MYSQL 高阶语句
目录
1、排列查询
2、区间判断
3、对结果进行分组查询
4、limit和distinct
5、设置别名
通配符
6、子查询
7、exists语句,判断子查询的结果是否为空
8、视图表
9、连接查询
1. 内连接
2. 左连接
3. 右连接
create table info (
id int primary key,
name varchar(10) not null,
score decimal(5,2),
address varchar(20),
hobbid int(5)
);INSERT INTO `xy104`.`info` (`id`, `name`, `score`, `address`, `hobbid`) VALUES ('1', '高', '92', '南京西路', '12');
INSERT INTO `xy104`.`info` (`id`, `name`, `score`, `address`, `hobbid`) VALUES ('2', '徐', '93', '北京西路', '10');
INSERT INTO `xy104`.`info` (`id`, `name`, `score`, `address`, `hobbid`) VALUES ('3', '杨', '85', '云南西路', '11');
INSERT INTO `xy104`.`info` (`id`, `name`, `score`, `address`, `hobbid`) VALUES ('4', '沈', '90', '福建北路', '13');
INSERT INTO `xy104`.`info` (`id`, `name`, `score`, `address`, `hobbid`) VALUES ('5', '李', '84', '湖南北路', '14');
INSERT INTO `xy104`.`info` (`id`, `name`, `score`, `address`, `hobbid`) VALUES ('6', '林', '85', '天津西路', '15');
INSERT INTO `xy104`.`info` (`id`, `name`, `score`, `address`, `hobbid`) VALUES ('7', '杰', '82', '江苏西路', '16');
1、排列查询
select id,name from info order by score;
#我们查询的是name,按照成绩实现默认升序的操作
select id,name from info order by score desc;
#从大到小进行排序,降序select name,score from info where address='天津西路' order by id;
#查找相同字段select name,score from info order by hobbid,id;
#第一个字段必须要有相同的值,第二个字段才会有意义。#查询ID,姓名,成绩,根据爱好都是10,按照id的进行降序排列:
select id,name,score from info where hobbid=10 order by id desc;
2、区间判断
根据where的条件,来对数据进行逻辑的区分
and or
and表示逻辑且,and的所有条件都要为真。
or表示逻辑或,只要有一个条件满足即为真。
select * from info where score > 80 and score <=90;select * from info where score <80 or score > 90;区间嵌套:
select * from info where score > 80 and ( score > 90 and score < 95);
3、对结果进行分组查询
group by 语句group by都是和聚合函数一起使用的。
count()统计行数
sum()求和
avg()求平均值
max()最大值
min()最小值
select count(name),hobbid from info group by hobbid;
1、不要使用聚合函数的字段来进行分组
2、要有多个字段,按照非统计的字段来进行分组
3、对聚合函数的结果进行过滤,使用having语句
select avg(score),hobbid from info group by hobbid;
#按照hobbid分组查询
select avg(score),hobbid from info group by hobbid having avg(score)> 85;
#求聚合函数的平均值用having
CREATE TABLE `test` (`id` int NOT NULL,`name` varchar(10) NOT NULL,`score` decimal(5,2) DEFAULT NULL,`address` varchar(20) DEFAULT NULL,`hobbid` varchar(10) DEFAULT NULL,`sex` varchar(5) NOT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;INSERT INTO `xy104`.`test` (`id`, `name`, `score`, `address`, `hobbid`, `sex`) VALUES ('1', '高', '92', '南京西路', '足球', ' 男');
INSERT INTO `xy104`.`test` (`id`, `name`, `score`, `address`, `hobbid`, `sex`) VALUES ('2', '徐', '93', '南京西路', '羽毛球', '女');
INSERT INTO `xy104`.`test` (`id`, `name`, `score`, `address`, `hobbid`, `sex`) VALUES ('3', '杨', '85', '云南西路', '乒乓球', '男');
INSERT INTO `xy104`.`test` (`id`, `name`, `score`, `address`, `hobbid`, `sex`) VALUES ('4', '沈', '90', '福建北路', '乒乓球', '男');
INSERT INTO `xy104`.`test` (`id`, `name`, `score`, `address`, `hobbid`, `sex`) VALUES ('5', '李', '84', '天津北路', '乒乓球', '女');
INSERT INTO `xy104`.`test` (`id`, `name`, `score`, `address`, `hobbid`, `sex`) VALUES ('6', '林', '85', '天津北路', '冰球', '男');
INSERT INTO `xy104`.`test` (`id`, `name`, `score`, `address`, `hobbid`, `sex`) VALUES ('7', '杰', '82', '江苏西路', '冰球', '女');#1、先根据where条件过滤出成绩大于等于80分然后查询姓名,性别,按照性别来进行分组,统计姓名。
select count(name),sex from jx1 where score >= 80 group by sex;#2、求出男生组和女生组平均成绩
select avg(score),sex from jx1 group by sex;#3、分别统计处男生和女生组的最大成绩和最小成绩
select max(score),min(score),sex from jx1 group by sex;#4、根据地址进行分组,统计平均成绩大于85分的地址
select avg(score),address from jx1 group by address having avg(score)> 85;4、limit和distinct
select * from test
只显示前三个最高的成绩。
select * from test order by score desc limit 3;5、设置别名
select name as 姓名,score as 成绩 from test;
#as:就是用来起别名的命令,表名和列名过长的时候可以使用别名进行替代select name 姓名,score 成绩 from info;
#尤其是在多表联查时,可以不用申明表名
select a.hobbid,a.address,a.sex from test a,info b where a.name=b.name;#创建表时,根据另一张表的结果,直接创建,主键的约束无法继承
create table test2 as select * from test where score >90;
select * from test2;desc test2;
#查看结构
通配符
%表示0个,1个,多个字符
_下划线表示单个字符
通配符一般是和1ike一起使用,并且是配合where条件进行过滤select id,name from jx1 where name like '_';
6、子查询
内查询或者是嵌套查询,就是在查询语句当中又嵌套着另外一个select。
先查询子语句,然后把子语句的结果传给主语句进行执行
子查询的表可以是同一张表,也可以是不同的表
select where (select)select name,score from test where id in (select id from test where score > 85);
#前后的条件要一致select name,score from test where id not in (select id from test where score > 85);
#多表联查不要超过三张!更新info表,设置成绩的值是65,根据子查询的语句,只修改地址是由南京的记录的值。
update test set score=65 where address in (select address from info where address like '%南京%');
#不能 查自己 改自己。
7、exists语句,判断子查询的结果是否为空
select count(*) from test where exists(select id from test where score > 90);
#不指定字段名称时。可以不使用group by
判断返回的结果是真还是假:
select count(*)from info;
8、视图表
视图是一个虚拟表,数据基于检索的查询结果
把复杂的查询语句,简单化的呈现给用户。
查询视图就可以获取数据,避免找到真正的表,提高了数据安全。
create view test6 as select * from test1 where score >= 90;
select * from test6;
drop view test2; #删除视图
view和table之间的区别
存储方式,表都是实际数据,保存在硬盘,视图存储的不是数据行,而是结果的集合
数据更新,更新表可以更新视图,更新视图也可以更新表,一般情况下,视图仅仅用于展示数据
占用空间,表是实际空间,视图不占用数据库的空间,就是一个的结果。
注:视图表的主要作用就是通过把复杂的查询语句简化的一个查询集合
9、连接查询
把两个或者三个表的记录行结合起来,基于这些表之间共同的字段,进行数据的拼接,首先确定一个主表的结果集(主表的列),然后把其他表的行进行选择性的连接到主表的结果上。
1. 内连接
结合两个表之间基于一个字段或者多个字段之间,将两个表中结果进行组合。
create table test1 (
a_id int(11) default null,
a_name varchar(32) default null,
a_level int(11) default null);create table test2 (
b_id int(11) default null,
b_name varchar(32) default null,
b_level int(11) default null);insert into test1 values (1,'aaaa',10);
insert into test1 values (2,'bbbb',20);
insert into test1 values (3,'cccc',30);
insert into test1 values (4,'dddd',40);insert into test2 values (2,'bbbb',20);
insert into test2 values (3,'cccc',30);
insert into test2 values (5,'eeee',50);
insert into test2 values (6,'ffff',60);select a.a_id,a.a_name from test1 a INNER JOIN test2 b on a.a_name=b.b_name;
2. 左连接
左外连接,在from之后使用left join 或者 LEET OUTER JOIN 用为键字来匹配,
左连接以左侧表为基础,接受左表所有的行,并用这些行,与右侧表一起参与,
显示坐标以及右表符合条件的行,不满足的显示为nu11
select * from test1 a left join test2 b on a.a_name=b.b_name;
left左边即为左侧表
3. 右连接
右外连接,在from之后使用right join 或者 right OUTER JOIN 用为键字来匹配,
右连接以右侧表为基础,接受右表所有的行,并用这些行,与左侧表一起参与,
显示坐标以及左表符合条件的行,不满足的显示为nu11
select * from test1 a right join test2 b on a.a_name=b.b_name;
right右边即为右侧表
相关文章:

MYSQL 高阶语句
目录 1、排列查询 2、区间判断 3、对结果进行分组查询 4、limit和distinct 5、设置别名 通配符 6、子查询 7、exists语句,判断子查询的结果是否为空 8、视图表 9、连接查询 1. 内连接 2. 左连接 3. 右连接 create table info ( id int primary key, name…...

VS Code中怎样查看某分支的提交历史记录
VsCode中无法直接查看某分支的提交记录,需借助插件才行,常见的插件如果git history只能查看某页面的改动记录,无法查看某分支的整体提交记录,我们可以安装GIT Graph插件来解决这个问题 1.在 VSCode的插件库中搜索 GIT Graph安装&a…...
)
知识库搭建实战一、(基于 Qianwen 大模型的知识库搭建)
基于 Qianwen 大模型的知识库开发规划 基础环境搭建可以参考文章:基础环境搭建 在构建智能应用时,知识库是一个重要的基础模块。以下将基于 Qianwen 大模型,详细介绍构建一个标准知识库的设计思路及其实现步骤。 知识库的核心功能模块 知识库开发的核心功能模块主要包括…...

ctr方法下载的镜像能用docker save进行保存吗?
ctr 和 docker 是两个不同的容器运行时工具,它们使用的镜像存储格式是兼容的(都是 OCI 标准镜像),但它们的镜像管理方式和存储路径不同。因此,直接使用 docker save 保存 ctr 拉取的镜像可能会遇到问题。 关键点 ctr 和 docker 的镜像存储位置不同: ctr(containerd)的镜…...

win32汇编环境下,窗口程序中生成listview列表控件及显示
;运行效果 ;抄下面源码在radasm里面,可以直接编译运行。重要部分加了备注。 ;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>&…...

运维之网络安全抓包—— WireShark 和 tcpdump
为什么要抓包?何为抓包? 抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。为什么要抓包?因为在处理 IP网络…...

【复刻】数字化转型是否赋能企业新质生产力发展?(2015-2023年)
参照赵国庆(2024)的做法,对来自产业经济评论《企业数字化转型是否赋能企业新质生产力发展——基于中国上市企业的微观证据》一文中的基准回归部分进行复刻基于2015-2023年中国A股上市公司数据,实证分析企业数字化转型对新质生产力…...

【数据仓库】spark大数据处理框架
文章目录 概述架构spark 架构角色下载安装启动pyspark启动spark-sehll启动spark-sqlspark-submit经验 概述 Spark是一个性能优异的集群计算框架,广泛应用于大数据领域。类似Hadoop,但对Hadoop做了优化,计算任务的中间结果可以存储在内存中&a…...

2 秒杀系统架构
第一步 思考面临的问题和业务场景 秒杀系统面临的问题: 短时间内并发非常高,如果按照秒杀的并发做相应的承载会造成大量资源的浪费。第二解决超卖的问题。 第二步 思考目前的处境和解决方案 因为秒杀系统属于短时间内的高并发问题,我们不可能使用那么…...

UNI-APP_i18n国际化引入
官方文档:https://uniapp.dcloud.net.cn/tutorial/i18n.html vue2中使用 1. 新建文件 locale/index.js import en from ./en.json import zhHans from ./zh-Hans.json import zhHant from ./zh-Hant.json const messages {en,zh-Hans: zhHans,zh-Hant: zhHant }…...

【详解】AndroidWebView的加载超时处理
Android WebView的加载超时处理 在Android开发中,WebView是一个常用的组件,用于在应用中嵌入网页。然而,当网络状况不佳或页面加载过慢时,用户可能会遇到加载超时的问题。为了提升用户体验,我们需要对WebView的加载超时…...

RedisDesktopManager新版本不再支持SSH连接远程redis后
背景 RedisDesktopManager(又名RDM)是一个用于Windows、Linux和MacOS的快速开源Redis数据库管理应用程序。这几天从新下载RedisDesktopManager最新版本,结果发现新版本开始不支持SSH连接远程redis了。 解决方案 第一种 根据网上有效的信息,可以回退版…...

开源 SOAP over UDP
简介 看到有人想要实现两个 EXE 之间的互动。这可以采用 RPC 的方式嘛。 Delphi 现成的 RPC 框架,比如 WebService,比如 DataSnap; 当然,github 上面还有第三方开源的 XMLRPC 等等。 为啥要搞一个 UDP Delphi 的 WebService …...

Levenshtein 距离的原理与应用
引言 在文本处理和自然语言处理(NLP)中,衡量两个字符串相似度是一项重要任务。Levenshtein 距离(也称编辑距离)是一种常见的算法,用于计算将一个字符串转换为另一个字符串所需的最少编辑操作次数。这些操作…...
)
解决json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
前言 作者在读取json文件的时候出现上述报错,起初以为是自己json文件有问题,但借助在线工具查看后发现没问题,就卡住了,在debug的过程中发现了json文件读取的一个小坑,在此分享一下 解决过程 原代码 with open(anno…...

hive中的四种排序类型
1、Order by 全局排序 ASC(ascend): 升序(默认) DESC(descend): 降序 注意 :只有一个 Reducer,即使我们在设置set reducer的数量为多个,但是在执行了order by语句之后,当前此次的运算还是只有…...

Spring-AI讲解
Spring-AI langchain(python) langchain4j 官网: https://spring.io/projects/spring-ai#learn 整合chatgpt 前置准备 open-ai-key: https://api.xty.app/register?affPuZD https://xiaoai.plus/ https://eylink.cn/ 或者淘宝搜: open ai key魔法…...

【brew安装失败】DNS 查询 raw.githubusercontent.com 返回的是 0.0.0.0
从你提供的 nslookup 输出看,DNS 查询 raw.githubusercontent.com 返回的是 0.0.0.0,这通常意味着无法解析该域名或该域名被某些 DNS 屏蔽了。这种情况通常有几个可能的原因: 可能的原因和解决方法 本地 DNS 问题: 有可能是你的本…...

HTML——29. 音频引入二
<!DOCTYPE html> <html><head><meta charset"UTF-8"><title>音频引入</title></head><body><!--audio:在网页中引入音频IE8以及之前版本不支持属性名和属性值一样,可以只写属性名src属性:指定音频文件…...
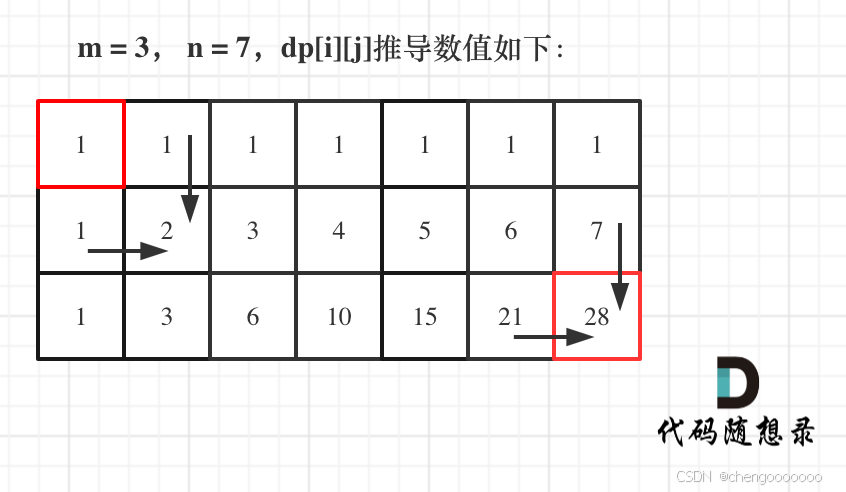
代码随想录训练营第三十四天| 62.不同路径 63. 不同路径 II
62.不同路径 题目链接:62. 不同路径 - 力扣(LeetCode) 讲解链接:代码随想录 动态规划五步走 1 定义dp数组是到dp[i][j]时有dp[i][j]条路径 dp[i][j] :表示从(0 ,0)出发…...

CANN/cann-bench MHA算子API描述
MHA 算子 API 描述 【免费下载链接】cann-bench 评测AI在处理CANN领域代码任务的能力,涵盖算子生成、算子优化等领域,支撑模型选型、训练效果评估,统一量化评估标准,识别Agent能力短板,构建CANN领域评测平台࿰…...

拯救者笔记本终极优化指南:5个必知技巧彻底释放硬件潜能
拯救者笔记本终极优化指南:5个必知技巧彻底释放硬件潜能 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 你是否厌…...

PotPlayer百度翻译插件终极指南:免费实现20+语言实时字幕翻译
PotPlayer百度翻译插件终极指南:免费实现20语言实时字幕翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu PotPlayer字幕…...

[实战剖析] 从零构建CSRF攻击:GET与POST请求的攻防博弈
1. CSRF攻击的本质与危害 跨站请求伪造(CSRF)就像有人偷偷用你的手机给朋友发消息。想象你登录了社交网站没有退出,这时访问了恶意网页,它就能冒充你执行加好友、改资料等操作。这种攻击不需要窃取密码,只要浏览器保持…...

Vue3后台管理系统终极指南:5个关键问题与V3 Admin Vite解决方案
Vue3后台管理系统终极指南:5个关键问题与V3 Admin Vite解决方案 【免费下载链接】v3-admin-vite ☀️ A crafted Vue3 admin template | Vue Admin | Vue Template | Vue3 Admin | Vue3 Template | Vue 后台 | Vue 模板 | Vue3 后台 | Vue3 模板 项目地址: https:…...

STM32F103 + TM1628实战:如何用31个LED做一个可调亮度的简易仪表盘?
STM32F103 TM1628实战:如何用31个LED打造智能动态仪表盘 在嵌入式开发领域,将基础硬件模块转化为实用创意项目的能力,往往是区分普通开发者和资深工程师的关键。STM32F103作为经典的ARM Cortex-M3内核微控制器,以其出色的性价比和…...

影像技术实战12:图片清晰度评估不准?Laplacian、Tenengrad、噪声干扰与模糊图片批量筛选方案
影像技术实战12:图片清晰度评估不准?Laplacian、Tenengrad、噪声干扰与模糊图片批量筛选方案 一、问题场景:数据集里混入模糊图,模型效果怎么调都上不去 在图像识别、OCR、人脸识别、商品图审核、视频抽帧数据清洗中,经…...
:金融工程师内部使用的12项校验规则)
Perplexity股票数据清洗SOP(含NASDAQ非标字段映射表):金融工程师内部使用的12项校验规则
更多请点击: https://codechina.net 第一章:Perplexity股票信息检索 Perplexity AI 公司尚未上市,因此不存在公开交易的股票代码、实时行情或交易所挂牌信息。这一事实常被开发者和投资者误读,尤其在使用金融数据 API 时容易触发…...
)
实测!Gemini+ChatGPT赋能学术写作:我的论文写作SOP(附提示词)
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 为什么ChatGPT逻辑清晰却写不长?为什么Gemini能深入分析但废话连篇? …...

视听融合新范式!黎阳之光打破视觉边界,声影协同赋能全域智慧管控
长久以来,图形图像可视化技术早已成为智慧安防、低空管控、工业监测领域的主流应用,依托高清视频、三维实景、数字孪生图形图像能力,实现场景直观呈现、目标可视追踪、环境全景复刻,为各行各业搭建起可视化智慧管理体系。深耕图形…...