贝叶斯神经网络(Bayesian Neural Network)
最近在研究贝叶斯神经网络,一些概念一直搞不清楚,这里整理一下相关内容,方便以后查阅。
贝叶斯神经网络(Bayesian Neural Network)
- 贝叶斯神经网络(Bayesian Neural Network)
- 1. BNN 的核心思想
- 2. BNN 的优化目标
- 3. BNN 的结构与特点
- 4. BNN 的训练过程
- 5. BNN 的优缺点
- 6. 与经典神经网络的对比
- 7. 简单代码示例(PyTorch)
- 总结
- BNN 的目标是计算后验分布
- 1. 经典神经网络与最大化似然估计
- 2. 贝叶斯神经网络的目标
- 3. 经典神经网络与贝叶斯神经网络的核心区别
- 4. 为什么不是最大化似然估计或最小化损失函数
- 5. 贝叶斯神经网络的优化目标
- 6. 实际意义:后验分布的好处
- 总结
- Bayes by Backprop
- 1. Bayes by Backprop 的目标
- 2. Bayes by Backprop 的实现细节
- 总结
- 经典神经网络优化的例子
- 使用均方根误差优化
- 代码实现
- 代码解释
- 对比 Bayes by Backprop
- 使用最大化似然估计优化
- 代码实现
- 代码解释
- MLE如何在此应用
- 对比 Bayes by Backprop
贝叶斯神经网络(Bayesian Neural Network)
贝叶斯神经网络(Bayesian Neural Network, BNN) 是在经典神经网络中引入贝叶斯概率框架的一种扩展模型。它将网络的权重参数表示为概率分布,而不是确定性的点值,从而可以量化模型和预测结果的不确定性。


1. BNN 的核心思想
在经典神经网络中,权重是固定的点值,通过最小化损失函数(如均方误差、交叉熵)来优化权重参数。而在贝叶斯神经网络中,权重被建模为概率分布,目标是通过数据更新这些分布(即计算后验分布)。
贝叶斯定理:
p ( w ∣ D ) = p ( D ∣ w ) p ( w ) p ( D ) , p(\mathbf{w}|\mathcal{D}) = \frac{p(\mathcal{D}|\mathbf{w}) p(\mathbf{w})}{p(\mathcal{D})}, p(w∣D)=p(D)p(D∣w)p(w),
其中:
- p ( w ∣ D ) p(\mathbf{w}|\mathcal{D}) p(w∣D):后验分布,表示在观察数据后,权重的分布。
- p ( D ∣ w ) p(\mathcal{D}|\mathbf{w}) p(D∣w):似然函数,表示数据在给定权重下的可能性。
- p ( w ) p(\mathbf{w}) p(w):先验分布,表示我们对权重的先验假设(如权重可能是零均值的高斯分布)。
- p ( D ) p(\mathcal{D}) p(D):边际似然,通常通过积分对所有可能的权重求和:
p ( D ) = ∫ p ( D ∣ w ) p ( w ) d w . p(\mathcal{D}) = \int p(\mathcal{D}|\mathbf{w}) p(\mathbf{w}) d\mathbf{w}. p(D)=∫p(D∣w)p(w)dw.
2. BNN 的优化目标
BNN 的目标是计算后验分布 p ( w ∣ D ) p(\mathbf{w}|\mathcal{D}) p(w∣D)。由于边际似然 p ( D ) p(\mathcal{D}) p(D) 的计算通常非常困难(涉及高维积分),我们采用近似方法来推断后验分布,例如:
-
变分推断(Variational Inference)
用一个简单的分布 q ( w ∣ θ ) q(\mathbf{w}|\boldsymbol{\theta}) q(w∣θ) 近似 p ( w ∣ D ) p(\mathbf{w}|\mathcal{D}) p(w∣D),并最小化 KL 散度:
K L ( q ( w ∣ θ ) ∥ p ( w ∣ D ) ) . \mathrm{KL}(q(\mathbf{w}|\boldsymbol{\theta}) \| p(\mathbf{w}|\mathcal{D})). KL(q(w∣θ)∥p(w∣D)). -
蒙特卡罗方法(Monte Carlo Methods)
使用随机采样方法(如 MCMC)直接从后验分布中采样。 -
贝叶斯 by Backprop
通过重参数化技巧,将变分推断和神经网络的反向传播结合。
3. BNN 的结构与特点
BNN 与经典神经网络的主要区别是权重的建模方式:
- 经典神经网络:权重是固定值(点估计)。
- 贝叶斯神经网络:权重是概率分布,表示为 p ( w ) p(\mathbf{w}) p(w)。
在 BNN 中,推断网络输出时也会引入随机性:
p ( y ∣ x , D ) = ∫ p ( y ∣ x , w ) p ( w ∣ D ) d w . p(\mathbf{y}|\mathbf{x}, \mathcal{D}) = \int p(\mathbf{y}|\mathbf{x}, \mathbf{w}) p(\mathbf{w}|\mathcal{D}) d\mathbf{w}. p(y∣x,D)=∫p(y∣x,w)p(w∣D)dw.
这意味着预测结果(输出 y \mathbf{y} y)不仅依赖于输入 x \mathbf{x} x,还受到权重分布的不确定性影响。
4. BNN 的训练过程
BNN 的训练过程包括以下步骤:
-
定义先验分布:
对权重 w \mathbf{w} w 定义一个先验分布 p ( w ) p(\mathbf{w}) p(w),例如零均值的高斯分布:
p ( w ) = N ( w ∣ 0 , σ 2 ) . p(\mathbf{w}) = \mathcal{N}(\mathbf{w}|0, \sigma^2). p(w)=N(w∣0,σ2). -
计算似然函数:
定义数据的似然函数 p ( D ∣ w ) p(\mathcal{D}|\mathbf{w}) p(D∣w),例如对分类任务,通常是交叉熵损失对应的概率分布。 -
近似后验分布:
用 q ( w ∣ θ ) q(\mathbf{w}|\boldsymbol{\theta}) q(w∣θ) 近似 p ( w ∣ D ) p(\mathbf{w}|\mathcal{D}) p(w∣D)。- q ( w ∣ θ ) q(\mathbf{w}|\boldsymbol{\theta}) q(w∣θ) 的参数(如均值 μ \mu μ 和方差 σ \sigma σ)是通过优化得到的。
- 目标是最大化变分下界:
L ( θ ) = E q ( w ∣ θ ) [ log p ( D ∣ w ) ] − K L ( q ( w ∣ θ ) ∥ p ( w ) ) . \mathcal{L}(\boldsymbol{\theta}) = \mathbb{E}_{q(\mathbf{w}|\boldsymbol{\theta})}[\log p(\mathcal{D}|\mathbf{w})] - \mathrm{KL}(q(\mathbf{w}|\boldsymbol{\theta}) \| p(\mathbf{w})). L(θ)=Eq(w∣θ)[logp(D∣w)]−KL(q(w∣θ)∥p(w)).
对最小化变分下界的理解:
第一部分:对数似然的期望 E q ( w ∣ θ ) [ log p ( D ∣ w ) ] \mathbb{E}_{q(\mathbf{w}|\boldsymbol{\theta})}[\log p(\mathcal{D}|\mathbf{w})] Eq(w∣θ)[logp(D∣w)]
- 作用:评估近似分布 q ( w ∣ θ ) q(\mathbf{w}|\boldsymbol{\theta}) q(w∣θ) 在训练数据 D \mathcal{D} D 上的拟合能力。
- 解释:从分布 q ( w ∣ θ ) q(\mathbf{w}|\boldsymbol{\theta}) q(w∣θ) 中采样权重 w \mathbf{w} w,然后计算其对应的对数似然 log p ( D ∣ w ) \log p(\mathcal{D}|\mathbf{w}) logp(D∣
相关文章:
贝叶斯神经网络(Bayesian Neural Network)
最近在研究贝叶斯神经网络,一些概念一直搞不清楚,这里整理一下相关内容,方便以后查阅。 贝叶斯神经网络(Bayesian Neural Network) 贝叶斯神经网络(Bayesian Neural Network)1. BNN 的核心思想2. BNN 的优化目标3. BNN 的结构与特点4. BNN 的训练过程5. BNN 的优缺点6. …...

Direct Preference Optimization: Your Language Model is Secretly a Reward Model
DPO直接偏好优化:你的语言模型实际上是一个奖励模型 前言知识储备 什么是用户偏好数据目的:用于指导模型行为,使其输出更符合特定用户或者用户群体期望和喜好的信息。 用户偏好数据通常反映了用户对特定内容、风格、观点或者互动方式的倾向。 用户偏好数据的收集通常涉及直…...

如何通过 Kafka 将数据导入 Elasticsearch
作者:来自 Elastic Andre Luiz 将 Apache Kafka 与 Elasticsearch 集成的分步指南,以便使用 Python、Docker Compose 和 Kafka Connect 实现高效的数据提取、索引和可视化。 在本文中,我们将展示如何将 Apache Kafka 与 Elasticsearch 集成以…...

嵌入式系统 第十二讲 块设备和驱动程序设计
• 块设备是Linux三大设备之一(另外两种是字符设备,网络设备),块 设备也是通过/dev下的文件系统节点访问。 • 块设备的数据存储单位是块,块的大小通常为512B至32KB不等。 • 块设备每次能传输一个或多个块,…...

攻防世界web第六题upload
这是题目,可以看出是个上传文件的题目,考虑文件上传漏洞,先随便上传一个文件试试,要求上传的是图片。 可以看到上传成功。 考虑用一句话木马解决,构造文件并修改后缀为jpg,然后上传。 <?php eval($_POST[attack])…...

人工智能-Python网络编程-HTTP
用Python创建自己的HTTP服务器 方案一 HTTP-Python官方 python -m http.server 80 方案二 HTTP-概念版 import socketIPV4_ADDR 192.168.124.7 IPV4_PORT 8888# TCP 服务端程序必须绑定端口号,否则客户端找不到这个 TCP 服务端程序 class ServerSocket(obje…...

探索仓颉编程语言:功能、实战与展望
目录 引言 一.使用体验 二.功能剖析 1.丰富的数据类型与控制结构 2.强大的编程范式支持 3.标准库与模块系统 4.并发编程能力 三.实战案例 1.项目背景与目标 2.具体实现步骤 (1).导入必要的模块 (2).发送 HTTP 请求获取网页内容 (3).解析 HTML 页面提取文章信息 (…...

Unity-Editor扩展显示文件夹大小修复版 FileCapacity.cs
实战中是这样的,大项目, 容易定位美术大资产 (原版的代码有问题,每次点运行都会卡顿,大项目20S) //但其实获整个项目内容,1G都没有,有够省的(10年前的中型项目,一直有出DLC) using System; using System.Collections; using System.Collections.Generic; using Sy…...

BLE core 内容整理解释
本文内容比较杂散,只是做记录使用,后续会整理的有条理些 link layer 基本介绍 **Link Layer Control(链路层控制)**是蓝牙低功耗(BLE)协议栈的核心部分,负责实现设备间可靠、安全、低功耗的数…...

Linux CPU调度算法
简述 ● CPU数量 < 进程数 ● 每次CPU都要决定下一个运行的进程,这个选择叫做CPU调度;这个选择工作就叫做CPU调度程序 ● 如果一个进程中有多个线程的话,内核管理的线程就以线程为基本单位 ● 进程通常分为两种,一种长时间占…...

Linux套接字通信学习
Linux套接字通信 在网络通信的时候, 程序猿需要负责的应用层数据的处理(最上层),而底层的数据封装与解封装(如TCP/IP协议栈的功能)通常由操作系统、网络协议栈或相关网络库(如Socket库)实现。(程序员只需要…...

mybatis-plus 用法总结
MyBatis-Plus(简称 MP)是 MyBatis 的增强工具,旨在简化开发者的 CRUD 操作。它在 MyBatis 的基础上提供了更多的功能和便利性,如代码生成器、分页插件、性能分析插件等,使开发者能够更高效地进行数据库操作。MyBatis-P…...

小程序配置文件 —— 14 全局配置 - tabbar配置
全局配置 - tabBar配置 tabBar 字段:定义小程序顶部、底部 tab 栏,用以实现页面之间的快速切换;可以通过 tabBar 配置项指定 tab 栏的表现,以及 tab 切换时显示的对应页面; 在上面图中,标注了一些 tabBar …...

Redis-十大数据类型
Reids数据类型指的是value的类型,key都是字符串 redis-server:启动redis服务 redis-cli:进入redis交互式终端 常用的key的操作 redis的命令和参数不区分大小写 ,key和value区分 1、查看当前库所有的key keys * 2、判断某个key是否存在 exists key 3、查…...
管道和FIFO)
linux系统编程(七)管道和FIFO
1、管道 使用系统调用pipe可以创建一个新管道: #include <unistd.h> int pipe(int filedes[2]);成功的pipe调用会在数组filedes中返回两个打开的文件描述符,读取端为filedes[0],写入端为filedes[1]。我们可以使用read/write系统调用在…...
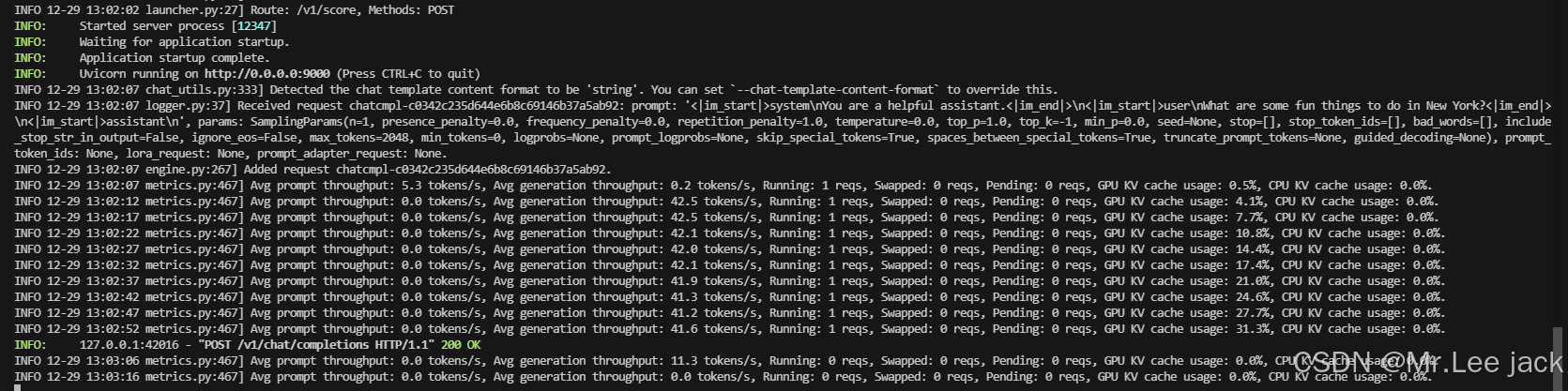
【vLLM大模型TPS测试三部曲】
安装 pip install vllm模型自行下载 例如: https://modelscope.cn/models/jackle/Qwen2.5-Coder-32B-GPTQ-Int4/ 部署测试 export VLLM_MODELQwen2.5-Coder-32B-GPTQ-Int4 # 启动 python3 -m vllm.entrypoints.openai.api_server --model $VLLM_MODEL --deviceauto --enf…...

Elasticsearch:使用 Ollama 和 Go 开发 RAG 应用程序
作者:来自 Elastic Gustavo Llermaly 使用 Ollama 通过 Go 创建 RAG 应用程序来利用本地模型。 关于各种开放模型,有很多话要说。其中一些被称为 Mixtral 系列,各种规模都有,而一种可能不太为人所知的是 openbiollm,这…...

Windows平台ROBOT安装
Windows环境下ROBOT的安装,按照下文进行部署ROBOT的前提是你的python已安装并且环境变量已设置好. 一、安装setuptools 1、下载后安装 https://pypi.python.org/pypi/setuptools/ 下载你需要的包 setuptools-75.6.0.tar.gz 解压下载的包在命令行中进入该包,敲击如下命令后…...

【动态规划篇】穿越算法迷雾:约瑟夫环问题的奇幻密码
欢迎拜访:羑悻的小杀马特.-CSDN博客 本篇主题:带你众人皆知的约瑟夫环问题 制作日期:2024.12.29 隶属专栏:C/C题海汇总 目录 引言: 一约瑟夫环问题介绍: 11问题介绍: 1.2起源与历史背景&…...
代码随想录算法训练营第51期第32天 | 理论基础、509. 斐波那契数、70. 爬楼梯、746. 使用最小花费爬楼梯
理论基础 动态规划:dp,每一个状态都是由上个状态推导出来的,因为我是先写完三道题再看理论的,所以有点感概; 确定dp数组(dp table)以及下标的含义确定递推公式dp数组如何初始化确定遍历顺序举…...

谷歌DeepMind与卡内基梅隆大学揭秘声音背后的脸
这项由谷歌DeepMind与卡内基梅隆大学联合开展的研究,发表于2024年的计算机视觉与模式识别顶级会议CVPR(IEEE/CVF Conference on Computer Vision and Pattern Recognition),论文编号为arXiv:2404.01975,有兴趣深入了解…...

鸿蒙SpeechKit离线语音识别避坑指南:从PCM格式到权限配置,一次搞定
鸿蒙SpeechKit离线语音识别实战避坑指南 1. 音频格式的致命陷阱 PCM格式是鸿蒙SpeechKit离线语音识别的唯一选择,但开发者常犯的错误远不止文件类型这么简单。我曾见过一个团队花费三天时间排查识别率低的问题,最终发现是采样深度设置错误——这个细节在…...

CTE、临时表、子查询如何选?
在 SQL Server 等关系型数据库中,处理复杂查询逻辑时,子查询 (Subquery)、临时表 (Temporary Table) 和公共表表达式 (CTE, Common Table Expression) 是三种核心工具。它们各有优劣,选择哪种取决于具体的性能需求、数据规模、代码可读性以及…...

基于CATIA有限元的焊装夹具Base板应力分析与优化设计
1. 为什么焊装夹具Base板需要应力分析? 在汽车制造领域,焊装夹具是确保车身焊接精度的关键设备。其中Base板作为夹具的支撑基础,承受着来自机器人抓手和工件的全部载荷。很多新手工程师常犯的错误是直接套用经验公式设计,结果要么…...

Anthropic调整Claude使用限制以缓解高峰时段需求压力
Anthropic公司周三调整了Claude客户的使用限制策略,在高峰需求时段降低服务功率,以平衡用户需求与其服务交付能力。Anthropic技术团队成员Thariq Shihipar在社交媒体上发布消息称:"为了管理Claude日益增长的需求,我们正在调整…...

BY8X01-16P Arduino音频模块驱动库深度解析
1. 项目概述BY8X01-16P-Arduino 是一款专为 Arduino 生态设计的轻量级、高兼容性音频模块控制库,面向 BY8001-16P 与 BY8301-16P(文档中偶见笔误为 BY83001-16P)双芯片平台。该库并非简单封装串口指令,而是以嵌入式系统工程视角重…...

老牌CMS的隐痛:从DedeCMS漏洞看开源系统会员模块的安全设计误区
DedeCMS会员模块漏洞剖析:开源系统安全设计的深层反思 当一款拥有百万级安装量的老牌CMS系统曝出前台任意密码修改漏洞时,我们看到的不仅是一个具体的技术缺陷,更是开源项目在安全架构设计上的系统性隐忧。2018年那场影响广泛的DedeCMS漏洞事…...

Anthropic 经济指数报告:学习曲线
引言 Anthropic 经济指数利用隐私保护数据分析系统,追踪 Claude 在整个经济领域中的应用情况。这是Anthropic 努力的一部分,旨在尽早理解 AI 对经济的影响,以便研究人员和政策制定者有充足的时间做好准备。 在最新一期的报告中,首先观察到了与先前报告相比使用情况的变化…...
参数)
煤矿电液阀系统摄像仪护套连接器 DLJ01(1000)参数
在煤矿综采工作面液压支架电液控制系统中,摄像仪护套连接器 DLJ01(1000)作为矿用本安型摄像仪与电源、信号传输线缆之间的专用接口,承担着视频信号与供电的稳定传输任务。其型号中的“1000”代表线缆长度为1000mm(1米),…...

Lobe Theme:为Stable Diffusion WebUI注入现代设计美学的终极界面解决方案
Lobe Theme:为Stable Diffusion WebUI注入现代设计美学的终极界面解决方案 【免费下载链接】sd-webui-lobe-theme 🤯 Lobe theme - The modern theme for stable diffusion webui, exquisite interface design, highly customizable UI, and efficiency …...