

uniapp下载打开实现方案,支持安卓ios和h5,下载文件到指定目录,安卓文件管理内可查看到
uniapp下载&打开实现方案,支持安卓ios和h5 Android: 1、申请本地存储读写权限 2、创建文件夹(文件夹不存在即创建) 3、下载文件 ios: 1、下载文件 2、保存到本地,需要打开文件点击储存 使用方法&…...

免费干净!付费软件的平替款!
今天给大家介绍一个非常好用的电脑录屏软件,完全没有广告界面,非常的干净简洁。 电脑录屏 无广告的录屏软件 这个软件不需要安装,打开就能看到界面直接使用了。 软件可以全屏录制,也可以自定义尺寸进行录制。 录制的声音选择也非…...

软路由系统 iStoreOS 中部署 Minecraft 服务器
商业转载请联系作者获得授权,非商业转载请注明出处。协议(License): 知识共享署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)作者(Author): lhDream链接(URL): https://blog.luhua.site/archives/1734968846131 软路由系统 iStoreOS 中部署 Minecraft…...
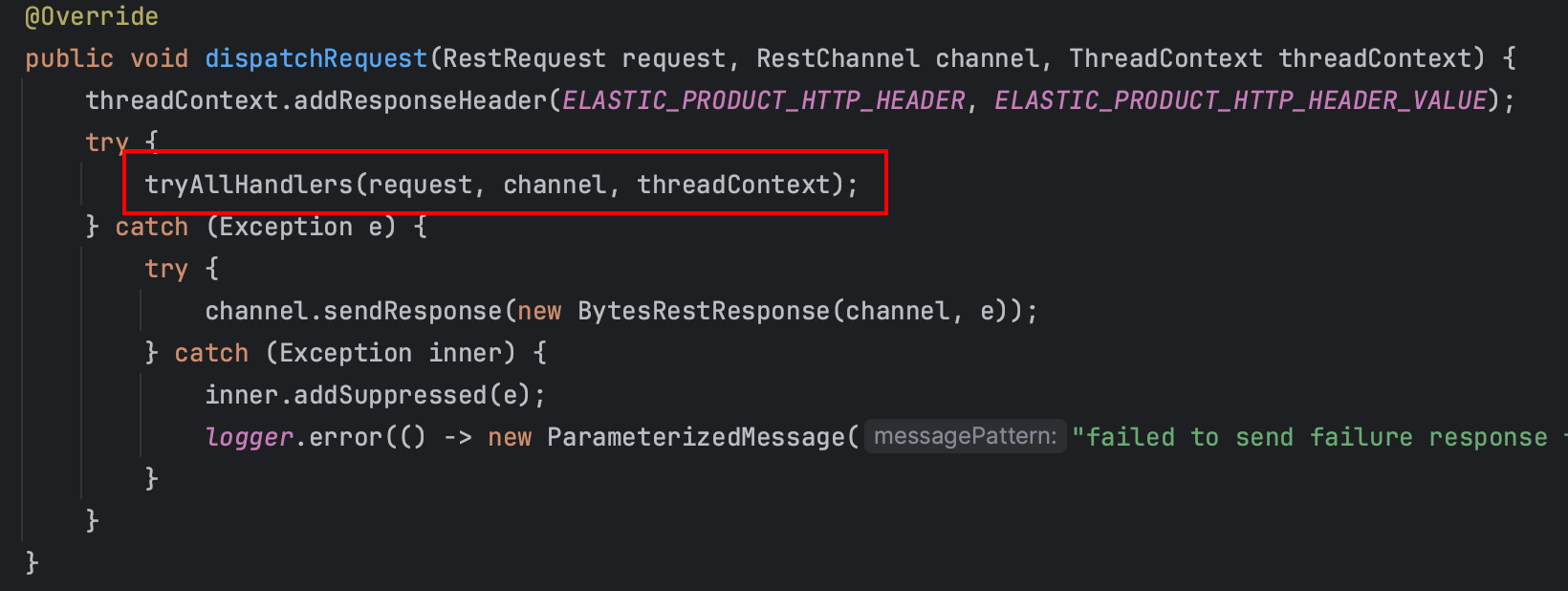
第 29 章 - ES 源码篇 - 网络 IO 模型及其实现概述
前言 本文介绍了 ES 使用的网络模型,并介绍 transport,http 接收、响应请求的代码入口。 网络 IO 模型 Node 在初始化的时候,会创建网络模块。网络模块会加载 Netty4Plugin plugin。 而后由 Netty4Plugin 创建对应的 transports࿰…...

细说STM32F407单片机IIC总线基础知识
目录 一、 I2C总线结构 1、I2C总线的特点 2、I2C总线通信协议 3、 STM32F407的I2C接口 二、 I2C的HAL驱动程序 1、 I2C接口的初始化 2、阻塞式数据传输 (1)函数HAL_I2C_IsDeviceReady() (2)主设备发送和接收数据 &#…...

从头开始学MyBatis—04缓存、逆向工程、分页插件
介绍了MyBatis的缓存、逆向工程和分页插件的使用 目录 1.Mybatis的缓存 1.1MyBatis的一级缓存 1.2MyBatis的二级缓存 1.3二级缓存的相关配置 1.4MyBatis缓存查询的顺序 1.5整合第三方缓存EHCache 1.5.1添加依赖 1.5.2各jar包功能 1.5.3创建EHCache的配置文件ehcache.x…...

Artec Space Spider助力剑桥研究团队解码古代社会合作【沪敖3D】
挑战:考古学家需要一种安全的方法来呈现新出土的陶瓷容器,对比文物形状。 解决方案:Artec Space Spider, Artec Studio 效果:本项目是REVERSEACTION项目的一部分,旨在研究无国家社会中复杂的古代技术。研究团队在考古地…...

《探索PyTorch计算机视觉:原理、应用与实践》
《探索PyTorch计算机视觉:原理、应用与实践》 一、PyTorch 与计算机视觉的奇妙相遇二、核心概念解析(一)张量:计算机视觉的数据基石(二)神经网络:视觉任务的智慧大脑(三)…...

【C#设计模式(21)——状态模式(State Pattern)】
前言 状态模式:在对象内部发生改变时改变其行为,使得对象在不同的状态下具有不同的行为表现。 代码 #region 状态模式-类/// 抽象 交通灯状态public abstract class TrafficLightState{public abstract void Display();}//红灯public class RedLight : TrafficLight…...

nvm日常使用中常用命令总结
日常开发vue项目中,不同的项目 我们可能需要安装不同的node版本,但是为了方便切换node,我们一般会安装一个名称为nvm的工具,这里总结一下,nvm常用的命令: 1、为了查看可用的 Node.js 版本,你可…...

【数据仓库】SparkSQL数仓实践
文章目录 集成hive metastoreSQL测试spark-sql 语法SQL执行流程两种数仓架构的选择hive on spark数仓配置经验 spark-sql没有元数据管理功能,只有sql 到RDD的解释翻译功能,所以需要和hive的metastore服务集成在一起使用。 集成hive metastore 在spark安…...

收藏 | 阿里字节开源Agent框架大比拼:小白程序员必看,三种思路助你入门大模型!
本文对比了阿里和字节开源的HiClaw、CoPaw和DeerFlow三个Agent框架,分析了它们在架构设计、安全模型和适用场景上的差异。HiClaw侧重多Agent协作,CoPaw聚焦个人AI助手,DeerFlow强调单Agent深度任务处理。文章还探讨了阿里组合拳与字节单点突破…...

Umi-OCR无界面服务化启动指南:将OCR能力无缝集成到自动化工作流
Umi-OCR无界面服务化启动指南:将OCR能力无缝集成到自动化工作流 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode…...

避坑指南:通达信指标加密的4种方法实测,哪种最难被破解?
通达信指标加密技术深度测评:从入门到防破解实战 在量化交易和个性化指标分析领域,通达信作为国内主流证券分析软件,其自定义指标功能一直备受投资者青睐。但随之而来的指标被盗用、滥用问题也让许多开发者头疼不已——一个经过数月验证的高胜…...
)
从IPv4到IPv6迁移实战:在eNSP里排查那些容易被忽略的安全配置(避坑指南)
从IPv4到IPv6迁移实战:eNSP环境下的安全配置深度排查指南 当企业网络从IPv4向IPv6过渡时,工程师们常常会陷入一种"配置惯性"——沿用IPv4时代的安全策略直接套用到IPv6环境。这种思维定式往往会导致网络出现各种"隐形漏洞"。本文将通…...

别再让DeepSeek-R1的<think>标签刷屏了!手把手教你用API和Python脚本一键隐藏思考过程
高效隐藏DeepSeek-R1思考过程的工程实践 当你在深夜调试一个集成DeepSeek-R1的客服系统时,终端突然被满屏的<think>标签刷爆——这种场景对开发者来说再熟悉不过了。作为一款强调推理过程的大语言模型,DeepSeek-R1默认会在输出中包含详细的思考步骤…...

告别广告侵扰:AdGuard广告拦截扩展全平台部署指南
告别广告侵扰:AdGuard广告拦截扩展全平台部署指南 【免费下载链接】AdguardBrowserExtension AdGuard browser extension 项目地址: https://gitcode.com/gh_mirrors/ad/AdguardBrowserExtension 副标题:从新手到高手的一站式配置方案 一、价值定…...

LightOnOCR-2-1B部署指南:快速搭建你的私有OCR识别服务
LightOnOCR-2-1B部署指南:快速搭建你的私有OCR识别服务 1. 认识LightOnOCR-2-1B 你是否遇到过需要从大量图片中提取文字的场景?比如扫描的合同、拍照的会议记录,或者历史档案数字化?传统的OCR解决方案要么识别准确率不高&#x…...

5步定制UEFI启动界面:技术爱好者的HackBGRT实战指南
5步定制UEFI启动界面:技术爱好者的HackBGRT实战指南 【免费下载链接】HackBGRT Windows boot logo changer for UEFI systems 项目地址: https://gitcode.com/gh_mirrors/ha/HackBGRT 一、问题发现:启动界面定制的3大痛点 在计算机使用体验中&am…...

3大突破!115proxy-for-Kodi实现云视频原码播放全攻略
3大突破!115proxy-for-Kodi实现云视频原码播放全攻略 【免费下载链接】115proxy-for-kodi 115原码播放服务Kodi插件 项目地址: https://gitcode.com/gh_mirrors/11/115proxy-for-kodi 副标题:突破存储限制,零缓冲流畅播放云端高清视频…...

Go后端项目代码规范:编写可维护Clean Architecture代码的7个黄金法则
Go后端项目代码规范:编写可维护Clean Architecture代码的7个黄金法则 【免费下载链接】go-backend-clean-architecture A Go (Golang) Backend Clean Architecture project with Gin, MongoDB, JWT Authentication Middleware, Test, and Docker. 项目地址: https…...