【数据仓库】spark大数据处理框架
文章目录
- 概述
- 架构
- spark 架构角色
- 下载
- 安装
- 启动pyspark
- 启动spark-sehll
- 启动spark-sql
- spark-submit
- 经验
概述
Spark是一个性能优异的集群计算框架,广泛应用于大数据领域。类似Hadoop,但对Hadoop做了优化,计算任务的中间结果可以存储在内存中,不需要每次都写入HDFS,更适用于需要迭代运算的算法场景中。
Spark专注于数据的处理分析,而数据的存储还是要借助于Hadoop分布式文件系统HDFS等来实现。
大数据问题场景包含以下三种:
- 复杂的批量数据处理
- 基于历史数据的交互式查询
- 基于实时数据流的数据处理
Spark技术栈基本可以解决以上三种场景问题。
架构

1 spark Core :spark的核心模块,是spark运行基础。以RDD为数据抽象,提供python、java、scala、R语言的api,可以通过RDD编程进行海量离线数据批处理计算。
2 Spark SQL:基于Spark Core,提供结构化数据处理功能。可以使用SQL语言对数据进行处理,可用于离线计算场景。同时基于Spark SQL提供了StructuredStreaming模块,可以使用时SQL进行流式计算。
3 sparkStreaming : 以Spark Core为基础,提供数据的流式计算功能
4 MLlib:以spark Core为基础,进行机器学习计算,内置大量机器学习库和API算法等。
5 Graphx:以spark Core为基础,进行图计算,提供大量图计算的API,方便以分布式资源进行图计算。
6 spark底层的文件存储还是基于hdfs分布式文件系统,支持多种部署方式。
spark 架构角色

从两个层面理解:
资源管理层面:(典型的Master-Worker架构)
管理者:即Master角色,只能有一个
工作者:即Worker角色,可以有多个。一个worker在一个分布式节点上,监测当前节点的资源状况,向master节点汇总。
任务执行层面:
某任务管理者:Driver角色,一个任务只能有一个
某任务执行者:Executor角色,可以有多个
在特殊场景下(local模式),Driver即是管理者又是执行者
下载
下载地址:
http://spark.apache.org/downloads.html
或者
https://archive.apache.org/dist/spark/
选择合适自己的版本下载。
Spark2.X预编译了Scala2.11(Spark2.4.2预编译Scala2.12)
Spark3.0+预编译了Scala2.12
该教程选择Spark3.2.1版本,其中预编译了Hadoop3.2和Scala2.13,对应的包是 spark-3.2.1-bin-hadoop3.2-scala2.13.tgz,但这里的预编译Hadoop不是指不需要再安装Hadoop。
linux 服务器上下载地址
wget https://archive.apache.org/dist/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2-scala2.13.tgz
安装
Spark的安装部署支持三种模式,
local本地模式(单机):启动一个JVM Process进程,通过其内部的多个线程来模拟整个spark运行时各个角色。一个进程里有多个线程。
Local[N]:可以使用N个线程,一个线程利用一个cpu核,通常cpu有几个核,就指定几个线程,最大化利用计算能力;
Local[*],按照cpu核数设置线程数;
standalone模式(集群):各个角色以独立进程的形式存在,并组成spark集群
spark on YARN模式(集群):各个角色运行在yarn的容器内部,组成集群环境
kubernetes 模式(容器集群):各个角色运行在kubernetes 容器内部,组成集群环境
本文将只介绍 本地Local模式,其它模式将会在后续文章中进行介绍。
该文的安装环境为centos7。
1、将下载的包上传到服务器指定目录,解压
[root@localhost softnew]# tar zxvf spark-3.1.2-bin-hadoop3.2.tgz
# 修改目录
mv spark-3.1.2-bin-hadoop3.2 spark-3.1.2
2、修改配置文件
修改/etc/profile文件,新增spark环境变量:
# Spark Environment Variablesexport SPARK_HOME=/home/bigData/softnew/sparkexport PATH=$PATH:$SPARK_HOME/bin
修改完成后记得执行 source /etc/profile 使其生效
启动pyspark
pyspark 是spark集成python后,可以使用python 脚本编写spark 数据 批处理计算。pyspark提供了一个shell窗口。
./pyspark
[root@yd-ss bin]# ./pyspark
Python 3.10.10 (main, Dec 26 2024, 22:46:13) [GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
24/12/27 10:46:44 WARN Utils: Your hostname, yd-ss resolves to a loopback address: 127.0.0.1; using xx.xx.xx.xx instead (on interface bond0)
24/12/27 10:46:44 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
24/12/27 10:46:46 WARN HiveConf: HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
24/12/27 10:46:46 WARN HiveConf: HiveConf of name hive.server2.active.passive.ha.enable does not exist
24/12/27 10:46:46 WARN HiveConf: HiveConf of name hive.exec.default.charset does not exist
24/12/27 10:46:46 WARN HiveConf: HiveConf of name hive.exec.default.national.charset does not exist
24/12/27 10:46:46 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//__ / .__/\_,_/_/ /_/\_\ version 3.2.1/_/Using Python version 3.10.10 (main, Dec 26 2024 22:46:13)
Spark context Web UI available at http://sc:4040
Spark context available as 'sc' (master = local[*], app id = local-1735267609271).
SparkSession available as 'spark'.
>>>
进入窗口,即可使用python 写RDD编程代码了。
同时,可以通过web ui 在4040端口访问,查看spark 任务执行情况。
执行如下计算任务
sc.parallelize([1,2,3,4,5]).map(lambda x:x*10).collect()
访问localhost:4040

可以看到job清单,这个job,起了24个线程去处理计算。 由于跑任务的服务器是24核的,执行./pyspark 默认以local[*]最大线程去启动。

可以看到任务层面,启动了一个driver,由于是local模式,所以driver即是管理者也是执行者。
可以在pyspark-shell下利用spark做一些简单开发任务;
下面修改启动命令:
# 该local模式启动2个线程
./pyspark --master local[2]
再次执行
sc.parallelize([1,2,3,4,5]).map(lambda x:x*10).collect()

可以看到这个job只用了2个线程来处理计算。
还可以利用该shell处理其他计算任务,也就是说一个shell 启动起来,是可以处理多个任务的,但只要关闭窗口,shell就会关闭。就不能再处理任务了。
通过shell 总是不便,后续将介绍通过pycharm进行RDD计算任务编写。
退出shell脚本
quit()或者ctrl + D
启动spark-sehll
./spark-shell
可以看到如下信息:
[root@yd-ss bin]# ./spark-shell
24/12/27 11:11:50 WARN Utils: Your hostname, yd-ss resolves to a loopback address: 127.0.0.1; using xx.xx.xx.xx instead (on interface bond0)
24/12/27 11:11:50 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 3.2.1/_/Using Scala version 2.13.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_201)
Type in expressions to have them evaluated.
Type :help for more information.
24/12/27 11:12:04 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://sc:4040
Spark context available as 'sc' (master = local[*], app id = local-1735269126553).
Spark session available as 'spark'.scala>这个是要使用scala语言编写,其他跟pyspark类似。
启动spark-sql
./spark-sql
可以看到如下:
[root@yd-ss bin]# ./spark-sql
24/12/27 11:14:28 WARN Utils: Your hostname, yd-ss resolves to a loopback address: 127.0.0.1; using xx.xx.xx.xx instead (on interface bond0)
24/12/27 11:14:28 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
24/12/27 11:14:29 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
24/12/27 11:14:30 WARN HiveConf: HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
24/12/27 11:14:30 WARN HiveConf: HiveConf of name hive.server2.active.passive.ha.enable does not exist
24/12/27 11:14:30 WARN HiveConf: HiveConf of name hive.exec.default.charset does not exist
24/12/27 11:14:30 WARN HiveConf: HiveConf of name hive.exec.default.national.charset does not exist
Spark master: local[*], Application Id: local-1735269273943
spark-sql>可以看到这个是依赖hive数仓配置的。spark-sql是没有元数据管理的,所以需要跟hive集成,利用其元数据管理功能。后续将详细介绍。
spark-submit
该工具是用来提交写好的计算脚本,到saprk上去执行,执行完成即结束。和前面的shell不一样,shell只要没关闭,就可以一直执行的。
# 执行spark自带的python示例,计算pi的值(8次迭代)
./spark-submit /home/spark/spark-3.2.1/examples/src/main/python/pi.py 8
该脚本,会基于spark启动一个driver,执行pi.py计算,然后打开web ui 4040监控接口,执行完成后输出结果,最后关闭driver,关闭web ui。
是个一次性的任务执行。
经验
1 spark 功能比较强大,使用方式也很丰富,初步学习只需要了解自己使用方式即可;
2 spark local模式使用配置是比较简单的,基本是开箱即用;
相关文章:
【数据仓库】spark大数据处理框架
文章目录 概述架构spark 架构角色下载安装启动pyspark启动spark-sehll启动spark-sqlspark-submit经验 概述 Spark是一个性能优异的集群计算框架,广泛应用于大数据领域。类似Hadoop,但对Hadoop做了优化,计算任务的中间结果可以存储在内存中&a…...

2 秒杀系统架构
第一步 思考面临的问题和业务场景 秒杀系统面临的问题: 短时间内并发非常高,如果按照秒杀的并发做相应的承载会造成大量资源的浪费。第二解决超卖的问题。 第二步 思考目前的处境和解决方案 因为秒杀系统属于短时间内的高并发问题,我们不可能使用那么…...

UNI-APP_i18n国际化引入
官方文档:https://uniapp.dcloud.net.cn/tutorial/i18n.html vue2中使用 1. 新建文件 locale/index.js import en from ./en.json import zhHans from ./zh-Hans.json import zhHant from ./zh-Hant.json const messages {en,zh-Hans: zhHans,zh-Hant: zhHant }…...

【详解】AndroidWebView的加载超时处理
Android WebView的加载超时处理 在Android开发中,WebView是一个常用的组件,用于在应用中嵌入网页。然而,当网络状况不佳或页面加载过慢时,用户可能会遇到加载超时的问题。为了提升用户体验,我们需要对WebView的加载超时…...

RedisDesktopManager新版本不再支持SSH连接远程redis后
背景 RedisDesktopManager(又名RDM)是一个用于Windows、Linux和MacOS的快速开源Redis数据库管理应用程序。这几天从新下载RedisDesktopManager最新版本,结果发现新版本开始不支持SSH连接远程redis了。 解决方案 第一种 根据网上有效的信息,可以回退版…...

开源 SOAP over UDP
简介 看到有人想要实现两个 EXE 之间的互动。这可以采用 RPC 的方式嘛。 Delphi 现成的 RPC 框架,比如 WebService,比如 DataSnap; 当然,github 上面还有第三方开源的 XMLRPC 等等。 为啥要搞一个 UDP Delphi 的 WebService …...

Levenshtein 距离的原理与应用
引言 在文本处理和自然语言处理(NLP)中,衡量两个字符串相似度是一项重要任务。Levenshtein 距离(也称编辑距离)是一种常见的算法,用于计算将一个字符串转换为另一个字符串所需的最少编辑操作次数。这些操作…...
)
解决json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
前言 作者在读取json文件的时候出现上述报错,起初以为是自己json文件有问题,但借助在线工具查看后发现没问题,就卡住了,在debug的过程中发现了json文件读取的一个小坑,在此分享一下 解决过程 原代码 with open(anno…...

hive中的四种排序类型
1、Order by 全局排序 ASC(ascend): 升序(默认) DESC(descend): 降序 注意 :只有一个 Reducer,即使我们在设置set reducer的数量为多个,但是在执行了order by语句之后,当前此次的运算还是只有…...

Spring-AI讲解
Spring-AI langchain(python) langchain4j 官网: https://spring.io/projects/spring-ai#learn 整合chatgpt 前置准备 open-ai-key: https://api.xty.app/register?affPuZD https://xiaoai.plus/ https://eylink.cn/ 或者淘宝搜: open ai key魔法…...

【brew安装失败】DNS 查询 raw.githubusercontent.com 返回的是 0.0.0.0
从你提供的 nslookup 输出看,DNS 查询 raw.githubusercontent.com 返回的是 0.0.0.0,这通常意味着无法解析该域名或该域名被某些 DNS 屏蔽了。这种情况通常有几个可能的原因: 可能的原因和解决方法 本地 DNS 问题: 有可能是你的本…...

HTML——29. 音频引入二
<!DOCTYPE html> <html><head><meta charset"UTF-8"><title>音频引入</title></head><body><!--audio:在网页中引入音频IE8以及之前版本不支持属性名和属性值一样,可以只写属性名src属性:指定音频文件…...
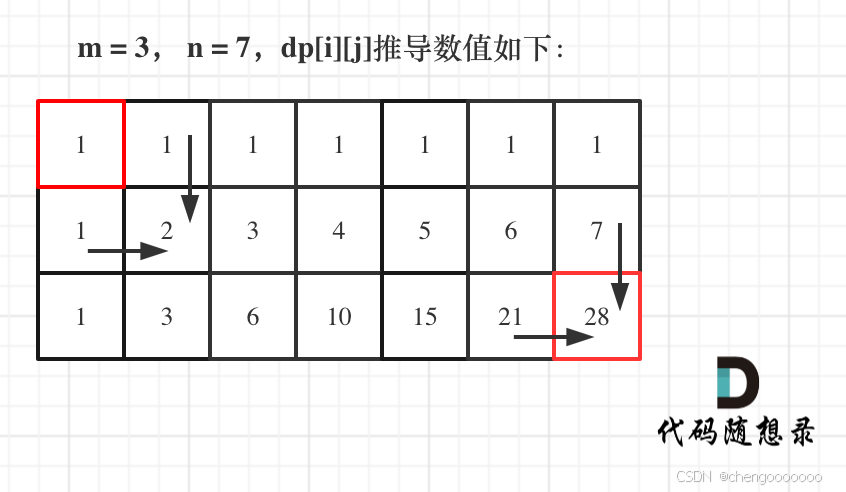
代码随想录训练营第三十四天| 62.不同路径 63. 不同路径 II
62.不同路径 题目链接:62. 不同路径 - 力扣(LeetCode) 讲解链接:代码随想录 动态规划五步走 1 定义dp数组是到dp[i][j]时有dp[i][j]条路径 dp[i][j] :表示从(0 ,0)出发…...

V90伺服PN版组态配置<一>
1、添加PLC之后,继续博图中网络视图中添加新设备,添加伺服驱动器组态设备 2、SINAMICS V90 PN V1.0 3、修改驱动器的IP地址。 【注意】 在项目中提前做好项目规划,如PLC设备从192.168.0.1开始,顺序递增------个位数都是CPU设备…...

又一年。。。。。。
2024,浑浑噩噩的一年。 除了100以内的加减法(数据,数据,还是数据。。。。。。),似乎没做些什么。 脸盲症越来越重的,怕是哪天连自己都不认得自己的了。 看到什么,听到什…...

xterm + vue3 + websocket 终端界面
xterm.js 下载插件 // xterm npm install --save xterm// xterm-addon-fit 使终端适应包含元素 npm install --save xterm-addon-fit// xterm-addon-attach 通过websocket附加到运行中的服务器进程 npm install --save xterm-addon-attach <template><div :…...

医疗数仓业务数据采集与同步
业务数据采集与同步 业务采集组件配置业务数据同步概述数据同步策略选择数据同步工具概述1.1.4 全量表数据同步DataX配置文件生成全量表数据同步脚本增量表数据同步 MySQL - Maxwell - Kafka - Flume - HDFSMaxwell配置增量表首日全量同步 业务采集组件配置 Maxwell将业务采集到…...

数字孪生智慧水利与水务所包含的应用场景有哪些?二者有何区别
水利和水务是两个密切相关但有所区别的概念,它们在水资源管理和保护方面各自承担着不同的职责和功能。 定义 智慧水务:智慧水务是指通过物联网、大数据、云计算、人工智能等新一代信息技术,对城市供水、排水、污水处理、水质监测等水务系统…...

Qt Creator项目构建配置说明
QT安装好之后,在安装目录的Tools\QtCreator\bin下找到qtcreator.exe文件并双击打开 点击文件-新建文件或项目 选择Qt Widgets Application 设置项目名称以及路径 make工具选择qmake(cmake还未尝试过) 设置主界面对应类的名称、父类&#…...

进程间通信的“五大武器”
😄作者简介: 小曾同学.com,一个致力于测试开发的博主⛽️,主要职责:测试开发、CI/CD 如果文章知识点有错误的地方,还请大家指正,让我们一起学习,一起进步。 😊 座右铭:不…...

避坑指南:OpenMV形状识别参数调不好?从霍夫圆检测到find_rects的实战经验分享
OpenMV形状识别实战:从参数调优到多场景适配的深度解析 当你在实验室里用OpenMV官方例程完美识别出圆形贴片时,是否曾信心满满地将设备搬到车间现场,却发现识别率断崖式下跌?这种"实验室王者,现场青铜"的困…...

IfcOpenShell技术架构深度解析:开源IFC引擎的模块化设计与高性能实现
IfcOpenShell技术架构深度解析:开源IFC引擎的模块化设计与高性能实现 【免费下载链接】IfcOpenShell Open source IFC library and geometry engine 项目地址: https://gitcode.com/gh_mirrors/if/IfcOpenShell IfcOpenShell作为开源建筑信息模型(…...

长期项目使用Taotoken聚合API在稳定性与成本上的综合感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期项目使用Taotoken聚合API在稳定性与成本上的综合感受 在最近一个持续数月的实际开发项目中,我们选择将Taotoken作为…...

思源宋体TTF格式终极指南:免费商用中文字体的完整使用教程
思源宋体TTF格式终极指南:免费商用中文字体的完整使用教程 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目寻找既专业又免费的中文字体而烦恼吗?…...
保姆级配置与排错指南)
别再为VMware里Kali上不了网发愁了!三种网络模式(桥接/NAT/仅主机)保姆级配置与排错指南
VMware中Kali Linux网络配置全攻略:从原理到实战排错 当你第一次在VMware中启动Kali Linux准备大展身手时,却发现连最基本的网络连接都无法建立——这种挫败感我深有体会。作为网络安全学习和渗透测试的必备工具,Kali在虚拟机中的网络配置往往…...

实用汽车CAN总线解码:opendbc项目如何高效解决汽车数据解析难题
实用汽车CAN总线解码:opendbc项目如何高效解决汽车数据解析难题 【免费下载链接】opendbc a Python API for your car 项目地址: https://gitcode.com/gh_mirrors/op/opendbc 在汽车电子开发、ADAS系统研究或汽车诊断领域,你是否曾面临这样的困境…...

终极指南:Visual C++运行库合集AIO - 一站式解决Windows软件依赖问题
终极指南:Visual C运行库合集AIO - 一站式解决Windows软件依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 还在为运行软件时遇到"找不到…...
)
告别编译报错!手把手教你为最新版Keil MDK安装ARM Compiler 5(保姆级图文)
嵌入式开发者的救星:彻底解决Keil MDK缺失ARM Compiler 5的终极方案 当你满怀信心地打开一个历史遗留的嵌入式项目,准备进行功能迭代时,Keil MDK突然弹出一个冰冷的错误窗口:"Error: Compiler V5.06 update 7 (build 960) no…...

工业控制新方案:电容HMI与字符LCD组合应用实战
1. 项目概述:当经典LCD遇上电容触控,工业控制的新解法最近在做一个产线设备升级的项目,客户对操作界面的要求突然拔高了不少:既要能看清复杂的工艺参数,又要求操作像手机一样流畅,还得扛得住车间里的油污、…...

meituan 民宿 mtgsig1.2
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!逆向分析cp execjs.compile(open(民宿-…...