SQL Server大批量数据插入
数据库连接及相关操作
public class DataBase {/*** 驱动*/private static final String DRIVER = PropertiesUtil.getString("spring.datasource.driver-class-name");/*** 数据库地址*/private static final String URL = PropertiesUtil.getString("spring.datasource.url");/*** 数据库用户名*/private static final String NAME = PropertiesUtil.getString("spring.datasource.username");/*** 数据库密码*/private static final String PASSWORD = PropertiesUtil.getString("spring.datasource.password");/*** 数据库连接,定义为全局变量,方便调用*/private Connection con;//导入驱动,静态代码块的作用为只运行一次,异常无法向上抛出,只能及时处理static {try {Class.forName(DRIVER);} catch (ClassNotFoundException e) {//打印异常相关信息e.printStackTrace();}}/*** 无参构造方法,连接数据库*/public DataBase() {try {con = DriverManager.getConnection(URL, NAME, PASSWORD);} catch (SQLException throwable) {throwable.printStackTrace();}}/*** 数据查找,返回查找的内容,向上抛异常** @param sql* @param object* @return* @throws SQLException*/public ResultSet executeSQL(String sql, Object... object) throws SQLException {PreparedStatement ps = con.prepareStatement(sql);for (int i = 0; i < object.length; i++) {//ps传入参数的下标是从1开始ps.setObject(i + 1, object[i]);}//返回结果集return ps.executeQuery();}/*** 关闭数据库连接** @throws SQLException*/public void close() throws SQLException {con.close();}/*** 设置 AutoCommit 模式为 false** @throws SQLException*/public void setAutoCommit(boolean flag) throws SQLException {// 设置 AutoCommit 模式con.setAutoCommit(flag);}/*** 事务提交** @throws SQLException*/public void commit() throws SQLException {// 手动提交事务con.commit();}/*** 事务回滚** @throws SQLException*/public void rollback() throws SQLException {con.rollback();}
}批量插入数据
public class BulkCopyUtil {/*** 批量插入数据** @param tableName 表名* @param list 数据集合* @throws SQLException*/public static <T> void insertBatch(String tableName, List<T> list) throws Exception {// 查询出空值用于构建 CachedRowSetImpl 对象以省去列映射的步骤DataBase dataBase = new DataBase();// 从源表中获取数据作为 ResultSetResultSet resultSet = dataBase.executeSQL("select * from " + tableName + " where 1=0");CachedRowSetImpl crs = new CachedRowSetImpl();crs.populate(resultSet);ResultSetMetaData metaData = resultSet.getMetaData();int columnCount = metaData.getColumnCount();String[] dbFieldNames = new String[columnCount];for (int i = 1; i <= columnCount; i++) {dbFieldNames[i-1] = metaData.getColumnName(i);}// 循环批量插入for (T t : list) {if (ObjectUtil.isNotEmpty(t)) {// 移动指针到“插入行”,插入行是一个虚拟行crs.moveToInsertRow();// 向 CachedRowSet 对象插入一条数据populate(crs, t, dbFieldNames);// 插入虚拟行crs.insertRow();// 移动指针到当前行crs.moveToCurrentRow();}}// 进行批量插入bulkCopyHelp(dataBase, crs, tableName, list.size());}/*** 批量插入数据** @param dataBase 数据库连接相关操作* @param crs CachedRowSet* @param tableName 表名* @param size 拷贝列表大小*/public static void bulkCopyHelp(DataBase dataBase, CachedRowSetImpl crs, String tableName, int size) throwsSQLException {// 数据库地址String url = PropertiesUtil.getString("spring.datasource.url");// 数据库用户名String name = PropertiesUtil.getString("spring.datasource.username");// 数据库密码String password = PropertiesUtil.getString("spring.datasource.password");// 数据库连接字符串String urlStr = url + ";user=" + name + ";password=" + password;// 使用 KeepIdentity 选项和 BatchSize 设置大容量复制对象SQLServerBulkCopyOptions copyOptions = new SQLServerBulkCopyOptions();copyOptions.setKeepIdentity(true);copyOptions.setBatchSize(size);// 开启数据库事务copyOptions.setUseInternalTransaction(true);// 设置超时时间copyOptions.setBulkCopyTimeout(60000);SQLServerBulkCopy bulkCopy = new SQLServerBulkCopy(urlStr);bulkCopy.setBulkCopyOptions(copyOptions);// 设置拷贝目标表名bulkCopy.setDestinationTableName(tableName);// 将 crs 写入目标try {// 设置 AutoCommit 模式为 falsedataBase.setAutoCommit(false);// 执行数据库操作bulkCopy.writeToServer(crs);// 手动提交事务dataBase.commit();} catch (SQLException e) {e.printStackTrace();// 回滚dataBase.rollback();}crs.close();bulkCopy.close();}/*** 这里主要是通过表的列名,通过反射,拿到待插入对象的属性值** @param crs* @param record* @param dbFieldNames* @param <T>* @throws Exception*/private static <T> void populate(CachedRowSetImpl crs, T record, String[] dbFieldNames) throws Exception {Class<?> clazz = record.getClass();for (String fieldName : dbFieldNames) {StringBuilder getMethodName = new StringBuilder("get");if (fieldName.contains("_")) {String[] singleWords = fieldName.split("_");for (String singleWord : singleWords) {getMethodName.append(upperFirstChar(singleWord));}} else {getMethodName.append(upperFirstChar(fieldName));}Method method = clazz.getMethod(getMethodName.toString(), null);Object value = method.invoke(record, null);updateCrs(crs, fieldName, value);}}/*** 根据数据值的类型,将值设置到rowset里--这里value是否为空,都要做crs.update操作,否则会出bug** @param crs* @param dbFieldName* @param value* @throws SQLException*/private static void updateCrs(CachedRowSetImpl crs, String dbFieldName, Object value) throws SQLException {if (value instanceof String) {crs.updateString(dbFieldName, (String) value);} else if (value instanceof Integer) {crs.updateInt(dbFieldName, (int) value);} else if (value instanceof Double) {crs.updateDouble(dbFieldName, (double) value);} else if (value instanceof Long) {crs.updateLong(dbFieldName, (long) value);} else if (value instanceof Float) {crs.updateFloat(dbFieldName, (float) value);} else if (value instanceof Timestamp) {crs.updateTimestamp(dbFieldName, (Timestamp) value);} else if (value instanceof java.util.Date) {crs.updateDate(dbFieldName, new java.sql.Date(((java.util.Date) value).getTime()));} else {crs.updateObject(dbFieldName, value);}}/*** 首字母大写* @param camelCaseStr* @return*/private static String upperFirstChar(String camelCaseStr) {return camelCaseStr.substring(0, 1).toUpperCase() + camelCaseStr.substring(1);}
}
备注(数据库连接取值)
# 配置数据源
spring:datasource:driver-class-name: com.microsoft.sqlserver.jdbc.SQLServerDriverurl: jdbc:sqlserver://ip:port;DatabaseName=collectionusername: sapassword: 123456相关文章:

SQL Server大批量数据插入
数据库连接及相关操作 public class DataBase {/*** 驱动*/private static final String DRIVER PropertiesUtil.getString("spring.datasource.driver-class-name");/*** 数据库地址*/private static final String URL PropertiesUtil.getString("spring.da…...

在 Ubuntu 下通过 Docker 部署 Caddy 服务器
嘿,伙伴们!今天我们来聊聊如何在 Ubuntu 系统下通过 Docker 部署 Caddy 服务器。Caddy 是一个现代的 Web 服务器,支持自动 HTTPS,简单易用,特别适合快速搭建网站。而 Docker 则是一个让你可以隔离和管理应用的神器。结…...

ZooKeeper注册中心实现
具体步骤 安装ZooKeeper(启动端口占用,2181:客户端,8080:管理端)引入客户端依赖实现注册中心接口SPI补充ZooKeeper注册中心 引入依赖 <!-- zookeeper --> <dependency><groupId>org.a…...

数仓建模:如何进行实体建模?
目录 1 如何进行实体建模? 业务建模 领域建模 逻辑建模 2 实体建模具体步骤 需求分析...

Python编程技术
设计目的 该项目框架Scrapy可以让我们平时所学的技术整合旨在帮助学习者提高Python编程技能并熟悉基本概念: 1. 学习基本概念:介绍Python的基本概念,如变量、数据类型、条件语句、循环等。 2. 掌握基本编程技巧:教授学生如何使…...

「Mac玩转仓颉内测版55」应用篇2 - 使用函数实现更复杂的计算
本篇教程基于仓颉编程语言扩展了计算器功能,支持加减乘除的基础运算,以及幂运算和开平方等高级功能。代码经过简化后,移除了对输入的复杂校验,提升了程序的可维护性和交互效率。 关键词 仓颉编程语言函数封装高级运算 一、功能说…...

map参数详解
const items new Array(15).fill(null).map((_, index) > ({key: index 1,label: nav ${index 1}, })); $.map() 函数用于使用指定函数处理数组中的每个元素(或对象的每个属性),并将处理结果封装为新的数组返回。 注意:1. 在jQuery 1.6 之前&#…...

OSI 七层模型 | TCP/IP 四层模型
注:本文为 “OSI 七层模型 | TCP/IP 四层模型” 相关文章合辑。 未整理去重。 OSI 参考模型(七层模型) BeretSEC 于 2020-04-02 15:54:37 发布 OSI 的概念 七层模型,亦称 OSI(Open System Interconnection…...

高转速风扇|无刷暴力风扇方案设计
在当今科技高速发展的时代,电子设备的性能不断提升,散热问题也日益成为关注的焦点。而 13w 高转速暴力风扇方案的出现,为解决各种设备的散热难题提供了强大的技术支持。 一、高转速暴力风扇的重要性 随着电子设备的不断升级,其功率…...

GPU 进阶笔记(三):华为 NPU/GPU 演进
大家读完觉得有意义记得关注和点赞!!! 1 术语 1.1 CPU1.2 GPU1.3 NPU / TPU1.4 小结2 华为 DaVinci 架构:一种方案覆盖所有算力场景 2.1 场景、算力需求和解决方案2.2 Ascend NPU 设计3 路线一:NPU 用在手机芯片&…...

计算机网络 (13)信道复用技术
前言 计算机网络中的信道复用技术是一种提高网络资源利用率的关键技术。它允许在一条物理信道上同时传输多个用户的信号,从而提高了信道的传输效率和带宽利用率。 一、信道复用技术的定义 信道复用(Multiplexing)就是在一条传输媒体上同时传输…...

数据库约束和查询
一 约束意义 这个后面的字段是什么意思呢? 先前说数据类型是一种约束,约束我们只能放该类型的数据,还有其它的约束来保证数据的合法性,下面的字段就和约束有关。 编译器的编译就是一个约束,保证我们的代码一定是语法合格的。我们…...

网工日记:FTP两种工作模式的区别
FTP 的主动模式和被动模式在连接建立的发起方、数据传输端口以及对网络环境的适应性等方面存在明显区别: 1. 连接发起方 主动模式:数据连接由服务器主动发起。在控制连接建立后,客户端通过 PORT 命令告知服务器自己用于接收数据的临时端口号…...

NLP模型工程化部署
文章目录 一、理论-微服务、测试与GPU1)微服务架构2)代码测试3)GPU使用 二、实践-封装微服务,编写测试用例和脚本,并观察GPU1)微服务封装(RestFul和RPC)2)测试编写(unit_test\api_test\load_tes…...

分布式版本管理工具——git 中忽略文件的版本跟踪(初级方法及高级方法)
git工具忽略指定文件的版本跟踪 一、简单方式实现二、复杂方式实现(模式匹配)1. 相关规则2. 应用案例a) 忽略所有内容b) 忽略所有目录(不忽略当前目录的具体文件)c)忽略指定目录下的所有文件,但排除某文件d)…...
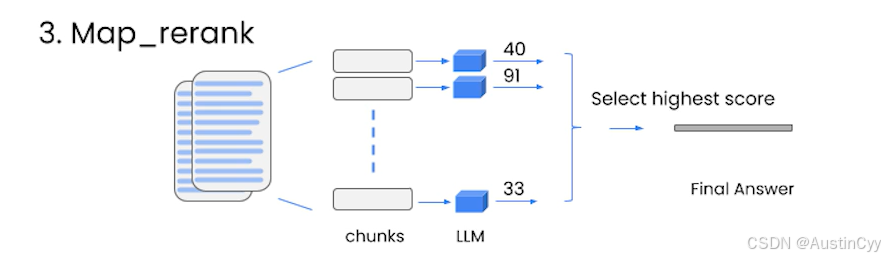
【LangChain】Chapter4 - Question and Answer Over Documents
说在前面 文档问答,是常见的一类LLM应用,给定一段可能是从 PDF文件、网页或某公司内部文档库中提取的文本,使用LLM回答关于这些文档内容的问题。这样的应用非常的强大,它可以将LLM与完全没被训练的数据相结合,可以灵活…...

TCP/IP 协议演进中的瓶颈,权衡和突破
所有(去掉 “几乎” 修饰)问题都来自于生长速度的不一致,换句话说,膨胀不是均匀的,从而产生瓶颈甚至触碰极限,TCP/IP 从协议到实现面临的多方问题与动物体型不能无限大,摩天大楼不能无限高本质上一样。 如今被高性能网…...

软件测试面试八股文,查漏补缺(附文档)
大家好,最近有不少小伙伴在后台留言,准备面试了,又不知道从何下手!为了帮大家节约时间,特意准备了一份面试相关的资料,内容非常的全面,真的可以好好补一补,希望大家在都能拿到理想的…...
IDEA工具使用介绍、IDEA常用设置以及如何集成Git版本控制工具
文章目录 一、IDEA二、建立第一个 Java 程序三、IDEA 常用设置四、IDEA 集成版本控制工具(Git、GitHub)4.1 IDEA 拉 GitHub/Git 项目4.2 IDEA 上传 项目到 Git4.3 更新提交命令 一、IDEA 1、什么是IDEA? IDEA,全称为 IntelliJ ID…...
YOLOv10-1.1部分代码阅读笔记-transformer.py
transformer.py ultralytics\nn\modules\transformer.py 目录 transformer.py 1.所需的库和模块 2.class TransformerEncoderLayer(nn.Module): 3.class AIFI(TransformerEncoderLayer): 4.class TransformerLayer(nn.Module): 5.class TransformerBlock(nn.Module)…...

OpenClaw+Kimi-VL-A3B-Thinking:自动化学习笔记整理工具
OpenClawKimi-VL-A3B-Thinking:自动化学习笔记整理工具 1. 为什么需要自动化笔记整理 作为一名长期与技术文档打交道的开发者,我发现自己陷入了一个困境:每天阅读大量论文、技术博客和在线课程,但收集的笔记却散落在不同格式的文…...

DS3232 Arduino轻量RTC库:嵌入式时间管理与I²C优化实践
1. DS3232 Arduino库深度解析:面向嵌入式工程师的精简型RTC驱动实践指南1.1 库定位与工程设计哲学DS3232 Arduino库是一个专为嵌入式实时系统优化的轻量级IC实时时钟(RTC)驱动,其核心设计目标并非功能堆砌,而是在资源受…...

代码审计 | Log4j2 —— CVE-2021-44228 JNDI 注入与递归解析的完整链路分析
代码审计 | Log4j2 —— CVE-2021-44228 JNDI 注入与递归解析的完整链路分析 目录 环境搭建 漏洞复现 编写测试代码 构造恶意 class 文件 启动 LDAP 转发器 请求流程 使用 JNDI 工具一键利用 代码审计 payload 入口追踪 MessagePatternConverter:关键转折点 substitu…...
)
C# Span<T>性能优化实战指南(90%开发者忽略的栈内存安全边界与Unsafe.As<T>陷阱)
第一章:C# Span性能优化实战指南(90%开发者忽略的栈内存安全边界与Unsafe.As陷阱)Span 的栈内存安全边界 Span<T> 在栈上分配元数据(仅 16 字节),但其指向的数据仍可能位于堆、本机内存或栈。关键约束…...

基于扩展卡尔曼滤波EKF和模型预测控制MPC,自动泊车场景建模开发,文复现。 MATLAB(工...
基于扩展卡尔曼滤波EKF和模型预测控制MPC,自动泊车场景建模开发,文复现。 MATLAB(工程项目线上支持)自动泊车这活儿看着简单,实际操作起来全是坑。今天咱们就掰开揉碎了聊聊怎么用EKF和MPC这对黄金搭档搞定车位里的毫米…...

十大AI写作工具迎来深度评测,AIGC论文助手从功能性、稳定性等维度出发,量化分析其核心表现。
工具名称 核心优势 适用场景 aicheck 快速降AIGC率至个位数 AIGC优化、重复率降低 aibiye 智能生成论文大纲 论文结构与内容生成 askpaper 文献高效整合 开题报告与文献综述 秒篇 降重效果显著 重复率大幅降低 一站式论文查重降重 查重改写一站式 完整论文优化…...
)
给嵌入式开发者的698协议实战拆解:从报文抓包到C语言解析(附代码)
给嵌入式开发者的698协议实战拆解:从报文抓包到C语言解析(附代码) 在智能电表与集中器通信领域,698协议正逐渐成为主流标准。不同于传统645协议的简单数据标识,698协议采用面向对象的设计思想,为开发者提供…...

终极Windows和Office激活指南:KMS_VL_ALL_AIO完整教程
终极Windows和Office激活指南:KMS_VL_ALL_AIO完整教程 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office激活烦恼吗?每次系统提示"产品未激活&q…...
:被忽视的IT力量——为什么业务主导的项目更需要IT深度参与?)
实战复盘】游戏上市公司合同系统实施案例(六):被忽视的IT力量——为什么业务主导的项目更需要IT深度参与?
本文为《游戏上市公司合同系统实施案例》系列第六篇。 👉 (一)业务背景|(二)多维预算|(三)合同预警|(四)安全攻防|&#x…...

OpenClaw如何做好记忆持久化的 · 六、经济学与可扩展性——记忆的代价
六、经济学与可扩展性——记忆的代价⏱ 30 秒速览 | 中度使用(日均 50 次对话)纯记忆附加成本:~$5/月(Claude Sonnet)/ ~$1/月(GPT-4o-mini)。72% 花在记忆注入,24% 花在自动提取&am…...